集合框架(二)
此笔记参考黑马教程,仅学习使用,如有侵权,联系必删
文章目录
- 集合框架(二)
-
- [6. 注意事项:集合的并发修改异常问题](#6. 注意事项:集合的并发修改异常问题)
-
- [怎么保证遍历集合同时删除数据时不出 bug?](#怎么保证遍历集合同时删除数据时不出 bug?)
- 代码演示
- [7. Collection 的其他相关知识](#7. Collection 的其他相关知识)
-
- [7.1 前置知识:可变参数](#7.1 前置知识:可变参数)
-
- [7.1.1 可变参数的特点和好处](#7.1.1 可变参数的特点和好处)
- [7.1.2 可变参数的注意事项](#7.1.2 可变参数的注意事项)
- 代码演示
- [7.2 Collections](#7.2 Collections)
- 综合案例:斗地主游戏
- [8. Map 集合(键值对集合)](#8. Map 集合(键值对集合))
-
- [8.1 概述](#8.1 概述)
-
- [8.1.1 Map 集合在什么业务场景下使用](#8.1.1 Map 集合在什么业务场景下使用)
- [8.1.2 Map 集合体系](#8.1.2 Map 集合体系)
- [8.1.3 Map 集合体系的特点](#8.1.3 Map 集合体系的特点)
- 代码演示
- [8.2 常用方法](#8.2 常用方法)
-
- [8.2.1 Map 的常用方法如下:](#8.2.1 Map 的常用方法如下:)
- 代码演示
- [8.3 遍历方式](#8.3 遍历方式)
- [8.4 HashMap](#8.4 HashMap)
- [8.5 LinkedHashMap](#8.5 LinkedHashMap)
-
- [8.5.1 LinkedHashMap 的底层原理](#8.5.1 LinkedHashMap 的底层原理)
- [8.6 TreeMap](#8.6 TreeMap)
-
- [8.6.1 TreeMap 集合同样也支持两种方式来指定排序规则](#8.6.1 TreeMap 集合同样也支持两种方式来指定排序规则)
- 代码演示
- [8.7 补充知识:集合的嵌套](#8.7 补充知识:集合的嵌套)
- [9. Stream 流](#9. Stream 流)
-
- [9.1 认识 Stream](#9.1 认识 Stream)
-
- [9.1.1 体验 Stream 流](#9.1.1 体验 Stream 流)
- [9.1.2 Stream 流的使用步骤](#9.1.2 Stream 流的使用步骤)
- [9.2 Stream 的常用方法](#9.2 Stream 的常用方法)
6. 注意事项:集合的并发修改异常问题
- 使用迭代器遍历集合时,又同时在删除集合中的数据,程序就会出现并发修改异常的错误
- 由于增强 for 循环遍历集合就是迭代器遍历集合的简化写法,因此,使用增强 for 循环遍历集合,又在同时删除集合中的数据时,程序也会出现并发修改异常的错误
怎么保证遍历集合同时删除数据时不出 bug?
- 使用迭代器遍历集合,但用迭代器自己的删除方法删除数据即可
- 如果能用 for 循环遍历时:可以倒着遍历并删除;或者从前往后遍历,但删除元素后做
i--操作
代码演示
java
package Advanced.e_collection.d5_collection_exception;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* 目标:理解集合的并发修改异常问题,并解决
*/
public class Collection_exception {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
System.out.println(list); // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]
// 需求:找出集合中全部带"李"的名字,并从集合中删除
// Iterator<String> it = list.iterator();
// while (it.hasNext()) {
// String name = it.next();
// if (name.contains("李")) {
// list.remove(name);
// }
// }
// System.out.println(list); // 报错
// 使用for循环遍历集合并删除集合中带李字的名字
// for (int i = 0; i < list.size(); i++) {
// String name = list.get(i);
// if (name.contains("李")){
// list.remove(name);
// }
// }
// System.out.println(list);
System.out.println("------------------------------------");
// 怎么解决呢?
