本文提出了一种基于动态图卷积增强的 Informer 模型(Dynamic Graph Convolution Enhanced Informer),用于多变量时间序列分类任务。
该模型在经典 Informer 架构的基础上,引入了动态图卷积机制,以自适应地捕捉变量之间的时变依赖关系,显著提升了对复杂时间序列结构的建模能力。
目前大多数人都是用lstm,cnn-lstm,transformer类模型做分类,太老了!
代码还可以进一步继续改进,稳3-4区和北核,冲1-2区。
代码功能如下:
1.多变量输入,单标签输出(多分类,数据集如图5)
2.多个指标和结果图(如图1图2图3)
4.将训练的模型结果保存下来供后续处理
5.代码自带数据,一键运行,csv,xlsx文件读取数据,也可以替换自己数据集很简单。
1.整体结构
模型首先通过 DataEmbedding 将输入的时间序列编码为高维特征表示,随后送入由多层 ProbAttention 支持的 Encoder,以高效提取长期依赖和全局上下文信息。
在分类任务中,Encoder 的输出特征序列被送入一个动态图卷积模块(Dynamic GCN),其核心创新在于:邻接矩阵并非预设或固定,而是根据当前输入的平均特征动态计算。具体而言,在每次前向传播中,模型首先计算输入序列在时间维度上的平均特征,然后通过变量间的欧氏距离构建高斯核邻接矩阵,从而生成一个反映当前样本中变量间相关性的动态图结构。该邻接矩阵被用于图卷积操作,实现特征在变量维度上的自适应聚合。
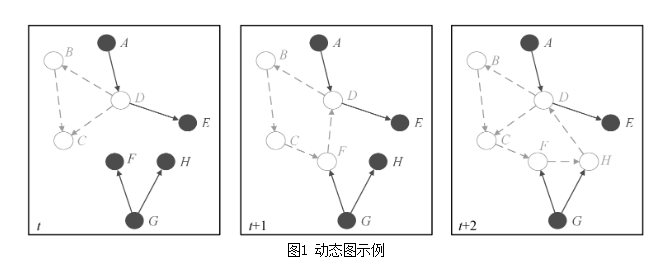
相较于传统图卷积网络(GCN)中使用静态邻接矩阵的局限性,本模型的动态图卷积机制能够根据输入数据的变化自适应地学习变量间的依赖关系,从而更好地捕捉时间序列中非平稳、时变的关联模式。例如,在某些时刻变量间可能呈现强相关性,而在另一时刻则趋于独立,该机制能够灵活响应这种变化,增强模型的表达能力。
本文提出的动态图卷积增强的 Informer 模型(Dynamic GCN Enhanced Informer) 的核心创新点可精炼总结如下:
动态邻接矩阵: 提出基于输入序列平均特征的动态图构建机制,通过欧氏距离与高斯核自适应生成时变邻接矩阵,突破传统GCN中静态图结构的限制。
时变依赖建模: 实现变量间依赖关系的自适应学习,有效捕捉时间序列中非平稳、动态变化的变量相关性。
结构化特征增强 :将动态图卷积嵌入 Informer 编码器后,融合图结构信息与序列上下文,提升特征表示能力。
**端到端可学习:**整个图结构与卷积过程可端到端训练,增强模型对复杂时序模式的表达与分类性能。
2.代码核心细节
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers.Transformer_EncDec import Decoder, DecoderLayer, Encoder, EncoderLayer, ConvLayer
from layers.SelfAttention_Family import ProbAttention, AttentionLayer
from layers.Embed import DataEmbedding
import numpy as np
import torch.optim as optim
"""
本文提出了一种基于动态图卷积增强的 Informer 模型(Dynamic Graph Convolution Enhanced Informer),用于多变量时间序列分类任务。
该模型在经典 Informer 架构的基础上,引入了动态图卷积机制,以自适应地捕捉变量之间的时变依赖关系,显著提升了对复杂时间序列结构的建模能力。
模型首先通过 DataEmbedding 将输入的时间序列编码为高维特征表示,随后送入由多层 ProbAttention 支持的 Encoder,以高效提取长期依赖和全局上下文信息。
在分类任务中,Encoder 的输出特征序列被送入一个动态图卷积模块(Dynamic GCN),其核心创新在于:邻接矩阵并非预设或固定,而是根据当前输入的平均特征动态计算。
具体而言,在每次前向传播中,模型首先计算输入序列在时间维度上的平均特征,
然后通过变量间的欧氏距离构建高斯核邻接矩阵,从而生成一个反映当前样本中变量间相关性的动态图结构。该邻接矩阵被用于图卷积操作,实现特征在变量维度上的自适应聚合。
