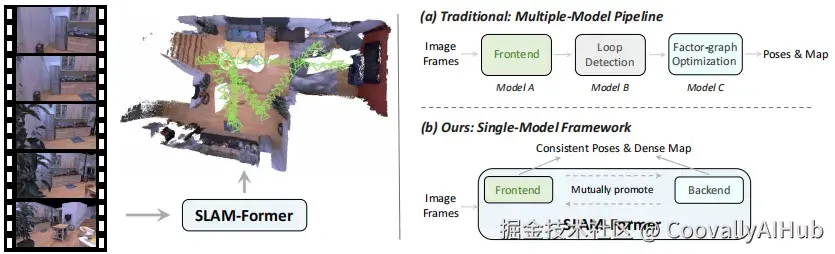
将前端跟踪与后端优化统一在一个模型中,实现实时、高一致性的视觉SLAM
在机器人感知领域,同时定位与地图构建(Simultaneous Localization and Mapping,SLAM)技术至关重要。它使机器人能够在未知环境中构建地图,并同时跟踪自身位置,是实现自主导航的核心技术。
传统SLAM系统通常分为前端 (实时跟踪与局部建图)和后端(全局优化与回环检测),二者分离设计,虽成熟但存在误差累积与全局一致性难以保证的问题。
传统SLAM的局限与神经SLAM的兴起
早期SLAM系统如ORB-SLAM、LSD-SLAM等主要依赖稀疏特征点,虽然高效稳定,但无法提供丰富的环境几何信息。近年来,随着深度学习的发展,尤其是光流估计 与多视图深度估计 技术的进步,基于单目相机的密集SLAM 方法逐渐成熟。
这类方法仅依靠图像输入就能实现高质量的地图重建,例如DROID-SLAM、SceneFactory等。近年来,更出现了基于几何基础模型(如DUSt3R、VGGT)的SLAM系统,如MASt3R-SLAM、VGGT-SLAM等。
然而,这些方法仍存在明显缺陷:
- 依赖局部子图对齐,导致全局不一致
- 增量式处理方法无法修正历史估计,造成漂移现象
SLAM-Former:统一的前端-后端Transformer架构
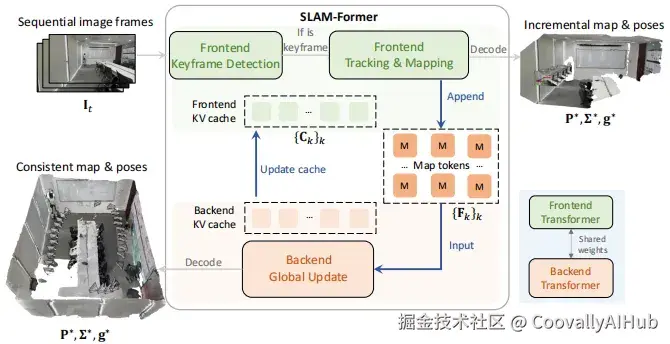
清华大学Mars Lab团队提出SLAM-Former ,将完整的SLAM能力集成于单一Transformer模型中。其核心思想是:前端与后端共享同一套Transformer骨干网络,交替执行,相互促进。
前端负责实时处理序列图像,进行关键帧检测、姿态估计与增量式地图更新;后端则以较低频率启动,对所有历史地图令牌进行全局优化,确保几何一致性。
关键技术设计
- 前端:实时跟踪与建图
前端采用因果注意力机制,每到来一帧图像,模型会决定是否将其设为关键帧。若是,则利用历史KV缓存生成新的地图令牌,并更新当前地图状态:
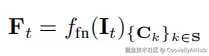
- 后端:全局优化
后端使用全注意力机制,对所有地图令牌进行一次性优化:
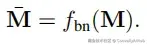
这种设计相当于在密集因子图上执行回环检测,无需传统SLAM中复杂的图优化模块。
- 缓存共享机制
