为什么检索增强生成(RAG)将无法在上下文革命中幸存,以及我们所知的分块、嵌入和重排序器(Rerankers)的终结。
关于原作者 Nicolas Bustamante
出生于巴黎,现居旧金山。毕业于法国高等师范学院(École Normale Supérieure)和加州大学伯克利分校,21 岁辍学创业。
联合创始人兼 CEO -
Doctrine(AI 驱动的法律信息平台,被誉为"欧洲律师的彭博社")现在 :正在创建新公司,为 CFO 构建 B2B SaaS 基础设施工具;同时担任 Figures 的运营顾问。
全文概览
我在人工智能和搜索领域工作了十年。最初是构建欧洲最大的法律搜索引擎 Doctrine,现在是构建 Fintool,一个由人工智能驱动的金融研究平台,帮助机构投资者分析公司、筛选股票并做出投资决策。
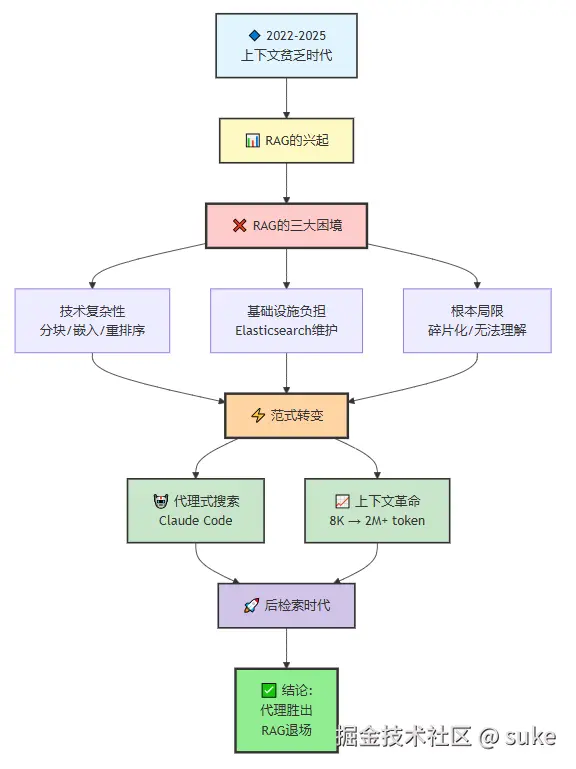
在构建、优化和扩展基于检索增强生成(RAG)系统的 LLM 三年后,我认为我们正在见证基于 RAG 的架构的黄昏。随着上下文窗口的爆炸式增长和基于代理(Agent)的架构的成熟,我有一个有争议的观点,即我们花费大量时间构建和优化的现有 RAG 基础设施正在衰落。
检索增强生成的兴起
2022 年末,ChatGPT 横空出世。人们开始无休止的对话,委派重要的工作,却发现底层模型 GPT-3.5 只能处理 4,096 个 token......大约六页文本!
人工智能世界面临一个根本性问题:如何让智能系统处理比它一次能阅读的知识库大好几个数量级的知识库?
答案是检索增强生成(RAG),一种在未来三年主导人工智能的架构模式。
早期 LLM 的数学现实
GPT-3.5 可以处理 4,096 个 token,下一个模型 GPT-4 将其翻倍至 8,192 个 token,大约十二页。这不仅仅是不方便;它在架构上是毁灭性的。
考虑一下这些数字:一份 SEC 10-K 文件包含大约 51,000 个 token(130 多页)。
使用 8,192 个 token,您只能看到 10-K 文件的不到 16%。这就像通过钥匙孔阅读财务报告一样!
RAG 架构:技术深入探讨
RAG 作为一个直接借鉴自搜索引擎的优雅解决方案而出现。就像 Google 为您的查询显示 10 个蓝色链接和相关摘要一样,RAG 检索最相关的文档片段并将其提供给 LLM 进行合成。
核心思想非常简单:如果无法将所有内容放入上下文中,则找到最相关的部分并使用它们。 它将 LLM 变成了复杂的搜索结果摘要工具。
基本上,LLM 无法阅读整本书,但它们可以知道结局谁死了;很方便!
分块挑战
长文档需要分块,这时问题就开始了。这些易于消化的片段通常每个包含 400-1,000 个 token,大约是 300-750 个单词。
问题是?这不像每 500 个单词就剪切一次那么简单。
考虑对典型的 SEC 10-K 年度报告进行分块。该文档具有复杂的层次结构:
- 第 1 项:业务概览(10-15 页)
- 第 1A 项:风险因素(20-30 页)
- 第 7 项:管理层讨论与分析(30-40 页)
- 第 8 项:财务报表(40-50 页)
在对 500 个 token 进行简单分块后,关键信息会分散:
- 收入确认政策分散在 3 个分块中
- 风险因素解释在句子中间被打断
- 财务报表标题与其数据分离
- MD&A 叙述与它所讨论的数字脱节
如果您搜索"收入增长驱动因素",您可能会得到一个提到增长的分块,但会错过不同分块中的实际数值数据,或者另一个分块中 MD&A 的战略背景!
