背景需求:
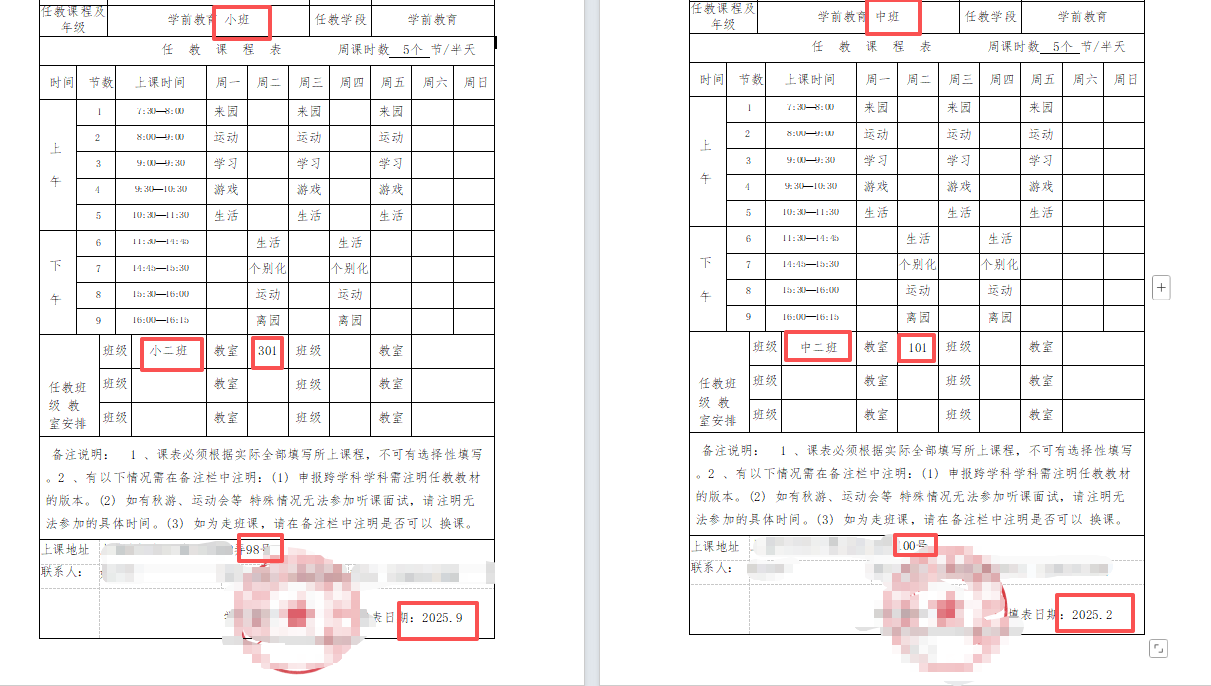
职称有一个课程表
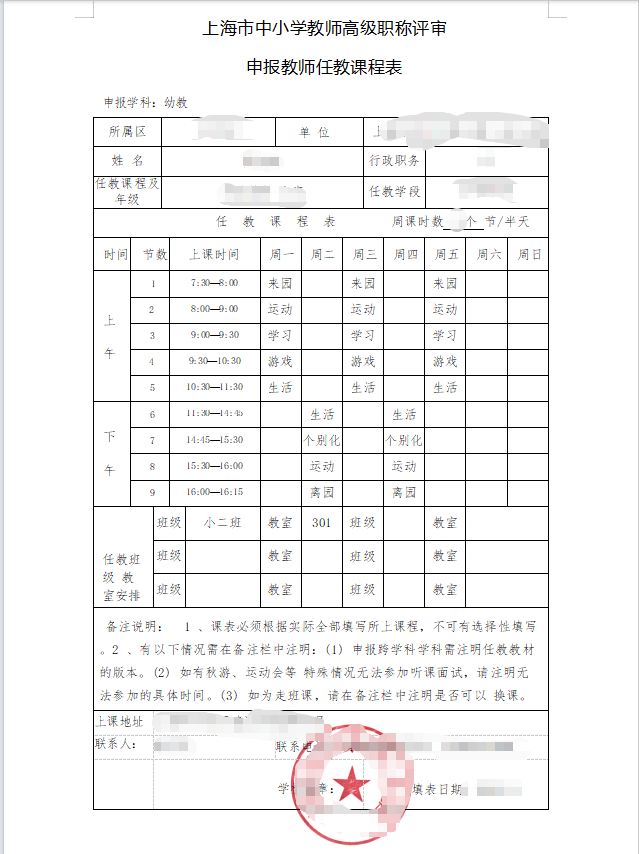
需要倒推写11个半学期的课程表docx


都是机械重复填写,但是表格太多,人工填写很容易写错、核对也容易头晕。
所以我就想用Python批量做
制作一个模版,填写英文占位符。
一些完全一样的信息,如申报学科、所属区、单位、职务,就在模版上预先填好。
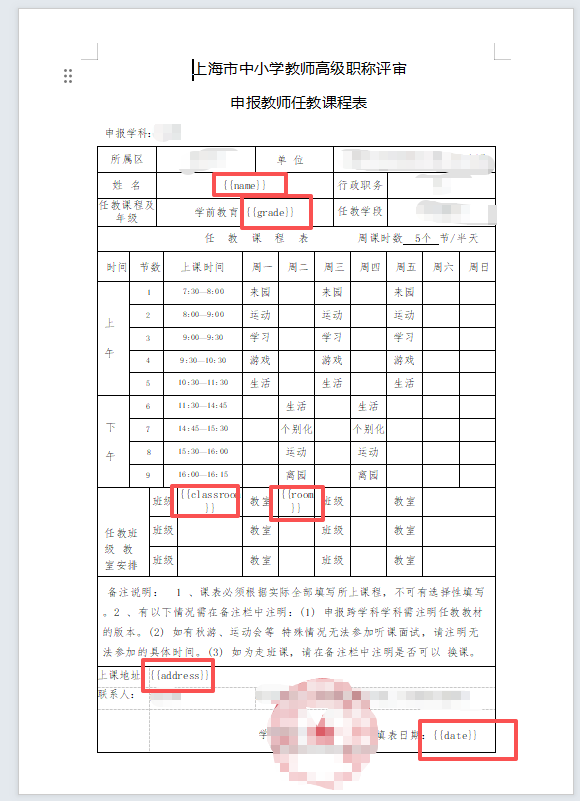
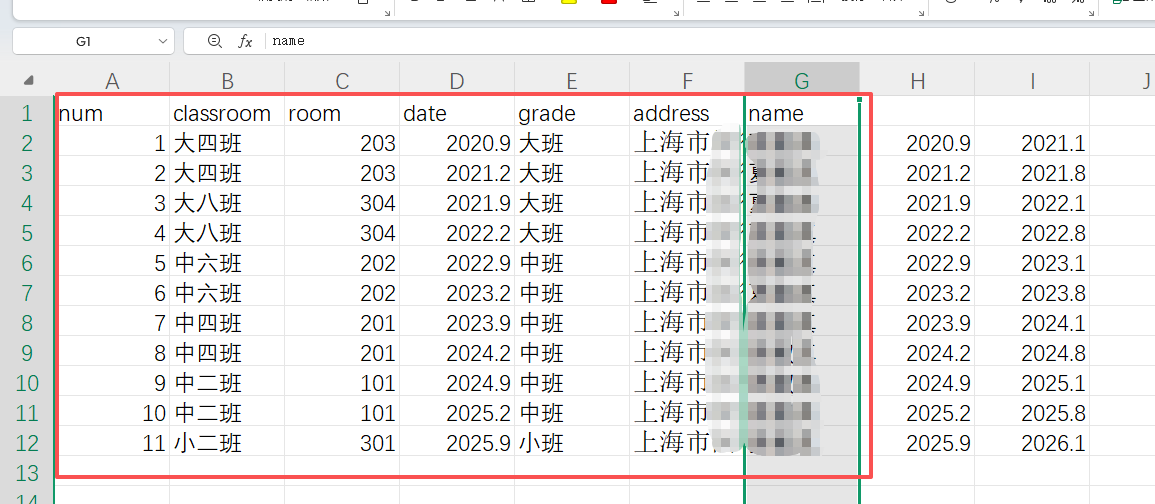
在EXCEL里写好11个学期的课程内容
python
'''
职称05 ,docx课程表复制
deepseek,阿夏
20250920
'''
import os
import pandas as pd
from docx import Document
from docxcompose.composer import Composer
import win32com.client as win32
from copy import deepcopy
def excel_to_docx_template():
# 文件夹路径
path = r"......\12任课课程表(本年度11次)\py"
aa='Xia' # 教师的名字
excel_path = os.path.join(path, f"{aa[0]}课程表.xlsx") # 指定Excel文件路径
template_path = os.path.join(path, "模版.docx") # 模版文件路径
output_folder = os.path.join(path, "临时")
merged_docx_path = os.path.join(path, f"{aa}副高任教课程表1.docx")
pdf_path = os.path.join(path, f"{aa}副高任教课程表1.pdf")
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 检查Excel文件是否存在
if not os.path.exists(excel_path):
print(f"未找到Excel文件: {excel_path}")
# 列出目录下的所有Excel文件供选择
excel_files = [f for f in os.listdir(path) if f.endswith('.xlsx')]
if excel_files:
print("目录中找到以下Excel文件:")
