✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:大数据、Java、测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨

前言&课程重点
大家好,我是程序员小羊!接下来一周,咱们将用 "实战拆解 + 技术落地" 的方式,带大家吃透一个完整的大数据电商项目 ------不管你是想靠项目经验敲开大厂就业门,还是要做毕业设计、提升技术深度,这门课都能帮你 "从懂概念到能落地"。
毕竟大数据领域不缺 "会背理论" 的人,缺的是 "能把项目跑通、能跟业务结合" 的实战型选手。咱们这一周的内容,不搞虚的,全程围绕 "电商业务痛点→数据解决方案→技术栈落地" 展开,每天聚焦 1 个核心模块,最后还能输出可放进简历的项目成果。
进入正题:
本项目是一门实战导向的大数据课程,专为具备Java基础但对大数据生态系统不熟悉的同学量身打造。你将从零开始,逐步掌握大数据的基本概念、架构原理以及在电商流量分析中的实际应用,迅速融入当下热门的离线数据处理技术。
在这门课程中,你将学会如何搭建和优化Hadoop高可用环境,了解HDFS存储、YARN资源调度的核心原理,为数据处理打下坚实的基础。同时,你将掌握Hive数据仓库的构建和数仓建模方法,了解如何将海量原始数据经过层次化处理,转化为高质量的数据资产。
课程还将引领你深入Spark SQL的世界,通过实际案例学习如何利用Spark高效计算PV、UV以及各类衍生指标,提升数据分析效率。此外,你还将学习Flume的安装与配置,实现Web日志的实时采集和ETL入仓,确保数据传输的稳定与高效。
为了贴近企业实际运作,本项目还包括定时任务的设置和自动化数据管道构建,教你如何编写Shell脚本并利用crontab定时调度Spark作业,让数据处理过程实现自动化与智能化。最后,通过可视化展示模块,你将学会用FineBI等工具将数据分析结果直观呈现
总之,这是一门集大数据基础、系统搭建、数据处理与智能分析于一体的全链路实战课程。无论你是初入大数据领域的新手,还是希望提升数据处理能力的开发者,都将在这里收获满满,掌握最前沿的大数据技术。
课程计划:
| 天数 | 主题 | 主要内容 |
|---|---|---|
| Day 1 | 大数据基础+项目分组 (ZK补充) | 大数据概念、数仓建模、组件介绍、分组;简单介绍项目。 |
| Day 2 | Hadoop初认识+ HA环境搭建 | 初认识Hadoop,了解HDFS 基本操作,YARN 资源调度,数据存储测试等,并且完成Hadoop高可用的环境搭建。 |
| Day 3 | Hive 数据仓库 | Hive SQL 基础、表设计、加载数据,搭建Hive环境并融入Hadoop实现高可用 |
| Day 4 | Spark SQL 基础 | 讲解Spark基础,DataFrame & SQL 查询,Hive 集成和环境的搭建 |
| Day 5 | Flume 数据采集及ETL入仓 | 安装Flume高可用,学习基础的Flume知识并且使用Flume 采集 Web 日志,存入 HDFS;数据格式解析,数据传输优化 |
| Day 6 | 数据入仓 & 指标计算 | 解析 PV、UV 计算逻辑,Hive 数据清洗、分层存储(ODS → DWD) |
| Day 7 | Spark 计算 & 指标优化 | 使用 Spark SQL 计算 PV、UV 及衍生指标(如跳出率、人均访问时长等) |
| Day 8 | 定时任务 & 数据管道 | 编写 Shell 脚本,使用 crontab 实现定时任务,调度 Spark SQL |
| Day 9 | 可视化 & 数据分析 | 搭建一个简单的项目使用 FineBI 进行数据展示,分析趋势。 |
| Day 10 | 项目答辩 | 小组演示分析结果,可以后台联系程序员小羊点评 |
今日学习重点:
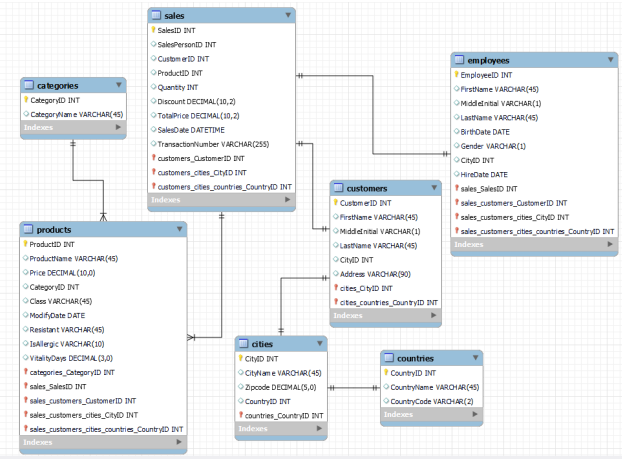
《Grocery Sales Dataset》参考课件 · 教师版
本参考课件基于《Grocery Sales Dataset》构建,面向大数据分析教学场景,旨在帮助学生全面理解电商数据的组织结构与分析流程,掌握多表数据整合与可视化建模的实战能力。通过使用 FineBI 完成全链路的数据探索、清洗、分析与报表呈现,本课件将提供完整的技术实现方案和分析逻辑,以支持教师在教学过程中提供有效示范。
课程目标:
-
建立对多维数据模型的整体认知。
-
掌握 Hive 数据建模及入仓过程。
-
理解指标设计思路与业务洞察方向。
-
掌握 FineBI 报表设计与数据可视化实践。
-
完成业务视角下的销售洞察分析报告。
涉及技术与工具:
| 类别 | 工具/语言 |
|---|---|
| 数据仓库 | Hive |
| 数据处理 | HiveQL / Spark SQL(可选扩展) |
| 数据可视化 | FineBI |
| 数据源格式 | CSV(7张表,509MB) |
数据集分析
在《Grocery Sales Dataset》中,一共有7张表。每张表代表了电商系统中的一个核心实体,我们可以将它们类比为现实中的业务环节,例如"卖出的商品""谁买的""谁卖的""在哪买的"这些信息,都是以表的形式存在。
categories.csv - 商品类别表
这张表是最简单的维度表之一,主要是用来分类商品的。例如"饮料类"、"乳制品"、"新鲜蔬果"这些都属于商品类别。
-
CategoryID是这个表的主键,是每一个类别的唯一编号。 -
CategoryName是类别的名称。
每个商品都会关联到一个类别,便于我们在做"类目销售分析"时聚合数据。
cities.csv - 城市信息表
这张表保存了所有城市的地理信息,它主要用于描述"客户"和"员工"的所在城市。我们在做区域销售分析、地理热力图时,会频繁用到它。
-
CityID是城市的唯一标识(主键)。 -
CityName是城市的名字,比如 Tokyo、Shanghai 等。 -
Zipcode这里虽然字段名为 Zipcode,但其实代表的是城市人口(或可能是编号),可以作为城市规模参考。 -
CountryID是外键,关联到countries.csv,表示这个城市属于哪个国家。
countries.csv - 国家信息表
这张表描述了国家的基本信息,是"城市"的上级行政单位,用于国家级别的销售分析。
-
CountryID是国家的唯一标识符。 -
CountryName是国家全称,例如"China"、"Japan"。 -
CountryCode是国家的两个字母代码,比如"CN"、"JP",通常用于展示或地图可视化。
customers.csv - 客户信息表
客户是电商平台最重要的组成部分之一,这张表用于存储用户的基本身份信息。