相较于传统图卷积网络(GCN)中使用静态邻接矩阵的局限性,本模型的动态图卷积机制能够根据输入数据的变化自适应地学习变量间的依赖关系,从而更好地捕捉时间序列中非平稳、时变的关联模式。
例如,在某些时刻变量间可能呈现强相关性,而在另一时刻则趋于独立,该机制能够灵活响应这种变化,增强模型的表达能力。
此外,模型在 Informer 的编码-解码结构 基础上,通过引入动态图卷积模块,实现了特征表示的增强与结构化学习的融合。最终,经过图卷积处理的特征被展平并送入全连接分类层,完成类别预测。
"""
# --- 定义 GCN 层 ---
class SimpleGCN(nn.Module):
def __init__(self, in_channels, out_channels, adj_matrix=None):
super(SimpleGCN, self).__init__()
self.W = nn.Parameter(torch.randn(in_channels, out_channels))
if adj_matrix is None:
# 可学习的邻接矩阵
self.adj = nn.Parameter(torch.randn(in_channels, in_channels), requires_grad=True)
else:
# 固定邻接矩阵(如基于相关性)
self.register_buffer('adj', adj_matrix)
def forward(self, x):
# x: [B, L, D]
# self.adj: [D, D]
# 应用图卷积:x @ adj.T
x = torch.matmul(x, self.adj.T) # [B, L, D] @ [D, D] → [B, L, D]
x = torch.matmul(x, self.W) # [B, L, D] @ [D, D] → [B, L, D]
return x
# --- Model 类 ---
class Model(nn.Module):
"""
Informer with GCN (based on correlation) for classification
"""
def __init__(self, configs):
super(Model, self).__init__()
self.task_name = configs.task_name
self.pred_len = configs.pred_len
self.label_len = configs.label_len
self.d_model = configs.d_model
self.c_out = configs.c_out
self.num_class = configs.num_class
# Embedding
self.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
self.dec_embedding = DataEmbedding(configs.dec_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
# Encoder
self.encoder = Encoder(
[
EncoderLayer(
AttentionLayer(
ProbAttention(False, configs.factor, attention_dropout=configs.dropout,
output_attention=configs.output_attention),
configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff,
dropout=configs.dropout,
activation=configs.activation
) for l in range(configs.e_layers)
],
[
ConvLayer(
configs.d_model
) for l in range(configs.e_layers - 1)
] if configs.distil and ('forecast' in configs.task_name) else None,
norm_layer=torch.nn.LayerNorm(configs.d_model)
)
