
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈大数据技术原理与应用 ⌋ ⌋ ⌋专栏系统介绍大数据的相关知识,分为大数据基础篇、大数据存储与管理篇、大数据处理与分析篇、大数据应用篇。内容包含大数据概述、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、MapReduce、Hadoop再探讨、数据仓库Hive、Spark、流计算、Flink、图计算、数据可视化,以及大数据在互联网领域、生物医学领域的应用和大数据的其他应用。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/BigData_principle_application。
文章目录
一、数据模型概述
HBase 是一个稀疏、多维度、排序的映射表,这张表的索引包括行键、列族、列限定符和时间戳。每个值是一个未经解释的字符串,没有数据类型。用户在表中存储数据,每一行都有一个可排序的行键和任意多的列。表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起。列族支持动态扩展,可以很轻松地添加一个列族或列,无须预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换。由于同一张表里面的每一行数据都可以有截然不同的列,因此对于整个映射表的每行数据而言,有些列的值是空的,所以说 HBase 是稀疏的。
在 HBase 中执行更新操作时,并不会删除数据的旧的版本,而是生成一个新的版本,旧的版本仍然保留,HBase 可以对允许保留的版本的数量进行设置。客户端可以选择获取距离某个时间最近的版本,或者一次获取所有版本。如果在查询的时候不提供时间戳,那么会返回距离现在最近的那一个版本的数据,因为在存储的时候,数据会按照时间戳排序。HBase 提供了两种数据版本回收方式:一是保存数据的最后 n 个版本;二是保存最近一段时间内的版本(如最近 7 天)。
二、数据模型的相关概念
HBase 实际上就是一个稀疏、多维、持久化存储的映射表,它采用行键(Row Key)、列族(Column Family)、列限定符(Column Qualifier)和时间戳(Timestamp)进行索引,每个值都是未经解释的字节数组 byte\[\]。下面具体介绍 HBase 数据模型的相关概念。
(一)表
HBase 采用表来组织数据,表由行和列组成,列划分为若干个列族。
(二)行
每个 HBase 表都由若干行组成,每个行由行键(Row Key)来标识。访问表中的行只有 3 种方式:通过单个行键访问;通过一个行键的区间来访问;全表扫描。行键可以是任意字符串(最大长度是 64 KB,实际应用中长度一般为 10~100 Byte)。在 HBase 内部,行键保存为字节数组。存储时,数据按照行键的字典序存储。在设计行键时,要充分考虑这个特性,将经常一起读取的行存储在一起。
(三)列族
