本文主要介绍如何在虚拟机 Ubuntu 上安装 Hbase ,具体操作如下所示。
Hbase 下载网址:https://hbase.apache.org/
Hbase 中文学习文档:https://abloz.com/hbase/book.html
Hbase 英文学习文档:https://hbase.apache.org/book.html
安装HBase
1.前置要求:
- HBase 需要 Java 才能运行,从官网上(网址:https://hbase.apache.org/book.html#java )获悉,最新的 HBase 2.6.0 支持在 JDK-8、JDK-11、JDK-17上运行。虚拟机 ubuntuvm1 系统默认 JDK 是 OpenJDK-11,满足此要求。
- HBase 需要运行在 Hadoop 上。 HBase 2.6.0 支持在 Hadoop-3.3.5 以上运行。虚拟机 ubuntuvm1 系统安装的是 Hadoop-3.4.0,满足此要求。
- 操作系统的文件和进程数量限制。 HBase 是一个数据库,它需要同时打开大量的文件。许多 Linux 操作系统限制一个用户可以打开的文件数量为 1024。例如,虚拟机 ubuntuvm1 查看示例:
查看单个用户可以打开的文件数量。
bash
ulimit -n
修改操作系统的设置,编辑系统配置文件:
bash
sudo vi /etc/security/limits.conf在尾部添加下面的设置:
shell
hadoop - nofile 32768
hadoop - nproc 32000
在上面的示例中,第一行为用户名为 hadoop 的操作系统用户将打开文件的数量(nofile)的软限制和硬限制设置为 32768。第二行将同一用户的进程数(nproc)的限制设置为 32000。重启操作系统(reboot)生效。 再次以 hadoop 用户登录检查:
bash
ulimit -n
ulimit -u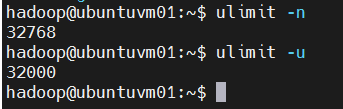
确认上述修改已经生效。
2.独立HBase-软件安装**:**
a.到 HBase 官网下载最新的发行版。 下载地址: https://hbase.apache.org/downloads.html 这里得到文件: hbase-2.6.0-bin.tar.gz, 解压缩。目标安装文件夹: /opt/app
bash
# 进入目标文件夹。
cd /opt/app
# 解压缩。
tar zxf /media/sf_vmshare/hbase-2.6.0-bin.tar.gz
# 进入文件夹,检查一下文件。
cd hbase-2.6.0
b. 设置环境变量。在当前用户 hadoop 的 ~/.profile 尾部,添加环境变量:
bash
sudo vi ~/.profile
