这篇我们会讲一下如何设计和调整自定义监控模板,以及如何配置属于自己的告警规则和通知通道,让监控系统真正"动"起来。
监控那么多指标,我们到底该盯哪些?
Prometheus 和 Grafana 一接上,最常见的做法就是去导入一些官方推荐的监控模板,比如:
- 4701:JVM(Micrometer)监控模板,能看到内存、GC、线程等常规系统指标;
- 11378:Spring Boot Statistics 模板,提供了 Spring Boot 应用级的全套监控项;
- 12900:Micrometer JVM Dashboard 模板,针对 Micrometer 框架做了更详细的 JVM 数据展示。
这些模板确实挺全的,基本上我们想得到的系统和应用指标,它们都帮我们拉了一遍。
但问题也随之而来,我个人觉得主要有这三点:
- 全是英文字段,看起来很费劲
什么jvm_memory_used_bytes、process_cpu_usage、system_load_average_1m......
不说小白,哪怕是开发老手,第一次上来看到这么一堆英文指标,也容易懵。 - 指标太多,不够聚焦
模板里一页页图表,不同时间段、不同类型的折线图铺满整个大盘。
如果我们想找个"当前 CPU 使用率"这种关键指标,反而得翻半天。 - 不贴合我们自己的业务习惯
模板虽然通用,但跟我们具体的项目没啥"情感联系"。
比如我们是做支付的,最关心的可能是下单成功率、支付接口耗时;
模板却没这类内容,全靠自己动手加。
所以,用这些模板没问题,但想让它们真正服务于我们日常运维,还是得改。
我们要做的,是把这些"大而全"的仪表盘,瘦身成一个"小而精"的中文化业务看板。
真正的日常运维,其实就关心几个核心问题:
服务器吃紧了吗?接口卡了吗?数据库慢了吗?服务挂了没?
所以我这边把常见监控指标分了几类,按"我们什么时候真的会点开 Grafana 看一眼"的思路来划分:
- 系统层:机器撑得住吗?
这部分主要是看服务器的基本状态,撑不住,再好的业务逻辑也跑不动。
- CPU 使用率:有没有哪台机器 CPU 飙到 90%+,这是性能瓶颈的第一信号。
- 内存占用:内存是否一直处在高位,有没有频繁 GC、OOM。
- 磁盘空间:别忘了磁盘也是消耗品,满了会直接让服务挂掉。
- 网络流量 / 错误率:有没有接口卡顿、掉包,或者出口流量异常突增。
一句话总结:机器健康,才有一切的可能性。
- 接口层:请求顺不顺?
比如我是主后端开发,最关心的可能就是这一层了,特别是那些关键接口:
- QPS(每秒请求数) :流量有没有明显变化,是否出现打满的风险。
- 响应时间(P99 / 平均) :接口是不是变慢了,用户会不会卡住。
- 错误率(5xx) :有没有突然报错变多,是代码问题还是下游出问题了。
尤其是下单、支付、注册这种关键路径,出点抖动就可能直接影响收入。
这类接口,一定要单独监控,别混在大盘里湮灭了。
- 业务层:项目特有的指标
这部分就属于"别人家用不到,但你家必须盯"的那类指标了,比如:
- 电商系统:今日下单数、支付成功率、新用户数;
- 内容平台:笔记发布量、审核通过率、视频播放时长;
- 游戏项目:抽卡次数、在线人数、道具消耗量;
这些指标在 Prometheus 默认是看不到的,一般都需要我们在代码里埋点,然后通过 MeterRegistry 或 Prometheus Client 主动上报。
但好处是 ------ 它才是真正跟我们业务死死绑在一起的数据,能看得懂、用得上。
- 组件层:中间件稳不稳?
像 Redis、MySQL、RabbitMQ 这些"底层中坚力量",一出问题就牵一发动全身,也建议单独关注它们的运行情况,比如:
- Redis:连接数、内存占用、命中率;
- MySQL:慢查询数、连接数、事务失败数;
- 消息队列:堆积消息数、消费失败数。
这些一般通过官方 Exporter 就能采集,只是需要我们有意识地单独盯一下。
- 实例健康:服务都活着吗?
这是最"底线"的指标了,比如:
- 某个实例是否挂了(up 为 0);
- 服务是否在不断重启;
- 启动时间是否异常短(频繁挂又重启);
建议这类问题直接配告警,一挂就发消息,不需要等人去手动点开 Grafana 发现。
顺带一提:我们之前也讲过怎么自定义业务指标
在上一篇文章中,我们已经实现了 Prometheus 的业务指标埋点,比如订单数、支付成功率等。
这类指标展示是没问题的,但很多人可能也遇到一个小麻烦:
每加一个指标就要新建一个 Dashboard,久而久之满屏都是看板,
找个问题都得想半天:"是 Redis 出问题了?接口慢了?还是订单写不进去了?"
所以这篇我们就顺手把这个问题也解决掉------
把系统指标、接口指标、业务指标、组件指标,全都整合在一个统一大盘中展示。
这样一来,运维、开发、测试,甚至产品都能看一个看板,一眼就能看出当前系统是不是"健康的"。
如何自定义模板导入到 Grafana
前面我们说了那么多"到底该监控哪些指标",那我们就可以自己动手整一个自己需要的监控大盘了。
我这边根据我们刚才分类的几大类指标(系统层、接口层、业务层、组件层、实例健康)写了一个简单的自定义监控模板 Demo ,方便大家直接使用或按需修改。
主要内容包括:
- 系统层:CPU 使用率、内存占用、磁盘使用情况、网络流量等;
- 接口层:QPS、响应时间(P95)、错误率(5xx);
- 业务层:下单数、支付成功率等(这些是我在 Micrometer 里手动埋的点);
- 组件层:Redis 命中率、MySQL 慢查询数等;
- 实例健康:up 状态、重启频率等基本可用性检测;
有了上面的 JSON 模板之后,我们就可以在 Grafana 里一键导入,直接生成我们自己的监控大盘。
第一步:进入 Dashboards 页面
打开我们的 Grafana 后台,点击左侧菜单栏的 Dashboards ,如下图:
第二步:点击右上角的 "New" ➝ 选择 "Import"
进入 Dashboards 页面后,在页面右上角找到那个 "New" 按钮,点击它会弹出下拉框,选择里面的 "Import" 。
第三步:导入模板内容
Grafana 提供两种方式导入:
- 方法一 :直接复制粘贴我们上面提到的
prometheus.json的内容; - 方法二(推荐) :点击 "Upload JSON file",直接上传刚才下载的模板文件。
第四步:选择 Prometheus 数据源
导入模板后,Grafana 会让我们选择一个数据源。这里选择我们之前配置好的 Prometheus 数据源(一般叫 Prometheus,也可以是我们自定义的名字)。
然后点击 "Import" 就完成啦!
