Starlake 是一款免费开源的 ETL 数据管道编排工具,可以通过声明式的配置方法(YAML、SQL)简化数据处理流程。
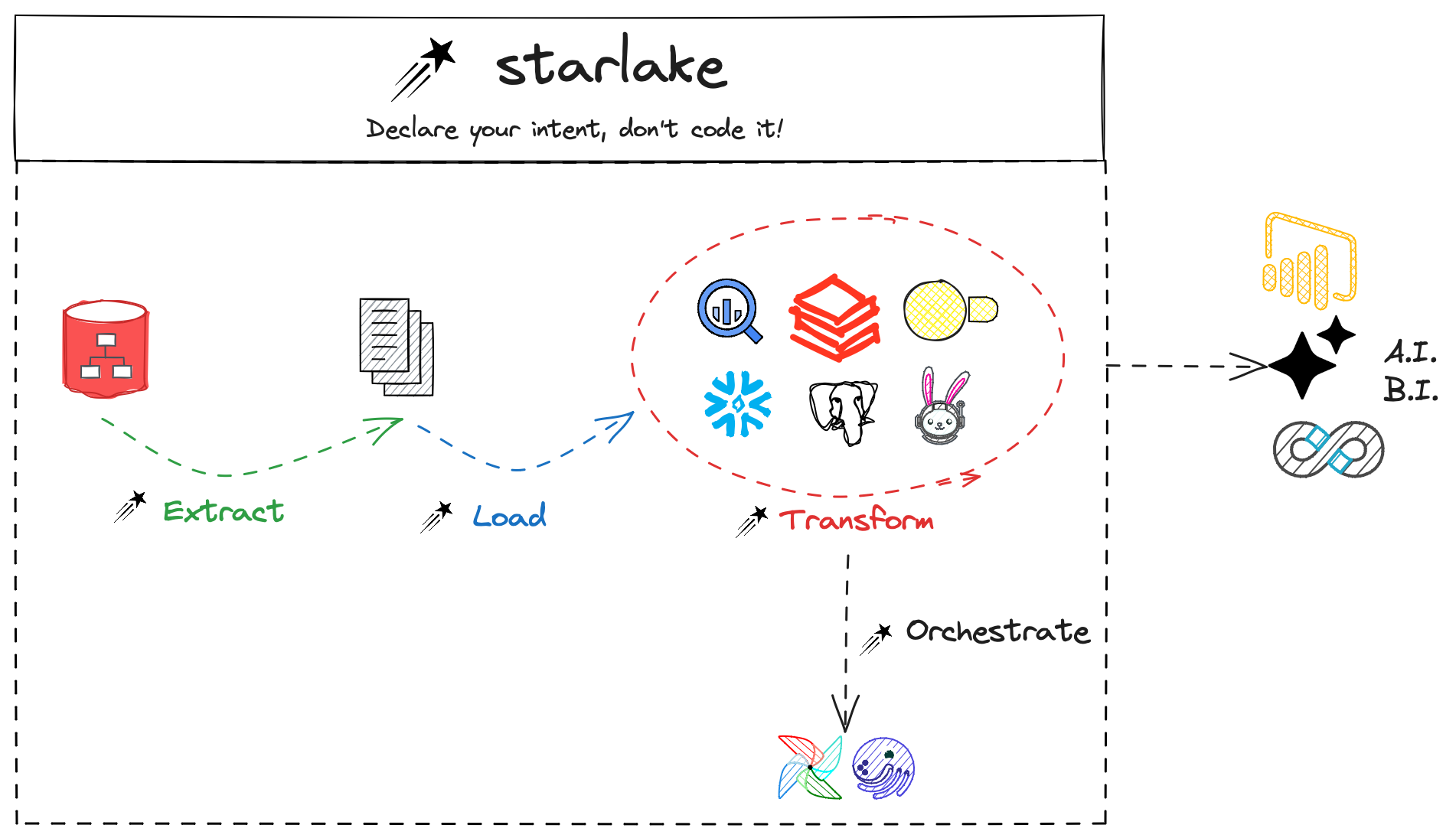
Starlake 项目主要基于 Scala 语言开发,遵循 Apache 2.0 开源协议,代码托管在 GitHub:
https://github.com/starlake-ai/starlake
功能特性
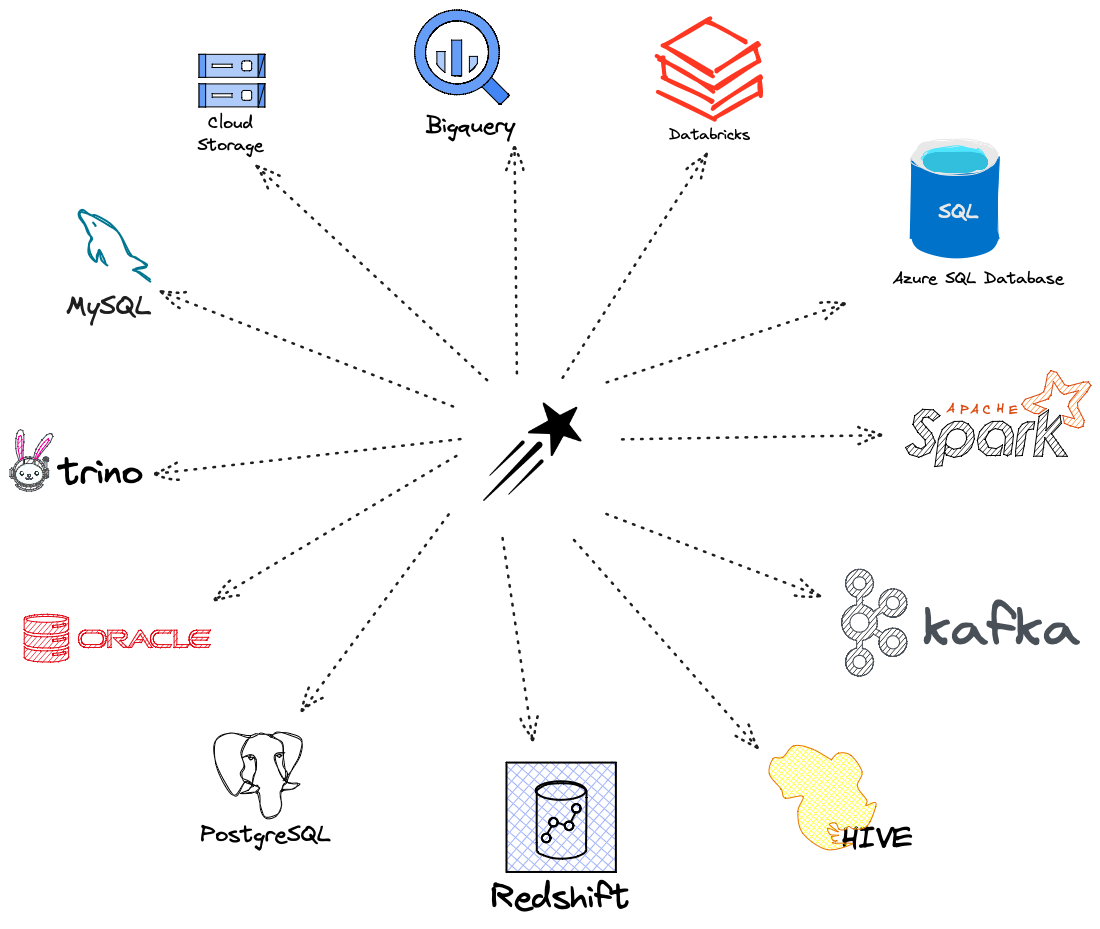