shell
export HBASE_HOME=/opt/app/hbase-2.6.0 
退出当前的 SSH 连接并重新登录生效。
c.配置 HBase。 编辑配置文件 conf/hbase-env.sh:
bash
cd $HBASE_HOME
vi conf/hbase-env.sh在里面找到 JAVA_HOME 的设置,增加一行让它指向它支持的最新版 OpenJDK-11:
shell
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
再把这个注释去掉,结果如下:
shell
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
注意,上面这个设置要去掉注释,不然启动 HBase 会报错(引入Hadoop的类和HBase的有冲突)
修改完成后,保存并退出 vim 编辑器。
d. 以独立模式运行 HBase。 请注意,因 HBase 以独立模式(Standalone)运行,它将数据持续化到本地磁盘(不在 HDFS),因此,不需要先启动 Hadoop。 直接运行 HBase:
bash
cd $HBASE_HOME
bin/start-hbase.sh # 启动 HBase。
jps # 检查 Java 进程,可以看到 HMaster。
3.首次使用 HBase
a. 连接到 HBase。 以下面的命令,连接到 HBase:
bash
cd $HBASE_HOME
bin/hbase shellb. 屏幕输出示例如下:

当看到类似上述 hbase:001:0> 提示符,表示连接成功。
c. 查看帮助。 输入 help 并回车,可以查看基本的使用帮助信息。

d. 创建表。 使用 create 命令创建新表。必须指定2个参数:表名和 ColumnFamily 名称。
hbase
create 'test', 'cf'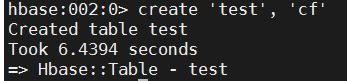
查看表。 使用 list 命令确认表存在:
hbase
list 'test'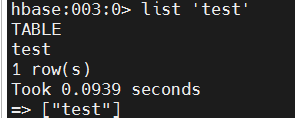
再使用 describe 命令查看详细信息,包括配置默认值。
hbase
describe 'test'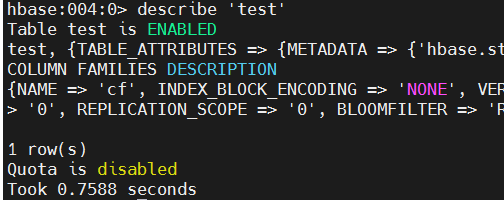
插入数据到表中。 要将数据插入到表中,使用 put 命令:
hbase
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'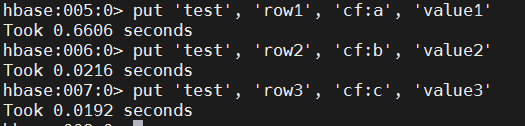
在这里,我们插入三个值,一次一个。第一个插入位于第 1 行的 cf:a 列,值为 value1。HBase 中的列由列系列前缀(在此示例中为 cf)组成,后跟冒号,然后是列限定符后缀(在本例中为 a)。