-
CustomerID是客户编号,是这张表的主键。 -
FirstName/MiddleInitial/LastName分别是客户的姓名部分,注意中间名不是必须的。 -
CityID是外键,关联到城市表,表示这个客户所在的城市。 -
Address是客户的居住地址,用于展示或投放策略分析。
employees.csv - 员工信息表
每一笔销售都会由某个销售人员完成,这张表记录了销售人员的基本信息。
-
EmployeeID是员工编号(主键)。 -
FirstName/MiddleInitial/LastName是员工姓名。 -
BirthDate是员工的出生日期。 -
Gender是性别字段。 -
CityID是员工所在城市的外键。 -
HireDate是员工的入职时间,可以分析销售经验与销售表现之间的关系。
products.csv - 商品信息表
这是非常关键的一张表,记录了所有销售商品的详细资料。
-
ProductID是每种商品的唯一编号(主键)。 -
ProductName是商品名称。 -
Price是每单位商品的单价。 -
CategoryID是外键,对应商品所属的类别。 -
Class描述商品的分类标准,可能是"日用"、"有机"、"冷藏"等。 -
ModifyDate是商品最后一次修改时间,可以用于更新追踪。 -
Resistant是产品的电阻类别,可能是专属行业属性。 -
IsAllergic是是否为过敏原(布尔值或标签),可用于标签分析。 -
VitalityDays是商品的保质天数或活性周期,对库存管理很重要。
sales.csv - 销售交易记录表(事实表)
这张表是最核心的"事实表",记录了所有销售事件,每一条数据都是一笔交易。
-
SalesID是销售记录的唯一编号(主键)。 -
SalesPersonID是员工编号(外键),表明是谁卖的。 -
CustomerID是客户编号(外键),说明是谁买的。 -
ProductID是商品编号(外键),说明卖的是什么。 -
Quantity是销售的商品数量。 -
Discount是本次销售的折扣金额。 -
TotalPrice是折扣后的实际支付金额。 -
SalesDate是销售发生的时间(日期+时间)。 -
TransactionNumber是交易编号(可能用于对账或溯源)。
为帮助理解各表之间的关联关系,我们补充说明以下主外键连接情况:
-
销售表
sales.csv是事实表,其他表为维度表。 -
sales.csv.SalesPersonID→employees.csv.EmployeeID -
sales.csv.CustomerID→customers.csv.CustomerID -
sales.csv.ProductID→products.csv.ProductID -
products.csv.CategoryID→categories.csv.CategoryID -
customers.csv.CityID→cities.csv.CityID -
employees.csv.CityID→cities.csv.CityID -
cities.csv.CountryID→countries.csv.CountryID
指标和场景建模
我们已经对《Grocery Sales Dataset》的整体结构和各个数据表的字段含义有了初步了解,也建立了每张表之间的关联视图。现在,是时候进入到项目中最关键的部分------业务指标设计与计算。
在现实的商业分析中,我们并不是为了"看数据而看数据",而是通过数据回答问题,通过指标揭示规律,从而支撑业务判断和决策制定。换句话说,指标就是从数据通往价值的桥梁。
那么我们该如何从这份看似杂乱的数据中,理清头绪、抽象业务行为、拆解出可计算的指标呢?答案就是:划分指标域。
根据实际商超和电商企业在经营过程中的关注点,我们将整个分析任务拆解为以下五大业务域:
-
销售域(Sales Domain)
-
产品域(Product Domain)
-
客户域(Customer Domain)
-
员工绩效域(Employee Performance Domain)
-
地理域(Geographic Domain)
每个业务域代表了不同的关注角度:有的看整体销售规模,有的看具体商品表现,有的看客户行为习惯,也有的聚焦员工效能或区域表现。接下来我们逐个展开介绍。
销售域(Sales Domain)
📌 关注点:我们卖了多少?卖得怎么样?走势如何?这个域是整个项目的核心,所有交易都汇聚于此。关键指标如下:
| 指标名称 | 解释 | 数学含义 |
|---|---|---|
| 销售总额(Total Sales) | 一段时间内的所有销售金额之和 | SUM(TotalPrice) |
| 销售单量(Sales Count) | 总交易笔数 | COUNT(SalesID) |
| 销售均价(Average Sale) | 每单平均销售额 | SUM(TotalPrice) / COUNT(SalesID) |
| 折扣率(Discount Rate) | 所有折扣占总销售的比例 | SUM(Discount) / (SUM(Discount) + SUM(TotalPrice)) |
| 月度销售增长率 | 销售额的时间趋势 | (本月销售额 - 上月销售额) / 上月销售额 |
这些指标是每一个销售报告的核心内容,无论是内部经营会,还是对外报告,都绕不开这些数据。
产品域(Product Domain)
📌 关注点:哪些产品卖得最好?什么类目是热门?商品是商场的核心商品资产,本域关注的是"什么卖得好"、"卖得多"。代表指标有:
| 指标名称 | 解释 |
|---|---|
| 商品销量 | 各商品的售出数量(SUM(Quantity)) |
| 商品销售额 | 各商品的销售总金额(SUM(TotalPrice)) |
| 类别销售占比 | 每个商品类别占总销售额的比例 |
| 商品动销率 | 有销量的商品种类数 / 总商品种类数 |
这些数据将帮助我们识别热销商品、优化库存结构、调整上架策略。
客户域(Customer Domain)
📌 关注点:谁在买?买得多吗?会回头吗?
客户是收入的源头。本域的分析将帮助我们了解客户行为,划分高价值客户与一次性买家。
| 指标名称 | 解释 |
|---|---|
| 客户总数 | 不重复的客户数量 |
| 回购率 | 多次购买客户占比(一次性 vs 回头客) |
| 平均订单价值(AOV) | 单次交易金额平均值 |
| 客户生命周期价值(CLV) | 每个客户的总贡献 |
| 客户活跃度/频率 | 平均客户下单次数 |
通过这些指标,我们能评估用户粘性、预测未来购买力,是精准营销的重要依据。
员工绩效域(Employee Performance Domain)
📌 关注点:谁是销售冠军?谁需要提升?