// 使用for循环遍历集合并删除集合中带李字的名字
// for (int i = 0; i < list.size(); i++) {
// String name = list.get(i);
// if (name.contains("李")){
// list.remove(name);
// i--;
// }
// }
// System.out.println(list); // [王麻子, 张全蛋]
// 倒着删除也是可以的
// 需求:找出集合中全部带"李"的名字,并从集合中删除
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String name = it.next();
if (name.contains("李")) {
// list.remove(name); // 并发修改异常的错误
it.remove(); // 删除迭代器当前遍历到的数据,没删除一个数据后,相当于也在底层做了i--
}
}
System.out.println(list); // [王麻子, 张全蛋]
// 使用增强for循环遍历集合并删除数据,没有办法解决bug
// for (String name : list) {
// if (name.contains("李")) {
// list.remove(name);
// }
// }
// System.out.println(list); // 报错
// Lambda表达式也不行
// list.forEach(name ->{
// if (name.contains("李")){
// list.remove(name);
// }
// });
// System.out.println(list); // 报错
}
}7. Collection 的其他相关知识
7.1 前置知识:可变参数
- 就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:
数据类型... 参数名称;
7.1.1 可变参数的特点和好处
- 特点:可以不传数据给它;可以传一个或者同时传多个数据给它;也可以传一个数组给它
- 好处:常常用来灵活的接收数据
7.1.2 可变参数的注意事项
- 可变参数在方法内部就是一个数组
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
代码演示
java
package Advanced.f_parameter.d1_parameter;
import java.util.Arrays;
/**
* 目标:认识可变参数,掌握其作用
*/
public class ParamTest {
public static void main(String[] args) {
// 特点:
test(); // 不传数据
test(10); // 传输一个数据
test(10, 20, 30); // 传输多个数据
test(new int[]{10, 20, 30, 40}); // 传输一个数组
}
// 注意事项1:一个形参列表中,只能有一个可变参数
// 注意事项2:可变参数必须放在形参列表的最后面
public static void test(int... nums) {
// 可变参数在方法内部,本质就是一个数组
System.out.println(nums.length); // 长度属性是数组专有的
System.out.println(Arrays.toString(nums));
System.out.println("---------------------------------------");
}
}7.2 Collections
- 是一个用来操作集合的工具类
7.2.1 Collections 提供的常用静态方法
| 方法名称 | 说明 |
|---|---|
| public static boolean addAll(Collection<? super T> c, T... elements) | 给集合批量添加元素 |
| public static void shuffle(List<?> list) | 打乱 List 集合中的元素顺序 |
| public static void sort(List list) | 对 List 集合中的元素进行升序排序 |
| public static void sort(List list, Comparator<? super T> c) | 对 List 集合中元素,按照比较器对象指定的规则进行排序 |
7.2.2 Collections 只能支持对 List 集合进行排序
排序方式1
| 方法名称 | 说明 |
|---|---|
| public static void sort(List list) | 对 List 集合中元素按照默认规则排序 |
注意:本方法可以直接对自定义类型的 List 集合排序,但自定义类型必须实现了 Comparable 接口,指定了比较规则才可以
排序方式2
| 方法名称 | 说明 |
|---|---|
| public static void sort(List list, Comparator<? super T> c) | 对 List 集合中元素,按照比较器对象指定的规则进行排序 |
代码演示
java
package Advanced.g_collections;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/**
* mb:掌握Collections集合工具类的使用
*/
public class CollectionsTest1 {
public static void main(String[] args) {
// 1. public static <T> boolean addAll(Collection<? super T> c, T... elements):给集合批量添加元素
List<String> names = new ArrayList<>();
Collections.addAll(names, "张三", "王五", "李四", "张麻子");
System.out.println(names); // [张三, 王五, 李四, 张麻子]
// 2. public static void shuffle(List<?> list):打乱 List 集合中的元素顺序
Collections.shuffle(names);
System.out.println(names); // [王五, 李四, 张三, 张麻子]
// 3. public static <T> void sort(List<T> list):对 List 集合中的元素进行升序排序
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(5);
list.add(2);
Collections.sort(list);
System.out.println(list); // [2, 3, 5]
List<Student> students = new ArrayList<>();
students.add(new Student("蜘蛛精", 23, 169.7));
students.add(new Student("紫霞", 22, 169.8));
students.add(new Student("至尊宝", 26, 165.5));
students.add(new Student("牛魔王", 22, 183.5));
// Collections.sort(students);
// System.out.println(students);
// 4. public static <T> void sort(List<T> list, Comparator<? super T> c):对 List 集合中元素,按照比较器对象指定的规则进行排序
Collections.sort(students, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return Double.compare(o1.getHeight(), o2.getHeight());
}
});
System.out.println(students);
}
}综合案例:斗地主游戏
分析业务需求:
- 总共有54张牌
- 点数:"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"
- 花色:"♠", "♥", "♣", "♦"
- 大小王:"👲", "🃏"
- 斗地主:发51张牌,剩下3张作为底牌
分析实现
- 在启动游戏房间的时候,应该提前准备好54张牌
- 接着,需要完成洗牌、发牌、对牌排序、看牌
代码实现
- Card.java
java
package Advanced.g_collections.d2_collections_test;
public class Card {
private String number;
private String color;
// 每张牌是存在大小的
private int size; // 0 1 2 ...