e. 查看表的全部数据。 从 HBase 获取数据的方法之一是扫描(scan)。使用 scan 命令扫描表中的数据。您可以限制扫描的数量,但现在因数据量小,已获取全部数据。
hbase
scan 'test'
f. 获取单行数据。 要获取单行数据,使用 get 命令:
hbase
get 'test', 'row1'
g. 禁用表。 如果要删除表或更改其设置,以及其他一些情况,则需要先使用 disable 命令禁用该表。您可以使用 enable 命令重新启用它。
hbase
disable 'test'
enable 'test'如果您测试了上述 enable 命令,请再次禁用该表:
hbase
disable 'test'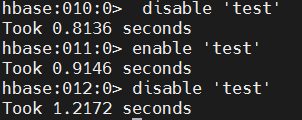
h. 删除表。 要删除表,请使用 drop 命令。
hbase
drop 'test'
i. 退出 HBase Shell。 要退出 HBase Shell 并断开与集群的连接,请使用 quit 命令。注意,HBase 仍在后台运行。
hbase
quit
j. 完成上述使用后,停止 HBase:
bash
cd $HBASE_HOME
bin/stop-hbase.sh # 停止 HBase。
jps # 检查 Java 进程,没有 HMaster
4.HDFS上的独立HBase
在独立的 Hbase 上,所有守护进程都在一个 JVM 内运行。下面讲述 HBase 不是持久化到本地文件系统,而是持久化到 HDFS 上的配置与运行。
a. 先确认 HBase 已经停止。若没有,则将 HBase 停止:
bash
cd $HBASE_HOME
bin/stop-hbase.sh
jps # 检查 Java 进程,没有 HMasterb. 配置。编辑配置文件 hbase-site.xml :
bash
cd $HBASE_HOME/conf
vi hbase-site.xml修改内容如下(增加开头的第一个属性 hbase.rootdir,它对应于 HDFS 的服务地址):
xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>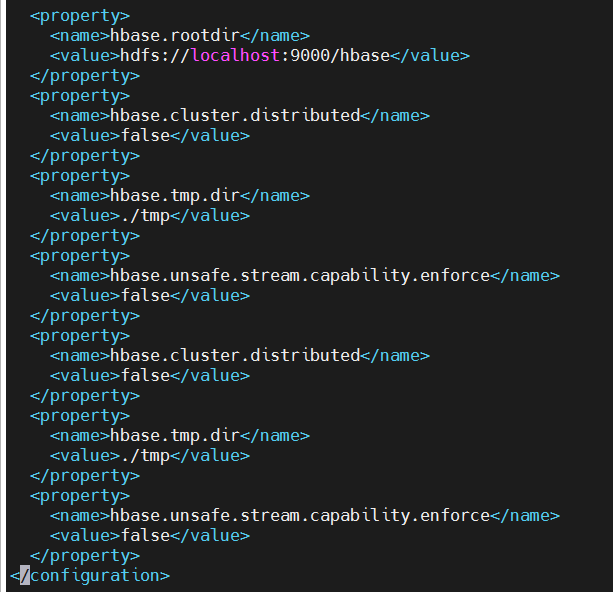
c. 启动 Hadoop 因为要运行在 HDFS 上(将数据持久化到 HDFS),必须先将 Hadoop 运行起来:
bash
cd $HADOOP_HOME
sbin/start-dfs.sh # 启动 Hadoop。
jps # 检查 Java 进程,可以看到 NameNode、DataNode、SecondaryNameNode。
#启动 HBase
cd $HBASE_HOME