for i, file in enumerate(excel_files, 1):
print(f"{i}. {file}")
return
# 检查模板文件是否存在
if not os.path.exists(template_path):
print(f"未找到模板文件: {template_path}")
return
# 读取Excel数据
try:
df = pd.read_excel(excel_path)
print(f"成功读取Excel文件,共{len(df)}行数据")
except Exception as e:
print(f"读取Excel文件失败: {e}")
return
# 存储生成的docx文件路径
docx_files = []
# 为每一行数据生成一个docx文件
for index, row in df.iterrows():
# 读取模板
try:
doc = Document(template_path)
except Exception as e:
print(f"读取模板文件失败: {e}")
return
# 替换占位符
replacements = {
'{{name}}': str(row['name']),
'{{classroom}}': str(row['classroom']),
'{{room}}': str(row['room']),
'{{date}}': str(row['date']),
'{{grade}}': str(row['grade']),
'{{address}}': str(row['address'])
}
print(f"处理第{index+1}行数据: {replacements}")
# 遍历所有段落进行替换
for paragraph in doc.paragraphs:
for key, value in replacements.items():
if key in paragraph.text:
for run in paragraph.runs:
if key in run.text:
run.text = run.text.replace(key, value)
# 遍历所有表格进行替换
for table in doc.tables:
for row_table in table.rows:
for cell in row_table.cells:
for key, value in replacements.items():
if key in cell.text:
for paragraph in cell.paragraphs:
for run in paragraph.runs:
if key in run.text:
