一个项目会不会变得坚固的屎山,很多时候不光是代码质量问题,还跟工作流程和使用的工具有关。一个顺手的工具能自动化一些乱七八糟的事情,让复杂的流程变得清晰,能让我的项目干净又卫生。
今天我不打算聊那些人尽皆知的库,比如Requests或者Pandas。我想分享一些真正帮我理顺工作流、提升开发体验的工具,它们是我在解决实际问题时发现并一直用到现在的。
ServBay:管理本地开发环境的不二之选
有没有铁子为管理Python环境头疼的?这个项目用Python 3.8,那个项目要用3.11,居然还有老项目用Python 2.7的。用pyenv、virtualenv、conda这些工具组合起来,问题是解决了,但是零散又麻烦。
直到我开始用ServBay,这些问题就迎刃而解了。它可以解决很多问题
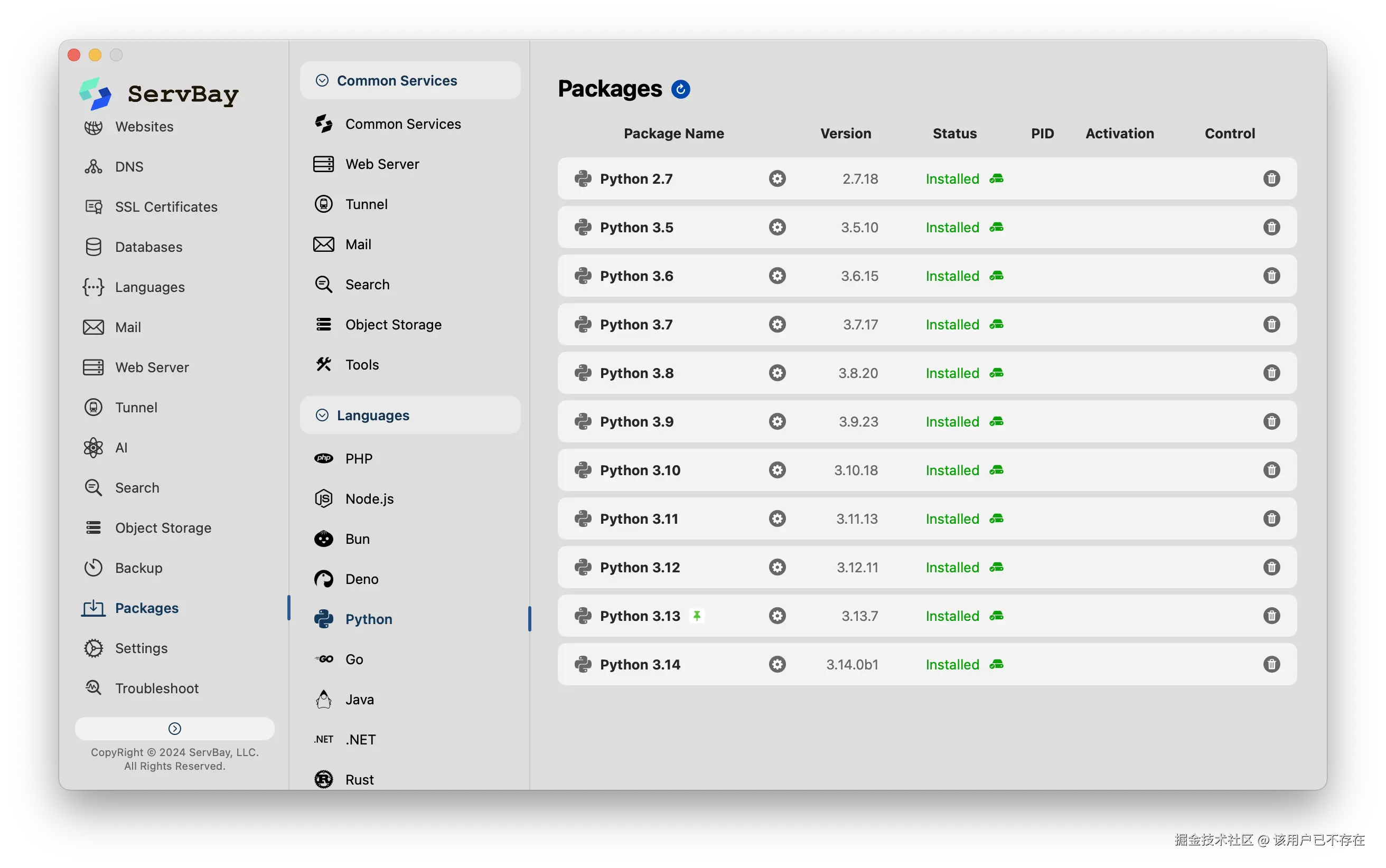
- 多版本共存与隔离:我可以在ServBay里一键安装从2.7到3.14等多个Python版本。每个版本都干干净净地独立存在。我可以给不同项目指定不同的Python版本,它们之间互不影响。而且我从2.7装到3.14,总共也就花了5分钟不到。
-
一站式服务:它不只是个Python管理器。我经常需要用到数据库和缓存,ServBay集成了Nginx、MariaDB、MySQL、Redis这些常用服务。我需要什么,就启动什么,都在一个面板里统一管理,非常省心。
-
本地AI环境一键搞定:我想在本地跑个开源大模型(比如Qwen 3)做些实验时,不需要自己去折腾复杂的环境配置,在ServBay里点一下就能安装和运行,非常方便。
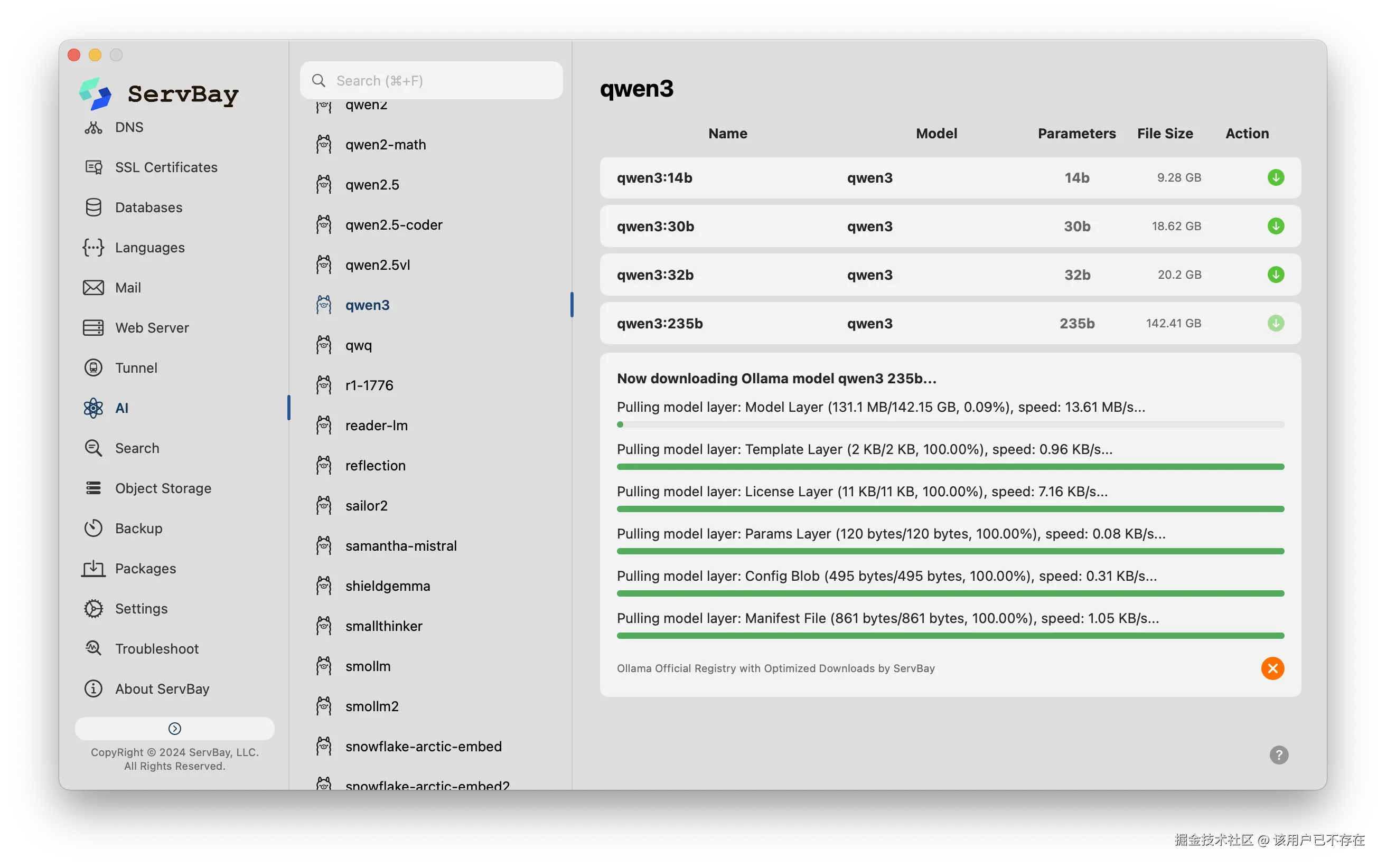
一句话点评:它帮我统一管理了本地开发所需的一切,从Python版本到数据库再到AI模型,我不用再东拼西凑地维护一套环境了。
Doit:告别乱七八糟的Makefile
每个项目里我都会有一些需要自动化的任务,比如格式化代码、跑测试、打包发布。以前我可能会写一堆.sh脚本,或者用Makefile,但这些写起来总觉得不那么顺手。doit让我能用纯Python来定义和执行这些任务。
示例代码:
python