- 丰富的数据源:包括 Apache Spark、Databricks、Apache Kafka、Amazon Redshift、DuckDB、DuckLake、Google BigQuery、Snowflake、PostgreSQL、 MySQL、Oracle、SQL Server、JDBC、本地文件(JSON、CSV、Excel、XML、Parquet 等)。
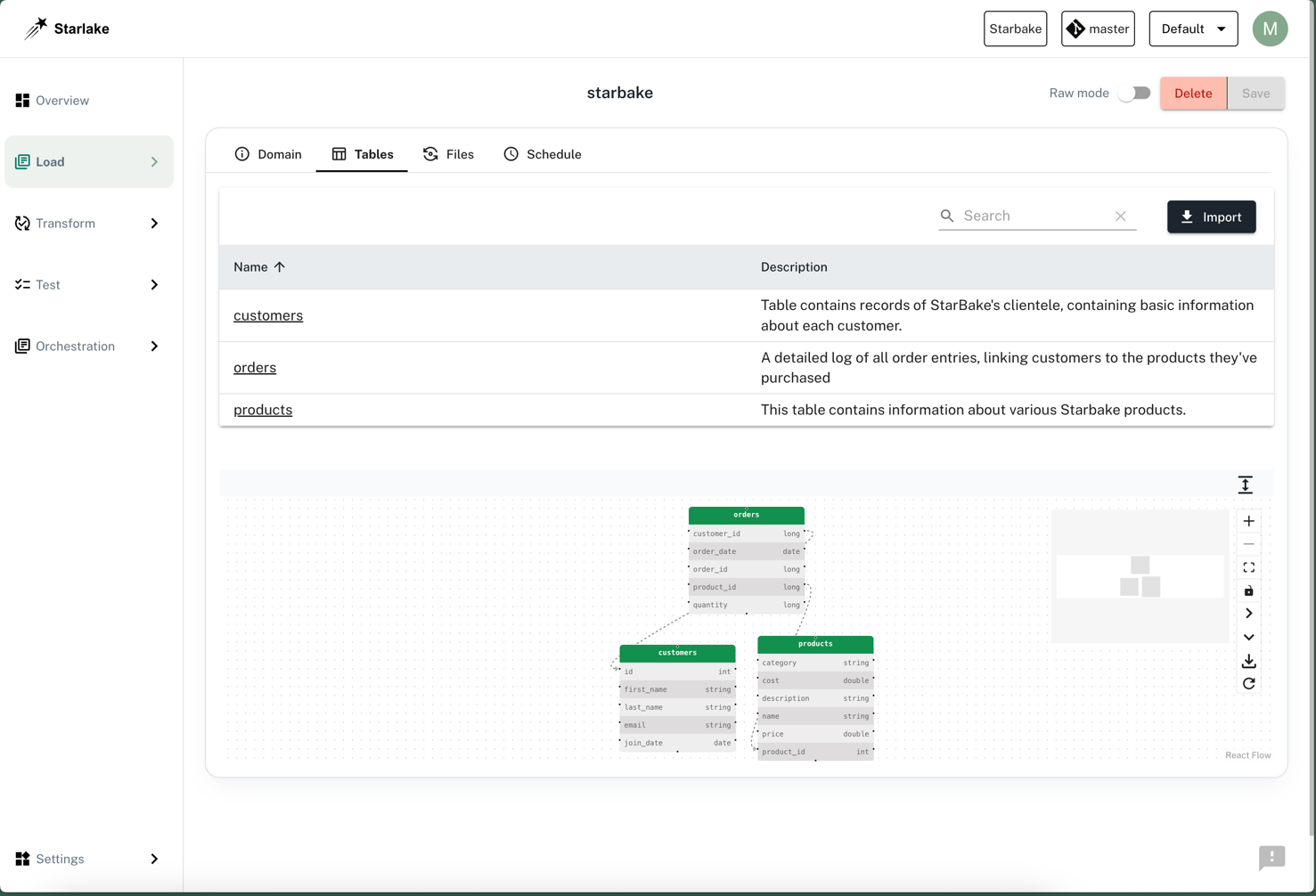