销售人员的能力直接影响业绩表现。我们通过以下指标来进行绩效评估:
| 指标名称 | 解释 |
|---|---|
| 员工销售额 | 每个员工完成的销售金额总和 |
| 成交单量 | 员工完成的订单数 |
| 员工平均订单价值 | 员工每单平均带来的销售额 |
| 服务客户数 | 员工服务的客户数量 |
可以作为绩效考核依据,也可以识别培训与激励对象。
地理域(Geographic Domain)
📌 关注点:哪些城市/国家销售好?有地域差异吗?
地理信息帮助我们了解市场分布和区域潜力,常见指标如下:
| 指标名称 | 解释 |
|---|---|
| 城市销售额 | 每个城市的销售金额 |
| 国家销售额 | 每个国家的销售金额 |
| 区域AOV | 区域平均订单金额 |
| 城市订单数量 | 城市下单总量 |
结合地图图层展示后,可用于制定区域投放、物流布局等策略。
通过以上五大指标域的拆解,我们不仅将庞大的数据拆成了若干清晰的分析方向,也为后续的数据建模与可视化做好了铺垫。下一步,我们将从这些指标出发,在 Hive 中进行数据计算,并在 FineBI 中设计相应的图表与仪表盘。
记住:每一个指标的背后,都是一个真实的业务问题。
数仓建模分析
在我们构建一个用于分析的销售数据平台时,每一张表的数据不是一股脑儿都往一个地方放,而是要根据它的变化规律 和业务特性,分别处理。
不同的数据,有的变化快,有的基本不变;有的每天都要更新,有的几年都不需要管。我们做的,是为后续分析做好结构安排。
总体设计思路:看"变不变"?
我们可以把所有数据分成三类处理方式:
-
基本不会变的,直接做成公共维度表使用(DIM)。
-
有变动可能,但不是很频繁的,可以设计成拉链表(记录历史版本)DIM+ODS。
-
每天都可能变化的数据,先按原样采集保存ODS。
例如现在我们回头看,你觉得国家和城市会变化吗(国家 countries、城市 cities)?可能花几十年几百年的时间都不会出现一个新的国家,突然出现一个新的城市,在这种情况下我们可以就可以把他当成一个不会变化的维度表,直接采集就放在DIM中,并且采用全量采集的方案放置在DIM层中,使用Sinppy压缩;直接做成公共维度表使用。
categories 商品分类的变化频率不高,基本上有关杂货的商品都是按照对应的类别有编号的,在通常情况下可以认定为是一个静态的公共维度表,但是有些公司认为,类别会根据时间进行调整和变化,可能会是一个新的变化维度把他做成拉链表。我们这边为了方便采用:直接采集就放在DIM中,并且采用全量采集的方案放置在DIM层中,使用Sinppy压缩;直接做成公共维度表使用。
products 产品变化非常明显:价格会变,可能换包装、换分类,甚至下架再上架。在这种情况下我们就要使用,先全量采集,再存储在DIM绘制成拉链表,随后变为增量采集并且走拉链匹配的代码,让商品的变化随着时间缓慢变化体现出历史变化趋势;方案:ODS+DIM(gzip+Sinppy)DIM做拉链。
同样的,下面客户(customers),员工信息(employees)都会出现类似于,客户绑架,换名字,注册新用户等等情况,员工入职、离职、调岗也会影响销售记录的归属,所以也是要做拉链表方便体现出历史变化,方案和上面产品一致:ODS+DIM(gzip+Sinppy)DIM做拉链。
销售记录 sales这是核心交易数据,一经生成不会更改,是事实记录。直接采集保存,先全量采集后面再增量采集,不断分析和抽取补充维度,最后参与指标计算。(ods+gzip,DWD,DWS Sinppy, ADS 不压缩)
| 表名 | 存放位置 | 是否做拉链表 | 用途说明 |
|---|---|---|---|
countries |
公共维度 | ❌ | 国家图表、分析 |
cities |
公共维度 | ❌ | 城市分布、地图 |
categories |
公共维度 | ❌(建议✅) | 类目趋势分析 |
products |
分层存储 | ✅ | 商品分析、历史比对 |
customers |
分层存储 | ✅ | 客户画像、地址变更 |
employees |
分层存储 | ✅ | 员工业绩、在岗分析 |
sales |
明细记录层 | ❌ | 所有分析的基础 |
📌 注:图中红色为原始数据需保存,黄色为维度但需记录变化,绿色为完全静态维度。
数仓采集策略
在建设一个用于分析和决策的数据仓库时,第一步要做的就是"把数据采集进来"。这听起来好像很简单,但其实采集策略的设计决定了后续数据质量、可维护性以及分析的效率。
打个比方,我们在做一顿饭之前,先得决定从哪里买菜、什么时候买、怎么保存。数据采集就像买菜,买错了、保存方式不对,后面的流程都会出问题。
所以,数仓采集不是随便"导入"就行,而是要讲策略。
为了更清晰地管理这些不同类型的数据,我们通常会按照以下方式来设计采集流程:
对于事实类数据,例如销售记录,我们会设计成每天采一批(比如昨天的数据),每条记录一旦生成就不会更改。这类数据采完之后,我们通常会根据时间进行分区(比如按月份),便于后续查询时快速定位数据范围。同时,如果数据量大,还可以按某些字段做分桶,比如每月分成三个桶,进一步提高读取效率。
这部分数据通常会先落在最底层的原始数据区(我们叫它 ODS),采用高压缩比的 gzip 压缩方式,既节省存储又保证数据可追溯。
而对于维度类数据,就要分情况处理了。
像"国家""城市""商品分类"这种数据,几乎不变,我们就一次性导入到维度层(DIM),保存为静态维度,供所有分析使用。这类表通常用 snappy 压缩,既节省空间又方便读取,格式使用 ORC 是主流方案。
至于"商品信息""客户资料""员工档案"这些缓慢变化的表,我们通常也是先采集到 ODS,再通过处理逻辑(如拉链合并、字段比对)形成维度历史记录表。这样一来,即使某个客户搬了家,我们也能知道他在某年某月住在哪里,便于做历史回溯分析。
假设我们现在运营一个杂货电商平台,每天都有几千条销售记录,同时还在不断上架新商品、接收新用户注册。
在这个平台中:
-
"销售记录"每天都更新,属于事实表,需要每天采集,按月分区,按客户 ID 分桶;
-
"商品信息"可能一周改几次,比如调价、换分类,这时我们每天采一次,把变化记录下来做成拉链;
-
"客户信息"类似,虽然用户不常改资料,但也可能会改名、换地址,我们也要记录;
-
"商品分类""城市""国家"这些基本不动,就一次性放到公共维度中,供后续分析直接引用。
这样一来,我们的数据结构就非常清晰:
-
ODS 层保存原始版本,主要用
gzip压缩; -
DIM 层保存维度信息,有些是静态的,有些是拉链记录;
-
所有数据都统一使用 ORC 格式,压缩方式按访问频率选择
snappy或gzip,确保查询效率和存储空间的平衡。
数据采集方案
Linux 文件的存放位置:/data/yjx/flume/source/ dim|fact
HDFS文件采集存放位置:hdfs://hdfs-yjx/yjxshop/ods |dim|dwd|dws|ads
准备任务:ZK,Hadoop,Hive,Spark都启动正常运行。
- 下载数据source.zip,在Windows中解压,上传文件在Linux中先把文件按照下面的层级创建文件夹放好,上传到指定位置,这是为了采集区分放到dim或ods,做分段采集。存储如下所示
Properties
mkdir -p /data/yjx/flume/source/dim
mkdir -p /data/yjx/flume/source/fact
/data/yjx/flume/source/dim/
├── cities/ → cities.csv
├── countries/ → countries.csv
├── categories/ → categories.csv
├── products/ → products.csv
├── employees/ → employees.csv
└── customers/ → customers.csv
/data/yjx/flume/source/fact/
└── sales/ → sales.csv- 打开Datagrip先创建一个标准的数据存储仓库,ods,dwd,dws,ads,dim都要有,依次运行下面的代码。
SQL
-- 打开hive连接控制台
create database ods;
create database dwd;
create database dws;
create database dim;
create database ads;维度数据采集
我们会把 维度数据和事实数据两个类型的数据分开来采集,分成两个不同的任务,接下来我要拉取
- 在 FLUME_HOME/jobs/ 目录下创建一个名为 flume-dim.conf 的置文件,这个配置文件主要是为了采集有关拉链的那三个表和三个静态的表。
shell
mkdir -p $FLUME_HOME/jobs/
cd $FLUME_HOME/jobs/
vim flume-dim.conf
-------------------------文件内容------------------------
# ====================== Source 声明 ======================
agent.sources = s_cities s_countries s_categories s_products s_employees s_customers
agent.channels = c_cities c_countries c_categories c_products c_employees c_customers
agent.sinks = sink_cities sink_countries sink_categories sink_products sink_employees sink_customers
