大模型的视力很重要
当我们谈论大模型时,总在惊叹其 "读懂" 文本、"生成" 内容的能力,GPT-4o 能写代码、Gemini-2.5 Pro 能做逻辑推理。大语言模型(LLM)的能力边界不断拓宽。其中,检索增强生成(RAG)技术更是遍地开花,它让LLM能够连接外部知识库,回答训练数据之外的问题,使其从一个"博学的书呆子"变成了一个能够实时获取信息的"全科专家"。
但有时候觉得市面上的大模型或者是自己制作的智能体好像并不是那么聪明。这其中有一个被许多人忽略的关键问题:如果你的大模型"视力"不行,RAG的效果会怎样?
现实世界中大多数信息是藏在非结构化文档里,比如学术论文的PDF、财报的扫描件、手写的笔记、竖排的古籍善本...... 这些 "视觉化信息" 对大模型而言,就像模糊的 "视力表"。没有 OCR ( 光学字符识别 )技术的 "翻译",再强的大模型也只能 "视而不见"。

从这个角度去看,OCR就是大模型的上游。
一个"近视"的OCR,会给下游的大模型喂进去一堆"垃圾"信息。而我们都知道一个朴素的真理:Garbage In, Garbage Out。再强大的LLM,面对一堆错乱的输入,也无法产出准确、可靠的答案。
因此,给大模型挑选一双"火眼金睛"至关重要。在半个月前我介绍过百度的PP-OCRv5这款小身材大能力的OCR模型,没想到10月16日百度又来一款更强悍的OCR模型------ PaddleOCR-VL。
和PP-OCRv5专注于文字识别不同,PaddleOCR-VL的特点在于多模态文档解析,它能够像人一样读懂、理解复杂版面结构,精准提取财报表格、数学公式、课堂手写笔记等多元信息,并在识别后自动还原符合人类阅读习惯的阅读顺序,精准区分标题、正文、图片与图注,确保信息无遗漏、逻辑不混乱。
这完全刷新了全球OCR的性能天花板,它到底有多强悍?让我们一探究竟。
你也可以一边看文章一边动手试试:aistudio.baidu.com/application...
掰掰手腕
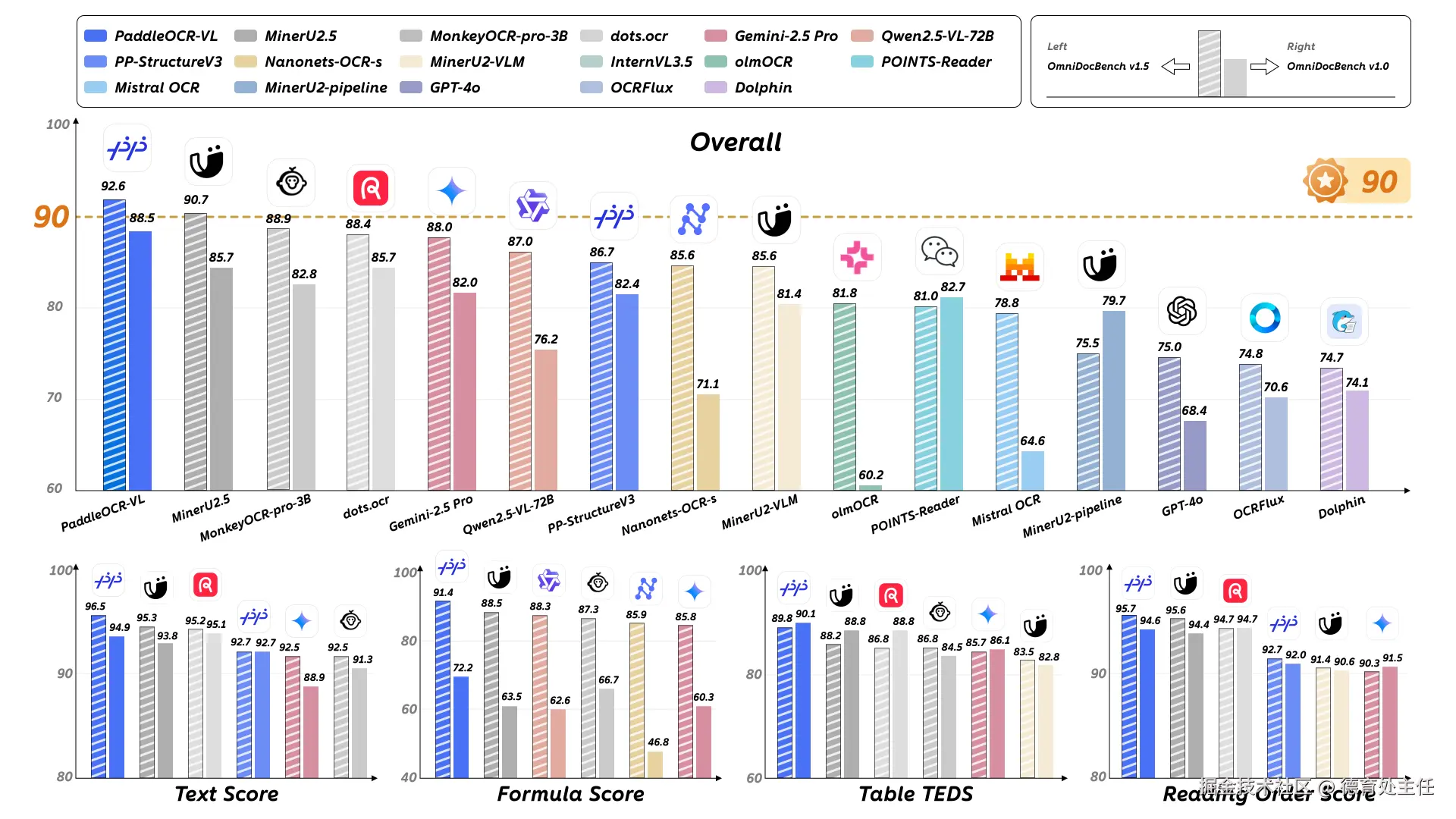
评价一款OCR模型,不能只凭感觉,必须要在最严苛、最权威的赛场上真刀真枪地比试。这个赛场,就是OmniBenchDoc V1.5全球评测榜单。
PaddleOCR-VL,作为文心4.5的 最强 衍生模型 ,基于ERNIE-4.5-0.3B语言模型训练,参数仅0.9B ,却爆发出惊人能量。它在最新榜单中,以92.6的综合得分位列全球第一。

我从文本识别、公式识别、表格理解、阅读顺序这四个维度测试PaddleOCR-VL,同时也会拉出GPT、Gemini以及豆包这几个模型横评。一起看看PaddleOCR-VL是不是这么能打~
中文手写识别
印刷体识别已是基础操作,真正的挑战在于复杂、多变的手写体。我选用了一张有一定拍摄倾斜角度、且包含涂改痕迹的学生作文来测试。

PaddleOCR - VL
识别率惊人地准确,完美识别出所有手写文字,并且智能地识别出自然段落并进行了分段。
唯一可提及的是未识别出页面右上角"评语"二字,但这在作文内容识别的核心任务中瑕不掩瑜。

ChatGPT
开局就出现错乱,更严重的是,它似乎在我的提示词"识别图中的文字并返回给我"之外,进行了"自我润色",这在要求精准还原的OCR任务中是严重的大忌。

Gemini
Gemini也是一开始就错了,但表现优于ChatGPT。Gemini同样存在"过度推理"的问题。例如,原文缺少一个"具"字,Gemini自作主张地给补全了。

