点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月13日更新到: Java-147 深入浅出 MongoDB 分页查询详解:skip() + limit() + sort() 实现高效分页、性能优化与 WriteConcern 写入机制全解析 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Flink 状态存储
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
- KeyedState
- Operator State

上节进度
上节我们到了: 使用ManageOperatorState (这里以及后续放到下一篇:大数据-127 Flink)
接下来我们继续上节的内容
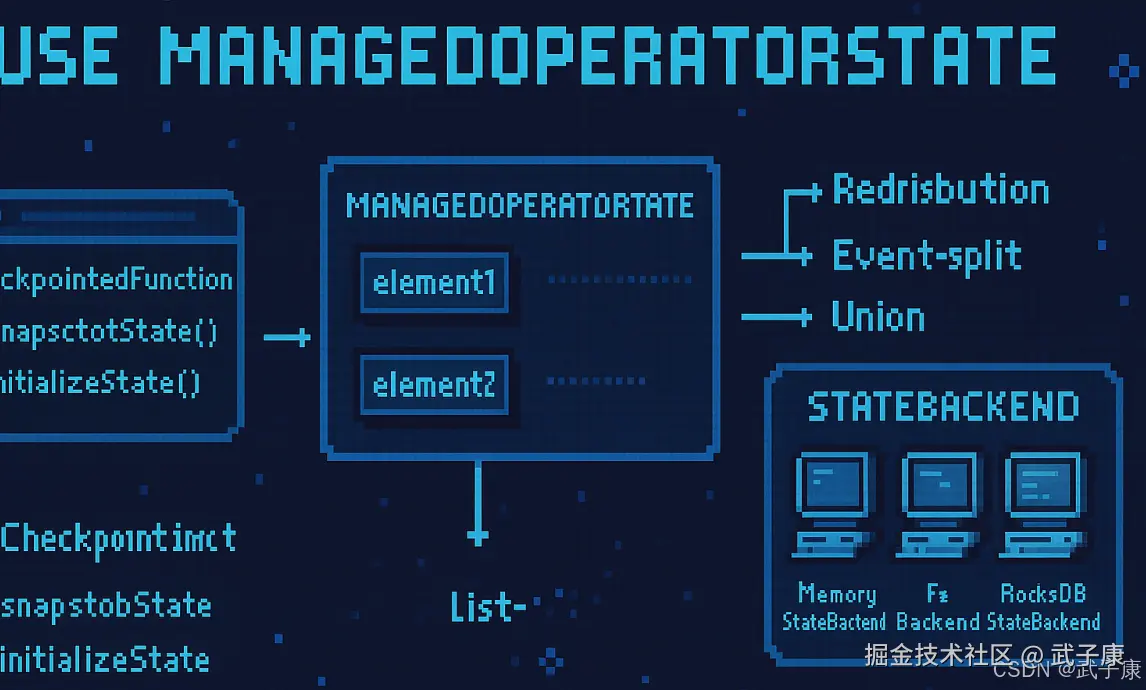
使用ManageOperatorState
我们可以通过实现CheckpointedFunction或ListCheckpointed接口来使用 ManagedOperatorState。 CheckpointFunction CheckpointFunction接口提供了访问 non-keyed state的方法,需要实现如下两个方法:
shell
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;进行Checkpoint时会调用snapshotState(),用户自定义函数化时会调用 initializeState(),初始化包括第一次自定义函数初始化和从之前的Checkpoint恢复。因此 initializeState(),不仅是定义不同的状态类型初始化的地方,也需要包括状态恢复的逻辑。 当前,ManagedOperatorState以list的形式存在,这些状态是一个可序列化对象的集合List,彼此独立,方便在改变后进行状态的重新分派,换句话说,这些对象是重新分配non-keyed state的最新粒度,根据状态不同访问方式,有如下几种重新分配的模式:
- Event-split redistribution:每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成,当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。比如说,算子A的并发读为1,包含两个元素element1和element2,当并发增加为2时,element1会被分发到并发0上,element2会被分发到并发1上。
- Union redistribution:每个算子保存一个列表形式的状态集合,整个状态由所有列表拼接而成,当作业恢复或重新分配时,每个算子都将获得所有的状态数据。
ListCheckpointed ListCheckpointed 接口是 CheckpointedFunction的精简版,仅支持 even-split redistribution 的list state,同样需要实现下面两个方法:
java
List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
void restoreState(List<T> state) throws Exception;snapshotState()需要返回一个将写入到checkpoint的对象列表,restoreState则需要处理恢复回来的对象列表,如果状态不可切分,则可以在snapshotState()中返回,Collections.singletonList(MY_STATE)。
StateBackend 如何保存
上面我们介绍了三种 StateBackend:
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
 在Flink的实际实现中,对于同一种StateBackend,不同的State在运行时会有细分的StateBackend托管,例如:MemoryStateBackend,就有DefaultOperatorStateBackend管理OperatorState,HeapKeyedStateBackend管理KeyedState。
