文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: F025
架构: vue+flask+neo4j+mysql
亮点:协同过滤推荐算法+知识图谱可视化
支持爬取图书数据,数据超过万条,知识图谱节点几万个
视频介绍
vue+flask+neo4j 图书知识图谱推荐算法可视化系统|全源码带数据库
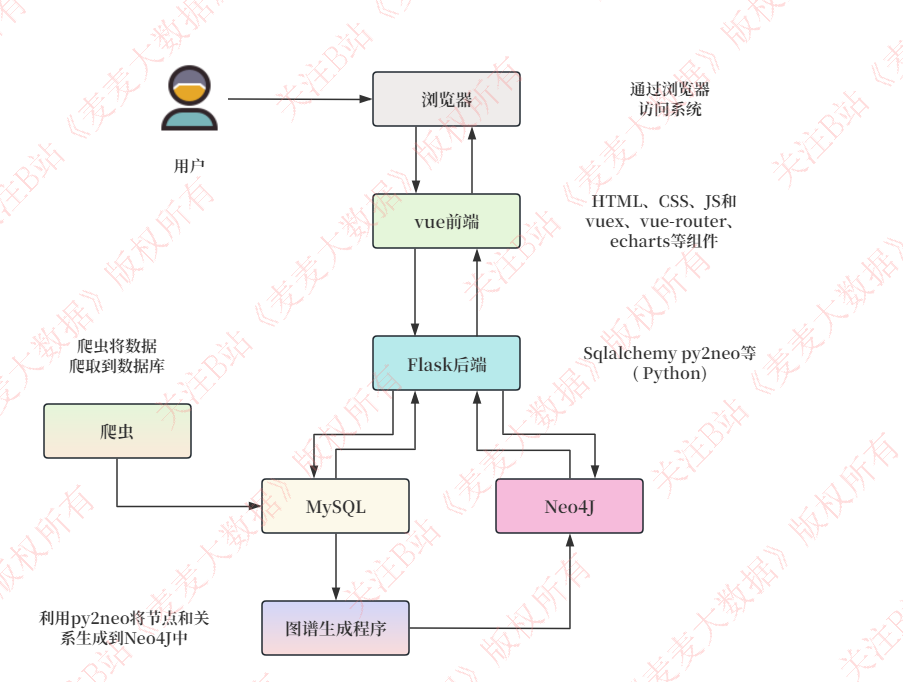
架构说明
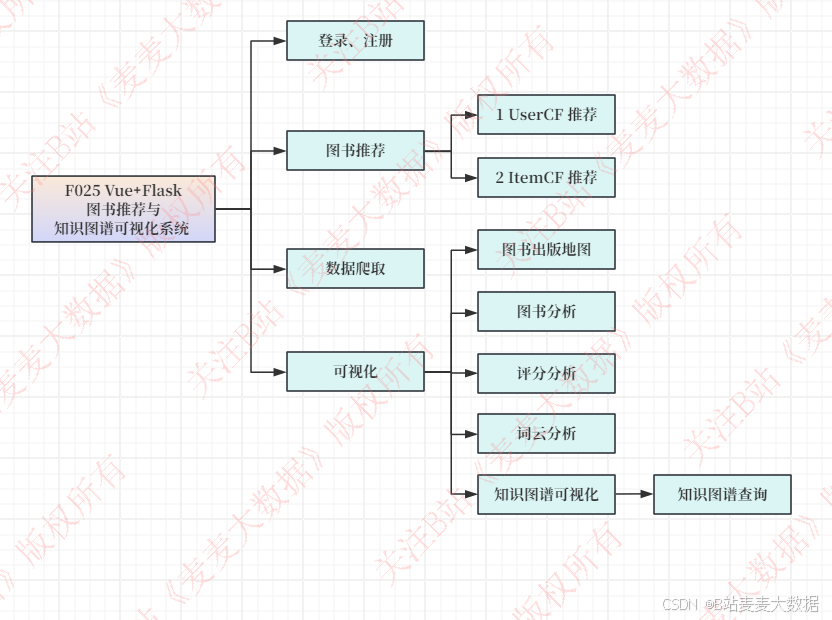
功能模块
系统架构主要分为以下几个部分:用户前端 、后端服务 、数据库 、数据爬取与处理。各部分通过协调工作,实现数据的采集、存储、处理以及展示。具体如下:
1. 用户前端
用户通过浏览器访问系统,前端采用了基于 Vue.js 的技术栈来构建。
- 浏览器:作为用户与系统交互的媒介,用户通过浏览器进行各种操作,如浏览图书、获取推荐等。
- Vue 前端:使用 Vue.js 框架搭建前端界面,包含 HTML、CSS、JavaScript,以及 Vuex(用于状态管理),vue-router(用于路由管理),和 Echarts(用于数据可视化)等组件。前端向后端发送请求并接收响应,展示处理后的数据。
2. 后端服务