导入完成后,我们就能看到这样的效果:
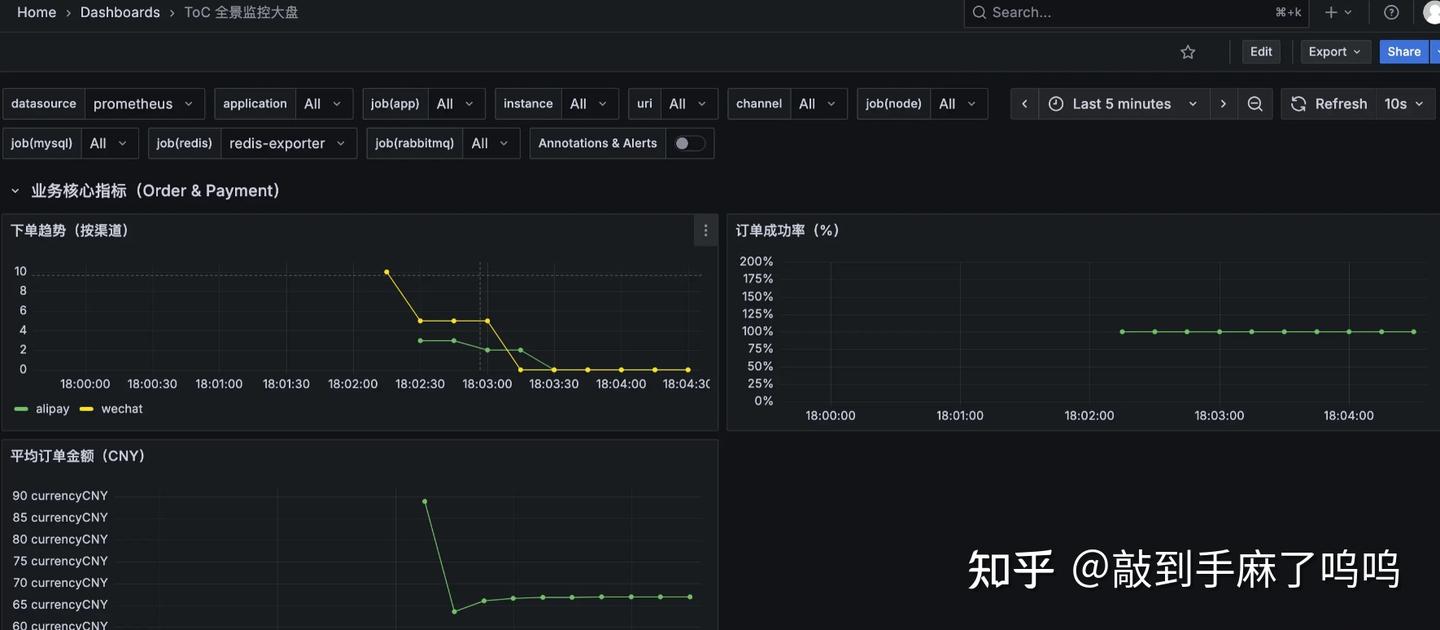
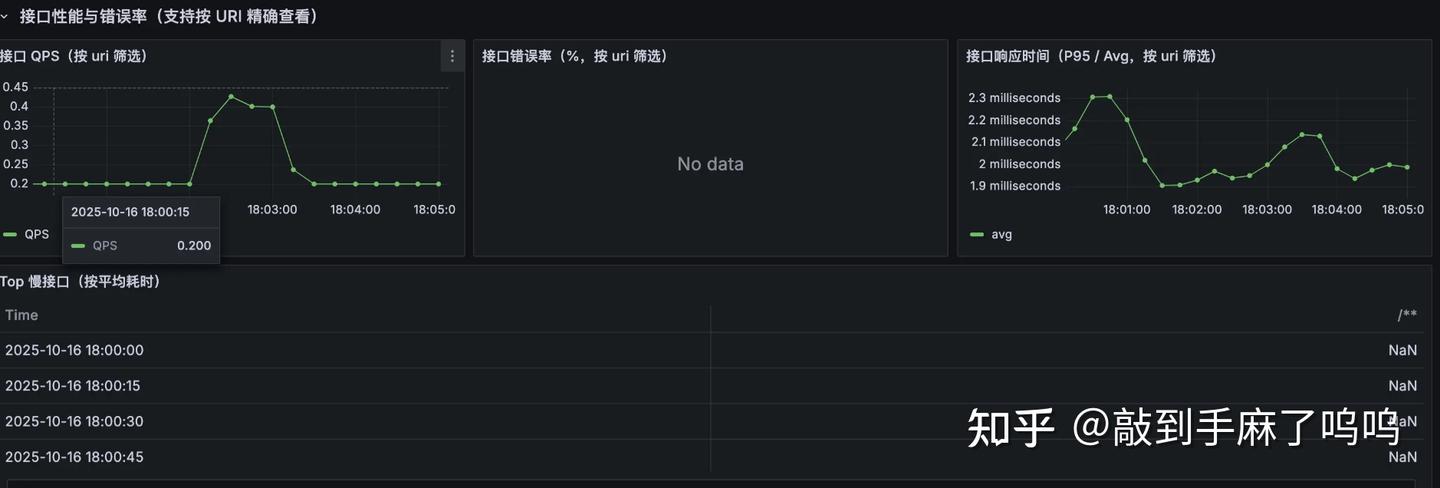
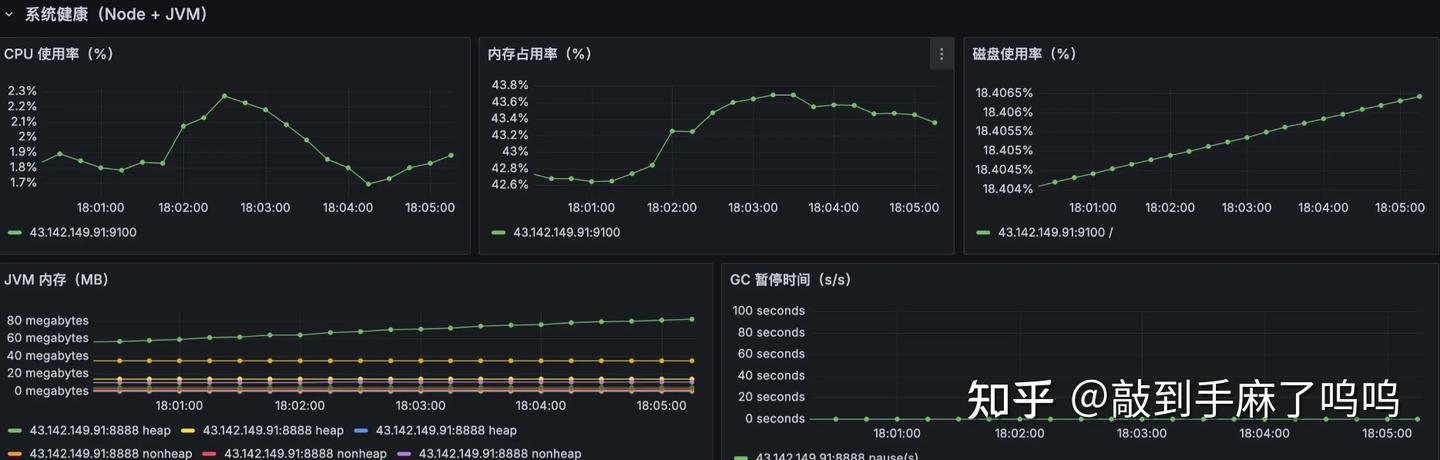
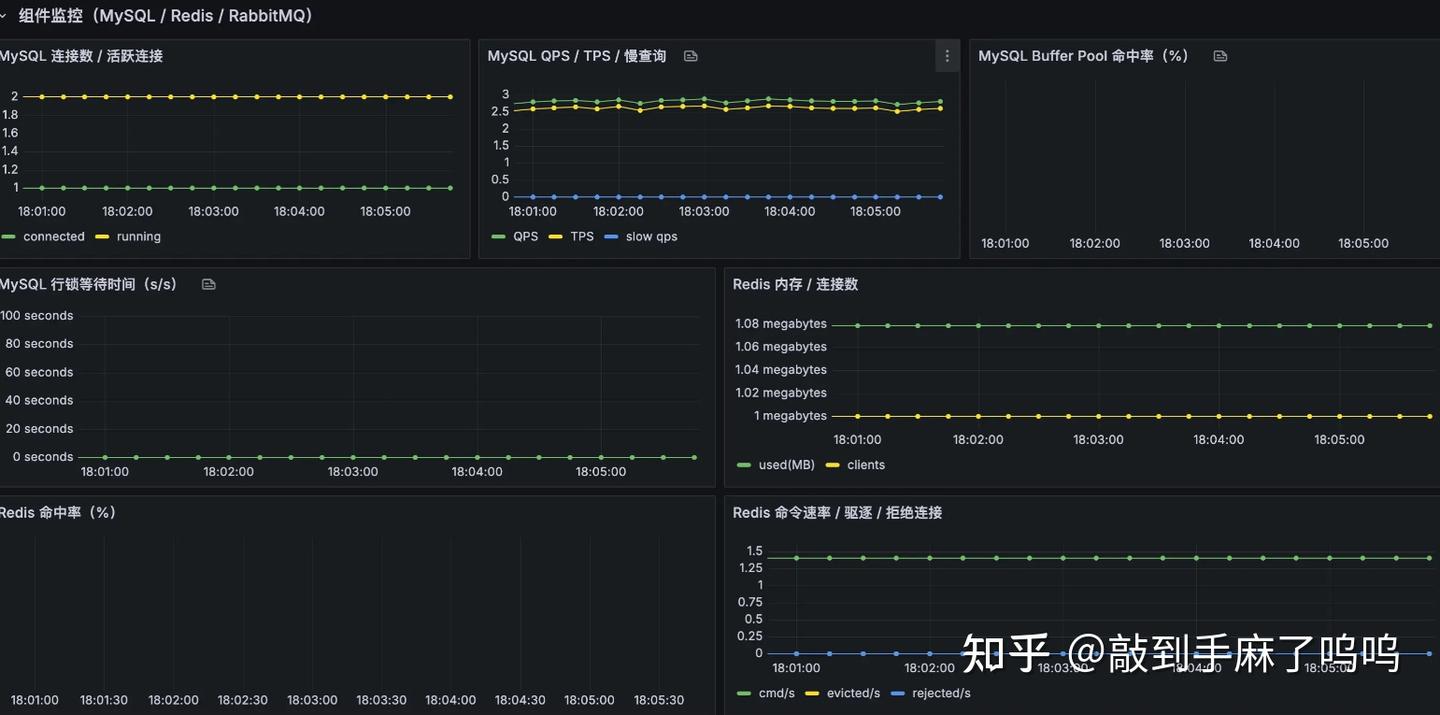
整个看板一目了然,展示的都是我们真正关心、第一时间想看到的关键指标,不管是系统、接口、业务还是组件,都能一眼掌握当前运行情况,排查问题也更有方向感了。
监控报警怎么做?我们先了解整体逻辑
在上文中,我们已经配置好了 Prometheus 和 Grafana,能看到各种系统指标和业务指标了。但这只是「可视化」,真正的监控系统,还需要能主动告诉我们哪里出了问题 ------ 也就是报警机制。
我们整体的报警流程分为三步:
- 定义规则
首先要明确:什么样的情况算是异常?比如:
- CPU 使用率超过 90%,并且持续 2 分钟;
- 接口错误率高于 10%;
- 业务指标异常为 0,比如下单数或支付成功数;
这些条件就是我们需要定义的「报警规则」,通常写在 Prometheus 的rules.yml文件里。
- 触发告警
Prometheus 会周期性地计算这些规则,如果发现条件被满足,就会生成告警事件 ,并发送给 Alertmanager。 - 通知接收人