# Decoder
self.decoder = Decoder(
[
DecoderLayer(
AttentionLayer(
ProbAttention(True, configs.factor, attention_dropout=configs.dropout, output_attention=False),
configs.d_model, configs.n_heads),
AttentionLayer(
ProbAttention(False, configs.factor, attention_dropout=configs.dropout, output_attention=False),
configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff,
dropout=configs.dropout,
activation=configs.activation,
)
for l in range(configs.d_layers)
],
norm_layer=torch.nn.LayerNorm(configs.d_model),
projection=nn.Linear(configs.d_model, configs.c_out, bias=True)
)
# Classification
if self.task_name == 'classification':
self.act = F.gelu
self.dropout = nn.Dropout(configs.dropout)
# 使用 GCN 替代 CNN
self.gcn_layer = SimpleGCN(configs.d_model, configs.d_model, None) # 可学习 adj
self.projection = nn.Linear(configs.d_model * configs.seq_len, configs.num_class)
# 其他任务
if self.task_name == 'imputation' or self.task_name == 'anomaly_detection':
self.projection = nn.Linear(configs.d_model, configs.c_out, bias=True)
def long_forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
enc_out = self.enc_embedding(x_enc, x_mark_enc)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.decoder(dec_out, enc_out, x_mask=None, cross_mask=None)
return dec_out
def short_forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
mean_enc = x_enc.mean(1, keepdim=True).detach()
x_enc = x_enc - mean_enc
std_enc = torch.sqrt(torch.var(x_enc, dim=1, keepdim=True, unbiased=False) + 1e-5).detach()
x_enc = x_enc / std_enc
enc_out = self.enc_embedding(x_enc, x_mark_enc)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.decoder(dec_out, enc_out, x_mask=None, cross_mask=None)
dec_out = dec_out * std_enc + mean_enc
return dec_out
def imputation(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask):
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.projection(enc_out)
return dec_out
def anomaly_detection(self, x_enc):