豆包
和ChatGPT一样离谱,前半段识别结果完全错误😂
不过后半段豆包又清醒了,能识别出来。

排名
在中文手写识别这个核心场景,PaddleOCR-VL展现了绝对的实力,它忠实于原文,精准还原,不像其他大模型会"画蛇添足"。
在"文字识别"的测试中,我给出的排名:
- PaddleOCR-VL
- Gemini
- 豆包
- ChatGPT
阅读顺序测试
不是所有文稿都是从左往右、从上往下阅读的。
比如我们的古诗词,以前的习惯是从右往左读,竖向排版。普通的OCR工具是很难准确判断材料的排版方式。PaddleOCR-VL可以!
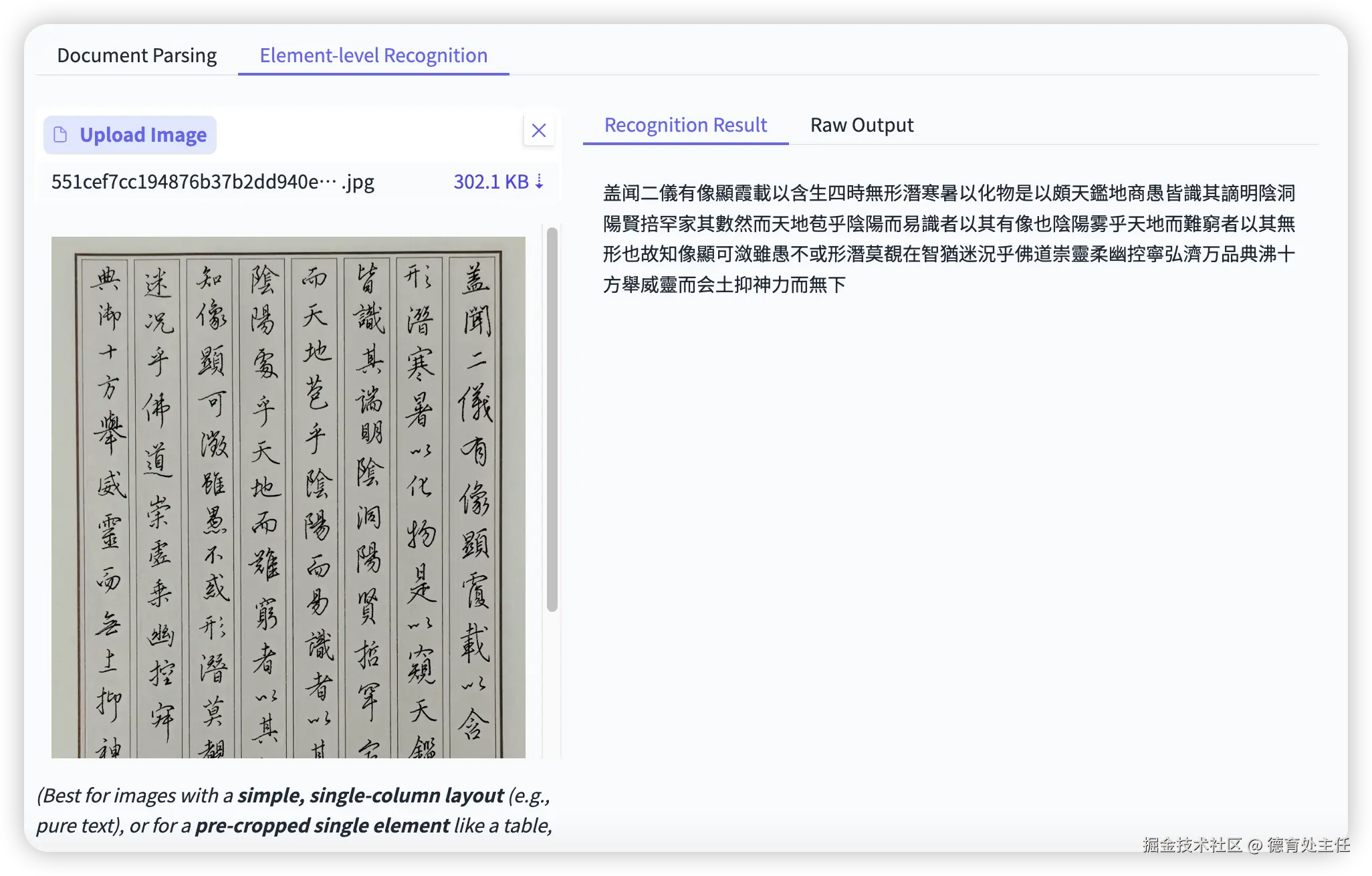
这次用到的这张测试图的内容是《大唐三藏圣教序》的节选,而且把标点符号全部去掉,从右往左竖向排版,简体和繁体混合适用。

PaddleOCR VL
PaddleOCR VL果然能完美完成这次任务!
ChatGPT
ChatGPT能理解图片的内容,然后转成简体中文输出,但莫名其妙加了一点空格。

Gemini
Gemini也能识别出图片的内容,但可能检测到图片中存在繁体中文,所以返回的内容都改成繁体字了(第一个字就改成繁体了)。而且也莫名其妙加了标点符号进去。

