背景意义
随着全球农业生产的不断发展,植物计数与分类技术在精准农业、作物监测和管理中扮演着越来越重要的角色。传统的人工计数方法不仅耗时耗力,而且容易受到人为因素的影响,导致计数结果的不准确性。因此,利用计算机视觉技术进行植物计数与分类,成为提升农业生产效率和管理水平的有效手段。近年来,深度学习特别是目标检测算法的快速发展,为这一领域提供了新的解决方案。
YOLO(You Only Look Once)系列算法因其高效的实时检测能力和良好的准确性,广泛应用于各种目标检测任务。YOLOv11作为该系列的最新版本,进一步提升了检测精度和速度,使其在复杂环境下的应用潜力更为显著。本研究旨在基于改进的YOLOv11算法,构建一个高效的烟叶植株计数与分类系统,专注于烟草植物和棉花植物的识别与计数。通过对包含3150张图像的数据集进行训练,该系统将实现对这两类植物的精准识别,为农业生产提供科学依据。
在数据集的构建过程中,采用了多种数据增强技术,以提高模型的泛化能力和鲁棒性。这些技术包括图像的水平翻转、垂直翻转及90度旋转等,使得模型能够在不同的环境和光照条件下保持良好的性能。此外,数据集的标注采用了YOLOv8格式,便于与现有的深度学习框架兼容,提升了模型训练的效率。
本研究不仅为烟叶植株的监测提供了创新的技术手段,还为其他农作物的智能化管理提供了参考。通过提高植物计数与分类的准确性,能够有效支持农业决策,促进可持续发展,最终实现农业生产的智能化与现代化。
图片效果
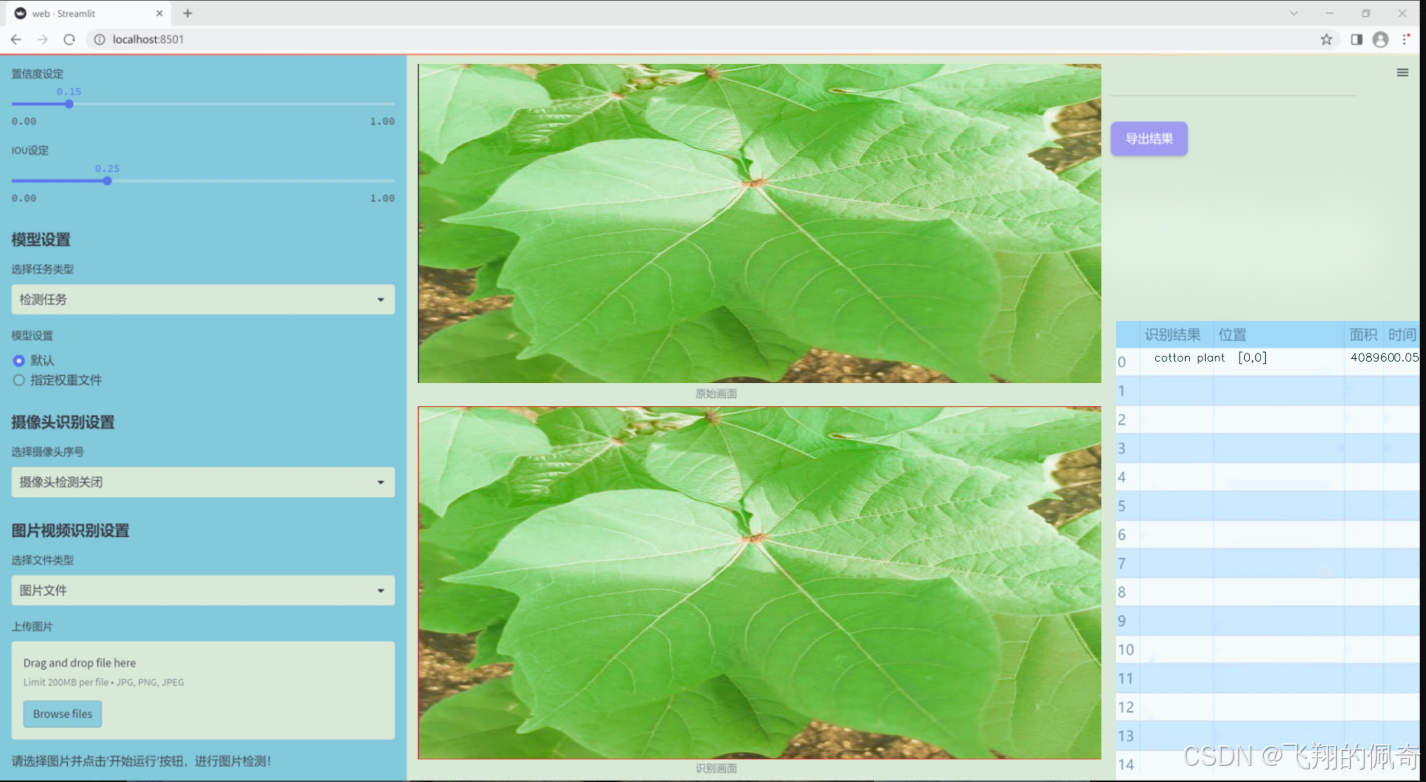
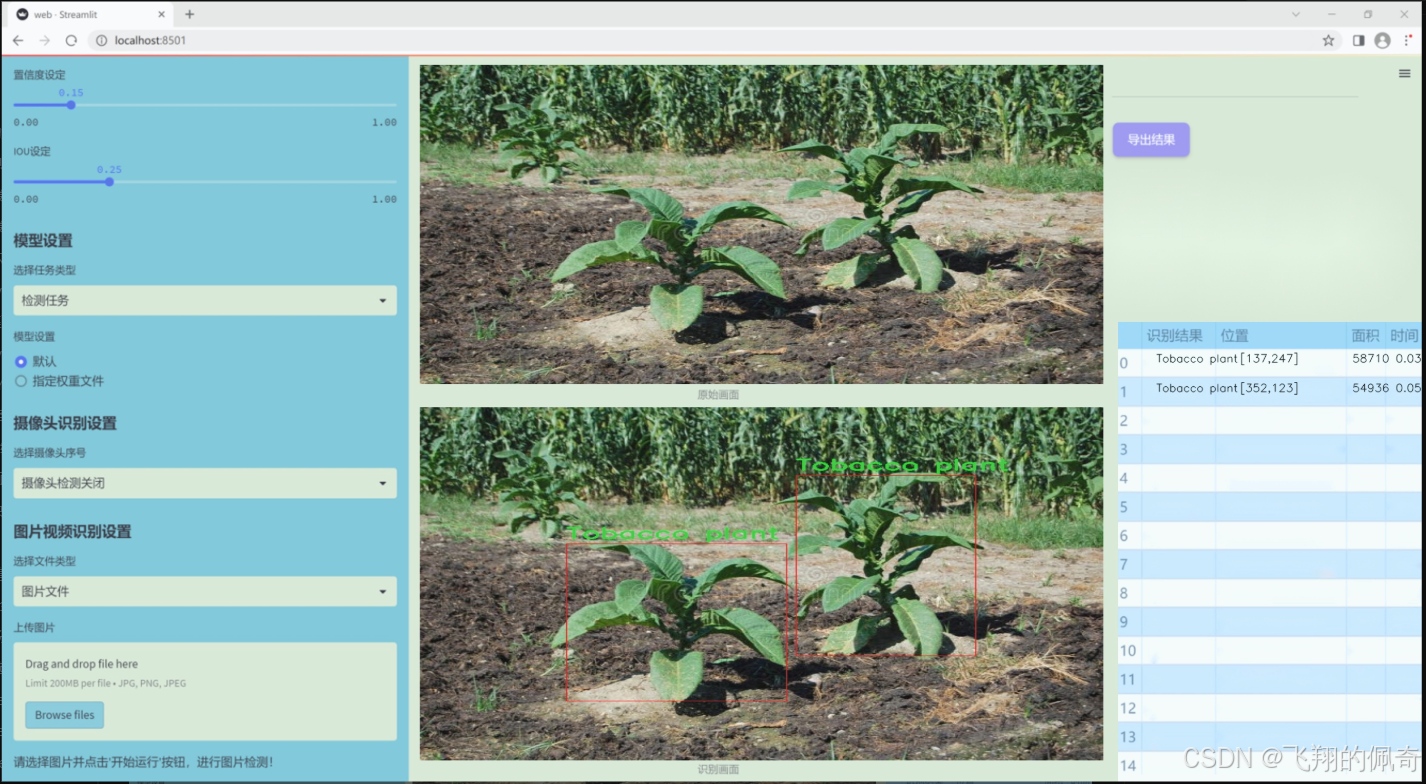
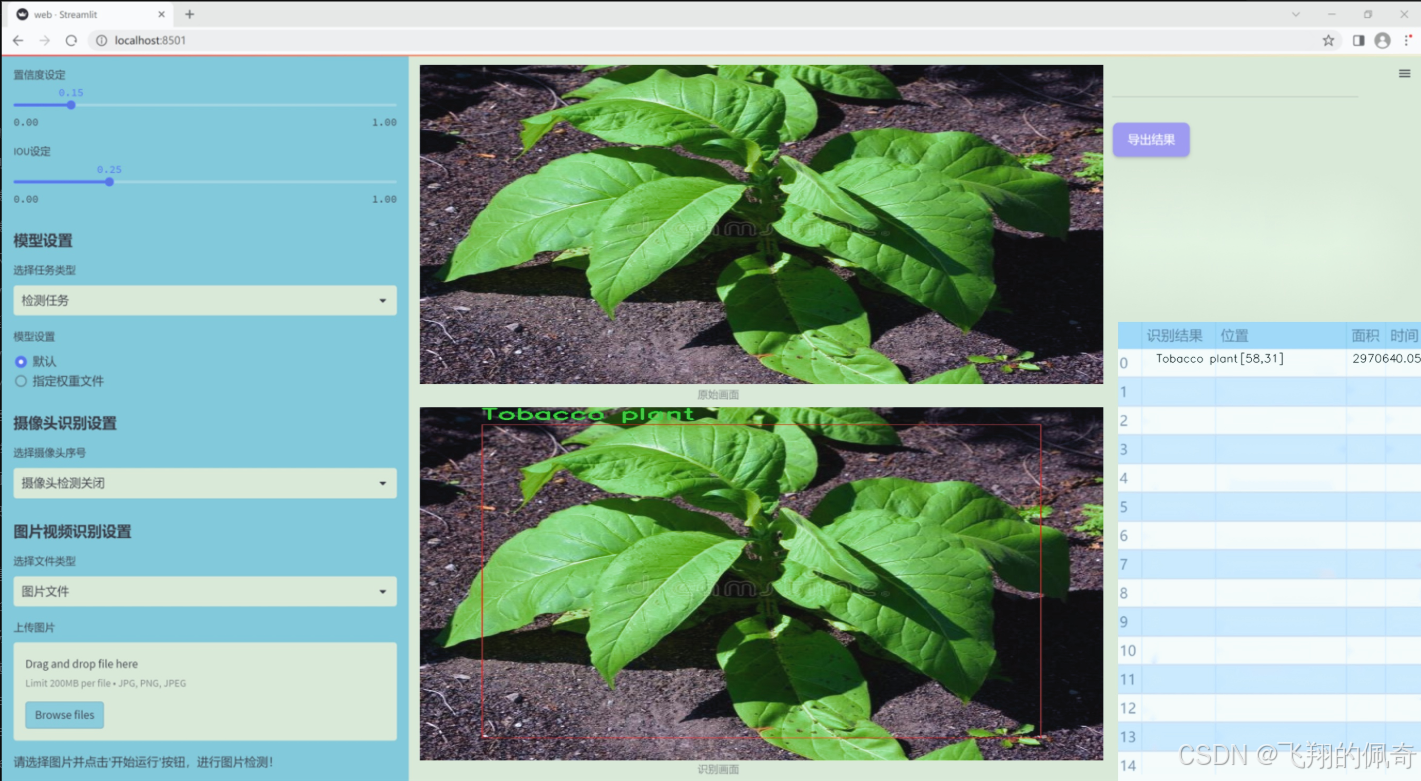
数据集信息
本项目旨在改进YOLOv11模型,以实现高效的烟叶植株计数与分类系统。为此,我们构建了一个专门的数据集,聚焦于植物计数这一主题。该数据集包含两类植物,分别为"烟草植株"和"棉花植株",共计两个类别。这些类别的选择不仅反映了农业生产中的重要性,也为模型的训练提供了丰富的多样性和挑战性。
在数据集的构建过程中,我们采集了大量的图像数据,涵盖了不同生长阶段、不同光照条件以及不同背景下的烟草和棉花植株。这种多样性确保了模型在实际应用中的鲁棒性,能够适应各种环境和条件下的植物识别任务。每张图像都经过精确标注,确保模型能够准确学习到每个类别的特征,从而提高计数和分类的准确性。
此外,数据集的设计还考虑到了现实农业场景中的复杂性,例如植株之间的遮挡、不同植株的生长高度差异等。这些因素都可能影响模型的表现,因此我们在数据集中尽量模拟这些情况,以便训练出更为智能和适应性强的YOLOv11模型。通过这种方式,我们希望能够提升烟叶和棉花植株的自动识别能力,为农业生产提供更为高效的技术支持。
总之,本项目的数据集不仅为YOLOv11模型的训练提供了必要的基础数据,也为后续的研究和应用奠定了坚实的基础。通过不断优化和扩展数据集,我们期望能够推动植物计数与分类技术的发展,为现代农业的智能化进程贡献力量。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from functools import lru_cache
class KAGNConvNDLayer(nn.Module):