bin/start-hbase.sh # 启动 HBase。
jps # 检查 Java 进程,可以看到 HMaster。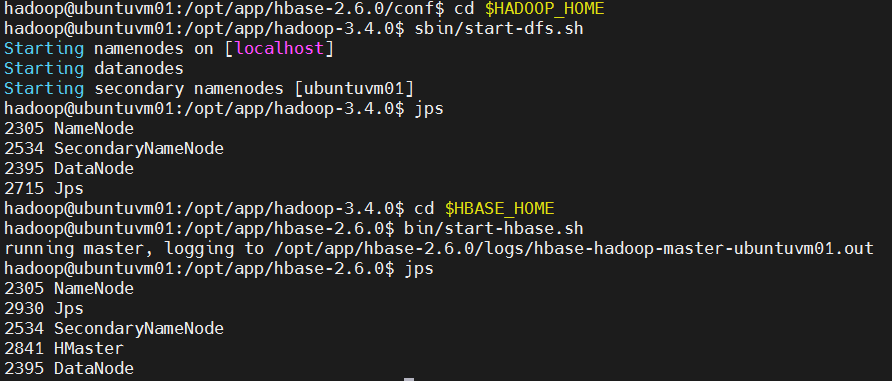
运行过程中若出现错误,可以检查在 logs 文件夹中的日志。 如果一切正常,HBase 将在 HDFS 中创建其目录。在上面的配置中,它存储在 HDFS 的 /hbase/ 中。您可以在 Hadoop 的 bin/ 目录中使用 hadoop fs 命令来列出此目录。 屏幕输出示例如下:
bash
cd $HADOOP_HOME
bin/hadoop fs -ls /hbase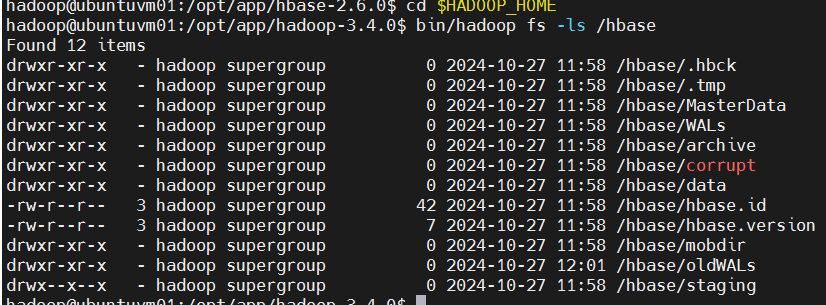
这里如果发现 HBase 启动不了,过一会儿就退出。查日志发现 region 服务器一直运行不起来,再过一会儿 HMaster 进程就退出了。再次重启也无效。这种情况下可能是由于 HBase Master 节点在初始化时,发现了之前未完成的初始化标记或者状态信息,从而导致无法正常启动。
一并删除 HBase 自带的 ZooKeeper 文件中的 version-2 目录和在 HDFS 中的 HBase 数据可以清除掉一切数据,从而使得下次启动时不会出现冲突,解决日志中提示的这个 org.apache.hadoop.hbase.PleaseHoldException: Master is initializing 错误。删除这些文件相当于重置了 HBase ,让它可以重新进行初始化并启动。
需要提醒的是,删除 HBase 数据和 ZooKeeper 文件夹中的内容是危险操作,应当谨慎。在进行此类敏感操作前,建议备份数据以及配置文件,以免造成不可逆的数据损失。
下面是删除文件,让 HBase 重新启动的操作命令,仅供参考。
bash
# 通过jps看到HMaster进程已经退出(HBase未启动)。
jps
# 删除HBase在HDFS上的数据。
cd $HADOOP_HOME
bin/hdfs dfs -rm -r /hbase
# 删除HBase在ZooKeeper上的version-2目录。
cd $HBASE_HOME
rm -rf tmp/zookeeper/zookeeper_0/version-2
# 启动HBase。
cd $HBASE_HOME
bin/start-hbase.sh启动后,注意通过 jps 检查 HMaster 进程,并查看 HBase 的日志,确保它正常启动。
为避免以上问题,应当在关闭或挂起虚拟机之前先正常停止HBase服务,确保所有数据(包括内存缓冲数据)都写入磁盘:
bash
# 停止HBase。
cd $HBASE_HOME
bin/stop-hbase.sh另外,在生产环境中建议配置 HBase 的高可用性和容错性,以减少因意外故障而导致的数据损失和系统不稳定的风险。