public Card() {
}
public Card(String number, String color, int size) {
this.number = number;
this.color = color;
this.size = size;
}
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public int getSize() {
return size;
}
public void setSize(int size) {
this.size = size;
}
@Override
public String toString() {
return color + number;
}
}- Room.java
java
package Advanced.g_collections.d2_collections_test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Room {
// 必须有一副牌
private List<Card> allCards = new ArrayList<>();
public Room() {
// 1. 做出54张牌,存入到集合allCards
// a、点数:个数确定了,类型确定
String[] numbers = {"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};
// b、花色:个数确定了,类型确定
String[] colors = {"♠", "♥", "♣", "♦"};
int size = 0; // 表示每张牌的大小
// c、遍历点数,再遍历花色,组织牌
for (String number : numbers) {
size++;
for (String color : colors) {
// 得到一张牌
Card c = new Card(number, color, size);
allCards.add(c); // 存入了牌
}
}
// 单独存入大小王的
Card c1 = new Card("", "🃏", ++size);
Card c2 = new Card("", "👲", ++size);
Collections.addAll(allCards, c1, c2);
System.out.println("新牌:" + allCards);
}
/**
* 游戏启动
*/
public void start() {
// 1. 洗牌:allCards
Collections.shuffle(allCards);
System.out.println("洗牌后" + allCards);
// 2. 发牌:首先肯定要定义三个玩家。
List<Card> linHuChong = new ArrayList<>();
List<Card> jiuMoZhi = new ArrayList<>();
List<Card> renYingYing = new ArrayList<>();
// 正式发牌给这三个玩家,依次发出51张牌,剩余三张作为底牌
for (int i = 0; i < allCards.size() - 3; i++) {
Card c = allCards.get(i);
// 判断牌发给谁
if (i % 3 == 0) {
// 请啊冲接牌
linHuChong.add(c);
} else if (i % 3 == 1) {
// 请啊鸠接牌
jiuMoZhi.add(c);
} else if (i % 3 == 2) {
// 请盈盈接牌
renYingYing.add(c);
}
}
// 3. 对三个玩家的牌进行排序
sortCards(linHuChong);
sortCards(jiuMoZhi);
sortCards(renYingYing);
// 4. 看牌
System.out.println("啊冲:" + linHuChong);
System.out.println("啊鸠:" + jiuMoZhi);
System.out.println("盈盈:" + renYingYing);
List<Card> lastThreeCards = allCards.subList(allCards.size() - 3, allCards.size()); // 51 52 53
System.out.println("底牌:" + lastThreeCards);
jiuMoZhi.addAll(lastThreeCards);
sortCards(jiuMoZhi);
System.out.println("啊鸠抢到地主后" + jiuMoZhi);
}
/**
* 集中进行排序
*
* @param cards
*/
private void sortCards(List<Card> cards) {
Collections.sort(cards, new Comparator<Card>() {
@Override
public int compare(Card o1, Card o2) {
return o1.getSize() - o2.getSize(); // 升序
}
});
}
}- GameDemo.java
java
package Advanced.g_collections.d2_collections_test;
/**
* 目标:斗地主游戏的案例开发
* 分析业务需求:
* 总共有54张牌
* 点数:"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"
* 花色:"♠", "♥", "♣", "♦"
* 大小王:"👲", "🃏"
* 斗地主:发51张牌,剩下3张作为底牌
*/
public class GameDemo {
public static void main(String[] args) {
// 1. 牌类
// 2. 房间
Room m = new Room();
// 3. 启动游戏
m.start();
}
}8. Map 集合(键值对集合)
8.1 概述
- Map 集合称为双列集合,格式:
{key1=value1, key2=value2, key3=value3, ...},一次需要存一对数据做为一个元素 - Map 集合的每个元素 "key=value" 称为一个键值对/键值对对象/一个 Entry 对象,Map 集合也被叫做 "键值对集合"
- Map 集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值

8.1.1 Map 集合在什么业务场景下使用
- 购物车
- {商品1=2, 商品2=3, 商品3=2, 商品4=3}
需要存储一一对应的数据时,就可以考虑使用 Map 集合来做
8.1.2 Map 集合体系
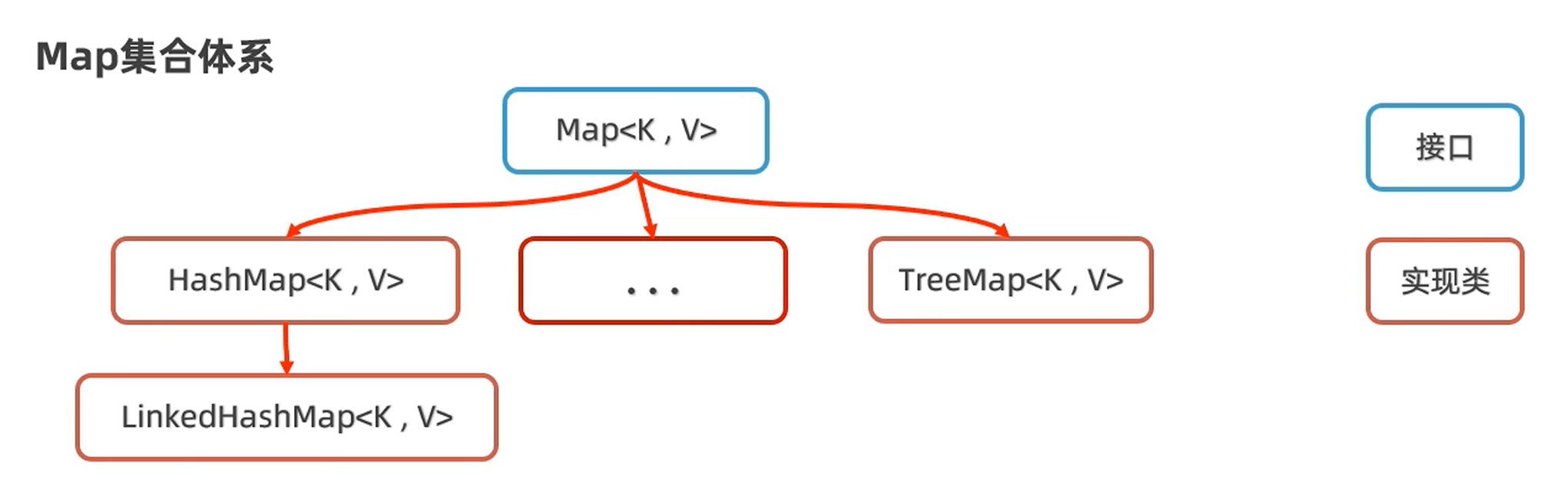
8.1.3 Map 集合体系的特点
注意:Map 系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap(由键决定特点):无序、不重复、无索引;(用的最多)
- LinkedHashMap(由键决定特点):由键决定的特点:有序、不重复、无索引
- TreeMap(由键决定特点):按照大小默认升序排序、不重复、无索引
代码演示
java
package Advanced.h_map.d1_map;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
/**
* 目标:掌握Map集合的特点
*/
public class MapTest1 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>(); // 一行经典代码 按照键 无序、不重复、无索引
map.put("手表", 100);
map.put("手表", 220); // 后面重复的数据会覆盖前面的数据(键)
map.put("手机", 2);
map.put("Java", 2);
map.put(null, null);
System.out.println(map); // {null=null, 手表=220, Java=2, 手机=2}
System.out.println("--------------------------------------");
Map<String, Integer> map2 = new LinkedHashMap<>(); // 有序、不重复、无索引