Alertmanager 收到告警后,会根据配置好的「通知策略」,将告警发送到我们设定的渠道,比如:
- 邮件 / 企业微信 / 钉钉 / 飞书等;
- 或是自定义 webhook 接口,推送到我们的内部告警系统。
大概的流程如下:

流程说明
- Prometheus 定期拉取系统、接口、业务等所有指标(不管有没有报警)
- 根据我们写好的 rules.yml 中的报警规则(比如 CPU > 90% 且持续 2 分钟)做实时判断;
- 如果不满足条件就继续轮询 ;满足条件时,就会生成告警事件;
- 事件会被 发送给 Alertmanager;
- Alertmanager 再根据配置判断要不要通知(比如是否处于静默期?要通知哪个人?什么渠道?)
- 最后,通过我们设定的方式把告警发出去,让相关人第一时间知道出问题了。
配置rule报警规则
在配置 Prometheus 的报警规则之前,我们建议先把整体的目录结构规划好,这样后续的维护会更清晰、也更方便多人协作。
我们可以在项目根目录下准备一个 docker-compose.yml 文件用于一键启动所有监控相关的组件,比如 Prometheus、Grafana、Alertmanager、MySQL、Redis 等。同时,可以把 Prometheus 用到的报警规则单独放在一个 rule/ 目录下,方便分类管理。
整个项目目录结构大致如下:
.