豆包
豆包也能准确是被出图片的内容,但和ChatGPT一样都改成简体中文。在排版上豆包反而能更符合原文要求。

排名
在还原度方面,PaddleOCR-VL毋庸置疑是排第一的,各家大语言模型应该是用过《大唐三藏圣教序》做训练数据,推理出现在要识别的是《大唐三藏圣教序》的内容,而不是完完全全把OCR的识别接过返回给用户。
在"阅读顺序"的测试中,我给出的排名:
- PaddleOCR-VL
- 豆包
- ChatGPT和Cemini并列第三
表格理解能力
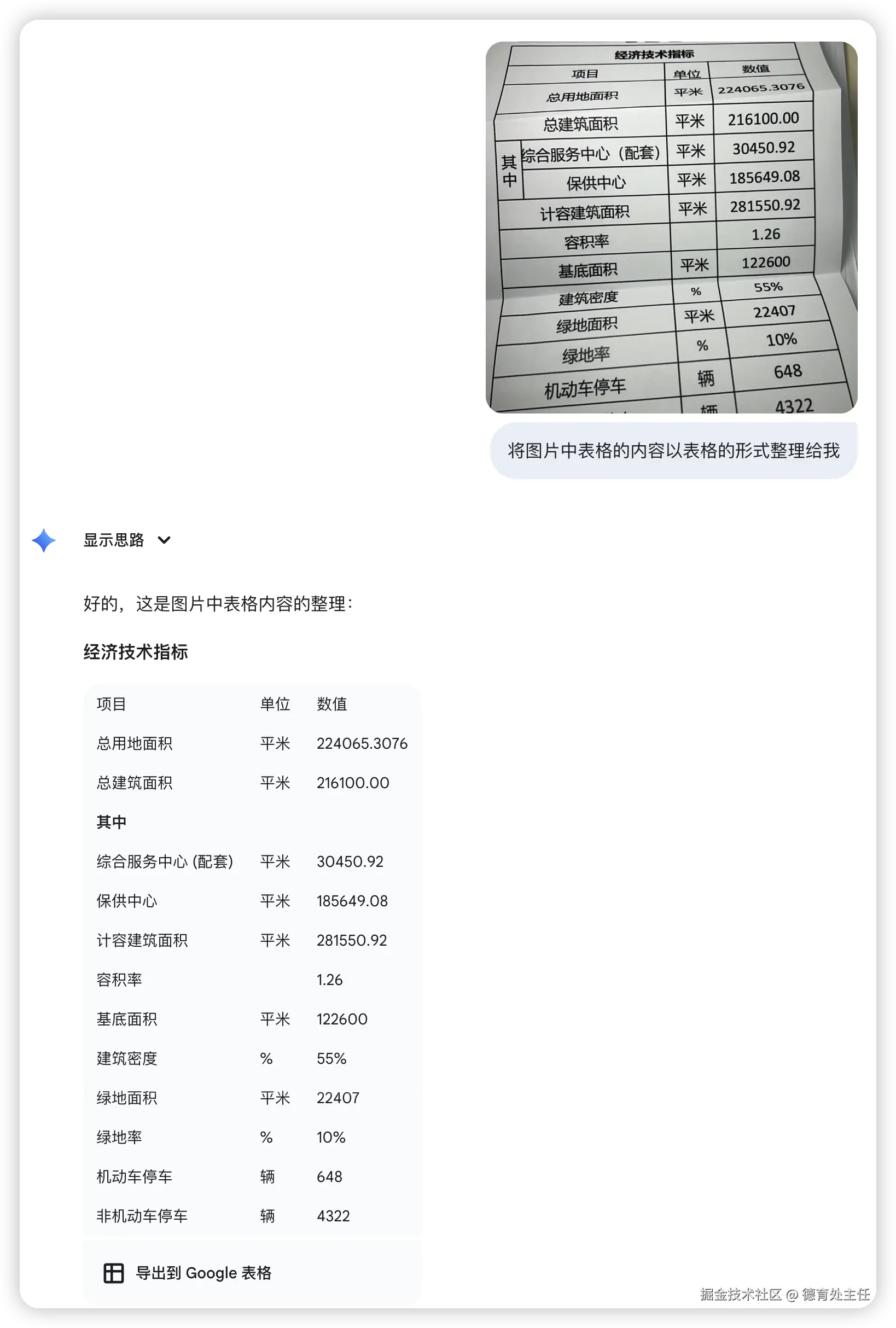
这可能是最具挑战性的一关。我选择了一张打印后被折叠、有阴影、有角度、且包含合并单元格的真实表格照片。这考验的不仅仅是文字识别,更是对空间和逻辑结构的深度理解。
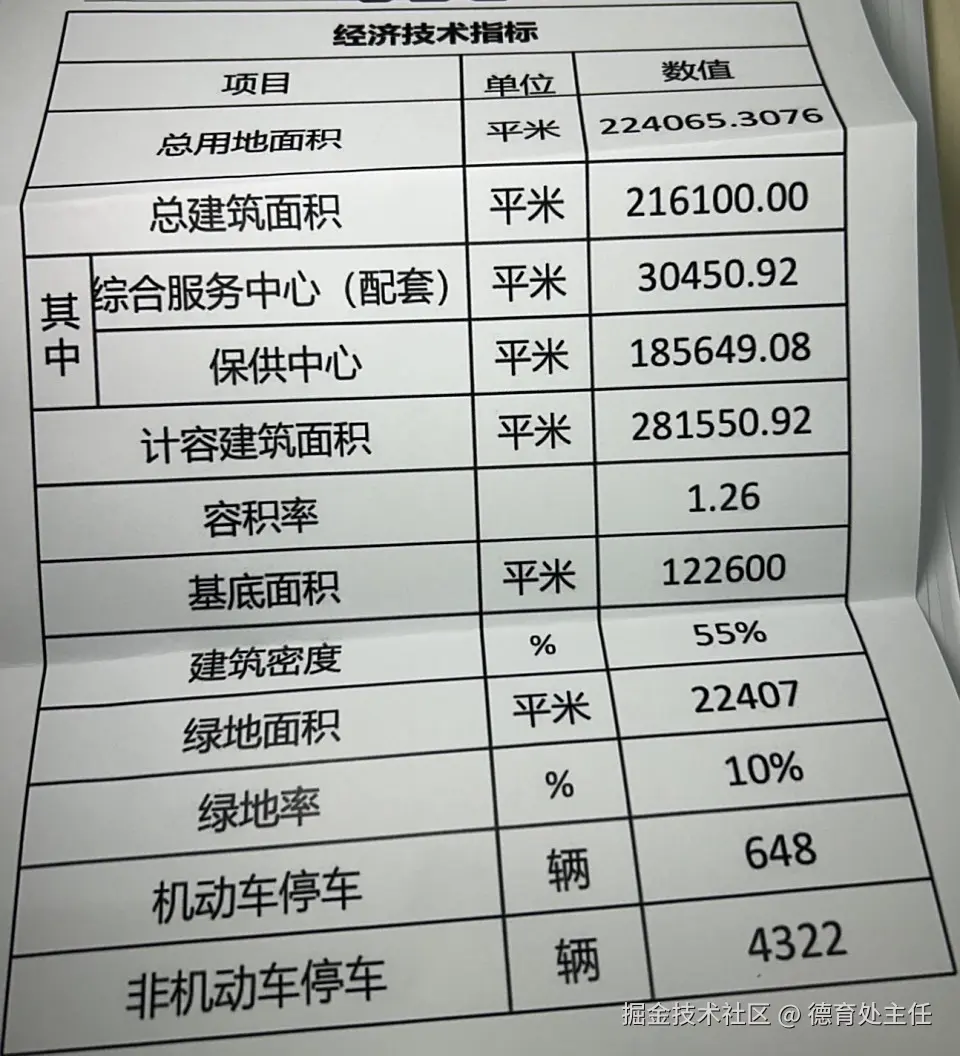
PaddleOCR - VL
PaddleOCR-VL不仅100%还原了表格的排版布局,精准处理了合并单元格,甚至连与边框重叠的文字都分毫不差地提取出来。它直接输出了结构化的HTML代码,展现了真正的"表格理解"能力。如果要挑刺,可能只有在线Demo的预览文字没有居中,但这已是吹毛求疵。
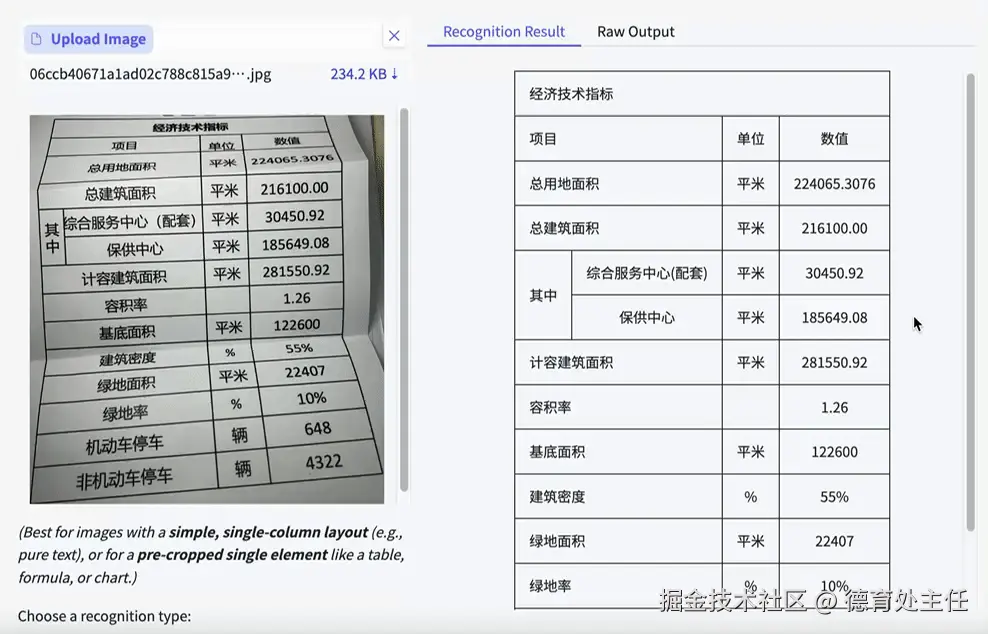
ChatGPT
识别率很高,但完全忽略了表头"经济技术指标",并且错误地填充了空白单元格。它基于Markdown的表格语法,难以处理合并单元格的复杂结构。