一个 HBase 表被分组成许多"列族"的集合,它是基本的访问控制单元。列族需要在表创建时就定义好,数量不能太多(HBase 的一些缺陷使得列族的数量只限于几十个),而且不能频繁修改。存储在一个列族当中的所有数据,通常都属于同一种数据类型,这通常意味着数据具有较高的压缩率。表中的每个列都归属于某个列族,数据可以被存放到列族的某个列下面,但是在把数据存放到这个列族的某个列下面之前,必须首先创建这个列族。在创建完列族以后,就可以使用同一个列族当中的列。列名都以列族作为前缀。例如,courses:history 和 courses:math 这两个列都属于 courses 这个列族。在 HBase 中,访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,我们可以借助列族上的控制权限帮助实现特定的目的。比如,我们可以允许一些应用能够向表中添加新的数据,而另一些应用只被允许浏览数据。HBase 列族还可以被配置成支持不同类型的访问模式。比如,一个列族也可以被设置成放入内存当中,以消耗内存为代价,从而换取更好的响应性能。
(四)列限定符
列族里的数据通过列限定符(或列)来定位。列限定符不用事先定义,也不需要在不同行之间保持一致。列限定符没有数据类型,总被视为字节数组 byte\[\]。
(五)单元格
在 HBase 表中,通过行键、列族和列限定符确定一个"单元格"(Cell)。单元格中存储的数据没有数据类型,总被视为字节数组 byte\[\]。每个单元格中可以保存一个数据的多个版本,每个版本对应一个不同的时间戳。
(六)时间戳
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。每次对一个单元格执行操作(新建、修改、删除)时,HBase 都会隐式地自动生成并存储一个时间戳。时间戳一般是 64 位整型数据,可以由用户自己赋值(自己生成唯一时间戳可以避免应用程序中出现数据版本冲突),也可以由 HBase 在数据写入时自动赋值。一个单元格的不同版本根据时间戳降序存储,这样,最新的版本可以被最先读取。
下面以一个实例来阐释 HBase 的数据模型。图1是一张用来存储学生信息的 HBase 表,学号作为行键来唯一标识每个学生,表中设计了列族 Info 来保存学生相关信息,列族 Info 中包含 3个列---name、major 和 email,分别用来保存学生的姓名、专业和电子邮件信息。学号为"201505003"的学生存在两个版本的电子邮件地址,时间戳分别为 ts1=1174184619081 和 ts2=1174184620720,时间戳较大的版本的数据是最新的数据。
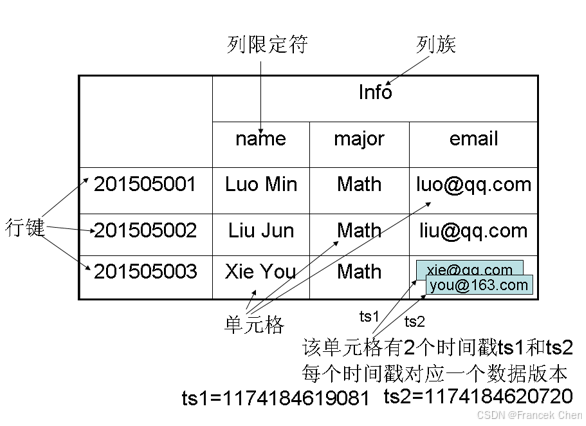
图1 HBase数据模型的一个实例
三、数据坐标
HBase 使用坐标来定位表中的数据,也就是说,每个值都通过坐标来访问。对于我们熟悉的关系数据库而言,数据定位可以理解为采用"二维坐标",即根据行和列就可以确定表中一个具体的值。但是,HBase 中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此可以视为一个"四维坐标",即"行键", "列族", "列限定符", "时间戳"。