bash
# 关闭HDFS
cd $HADOOP_HOME
sbin/stop-dfs.sh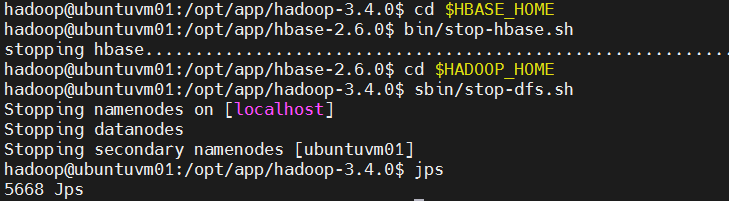
5.Hadoop 与 Hbase 的综合使用
- 熟悉 HBase 的安装和配置,运行、停止、状态检查等。
bash
# 启动HDFS
cd $HADOOP_HOME
sbin/start-dfs.sh
jps # 检查Java进程,应该有: NameNode, DataNode, SecondaryNameNode
# 启动HBase
cd $HBASE_HOME
bin/start-hbase.sh
jps # 检查Java进程,应该有: HMaster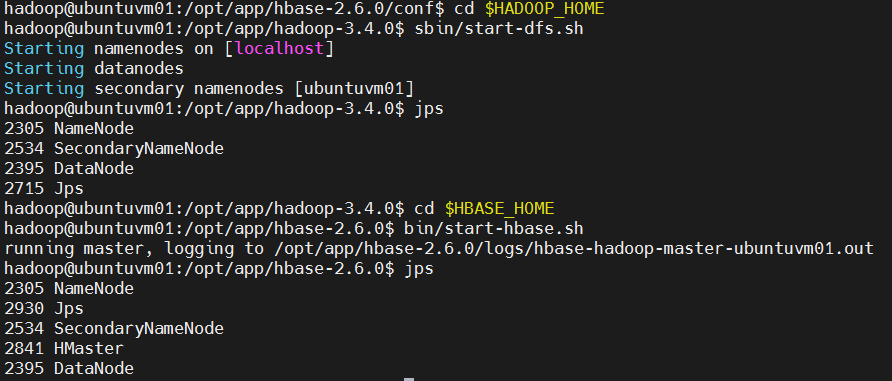
- 在 Windows 宿主机的浏览器,打开虚拟机内 HBase Web UI: http://localhost:16010
注意,虚拟机是以 NAT 方式联网,在 Windows 宿主机上要通过端口转发才能连接到虚拟机内的端口。
① 查看防火墙是否关闭
bash
ss②查看16010端口是否被侦听
bash
ss -tulpn | grep 16010 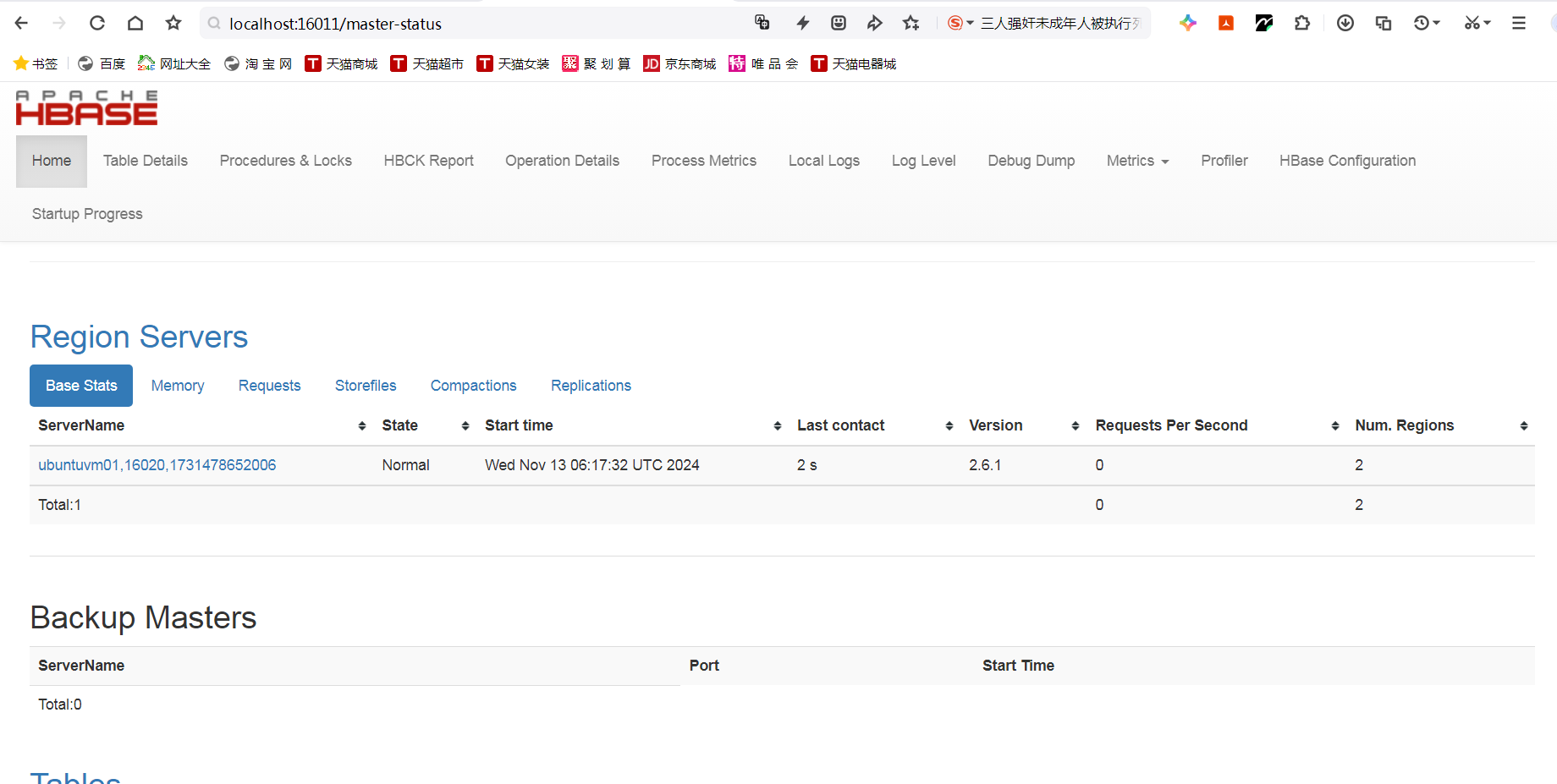
- 熟悉 HBase Shell 的基本操作。
①启动 HBase Shell:
bash
# 启动 hbase shell,可按 Ctrl+D 退出。
cd $HBASE_HOME
bin/hbase shell
②基本操作命令:
hbase
# create table.
create 'test', 'cf'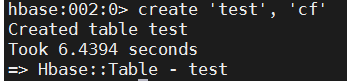
hbase
list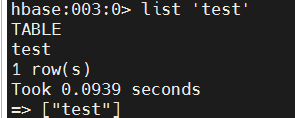
hbase
describe 'test'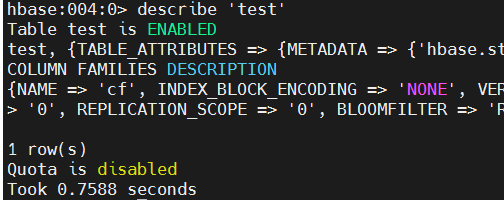
hbase
# put value.
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'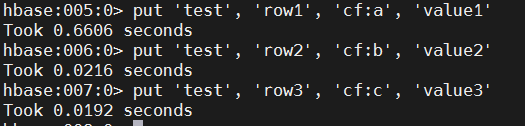
hbase
scan 'test'
hbase
get 'test', 'row1'
get 'test', 'row1', 'cf:a'
get 'test', 'row2', 'cf:b'
hbase
disable 'test'
enable 'test'
disable 'test'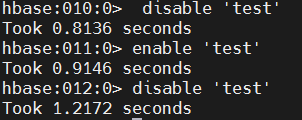
hbase
drop 'test'
