点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月13日更新到: Java-147 深入浅出 MongoDB 分页查询详解:skip() + limit() + sort() 实现高效分页、性能优化与 WriteConcern 写入机制全解析 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Flink 广播状态
- 基本概念、代码案例、测试结果

状态存储
Flink的一个重要特性就是有状态计算(stateful processing),Flink提供了简单易用的API来存储和获取状态,但是我们还是要理解API背后的原理,才能更好的使用。
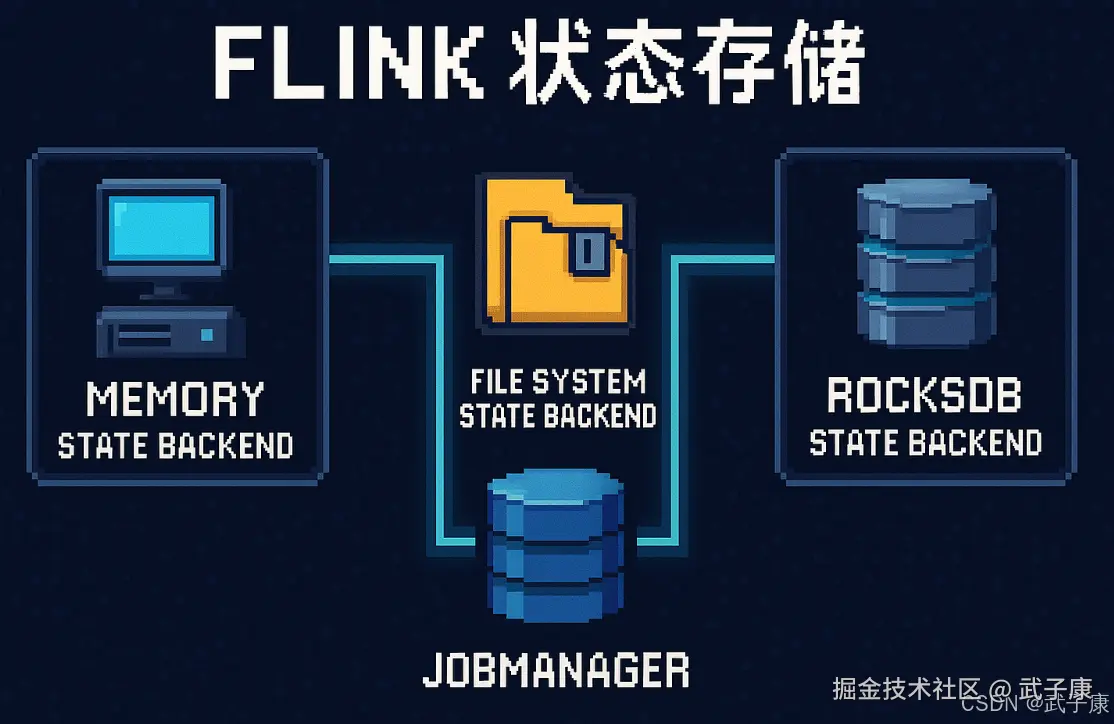
State存储方式
Flink为State提供了三种开箱即用的后端存储方式(state backend):
- Memory State Backend
- File System (FS)State Backend
- RocksDB State Backend
MemoryStateBackend
MemoryStateBackend将工作状态数据保存在TaskManager的Java内存中。Key/Value状态和Window算子使用哈希表存储数值和触发器。进行快照时(CheckPointing),生成的快照数据将和 CheckPoint ACK消息一起发送给 JobManager,JobManager将收到的所有快照数据保存在Java内存中。 MemoryStateBackend现在被默认配置成异步的,这样避免阻塞主线程的pipline处理,MemoryStateBackend的状态存取的数据都非常快,但是不适合生产环境中使用。这是以为它有以下限制:
- 每个state的默认大小被限制为5MB(这个值可以通过MemoryStateBackend构造方法设置)
- 每个Task的所有State数据(一个Task可能包含一个Pipline中的多个的Operator)大小不能超过RPC系统的帧大小(akk.framesize 默认10MB)