enc_out = self.enc_embedding(x_enc, None)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.projection(enc_out)
return dec_out
def classification(self, x_enc, x_mark_enc):
# 前向传播
enc_out = self.enc_embedding(x_enc, None) # [B, L, D]
enc_out, attns = self.encoder(enc_out, attn_mask=None) # [B, L, D]
B, L, D = enc_out.shape
# 动态计算邻接矩阵(基于当前输入的平均特征)
with torch.no_grad():
mean_enc = enc_out.mean(dim=1) # [B, D]
# 计算变量间的距离(D 维)
dist_var = torch.cdist(mean_enc.T, mean_enc.T, p=2) # [D, D]
sigma = 1.0
adj = torch.exp(-dist_var**2 / (2 * sigma**2)) # 高斯核
# 添加自环
adj = adj + torch.eye(adj.size(0))
# 归一化
adj = adj / adj.sum(dim=1, keepdim=True)
# 更新 gcn_layer 的 adj(必须用 .data 赋值,不破坏梯度)
self.gcn_layer.adj.data = adj
# GCN 层
gcn_output = self.gcn_layer(enc_out) # [B, L, D]
# 分类头
output = self.act(gcn_output)
output = self.dropout(output)
output = output.reshape(output.shape[0], -1) # [B, L*D]
output = self.projection(output) # [B, num_class]
return output
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask=None):
if self.task_name == 'long_term_forecast':
dec_out = self.long_forecast(x_enc, x_mark_enc, x_dec, x_mark_dec)
return dec_out[:, -self.pred_len:, :]
if self.task_name == 'short_term_forecast':
dec_out = self.short_forecast(x_enc, x_mark_enc, x_dec, x_mark_dec)
return dec_out[:, -self.pred_len:, :]
if self.task_name == 'imputation':
return self.imputation(x_enc, x_mark_enc, x_dec, x_mark_dec, mask)
if self.task_name == 'anomaly_detection':
return self.anomaly_detection(x_enc)
if self.task_name == 'classification':
return self.classification(x_enc, x_mark_enc)
return None3.实验数据
多特征列+标签列即可(这里我做的是4分类)
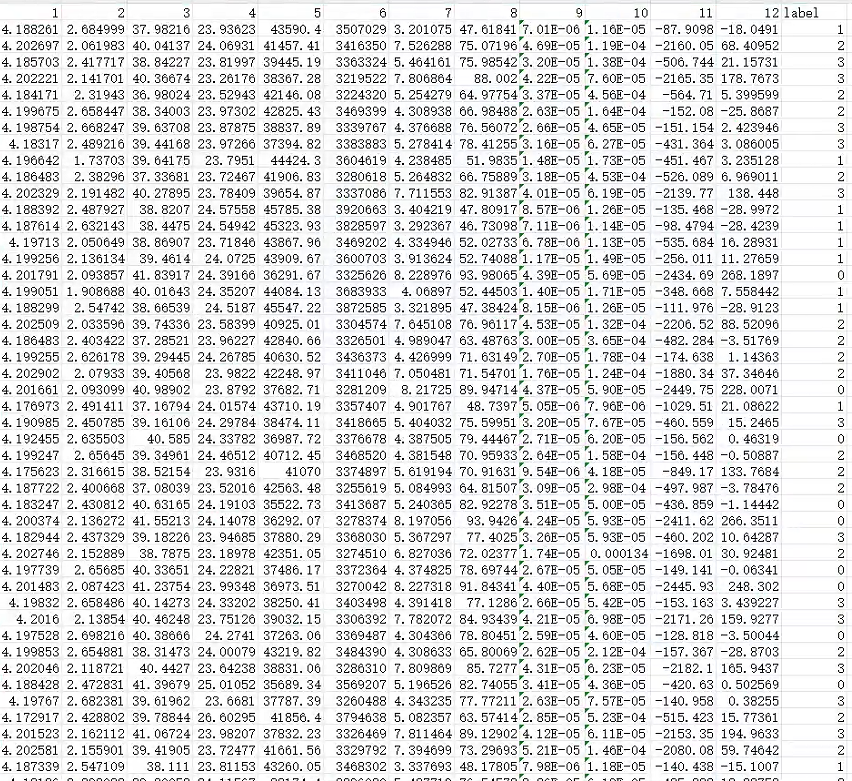
4.实验结果
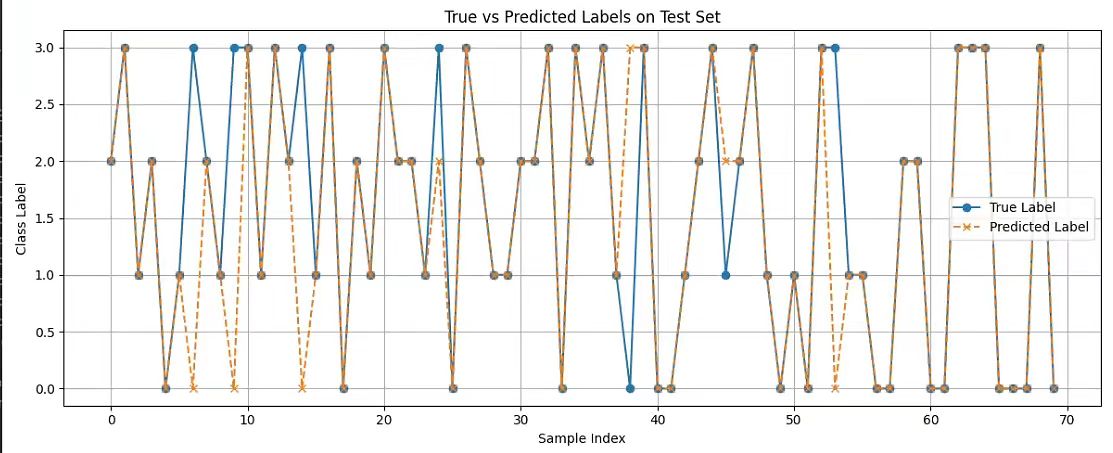
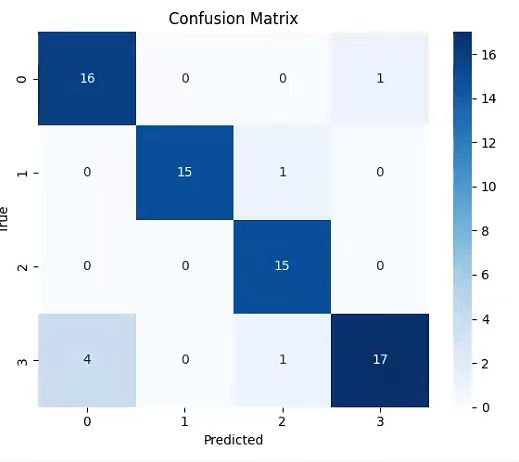
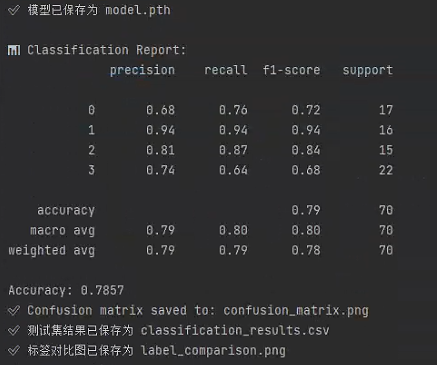
预测准确率中规中矩
5.代码地址及其详细讲解
源码地址:https://space.bilibili.com/51422950?spm_id_from=333.1007.0.0
bili私信up即可