zk02-知识演进
【尚硅谷】大数据技术之Zookeeper 3.5.7版本教程:https://www.bilibili.com/video/BV1to4y1C7gw
文章目录
- zk02-知识演进
- 1-知识总结
- 2-知识整理
-
- 1-【类uninx文件系统】+【观察者模式通知机制】
-
- [1)类 Unix 文件系统 -> ZAB原子事务广播](#1)类 Unix 文件系统 -> ZAB原子事务广播)
- [2)观察者模式通知机制 -> 监听器原理](#2)观察者模式通知机制 -> 监听器原理)
- [🔍 补充说明:](#🔍 补充说明:)
- [✅ 总结一句话:](#✅ 总结一句话:)
- 2-数据一致性方法
-
- 一、写入一条数据时到底发生了什么(正常流程)
- [二、崩溃恢复阶段(Leader 挂了重新选主)](#二、崩溃恢复阶段(Leader 挂了重新选主))
- 三、读一致性怎么保证
- [四、纠正 / 补充你原句的 3 个细节](#四、纠正 / 补充你原句的 3 个细节)
- 五、一句话总结
- 3-zookeeper监视器原理
- 4-zookeeper的leader和follower选举机制是不是和数据写入的proposal机制是一样的,都是基于zxid的ACK
- 5-ZooKeeper事务提交过程中,如果Leader宕机了怎么办?
- 6-选举新Leader后,Followers如何同步数据?
- 7-ZK在代码层面怎么保证每个操作都是原子的
- [8-ZooKeeper 如何保证事务日志的持久化?](#8-ZooKeeper 如何保证事务日志的持久化?)
- [9-ZAB 协议包含两个阶段: Leader election 阶段和 Atomic Brodcast 阶段](#9-ZAB 协议包含两个阶段: Leader election 阶段和 Atomic Brodcast 阶段)
-
- [一、Leader Election(领导者选举)阶段](#一、Leader Election(领导者选举)阶段)
-
- [1. 选举触发条件:](#1. 选举触发条件:)
- [2. 选举过程:](#2. 选举过程:)
- [3. 选举完成后:](#3. 选举完成后:)
- [二、Atomic Broadcast(原子广播)阶段](#二、Atomic Broadcast(原子广播)阶段)
-
- [1. 写请求处理流程(两阶段提交):](#1. 写请求处理流程(两阶段提交):)
- [2. 特点:](#2. 特点:)
- 总结对比:
- [10-ZooKeeper 的持久化机制](#10-ZooKeeper 的持久化机制)
-
- [✅ 1. 事务日志(Transaction Log)](#✅ 1. 事务日志(Transaction Log))
- [✅ 2. 快照(Snapshot)](#✅ 2. 快照(Snapshot))
- [✅ 3. 恢复流程(启动时)](#✅ 3. 恢复流程(启动时))
- [✅ 4. 配置参数(部分)](#✅ 4. 配置参数(部分))
- [✅ 5. 优化建议](#✅ 5. 优化建议)
- [✅ 总结一句话:](#✅ 总结一句话:)
- 11-KRaft的强一致性和ZAB的最终一致性最核心的区别是什么
- [12-KRaft 是怎么做到强一致性的?](#12-KRaft 是怎么做到强一致性的?)
- [13-ZAB 的最终一致性的理解](#13-ZAB 的最终一致性的理解)
- 14-ZAB也是强一致性吗?
- 15-ZAB协议对比KRaft的最终一致性
- 16-ZAB协议是强一致性,那怎么说zookeeper自己是最终一致性的分布式协调工具
- 17-那我是不是可以这样理解:最终一致性或者强一致性,是针对会不会读取到旧数据,不是针对是否是最新的数据(因为半数提交之后,不同节点的最新数据不一定一致)
- 18-Kafka数据的读取,一定是从Leader进行读取的吗?
- 19-zookeeper的数据读取可以从任意一个ZkServer中读取,还是从Leader中读取?