run.text = run.text.replace(key, value)
# 保存生成的docx文件
output_docx_path = os.path.join(output_folder, f"课程表_{index+1}.docx")
doc.save(output_docx_path)
docx_files.append(output_docx_path)
print(f"已生成: {output_docx_path}")
# 合并所有docx文件
if docx_files:
try:
# 以第一个文档为基础
master_doc = Document(docx_files[0])
composer = Composer(master_doc)
# 添加其他文档(从第二个开始)
for doc_path in docx_files[1:]:
doc_to_append = Document(doc_path)
composer.append(doc_to_append)
# master_doc = Document(docx_files[-1])
# composer = Composer(master_doc)
# # 添加其他文档(从倒数第二个到第一个,按倒序添加)
# for doc_path in reversed(docx_files[:-1]):
# doc_to_append = Document(doc_path)
# composer.append(doc_to_append)
# 保存合并后的文档
composer.save(merged_docx_path)
print(f"已合并文档: {merged_docx_path}")
# 转换为PDF
try:
word = win32.DispatchEx("Word.Application")
word.Visible = False
# 打开合并后的docx文件
doc = word.Documents.Open(os.path.abspath(merged_docx_path))
# 保存为PDF
doc.SaveAs(os.path.abspath(pdf_path), FileFormat=17) # 17代表PDF格式
doc.Close()
word.Quit()
print(f"已转换为PDF: {pdf_path}")
except Exception as e:
print(f"PDF转换失败: {e}")
print("请确保已安装Microsoft Word")
except Exception as e:
print(f"合并文档失败: {e}")
else:
print("没有生成任何docx文件")
print("处理完成!")