├── alertmanager/ # Alertmanager 配置目录
├── app/ # 应用服务目录(Spring Boot 项目等)
├── docker-compose.yml # Docker Compose 启动入口
├── grafana/ # Grafana 配置目录
├── mysql/ # MySQL 配置目录
├── mysql_exporter/ # MySQL 监控 Exporter
├── prometheus/ # Prometheus 主程序配置
└── rule/ # Prometheus 报警规则文件目录
├── business.rules.yml # 业务类报警(如下单失败率、支付成功率等)
├── system.rules.yml # 系统层指标报警(CPU、内存、磁盘等)
├── component.rules.yml # 中间件相关报警(Redis、MySQL、MQ 等组件)
└── instance.rules.yml # 实例通用报警(服务挂掉、up=0 等基础可用性检测)其中,rule/ 目录是我们自定义的,用来放置 Prometheus 的 .yml 格式报警规则文件。
至于为什么要拆分多个 rule 文件?
主要是为了后期维护更方便。比如我们写了很多报警规则,分散在一个大文件里非常难找。如果按照"业务指标"、"系统资源"、"中间件组件"、"实例通用"这几类来拆分,每类一个文件,后期要新增或修改某类规则就能快速定位到对应的文件。
在前面我们说了要针对不同类型的监控项(业务、系统、组件、实例)分别编写对应的报警规则文件。那么在 Prometheus 中,报警规则必须以一个固定的格式来写,否则 Prometheus 是不会识别的。
我们以一个业务报警为例,比如 "订单失败率过高",真实写法应该长这样:
groups:
- name: business-rules
rules:
- alert: OrderFailRateHigh
expr: sum(rate(order_fail_count_total[1m])) / sum(rate(order_total_count_total[1m])) > 0.2
for: 1m
labels:
severity: warning
category: business
annotations:
summary: "订单失败率过高"
description: "订单失败率超过 20%,请检查支付/库存等模块。"我们来解释一下这段配置是怎么写的:
groups: 表示规则组,一个规则文件里可以有多个组。name: 给这个规则组起个名字,建议和文件名保持一致,比如business.rules.yml就叫business-rules。rules: 这个组下可以有多个具体的报警规则。- 每条规则都需要写:
alert: 报警的名字,比如 "OrderFailRateHigh",建议用驼峰风格,简洁清晰。expr: 触发报警的 PromQL 表达式,这里就是"订单失败率超过 20%"的意思。for: 条件持续多久才触发报警,避免瞬时波动误报。labels: 自定义标签,比如报警等级(warning、critical)或报警类型(business、system)。annotations: 给报警加点说明文字,summary 是标题,description 是详细描述,会显示在告警信息里。
注意:
前面我们举的一些规则示例是单条规则体,为了方便讲解。但真正写入 .yml 文件时,一定要遵守 groups -> rules -> alert 这一层级结构,否则 Prometheus 会报错或者直接忽略这条规则。
我们已经搞清楚了一条报警规则该怎么写,那接下来就来看看 不同类型的报警场景,我们分别该怎么配置这些规则 。
业务类报警(business.rules.yml)
这类规则主要用来监控核心业务流程是否异常 ,比如下单失败、支付异常等。下面这个规则是"订单失败率超过 20%"的报警示例:
groups:
- name: business-rules
rules:
- alert: OrderFailRateHigh
expr: sum(rate(order_fail_count_total[1m])) / sum(rate(order_total_count_total[1m])) > 0.2
for: 1m
labels:
severity: warning
category: business
annotations:
summary: "订单失败率过高"
description: "订单失败率超过 20%,请尽快排查支付或库存等关键模块。"说明:
- 这个规则会在连续 1 分钟内失败率超过 20% 时触发。
- 我们假设业务代码中已经通过 Micrometer 埋了
order_total_count_total和order_fail_count_total两个指标。
系统类报警(system.rules.yml)
系统类的报警规则主要是监控服务器自身的基础资源,比如 CPU、内存和磁盘。如果这些资源使用率过高,服务很容易出现卡顿甚至崩溃,所以这些指标属于最基础也最关键的一类。
groups:
- name: system-rules
rules:
- alert: HighCpuUsage
expr: avg(rate(node_cpu_seconds_total{mode!="idle"}[1m])) by (instance) > 0.9
for: 2m
labels:
severity: warning
category: system
annotations:
summary: "CPU 使用率过高"
description: "{{ $labels.instance }} 的 CPU 使用率超过 90%。"
- alert: HighMemoryUsage
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) > 0.9
for: 2m
labels:
severity: warning
category: system
annotations:
summary: "内存使用率过高"
description: "{{ $labels.instance }} 的内存使用率超过 90%。"
- alert: DiskUsageHigh
expr: (1 - (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"})) > 0.9
for: 2m
labels:
severity: warning
category: system
annotations:
summary: "磁盘使用率过高"
description: "{{ $labels.instance }} 的磁盘使用率超过 90%。"说明一下:
1. CPU 使用率报警(HighCpuUsage)
- PromQL 逻辑:计算过去 1 分钟内每台服务器 CPU 的非空闲时间占比;
- 触发条件:如果平均 CPU 使用率超过 90%,并持续 2 分钟以上,就触发告警;
- 用途:服务器 CPU 跑满会导致系统卡顿或服务响应变慢,这条告警可以第一时间发现。
** 2. 内存使用率报警(HighMemoryUsage)**
- PromQL 逻辑 :通过
MemAvailable / MemTotal来计算剩余内存比例; - 触发条件:内存使用率超过 90%,并持续 2 分钟就报警;
- 用途:内存占用过高容易导致 OOM(内存溢出),服务被系统强制杀死,这种情况必须预警。
3. 磁盘使用率报警(DiskUsageHigh)
- PromQL 逻辑 :用可用空间除以磁盘总大小,排除掉临时分区(如
tmpfs、overlay); - 触发条件:磁盘使用率超过 90%,并持续 2 分钟触发告警;
- 用途:磁盘快满会导致日志无法写入、数据库无法落盘,最终可能直接导致服务中断。
组件类报警(component.rules.yml)
这类规则用来监控依赖的中间件组件 ,比如 Redis、MySQL、MQ 等是否正常运行。
下面是一个 Redis 挂掉的报警规则:
groups:
- name: component-rules
rules:
- alert: RedisDown
expr: redis_up == 0
for: 1m
labels:
severity: critical
category: component
annotations:
summary: "Redis 服务异常"
description: "Redis 连接不上或服务宕机,请检查实例是否存活。"说明:
redis_up是 Redis exporter 提供的指标,值为1表示正常,为0表示挂了。- 如果挂掉超过 1 分钟,就触发报警。
实例类报警(instance.rules.yml)
这类规则是用来判断服务实例是否还在运行 ,比如服务突然挂掉、被 kill 掉了等等。
最常用的就是通过 Prometheus 的 up 指标来判断:
groups:
- name: instance-rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
category: instance
annotations:
summary: "实例存活检测失败"
description: "{{ $labels.instance }} 实例无法连接,可能已经挂掉或被重启。"说明:
up是 Prometheus 默认抓到的存活指标,1表示在线,0表示不在线。- 如果某个实例连续 1 分钟没有被 Prometheus 抓到,就会被认为挂了。
以上就是四类报警规则的典型写法,格式都一致,只是关注的维度不同。我们其实可以根据自己的服务实际情况,把这些规则扩展或细化,比如:
- 添加 P95 响应时间的报警;
- 检测 JVM GC 时间是否异常;
- 组件连接数是否过多等。
怎么让 Prometheus 加载这些报警规则?