# dodo.py,这是doit的配置文件
def task_format():
"""格式化代码"""
return {
'actions': ['ruff check . --fix'],
}
def task_test():
"""运行测试,这会在格式化之后运行"""
return {
'actions': ['pytest -q'],
'task_dep': ['format'], # 声明任务依赖
}在命令行里运行 doit 就行,它会自动处理任务依赖,只运行需要跑的部分。
一句话点评:我用它来替代零散的Shell脚本,让项目任务管理变得更清晰、更Pythonic。
Playwright:新一代的浏览器自动化工具
在做Web自动化和爬虫时,我用了很多年的Selenium。但自从换到Playwright,我的体验好了很多。它是微软出的,感觉更现代,API也更友好。它天生就考虑了异步等待,帮我有效减少了因页面加载慢而导致的各种奇怪错误。
示例代码:
python
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://www.baidu.com")
page.screenshot(path="baidu.png")
browser.close()一句话点评:做Web自动化或者爬虫,我现在首选它,比Selenium省心。
pyinfra:用Python代码来描述服务器
当需要部署应用到服务器上时,很多人会用Ansible。我也用过,但写一堆YAML文件来表达复杂的逻辑时,会感觉很别扭。pyinfra 让我能用纯Python代码来完成服务器的配置和部署,这更符合我的编程习惯。
示例代码:
python
from pyinfra import host
from pyinfra.operations import server, files
# 确保服务器上有一个叫'app'的用户
server.user(
name="Create app user",
user="app",
home="/home/app",
)
# 把本地的app目录同步到服务器的/opt/app下
files.sync(
name="Sync app files",