def init (self, conv_class, norm_class, conv_w_fun, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1, dropout: float = 0.0, ndim: int = 2):
super(KAGNConvNDLayer, self).init()
# 初始化参数
self.inputdim = input_dim # 输入维度
self.outdim = output_dim # 输出维度
self.degree = degree # 多项式的度数
self.kernel_size = kernel_size # 卷积核大小
self.padding = padding # 填充
self.stride = stride # 步幅
self.dilation = dilation # 膨胀
self.groups = groups # 分组卷积的组数
self.base_activation = nn.SiLU() # 基础激活函数
self.conv_w_fun = conv_w_fun # 卷积权重函数
self.ndim = ndim # 数据的维度(1D, 2D, 3D)
self.dropout = None # Dropout层
# 根据维度选择合适的Dropout层
if dropout > 0:
if ndim == 1:
self.dropout = nn.Dropout1d(p=dropout)
elif ndim == 2:
self.dropout = nn.Dropout2d(p=dropout)
elif ndim == 3:
self.dropout = nn.Dropout3d(p=dropout)
# 检查参数的有效性
if groups <= 0:
raise ValueError('groups must be a positive integer')
if input_dim % groups != 0:
raise ValueError('input_dim must be divisible by groups')
if output_dim % groups != 0:
raise ValueError('output_dim must be divisible by groups')
# 创建基础卷积层和归一化层
self.base_conv = nn.ModuleList([conv_class(input_dim // groups,
output_dim // groups,
kernel_size,
stride,
padding,
dilation,
groups=1,
bias=False) for _ in range(groups)])
self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])
# 多项式权重的形状
poly_shape = (groups, output_dim // groups, (input_dim // groups) * (degree + 1)) + tuple(
kernel_size for _ in range(ndim))
# 初始化多项式权重和beta权重
self.poly_weights = nn.Parameter(torch.randn(*poly_shape))
self.beta_weights = nn.Parameter(torch.zeros(degree + 1, dtype=torch.float32))