# ====================== Source 配置 ======================
agent.sources.s_cities.type = spooldir
agent.sources.s_cities.spoolDir = /data/yjx/flume/source/dim/cities
agent.sources.s_cities.fileHeader = false
agent.sources.s_cities.channels = c_cities
agent.sources.s_countries.type = spooldir
agent.sources.s_countries.spoolDir = /data/yjx/flume/source/dim/countries
agent.sources.s_countries.fileHeader = false
agent.sources.s_countries.channels = c_countries
agent.sources.s_categories.type = spooldir
agent.sources.s_categories.spoolDir = /data/yjx/flume/source/dim/categories
agent.sources.s_categories.fileHeader = false
agent.sources.s_categories.channels = c_categories
agent.sources.s_products.type = spooldir
agent.sources.s_products.spoolDir = /data/yjx/flume/source/dim/products
agent.sources.s_products.fileHeader = false
agent.sources.s_products.channels = c_products
agent.sources.s_employees.type = spooldir
agent.sources.s_employees.spoolDir = /data/yjx/flume/source/dim/employees
agent.sources.s_employees.fileHeader = false
agent.sources.s_employees.channels = c_employees
agent.sources.s_customers.type = spooldir
agent.sources.s_customers.spoolDir = /data/yjx/flume/source/dim/customers
agent.sources.s_customers.fileHeader = false
agent.sources.s_customers.channels = c_customers
# ====================== Channel 配置 ======================
agent.channels.c_cities.type = file
agent.channels.c_cities.capacity = 100000
agent.channels.c_cities.transactionCapacity = 1000
agent.channels.c_cities.checkpointDir = /data/yjx/flume/checkpoint/c_cities
agent.channels.c_cities.dataDirs = /data/yjx/flume/data/c_cities
agent.channels.c_countries.type = file
agent.channels.c_countries.capacity = 100000
agent.channels.c_countries.transactionCapacity = 1000
agent.channels.c_countries.checkpointDir = /data/yjx/flume/checkpoint/c_countries
agent.channels.c_countries.dataDirs = /data/yjx/flume/data/c_countries
agent.channels.c_categories.type = file
agent.channels.c_categories.capacity = 100000
agent.channels.c_categories.transactionCapacity = 1000
agent.channels.c_categories.checkpointDir = /data/yjx/flume/checkpoint/c_categories
agent.channels.c_categories.dataDirs = /data/yjx/flume/data/c_categories
agent.channels.c_products.type = file
agent.channels.c_products.capacity = 100000
agent.channels.c_products.transactionCapacity = 1000
agent.channels.c_products.checkpointDir = /data/yjx/flume/checkpoint/c_products
agent.channels.c_products.dataDirs = /data/yjx/flume/data/c_products
agent.channels.c_employees.type = file
agent.channels.c_employees.capacity = 100000
agent.channels.c_employees.transactionCapacity = 1000
agent.channels.c_employees.checkpointDir = /data/yjx/flume/checkpoint/c_employees
agent.channels.c_employees.dataDirs = /data/yjx/flume/data/c_employees
agent.channels.c_customers.type = file
agent.channels.c_customers.capacity = 100000
agent.channels.c_customers.transactionCapacity = 1000
agent.channels.c_customers.checkpointDir = /data/yjx/flume/checkpoint/c_customers
agent.channels.c_customers.dataDirs = /data/yjx/flume/data/c_customers
# ====================== Sink 配置 ======================
# ----- DIM 静态维度(Snappy) -----
agent.sinks.sink_cities.type = hdfs
agent.sinks.sink_cities.channel = c_cities
agent.sinks.sink_cities.hdfs.path = hdfs://hdfs-yjx/yjxshop/dim/cities
agent.sinks.sink_cities.hdfs.filePrefix = cities
agent.sinks.sink_cities.hdfs.fileType = CompressedStream
agent.sinks.sink_customers.hdfs.codeC = gzip
agent.sinks.sink_cities.hdfs.writeFormat = Text
agent.sinks.sink_cities.hdfs.useLocalTimeStamp = true
agent.sinks.sink_cities.hdfs.rollInterval = 0
agent.sinks.sink_cities.hdfs.rollSize = 134217728
agent.sinks.sink_cities.hdfs.rollCount = 0
agent.sinks.sink_cities.hdfs.codeC = snappy
agent.sinks.sink_countries.type = hdfs
agent.sinks.sink_countries.channel = c_countries
agent.sinks.sink_countries.hdfs.path = hdfs://hdfs-yjx/yjxshop/dim/countries
agent.sinks.sink_countries.hdfs.filePrefix = countries
agent.sinks.sink_countries.hdfs.fileType = CompressedStream
agent.sinks.sink_customers.hdfs.codeC = gzip
agent.sinks.sink_countries.hdfs.writeFormat = Text
agent.sinks.sink_countries.hdfs.useLocalTimeStamp = true
agent.sinks.sink_countries.hdfs.rollInterval = 0
agent.sinks.sink_countries.hdfs.rollSize = 134217728
agent.sinks.sink_countries.hdfs.rollCount = 0