前面我们已经把 business.rules.yml、system.rules.yml 等报警规则都写好了,但 Prometheus 默认是不会自动去加载这些规则文件的,我们还需要在主配置文件 prometheus.yml 中,把这些规则"声明"进去
写法一:一条一条写明白
在 prometheus.yml 中增加如下配置:
rule_files:
- "rule/business.rules.yml"
- "rule/system.rules.yml"
- "rule/component.rules.yml"
- "rule/instance.rules.yml"这种方式比较清晰,适合报警规则数量不多的项目。后期如果文件多了、变动频繁,也可以用通配符的写法。
写法二:用通配符统一引入
rule_files:
- "/etc/prometheus/rule/*.yml"上面这种方式表示"把 /etc/prometheus/rule/ 目录下所有 .yml 文件都加载进来",不管是业务报警还是系统报警都能一起加载,方便管理。
但这里有一个重点:比如我们用的是 Docker 启动 Prometheus,那么容器里的路径 /etc/prometheus/rule/ 是需要做映射的。
Docker 启动 Prometheus 时的挂载方式
假设我们在主机上的规则目录是 /opt/monitor/rule/,那我们在 docker-compose.yml 里要这么写:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/monitor/rule:/etc/prometheus/rule
ports:
- "9090:9090"
restart: always
networks:
- monitor-net这样写之后,Prometheus 容器内部就能访问到 /etc/prometheus/rule/*.yml 路径下的所有规则文件了。
- 如果我们希望灵活加载所有规则文件,推荐用通配符方式配合 volume 挂载;
- 如果我们规则文件较少,也可以在
prometheus.yml中一条一条列出来,管理更清晰; - 无论哪种方式,记得重启 Prometheus 容器生效,或者执行热加载接口(后面讲 Alertmanager 的时候我会顺带介绍);
怎么验证规则加载成功?支持热加载吗?
报警规则写完之后,我们需要让 Prometheus 加载这些规则并启动起来。
第一步:重启 Prometheus,让规则生效
如果我们是用 Docker 启动的 Prometheus,最直接的方式就是重启容器。命令如下:
docker compose down
docker compose up -d等容器重新启动后,我们可以打开 Prometheus 的 Web 页面:
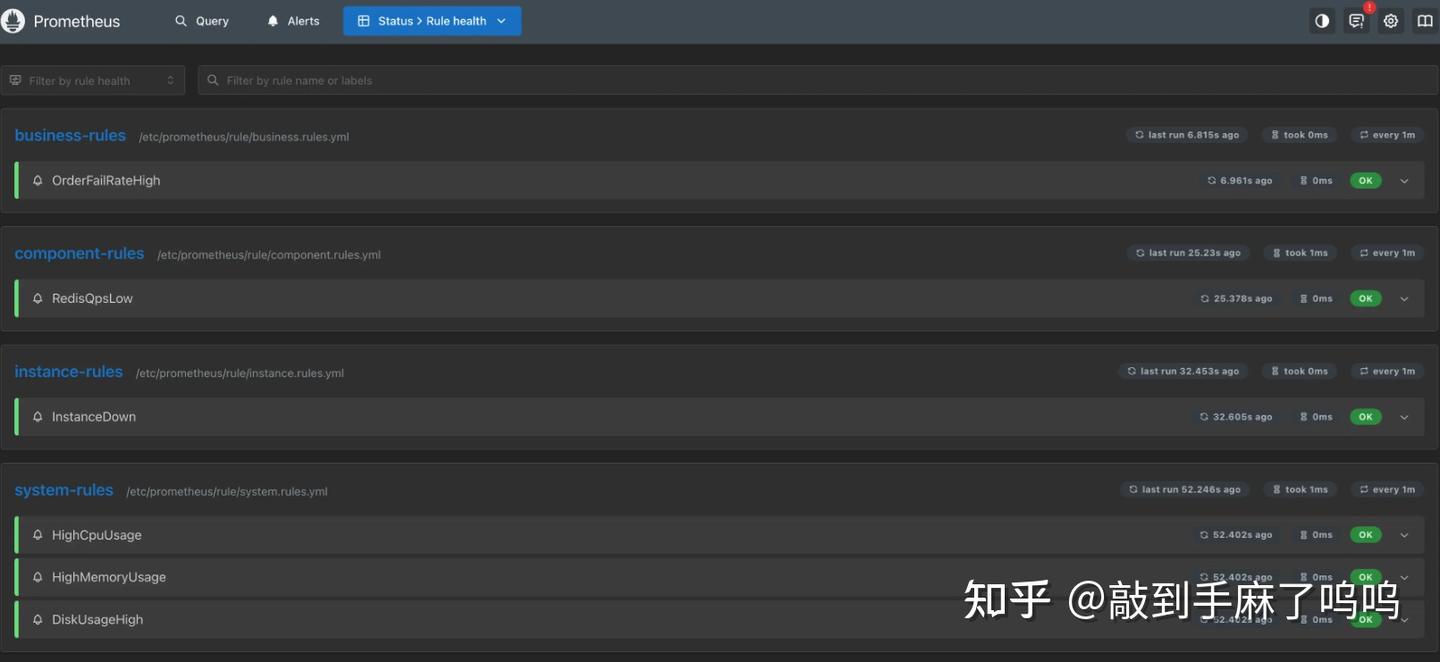
http://43.142.149.91:9090/点击顶部导航栏里的 Status → Rules,就可以看到当前加载进来的所有报警规则了。
如果我们能在页面中看到我们自己写的 business.rules.yml、system.rules.yml 等规则内容,就说明已经加载成功了。
(可选)开启热加载:每次改规则都要重启太麻烦?
有时候我们可能会频繁地调整报警逻辑,比如:
- 某个指标波动太大,想把阈值从 80% 改成 90%
- 新增一个业务指标,想马上生效
这种场景下,如果每次都要 docker compose down && up,显然太重了。
Prometheus 实际上是支持"热加载"的,也就是我们改完规则文件后,不用重启容器,只要"通知"它重新加载一次就行了 。
怎么开启 Prometheus 的热加载功能?
我们只需要在启动参数里加上这一句:
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.enable-lifecycle'如果我们用的是 docker-compose.yml,就在 Prometheus 的配置里加上这个 command 配置项即可。
然后重新启动 Prometheus(只需要加这一次):
docker compose down
docker compose up -d热加载怎么用?