- 零代码数据提取:通过 YAML 配置文件实现全量或者增量数据提取和加载,包括自动化的数据质量验证,数据隐私安全控制,应用行级和列级安全,整个不需要编写任何代码。
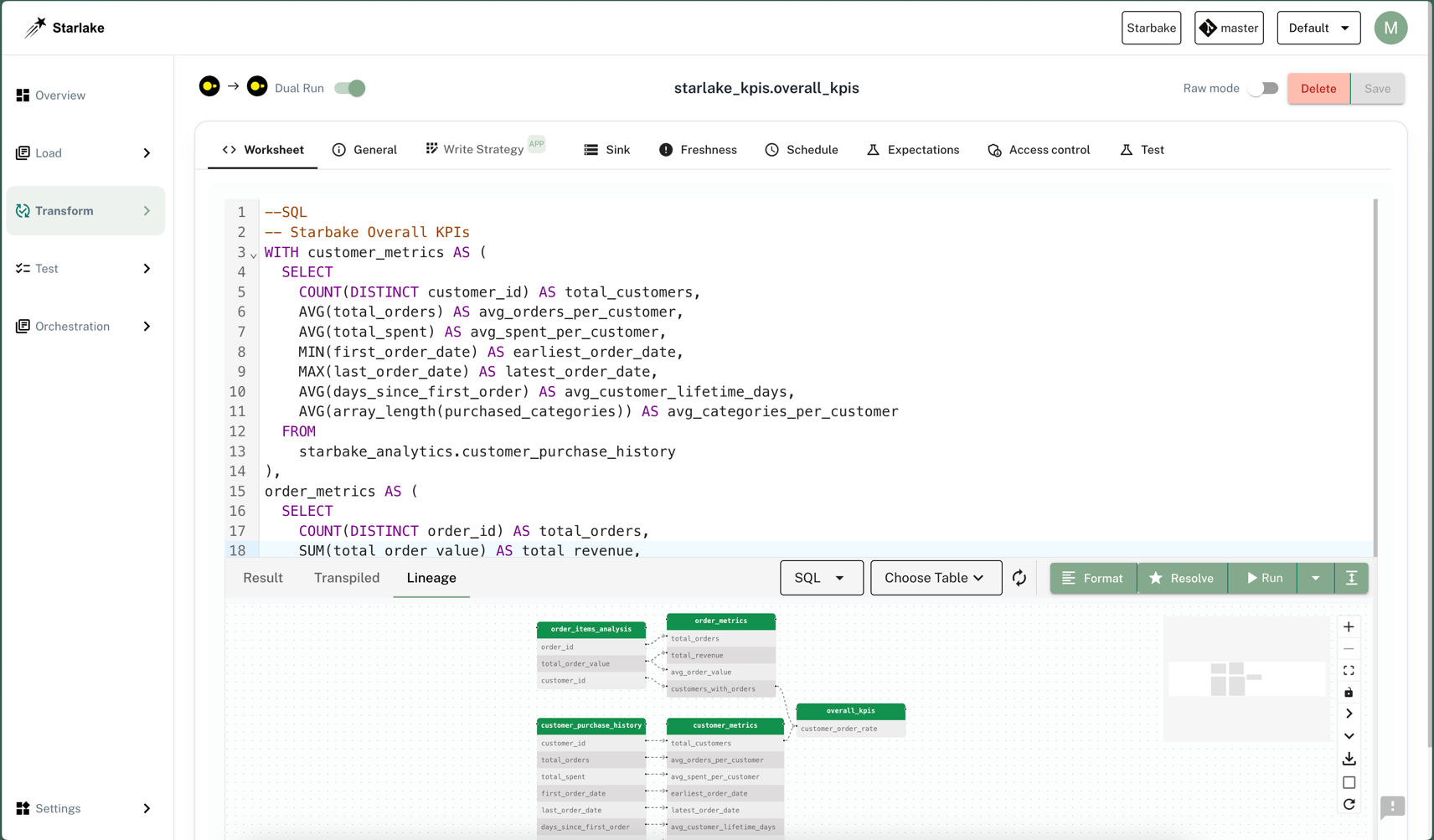
- 低代码数据转换:基于 SQL 和 YAML 定义转换操作,自动化表级和字段级血缘关系。也可以通过 Python 脚本实现复杂的数据转换。
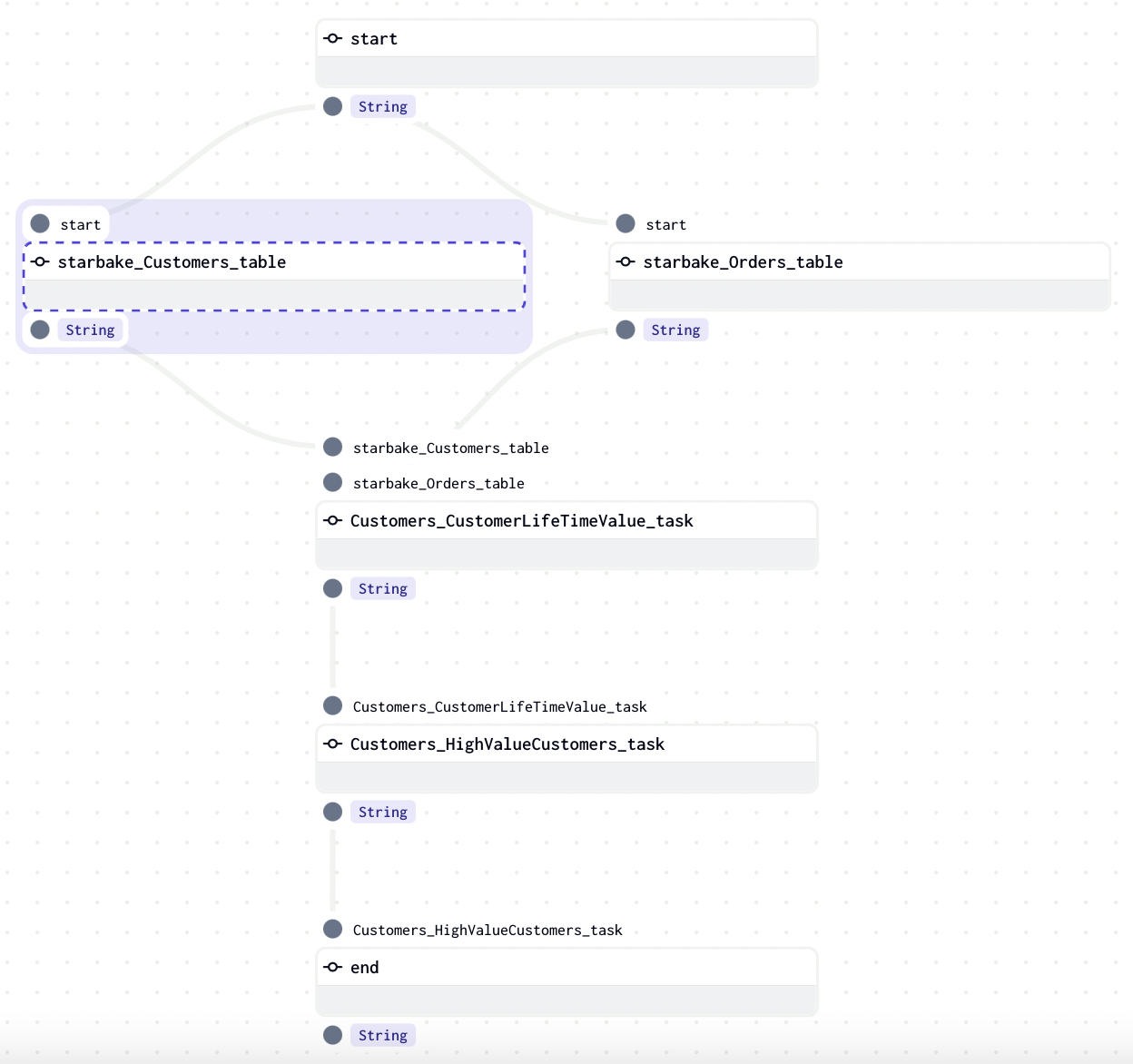
