文章目录
-
- [📕1. 什么是缓存?](#📕1. 什么是缓存?)
- [📕2. 为什么要使用缓存呢?](#📕2. 为什么要使用缓存呢?)
- [📕3. 缓存的更新策略](#📕3. 缓存的更新策略)
- [📕4. 缓存三剑客](#📕4. 缓存三剑客)
-
-
- [✏️4.1 缓存穿透(Cache penetration)](#✏️4.1 缓存穿透(Cache penetration))
- [✏️4.2 缓存雪崩 (Cache avalanche)](#✏️4.2 缓存雪崩 (Cache avalanche))
- [✏️4.3 缓存击穿(Cache breakdown)](#✏️4.3 缓存击穿(Cache breakdown))
-
特此注明 :
Designed By :长安城没有风
Version:1.0
Time:2025.10.13
Location:辽宁 · 大连
📕1. 什么是缓存?
🌰举个栗子: 当我们坐高铁时,是需要反复刷⾝份证的 (进⼊⾼铁站,检票,上⻋,乘⻋过程中,出站...),正常来说,我的⾝份证是放在⽪箱⾥的(⽪箱的存储空间⼤,⾜够能装),但是每次刷⾝份证都需要开⼀次⽪箱找⾝份证,就⾮常不⽅便。因此我就可以把⾝份证先放到⾐服⼝袋⾥,⼝袋虽然空间⼩,但是访问速度⽐⽪箱快很多,这样的话每次刷⾝份证我只需要从⼝袋⾥掏⾝份证就⾏了,就不必开⽪箱了,此时 "⼝袋" 就是 "⽪箱" 的缓存,使⽤缓存能够⼤大提⾼访问效率。
缓存 (cache) 是计算机中的⼀个经典的概念,在很多场景中都会涉及到,核⼼思路就是把⼀些常⽤的数据放到触⼿可及(访问速度更快)的地⽅,⽅便随时读取。对于计算机硬件来说,往往访问速度越快的设备,成本越⾼,存储空间越⼩,缓存是更快,但是空间上往往是不⾜的,因此⼤部分的时候,缓存只放⼀些热点数据 (访问频繁的数据)。
🌟 这⾥所说的 "触⼿可及" 是个相对的概念:
对于硬件的访问速度来说,通常情况下,CPU 寄存器 > 内存 > 硬盘 > ⽹络,那么硬盘相对于⽹络是 "触⼿可及的",就可以使⽤硬盘作为⽹络的缓存,内存相对于硬盘是 "触⼿可及的",就可以使⽤内存作为硬盘的缓存,CPU 寄存器相对于内存是 "触⼿可及的",就可以使⽤ CPU 寄存器作为内存的缓存。
📕2. 为什么要使用缓存呢?
在⼀个⽹站中,我们经常会使⽤关系型数据库 (⽐如 MySQL) 来存储数据,关系型数据库虽然功能强⼤,但是有⼀个很⼤的缺陷,就是性能不⾼(换⽽⾔之,进⾏⼀次查询操作消耗的系统资源较多)。
✍ 为什么说关系型数据库性能不⾼?
- 数据库把数据存储在硬盘上,硬盘的 IO 速度并不快,尤其是随机访问。
- 如果查询不能命中索引,就需要进⾏表的遍历,这就会⼤大增加硬盘 IO 次数。
- 关系型数据库对于 SQL 的执⾏会做⼀系列的解析,校验,优化⼯作。
- 如果是⼀些复杂查询,⽐如联合查询,需要进⾏笛卡尔积操作,效率更是降低很多。
📚 为什么并发量⾼了就会宕机?服务器每次处理⼀个请求,都是需要消耗⼀定的硬件资源的,所谓的硬件资源包括不限于 CPU,内存,硬盘,⽹络带宽。⼀个服务器的硬件资源本⾝是有限的,⼀个请求消耗⼀份资源,请求多了,⾃然把资源就耗尽了,后续的请求没有资源可⽤,⾃然就⽆法正确处理,更严重的还会导致服务器程序的代码出现崩溃。
如何让数据库能够承担更⼤的并发量呢? 核⼼思路主要是两个:
- 开源: 引⼊更多的机器,部署更多的数据库实例,构成数据库集群。(主从复制,分库分表等...)