以后每次我们改了规则文件,只要执行这个命令即可:
curl -X POST http://localhost:9090/-/reload这条命令会告诉 Prometheus:"我改规则了,请重新加载一下"。几乎是秒级生效,非常方便。
如果我们在宿主机外部执行,需要把 localhost 改成我们自己机器的 IP,比如:
curl -X POST http://43.142.149.91:9090/-/reload小结一下:
- 初次部署时,用
docker compose up -d启动加载规则; - 如果不改规则,不用动;
- 如果经常调整规则,推荐开启热加载功能,避免每次重启容器。
接下来,我们就来配置报警通知,让告警信息真正能"推送"到我们手里。
常见现象:有的规则状态是 UNKNOWN?
当我们打开 Prometheus 页面,点击 Status → Rules 后,可能会看到类似下图的界面:

我们会注意到:
- system-rules 中的几条报警规则(比如 HighCpuUsage、HighMemoryUsage)状态显示为
OK,说明这些规则已经执行过,并且当前没有触发报警; - 但 business-rules 、component-rules 、instance-rules 中的规则,状态却是
UNKNOWN,而且last run never,也就是这些规则还从来没跑过。
这是不是说明配置错了?
不一定。这个情况很常见,也正常 ,尤其是在我们刚部署完 Prometheus、或者这些指标数据还没上报的时候。
出现 UNKNOWN 的常见原因包括:
- 这些指标还没有数据:
比如我们写了一个 Redis QPS 的报警规则,但此时 Redis Exporter 没启动,Prometheus 里根本没有对应的redis_ops相关指标,那这个规则就无法执行。 - 服务还没有运行过:
比如业务系统还没产生订单数据,那order_total_count和order_fail_count都是空的,自然不会去触发报警计算。 - Prometheus 才刚启动,还没轮到这条规则执行:
每条规则都是按固定时间间隔(默认 1 分钟)去跑的,刚启动时有可能还没到时间。
那该怎么办呢?
我们可以这样判断:
-
如果我们确认组件已经运行,Exporter 也已经部署,并且 Prometheus 已经正常采集到对应的指标,那么可以稍等 1-2 分钟刷新页面看看,状态通常会从 UNKNOWN → OK 或 Firing;
-
如果长时间都是 UNKNOWN,可以打开 Prometheus 的
Graph页面,搜索我们规则里的指标名,比如:rate(order_fail_count_total[1m])
-
如果查询结果是空的,说明这个指标目前确实没有数据,那就需要检查服务是否上报、Exporter 是否接入成功。
总结一下:
OK:规则已生效,当前状态正常;Firing:规则触发了,正在报警;UNKNOWN:规则还没执行,或者执行失败,常见于初次部署或指标缺失。
我们不需要为每个 UNKNOWN 都紧张,观察一下具体指标是否上报,耐心等一分钟后刷新即可判断是否是正常情况。
Alertmanager 报警
我们前面写了很多报警规则,比如"CPU 超过 90%"、"Redis QPS 低于阈值"等,这些规则一旦被触发,Prometheus 确实能检测出来,但它自己是不会发通知的 。
比如我们不会突然收到一条短信说"你的服务器 CPU 爆了",也不会在微信或钉钉上收到提醒。
那谁来负责发这些通知呢?这就是 Alertmanager 的工作。
Alertmanager 是干什么的呢?
我们可以这么理解:
- Prometheus 只负责"判断是否报警",就像医生发现了病情;
- Alertmanager 负责"通知相关人",就像护士打电话告诉病人家属或者医院处理系统。
它的职责包括:
- 接收 Prometheus 发来的报警;
- 把报警做进一步处理(分组、去重、抑制);
- 最终通过我们配置的方式(邮件、钉钉、微信、飞书、PagerDuty、Webhook 等)把消息推送出去。
整体流程是怎样的?
用一句话总结来说:
Prometheus 根据规则判断触发报警 → 通过 HTTP 把报警推给 Alertmanager → Alertmanager 根据配置决定发给谁、怎么发。
也就是说,Prometheus 并不是"直接发通知",而是"转发给 Alertmanager",由 Alertmanager 负责最后一步。
Prometheus 和 Alertmanager 是分开的服务
默认情况 Prometheus 并不会带有 Alertmanager,它们是两个独立的服务,我们就需要:
- 单独启动 Alertmanager(可以通过 Docker 或二进制方式);
- 在 Prometheus 的配置文件
prometheus.yml中,指定 Alertmanager 的地址; - 在 Alertmanager 的配置文件中,定义"接收到哪些报警,怎么发给谁"。
接下来,我们就会一步步来搭建 Alertmanager,并配置最基础的告警通知(比如控制台日志、钉钉、企业微信、飞书等)。
让报警真正能"吵醒人",而不是只停留在 Prometheus 网页上。
Alertmanager 是怎么配置的?
Alertmanager 启动时会读取一个配置文件(一般叫 alertmanager.yml),这个文件里主要定义了:
- 接收到报警后如何分组(比如根据 service、severity 分组)
- 是否需要做去重、抑制(比如不要重复发相同的报警)
- 最关键的:怎么通知到人(通过什么方式、发给谁)
常见的通知方式有哪些呢?
Alertmanager 默认就支持很多种通知方式,比如:
- 钉钉
- 飞书
- 企业微信
- 邮件
- Slack
- Webhook(比如我们接入自己的报警平台)
我们下面以钉钉为例,讲一下怎么配置。
钉钉通知配置示例
假设我们有一个钉钉群,群里配置了"自定义机器人",并拿到了一个 webhook 地址,比如:
https://oapi.dingtalk.com/robot/send?access_token=xxxxxx那我们可以在alertmanager.yml里这样配置:
global:
resolve_timeout: 5m
route:
group_by: ['alertname'] # 相同 alertname 的告警分到一组
group_wait: 10s
group_interval: 30s
repeat_interval: 1h # 相同的告警,至少间隔 1 小时才重复发
receiver: 'dingding-notify' # 默认的通知方式
receivers:
- name: 'dingding-notify'
webhook_configs:
- url: 'https://oapi.dingtalk.com/robot/send?access_token=你的token'
send_resolved: true # 告警恢复时也发送通知这个配置意思是:
- 所有报警默认都走
dingding-notify; dingding-notify使用的是钉钉的 webhook;- 当报警恢复时也会发送一条"恢复通知"。
钉钉机器人默认是不支持 markdown 格式 的,所以建议搭配一个中间服务来美化消息(后面可以讲怎么做)。
其他通知方式也类似
其实,Alertmanager 支持的通知方式,配置方法都差不多,只是换个配置字段而已:
飞书通知(用 webhook):
receivers:
- name: 'feishu-notify'
webhook_configs:
- url: 'https://open.feishu.cn/open-apis/bot/v2/hook/你的token'企业微信:
receivers:
- name: 'wechat-notify'
webhook_configs:
- url: 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=你的key'邮箱:
receivers:
- name: 'email-notify'
email_configs:
- to: 'your@email.com'
from: 'alert@yourdomain.com'
smarthost: 'smtp.yourdomain.com:587'
auth_username: 'alert@yourdomain.com'
auth_password: '授权码/邮箱密码'说明:邮箱配置比较繁琐,涉及 SMTP 发件服务器和鉴权,适合已经有企业邮箱系统的情况。
那配置好后怎么办?