hbase
list
# exit hbase shell.
Exit- 做习题:现有以下关系数据库中的表,要求将其转换为适合 HBase 存储的表并插入数据。
表1: 学生(Student)表
| 学号(S_No) | 姓名(S_Name) | 性别(S_Sex) | 年龄(S_Age) |
|---|---|---|---|
| 2015001 | Zhangsan | male | 23 |
| 2015002 | Mary | female | 22 |
| 2015003 | Lisi | male | 24 |
表2: 课程(Course)表
| 课程号(C_No) | 课程名(C_Name) | 学分(C_Credit) |
|---|---|---|
| 123001 | Math | 2 |
| 123002 | Computer Science | 5 |
| 123003 | English | 3 |
表3: 选课(SC)表
| 学号(SC_Sno) | 课程号(SC_Cno) | 成绩(SC_Score) |
|---|---|---|
| 2015001 | 123001 | 86 |
| 2015001 | 123003 | 69 |
| 2015002 | 123002 | 77 |
| 2015002 | 123003 | 99 |
| 2015003 | 123001 | 98 |
| 2015003 | 123002 | 95 |
解答:
hbase
# create table and column falimy.
create 't1', {NAME => 'Student'}
create 't2', {NAME => 'Course'}
create 't3', {NAME => 'SC'}
# list all existing tables.
list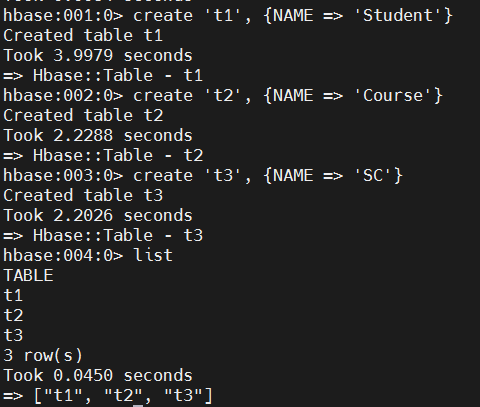
hbase
# put value.
put 't1', '2015001', 'Student:S_Name', 'Zhangsan'
put 't1', '2015001', 'Student:S_Sex', 'male'
put 't1', '2015001', 'Student:S_Age', '23'
put 't1', '2015002', 'Student:S_Name', 'Mary'
put 't1', '2015002', 'Student:S_Sex', 'female'
put 't1', '2015002', 'Student:S_Age', '22'
put 't1', '2015003', 'Student:S_Name', 'Lisi'
put 't1', '2015003', 'Student:S_Sex', 'male'
put 't1', '2015003', 'Student:S_Age', '24'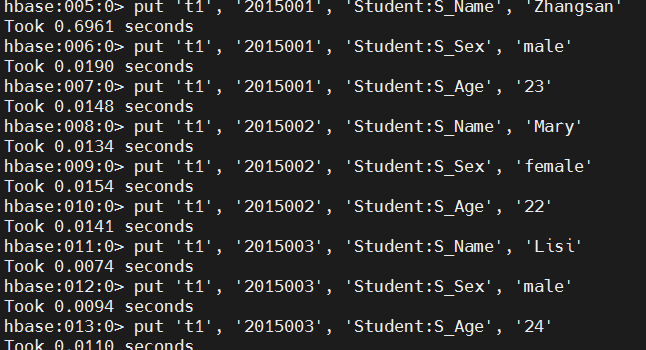
hbase
put 't2', '123001', 'Course:C_Name', 'Math'
put 't2', '123001', 'Course:C_Credit', '2.0'
put 't2', '123002', 'Course:C_Name', 'Computer Science'
put 't2', '123002', 'Course:C_Credit', '5.0'
put 't2', '123003', 'Course:C_Name', 'English'
put 't2', '123004', 'Course:C_Credit', '3.0'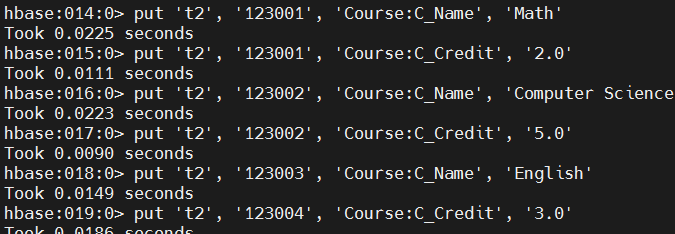
hbase
put 't3', '2015001', 'SC:SC_Cno', '123001'
put 't3', '2015001', 'SC:SC_Score', '86'
put 't3', '2015001', 'SC:SC_Cno', '123003'
put 't3', '2015001', 'SC:SC_Score', '69'
put 't3', '2015002', 'SC:SC_Cno', '123002'
put 't3', '2015002', 'SC:SC_Score', '77'
put 't3', '2015002', 'SC:SC_Cno', '123003'
put 't3', '2015002', 'SC:SC_Score', '99'
put 't3', '2015003', 'SC:SC_Cno', '123001'
put 't3', '2015003', 'SC:SC_Score', '98'
put 't3', '2015003', 'SC:SC_Cno', '123002'
put 't3', '2015003', 'SC:SC_Score', '95'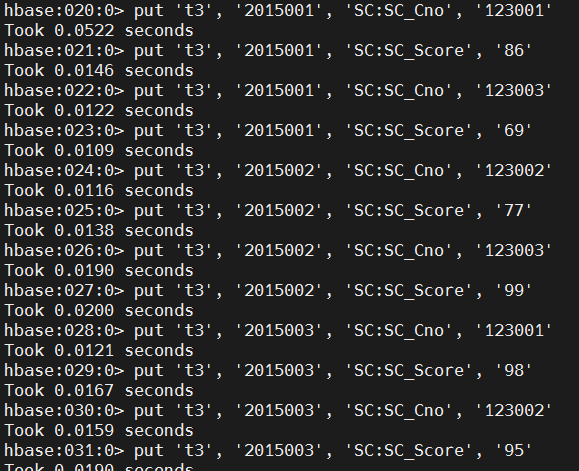
对它们进行一些操作:
hbase
# scan values.
scan 't1'
scan 't2'