- JobManager收到的State数据总和不能超过JobManager内存
MemoryStateBackend适合的场景:
- 本地开发和调试
- 状态很小的作业
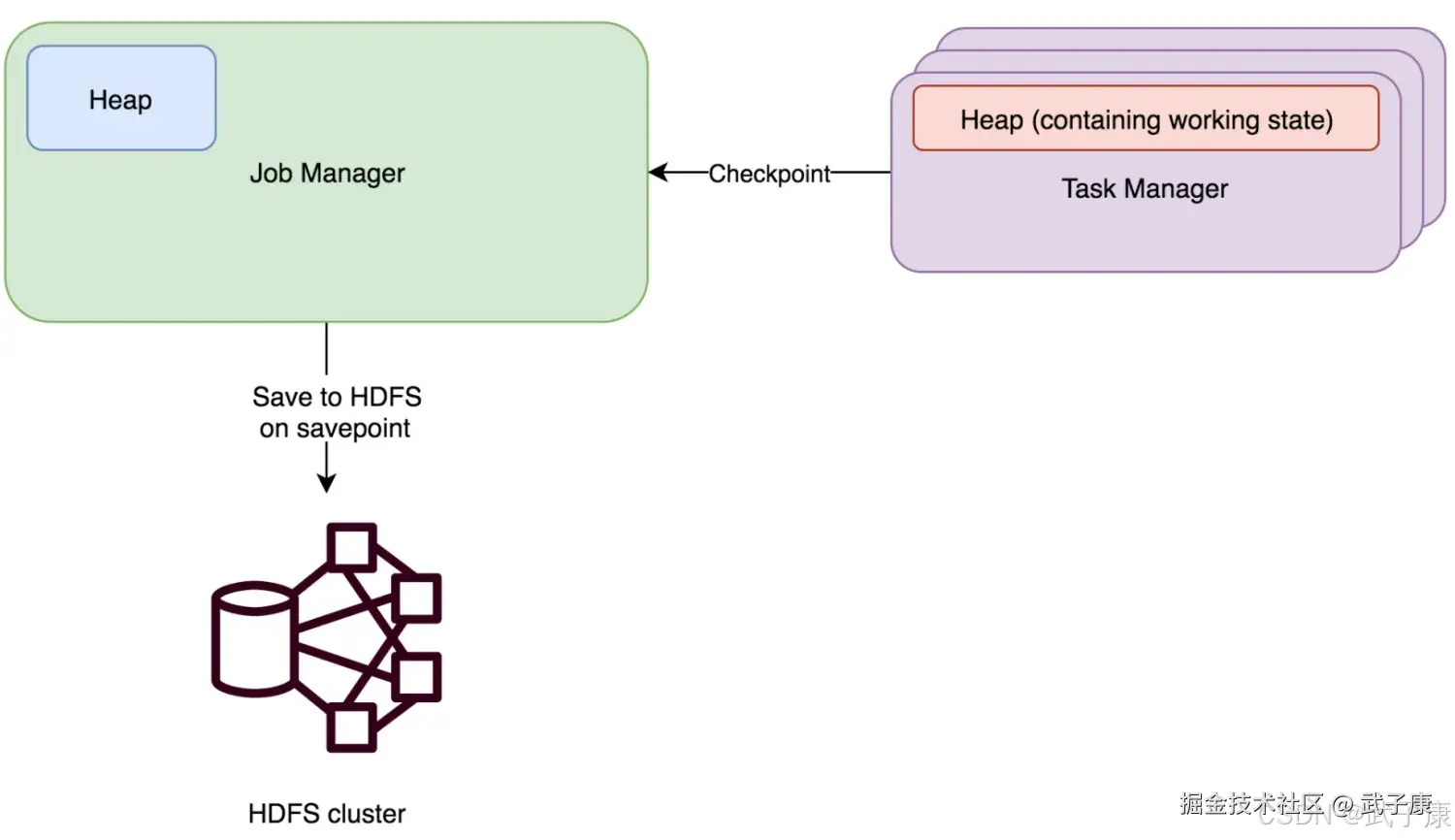
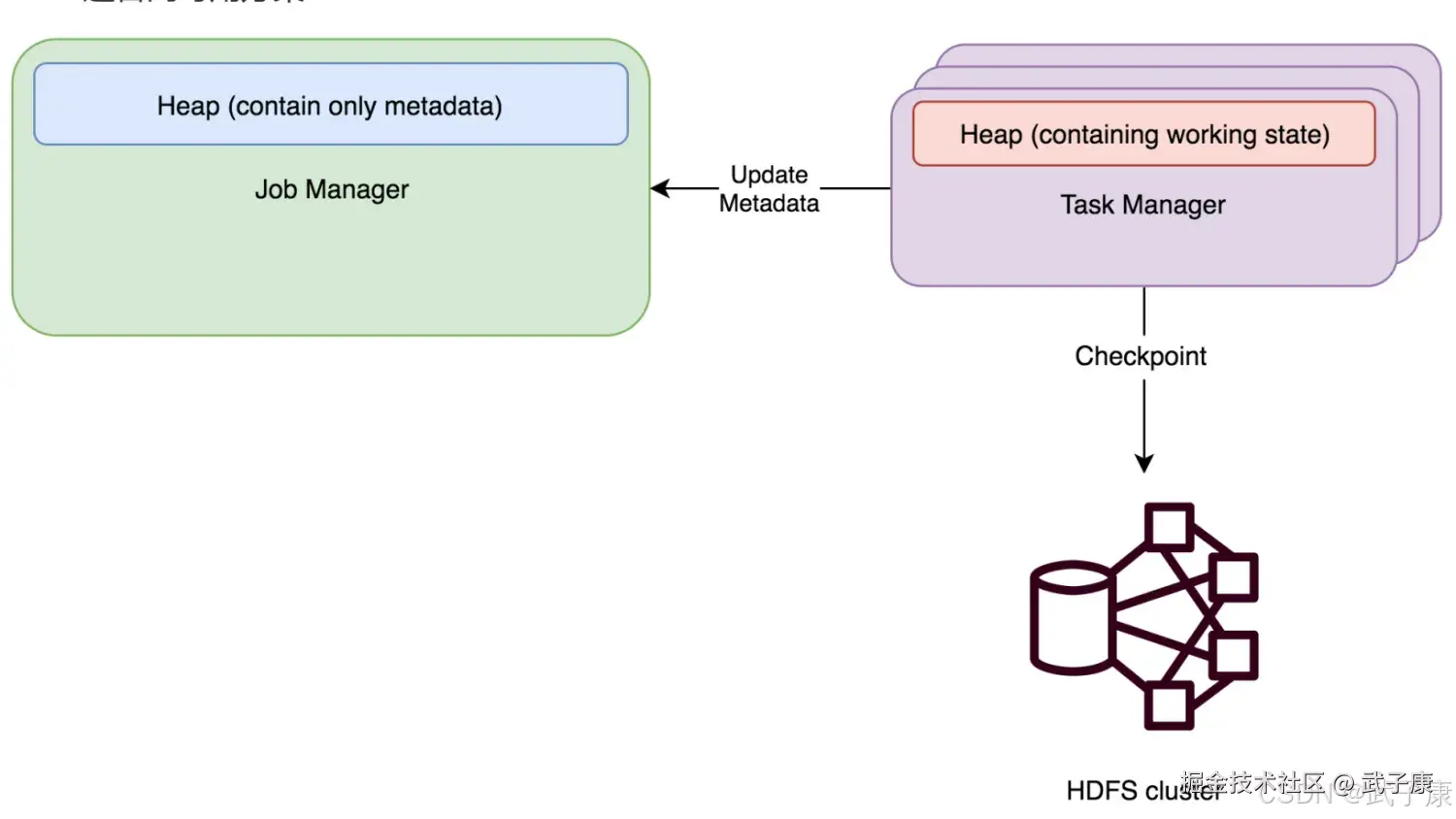
FsStateBackend
FsStateBackend 需要配置一个CheckPoint路径,例如:hdfs://xxxxxxx 或者 file:///xxxxx,我们一般都会配置HDFS的目录。 FsStateBackend将工作状态数据保存在TaskManager的Java内存中,进行快照时,再将快照数据写入上面的配置的路径,然后将写入的文件路径告知JobManager。JobManager中保存所有状态的元数据信息(在HA的模式下,元数据会写入CheckPoint目录)。 FsStateBackend 默认使用异步方式进行快照,防止阻塞主线程的Pipline处理,可以通过FsStateBackend构造函数取消该模式:
shell
new FsStateBackend(path, false)FsStateBackend 适合的场景:
- 大状态、长窗口、大键值(键或者值很大)状态的作业
- 适合高可用方案
RocksDBStateBackend
RocksDBStateBackend 也需要配置一个CheckPoint路径,例如:hdfs://xxx 或者 file:///xxx,一般是 HDFS 路径。 RocksDB是一种可嵌入的可持久型的 key-value 存储引擎,提供 ACID 支持。由Facebook基于LevelDB开发,使用LSM存储引擎,是内存和磁盘的混合存储。 RocksDBStateBackend将工作状态保存在TaskManager的RocksDB数据库中,CheckPoint时,RocksDB中的所有数据会被传输到配置的文件目录,少量元数据信息保存在JobManager内存中(HA模式下,会保存在CheckPoint目录)。 RocksDBStateBackend使用异步方式进行快照,RocksDBStateBackend的限制:
- 由于RocksDB的JNI Bridge API是基于 byte\[\] 的,RocksDBStateBackend支持的每个Key或者每个Value的最大值不超过 2的31次方(2GB)
- 要注意的是,有merge操作的状态(例如:ListState),可能会在运行过程中超过2的31次时,导致程序失败。 RocksDBStateBackend适用于以下的场景:
- 超大状态、超长窗口(天)、大键值状态的作业
- 适合高可用模式
使用RocksDBStateBackend时,能够限制状态大小是TaskManager磁盘空间(相对于FsStateBackend状态大小限制与TaskManager内存)。这也导致RocksDBStateBackend的吞吐比其他两个要低一些,因为RocksDB的状态数据的读写都要经过反序列化/序列化。
RocksDBStateBackend时目前三者中唯一支持增量CheckPoint的。 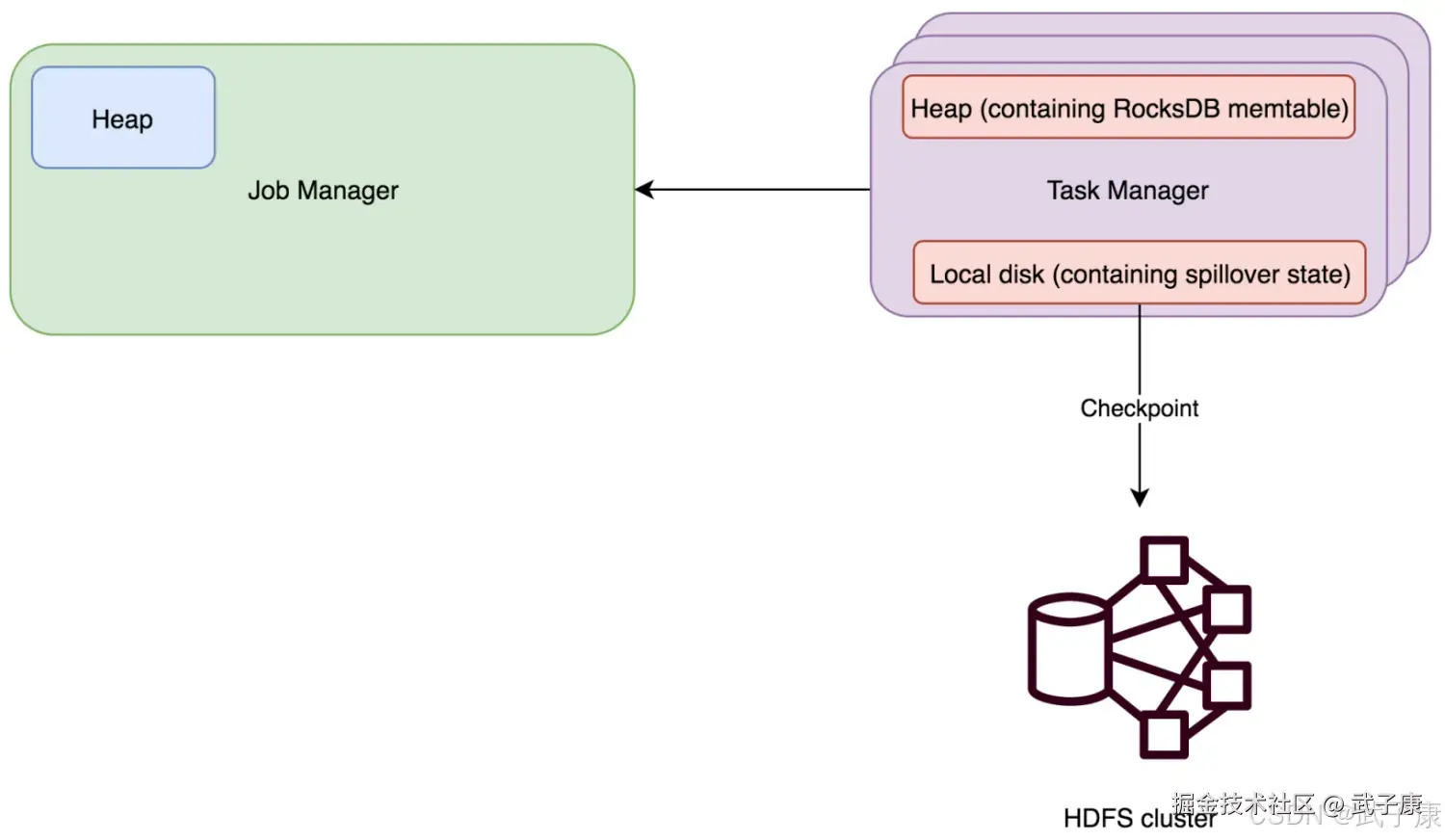
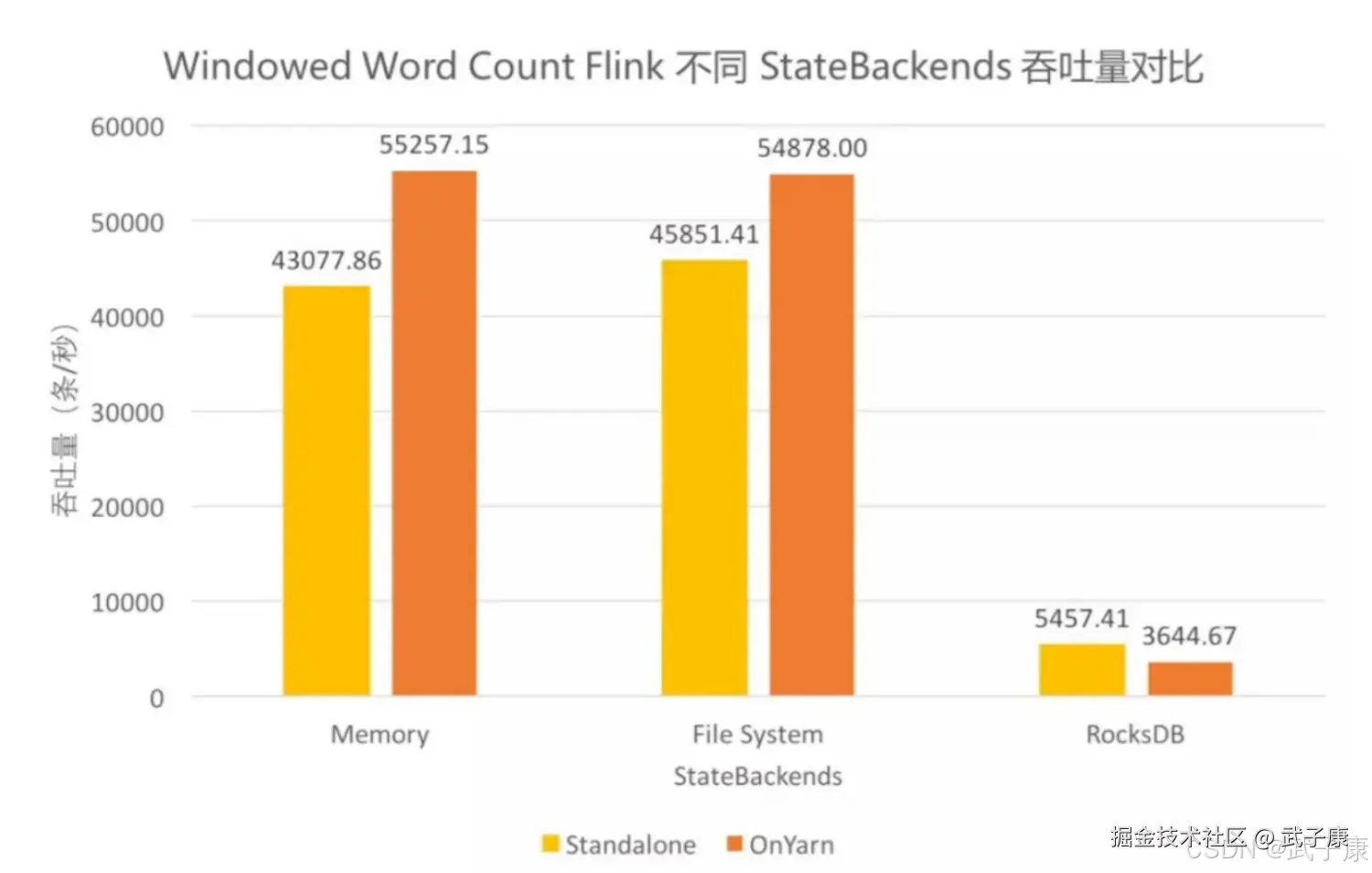
三者吞吐量对比
KeyedState 和 Operator State
State分类
Operator State
(或 non-keyed state): 每个Operator State绑定一个并行的Operator实例,KafkaConnector是使用OperatorState的典型示例:每个并行的Kafka Consumer实例维护了每个Kafka Topic分区和该分区Offset的映射关系,并将这个映射关系保存为OperatorState。 在算子并行度改变时,OperatorState也会重新分配。
Keyed State