我们只需要:
-
把
alertmanager.yml放到对应的容器挂载目录下; -
修改
docker-compose.yml启动 Alertmanager 服务; -
在 Prometheus 的配置文件里,指定 Alertmanager 的地址:
alerting:
alertmanagers:
- static_configs:
- targets:
- 'alertmanager:9093'
这样,Prometheus 一旦触发告警,就会把报警信息推送到 Alertmanager,然后再由 Alertmanager 发送到我们配置的钉钉、飞书、邮箱等等。
后面如果我们有多个接收人、多个服务(比如不同服务走不同钉钉群),也可以配置多个 receiver 并通过 route 做路由控制,我们后面可以专门写一章来讲解这个。
我们来测试下:用 QQ 邮箱接收报警通知
报警规则写完后,光在 Prometheus 页面里看到还不够,我们更关心的是:出问题的时候,系统能不能第一时间通过邮件、钉钉、微信这些方式把告警通知我们。
那我们就先从最基础、最通用的 ------ QQ 邮箱报警通知 开始配置。
一、准备工作:开启 QQ 邮箱的 SMTP 发信功能
Prometheus 的告警发送是由 Alertmanager 这个组件来完成的,而 Alertmanager 本质上就是个"通知分发器",我们要告诉它怎么去发邮件,它才能帮我们把消息转出去。
步骤如下:
- 登录 QQ 邮箱:mail.qq.com
- 点右上角「设置」>「账户」
- 拉到底,找到「POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务」那一栏
- 把 SMTP服务开启
- 开启后会生成一个"授权码"字符串,这就是我们后面要用的发信密码
注意哦:这个授权码不是 QQ 登录密码,而是用于程序发信的专用密码,只展示一次,记得复制保存!
二、Alertmanager 邮箱通知配置示例(完整配置)
然后我们来配置 alertmanager.yml 文件,让它支持发邮件。内容如下:
global:
smtp_smarthost: 'smtp.qq.com:587' # SMTP 服务地址 + 端口
smtp_from: 'luokakale@qq.com' # 发件人(我们自己的 QQ 邮箱)
smtp_auth_username: 'luokakale@qq.com' # 登录账号
smtp_auth_password: '*********' # 上一步获取的授权码
route:
receiver: 'email'
group_wait: 10s # 首次等待 10 秒再发送(防止瞬时抖动)
group_interval: 30s # 同组告警间隔时间
repeat_interval: 30m # 同一条告警 30 分钟内最多发一次
receivers:
- name: 'email'
email_configs:
- to: 'luokakale@qq.com' # 接收人(可以写成我们自己的邮箱或团队邮箱)
send_resolved: true # 告警恢复时也发通知三、挂载 Alertmanager 服务(Docker 方式)
比如我们是用 docker-compose.yml 来部署监控系统的,可以像下面这样配置 Alertmanager 服务:
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
ports:
- "9093:9093"
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
restart: always
networks:
- monitor-net把我们写好的 alertmanager.yml 放到 ./alertmanager 目录下,确保路径和挂载位置一致。
四、Prometheus 告诉它去哪发报警
记得在 prometheus.yml 里加上以下内容,告诉 Prometheus 报警要发给谁:
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']这里的 alertmanager 就是容器名,端口默认是 9093。
五、快速验证:写一个假报警测试一下
我们可以在任意一个 .rules.yml 文件中加入一个测试用的报警规则:
groups:
- name: test
rules:
- alert: AlwaysFiring
expr: vector(1)
for: 10s
labels:
severity: warning
annotations:
summary: "测试邮件报警"
description: "这个是用来测试邮件通知功能的报警规则"然后执行:
docker compose down
docker compose up -d等我们把 Prometheus、Alertmanager 和邮箱配置都搞定之后,执行 docker compose up -d 启动服务,然后静静等待十几秒。
如果前面的报警规则命中了,比如我们设置了"内存使用率超过 90%"的规则,那我们应该就能在邮箱里收到一封报警邮件。
像我这里就成功收到了报警通知邮件:

这说明我们整个监控报警链路已经跑通了:
此外,我们也可以直接打开 Alertmanager 页面查看告警情况,默认地址是:
http://localhost:9093在这个页面中,我们可以看到最新出现的告警,比如InstanceDown(服务实例宕机)、RedisQpsLow(Redis QPS 过低)等,非常方便调试和验证。
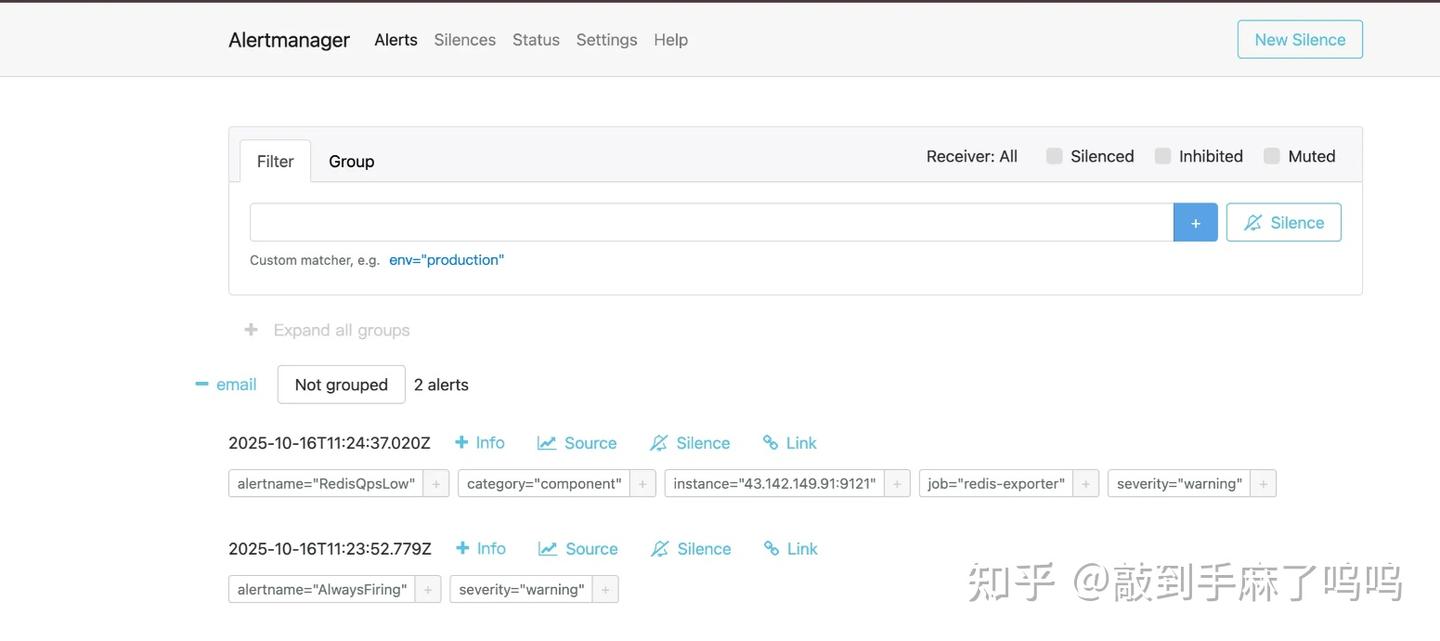
- Redis 探针的 QPS 过低触发了
RedisQpsLow告警 - 演示用的
AlwaysFiring告警也一并展示了出来 - 告警都按照我们配置的方式,发到了
email接收器上
这说明我们的整个监控报警链路已经跑通了:
- Prometheus 成功采集到指标数据;
- 自定义的报警规则被触发;
- Alertmanager 正确接收到了告警信息;
- 并通过配置的方式,把告警推送到了邮箱。
如果是集群部署,该怎么配置?