在 Fintool,我们开发了复杂的分块策略:保留层次结构、表格完整性、交叉引用、时间连贯性和脚注关联,并为每个分块附加丰富的元数据(文件类型、会计期间、章节层次、公司标识符等)。
但即使如此,也无法解决根本问题:我们仍在使用片段而非完整文档。
嵌入和检索管道
每个分块都被转换为高维向量(在大多数嵌入模型中通常为 1,536 维)。这些向量存在于一个空间中,理论上,相似的概念彼此靠近。
当用户提出问题时,该问题也变成一个向量。系统使用余弦相似度查找其向量最接近查询向量的分块。
这在理论上很优雅,但在实践中,它是边缘情况的噩梦。
嵌入模型在通用文本上进行训练,但在特定术语方面表现不佳。它们可以找到相似之处,但无法区分"收入确认"(会计政策)和"收入增长"(业务绩效)。
考虑这个例子:查询:"公司的诉讼风险敞口是多少?"
RAG 搜索"诉讼"并返回 50 个分块:
- 分块 1-10:样板风险因素中各种提及"诉讼"
- 分块 11-20:2019 年的历史案件(已解决)
- 分块 21-30:前瞻性安全港声明
- 分块 31-40:来自不同部分的重复描述
- 分块 41-50:通用"我们可能面临诉讼"警告
RAG 报告的内容: 诉讼费用 5 亿美元(来自法律诉讼部分)
实际情况:
- 法律诉讼费用 5 亿美元(第 3 项)
- 附注中 7 亿美元的或有事项(" individually 不重要")
- 后续事件中 10 亿美元的新集体诉讼
- 8 亿美元的赔偿义务(不同部分)
- 脚注中 20 亿美元的可能损失(关键词"可能"而不是"诉讼")
**实际风险敖口为 51 亿美元。是 RAG 发现的 10 倍。**糟糕!到 2023 年末,大多数开发者意识到纯向量搜索是不够的。
混合搜索:真正有效的复杂性
引入混合搜索:将语义搜索(嵌入)与传统关键词搜索(BM25)相结合。这是事情变得有趣的地方。
BM25(最佳匹配 25)是一种概率检索模型,擅长精确术语匹配。与嵌入不同,BM25:
- 奖励精确匹配 :当您搜索
EBITDA时,您会得到包含EBITDA的文档,而不是"营业收入"或"收益" - 更好地处理罕见术语 :像
CECL(预期信用损失)或ASC 606这样的金融术语会得到适当的权重 - 文档长度标准化:不会惩罚较长的文档
- 术语频率饱和:多次提及"收入"不会掩盖其他重要术语
在 Fintool,我们构建了复杂的混合搜索系统:并行运行语义和关键词搜索,根据查询类型动态调整权重,并使用倒数排序融合(RRF)合并结果。
所以现在你认为一切都做好了吗?但绝非如此!
