🔄 什么是循环依赖?
循环依赖指的是当两个或多个Spring的bean相互依赖,而这些bean都需要被实例化来满足依赖,导致Spring容器无法顺利完成Bean的初始化过程。具体来说,A依赖B,B又依赖A,导致一个死循环。Spring必须处理这种依赖关系,避免造成死锁或失败。
🛠️ Spring的解决方案
Spring容器如何解决这个问题呢?Spring采用了两种策略来解决循环依赖问题:
🗂️ Setter注入 + 三级缓存
1️⃣ 什么是三级缓存?
在 Spring 中,Bean 的创建分为三个阶段:实例化、属性注入、初始化。
- 一级缓存(singletonObjects) :存储完全初始化完成的 Bean。
- 二级缓存(earlySingletonObjects) :存储已实例化但未完成属性注入的"半成品"对象。
- 三级缓存(singletonFactories) :存储创建 Bean 的工厂,当需要时生成"半成品"。
三级缓存的目的是通过延迟暴露"半成品"对象,打破循环依赖。
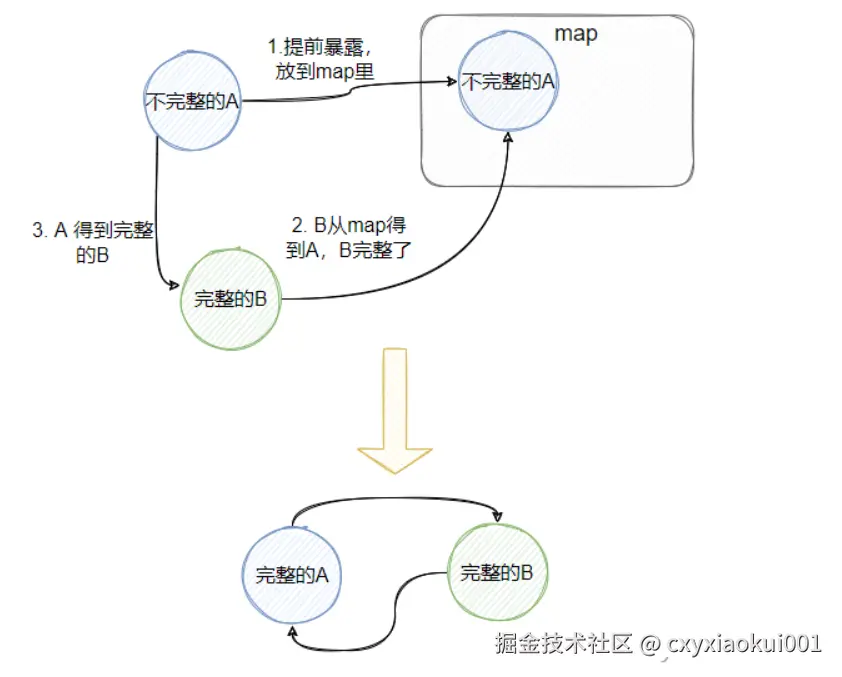
2️⃣ 解决循环依赖的完整流程
假设有 A 依赖 B,B 又依赖 A 的场景:
🔍 创建过程分为以下几个关键步骤:
-
实例化 Bean A
- Spring 首先实例化 A(通过构造函数创建对象)。
- 然后,将 A 的工厂(ObjectFactory)放入三级缓存(singletonFactories)。此时 A 是个"半成品"。
-
处理 A 的依赖:注入 B
- A 需要注入 B,Spring 开始创建 B。
- B 还没初始化,于是 B 的工厂也被放入三级缓存。
-
处理 B 的依赖:注入 A
- B 需要注入 A。此时 Spring 先检查一级缓存(完整对象),没找到。
- 检查二级缓存(半成品),还是没找到。
- 最后到三级缓存,通过 A 的工厂生成一个"半成品 A"。
- 将生成的"半成品 A"存入二级缓存(earlySingletonObjects),并注入到 B 中。
-
B 初始化完成
- 完成 B 的属性注入和初始化,将 B 移入一级缓存。
-
A 初始化完成
- A 获取到完整的 B 后,完成自身的属性注入和初始化,移入一级缓存。
整个流程逻辑图如下:
css
1. 实例化 A,放入三级缓存(工厂)。
2. A -> 依赖 B,开始创建 B。
3. 实例化 B,放入三级缓存(工厂)。
4. B -> 依赖 A,从三级缓存生成"半成品 A"。
5. 完成 B 的初始化,放入一级缓存。
6. A 注入完整 B,完成初始化,放入一级缓存。3️⃣ 核心代码解析
以下是 Spring 内部处理缓存的简化逻辑:
java
// 获取单例 Bean 的方法
public Object getSingleton(String beanName) {
// 1. 从一级缓存获取完整的 Bean
Object singleton = singletonObjects.get(beanName);
if (singleton == null) {
// 2. 从二级缓存获取"半成品" Bean
singleton = earlySingletonObjects.get(beanName);
if (singleton == null) {
// 3. 从三级缓存获取工厂并生成 Bean
ObjectFactory<?> factory = singletonFactories.get(beanName);
if (factory != null) {
singleton = factory.getObject();
earlySingletonObjects.put(beanName, singleton);
singletonFactories.remove(beanName);
}
}
}
return singleton;
}🌟注意
1️⃣ 为什么只支持单例循环依赖?
因为原型(Prototype)模式每次都创建新对象,不能复用"半成品"。而单例对象可以复用同一个"半成品",这才是循环依赖能解决的关键!