map2.put("手表", 100);
map2.put("手表", 220); // 后面重复的数据会覆盖前面的数据(键)
map2.put("手机", 2);
map2.put("Java", 2);
map2.put(null, null);
System.out.println(map2); // {手表=220, 手机=2, Java=2, null=null}
Map<Integer, String> map1 = new TreeMap<>(); // 可排序、不重复、无索引
map1.put(23, "Java");
map1.put(23, "MySQL");
map1.put(19, "李四");
map1.put(20, "王五");
System.out.println(map1); // {19=李四, 20=王五, 23=MySQL}
}
}8.2 常用方法
- Map 是双列集合的祖宗,它的功能是全部双列集合都可以继承过来使用的
8.2.1 Map 的常用方法如下:
| 方法名称 | 说明 |
|---|---|
| public V put(K key, V value) | 添加元素 |
| public int size() | 获取集合的大小 |
| public void clear() | 清空集合 |
| public boolean isEmpty() | 判断集合是否为空,为空返回 true,反之 |
| public V get(Object key) | 根据键获取对应值 |
| public V remove(Object key) | 根据键删除整个元素(删除键会返回键的值) |
| public boolean containsKey(object key) | 判断是否包含某个键,包含返回 true,反之 |
| public boolean containsValue(Object value) | 判断是否包含某个值 |
| public Set keySet() | 获取 Map 集合的全部键 |
| public Collection values() | 获取 Map 集合的全部值 |
代码演示
java
package Advanced.h_map.d1_map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapTest2 {
public static void main(String[] args) {
// 1. 添加元素:无序、不重复、无索引
Map<String, Integer> map = new HashMap<>();
map.put("手表", 100);
map.put("手表", 220);
map.put("手机", 2);
map.put("Java", 2);
map.put(null, null);
System.out.println(map); // {null=null, 手表=220, Java=2, 手机=2}
// 2. public int size():获取集合的大小
System.out.println(map.size()); // 4
// 3. public void clear():清空集合
// map.clear();
System.out.println(map); // {}
// 4. public boolean isEmpty():判断集合是否为空,为空返回true,反之
System.out.println(map.isEmpty()); // false
// 5. public V get(Object key):根据键获取对应值
int v1 = map.get("手表");
System.out.println(v1); // 220
System.out.println(map.get("手机")); // 2
System.out.println(map.get("张三")); // null
// 6. public V remove(Object key):根据键删除整个元素(删除键会返回键的值)
System.out.println(map.remove("手表")); // 220
System.out.println(map); // {null=null, Java=2, 手机=2}
// 7. public boolean containsKey(object key):判断是否包含某个键,包含返回true,反之
System.out.println(map.containsKey("手表")); // false
System.out.println(map.containsKey("java")); // false
System.out.println(map.containsKey("Java")); // true
// 8. public boolean containsValue(Object value):判断是否包含某个值
System.out.println(map.containsValue(2)); // true
System.out.println(map.containsValue("2")); // false
// 9. public Set<K> keySet():获取Map集合的全部键
Set<String> keys = map.keySet();
System.out.println(keys); // [null, Java, 手机]
// 10. public Collection<V> values():获取Map集合的全部值
Collection<Integer> values = map.values();
System.out.println(values); // [null, 2, 2]
// 11. 把其他Map集合的数据倒入到自己集合中去(拓展)
Map<String, Integer> map1 = new HashMap<>();
map1.put("java1", 10);
map1.put("java2", 20);
Map<String, Integer> map2 = new HashMap<>();
map2.put("java3", 10);
map2.put("java2", 222);
map1.putAll(map2); // putAll:把map2集合中的元素全部导入一份到map1集合中去
System.out.println(map1); // {java3=10, java2=222, java1=10}
System.out.println(map2); // {java3=10, java2=222}
}
}8.3 遍历方式
- 01键找值:先获取 Map 集合全部的键,再通过遍历键来找值
- 02键值对:把 "键值对" 看成一个整体进行遍历(难度较大)
- 03Lambda:JDK1.8 开始之后的新技术(非常的简单)
8.3.1 键找值
- 先获取 Map 集合全部的键,再通过遍历键来找值
需要用到 Map 的如下方法:
| 方法名称 | 说明 |
|---|---|
| public Set keySet() | 获取所有键的集合 |
| public V get(Object key) | 根据键获取其对应的值 |
代码演示
java
package Advanced.h_map.d2_map_traverse;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 目标:掌握Map集合的遍历方式1:键找值
*/
public class MapTest1 {
public static void main(String[] args) {
// 准备一个Map集合
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 162.5);
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map); // {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
// 1. 获取Map集合的全部键
Set<String> keys = map.keySet();
System.out.println(keys); // [蜘蛛精, 牛魔王, 至尊宝, 紫霞]
// 2. 遍历全部的键,根据键获取其对应的值
for (String key : keys) {
// 根据键获取对应的值