agent.sinks.sink_countries.hdfs.codeC = snappy
agent.sinks.sink_categories.type = hdfs
agent.sinks.sink_categories.channel = c_categories
agent.sinks.sink_categories.hdfs.path = hdfs://hdfs-yjx/yjxshop/dim/categories
agent.sinks.sink_categories.hdfs.filePrefix = categories
agent.sinks.sink_categories.hdfs.fileType = CompressedStream
agent.sinks.sink_customers.hdfs.codeC = gzip
agent.sinks.sink_categories.hdfs.writeFormat = Text
agent.sinks.sink_categories.hdfs.useLocalTimeStamp = true
agent.sinks.sink_categories.hdfs.rollInterval = 0
agent.sinks.sink_categories.hdfs.rollSize = 134217728
agent.sinks.sink_categories.hdfs.rollCount = 0
agent.sinks.sink_categories.hdfs.codeC = snappy
# ----- ODS 拉链维度(Gzip) -----
agent.sinks.sink_products.type = hdfs
agent.sinks.sink_products.channel = c_products
agent.sinks.sink_products.hdfs.path = hdfs://hdfs-yjx/yjxshop/ods/products
agent.sinks.sink_products.hdfs.filePrefix = products
agent.sinks.sink_products.hdfs.fileType = CompressedStream
agent.sinks.sink_customers.hdfs.codeC = gzip
agent.sinks.sink_products.hdfs.writeFormat = Text
agent.sinks.sink_products.hdfs.useLocalTimeStamp = true
agent.sinks.sink_products.hdfs.rollInterval = 0
agent.sinks.sink_products.hdfs.rollSize = 134217728
agent.sinks.sink_products.hdfs.rollCount = 0
agent.sinks.sink_products.hdfs.codeC = gzip
agent.sinks.sink_employees.type = hdfs
agent.sinks.sink_employees.channel = c_employees
agent.sinks.sink_employees.hdfs.path = hdfs://hdfs-yjx/yjxshop/ods/employees
agent.sinks.sink_employees.hdfs.filePrefix = employees
agent.sinks.sink_employees.hdfs.fileType = CompressedStream
agent.sinks.sink_customers.hdfs.codeC = gzip
agent.sinks.sink_employees.hdfs.writeFormat = Text
agent.sinks.sink_employees.hdfs.useLocalTimeStamp = true
agent.sinks.sink_employees.hdfs.rollInterval = 0
agent.sinks.sink_employees.hdfs.rollSize = 134217728
agent.sinks.sink_employees.hdfs.rollCount = 0
agent.sinks.sink_employees.hdfs.codeC = gzip
agent.sinks.sink_customers.type = hdfs
agent.sinks.sink_customers.channel = c_customers
agent.sinks.sink_customers.hdfs.path = hdfs://hdfs-yjx/yjxshop/ods/customers
agent.sinks.sink_customers.hdfs.filePrefix = customers
agent.sinks.sink_customers.hdfs.fileType = CompressedStream
agent.sinks.sink_customers.hdfs.codeC = gzip
agent.sinks.sink_customers.hdfs.writeFormat = Text
agent.sinks.sink_customers.hdfs.useLocalTimeStamp = true
agent.sinks.sink_customers.hdfs.rollInterval = 0
agent.sinks.sink_customers.hdfs.rollSize = 134217728
agent.sinks.sink_customers.hdfs.rollCount = 0
-------------------------文件结束------------------------- 运行任务
SQL
hdfs dfs -mkdir -p /yjxshop/{ods,dwd,dws,dim,ads}
hdfs dfs -chmod -R 755 /yjxshop
flume-ng agent --conf conf --conf-file $FLUME_HOME/jobs/flume-dim.conf --name agent -Dflume.root.logger=INFO,console- 在运行一段时间发现数据没有滚动后 按 Crtl+C 完成任务,任务时间大概 3-5 分钟
如果你运行失败了,需要删除一下缓存再重新启动,如果你的 source下的文件全部被标记为 completed则需要重新上传
rm -rf /data/yjx/flume/checkpoint/c_products
rm -rf /data/yjx/flume/data/c_products
事实数据采集
事实数据的采集会比较麻烦,因为数据比较多我们要根据月进行分区,否则会拉满后续计算和查询的速度,这边需要根据我们的实际需要创建一个自定义拦截器
- 创建一个Maven项目,Java版本选择JDK1.8。
- 配置 pom.xml 依赖 需要添加 flume-ng-core 和 flume-ng-api。案例如下:
XML
<dependencies>
<!-- Flume API -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-sdk</artifactId>
<version>1.11.0</version>
</dependency>
<!-- 如果需要 flume-ng-core 中的类 -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.11.0</version>
</dependency>
<!-- 日志依赖 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>- 创建拦截器类 在项目中创建包(例如:
com.yjxxt.flume.interceptor),在该包下创建类SalesDateInterceptor.java。此类要实现接口org.apache.flume.interceptor.Interceptor或者也可以继承AbstractInterceptor以简化代码。
- 修改代码内部逻辑,内容如下所示:
java
package com.yjxxt.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class SalesDateInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
String body = new String(event.getBody(), StandardCharsets.UTF_8);
try {
// 按逗号切分
String[] fields = body.split(",", -1);
if (fields.length >= 8) {
String salesDate = fields[7]; // 第8列
if (salesDate != null && salesDate.length() >= 7) {
String yearMonth = salesDate.substring(0, 7); // 取"yyyy-MM"
event.getHeaders().put("ym", yearMonth);
} else {
event.getHeaders().put("ym", "default");
}
} else {
event.getHeaders().put("ym", "default");
}
} catch (Exception e) {