重排序瓶颈:RAG 的肮脏秘密
没有人谈论的是:即使完成了所有检索工作,您也还没有完成。您需要再次对分块进行重排序以获得良好的检索,这并不容易。重排序器是机器学习模型,它们接收搜索结果并根据您的特定查询重新排序,从而限制发送到 LLM 的分块数量。
LLM 不仅上下文贫乏,而且在处理过多信息时也会遇到困难。 减少发送到 LLM 以获取最终答案的分块数量至关重要。
重排序管道:

以下是重排序面临的挑战:
- 延迟爆炸 :每次查询重排序会增加
300-2000ms - 成本倍增 :例如
Cohere Rerank 3.5每 1,000 个搜索单元的成本为$2.00 - 上下文限制 :
Cohere Rerank仅支持4096 token,需要处理更多必须拆分为并行API调用 - 另一个要管理的模型:又一个 API,又一个故障点
重排序是复杂管道中的又一步。
传统 RAG 的基础设施负担
我认为 RAG 困难的地方是我所谓的"级联故障问题"。
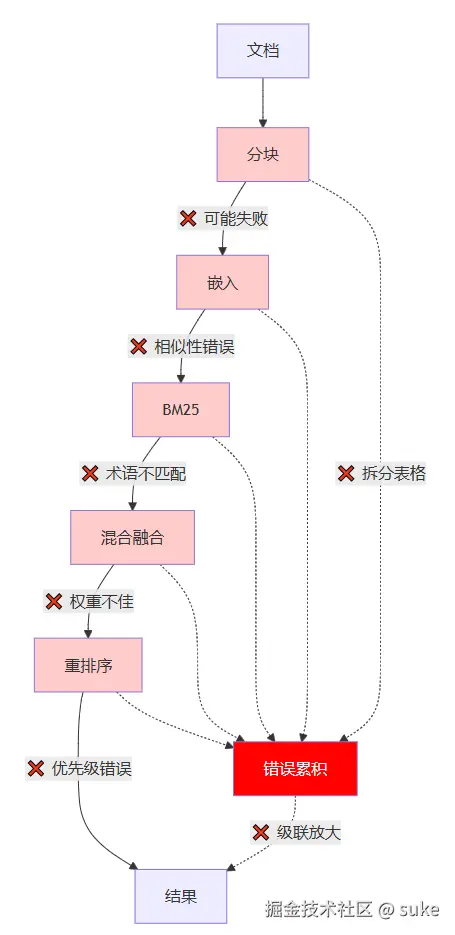
除了混合搜索本身的复杂性之外,还有一个很少讨论的基础设施负担。
运行生产环境的 Elasticsearch 并不容易。为了全面的文档覆盖,您需要维护 TB+ 的索引数据,这至少需要 128-256GB RAM 才能获得不错的性能。真正的噩梦在于重新索引。每次模式更改都会强制进行全面重新索引,对于大型数据集需要 48-72 小时。最重要的是,您需要不断处理集群管理、分片策略、索引优化、缓存调整、备份和灾难恢复,以及经常包含重大更改的版本升级。
RAG 在复杂文档方面的根本局限性
以下是一些结构性限制:
- 上下文碎片化
- 长文档是相互关联的网络,而不是独立的段落
- 一个问题可能需要来自 20 多个文档的信息
- 分块会永久破坏这些关系
- 语义搜索在数字方面失败
- " 45.2M"和"45,200,000"具有不同的嵌入
- "收入增长 10%"和"收入增长十分之一"的排名不同
- 充满数字的表格语义表示不佳
- 缺乏因果理解
- RAG 无法遵循"参见附注 12"→ 附注 12 → 附表 K
- 无法理解终止经营会影响持续经营
- 无法追溯一个财务项目如何影响另一个
- 词汇不匹配问题
- 公司对同一概念使用不同的术语
- "调整后 EBITDA"与"扣除特殊项目前的营业收入"
- 时间盲区
- 无法可靠地区分 2024 年第三季度和 2023 年第三季度
- 将当前期间与前期比较混淆
- 不理解财年边界
这些都不是小问题。它们是检索范式的根本局限性。
三个月前,我偶然发现了一项检索创新,让我大吃一惊。
代理式搜索的出现------一种新范式
2025 年 5 月,Anthropic 发布了 Claude Code,一个在终端中工作的 AI 编码代理。起初,我对这种形式感到惊讶。一个终端?我们回到了 1980 年代吗?没有用户界面?