double value = map.get(key);
System.out.println(key + " ===> " + value);
}
}
}8.3.2 键值对
- 把 "键值对" 看成一个整体进行遍历(难度较大)
| Map 提供的方法 | 说明 |
|---|---|
| Set<Map.Entry<K, V>> entrySet() | 获取所有 "键值对" 的集合 |
| Map.Entry 提供的方法 | 说明 |
|---|---|
| K getKey() | 获取键 |
| V getValue() | 获取值 |

代码演示
java
package Advanced.h_map.d2_map_traverse;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 目标:掌握Map集合的第二种遍历方式:键值对
*/
public class MapTest2 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 162.5);
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map); // {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
// 1. 调用Map集合提供的entrySet方法,把Map集合转换成键值对类型的Set集合
Set<Map.Entry<String, Double>> entries = map.entrySet();
for (Map.Entry<String, Double> entry : entries) {
String key = entry.getKey();
Double value = entry.getValue();
System.out.println(key + " ---> " + value);
}
}
}8.3.3 Lambda
-
JDK1.8 开始之后的新技术(非常的简单)
-
需要用到 Map 的如下方法
| 方法名称 | 说明 |
|---|---|
| default void forEach(BiConsumer<? super K, ? super V> action) | 结合 lambda 遍历 Map 集合 |
代码演示
java
package Advanced.h_map.d2_map_traverse;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
/**
* 目标:掌握Map集合的第三种遍历方式:Lambda
*/
public class MapTest3 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 162.5);
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map); // {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
// map.forEach(new BiConsumer<String, Double>() {
// @Override
// public void accept(String k, Double v) {
// System.out.println(k + " ---> " + v);
// }
// });
map.forEach((k, v) -> {
System.out.println(k + " ---> " + v);
});
}
}Map 集合的案例 - 统计投票人数
需求:
- 某个班级80名学生,现在需要组织秋游活动,班长提供了四个景点依次是(A、B、C、D),每个学生只能选择一个景点,请统计出最终哪个景点想去的人数最多
分析
- 将80个学生选择的数据拿到程序中去,A, A, B, A, B, C, D, ...
- 准备一个 Map 集合用于存储统计的结果,Map<String, Integer>,键是景点,值代表投票数量
- 遍历80个学生选择的景点,每遍历一个景点,就看 Map 集合中是否存在该景点,不存在存入 "景点=1",存在则其对应值+1
代码实现
java
package Advanced.h_map.d2_map_traverse;
import java.util.*;
/**
* 目标:完成Map集合的案例,统计投票人数
*/
public class MapDemo4 {
public static void main(String[] args) {
// 1. 把80个学生选择的景点数据拿到程序中来
List<String> data = new ArrayList<>();
String[] selects = {"A", "B", "C", "D"};
Random r = new Random();
for (int i = 1; i <= 80; i++) {
// 每次模拟一个学生选择一个景点,存入到集合中去
int index = r.nextInt(4);
data.add(selects[index]);
}
System.out.println(data);
// 2. 统计每个景点的投票人数
// 准备一个Map集合用于统计最终的结果
Map<String, Integer> result = new HashMap<>();
// 3. 开始遍历80个景点数据
for (String s : data) {
// 问问Map集合中是否存在该景点
if (result.containsKey(s)) {
// 说明这个景点之前统计过, 其值+1 存入到Map集合种
result.put(s, result.get(s) + 1);
} else {
// 说明这个景点是第一次统计,存入景点1
result.put(s, 1);
}
}
System.out.println(result);
}
}8.4 HashMap
- 无序、不重复、无索引;(用的最多)
8.4.1 HashMap 集合的底层原理
- HashMap 跟 HashSet 的底层原理是一模一样的,都是基于哈希表实现的
实际上:原来学的 Set 系列集合的底层就是基于 Map 实现的,只是 Set 集合中的元素只要键数据,不要值数据而已
java
public HashSet() {
map = new HashMap<>();
}8.4.2 哈希表
- JDK8 之前,哈希表 = 数组 + 链表
- JDK8 开始,哈希表 = 数组 + 链表 + 红黑树
- 哈希表是一种增删改查数据,性能都较好的数据结构
代码演示
- Student.java
java
package Advanced.h_map.d3_map_impl;
import java.util.Objects;
public class Student {
private String name;
private int age;
private double height;
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(height, student.height) == 0 && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
}- Test1HashMap.java
java
package Advanced.h_map.d3_map_impl;
import java.util.HashMap;
import java.util.Map;
/**
* 目标:掌握Map集合下的实现类:HashMap集合的底层原理
*/
public class Test1HashMap {
public static void main(String[] args) {
Map<Student, String> map = new HashMap<>();
map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");
map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");
map.put(new Student("至尊宝", 23, 163.5), "水帘洞");
map.put(new Student("牛魔王", 28, 183.5), "牛头山");
System.out.println(map);
}
}总结
- HashMap 集合是一种增删改查数据,性能都较好的集合