- 节流: 引⼊缓存,使⽤其他的⽅式保存经常访问的热点数据,从⽽降低直接访问数据库的请求数量。
🌾 Redis 就是⼀个⽤来作为数据库缓存的常⻅⽅案
Redis 访问速度⽐ MySQL 快很多,并且处理同⼀个访问请求,Redis 消耗的系统资源⽐MySQL 少很多,因此 Redis 能⽀持的并发量更⼤。Redis就像⼀个 "护盾" ⼀样,把 MySQL 给罩住了。
- Redis 数据在内存中,访问内存⽐硬盘快很多。
- Redis 只是⽀持简单的 key-value 存储,不涉及复杂查询的那么多限制规则。
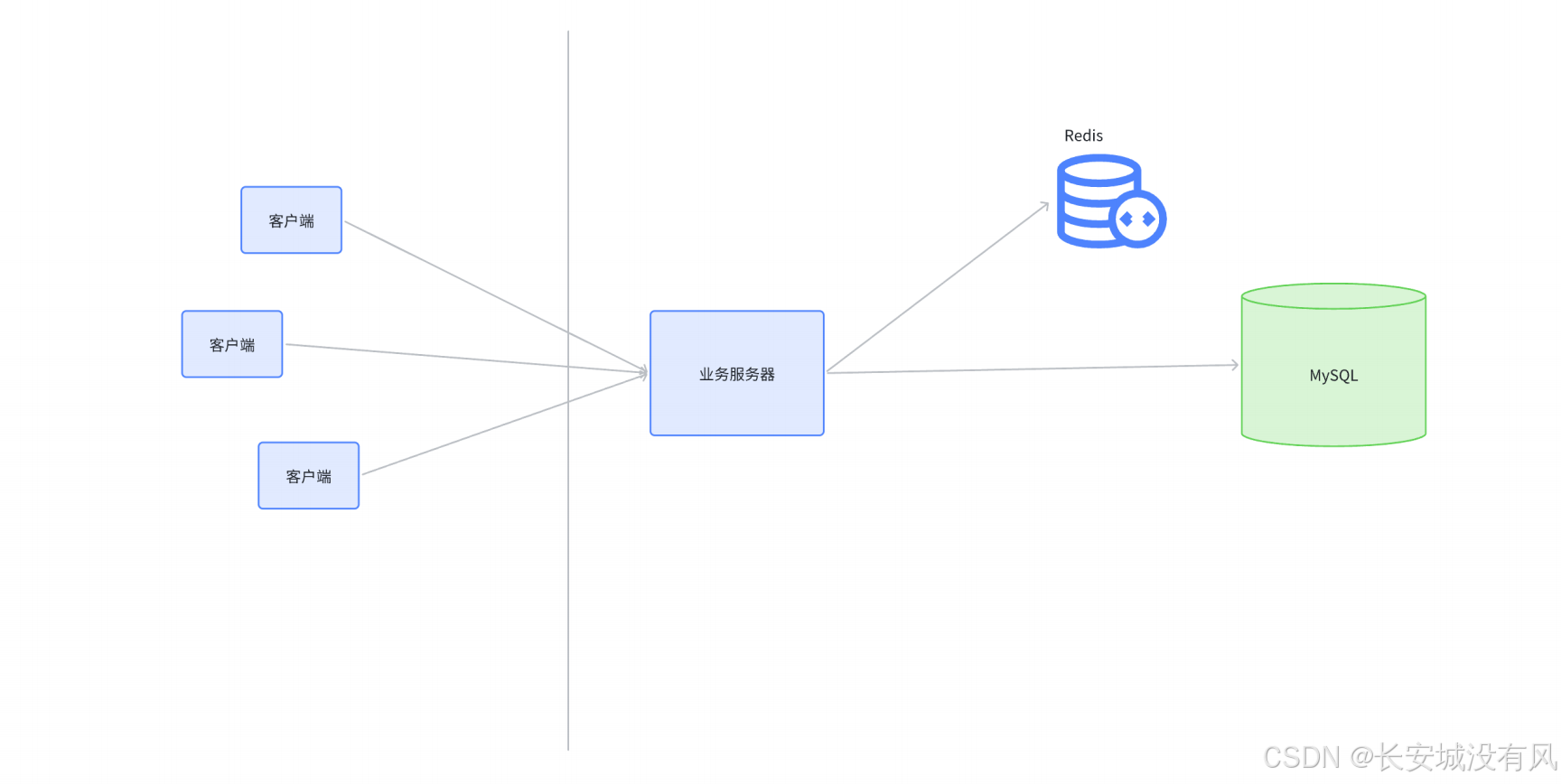
🚅 注意!缓存是⽤来加快 "读操作" 的速度的,如果是 "写操作",还是要⽼老实实写数据库,缓存并不能提⾼性能。
📕3. 缓存的更新策略
之前我们一再提及,Redis中的存的是热点数据,接下来又有一个重要的问题,什么是热点数据呢?我们又该如何保证缓存的是热点数据呢?
定期生成
每隔⼀定的周期(⽐如⼀天/⼀周/⼀个⽉),对于访问的数据频次进⾏统计,挑选出访问频次最⾼的前 N%的数据。
🥇 以搜索引擎为例
用户在搜索引擎中会输⼊⼀个 "查询词",有些词是属于⾼频的,⼤家都爱搜(鲜花,蛋糕,同城交友, 不孕不育...),有些词就属于低频的,⼤家很少搜。搜索引擎的服务器会把哪个⽤⼾什么时间搜了啥词,都通过⽇志的⽅式记录的明明白白,然后每隔⼀段时间对这期间的搜索结果进⾏统计 (⽇志的数量可能⾮常巨⼤,这个统计的过程可能需要使⽤ hadoop 或者 spark 等⽅式完成),从⽽就可以得到 "⾼频词表" 。