这种State只存在于KeyedStream上的函数和操作中,比如Keyed UDF(KeyedProcessFunction)Window State。可以把Keyed State想象成被分区的OperatorState。每个KeyedState在逻辑上可以看成与一个 <parallel-operator-instance, key> 绑定,由于一个key肯定只存在于一个Operator实例,所以我们可以简单的的认为一个 <operator, key>对应一个 KeyedState。
每个KeyedState在逻辑上还会被分配一个KeyGroup,分配方法如下:
shell
MathUtils.murmurHash(key.hashCode()) % maxParallelism;其中maxParallelism是Flink程序的最大并行度,这个值一般我们不会去手动设置,使用默认的值(128)就好,这里注意下,maxParallelism和我们运行程序时指定的算子并行度(parallelism)不同,parallelism不能大于maxParallelism,最多两者相等。
为什么会有 Key Group这个概念呢? 我们通常写程序,会给算子指定一个并行度,运行一段时间后,积累了一些State,这时候数据量大了,需要增加并行度。我们修改并行度后重新提交,那这些已经存在的State该如何分配到各个Operator呢?这就有了最大并行度和KeyGroup的概念。 上面的计算公式也说明了KeyGroup的个数最多是maxParallelism个。当并行度改变之后,我们在计算这个Key被分配到的Operator:
shell
keyGroupId * paralleism / maxParallelism;可以看到,一个KeyGroupId会对应一个Operator,当并行度更改时,新的Operator会去拉取对应的KeyGroup的KeyedState,这样就把KeyedState尽量均匀的分配给所有的Operator了。 根据State数据是否被Flink托管,Flink又将State分类为:
- Managed State:被Flink托管,保存为内部的哈希表或者RocksDB,CheckPoint时,Flink将State进行序列化编码。例如:ValueState ListState