- 但是它是无序,不能重复,没有索引支持的(由键决定特点)
- HashMap 的键依赖 hashCode 方法和 equals 方法保证键的唯一【Alt + Insert 后选择重写 hashCode 方法和 equals 方法】
- 如果键存储的是自定义类型的对象,可以通过重写 hashCode 和 equals 方法,这样可以保证多个对象内容一样时,HashMap 集合就能认为是重复的
8.5 LinkedHashMap
- 有序、不重复、无索引
8.5.1 LinkedHashMap 的底层原理
- 底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序)
实际上:原来学习的 LinkedHashSet 集合的底层原理就是 LinkedHashMap
8.6 TreeMap
- 按照键的大小默认升序排序、不重复、无索引
- 原理:TreeMap 跟 TreeSet 集合的底层原理是一样的,都是基于红黑树实现的排序
8.6.1 TreeMap 集合同样也支持两种方式来指定排序规则
- 让类实现 Comparable 接口,重写比较规则
- TreeMap 集合有一个有参构造器,支持创建 Comparator 比较器对象,以便用来指定比较规则
代码演示
- Student.java
java
package Advanced.h_map.d3_map_impl;
import java.util.Objects;
public class Student implements Comparable<Student> {
private String name;
private int age;
private double height;
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(height, student.height) == 0 && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
}- Test3TreeMap.java
java
package Advanced.h_map.d3_map_impl;
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
/**
* 目标:掌握TreeMap集合的使用
*/
public class Test3TreeMap {
public static void main(String[] args) {
Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return Double.compare(o2.getHeight(), o1.getHeight());
}
});
map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");
map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");
map.put(new Student("至尊宝", 23, 163.5), "水帘洞");
map.put(new Student("牛魔王", 28, 183.5), "牛头山");
System.out.println(map);
}
}8.7 补充知识:集合的嵌套
- 指的是集合中的元素又是一个集合
需求:
- 要求是再程序中记住如下省份和其对应的城市信息,记录成功后,要求可以查询出湖北省的城市信息
江苏省=南京市, 扬州市, 苏州市, 无锡市, 常州市
湖北省=武汉市, 孝感市, 十堰市, 宜昌市, 鄂州市
河北省=石家庄市, 唐山市, 邢台市, 保定市, 张家口市
分析:
- 定义一个 Map 集合,键用表示省份名曾,值表示城市名称,注意:城市会有多个
- 根据 "湖北省" 这个键获取对应的值展示即可
代码实现
java
package Advanced.h_map.d4_collection_nesting;
import java.util.*;
/**
* 目标:理解集合的嵌套
* 江苏省=南京市, 扬州市, 苏州市, 无锡市, 常州市
* 湖北省=武汉市, 孝感市, 十堰市, 宜昌市, 鄂州市
* 河北省=石家庄市, 唐山市, 邢台市, 保定市, 张家口市
*/
public class Test {
public static void main(String[] args) {
// 1. 定义一个Map集合存储全部的省份信息,和其对应的城市信息
Map<String, List<String>> map = new HashMap<>();
List<String> cities1 = new ArrayList<>();
Collections.addAll(cities1, "南京市", "扬州市", "苏州市", "无锡市", "常州市");
map.put("江苏省", cities1);
List<String> cities2 = new ArrayList<>();
Collections.addAll(cities2, "武汉市", "孝感市", "十堰市", "宜昌市", "鄂州市");
map.put("湖北省", cities2);
List<String> cities3 = new ArrayList<>();
Collections.addAll(cities3, "石家庄市", "唐山市", "邢台市", "保定市", "张家口市");
map.put("河北省", cities3);
System.out.println(map);
List<String> cities = map.get("湖北省");
for (String city : cities) {
System.out.println(city);
}
map.forEach((p, c) -> {
System.out.println(p + " ---> " + c);
});
}
}9. Stream 流
9.1 认识 Stream
- 也叫 Stream 流,是 JDK8 开始新增的一套 API(java.util.stream.*),可以用于操作集合或者数组的数据
- 优势:Stream 流大量的结合了 Lambda 的语法风格来编程 ,提供了一种更加强大,更加简单的方式操作集合或者数组中的数据,代码更简洁,可读性更好
9.1.1 体验 Stream 流
需求:
javaList<String> list = new ArrayList(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰");
- 把集合中所有以 "张" 开头,且是3个字的元素存储到一个新的集合
代码实现
java
package Advanced.i_stream;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* 目标:初步体验Stream流的方便与快捷
*/
public class StreamTest1 {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("张无忌");
names.add("周芷若");
names.add("赵敏");
names.add("张强");
names.add("张三丰");
System.out.println(names); // [张无忌, 周芷若, 赵敏, 张强, 张三丰]
List<String> list = new ArrayList<>();
for (String name : names) {
if (name.startsWith("张") && name.length() == 3) {
list.add(name);
}
}
System.out.println(list); // [张无忌, 张三丰]
// 开始用Stream流来解决这个问题
List<String> list2 = names.stream().filter(s -> s.startsWith("张")).filter(a -> a.length() == 3).collect(Collectors.toList());
System.out.println(list2); // [张无忌, 张三丰]
}
}9.1.2 Stream 流的使用步骤
- 获取 Stream 流:Stream 流代表一条流水线,并能与数据源建立连接
- 调用流水线的各种方法对数据进行处理、计算(过滤、排序、去重、...)