后端优化后的KV缓存会更新至前端,使得后续帧能在优化后的全局结构基础上进行跟踪,显著减少长序列中的误差累积。
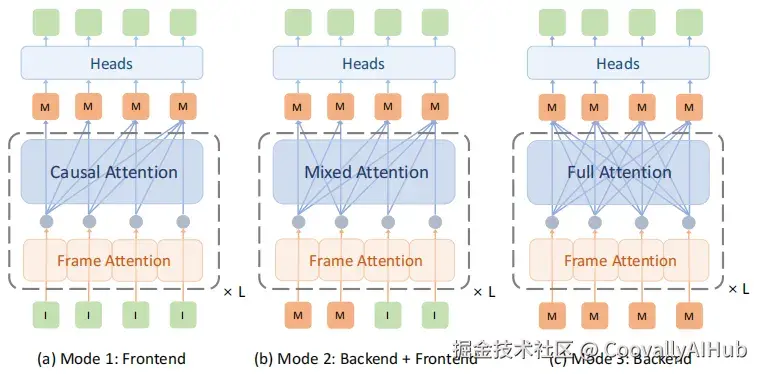
三种训练模式
SLAM-Former通过三种训练模式统一前端与后端功能:
- 模式1(前端训练): 使用因果注意力,模拟在线推理
- 模式2(前后端协作训练): 混合注意力,后端优化与前端处理同步进行
- 模式3(后端训练): 全注意力,专注于全局一致性优化
三种模式在单次迭代中顺序执行,共享模型权重,实现端到端联合训练。
实验成果
- 跟踪性能领先
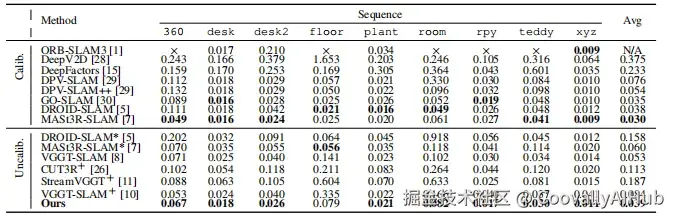
在TUM RGB-D、7-Scenes和Replica等标准数据集上,SLAM-Former在未标定设置下显著优于现有方法,甚至在许多场景下超越需要相机标定的传统方法。
- 重建质量大幅提升
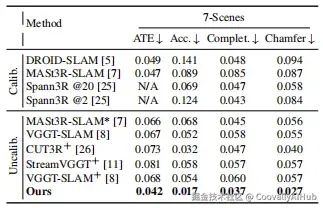
在7-Scenes数据集上,SLAM-Former的重建精度达到0.017m,比其他方法提升约50%以上;在Replica数据集上同样取得最佳重建质量。
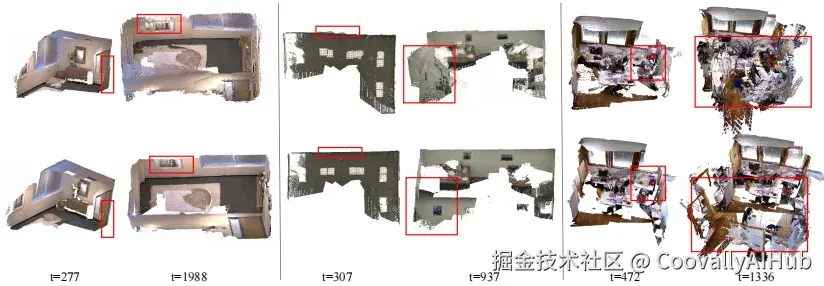
- 前后端协作的有效性
消融实验证明,后端模块的引入显著提升了系统性能。前端单独使用会随时间的推移积累误差,而结合后端后,系统能保持全局一致性。
实时性能
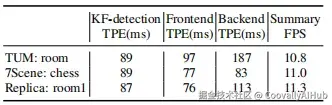
SLAM-Former在保持高质量的同时,也满足了实时性要求:
- 关键帧检测:< 100ms
- 前端处理:< 100ms
- 整体速度:> 10Hz
总结
SLAM-Former首次将完整SLAM能力整合到单一Transformer中,通过前端-后端的交替协作,在保持实时性的同时实现了全局一致性,在多个标准数据集上取得了领先的性能。
当前局限与未来方向:
后端全注意力的O(n²)复杂度限制可扩展性
需探索稀疏注意力、令牌合并等Transformer加速技术
支持纯局部前端模式,减少历史依赖
SLAM-Former为神经SLAM的发展开辟了新方向,证明统一的前端-后端设计能在单一模型中实现高效、一致的SLAM能力,为机器人的长期自主运行奠定了基础。

文档及项目地址
perl
文档地址:https://arxiv.org/abs/2509.16909Github
项目地址:https://tsinghua-mars-lab.github.io/SLAM-Former/