- 自动化流程编排:Starlake 可以生成任务的有向无环图(DAG),通过集成 Airflow、Dagster 等流程编排工具实现流程自动化。
- 数据治理和质量:支持每个操作节点的模式约束、规则验证、质量检查等措施确保数据一致性与合规性。
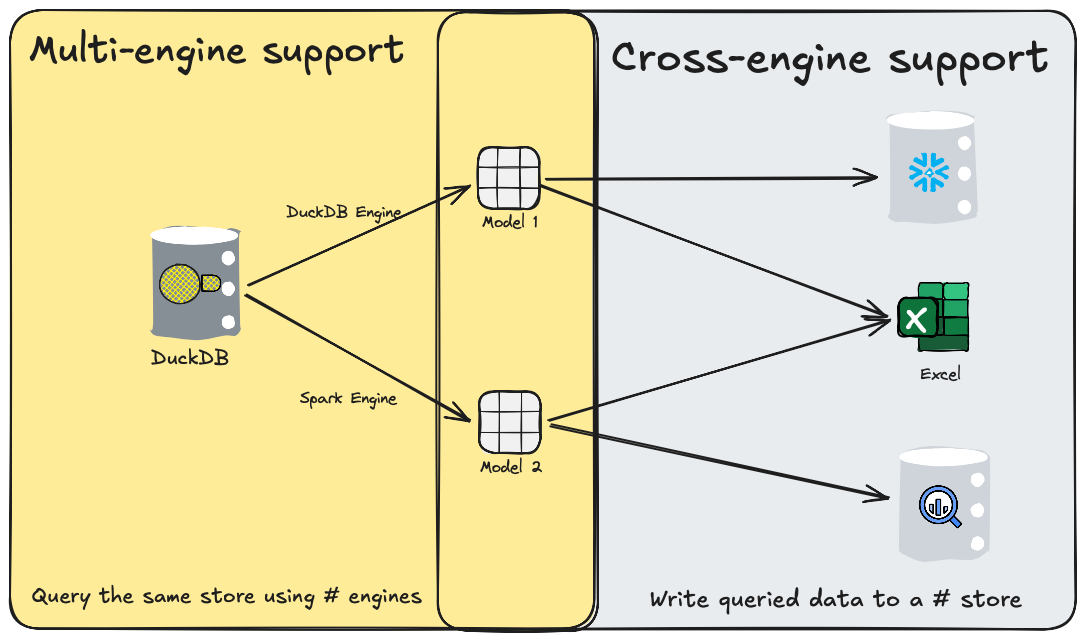
- 多引擎与跨引擎:Starlake 支持为不同的任务模型使用不同的存储引擎,例如使用原生数据仓库引擎执行简单的加载操作,同时使用 Spark 引擎处理 XML 文件或者加载过程中的转换操作。