- Row State:Operator 自行管理的数据结构, Checkpoint时,它们只能以byte数据写入CheckPoint。
建议使用 Managed State,当使用 Managed State时,Flink会帮助我们更改并行度时重新分配State,优化内存。
使用ManageKeyedState
如何创建? 上面提到,KeyedState只能在KeyedStream上使用,可以通过Stream.keyBy创建KeyedStream,我们可以创建以下几种:
- ValueState
- ListState
- ReducingState
- AggregatingState<IN,OUT>
- MapState<UK,UV>
- FoldingState<T,ACC>
每种State都对应各种的描述符,通过描述符RuntimeContext中获取对应的State,而RuntimeContext只有RichFunction才能获取,所以想要使用KeyedState,用户编写的类必须继承RichFunction或者其他子类。
- ValueState getState(ValueStateDescriptor)
- ReducingState getReducingState(ReducingStateDescriptor)
- ListState getListState(ListStateDescriptor)
- AggregationState<IN,OUT> getAggregatingState(AggregatingStateDescriptor<IN,ACC,OUT>)
- FoldingState<T,ACC> getFoldingState(FoldingStateDescriptor<T,ACC>)
- MapState<UK,UV> getMapState(MapStateDescriptor<UK,UV>)
给KeyedState设置过期时间 在Flink 1.6.0 以后,还可以给KeyedState设置 TTL(Time-To-Live),当某一个Key的State数据过期时,会被StateBackend尽力删除。 官方给出了示例:
java
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1)) // 状态存活时间
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // TTL 何时被更新,这里配置的 state 创建和写入时
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();// 设置过期的 state 不被读取
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("textstate", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);State的TTL何时被更新? 可以进行以下配置,默认只是key的state被modify(创建或者更新)的时候才更新TTL:
- StateTtlConfig.UpdateType.OnCreateAndWrite:只在一个key的state创建和写入时更新TTL(默认)
- StateTtlConfig.UpdateType.onReadAndWrite:读取state时仍然更新TTL
当State过期但是还未删除时,这个状态是否还可见? 可以进行以下配置,默认是不可见的:
- StateTtlConfig.StateVisibility.NerverReturnExpired:不可见(默认)
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp:可见
注意:
-
状态存储开销
- 启用TTL特性会增加状态存储的大小,具体影响取决于State Backend类型:
- Heap State Backend:会额外存储一个Java 8对象,包含用户状态及其时间戳。
- RocksDB State Backend:在每个状态值(如List或Map的每个元素)序列化后增加8个字节的时间戳开销。
- 示例:如果使用MapState存储10万个键值对,RocksDB State Backend会额外增加约800KB的存储空间(8字节 × 100,000)。
- 启用TTL特性会增加状态存储的大小,具体影响取决于State Backend类型:
-
时间语义限制
- 目前仅支持基于Processing Time的TTL,暂不支持Event Time或Ingestion Time。
- 应用场景:适用于需要定期清理过期数据的场景,如会话超时、缓存失效等。
-
Checkpoint/Savepoint恢复要求
- 从Checkpoint/Savepoint恢复时,TTL的开启状态(是否启用)必须与保存时完全一致,否则会抛出
StateMigrationException。 - 建议:在作业升级或迁移时,需确保TTL配置的一致性。
- 从Checkpoint/Savepoint恢复时,TTL的开启状态(是否启用)必须与保存时完全一致,否则会抛出
-
TTL配置的临时性
- TTL配置(如过期时间)不会持久化到Checkpoint/Savepoint中,仅对当前作业生效。
- 示例:如果作业重启且未显式设置TTL,即使从包含TTL状态的Checkpoint恢复,也不会自动启用TTL。
-
MapState对NULL值的支持
- 开启TTL的MapState仅在用户自定义序列化器支持NULL值时,才允许存储NULL。
- 解决方案 :如果序列化器不支持NULL值,可通过
NullableSerializer包装一层,例如:
java
MapStateDescriptor<String, String> descriptor = new MapStateDescriptor<>(
"myMapState",
String.class,
NullableSerializer.wrap(StringSerializer.INSTANCE)
);- 注意事项 :使用
NullableSerializer会额外增加1字节的序列化开销。
使用ManageOperatorState
(这里以及后续放到下一篇:大数据-127 Flink)