后端服务采用 Flask 框架,负责处理前端请求,执行业务逻辑,并与数据库进行交互。
- Flask 后端:使用 Python 编写,借助 Flask 框架处理 HTTP 请求。通过 SQLAlchemy 与 MySQL 进行交互,通过 py2neo 与 Neo4j 进行交互。后端主要负责业务逻辑处理、 数据查询、数据分析以及推荐算法的实现。
3. 数据库
系统使用了两种数据库:关系型数据库 MySQL 和图数据库 Neo4j。
- MySQL:存储从网络爬取的基本数据。数据爬取程序从外部数据源获取数据,并将其存储在 MySQL 中。MySQL 主要用于存储和管理结构化数据。
- Neo4j:存储图谱数据,特别是用户、图书及其关系(如阅读、写、出版等)。通过利用 py2neo 库将 MySQL 中的数据结构化为图节点和关系,再通过图谱生成程序(可能是一个 Python 脚本)将其导入到 Neo4j 中。
4. 数据爬取与处理
数据通过爬虫从外部数据源获取,并存储在 MySQL 数据库中,然后将数据转换为图结构并存储在 Neo4j 中。
- 爬虫:实现数据采集,从网络数据源抓取相关信息。爬取的数据首先存储在 MySQL 数据库中。
- 图谱生成程序:利用 py2neo 将爬取到的结构化数据(如用户、图书、作者、出版社,以及它们之间的关系)从 MySQL 导入到 Neo4j 中。通过构建图谱数据,使得后端能够进行复杂的图查询和推荐计算。
工作流程
- 数据爬取:爬虫程序从外部数据源抓取数据并存储到 MySQL 数据库中。
- 数据处理与导入:图谱生成程序将 MySQL 中的数据转换为图结构并导入到 Neo4j 中,利用 py2neo 与 Neo4j 交互。
- 前后端交互 :
- 用户通过浏览器访问系统,前端用 Vue.js 构建,提供友好的用户界面和交互。
- 前端向 Flask 后端发送请求,获取图书信息或推荐图书。
- 推荐算法:后端在接收请求后,利用 Neo4j 图数据库中的数据和关系进行处理(如推荐计算),并使用 py2neo 库与 Neo4j 交互获取数据结果。
- 数据返回与展示:后端将计算结果返回给前端进行展示,通过 Vue.js 的图表库(如 Echarts)进行数据可视化,让用户得到直观的推荐结果和分析信息。
小结
这套系统通过整合爬虫、关系型数据库、图数据库,以及前后端的协调配合,实现了数据的高效采集、存储、处理、推荐和展示。从用户体验的角度,系统能够提供高度个性化的推荐,并通过图形化的方式呈现数据分析结果。
功能介绍
0 图谱构建
利用python读取数据并且构建图谱到neo4j中