if __name__ == "__main__":
excel_to_docx_template()
第1-2页内容:日期从2020.9开始,,最后一页是2025.9
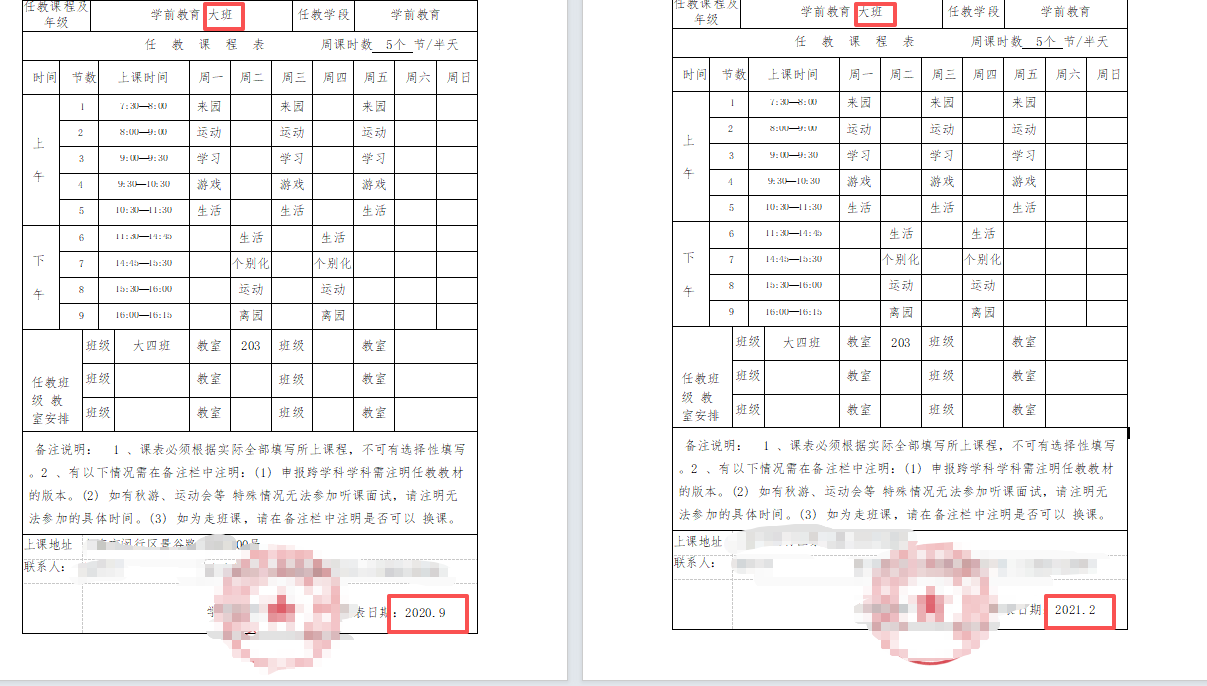
同时也转了PDF

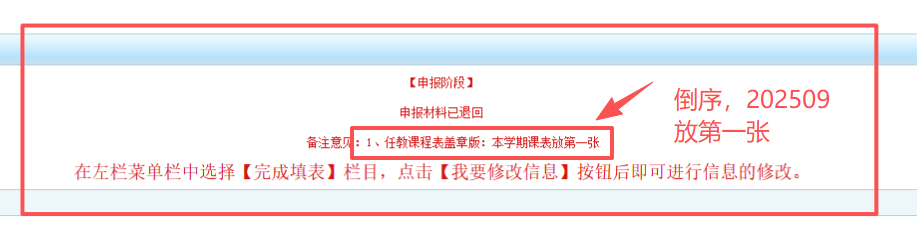
但是提交后退回,因为要求是课程表倒序,从最近日期开始
因为我的源代码以第一个文档为基础,复制其他docx到这第一个文档后面。
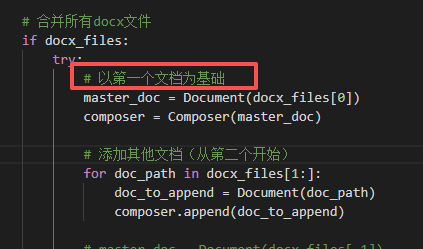
修改后倒序
python
'''
职称05 ,docx课程表复制
deepseek,阿夏
20250920
'''
import os
import pandas as pd
from docx import Document
from docxcompose.composer import Composer
import win32com.client as win32
from copy import deepcopy
def excel_to_docx_template():
# 文件夹路径
path = r"\12任课课程表(本年度,姚老师填写)\py"
aa='X' # 教师的名字
excel_path = os.path.join(path, f"{aa[0]}课程表.xlsx") # 指定Excel文件路径
template_path = os.path.join(path, "模版.docx") # 模版文件路径
output_folder = os.path.join(path, "临时")
merged_docx_path = os.path.join(path, f"{aa}副高任教课程表1.docx")
pdf_path = os.path.join(path, f"{aa}副高任教课程表1.pdf")
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 检查Excel文件是否存在
if not os.path.exists(excel_path):
print(f"未找到Excel文件: {excel_path}")
# 列出目录下的所有Excel文件供选择
excel_files = [f for f in os.listdir(path) if f.endswith('.xlsx')]
if excel_files:
print("目录中找到以下Excel文件:")
for i, file in enumerate(excel_files, 1):
print(f"{i}. {file}")
return
# 检查模板文件是否存在
if not os.path.exists(template_path):
print(f"未找到模板文件: {template_path}")
return
# 读取Excel数据
try:
df = pd.read_excel(excel_path)
print(f"成功读取Excel文件,共{len(df)}行数据")
except Exception as e:
print(f"读取Excel文件失败: {e}")
return
# 存储生成的docx文件路径
docx_files = []
# 为每一行数据生成一个docx文件
for index, row in df.iterrows():
# 读取模板
try:
doc = Document(template_path)
except Exception as e:
print(f"读取模板文件失败: {e}")
return
# 替换占位符
replacements = {
'{{name}}': str(row['name']),
'{{classroom}}': str(row['classroom']),
'{{room}}': str(row['room']),
'{{date}}': str(row['date']),