src="dist/app/",
dest="/opt/app/",
)一句话点评:我个人更喜欢用代码而不是配置文件来搞定部署,如果你也一样,pyinfra很适合。
Rio:用写前端的方式来构建终端UI
有时候我想给自己的命令行工具做炫酷的交互界面,而不是停留在简单的问答。Rio这个TUI框架就很有意思,它的设计思路和Web前端的React很像,用声明式的组件来构建界面,写起来感觉很清爽。
示例代码:
python
import rio
class MyAppComponent(rio.Component):
def build(self) -> rio.Component:
return rio.Column(
rio.Text("Hello, World!", style="heading1"),
rio.Button("Click Me!", on_press=lambda: print("Button clicked")),
)
app = rio.App(build=MyAppComponent)
app.run()一句话点评:当我想给命令行应用做一个漂亮的交互界面时,会用Rio来试试,它的组件化思想我很喜欢。
FreeSimpleGUI: 快速给脚本加个简单的图形界面
如果想要给非技术的用户写一些小工具,纯命令行他们用起来不方便。但为此去学庞大的Qt或Tkinter又觉得小题大做。FreeSimpleGUI 完美解决了这个需求,用很少的代码就能搭出一个简单的窗口。
示例代码:
python
import FreeSimpleGUI as sg
layout = [
[sg.Text("请输入你的名字")],
[sg.InputText(key='-INPUT-')],
[sg.Button('确定'), sg.Button('取消')]
]
window = sg.Window('一个简单的窗口', layout)
while True:
event, values = window.read()
if event in (sg.WIN_CLOSED, '取消'):
break
print(f'你好, {values["-INPUT-"]}!')