# 使用Kaiming均匀分布初始化卷积层权重
for conv_layer in self.base_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
nn.init.kaiming_uniform_(self.poly_weights, nonlinearity='linear')
nn.init.normal_(
self.beta_weights,
mean=0.0,
std=1.0 / ((kernel_size ** ndim) * self.inputdim * (self.degree + 1.0)),
)
def beta(self, n, m):
# 计算beta值,用于Legendre多项式的计算
return (
((m + n) * (m - n) * n ** 2) / (m ** 2 / (4.0 * n ** 2 - 1.0))
) * self.beta_weights[n]
@lru_cache(maxsize=128) # 使用缓存避免重复计算Legendre多项式
def gram_poly(self, x, degree):
# 计算Legendre多项式
p0 = x.new_ones(x.size()) # P0 = 1
if degree == 0:
return p0.unsqueeze(-1)
p1 = x # P1 = x
grams_basis = [p0, p1]
for i in range(2, degree + 1):
p2 = x * p1 - self.beta(i - 1, i) * p0 # 递归计算
grams_basis.append(p2)
p0, p1 = p1, p2
return torch.cat(grams_basis, dim=1) # 将多项式基组合在一起
def forward_kag(self, x, group_index):
# 前向传播函数,处理每个组的输入
basis = self.base_conv[group_index](self.base_activation(x)) # 基础卷积
# 将输入归一化到[-1, 1]范围内
x = torch.tanh(x).contiguous()
if self.dropout is not None:
x = self.dropout(x) # 应用Dropout
grams_basis = self.base_activation(self.gram_poly(x, self.degree)) # 计算Gram多项式基
# 使用卷积权重函数计算输出
y = self.conv_w_fun(grams_basis, self.poly_weights[group_index],
stride=self.stride, dilation=self.dilation,
padding=self.padding, groups=1)
# 归一化并激活输出
y = self.base_activation(self.layer_norm[group_index](y + basis))
return y
def forward(self, x):
# 前向传播,处理整个输入
split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入
output = []