event.getHeaders().put("ym", "default");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
List<Event> intercepted = new ArrayList<>(events.size());
for (Event event : events) {
Event interceptedEvent = intercept(event);
if (interceptedEvent != null) {
intercepted.add(interceptedEvent);
}
}
return intercepted;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new SalesDateInterceptor();
}
@Override
public void configure(Context context) {
}
}
}-
使用 Maven 命令将项目打包为 jar 文件
mvn clean package打包后的 jar 文件通常位于target/目录下,例如Custom-interceptor-1.0-SNAPSHOT.jar。 -
将打包好的 jar 文件复制到 Flume 安装目录的 lib 目录下,如果是 Flume 集群环境,确保所有 Flume Agent 节点的
$FLUME_HOME/lib/都包含此 jar 文件。
CustomInterceptor-1.0-SNAPSHOT.jar
- 编写flume任务文件 flume-fact.conf
Shell
cd $FLUME_HOME/jobs
vim flume-fact.conf
--------------文件开始-----------------
agent.sources = s_sales
agent.channels = c_sales
agent.sinks = sink_sales
# source
agent.sources.s_sales.type = spooldir
agent.sources.s_sales.spoolDir = /data/yjx/flume/source/fact/sales
agent.sources.s_sales.fileHeader = false
agent.sources.s_sales.interceptors = i1
agent.sources.s_sales.interceptors.i1.type = com.yjxxt.flume.interceptor.SalesDateInterceptor$Builder
agent.sources.s_sales.channels = c_sales
# channel
agent.channels.c_sales.type = file
agent.channels.c_sales.capacity = 100000
agent.channels.c_sales.transactionCapacity = 10000
agent.channels.c_sales.checkpointDir = /data/yjx/flume/checkpoint/c_sales
agent.channels.c_sales.dataDirs = /data/yjx/flume/data/c_sales
# sink
agent.sinks.sink_sales.type = hdfs
agent.sinks.sink_sales.channel = c_sales
agent.sinks.sink_sales.hdfs.path = hdfs://hdfs-yjx/yjxshop/ods/sales/ym=%{ym}
agent.sinks.sink_sales.hdfs.filePrefix = sales
agent.sinks.sink_sales.hdfs.fileType = CompressedStream
agent.sinks.sink_sales.hdfs.codeC = gzip
agent.sinks.sink_sales.hdfs.writeFormat = Text
agent.sinks.sink_sales.hdfs.useLocalTimeStamp = true
agent.sinks.sink_sales.hdfs.rollInterval = 0
agent.sinks.sink_sales.hdfs.rollSize = 134217728
agent.sinks.sink_sales.hdfs.rollCount = 0
--------------文件结束------------------ 运行拉取任务,查看是否成功
Shell
flume-ng agent \
--conf conf \
--conf-file $FLUME_HOME/jobs/flume-fact.conf \
--name agent \
-Dflume.root.logger=INFO,console这个任务拉取时间比较长,大概需要半小时到1小时,有点耐心,怎么证明已经拉取完成了可以手动停止了呢?首先你的源文件必须有 以
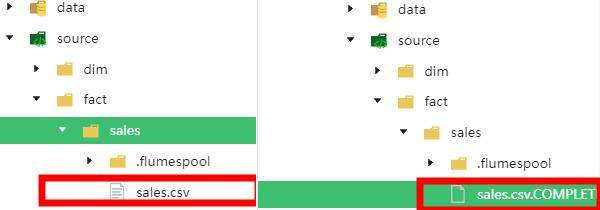
.COMPLETED的文件,说明已经拉取完成了;并且你的终端已经不输出日志了。你也可以看着网络一栏,如果网络传输速度和流量高于 正常情况说明还在进行传输。
拉取完成后我们会发现,数据中有一些脏数据,首先是除了正常日期以外还有 defult 说明这个日志是没有时间的,这样的数据大概有3MB,还有csv的行头没有去,有一条SalesDa数据后面要删除。
数据入库
下一步就是在 Hive 的 ods 库里建一张 sales 表,直接能读你现在拉取的 HDFS上ods/sales/ 里的原始数据。
如果你的目录出现了SalesDa 和 default 运行下面的命令删除他们
hdfs dfs -rm -r hdfs://hdfs-yjx/yjxshop/ods/sales/SalesDa
hdfs dfs -rm -r hdfs://hdfs-yjx/yjxshop/ods/sales/default
如果你查询的时候出现了:08S011 Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Permission denied: user=anonymous, access=EXECUTE, inode="/tmp/hadoop-yarn":root:supergroup:drwx------
错误,运行下面代码:
hdfs dfs -chmod 777 /tmp
hdfs dfs -chmod -R 777 /tmp/hadoop-yarn
注意,本数据集计算量过大,你需要调整虚拟机至少为 6 4 4 才可以启动,并且Spark应该提高内存
Shell
sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10015 \
--master yarn --deploy-mode client \
--queue default \
--driver-cores 2 --driver-memory 1G \
--num-executors 6 --executor-cores 2 --executor-memory 2Gods 数据入库
为避免Saprk没有权限计算 你需要 运行
hdfs dfs -chmod -R 777 /yjxshop放置权限问题报错
- 为 ods_sales 创建一个表,并管理上分区规则保证数据正常的能被查询。
SQL
-- 进入ODS数据库
USE ods;
-- 创建销售表
CREATE EXTERNAL TABLE IF NOT EXISTS ods_sales (
SalesID BIGINT,
SalesPersonID BIGINT,
CustomerID BIGINT,
ProductID BIGINT,
Quantity INT,
Discount DOUBLE,
TotalPrice DOUBLE,
SalesDate STRING,
TransactionNumber STRING
)
PARTITIONED BY (ym STRING) -- 按年月分区
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdfs-yjx/yjxshop/ods/sales/';
MSCK REPAIR TABLE ods_sales;
show tables;
select * from ods_sales limit 100;
select count(*) from ods_sales;
-- 预估数据量:669w - 700w- 为 ods_products创建表
SQL
CREATE EXTERNAL TABLE IF NOT EXISTS ods_products (
ProductID BIGINT,
ProductName STRING,
CategoryID BIGINT,
UnitPrice DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1")
LOCATION 'hdfs://hdfs-yjx/yjxshop/ods/products/';
select count(*) from ods_products;
select * from ods_products limit 100;
-- 产品数量预估 453- 为 ods_employees 创建一个表
SQL
CREATE EXTERNAL TABLE IF NOT EXISTS ods_employees (
EmployeeID BIGINT,
FirstName STRING,