例如,在图1中,由行键"201505003"、列族"Info"、列限定符"email"和时间戳"1174184619081"(ts1) 这4个坐标值确定的单元格 "201505003", "Info", "email", "1174184619081",里面存储的值是"xie@qq.com";由行键"201505003"、列族"Info"、列限定符"email"和时间戳"1174184620720"(ts2)这 4 个坐标值确定的单元格"201505003", "Info", "email", "1174184620720",里面存储的值是"you@163.com"。如果把所有坐标看成一个整体,视为"键",把四维坐标对应的单元格中的数据视为"值",那么,HBase 可以看成一个键值数据库(见表1)。
表1 HBase可以被视为一个键值数据库
| 键 | 值 |
|---|---|
| "201505003", "Info", "email", 1174184619081 | "xie@qq.com" |
| "201505003", "Info", "email", 1174184620720 | "you@163.com" |
四、概念视图
在 HBase 的概念视图中,一个表可以视为一个稀疏、多维的映射关系。表2就是 HBase 存储数据的概念视图,它是一个存储网页的 HBase 表的片段。行键是一个反向 URL(如com.baidu.www),之所以这样存放,是因为 HBase 是按照行键的字典序来排序存储数据的,采用反向 URL 的方式,可以让来自同一个网站的数据内容都保存在相邻的位置,在按照行键的值进行水平分区时,就可以尽量把来自同一个网站的数据划分到同一个分区(Region)中。列族 contents 用来存储网页内容;列族 anchor 包含了任何引用这个页面的锚链接文本。可以采用"四维坐标"来定位单元格中的数据,比如在这个实例表中,四维坐标"com.baidu.www","anchor","anchor: xmu.edu.cn",t5对应的单元格里存储的数据是"BAIDU",四维坐标"com.baidu.www","anchor","anchor: pku.edu.cn",t4对应的单元格里存储的数据是"BAIDU.com",四维坐标"com.baidu.www","contents","html",t3对应的单元格里存储的数据是网页内容。可以看出,在一个 HBase 表的概念视图中,每个行都包含相同的列族,尽管行不需要在每个列族里存储数据。比如表2中,前 2 行数据中,列族 contents 的内容为空,后 3 行数据中,列族 anchor 的内容为空。从这个角度来说,HBase 表是一个稀疏的映射关系,即里面存在很多空的单元格。
表2 HBase存储数据的概念视图
| 行键 | 时间戳 | 列族contents | 列族anchor |
|---|---|---|---|
| "com.baidu.www" | t5 | anchor:xmu.edu.cn="BAIDU" | |
| "com.baidu.www" | t4 | anchor:pku.edu.cn="BAIDU.com" | |
| "com.baidu.www" | t3 | contents:html="..." | |
| "com.baidu.www" | t2 | contents:html="..." | |