for group_ind, _x in enumerate(split_x):
y = self.forward_kag(_x.clone(), group_ind) # 处理每个组
output.append(y.clone())
y = torch.cat(output, dim=1) # 合并输出
return y代码说明:
KAGNConvNDLayer类:这是一个自定义的卷积层,支持任意维度的卷积(1D、2D、3D),并结合了Legendre多项式的计算。
初始化方法:设置输入输出维度、卷积参数、激活函数等,并初始化卷积层和归一化层。
beta方法:计算用于Legendre多项式的beta值。
gram_poly方法:计算给定度数的Legendre多项式,并使用缓存以提高效率。
forward_kag方法:实现了每个组的前向传播,计算卷积和激活。
forward方法:处理整个输入,按组分割并合并输出。
这个代码实现了一个复杂的卷积层,能够在多个维度上进行卷积操作,并结合了多项式的计算以增强模型的表达能力。
这个程序文件 kagn_conv.py 定义了一系列用于深度学习的卷积层,主要是基于 KAGN(Kochawongwat et al.)方法。文件中包含一个基类 KAGNConvNDLayer 和三个子类 KAGNConv3DLayer、KAGNConv2DLayer 和 KAGNConv1DLayer,分别用于处理三维、二维和一维的卷积操作。
首先,KAGNConvNDLayer 类是一个通用的卷积层实现,它接受多个参数,包括输入和输出维度、卷积核大小、分组数、填充、步幅、扩张率、丢弃率等。构造函数中,首先进行了一些参数的验证,确保分组数是正整数,并且输入和输出维度可以被分组数整除。接着,基于传入的卷积类和归一化类,创建了多个卷积层和归一化层的模块列表。
该类还定义了多项式权重和 beta 权重,并使用 Kaiming 均匀分布初始化这些权重,以便于训练的开始。beta 方法用于计算与 Legendre 多项式相关的 beta 值,而 gram_poly 方法则用于计算 Legendre 多项式的基函数,并使用 LRU 缓存来避免重复计算。
在 forward_kag 方法中,首先对输入进行激活,然后通过基础卷积层进行线性变换。接着,输入被归一化到 -1, 1 的范围,以便进行稳定的 Legendre 多项式计算。然后,计算多项式基函数,并通过自定义的卷积权重函数进行卷积操作,最后进行归一化和激活处理。
forward 方法则将输入分割成多个组,分别通过 forward_kag 方法处理每个组,并将结果拼接在一起。
接下来的三个子类分别实现了三维、二维和一维的卷积层。它们通过调用基类的构造函数,传入相应的卷积类和归一化类,简化了多维卷积层的实现。
整体而言,这个文件实现了一个灵活且功能强大的卷积层,能够处理不同维度的数据,并结合了多项式特征和归一化技术,以提高模型的表达能力和训练效果。
10.3 conv.py
以下是经过简化和注释的核心代码部分,主要保留了卷积模块的实现以及相关的注意力机制模块。
import math
import torch
import torch.nn as nn
def autopad(k, p=None, d=1):
"""自动计算填充以保持输出形状与输入相同。"""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else d \* (x - 1) + 1 for x in k # 实际的卷积核大小