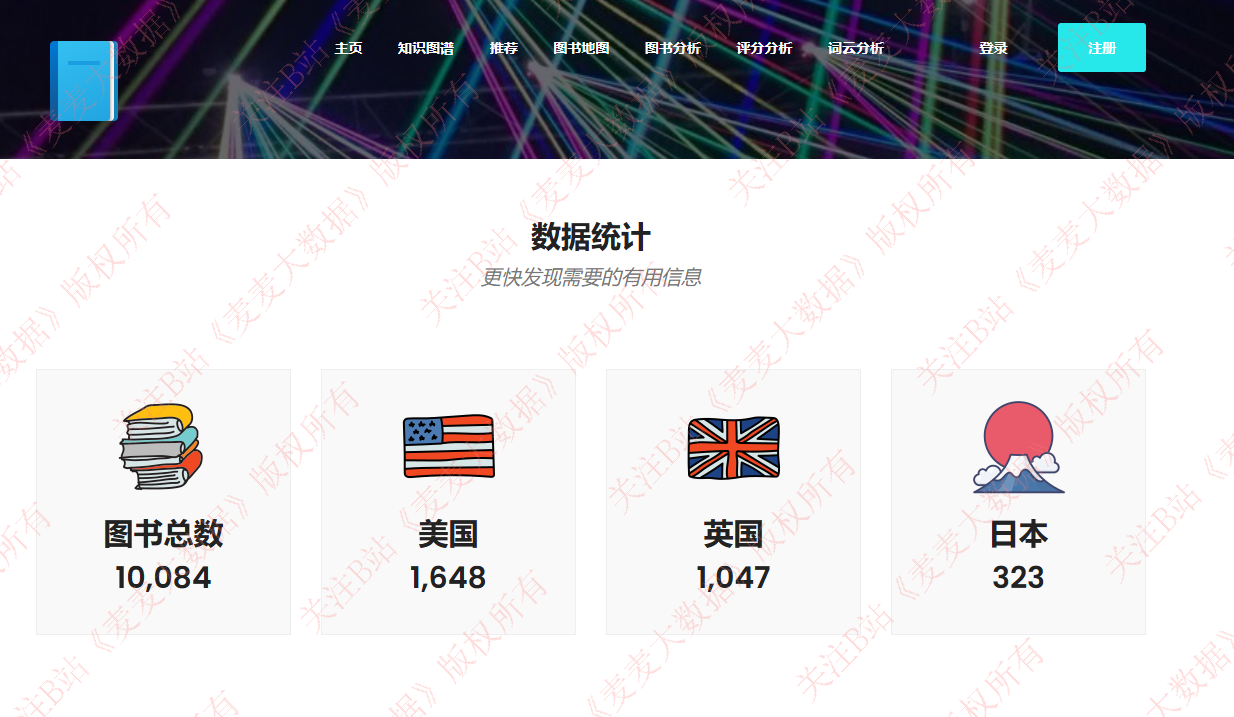
1 系统主页,统计页面
2 知识图谱
支持可视化

支持模糊搜索,比如搜索法国作家 加缪

3 推荐算法
没有登录无法推荐
两种协同过滤推荐算法推荐
usercf + itemcf

点击可以进入图书详情页面(可以查看 名称、作者、系列、图片、装帧、用户给图书的评分)

支持使用评分控件进行评分
4 可视化分析
分为4个页面
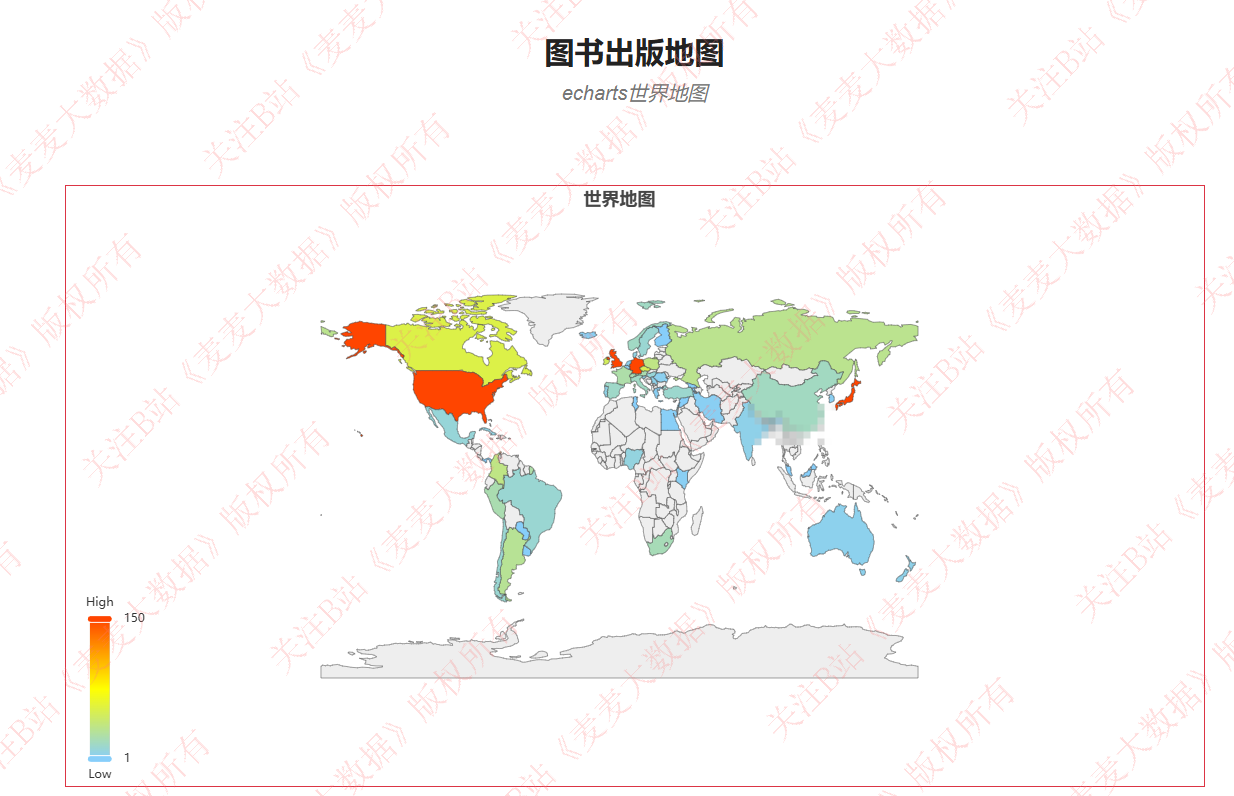
图书出版地图分析
图书分析
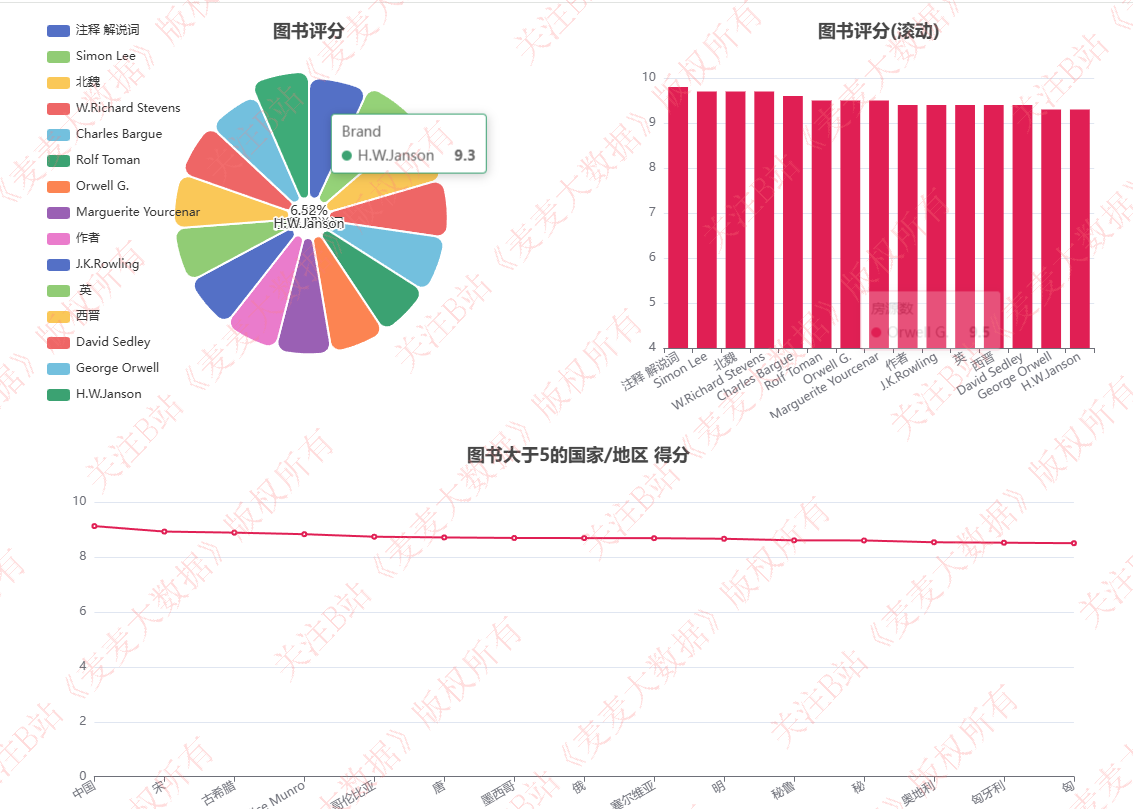
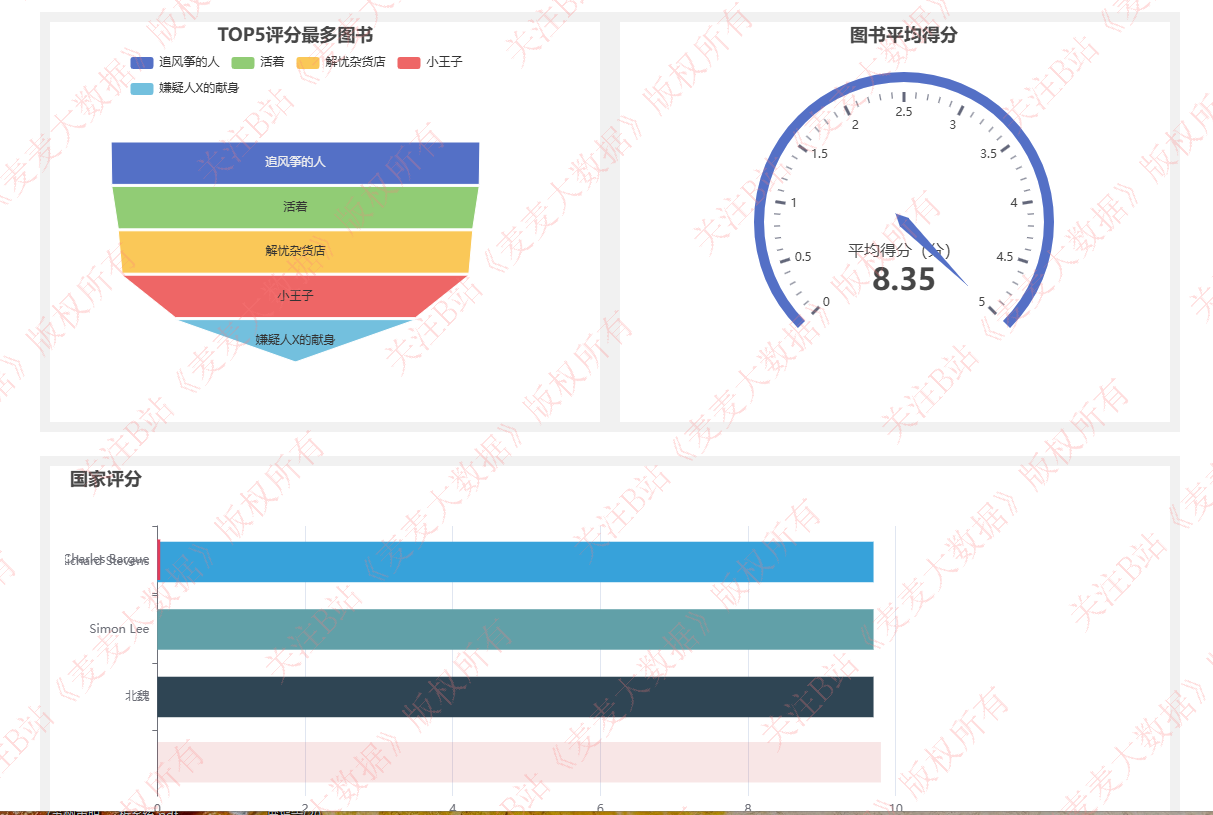
图书评分分析
图书词云分析

5 登录与注册
支持登录与注册
算法介绍
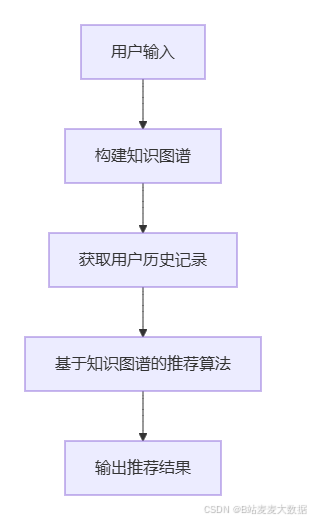
知识图谱构建:通过读取图书数据,构建图书、作者、类别等实体,并建立它们之间的关系。例如,图书与作者之间的"AUTHORED_BY"关系,图书与类别之间的"BELONGS_TO"关系。
推荐算法:基于用户的历史阅读记录,通过遍历知识图谱,找到与用户兴趣相似的图书。具体可以通过计算图书间的相似性、路径发现等方法。