window.close()一句话点评:需要快速给脚本加个图形界面时,我就会用它,几分钟就能搞定一个能用的窗口。
py-spy:无侵入的Python程序性能分析器
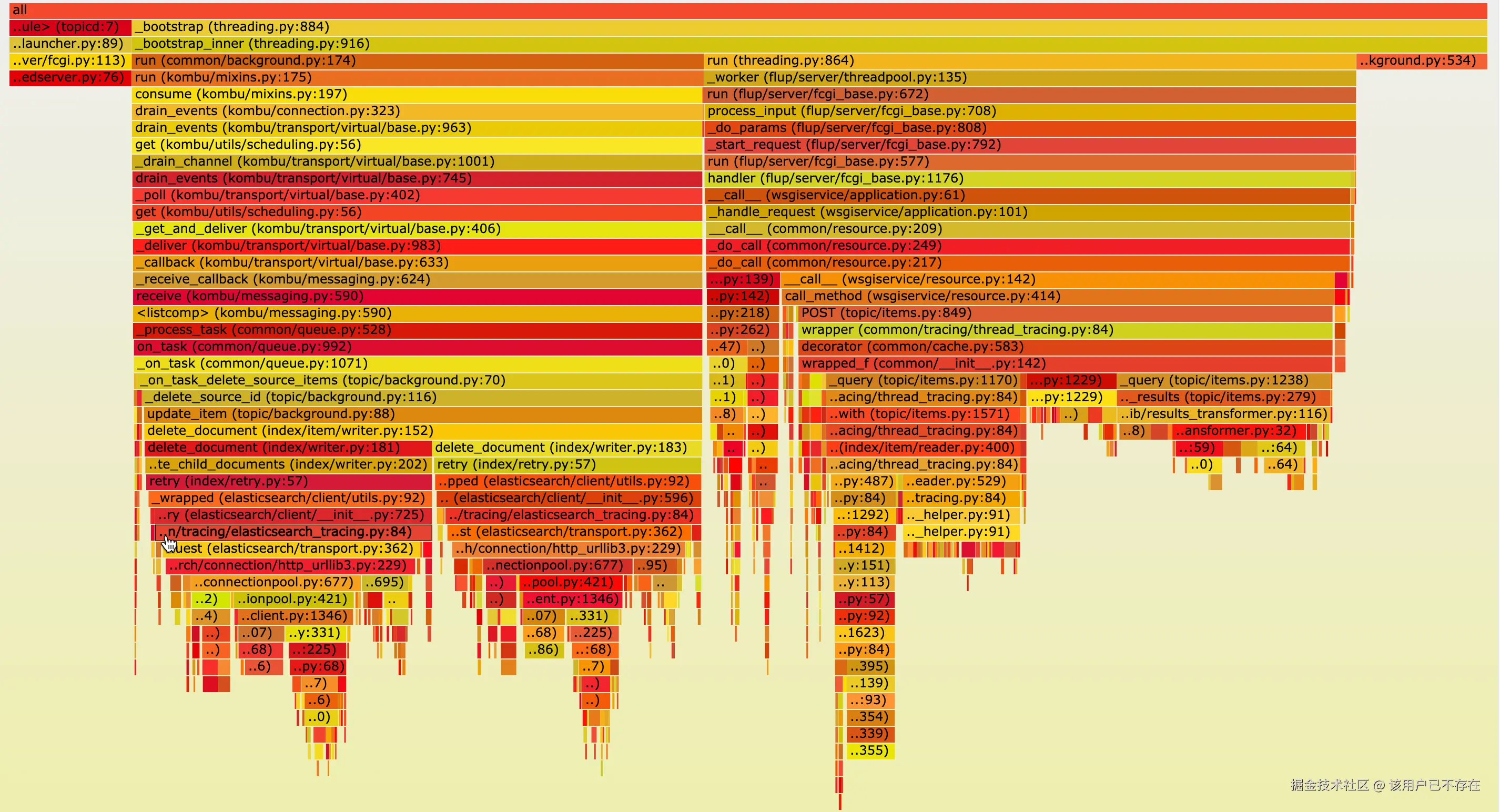
线上Python程序突然CPU占用很高,或者感觉很慢,这种事我遇到过好几次。py-spy是我排查这类问题的利器。它可以附加到一个正在运行的Python进程上进行性能采样,不需要修改任何代码,甚至不用重启进程。它生成的火焰图能让我一眼就看出性能瓶颈在哪。
命令行用法:
python
# 实时查看哪个函数最耗CPU
py-spy top --pid 12345
# 生成火焰图,方便事后分析
py-spy record -o profile.svg --pid 12345一句话点评:排查线上性能问题时,我首选py-spy,因为它无侵入、够直接。
Watchfiles:极速的文件监控与自动重载
在开发Web应用时,如果需要修改代码后服务能自动重启的功能。Watchfiles 是实现这个功能的核心。它是一个用Rust写的库,监控文件变动的速度飞快,能耗也低。我用它来触发自动跑测试、重新加载服务等操作。
监控并跑测试的脚本:
python
from watchfiles import watch
from subprocess import run
# 监控src目录下所有.py文件的变化
for changes in watch('./src', watch_filter=lambda change, filename: filename.endswith('.py')):
print("文件变动:", changes)
run(["pytest", "-q"])一句话点评:本地开发时,我用它来监听文件变动并自动执行命令,开发幸福感大大提升。
BeautifulSoup:HTML解析的老牌强者
这个库可能很多人都用过,但我还是想再提一次。做网络爬虫时,从杂乱的HTML代码里提取数据是很头疼的。BeautifulSoup把这个过程变得非常简单,它的API设计得很人性化,能很好地处理那些不规范的HTML,为我省了很多事。
示例代码:
python
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>一个故事</title></head>
<body><p class="title"><b>The Dormouse's story</b></p></body></html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.title.string) # 输出: 一个故事一句话点评:处理HTML解析和数据提取,它依然是我的首选,尤其是面对不规范的网页时。
希望我分享的这些工具,也能在某些时候帮上忙。好的工具不一定是最复杂的,而是最能解决当下问题的。