在Flink的实际实现中,对于同一种StateBackend,不同的State在运行时会有细分的StateBackend托管,例如:MemoryStateBackend,就有DefaultOperatorStateBackend管理OperatorState,HeapKeyedStateBackend管理KeyedState。
我们看到MemoryStateBackend和FsStateBackend对于KeyedState和OperatorState的存储都符合我们之前的理解,运行时State数据保存于内存,checkpoint的保存位置需要注意下,并不是在RocksDB中,而是通过DefaultOperatorStateBackend保存于TaskManager内存。创建的源码如下:
java
// RocksDBStateBackend.java
// 创建 keyed statebackend
public <K> AbstractKeyedStateBackend<K> createKeyedStateBackend(...){
...
return new RocksDBKeyedStateBackend<>(
...);
}
// 创建 Operator statebackend
public OperatorStateBackend createOperatorStateBackend(
Environment env, String operatorIdentifier) throws Exception {
//the default for RocksDB; eventually there can be a operator state
backend based on RocksDB, too.
final boolean asyncSnapshots = true;
return new DefaultOperatorStateBackend(
...);
}源码中也标注了,未来会提供基于RocksDB存储的OperatorState,所以当前即使使用RocksDBStateBackend,OperatorState也会超过内存限制。
Operator State 在内存中对应两种数据结构: 数据结构1:ListState 对应的实际实现类为 PartitionableListState,创建并注册的代码如下:
java
// DefaultOperatorStateBackend.java
private <S> ListState<S> getListState(...){
partitionableListState = new PartitionableListState<>(
new RegisteredOperatorStateBackendMetaInfo<>(
name,
partitionStateSerializer,
mode));
registeredOperatorStates.put(name, partitionableListState);
}PartitionableListState中通过ArrayList来保存State数据:
java
// PartitionableListState.java
/**
* The internal list the holds the elements of the state
*/
private final ArrayList<S> internalList;数据结构2:BroadcastState 对应的实际实现类为 HeapBroadcastState 创建并注册的代码如下:
java
public <K, V> BroadcastState<K, V> getBroadcastState(...) {
broadcastState = new HeapBroadcastState<>(
new RegisteredBroadcastStateBackendMetaInfo<>(
name,
OperatorStateHandle.Mode.BROADCAST,
broadcastStateKeySerializer,
broadcastStateValueSerializer));
registeredBroadcastStates.put(name, broadcastState);
}HeapBroadcastState中通过HashMap来保存State数据:
java
/**
* The internal map the holds the elements of the state.