推荐结果输出:根据算法计算的推荐结果,输出用户可能感兴趣的图书列表。
流程图
核心代码
python
from py2neo import Graph, Node, Relationship
import numpy as np
from collections import defaultdict
# 1. 知识图谱构建
def build_knowledge_graph():
# 连接数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 创建节点和关系
books = {
"Book1": {"author": "AuthorA", "category": "CategoryX"},
"Book2": {"author": "AuthorB", "category": "CategoryY"},
# ... 其他书籍数据
}
for title, info in books.items():
book_node = Node("Book", name=title)
graph.create(book_node)
# 创建作者关系
author_node = Node("Author", name=info["author"])
graph.create(Relationship(book_node, "AUTHORED_BY", author_node))
# 创建类别关系
category_node = Node("Category", name=info["category"])
graph.create(Relationship(book_node, "BELONGS_TO", category_node))
return graph
# 2. 推荐算法
def get_recommendations(graph, user_history):
# 基于知识图谱的推荐逻辑
# 1. 提取用户历史偏好
# 2. 找到相似的实体
# 3. 生成推荐
recommended_books = []
# ... 具体推荐算法实现
return recommended_books
# 3. 使用示例
if __name__ == "__main__":
# 构建知识图谱
kg_graph = build_knowledge_graph()
# 假设用户历史记录
user_history = ["Book1", "Book3"]
# 获取推荐
recommendations = get_recommendations(kg_graph, user_history)
print("推荐的图书:", recommendations)