如果我们的服务是多实例、集群部署的,那监控配置也要跟着做一些调整:
-
exporter 要部署在每台机器上 ,比如我们要监控多台服务器的资源情况,那每台服务器上都要跑一个
node_exporter,这样 Prometheus 才能采集到每个节点的 CPU、内存、磁盘等信息。 -
Prometheus 的
scrape_configs要配置多个 job 或多个 target,确保能抓到所有机器或服务的指标。例如:scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['192.168.1.10:9100', '192.168.1.11:9100']
- job_name: 'app'
static_configs:
- targets: ['192.168.1.10:8080', '192.168.1.11:8080'] -
如果服务是容器化部署在 Kubernetes 或 Docker Swarm 上,可以通过服务发现(如 k8s_sd_config、file_sd_config)自动发现目标,不用手动写死 IP。
-
报警规则中可以使用
instance或job维度进行聚合 ,比如可以用by(instance)来观察单台机器的状态,或者用by(job)看服务整体的表现。
简单来说:集群模式下,我们要监控的对象多了,Prometheus 就要配置更多的采集目标,报警规则也要考虑到多个实例的聚合、分组。只要这个思路清楚了,配置起来并不难
项目结构说明(附录)
为了便于同学一起交流学习,下面是我在本次项目中的目录结构,整体如下:
.
├── alertmanager/ # Alertmanager 配置目录
│ └── alertmanager.yml # 告警路由和通知渠道配置文件
├── app/ # 我们自己的 Java 项目(业务服务)
├── docker-compose.yml # 整体服务编排配置
├── grafana/ # Grafana 配置目录
│ └── data/ # 持久化数据目录
├── mysql/
│ ├── conf.d/ # MySQL 配置文件目录
│ └── data/ # MySQL 持久化数据目录
├── mysql_exporter/ # 监控 MySQL 的 exporter(暂未配置)
├── prometheus/
│ └── prometheus.yml # Prometheus 主配置文件
└── rule/ # Prometheus 告警规则目录
├── business.rules.yml # 业务类报警规则(如订单失败率)
├── component.rules.yml # 中间件报警(如 Redis、MySQL)
├── instance.rules.yml # 实例级别报警(如 up=0)
├── system.rules.yml # 系统资源报警(CPU、内存等)
└── test.rules.yml # 自定义测试用规则docker-compose.yml(服务编排文件)
下面是我们这套 Prometheus + Alertmanager + Grafana 的服务组合的 docker-compose 文件示例:
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/monitor/rule:/etc/prometheus/rule
ports:
- "9090:9090"
restart: always
networks:
- monitor-net
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
volumes:
- ./grafana/data:/var/lib/grafana
restart: always
networks:
- monitor-net
mysql:
image: mysql:8.0
container_name: mysql
environment:
MYSQL_ROOT_PASSWORD: root123
MYSQL_DATABASE: monitor_demo
ports:
- "3306:3306"
volumes:
- ./mysql/data:/var/lib/mysql
- ./mysql/conf.d:/etc/mysql/conf.d
restart: always
networks:
- monitor-net
mysql_exporter:
image: prom/mysqld-exporter:latest
container_name: mysql_exporter
restart: always
ports:
- "9104:9104"
command:
- '--config.my-cnf=/etc/mysql_exporter/.my.cnf'
volumes:
- ./mysql_exporter/.my.cnf:/etc/mysql_exporter/.my.cnf:ro
depends_on:
- mysql
networks:
- monitor-net
redis:
image: redis:latest
container_name: redis
ports:
- "6379:6379"
restart: always
networks:
- monitor-net
redis_exporter:
image: oliver006/redis_exporter:latest
container_name: redis_exporter
ports:
- "9121:9121"
environment:
- REDIS_ADDR=redis://redis:6379
restart: always
networks:
- monitor-net
node_exporter:
image: prom/node-exporter:latest
container_name: node_exporter
restart: always
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
networks:
- monitor-net
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
ports:
- "9093:9093"
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
restart: always
networks:
- monitor-net
networks:
monitor-net:
driver: bridgealertmanager.yml(邮件告警配置示例)
global:
smtp_smarthost: 'smtp.qq.com:587'
smtp_from: 'luokakale@qq.com'
smtp_auth_username: 'luokakale@qq.com'
smtp_auth_password: '******' # 这是 QQ 邮箱授权码
route:
receiver: 'email'
group_wait: 10s
group_interval: 30s
repeat_interval: 30m
receivers:
- name: 'email'
email_configs:
- to: 'luokakale@qq.com'
send_resolved: trueprometheus.yml(Prometheus 主配置文件)
global:
scrape_interval: 5s # 每 5 秒抓取一次指标
rule_files:
- "/etc/prometheus/rule/*.yml"
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
scrape_configs:
- job_name: 'monitor-demo'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['43.142.149.91:8888']
- job_name: 'redis-exporter'
static_configs:
- targets: ['43.142.149.91:9121']
- job_name: 'node-exporter'
static_configs:
- targets: ['43.142.149.91:9100']
- job_name: 'mysql-exporter'
static_configs:
- targets: ['mysql_exporter:9104']说明:
- 通过
rule_files加载报警规则目录; alerting.alertmanagers配置通知地址;scrape_configs配置要采集的服务指标源(比如 Prometheus 自己、MySQL Exporter);
最后絮絮念
到这里,我们就完整搭建了一套 Prometheus + Alertmanager 的监控告警体系,整体流程也已经跑通了。