Gemini
Gemini同样丢失了表头,排版美观度不及ChatGPT。
豆包
直接罢工了😓
排名
在最能体现"文档解析"价值的表格理解环节,PaddleOCR-VL展现了断层式的领先优势。它不只是"识别",而是真正地在"理解"。
在"理解表格能力"的测试中,我给出的排名:
- PaddleOCR-VL
- ChatGPT
- Gemini
- 豆包
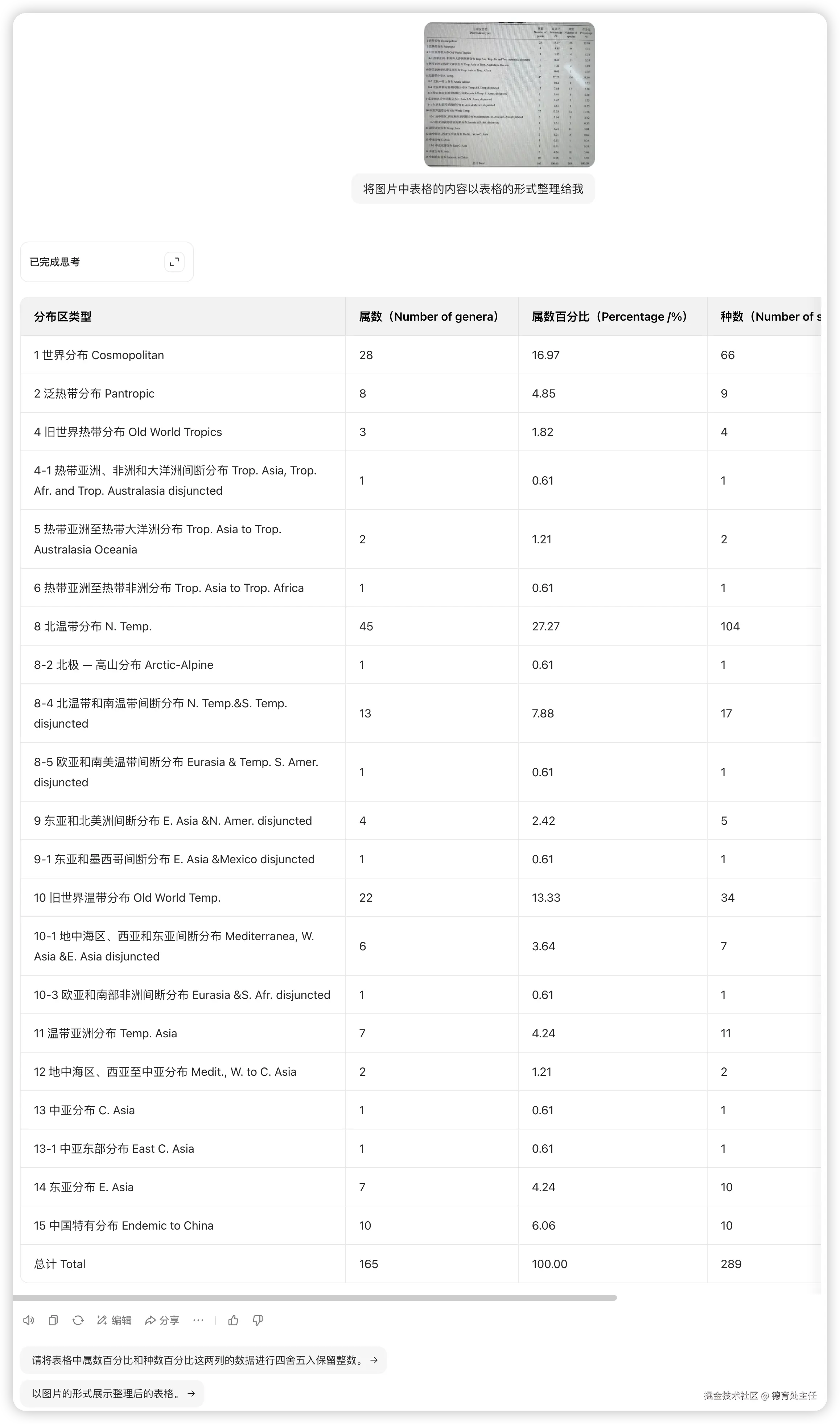
拍糊的表格
不知道大家有没有接触过这种图片。我在工作中经常会遇到有客户用手机拍出这种模糊的、带摩尔纹的同时还有点反光的照片过来让我处理问题。
如果公司系统接入AI功能,要提取用户发来的这种图片里的信息,一个优秀的OCR模型是必不可少的。
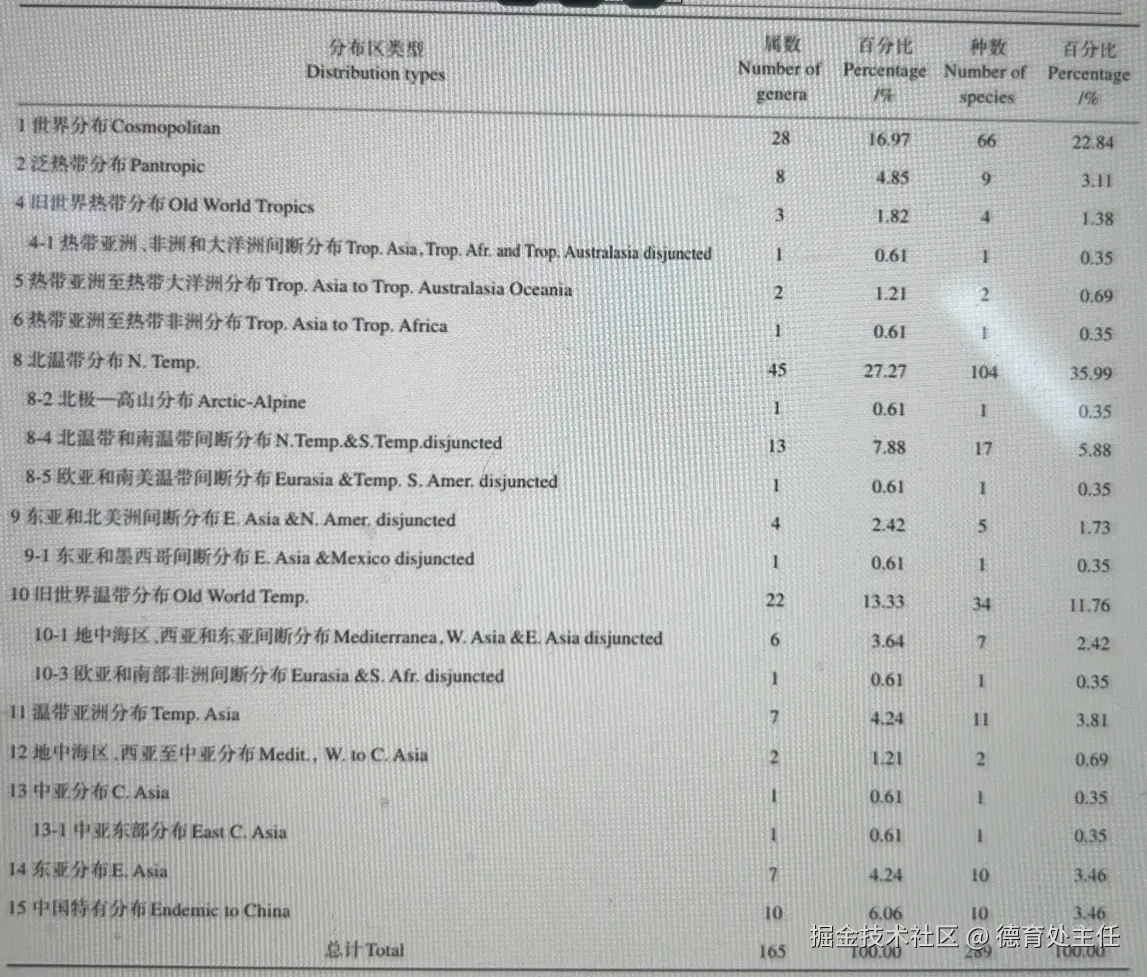
PaddleOCR - VL
PaddleOCR-VL的返回结果符合预期,唯一能挑刺的地方只有表格的缩进问题。不过原图表格并没有单元格边框,这就缺少了参考线,所以缩进部分识别不出来也可以理解。
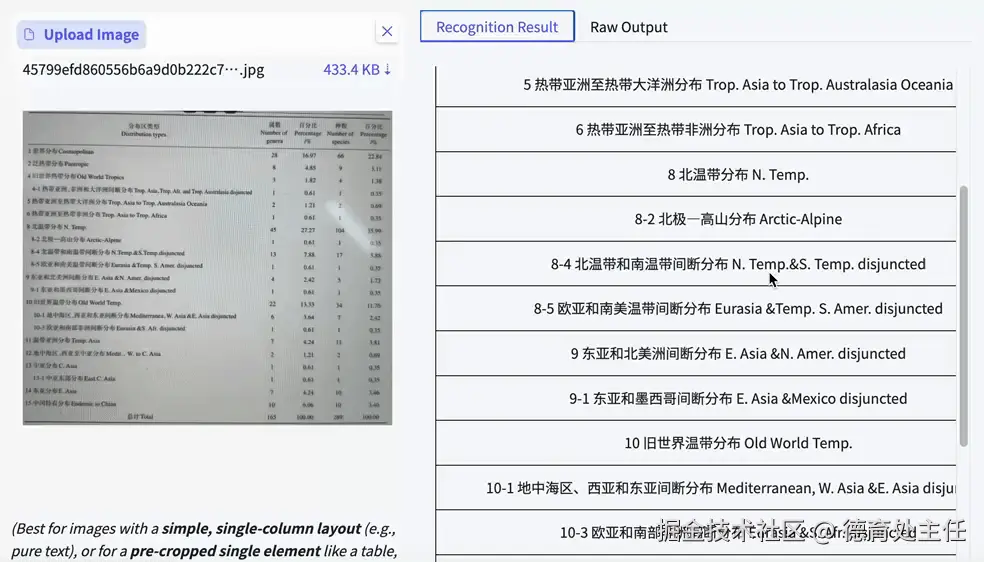
PaddleOCR-VL返回的结果 ⬇️
css
<table border=1 style='margin: auto; width: max-content;'><tr><td style='text-align: center;'>分布区类型Distribution types</td><td style='text-align: center;'>属数Number of genera</td><td style='text-align: center;'>百分比Percentage/%</td><td style='text-align: center;'>种数Number of species</td><td style='text-align: center;'>百分比Percentage/%</td></tr><tr><td style='text-align: center;'>1 世界分布 Cosmopolitan</td><td style='text-align: center;'>28</td><td style='text-align: center;'>16.97</td><td style='text-align: center;'>66</td><td style='text-align: center;'>22.84</td></tr><tr><td style='text-align: center;'>2 泛热带分布 Pantropic</td><td style='text-align: center;'>8</td><td style='text-align: center;'>4.85</td><td style='text-align: center;'>9</td><td style='text-align: center;'>3.11</td></tr><tr><td style='text-align: center;'>4 旧世界热带分布 Old World Tropics</td><td style='text-align: center;'>3</td><td style='text-align: center;'>1.82</td><td style='text-align: center;'>4</td><td style='text-align: center;'>1.38</td></tr><tr><td style='text-align: center;'>4-1 热带亚洲、非洲和大洋洲间断分布 Trop. Asia, Trop. Afr. and Trop. Australasia disjuncted</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>5 热带亚洲至热带大洋洲分布 Trop. Asia to Trop. Australasia Oceania</td><td style='text-align: center;'>2</td><td style='text-align: center;'>1.21</td><td style='text-align: center;'>2</td><td style='text-align: center;'>0.69</td></tr><tr><td style='text-align: center;'>6 热带亚洲至热带非洲分布 Trop. Asia to Trop. Africa</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>8 北温带分布 N. Temp.</td><td style='text-align: center;'>45</td><td style='text-align: center;'>27.27</td><td style='text-align: center;'>104</td><td style='text-align: center;'>35.99</td></tr><tr><td style='text-align: center;'>8-2 北极---高山分布 Arctic-Alpine</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>8-4 北温带和南温带间断分布 N. Temp.&S. Temp. disjuncted</td><td style='text-align: center;'>13</td><td style='text-align: center;'>7.88</td><td style='text-align: center;'>17</td><td style='text-align: center;'>5.88</td></tr><tr><td style='text-align: center;'>8-5 欧亚和南美温带间断分布 Eurasia &Temp. S. Amer. disjuncted</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>9 东亚和北美洲间断分布 E. Asia &N. Amer. disjuncted</td><td style='text-align: center;'>4</td><td style='text-align: center;'>2.42</td><td style='text-align: center;'>5</td><td style='text-align: center;'>1.73</td></tr><tr><td style='text-align: center;'>9-1 东亚和墨西哥间断分布 E. Asia &Mexico disjuncted</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>10 旧世界温带分布 Old World Temp.