scan 't3'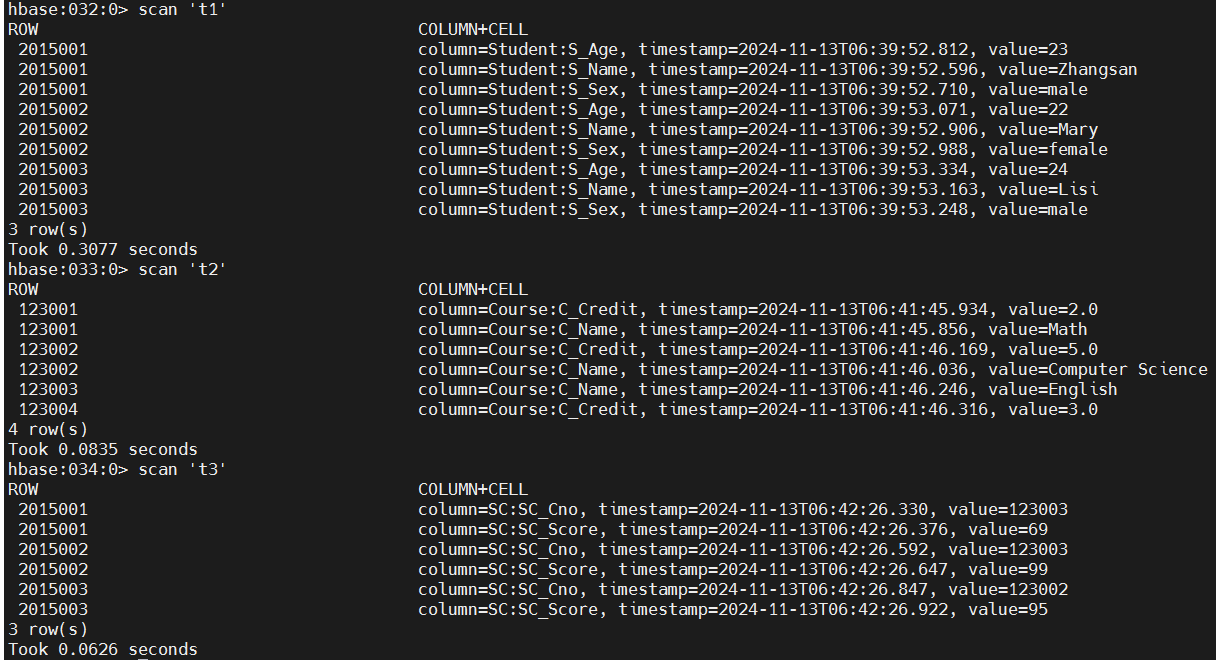
hbase
# get value.
get 't1', '2015001'
get 't1', '2015001', 'Student:S_Name'
get 't1', '2015002', 'Student:S_Name', 'Student:S_Sex'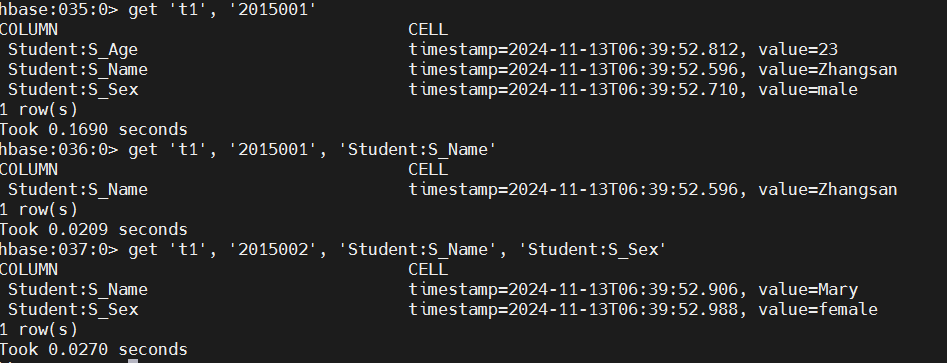
hbase
# count records
count 't1'
count 't2'
count 't3'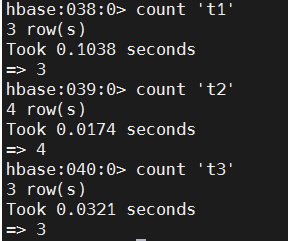
hbase
# describe table.
describe 't1'
# enable/disable/drop table
disable 't1'
enable 't1'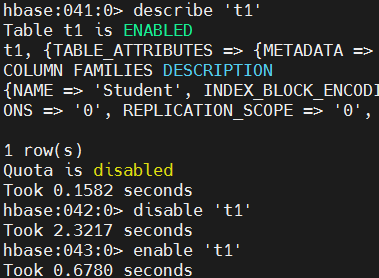
hbase
# truncate all data in given table.
truncate 't1'
count 't1'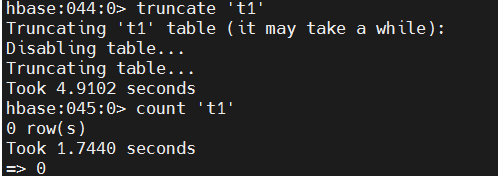
hbase
# drop tables
disable 't1'
disable 't2'
disable 't3'
drop 't1'
drop 't2'
drop 't3'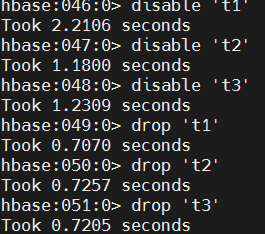
hbase
# list existing tables.
list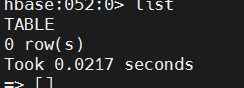