'{{grade}}': str(row['grade']),
'{{address}}': str(row['address'])
}
print(f"处理第{index+1}行数据: {replacements}")
# 遍历所有段落进行替换
for paragraph in doc.paragraphs:
for key, value in replacements.items():
if key in paragraph.text:
for run in paragraph.runs:
if key in run.text:
run.text = run.text.replace(key, value)
# 遍历所有表格进行替换
for table in doc.tables:
for row_table in table.rows:
for cell in row_table.cells:
for key, value in replacements.items():
if key in cell.text:
for paragraph in cell.paragraphs:
for run in paragraph.runs:
if key in run.text:
run.text = run.text.replace(key, value)
# 保存生成的docx文件
output_docx_path = os.path.join(output_folder, f"课程表_{index+1}.docx")
doc.save(output_docx_path)
docx_files.append(output_docx_path)
print(f"已生成: {output_docx_path}")
# 合并所有docx文件
if docx_files:
try:
# # 以第一个文档为基础
# master_doc = Document(docx_files[0])
# composer = Composer(master_doc)
# # 添加其他文档(从第二个开始)
# for doc_path in docx_files[1:]:
# doc_to_append = Document(doc_path)
# composer.append(doc_to_append)
master_doc = Document(docx_files[-1])
composer = Composer(master_doc)
# 添加其他文档(从倒数第二个到第一个,按倒序添加)
for doc_path in reversed(docx_files[:-1]):
doc_to_append = Document(doc_path)
composer.append(doc_to_append)
# 保存合并后的文档
composer.save(merged_docx_path)
print(f"已合并文档: {merged_docx_path}")
# 转换为PDF
try:
word = win32.DispatchEx("Word.Application")
word.Visible = False
# 打开合并后的docx文件
doc = word.Documents.Open(os.path.abspath(merged_docx_path))
# 保存为PDF
doc.SaveAs(os.path.abspath(pdf_path), FileFormat=17) # 17代表PDF格式
doc.Close()
word.Quit()
print(f"已转换为PDF: {pdf_path}")
except Exception as e:
print(f"PDF转换失败: {e}")
print("请确保已安装Microsoft Word")
except Exception as e:
print(f"合并文档失败: {e}")
else:
print("没有生成任何docx文件")
print("处理完成!")