</td><td style='text-align: center;'>22</td><td style='text-align: center;'>13.33</td><td style='text-align: center;'>34</td><td style='text-align: center;'>11.76</td></tr><tr><td style='text-align: center;'>10-1 地中海区、西亚和东亚间断分布 Mediterranean, W. Asia &E. Asia disjuncted</td><td style='text-align: center;'>6</td><td style='text-align: center;'>3.64</td><td style='text-align: center;'>7</td><td style='text-align: center;'>2.42</td></tr><tr><td style='text-align: center;'>10-3 欧亚和南部非洲间断分布 Eurasia &S. Afr. disjuncted</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>11 温带亚洲分布 Temp. Asia</td><td style='text-align: center;'>7</td><td style='text-align: center;'>4.24</td><td style='text-align: center;'>11</td><td style='text-align: center;'>3.81</td></tr><tr><td style='text-align: center;'>12 地中海区、西亚至中亚分布 Medit., W. to C. Asia</td><td style='text-align: center;'>2</td><td style='text-align: center;'>1.21</td><td style='text-align: center;'>2</td><td style='text-align: center;'>0.69</td></tr><tr><td style='text-align: center;'>13 中亚分布 C. Asia</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>13-1 中亚东部分布 East C. Asia</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.61</td><td style='text-align: center;'>1</td><td style='text-align: center;'>0.35</td></tr><tr><td style='text-align: center;'>14 东亚分布 E. Asia</td><td style='text-align: center;'>7</td><td style='text-align: center;'>4.24</td><td style='text-align: center;'>10</td><td style='text-align: center;'>3.46</td></tr><tr><td style='text-align: center;'>15 中国特有分布 Endemic to China</td><td style='text-align: center;'>10</td><td style='text-align: center;'>6.06</td><td style='text-align: center;'>10</td><td style='text-align: center;'>3.46</td></tr><tr><td style='text-align: center;'>总计 Total</td><td style='text-align: center;'>165</td><td style='text-align: center;'>100.00</td><td style='text-align: center;'>289</td><td style='text-align: center;'>100.00</td></tr></table>ChatGPT
ChatGPT好像把中英文分离开来了,我们肉眼能察觉到原图第一列是中文+英文,ChatGPT硬是要把它们分成两列😂
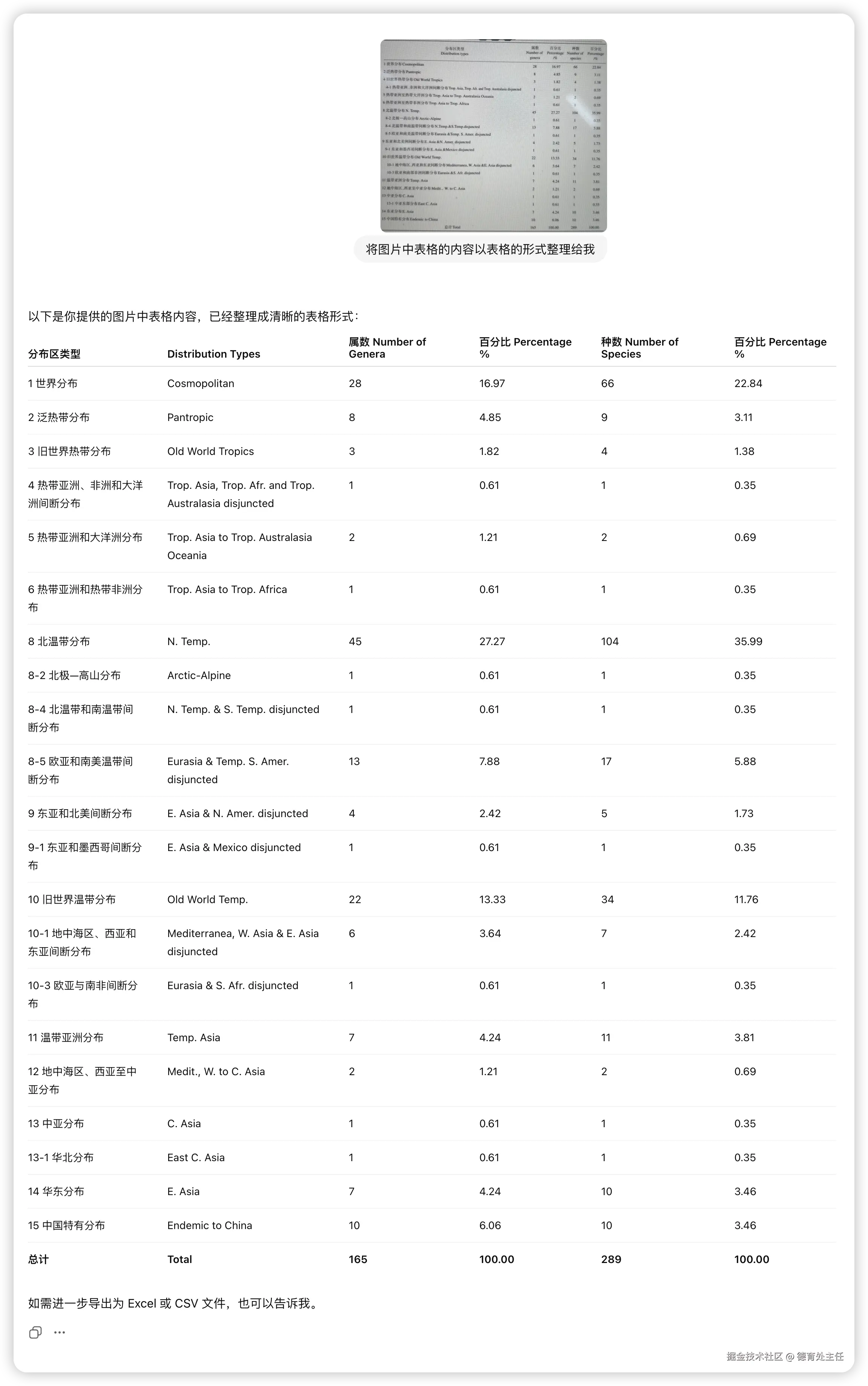
Gemini
Gemini的识别准确性和排版都符合要求,但表头这行的英文被它用括号括起来了。如果按照"英文要用括号括起来"的标准来看,它又没有给第一列的英文加上括号。
从严格遵守原图内容的角度来说,Gemini有一点点自作聪明了。
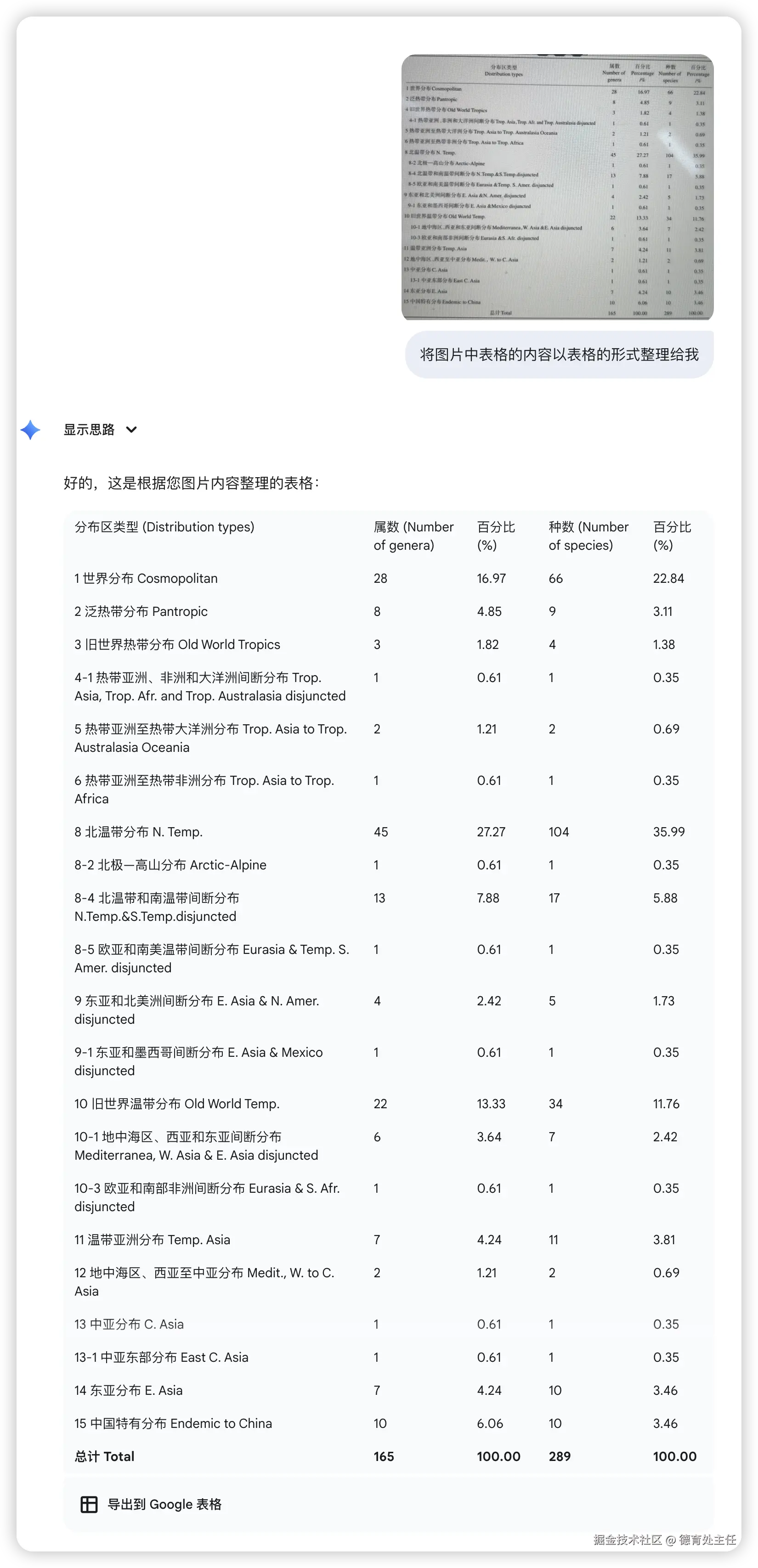
豆包
豆包的识别准确率和排版都没问题,唯一一个问题是表头第一列的"Distribution types"这个词不见了。
排名
在"拍糊的表格"的测试中,我给出的排名:
- PaddleOCR VL
- Gemini
- 豆包
- ChatGPT
数学公式识别
进入专业领域。数学公式包含了大量特殊符号、上下标,是OCR识别的噩梦。这次我们使用印刷体,看看谁能攻克这个难关。
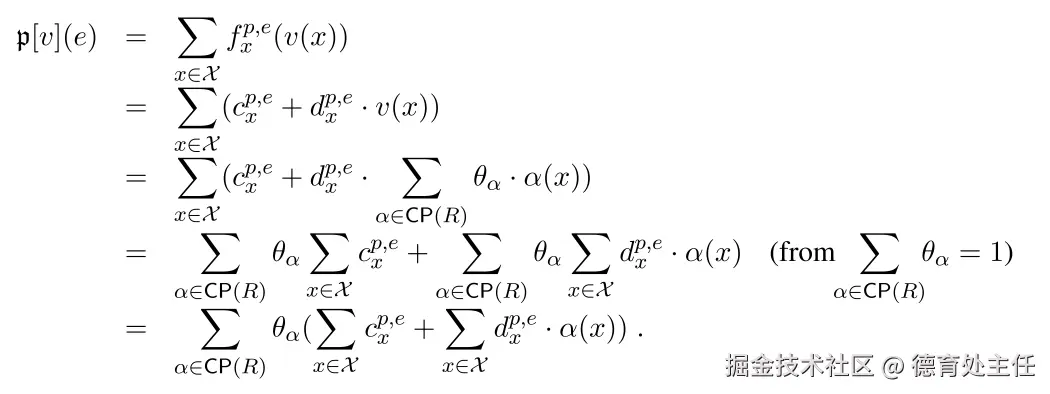
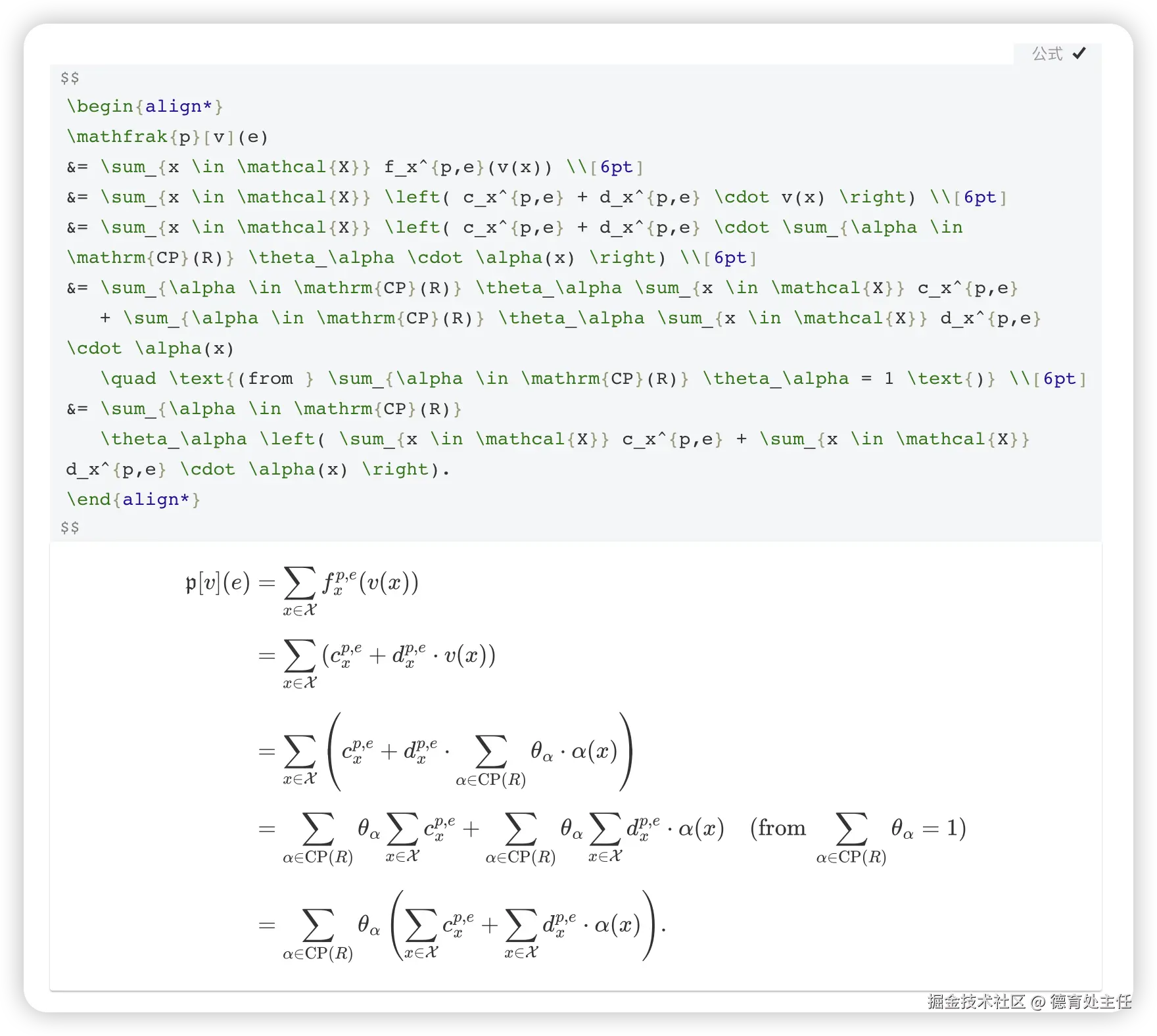
PaddleOCR VL