if p is None:
p = k // 2 if isinstance(k, int) else x // 2 for x in k # 自动填充
return p
class Conv(nn.Module):
"""标准卷积层,包含卷积、批归一化和激活函数。"""
default_act = nn.SiLU() # 默认激活函数
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""初始化卷积层,设置输入输出通道、卷积核大小、步幅、填充等参数。"""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) # 卷积层
self.bn = nn.BatchNorm2d(c2) # 批归一化层
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() # 激活函数
def forward(self, x):
"""前向传播:执行卷积、批归一化和激活函数。"""
return self.act(self.bn(self.conv(x)))class ChannelAttention(nn.Module):
"""通道注意力模块。"""
def __init__(self, channels: int) -> None:
"""初始化通道注意力模块,设置基本配置。"""
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True) # 1x1卷积
self.act = nn.Sigmoid() # Sigmoid激活函数
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播:通过卷积和激活函数对输入进行处理。"""
return x * self.act(self.fc(self.pool(x))) # 输入与注意力权重相乘class SpatialAttention(nn.Module):
"""空间注意力模块。"""
def __init__(self, kernel_size=7):
"""初始化空间注意力模块,设置卷积核大小。"""
super().__init__()
assert kernel_size in {3, 7}, "kernel size must be 3 or 7" # 限制卷积核大小
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 卷积层
self.act = nn.Sigmoid() # Sigmoid激活函数
def forward(self, x):
"""前向传播:对输入进行空间注意力处理。"""
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1))) # 输入与注意力权重相乘class CBAM(nn.Module):
"""卷积块注意力模块。"""
def __init__(self, c1, kernel_size=7):
"""初始化CBAM模块,设置输入通道和卷积核大小。"""
super().__init__()
self.channel_attention = ChannelAttention(c1) # 通道注意力