| "com.baidu.www" | t1 | contents:html="..." |
五、物理视图
从概念视图层面,HBase 中的每个表是由许多行组成的,但是在物理存储层面,它采用基于列的存储方式,而不是像传统关系数据库那样采用基于行的存储方式,这也是 HBase 和传统关系数据库的重要区别。表2的概念视图在物理存储的时候,会存成表3中的两个小片段。也就是说,这个 HBase 表会按照 contents 和 anchor 这两个列族分别存放,属于同一个列族的数据保存在一起,同时,和每个列族一起存放的还包括行键和时间戳。
表3 HBase存储数据的物理视图 列族contents
| 行键 | 时间戳 | 列族contents |
|---|---|---|
| "com.baidu.www" | t3 | contents:html="..." |
| "com.baidu.www" | t2 | contents:html="..." |
| "com.baidu.www" | t1 | contents:html="..." |
列族anchor
| 行键 | 时间戳 | 列族contents |
|---|---|---|
| "com.baidu.www" | t5 | anchor:xmu.edu.cn="BAIDU" |
| "com.baidu.www" | t4 | anchor:pku.edu.cn="BAIDU.com" |
六、面向列的存储
通过前面的论述,我们已经知道 HBase 是面向列的存储,也就是说,HBase 是一个"列式数据库"。而传统的关系数据库采用的是面向行的存储,被称为"行式数据库"。为了加深对这个问题的认识,下面我们对面向行的存储(行式数据库)和面向列的存储(列式数据库)做一个简单介绍。
简单地说,行式数据库使用行存储模型(N-ary Storage Model,NSM),一个元组(或行)会被连续地存储在磁盘页中,如图2所示。也就是说,数据是一行一行被存储的,第一行写入磁盘页后,再继续写入第二行,以此类推。在从磁盘中读取数据时,需要从磁盘中顺序扫描每个元组的完整内容,然后从每个元组中筛选出查询所需要的属性。如果每个元组只有少量属性的值对于查询是有用的,那么 NSM 就会浪费许多磁盘空间和内存带宽。
列式数据库采用列存储模型(Decomposition Storage Model,DSM),它是在 1985 年提出来的,目的是最小化无用的 I/O。DSM 采用了不同于 NSM 的思路,对于采用 DSM 的关系数据库,DSM 会对关系进行垂直分解,并为每个属性分配一个子关系。因此,一个具有 n 个属性的关系会被分解成 n 个子关系,每个子关系单独存储,每个子关系只有当其相应的属性被请求时才会被访问。也就是说,DSM 以关系数据库中的属性或列为单位进行存储,关系中多个元组的同一属性值(或同一列值)会被存储在一起,而一个元组中不同属性值通常会被分别存放于不同的磁盘页中。
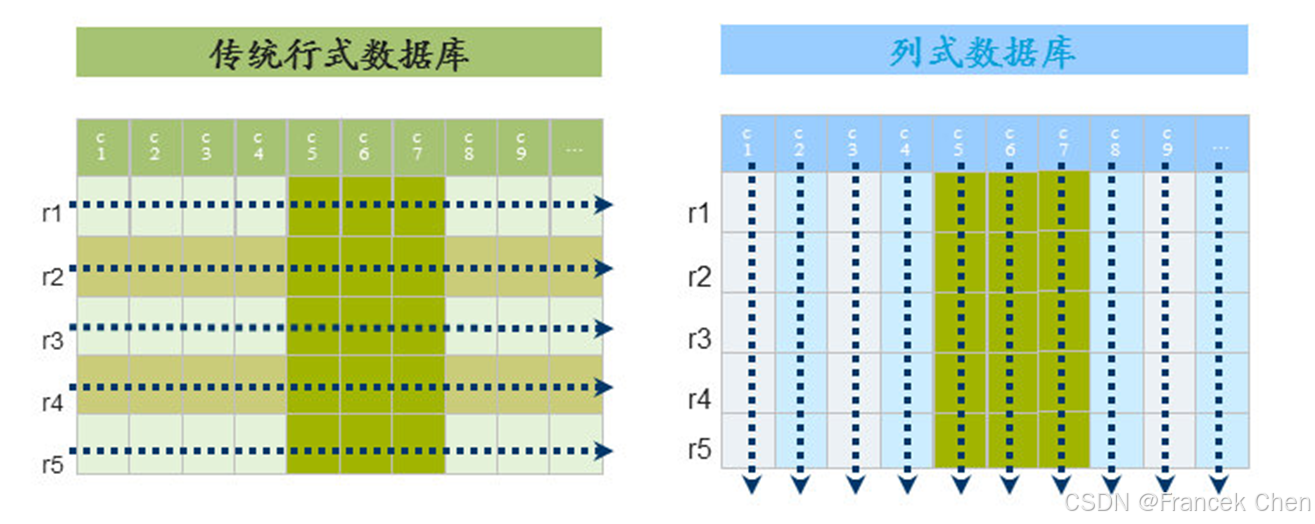
图2 行式数据库和列式数据库示意
图3是一个关于行式存储结构和列式存储结构的实例,从中可以看出两种存储方式的具体差别。
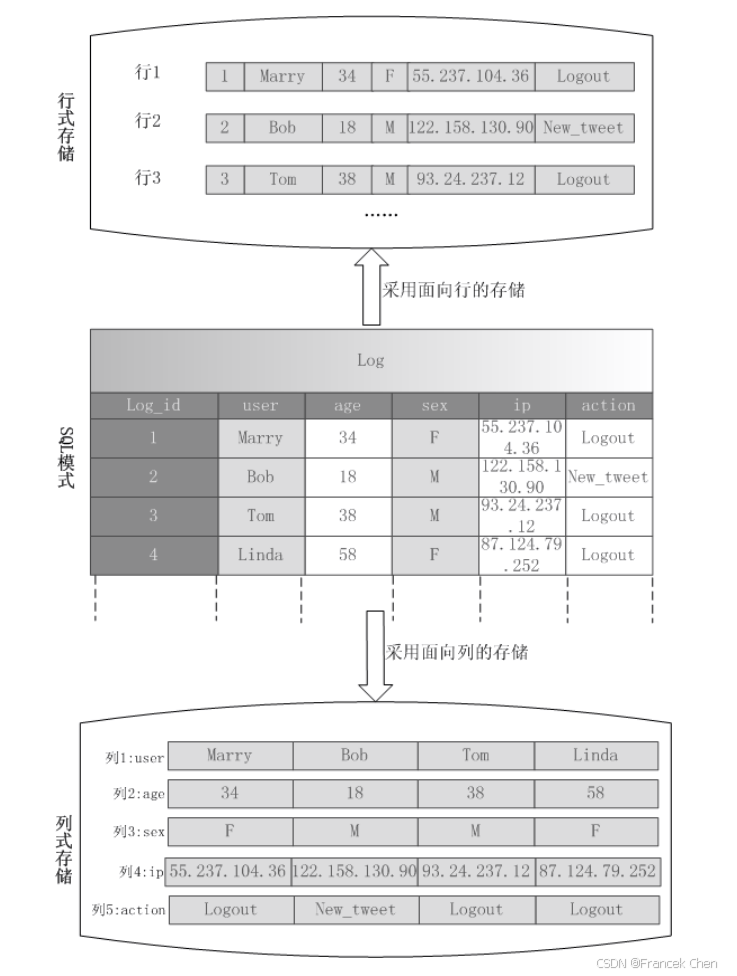