PaddleOCR-VL返回的结果 ⬇️
scss
$$ \begin{array}{rcl}\mathfrak{p}v&=&\displaystyle\sum {x\ in \mathcal{X}}f{x}^{p,e}(v(x))&=&\displaystyle\sum {x\ in \mathcal{X}}(c{x}^{p,e}+d {x}^{p,e}\cdot v(x))&=&\displaystyle\ sum{x\in\mathcal{X}}(c {x}^{p,e}+d{x}^{p,e}\cdot\sum {\alpha\ in \mathsf{CP}(R)}\theta{\alpha}\cdot\alpha(x))&=&\displaystyle\sum {\alpha\ in \mathsf{CP}(R)}\theta{\alpha}\sum {x\ in \mathcal{X}}c{x}^{p,e}+\sum {\alpha\ in \mathsf{CP}(R)}\theta{\alpha}\sum {x\ in \mathcal{X}}d{x}^{p,e}\cdot\alpha(x)\quad(\mathrm{from}\sum {\alpha\ in \mathsf{CP}(R)}\theta{\alpha}=1)&=&\displaystyle\sum {\alpha\ in \mathsf{CP}(R)}\theta{\alpha}(\sum {x\ in \mathcal{X}}c{x}^{p,e}+\sum {x\ in \mathcal{X}}d{x}^{p,e}\cdot\alpha(x)).\end{array} $$ChatGPT
ChatGPT给出的是LaTeX代码,需要用工具转一遍。