2️⃣为什么需要三级缓存,二级不够吗?关键在于AOP代理!
java
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}Copy to clipboardErrorCopied场景1:没有AOP代理(只有普通循环依赖)
在这种情况下,理论上二级缓存是够用的💪。
- 创建A,实例化后直接把原始对象A放入二级缓存➡️。
- 创建B,需要A,从二级缓存拿到A的原始对象🙋♂️。
- B创建完成,A用B创建自己,最终大家都创建成功🎉。
但Spring的设计是统一的,不能因为某些场景简单就采用不同的架构。
🔥场景2:有AOP代理(这才是关键)
假设A需要被AOP代理(比如有@Transactional注解)。
问题在于:代理对象生成的时机。💥
Spring AOP代理对象的创建最佳时机是在Bean的初始化之后(在BeanPostProcessor的后置处理中)。但如果存在循环依赖,B在创建过程中就需要A,而此时A还没有走到初始化那一步😭。
如果只有二级缓存:
- 创建A,实例化后,我们只能把A的原始对象放入二级缓存。
- 创建B,需要A,从二级缓存拿到A的原始对象并注入给B。
- B创建完成后,A继续后续流程。当A走到初始化后,Spring发现A需要被代理🚀,于是为A的原始对象生成一个代理对象。
- 最终,A的代理对象被放入一级缓存。
🚨这就导致了严重的不一致问题🚨:
- B里面持有的A,是A的原始对象。
- 而Spring容器一级缓存里和业务代码实际拿到的是A的代理对象。
这违背了单例的原则!同一个Bean(A)在容器中有了两个不同的实例😱(一个原始对象在B里,一个代理对象在容器里),这会导致事务等AOP功能在B调用A时完全失效,是一个致命的Bug💀。
🦸♂️三级缓存如何优雅解决这个问题?
三级缓存的精髓在于:我不提前给你对象,我给你一个"造物工厂"🏭
流程如下:
- 创建A,实例化后,将一个ObjectFactory (lambda表达式,能创建A的早期引用)放入三级缓存:
java
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));- 创建B,发现依赖A → 调用
getSingleton(A)。
👉 Spring 查一级 ❌ → 查二级 ❌ → 查三级 ✅
👉
🏭 找到A的生产工厂!
-
Spring发现A在三级缓存中有ObjectFactory → 调用它,执行
getEarlyBeanReference()。-
此时判断A是否需要代理:
- 需要 → 返回代理对象
- 不需要 → 返回原始对象
-
将结果放入二级缓存,并从三级缓存移除。
-
-
B拿到A的引用。
-
A继续创建,完成后放入一级缓存中,并清理二级缓存中的早期引用 🧹。
🗂️构造器注入 + @Lazy注解
@Lazy 注解可以让 Spring 稍微等一等,延迟对象的创建。它的作用就是让 Spring 不急着立刻创建对象,而是等到真正需要的时候才去创建。
当你在一个对象上使用 @Lazy ,Spring 会选择不立刻创建它,而是等到这部分真正被调用的时候才去创建。这样,Spring 就能够打破这两个对象相互等待的死循环,最终成功地创建这两个对象。
注意事项:
虽然 @Lazy 注解能帮你解决循环依赖问题,但实际上,还是建议尽量避免循环依赖 。因为如果经常出现这种情况,代码的逻辑会变得 复杂,也不容易维护。所以,最好从设计上尽量避免这种问题。
@Lazy 的魔力在哪里?
@Lazy 是 Spring 提供的一种延迟加载机制,意思是"等到用我的时候再初始化,不着急"。这就像告诉 Spring:"别急着建这个 Bean,等真需要再搞定。"
实战演示:用 @Lazy 解决构造器循环依赖 🛠️
假设我们有两个类 A 和 B,它们通过构造器互相依赖:
java
@Component
public class A {
private final B b;
@Autowired
public ClassA(@Lazy B b) { // 使用 @Lazy,让 classB 延迟初始化
this.b = b;
}
}
@Component
public class B {
private final A a;
@Autowired
public B(A a) {
this.a = a;
}
}🔍 关键点:
A创建时,Spring 不会急着实例化B。- 当
A真正需要用到B时,Spring 才去初始化B。 - 这样就避开了循环依赖的"死锁"问题。
使用 @Lazy 的注意事项 ⚠️
虽然 @Lazy 方便,但不能滥用!过度依赖延迟加载,可能会带来以下问题:
- 意外的初始化时机: Bean 的创建可能在某些逻辑中突然发生,难以预测。
- 性能开销: 如果延迟加载的 Bean 被频繁调用,性能可能受到影响。
- 设计隐患: 循环依赖本身是代码设计上的缺陷,建议优先优化代码结构。
@Lazy 的常见应用场景
-
类级别延迟: Bean 初始化比较耗时时,使用
@Lazy提升系统启动速度。java@Component @Lazy public class HeavyBean { public HeavyBean() { System.out.println("HeavyBean 初始化了!"); } } -
注入延迟: 某些依赖加载会导致性能瓶颈,可以使用
@Lazy注解。java@Component public class SomeService { private final HeavyBean heavyBean; @Autowired public SomeService(@Lazy HeavyBean heavyBean) { this.heavyBean = heavyBean; } }
🤹 小总结
- Spring 的三级缓存机制,通过提前暴露"半成品对象",巧妙地解决了单例循环依赖的问题,同时支持 AOP 等复杂场景。
@Lazy是解决构造器循环依赖的好工具,但别过度使用。- 循环依赖本质是设计问题,优先通过优化代码结构来解决。