- 获取处理的结果,遍历、统计、收集到一个新集合中返回
9.2 Stream 的常用方法
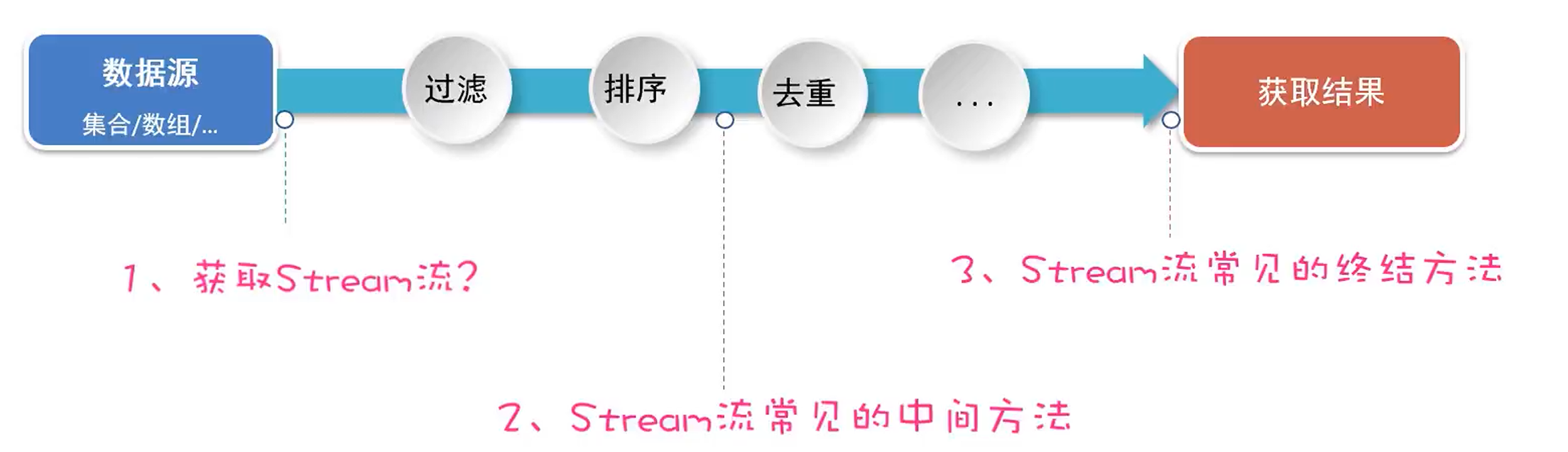
9.2.1 获取 Stream 流?
- 获取 集合 的 Stream 流
| Collection 提供的如下方法 | 说明 |
|---|---|
| default Stream stream() | 获取当前集合对象的 Stream 流 |
- 获取 数组 的 Stream 流
| Arrays 类提供的如下方法 | 说明 |
|---|---|
| public static Stream stream(T\[\] array) | 获取当前数组的 Stream 流 |
| Stream 类提供的如下方法 | 说明 |
|---|---|
| public static Stream of(T... values) | 获取当前接收数据的 Stream 流 |
代码演示
java
package Advanced.i_stream;
import java.util.*;
import java.util.stream.Stream;
public class StreamTest2 {
public static void main(String[] args) {
// 1. 如何获取List集合的Stream流?
List<String> names = new ArrayList<>();
Collections.addAll(names, "张无忌", "周芷若", "赵敏", "张强", "张三丰");
Stream<String> stream = names.stream();
// 2. 如何获取Set集合的Stream流?
Set<String> set = new HashSet<>();
Collections.addAll(set, "刘德华", "张曼玉", "蜘蛛精", "马德", "德玛西亚");
Stream<String> stream1 = set.stream();
stream1.filter(s -> s.contains("德")).forEach(s -> System.out.println(s));
// 3. 如何获取Map集合的Stream流?
Map<String, Double> map = new HashMap<>();
map.put("古力娜扎", 172.3);
map.put("迪丽热巴", 168.3);
map.put("马尔扎哈", 166.3);
map.put("卡尔扎巴", 168.3);
Set<String> keys = map.keySet();
Stream<String> ks = keys.stream();
Collection<Double> values = map.values();
Stream<Double> vs = values.stream();
Set<Map.Entry<String, Double>> entries = map.entrySet();
Stream<Map.Entry<String, Double>> kvs = entries.stream();
kvs.filter(e -> e.getKey().contains("巴")).forEach(e -> System.out.println(e.getKey() + " ---> " + e.getValue()));
// 4. 如何获取数组的Stream流?