LastName STRING,
BirthDate STRING,
Gender STRING,
HireDate STRING,
CityID BIGINT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1")
LOCATION 'hdfs://hdfs-yjx/yjxshop/ods/employees/';
select * from ods_employees limit 100;
select count(*) from ods_employees;
-- 员工数量 24- 为 ods_customers 建一个表
SQL
DROP TABLE IF EXISTS ods_customers;
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_customers (
CustomerID BIGINT,
FirstName STRING,
MiddleInitial STRING,
LastName STRING,
CityID BIGINT,
Address STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1")
LOCATION 'hdfs://hdfs-yjx/yjxshop/ods/customers/';dim 数据入库
dim里面有我们之前临时采集放在ods的例如 customers、employees、products 我们要拉出来做拉链表放在dim中,同时还有不变的,例如 cities,categories,countries
但是这里注意,我们之前没放在ods的数据没办法只能给dim再找另外的hdfs位置存储,这边我们换一个文件夹
- 为 dim_cities 创建一个表,并且倒数据到数据干净
SQL
use dim;
CREATE EXTERNAL TABLE IF NOT EXISTS dim_cities (
CityID BIGINT,
CityName STRING,
Zipcode STRING,
CountryID BIGINT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1")
LOCATION 'hdfs://hdfs-yjx/yjxshop/dim/cities/';
select * from dim_cities limit 100;
select count(*) from dim_cities;
-- 参考值 97- 为 dim_countries 创建一个表
SQL
CREATE EXTERNAL TABLE IF NOT EXISTS dim_countries (
CountryID BIGINT,
CountryName STRING,
CountryCode STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1")
LOCATION 'hdfs://hdfs-yjx/yjxshop/dim/countries/';
select * from dim_countries limit 100;
select count(*) from dim_countries;
-- 参考值 207- 为 dim_categories 创建一个表
SQL
CREATE EXTERNAL TABLE IF NOT EXISTS dim_categories (
CategoryID BIGINT,
CategoryName STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1")
LOCATION 'hdfs://hdfs-yjx/yjxshop/dim/categories/';
select * from dim_categories limit 100;
select count(*) from dim_categories;
-- 参考值 12| 表名 | 类型 | 预计数据量(行数) | 备注说明 |
|---|---|---|---|
ods_sales |
事实表(ODS) | 669万 - 700万 | 按年月(ym)分区管理 |
ods_products |
维度表(ODS) | 453 | 产品信息 |
ods_employees |
维度表(ODS) | 24 | 员工信息 |
ods_customers |
维度表(ODS) | 98760 | 客户信息 |
dim_cities |
维度表(DIM) | 97 | 城市列表 |
dim_countries |
维度表(DIM) | 207 | 国家列表 |
dim_categories |
维度表(DIM) | 12 | 商品类别列表 |
dim 拉链表入仓抽取
我们之前在ods中存储了几个表,包括 ods_customers,ods_employees,ods_products 我们要给他们在dim中创建拉链表并且插入进去。
下面的代码请在 hive 中运行
- dim_products_l 表 之前我们先创建一个hdfs目录确保数据可以以外部表的方式创建
hdfs dfs -mkdir /yjxshop/dim/products_l/
hdfs dfs -chmod 751 /yjxshop/dim/products_l/
SQL
USE dim;
DROP TABLE IF EXISTS dim_products_l;
-- 2. 重新用 ORC 正确创建
CREATE EXTERNAL TABLE IF NOT EXISTS dim_products_l (
ProductID BIGINT,
ProductName STRING,
CategoryID BIGINT,
UnitPrice DOUBLE,
start_dt STRING,
end_dt STRING
)
STORED AS ORC
LOCATION 'hdfs://hdfs-yjx/yjxshop/dim/products_l/'
TBLPROPERTIES ("orc.compress"="SNAPPY");
-- 3. 再执行插入
INSERT INTO TABLE dim_products_l
SELECT
ProductID,
ProductName,
CategoryID,
UnitPrice,
'2025-04-26' AS start_dt,
'9999-12-31' AS end_dt
FROM ods.ods_products
WHERE ProductID IS NOT NULL;
select * from dim_products_l limit 10;- dim_customers_l 我们还是先创建一个hdfs文件夹,保证后面的数据可以正确的进去。
hdfs dfs -mkdir /yjxshop/dim/customers_l/
hdfs dfs -chmod 751 /yjxshop/dim/customers_l/
SQL
USE dim;
DROP TABLE IF EXISTS dim_customers_l;
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_customers_l (
CustomerID BIGINT,
FirstName STRING,
Middleinitial STRING,
LastName STRING,
CityID BIGINT,
address STRING,
start_dt STRING,
end_dt STRING
)
STORED AS ORC
LOCATION 'hdfs://hdfs-yjx/yjxshop/dim/customers_l/'
TBLPROPERTIES ("orc.compress"="SNAPPY");
INSERT INTO TABLE dim.dim_customers_l
SELECT
CustomerID,
FirstName,
Middleinitial,
LastName,
CityID,
address,
'2025-05-02' AS start_dt,
'9999-12-31' AS end_dt
FROM ods.ods_customers
WHERE CustomerID IS NOT NULL;- dim_employees_l 我们还是先创建一个hdfs文件夹,保证后面的数据可以正确的进去。
hdfs dfs -mkdir /yjxshop/dim/employees_l/
hdfs dfs -chmod 751 /yjxshop/dim/employees_l/
SQL
USE dim;
DROP TABLE IF EXISTS dim_employees_l;
CREATE EXTERNAL TABLE IF NOT EXISTS dim_employees_l (
EmployeeID BIGINT,
FirstName STRING,
LastName STRING,
BirthDate STRING,
Gender STRING,
HireDate STRING,
CityID BIGINT,
start_dt STRING,
end_dt STRING
)
STORED AS ORC
LOCATION 'hdfs://hdfs-yjx/yjxshop/dim/employees_l/'
TBLPROPERTIES ("orc.compress"="SNAPPY");
INSERT INTO TABLE dim_employees_l
SELECT
EmployeeID,
FirstName,
LastName,
BirthDate,
Gender,
HireDate,
CityID,
'2025-04-26' AS start_dt,
'9999-12-31' AS end_dt