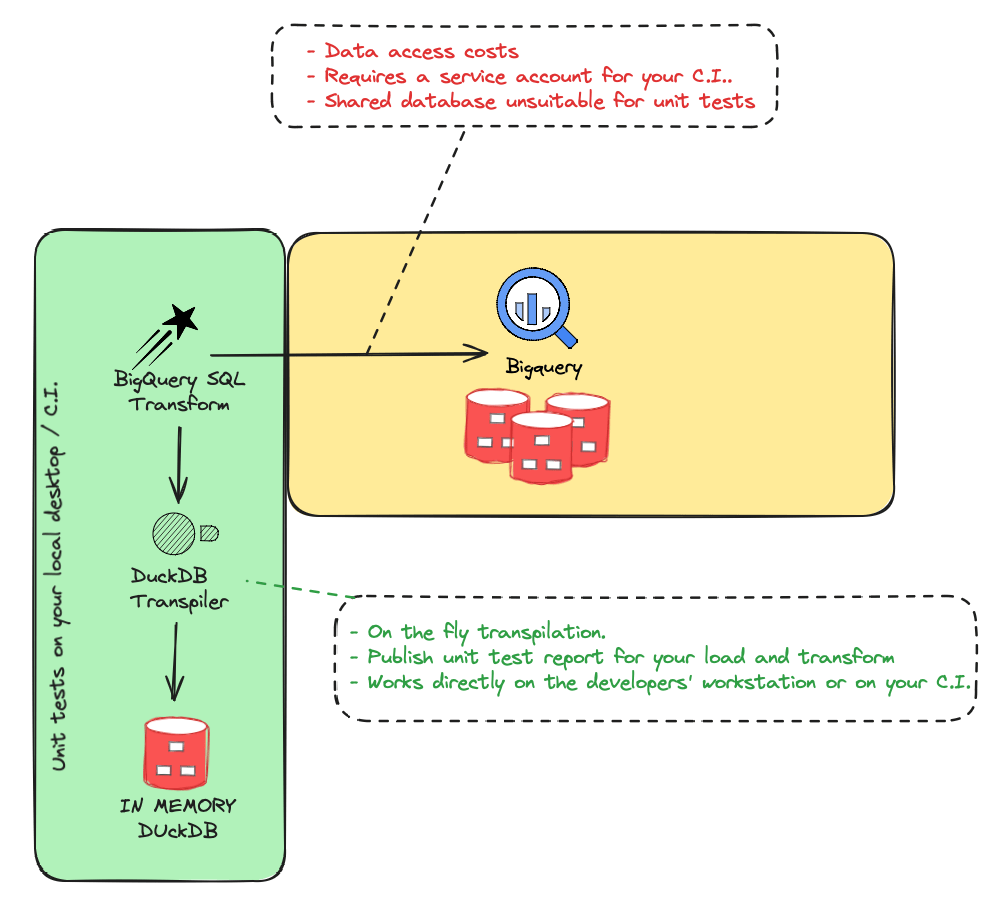
- 本地化测试集成:Starlake 提供了一个转换编译器,可以将各种 SQL 实现转换为本地 DuckDB 语法,不需要配置额外的测试环境就可以验证数据加载、数据转换等流程。
- VS Code 插件:支持 Starlake 配置语法高亮、模式验证、SQL 代码片段、数据管道可视化等功能。
下载安装
Starlake 支持本地部署,使用 Docker 进行安装体验的命令如下:
# 拉取最新镜像
docker pull starlakeai/starlake:latest
# 验证安装
docker run -it starlakeai/starlake:latest help然后可以参照以下指南和教程构建数据处理管道:
https://docs.starlake.ai/category/guides--tutorials
总结
Starlake 提供了一种基于配置的低代码数据集成管道和数据治理解决方案。