String[] names2 = {"张翠山", "东方不败", "唐大山", "独孤求败"};
Stream<String> s1 = Arrays.stream(names2);
Stream<String> s2 = Stream.of(names2);
}
}9.2.2 Stream 流常见的中间方法
- 中间方法指的是调用完成后会返回新的 Stream 流,可以继续使用(支持链式编程)
| Stream 提供的常见中间方法 | 说明 |
|---|---|
| Stream filter(Predicate<? super T> predicate) | 用于对流中的数据进行过滤 |
| Stream sorted() | 对元素进行升序排序 |
| Stream sorted(Comparator<? super T> comparator) | 按照指定规则排序 |
| Stream limit(long maxSize) | 获取前几个元素 |
| Stream skip(long n) | 跳过前几个元素 |
| Stream distinct() | 去除流中重复的元素 |
| Stream map(Function<? super T, ? extends R> mapper) | 对元素进行加工,并返回对应的新流 |
| static Stream concat(Stream a, Stream b) | 合并 a 和 b 两个流为一个流 |
代码演示
- Student.java
java
package Advanced.i_stream;
import java.util.Objects;
public class Student implements Comparable<Student> {
private String name;
private int age;
private double height;
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
public Student() {
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(height, student.height) == 0 && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
}- StreamTest3.java
java
package Advanced.i_stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Stream;
/**
* 目标:掌握Stream流提供的常见中间方法
*/
public class StreamTest3 {
public static void main(String[] args) {
List<Double> scores = new ArrayList<>();
Collections.addAll(scores, 88.5, 100.0, 60.0, 99.0, 9.5, 99.6, 25.0);
// 需求1:找出成绩大于等于60分的数据,并升序后,再输出
scores.stream().filter(s -> s >= 60).sorted().forEach(s -> System.out.println(s));
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精", 26, 172.5);
Student s2 = new Student("蜘蛛精", 26, 172.5);
Student s3 = new Student("紫霞", 23, 167.6);
Student s4 = new Student("白晶晶", 25, 169.0);
Student s5 = new Student("牛魔王", 35, 183.3);
Student s6 = new Student("牛夫人", 34, 168.5);
Collections.addAll(students, s1, s2, s3, s4, s5, s6);
// 需求2:找出年龄大于等于23,且年龄小于等于30岁的学生,并按照年龄降序输出
students.stream().filter(s -> s.getAge() >= 23 && s.getAge() <= 30)
.sorted(((o1, o2) -> o2.getAge() - o1.getAge()))
.forEach(s -> System.out.println(s));
// 需求3:取出身高最高的前3名学生,并输出。
students.stream().sorted(((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())))
.limit(3).forEach(System.out::println);
System.out.println("------------------------------------");
// 需求4:取出身高倒数的2名学生,并输出。
students.stream().sorted(((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())))
.skip(students.size() - 2).forEach(System.out::println);
// 需求5:找出身高超过168的学生叫什么名字,要求去除重复的名字,再输出。
students.stream().filter(s -> s.getHeight() > 168).map(s -> s.getName())
.distinct().forEach(System.out::println);
// distinct去重复,自定义类型的对象(希望内容一样就认为重复,重写hasCode、equals)
students.stream().filter(s -> s.getHeight() > 168)
.distinct().forEach(System.out::println);
Stream<String> st1 = Stream.of("张三", "李四");
Stream<String> st2 = Stream.of("张三2", "李四2", "王五");
Stream<String> allSt = Stream.concat(st1, st2);
allSt.forEach(System.out::println);
}
}9.2.3 Stream 流常见的终结方法
- 终结方法指的是调用完成后,不会返回新的 Stream 了,没法继续使用流了
| Stream 提供的常用终结方法 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流运算后的元素执行遍历 |
| long count() | 统计此流运算后的元素个数 |
| Optional max(Comparator<? super T> comparator) | 获取此流运算后的最大值元素 |
| Optional min(Comparator<? super T> comparator) | 获取此流运算后的最小值元素 |
- 收集 Stream 流:就是把 Stream 流操作后的结果转回到集合或者数组中去返回
- Stream 流:方便操作集合/数组的手段 ;集合/数组:才是开发中的目的
| Stream 提供的常用终结方法 | 说明 |
|---|---|
| R collect(Collector collector) | 把流处理后的结果收集到一个指定的集合中去 |
| Object\[\] toArray() | 把流处理后的结果收集到一个数组中去 |
| Collectors 工具类提供了具体的收集方式 | 说明 |
|---|---|
| public static Collector toList() | 把元素收集到 List 集合中 |
| public static Collector toSet() | 把元素收集到 Set 集合中 |
| public static Collector toMap(Function keyMapper, Function valueMapper) | 把元素收集到 Map 集合中 |
代码演示
java
package Advanced.i_stream;
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest4 {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精", 26, 172.5);
Student s2 = new Student("蜘蛛精", 26, 172.5);
Student s3 = new Student("紫霞", 23, 167.6);
Student s4 = new Student("白晶晶", 25, 169.0);
Student s5 = new Student("牛魔王", 35, 183.3);
Student s6 = new Student("牛夫人", 34, 168.5);
Collections.addAll(students, s1, s2, s3, s4, s5, s6);
// 需求1:请计算出身高超过168的学生有几人。
long size = students.stream().filter(s -> s.getHeight() > 168).count();
System.out.println(size); // 5
// 需求2:请找出身高最高的学生对象,并输出。
Student s = students.stream().max((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();
System.out.println(s); // Student{name='牛魔王', age=35, height=183.3}
//需求3:请找出身高最矮的学生对象,并输出。
Student ss = students.stream().min((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();
System.out.println(ss); // SStudent{name='紫霞', age=23, height=167.6}
//需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回。
// 流只能收集一次
List<Student> students1 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toList());
System.out.println(students1);
Set<Student> students2 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toSet());
System.out.println(students2);
// 需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回。
Map<String, Double> map = students.stream().filter(a -> a.getHeight() > 170)
.distinct().collect(Collectors.toMap(a -> a.getName(), a -> a.getHeight()));
System.out.println(map); // {蜘蛛精=172.5, 牛魔王=183.3}
Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(len -> new Student[len]);
System.out.println(Arrays.toString(arr));
}
}