if __name__ == "__main__":
excel_to_docx_template()
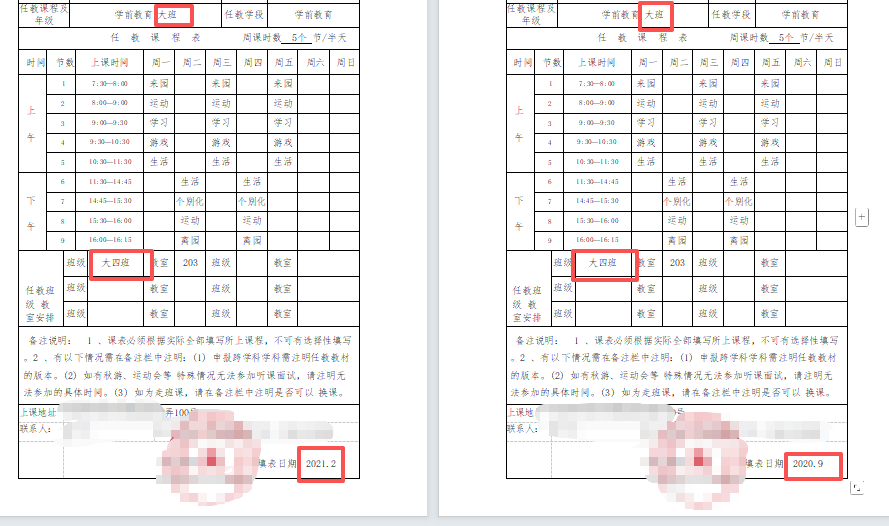
日期从2025.9最近的日期开始倒序
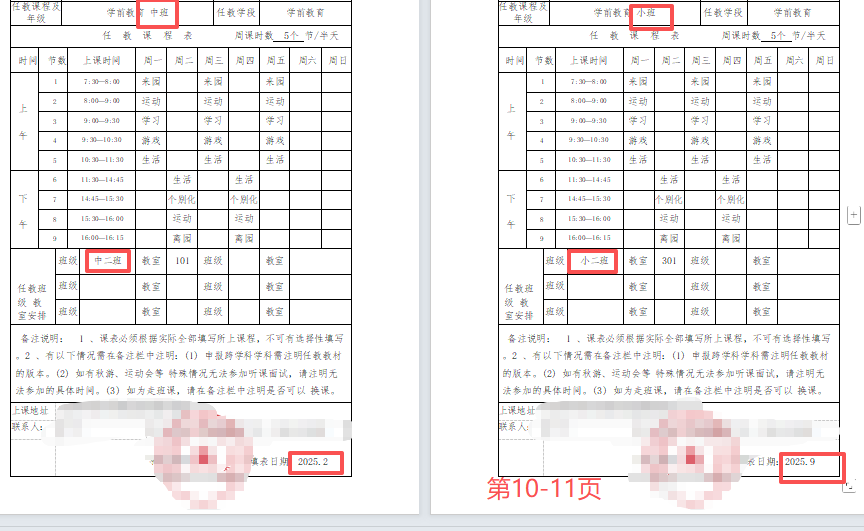
第1-2页
第10-11页
不过这个代码只适合11个学期都是班主任岗位的情况
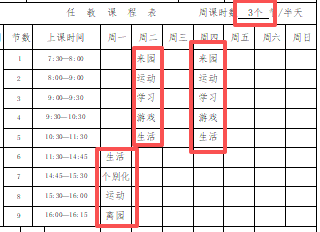
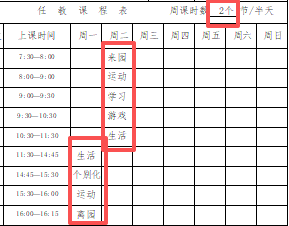
我做另一位领导的课程表时,就遇到她的职位调动,周课时数有5个半天、3个半天、2个半天的变化,此时所有的课程表内容都会变动。