Gemini

豆包

这一次,战况非常胶着!
PaddleOCR-VL、Gemini和豆包都给出了近乎完美的识别结果,直接渲染出了与原图一致的公式。
ChatGPT同样识别准确,但它默认返回的是LaTeX代码,需要用户自行使用工具转换才能看到最终效果,在用户体验上略有不便。
多语言识别
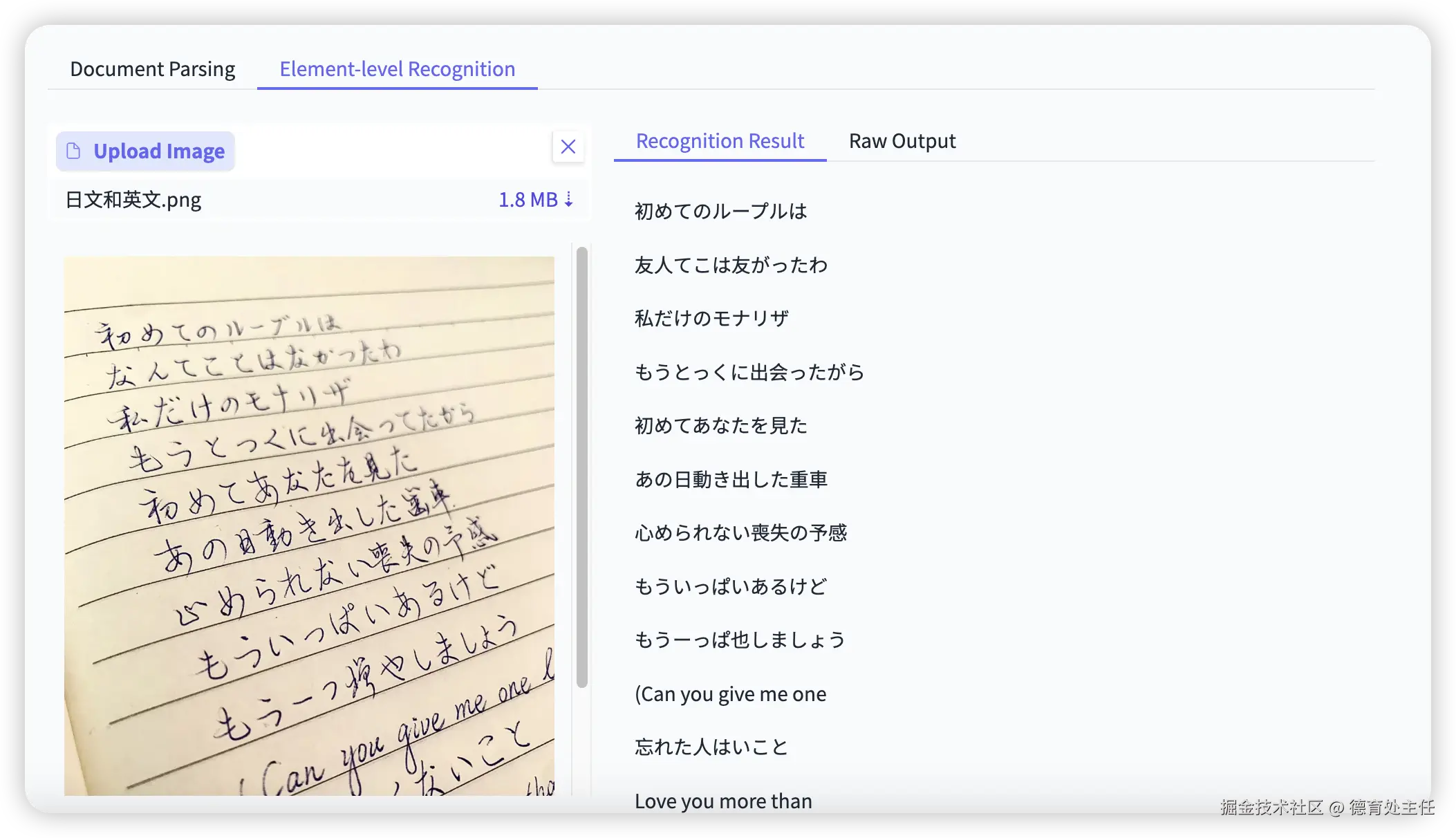
前面测试的大多数都是识别中文,为了排除"中文特攻"的可能性,这次测试一张包含日文和英文的混合手写体便签。