FROM ods.ods_employees
WHERE EmployeeID IS NOT NULL;数据清洗
这边我们看数据,其实基本上我们只需要关注事实表数据是否清洁即可,我们来分析一下里面的每一个字段,看看那些东西需要确定质量完备。
| 检查项 | 说明 | 必须 |
|---|---|---|
salesid 不为空 |
主键,不能为空 | 必须 |
salespersonid 不为空 |
销售人员ID,不能为空(否则记录是谁的订单都不知道)为空改为 -1 | 建议 |
customerid 不为空 |
客户ID,不能为空 为空改为 -1 | 建议 |
productid 不为空 |
产品ID,不能为空 为空改为 -1 | 建议 |
quantity 大于0 |
销售数量不能为负,也不能为0 否则为 -1 | 建议 |
discount 介于0~1之间 |
折扣比例必须合理,不能小于0或者大于1 | 建议 |
salesdate 有值且格式正常 |
必须有销售时间,没有剔除 | 必须 |
transactionnumber 不强制校验 |
交易编号,异常也不影响主业务 |
确定好清洗和过滤方案后,我们就开始把数据经过过滤SQL放置到dwd层。
为了在dwd层中创建一个新的外部表我们应该在hdfs中对应位置创建文件夹:
hdfs dfs -mkdir /yjxshop/dwd/sales/
hdfs dfs -chmod 751 /yjxshop/dwd/sales/
SQL
USE dwd;
CREATE EXTERNAL TABLE IF NOT EXISTS dwd_sales (
SalesID BIGINT,
SalesPersonID BIGINT,
CustomerID BIGINT,
ProductID BIGINT,
Quantity INT,
Discount DOUBLE,
TotalPrice DOUBLE,
SalesDate STRING,
TransactionNumber STRING
)
PARTITIONED BY (ym STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdfs-yjx/yjxshop/dwd/sales/';
set hive.exec.dynamic.partition.mode=nonstrict;
-- 开始插入
INSERT INTO TABLE dwd_sales
PARTITION (ym)
SELECT
SalesID,
IF(SalesPersonID IS NULL, -1, SalesPersonID),
IF(CustomerID IS NULL, -1, CustomerID),
IF(ProductID IS NULL, -1, ProductID),
CASE WHEN Quantity > 0 THEN Quantity ELSE -1 END,
Discount,
TotalPrice,
SalesDate,
TransactionNumber,
substr(SalesDate, 1, 7) AS ym
FROM ods.ods_sales
WHERE
SalesID IS NOT NULL
AND cast(SalesID as string) RLIKE '^[0-9]+$'
AND SalesDate IS NOT NULL
AND length(SalesDate) >= 7
AND Discount >= 0
AND Discount <= 1;DWS宽表补维
在运行这个代码之前先在HDFS中创建
hdfs://hdfs-yjx/yjxshop/dws/sales_wide/文件后再执行下面代码
SQL
USE dws;
CREATE EXTERNAL TABLE dws_sales_wide (
SalesID BIGINT,
SalesDate STRING,
ym STRING,
TotalPrice DOUBLE,
Quantity INT,
Discount DOUBLE,
CustomerID BIGINT,
CityName STRING,
CountryCode STRING,
CountryName STRING,
ProductID BIGINT,
ProductName STRING,
CategoryID BIGINT,
CategoryName STRING,
EmployeeID BIGINT,
EmployeeName STRING
)
STORED AS ORC
TBLPROPERTIES ('orc.compress' = 'SNAPPY')
LOCATION 'hdfs://hdfs-yjx/yjxshop/dws/sales_wide/';
SQL
INSERT OVERWRITE TABLE dws.dws_sales_wide
SELECT
s.SalesID,
s.SalesDate,
substr(s.SalesDate, 1, 7) AS ym,
s.TotalPrice,
s.Quantity,
s.Discount,
c.CustomerID,
ci.CityName,
ci.CountryID,
co.CountryName,
p.ProductID,
p.ProductName,
p.CategoryID,
cat.CategoryName,
e.EmployeeID,
concat_ws(' ', e.FirstName, e.LastName) AS EmployeeName
FROM dwd.dwd_sales s
LEFT JOIN dim.dim_customers_l c ON s.CustomerID = c.CustomerID
LEFT JOIN dim.dim_cities ci ON c.CityID = ci.CityID
LEFT JOIN dim.dim_countries co ON ci.CountryID = co.CountryID
LEFT JOIN dim.dim_products_l p ON s.ProductID = p.ProductID
LEFT JOIN dim.dim_categories cat ON p.CategoryID = cat.CategoryID
LEFT JOIN dim.dim_employees_l e ON s.SalesPersonID = e.EmployeeID
WHERE s.SalesID IS NOT NULL;
select * from dws.dws_sales_wide limit 100;在查询的时候发现国家并没有按照估计的那样,所有的国家都指向了一个,这样我们就缺少了一个地域国家的维度,那么我们可以这样做。创建一个临时表,针对国家进行 1-206 的随机生成并且重新加入有关国家代码和名称的参数。
SQL
-- 创建新的 DWS 表(带随机国家)
CREATE TABLE dws.dws_sales_wide2 AS
with a1 as (
select
SalesID,
SalesDate,
ym,
TotalPrice,
Quantity,
Discount,
CustomerID,
CityName,
floor(rand() * 206 + 1) AS CountryCodeid,
EmployeeID,
EmployeeName,
ProductID,
ProductName,
CategoryID,
CategoryName
from dws.dws_sales_wide
) select
SalesID,
SalesDate,
ym,
TotalPrice,
Quantity,
Discount,
CustomerID,
CityName,
EmployeeID,
EmployeeName,
d1.CountryID,
d1.CountryName,
d1.CountryCode,
ProductID,
ProductName,
CategoryID,
CategoryName
from a1 join dim.dim_countries d1 on a1.CountryCodeid = d1.countryid;
select * from dws.dws_sales_wide2 limit 10;ADS指标计算
结尾:
本课程是一门以电商流量数据分析为核心的大数据实战课程,旨在帮助你全面掌握大数据技术栈的核心组件及其在实际项目中的应用。从零开始,你将深入了解并实践Hadoop、Hive、Spark和Flume等主流技术,为企业级电商流量项目构建一个高可用、稳定高效的数据处理系统。
在课程中,你将学习如何搭建并优化Hadoop高可用环境,熟悉HDFS分布式存储和YARN资源调度机制,为大规模数据存储与计算奠定坚实基础。随后,通过Hive数据仓库的构建与数仓建模,你将掌握如何将原始日志数据进行分层处理,实现数据清洗与结构化存储,从而为后续数据分析做好准备。
借助Spark SQL的强大功能,你将通过实战案例学会快速计算和分析关键指标,如页面浏览量(PV)、独立访客数(UV),以及通过数据比较获得的环比、等比等衍生指标。这些指标将帮助企业准确洞察用户行为和流量趋势,为优化营销策略提供科学依据。
同时,本课程还包含Flume数据采集与ETL入仓的实战模块,教你如何采集实时Web日志数据,并利用ETL流程将数据自动导入HDFS和Hive,确保数据传输和处理的高效稳定。
总体来说,这门课程面向希望提升大数据应用能力的技术人员和企业项目团队,紧密围绕公司电商流量项目的实际需求展开。通过系统的理论讲解与动手实践,你不仅能够构建从数据采集、存储、处理到可视化展示的完整数据管道,还能利用PV、UV、环比、等比等关键指标,全面掌握电商流量数据分析的核心技能。
csharp
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文