hbase
# exit hbase shell
Exit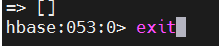
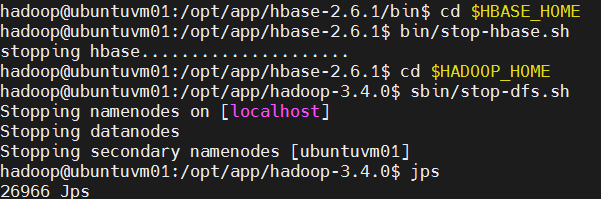
- 关闭HBase和HDFS。
bash
# 关闭HBase
cd $HBASE_HOME
bin/stop-hbase.sh
# 关闭HDFS
cd $HADOOP_HOME
sbin/stop-dfs.sh [外链图片转存中...(img-58VhAZPT-1760426221246)]
```hbase
# truncate all data in given table.
truncate 't1'
count 't1'外链图片转存中...(img-iwQLyvGu-1760426221246)
hbase
# drop tables
disable 't1'
disable 't2'
disable 't3'
drop 't1'
drop 't2'
drop 't3'外链图片转存中...(img-QvTBjPj8-1760426221246)
hbase
# list existing tables.
list外链图片转存中...(img-CYGxvwCd-1760426221246)
hbase
# exit hbase shell
Exit外链图片转存中...(img-ZXVG9AUt-1760426221247)
- 关闭HBase和HDFS。
bash
# 关闭HBase
cd $HBASE_HOME
bin/stop-hbase.sh
# 关闭HDFS
cd $HADOOP_HOME
sbin/stop-dfs.sh