🥈 这种做法实时性较低,对于⼀些突然情况应对的并不好⽐如春节期间,"春晚" 这样的词就会成为⾮常⾼频的词,⽽平时则很少会有⼈搜索 "春晚"。
实时生成
先给缓存设定容量上限(可以通过 Redis 配置⽂件的 maxmemory 参数设定),接下来把用户每次查询:
- 如果在 Redis 查到了,就直接返回。
- 如果 Redis 中不存在,就从数据库查,把查到的结果同时也写⼊ Redis。
如果缓存已经满了(达到上限),就触发缓存淘汰策略,把⼀些 "相对不那么热⻔" 的数据淘汰掉,按照上述过程,持续⼀段时间之后 Redis 内部的数据⾃然就是 "热⻔数据" 了。
🛸通⽤的淘汰策略主要有以下⼏种(下列策略并⾮局限于 Redis,其他缓存也可以按这些策略展开):
- FIFO (First In First Out) : 先进先出把缓存中存在时间最久的 (也就是先来的数据) 淘汰掉。
- LRU (Least Recently Used) : 淘汰最久未使⽤的,记录每个 key 的最近访问时间,把最近访问时间最⽼的 key 淘汰掉。
- LFU (Least Frequently Used) : 淘汰访问次数最少的,记录每个 key 最近⼀段时间的访问次数,把访问次数最少的淘汰掉。
- Random :随机淘汰,从所有的 key 中抽取幸运⼉被随机淘汰掉。
🏕 理解上述⼏种淘汰策略:想象你是个皇帝,有后宫佳丽三千,虽然你是 "真⻰天⼦",但是经常宠幸的妃⼦也就那么寥寥数⼈(精⼒有限)。
后宫佳丽三千,相当于数据库中的全量数据,经常宠幸的妃⼦相当于热点数据,是放在缓存中的。
今年选秀的⼀批新的⼩主,其中有⼀个被你看上了,宠幸新⼈。⾃然就需要有旧⼈被冷落,到底谁是要被冷落的⼈呢?