PaddleOCR - VL
识别率依旧非常高,基本达到"八九不离十"的水平。特别值得称赞的是,它精准地识别出英文首行的括号(, 而不是误判为字母C
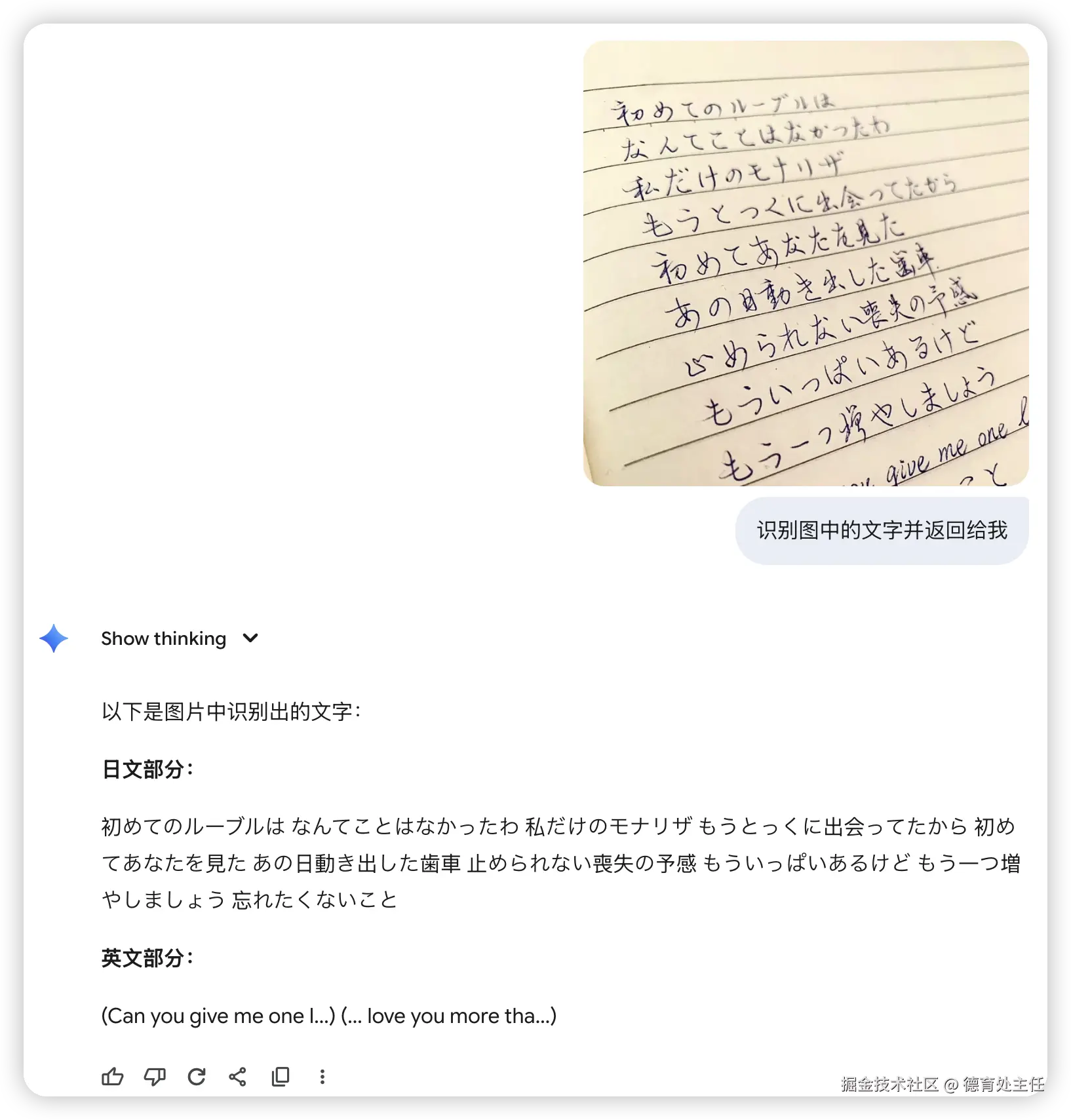
ChatGPT
识别率尚可,但它将日语和英语部分分开了,并且分离得不彻底,英文部分还夹杂着日文。

Gemini
识别率略逊一筹,排版未能遵循原文,并且同样出现了"自作聪明"的问题,给英文加上了原文没有的括号。
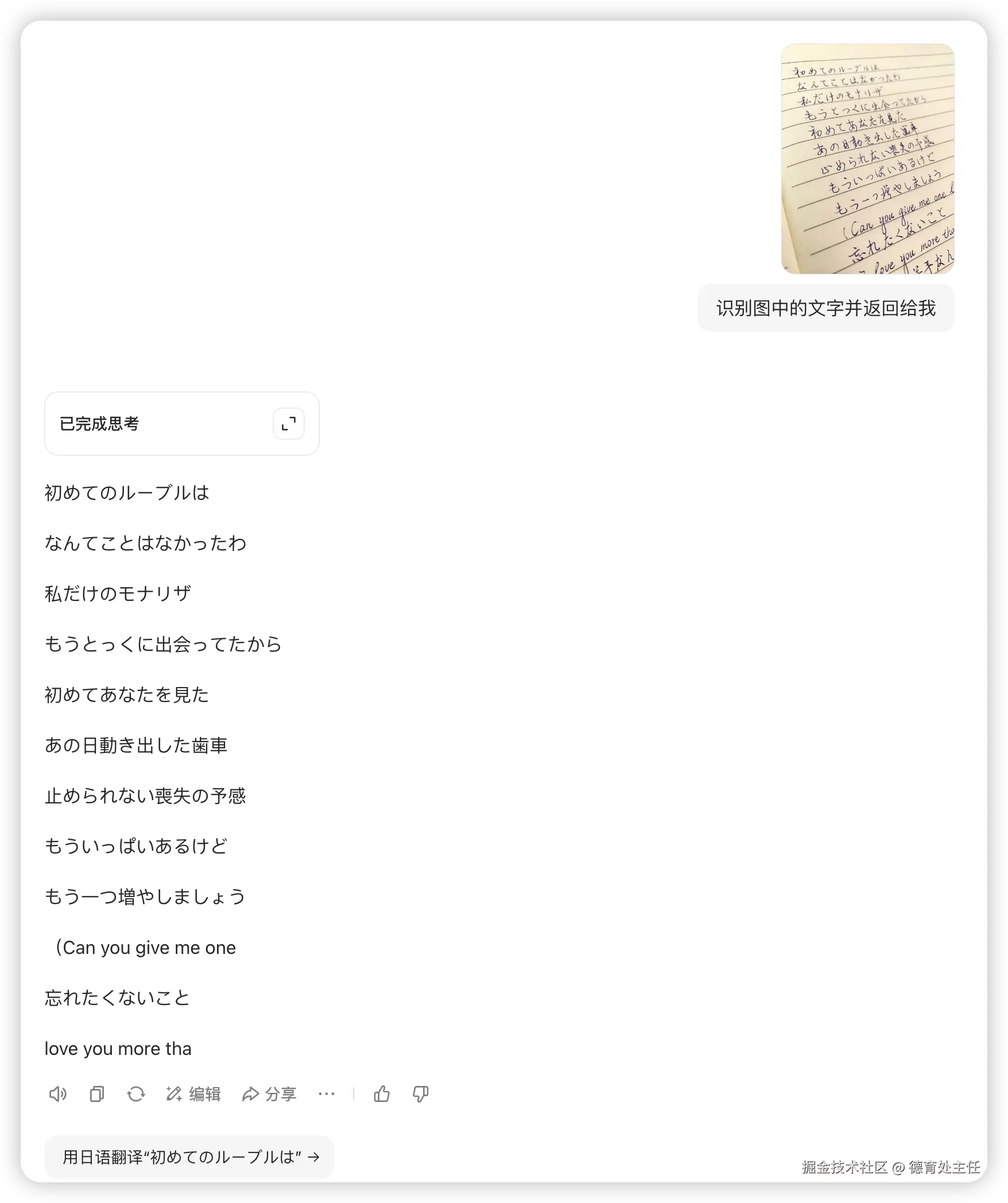
豆包
出息了,豆包在此次测试中表现出色,识别准确率和排版还原度都非常高,堪称完美。
排名
在多语言混合场景下,豆包表现惊艳,PaddleOCR-VL紧随其后,展现了强大的多语言处理能力。而ChatGPT和Gemini则在排版和忠实度上稍逊风骚。
在"多语言识别"的测试中,我给出的排名:
- 豆包
- PaddleOCR-VL
- ChatGPT
- Gemini
其他测试
除了纯文字的图片,有些时候也会遇到要识别证书内容等情况。比如提取证书的某些标识。

我试了一下PaddleOCR-VL也能做到这点。这次就不和其他大模型对比了,因为常用d大模型很难通过一次对话就把图片中的文字和特殊标识一次返回。
这次测试的图片是一张中大华远认证中心的《质量管理体系认证证书》,图片包含了标准的黑体字、手写签名以及证书的特殊标识。
从测试结果来看PaddleOCR-VL能把上述的几个内容都一一识别出来。

总结
如果说,2023年的大模型是"瞎子",2025年的多模态大模型是视力正常的人工智能,那2025年10月16日之后的大模型配合PaddleOCR-VL就相当于给它戴上智能眼镜。
而对于我来说,产品业务上需要识别各种图片里的文字,PaddleOCR-VL就相当于我的扫描仪。
在AI领域,我们常常追求"大而全"的模型。但经济学告诉我们一个基本原理:"分工产生效能"。AI社会亦是如此,一个由精进的"零部件"组成的系统,才能进化出一个全知全能的"神"。
在AI感官这个上游领域,视觉能力至关重要。PaddleOCR-VL选择将OCR、版面分析、公式识别这些"视觉"能力做到极致,最终以仅仅0.9B的参数量,实现了对百倍于己的大模型的全面超越。
更可怕的是,如此轻量的模型,意味着在普通智能手机上流畅运行也并非难事。
如果你的项目也需要用到OCR功能,不妨试试PaddleOCR-VL。相比起传统大模型的大以及时不时出现的幻觉,在OCR方面我还是会更相信专业的PaddleOCR-VL。
PaddleOCR VL项目地址:
- GitHub : github.com/PaddlePaddl...
- Hugging Face : huggingface.co/PaddlePaddl...