那时,我正在使用 Cursor,一个擅长传统 RAG 的产品。我让它访问我的代码库来嵌入我的文件,Cursor 在回答我的查询之前对我的代码库进行了搜索。生活很好。但是当测试 Claude Code 时,有一件事很突出:
它更好更快,不是因为它们的 RAG 更好,而是因为根本没有 RAG。
Claude Code 搜索的工作原理
Claude Code 没有使用分块、嵌入和搜索的复杂管道,而是使用直接的文件系统工具:
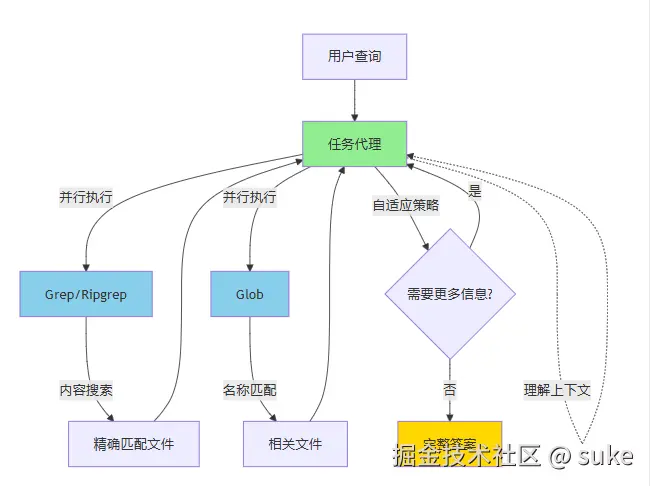
核心特性: Grep (1973年发明的工具)通过正则表达式搜索文件内容,Glob 通过名称模式发现文件,任务代理自主探索并自适应组合搜索策略。
Claude Code 不检索,它调查: 并行运行多个搜索,先广泛后缩小,自然遵循引用关系,没有嵌入、相似度分数或重排序。它简单、快速,基于 LLM 将从上下文贫乏变为上下文丰富的新假设。
正如您在此基准中看到的那样,一个带有 url+描述的简单 TXT 文件比复杂的 RAG 表现更好。哎呀。这是一个范式转变;LLM 将 RAG 脚手架当作早餐吃掉。
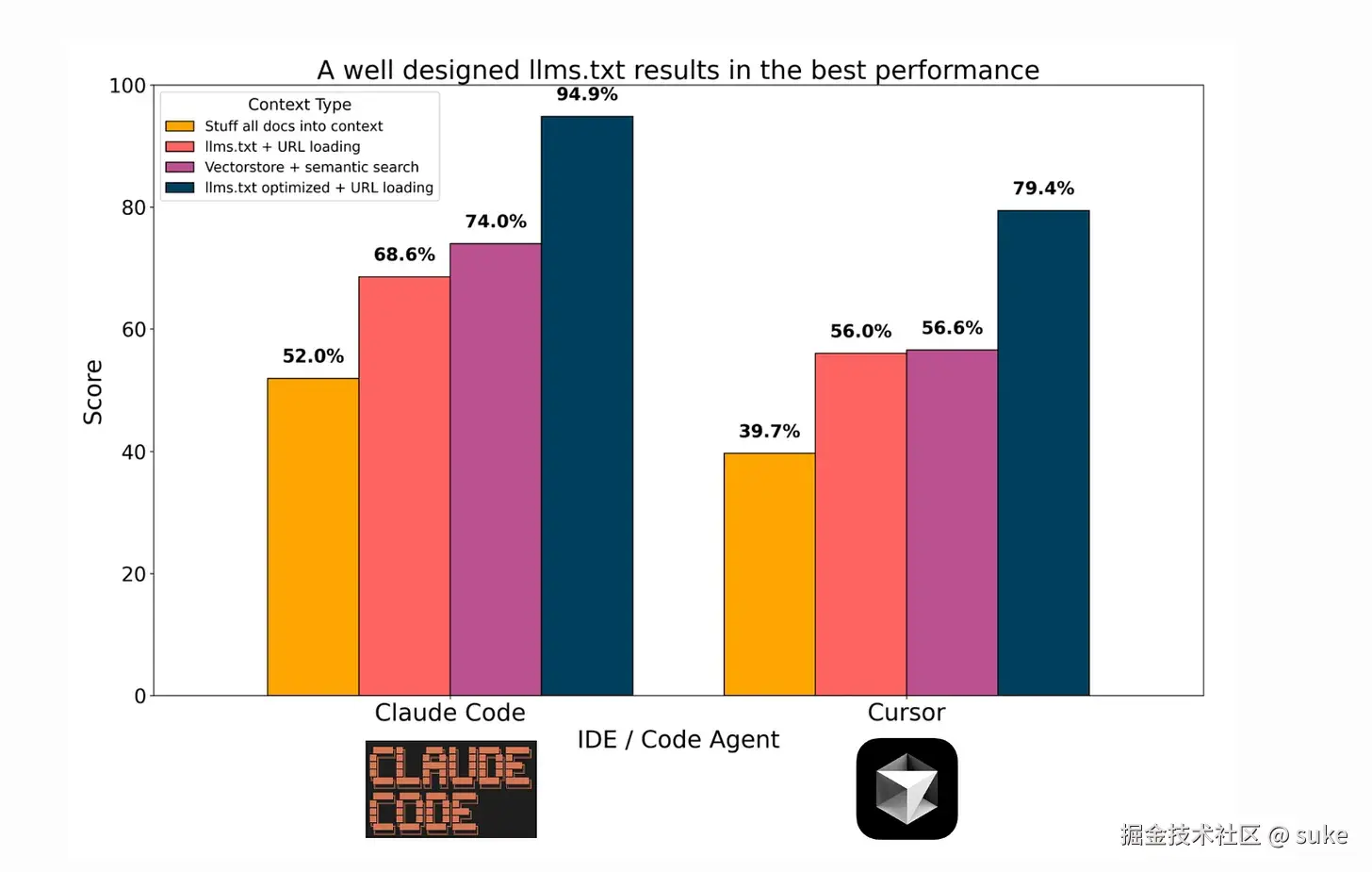 这不仅仅比 RAG 更好。它是一种根本不同的范式。适用于代码的也适用于任何非代码文件的长文档。
这不仅仅比 RAG 更好。它是一种根本不同的范式。适用于代码的也适用于任何非代码文件的长文档。
上下文革命:从稀缺到丰富
上下文窗口的爆炸式增长使 Claude Code 成为可能:
| 时代 | 模型 | 上下文窗口 | 相当页数 |
|---|---|---|---|
| 2022-2025 上下文贫乏时代 | GPT-4 | 8K token | 约 12 页 |
| GPT-4-32k | 32K token | 约 50 页 | |
| 2025 年及以后上下文革命 | Claude Sonnet 4 | 200k token | 约 700 页 |
| Gemini 2.5 | 1M token | 约 3,000 页 | |
| Grok 4-fast | 2M token | 约 6,000 页 |
在 2M token 的情况下,您可以装入大多数公司一整年的 SEC 文件。
这一轨迹甚至更引人注目:到 2027 年,我们很可能达到 10M+ 的上下文窗口,Sam Altman 暗示即将出现数十亿个上下文 token。这代表了 AI 系统处理信息方式的根本性转变 。同样重要的是,注意力机制正在迅速改进------LLM 在保持大规模上下文窗口的连贯性和焦点方面做得越来越好,而不会在噪音中"迷失"。
Claude Code 的洞察:为什么上下文改变一切