FIFO: 皇后是最先受宠的,现在已经年⽼⾊衰了,皇后失宠。
LRU: 统计最近宠幸时间,皇后(⼀周前),熹妃(昨天),安答应(两周前),华妃(⼀个⽉前),华妃失宠。
LFU: 统计最近⼀个⽉的宠幸次数,皇后(3次),熹妃(15次),安答应(1次),华妃(10次),安答应失宠。
Random: 随机挑⼀个妃⼦失宠。
🌙 这⾥的淘汰策略,我们可以⾃⼰实现,Redis 也提供了内置的淘汰策略供我们直接使⽤,Redis 内置的淘汰策略如下:volatile-lru: 当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中使⽤LRU(最近最少使⽤)算法进⾏淘汰。
allkeys-lru:当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LRU(最近最少使⽤)算法进⾏淘汰。
volatile-lfu: 4.0版本新增,当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中,使⽤LFU算法进⾏删除key。
allkeys-lfu: 4.0版本新增,当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LFU算法进⾏淘汰。
volatile-random: 当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中,随机淘汰数据。
allkeys-random: 当内存不⾜以容纳新写⼊数据时,从所有key中随机淘汰数据。
volatile-ttl: 在设置了过期时间的key中,根据过期时间进⾏淘汰,越早过期的优先被淘汰。
noeviction: 默认策略,当内存不⾜以容纳新写⼊数据时,新写⼊操作会报错。
📕4. 缓存三剑客
✏️4.1 缓存穿透(Cache penetration)
什么是缓存穿透?
访问的 key 在 Redis 和 数据库中都不存在,此时这样的 key 不会被放到缓存上,后续如果仍然在访问该key,依然会访问到数据库,这就会导致数据库承担的请求太多,压⼒很⼤,这种情况称为缓存穿透。
为什么会产生缓存穿透?
- 业务设计不合理,⽐如缺少必要的参数校验环节,导致⾮法的 key 也被进⾏查询了。
- 开发/运维误操作,不⼩⼼把部分数据从数据库上误删了。
- ⿊客恶意攻击。
如何解决缓存穿透?
- 针对要查询的参数进⾏严格的合法性校验,⽐如要查询的 key 是⽤⼾的⼿机号,那么就需要校验当前key 是否满⾜⼀个合法的⼿机号的格式。
- 针对数据库上也不存在的 key ,也存储到 Redis 中,⽐如 value 就随便设成⼀个 "",避免后续频繁访问数据库。
- 使⽤布隆过滤器先判定 key 是否存在,再真正查询。
✏️4.2 缓存雪崩 (Cache avalanche)
什么是缓存雪崩?
短时间内⼤量的 key 在缓存上失效或者Redis服务器宕机,导致数据库压⼒骤增,甚⾄直接宕机。(本来 Redis 是 MySQL 的⼀个护盾,帮 MySQL 抵挡了很多外部的压⼒,⼀旦护盾突然失效了,MySQL⾃⾝承担的压⼒骤增,就可能直接崩溃。)
为什么会产生缓存雪崩?
⼤规模 key 失效, 可能性主要有两种:
- Redis服务器宕机
- Redis 上的⼤量的 key 同时过期(这种和可能是短时间内在 Redis 上缓存了⼤量的 key,并且设定了相同的过期时间)
如何解决缓存雪崩?
- 部署⾼可⽤的 Redis 集群,并且完善监控报警体系。
- 不给 key 设置过期时间 或者 设置过期时间的时候添加随机时间因⼦。
✏️4.3 缓存击穿(Cache breakdown)
什么是缓存击穿?
相当于缓存雪崩的特殊情况,针对热点 key ,突然过期了,导致⼤量的请求直接访问到数据库上,甚⾄引起数据库宕机。
如何解决缓存击穿?
- 基于统计的⽅式发现热点 key,并设置永不过期。
- 进⾏必要的服务降级,例如访问数据库的时候使⽤分布式锁,限制同时请求数据库的并发数。