*/
private final Map<K, V> backingMap;
HeapBroadcastState(RegisteredBroadcastStateBackendMetaInfo<K, V> stateMetaInfo) {
this(stateMetaInfo, new HashMap<>());
}配置StateBackend
我们知道Flink提供了三个StateBackend,那么如何配置使用某个StateBackend呢?默认的配置在conf/flink-conf.yaml文件中 state.backend 指定,如果没有配置该值,就会使用 MemoryStateBackend,默认的是StateBackend可以被代码中的配置覆盖。
Per-job设置
我们可以通过StreamExecutionEnvironment设置:
shell
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new
FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));如果想使用RocksDBStateBackend,你需要将相关依赖加入你的Flink中:
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>默认状态后端设置详解
在Apache Flink中,如果没有在程序中显式指定状态后端(StateBackend),系统将自动采用配置文件中的默认设置。具体配置路径为conf/flink-conf.yaml文件中的state.backend参数。这个参数支持以下三种主要配置选项,每种配置对应不同的状态后端实现:
-
JobManager
对应
MemoryStateBackend实现,这是最基础的存储方式。- 状态数据存储在JobManager的内存中
- 检查点数据会存储在JobManager的内存中(默认)或指定的文件系统路径
- 典型应用场景:本地测试、小规模状态作业
- 示例配置:
state.backend: jobmanager
-
FileSystem
对应
FsStateBackend实现,适合生产环境使用。- 工作状态存储在TaskManager的内存中
- 检查点数据持久化到分布式文件系统(如HDFS、S3等)
- 支持大状态存储,但总大小受限于可用内存
- 典型配置示例:
yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:8020/flink/checkpoints- RocksDB
对应RocksDBStateBackend实现,适合超大规模状态作业。- 将工作状态存储在本地RocksDB实例中
- 检查点数据持久化到分布式文件系统
- 支持状态大小超过可用内存的情况
- 需要额外配置RocksDB原生库依赖
- 典型配置示例:
yaml
state.backend: rocksdb
state.checkpoints.dir: hdfs://namenode:8020/flink/checkpoints
state.backend.rocksdb.localdir: /mnt/flink/rocksdb实际生产环境中,建议根据作业特点选择合适的状态后端。对于需要高可用性的场景,还应该配置state.checkpoints.dir参数指定可靠的分布式存储路径。此外,在Flink 1.13及以上版本,推荐使用新的HashMapStateBackend和EmbeddedRocksDBStateBackend作为替代方案。
开启Checkpoint
开启CheckPoint后,StateBackend管理的TaskManager上的状态数据才会被定期备份到JobManager或外部存储,这些状态数据在作业失败恢复时会用到。我们可以通过以下代码开启和配置CheckPoint:
java
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
//env.getConfig().disableSysoutLogging();
//每 30 秒触发一次 checkpoint,checkpoint 时间应该远小于(该值 + MinPauseBetweenCheckpoints),否则程序会一直做checkpoint,影响数据处理速度
env.enableCheckpointing(30000); // create a checkpoint every 30 seconds
// set mode to exactly-once (this is the default)
// flink 框架内保证 EXACTLY_ONCE
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// make sure 30 s of progress happen between checkpoints
// 两个 checkpoints之间最少有 30s 间隔(上一个checkpoint完成到下一个checkpoint开始,默认 为0,这里建议设置为非0值)
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000);
// checkpoints have to complete within one minute, or are discarded
// checkpoint 超时时间(默认 600 s)
env.getCheckpointConfig().setCheckpointTimeout(600000);
// allow only one checkpoint to be in progress at the same time
// 同时只有一个checkpoint运行(默认)
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// enable externalized checkpoints which are retained after job cancellation
// 取消作业时是否保留 checkpoint (默认不保留)
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// checkpoint失败时 task 是否失败( 默认 true, checkpoint失败时,task会失败)
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);
// 对 FsStateBackend 刷出去的文件进行文件压缩,减小 checkpoint 体积
env.getConfig().setUseSnapshotCompression(true);FsStateBackend 和 RocksDBStateBackend CheckPoint完成后最终保存到下面的目录:
shell
hdfs:///your/checkpoint/path/{JOB_ID}/chk-{CHECKPOINT_ID}/JOB_ID是应用的唯一ID,CHECK_POINT_ID 是每次 CheckPoint时自增的数字ID,我们可以从备份的CheckPoint数据恢复当时的作业状态。
shell
flink-1x.x/bin/flink run -s hdfs:///your/checkpoint/path/{JOB_ID}/chk-{CHECKPOINT_ID}/ path/to//your/jar我们可以实现 CheckpointedFunction 方法,在程序初始化的时候修改状态:
java
public class StatefulProcess extends KeyedProcessFunction<String, KeyValue, KeyValue> implements CheckpointedFunction {
ValueState<Integer> processedInt;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
@Override
public void processElement(KeyValue keyValue, Context context,
Collector<KeyValue> collector) throws Exception {
try{
Integer a = Integer.parseInt(keyValue.getValue());
processedInt.update(a);
collector.collect(keyValue);
}catch(Exception e){
e.printStackTrace();
}
}
@Override
public void initializeState(FunctionInitializationContext
functionInitializationContext) throws Exception {
processedInt = functionInitializationContext.getKeyedStateStore().getState(new ValueStateDescriptor<>("processedInt", Integer.class));
if(functionInitializationContext.isRestored()){
//Apply logic to restore the data
}
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
processedInt.clear();
}
}
```