self.spatial_attention = SpatialAttention(kernel_size) # 空间注意力
def forward(self, x):
"""前向传播:依次通过通道注意力和空间注意力。"""
return self.spatial_attention(self.channel_attention(x)) # 先计算通道注意力,再计算空间注意力代码注释说明
autopad: 该函数用于自动计算卷积层的填充,以确保输出的形状与输入相同。
Conv: 这是一个标准的卷积层实现,包含卷积操作、批归一化和激活函数。forward方法实现了数据的前向传播。
ChannelAttention: 该模块实现了通道注意力机制,通过自适应平均池化和1x1卷积来计算通道权重,并与输入相乘以增强特征。
SpatialAttention: 该模块实现了空间注意力机制,通过对输入的均值和最大值进行卷积操作来计算空间权重,并与输入相乘。
CBAM: 该模块结合了通道注意力和空间注意力,依次对输入特征进行处理。
这个程序文件 conv.py 定义了一系列用于卷积操作的模块,主要用于深度学习中的卷积神经网络(CNN)。文件中包含多个类和函数,每个类实现了不同类型的卷积操作或相关功能。
首先,文件导入了必要的库,包括 math、numpy 和 torch,以及 torch.nn,后者是 PyTorch 中用于构建神经网络的模块。all 变量定义了该模块公开的接口,列出了所有可以被外部导入的类。
接下来,定义了一个辅助函数 autopad,用于自动计算卷积操作所需的填充量,以确保输出的形状与输入的形状相同。这个函数根据卷积核的大小、填充和扩张因子来计算填充量。
Conv 类实现了标准的卷积层,包含卷积操作、批归一化和激活函数。构造函数中可以设置输入通道数、输出通道数、卷积核大小、步幅、填充、分组和扩张等参数。forward 方法执行前向传播,依次应用卷积、批归一化和激活函数。
Conv2 类是 Conv 类的简化版本,添加了一个 1x1 的卷积层,以实现更复杂的卷积操作。它重写了 forward 方法,将两个卷积的输出相加后再通过激活函数。
LightConv 类实现了一种轻量级卷积,使用了深度卷积和标准卷积的组合。DWConv 类则实现了深度卷积,适用于处理高维数据。
DSConv 类实现了深度可分离卷积,它将深度卷积和逐点卷积结合在一起,以减少计算量。
DWConvTranspose2d 类实现了深度转置卷积,而 ConvTranspose 类则实现了转置卷积层,支持批归一化和激活函数。
Focus 类用于将空间信息聚焦到通道维度,通过对输入张量进行特定的拼接操作来实现。
GhostConv 类实现了 Ghost 卷积,结合了主要和廉价的操作,以提高特征学习的效率。
RepConv 类实现了一种重复卷积模块,支持训练和推理阶段的不同操作,能够在推理时将多个卷积层融合为一个。
ChannelAttention 和 SpatialAttention 类分别实现了通道注意力和空间注意力机制,能够增强网络对重要特征的关注。
CBAM 类则结合了通道注意力和空间注意力,形成了一个完整的卷积块注意力模块。
最后,Concat 类用于在指定维度上连接多个张量,方便在网络中处理多通道数据。
总体来说,这个文件实现了一系列高效的卷积模块和注意力机制,适用于构建现代卷积神经网络,尤其是在目标检测和图像处理等任务中。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