有足够上下文时,搜索就变成了导航:无需检索片段、相似性计算、重排序或嵌入。LLM 在代理行为方面的进步,使它们能够将工作组织成任务以实现目标。
Ripgrep vs Elasticsearch 对比:
| 特性 | Ripgrep | Elasticsearch |
|---|---|---|
| 设置 | 无需索引,零配置 | 需要复杂的索引和配置 |
| 可用性 | 文档即刻可搜索 | 需要等待索引完成 |
| 维护 | 零维护 | 需要管理集群、分片、优化 |
| 速度 | 10万行代码几毫秒 | 需要几分钟索引 |
| 成本 | $0 | 需要大量基础设施投入 |
代理能内在理解 SEC 文件结构:层次意识、交叉引用跟踪、多文档协调和时间分析。对于大规模搜索,混合检索成为代理的工具之一,代理最终加载完整文档进行深入分析。
RAG vs 代理式搜索对比:
| 维度 | RAG(研究助理) | 代理式搜索(法务会计师) |
|---|---|---|
| 信息检索 | "这里有 50 段提到了债务" | 系统地追踪资金流向 |
| 分析能力 | 无法告诉您债务是否增加或原因 | 理解会计关系(资产 = 负债 + 权益) |
| 关联能力 | 无法将债务与战略变化联系 | 连接跨时间段和文档的点 |
| 洞察力 | 无法识别隐藏的义务 | 识别缺失或隐藏的内容 |
| 理解深度 | 只检索文本,不理解关系 | 用数据挑战管理层的断言 |
为什么代理式搜索代表未来
五大趋势推动代理式搜索:
1. 文档复杂性增加 - 文档更长、关联性更强,需要遵循复杂的交叉引用路径
2. 结构化数据集成 - 表格、叙述和元数据必须一起理解,关系比孤立事实更重要
3. 实时要求 - 无时间重新索引,动态文档需要自适应方法
4. 跨文档理解 - 现代分析需连接主要文档、支持材料、历史版本和相关文件。RAG独立处理,代理建立累积理解
5. 精度优于相似度 - 跟踪引用胜过查找相关文本,导航胜过检索
代理式搜索的核心优势:
| 优势维度 | 具体表现 |
|---|---|
| 准确性 | 消除因缺少上下文而产生的幻觉 |
| 完整性 | 完整答案而不是片段 |
| 速度 | 通过并行探索实现更快洞察 |
| 精确度 | 通过系统导航实现更高准确性 |
| 成本 | 大幅降低基础设施成本 |
| 维护 | 零索引维护开销 |
关键洞察: 复杂文档分析的核心是理解关系、跟踪引用和保持精度,而非寻找相似文本。大上下文窗口和智能导航的结合提供了检索无法实现的功能。
RAG 是上下文贫乏时代的巧妙权宜之计 。它弥合了小窗口和海量文档间的鸿沟,但始终是临时方案。未来属于能够导航、推理并在工作内存中保存整个语料库的代理。
我们正进入后检索时代 。赢家不是维护最大向量数据库的人,而是设计最智能代理的人。回想起来,RAG 就像辅助轮------有用、必要,但只是暂时的。