图3 行式存储结构和列式存储结构的实例
行式数据库主要适合小批量的数据处理,如联机事务型数据处理,我们平时熟悉的 Oracle 和 MySQL 等关系数据库都属于行式数据库。列式数据库主要适合批量数据处理和即席查询(Ad-Hoc Query)。列式数据库的优点是:可以降低 I/O 开销,支持大量并发用户查询,其数据处理速度比传统方法快 100 倍,因为仅需要处理可以回答这些查询的列,而不是分类整理与特定查询无关的数据行;具有较高的数据压缩比,较传统的行式数据库更加有效,甚至能达到比其高 5 倍的效果。列式数据库主要用于数据挖掘、决策支持和地理信息系统等查询密集型系统中。因为采用列式数据库一次查询就可以得出结果,而不必每次都要遍历所有的数据库,所以,列式数据库大多应用在人口统计调查、医疗分析等情况中,这种情况需要处理大量的数据,假如采用行式数据库,势必导致消耗的时间被无限延长。
DSM 的缺陷是:执行连接操作时需要昂贵的元组重构代价。因为一个元组的不同属性被分散到不同磁盘页中存储,当需要一个完整的元组时,就要从多个磁盘页中读取相应字段的值来重新组合得到原来的一个元组。对于联机事务型数据而言,处理这些数据需要频繁对一些元组进行修改(如百货商场售出一件衣服后要立即修改库存数据),如果采用 DSM,就会带来高昂的开销。在过去的很多年里,数据库主要应用于联机事务型数据处理。因此,在很长一段时间里,主流商业数据库大都采用了 NSM 而不是 DSM。但是,随着市场需求的变化,分析型应用开始发挥着越来越重要的作用,企业需要分析各种经营数据帮助企业制定决策,而对于分析型应用而言,一般数据被存储后不会发生修改(如数据仓库),因此不会涉及昂贵的元组重构代价。所以,近些年 DSM 开始受到青睐,并且出现了一些采用 DSM 的商业产品和学术研究原型系统,如 Sybase IQ、ParAccel、Sand/DNA Analytics、Vertica、InfiniDB、INFOBright、MonetDB 和 LucidDB 等。类似 Sybase IQ 和 Vertica 这些商业化的列式数据库,已经可以很好地满足数据仓库等分析型应用的需求,并且可以获得较高的性能。鉴于 DSM 的许多优良特性,HBase 等非关系数据库(或称为 NoSQL数据库)也借鉴了这种面向列的存储格式。
可以看出,如果严格从关系数据库的角度来看,HBase 并不是一个列式存储的数据库,毕竟 HBase 是以列族为单位进行分解的(列族当中可以包含多个列),而不是每个列都单独存储,但是 HBase 借鉴和利用了磁盘上的这种列存储格式,所以,从这个角度来说,HBase 可以被视为列式数据库。
小结
HBase 作为稀疏、多维度、排序的映射表,以行键、列族、列限定符和时间戳为索引。表由行和列族组成,列族需预先定义且支持动态扩展列。数据按行键字典序存储,单元格可存多版本数据,以时间戳索引。概念视图是稀疏多维映射,物理视图则按列族存储,属于同一列族的数据保存在一起。HBase 借鉴列式存储格式,虽非严格列式数据库,但以列族为单位分解存储,适合批量数据处理和即席查询,在数据挖掘等查询密集型系统中有广泛应用。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