- 20-Kafka和zookeeper的一致性理解

1-知识总结
- 1-ZK核心设计:【类uninx文件系统】+【观察者模式通知机制】
- 1)类uninx文件系统->原子性设计
- 2)观察者模式通知机制->监听器原理
- 2ZK核心目的:【注册内容】并感知【内容变化】
- 1)向【统一入口】进行【内容注册】
- 2)【统一入口】可实时监听【内容变化】
- 3ZK应用场景->由节点动态上下线引发的场景应用
- 1)统一命名服务、统一配置管理、统一集群管理
- 2)服务器节点动态上下线、软负载均衡等
- 4-ZK集群工作机制
- 1)ZKClient如何保证数据一致性->每个ZKServer都有一份完整的数据
- 2)ZKServer之间如何保证数据一致性->【数据写入->由Leader广播Server,半数ACK后提交】+【Leader和Server之间数据同步】
- 3)Leader和Follower如何进行选举
- 5KRaft 通过"唯一 Leader 定序 + 半数以上写盘才提交 + 新 Leader 必须更全 + 冲突日志强制回滚对齐"这四板斧,确保:
- 1)所有副本最终拥有完全相同的日志;
- 2)任何一旦返回给客户端的写入都永远不会丢失或回滚。
- 这就是它宣称"强一致性"的全部底气
- 6-ZAB协议对比KRaft的最终一致性
- 全局单 Leader 把写请求转成事务 Proposal,并按 ZXID 严格保序;
- 2)Leader 收到半数以上 Follower 的 ACK 才在本地 commit,随后广播 COMMIT;
- 3)新 Leader 选举阶段会把自己日志补齐到 quorum 里最全,再强制所有 Follower 回滚-对齐;
- 通过以上手段保证"已提交事务"不会丢,且各副本最终完全一致。
- 7-ZAB强一致性协议 VS ZooKeeper最终一致性服务->两者谈论的层级不同,并不冲突
- 1)ZAB 协议 = 强一致日志;
2)ZooKeeper 服务 = 顺序一致(默认读可能滞后),所以文档说它是"eventually-consistent 的协调工具"。
- 1)ZAB 协议 = 强一致日志;
- 8-ZK写操作(关键字:【Server请求转发】+【Leader进行ZAB原子广播】+【二阶段提交】)
- 1)Server请求转发到Leader
- 2)Leader进行ZAB原子广播
- 1)【第一次提交】Follower将数据写入到本地日志,并给Leader进行ACK响应(此时这部分数据还不能被查询出来)
- 2)【第二次提交】Leader收到半数以上响应时,向Follower提交commit指令,Follower将数据写入内存(此时这部分数据才能被查询出来)
- 9-ZK读操作
- 每一个Server都可以提供查询请求(而Kafka只能使用Leader)->导致Zookeeper被定位是最终一致性的原因
2-知识整理
1-【类uninx文件系统】+【观察者模式通知机制】
1)类 Unix 文件系统 -> ZAB原子事务广播
- Zookeeper 的数据模型 确实类似于 Unix 文件系统,是一个层次化的命名空间 ,每个节点称为 ZNode。
- 每个 ZNode 可以存储数据,也可以有子节点。
- 原子性 体现在:每个操作(如创建、删除、更新)都是原子的,要么成功,要么失败,不会部分执行。
- 此外,Zookeeper 保证顺序一致性:所有客户端看到的数据更新顺序是一致的。
2)观察者模式通知机制 -> 监听器原理
- Zookeeper 提供了 Watcher 机制 ,这确实是观察者模式的实现。
- 客户端可以在读取某个 ZNode 时设置一个 Watcher,当该 ZNode 发生变化(如数据变更、子节点增减等),Zookeeper 会异步通知客户端。
- 这种机制使得客户端可以实时感知数据变化,而无需轮询。
🔍 补充说明:
| 特性 | 说明 |
|---|---|
| Watcher 是一次性的 | 一旦被触发,Watcher 就失效,需要重新注册。 |
| 通知是异步的 | 不保证实时性,但通常很快。 |
| Watcher 不携带数据 | 它只告诉你"某个节点变了",你需要重新读取数据。 |
✅ 总结一句话:
Zookeeper 的核心设计确实是"类 Unix 文件系统" + "观察者模式的通知机制",前者提供结构化数据存储和原子操作,后者实现高效的事件驱动通知。
2-数据一致性方法
数据一致性核心2个点:【数据写入->由Leader广播Server,半数ACK后提交】+【Leader和Server之间数据同步】
你的理解已经非常接近核心机制 了,但还缺几个关键细节。
ZooKeeper 并不是"简单地把数据写到所有 Server 然后半数 ACK 就完事",它底层依赖的是 ZAB(ZooKeeper Atomic Broadcast)协议,该协议把"写请求"当成**一条事务日志"来广播,并保证:
- 全局唯一顺序
- 崩溃恢复后依旧一致
- 只有提交过的事务才对客户端可见
下面给你一幅"完整拼图",你可以直接替换掉原先脑中的那张简化图。
一、写入一条数据时到底发生了什么(正常流程)
-
客户端把写请求发给任意一台 Follower/Observer
(也可以直接连 Leader,但生产环境通常前面挂客户端库+负载均衡)。
-
若请求落在 Follower:
Follower 把请求转发给 Leader → 进入 ZAB 阶段。
-
Leader 把这条请求包装成一个事务 Proposal:
- 分配全局单调递增的 zxid(64 位,高 32 位 epoch,低 32 位自增)
- 写本地磁盘日志(redo-log,默认 sync)
- 把 Proposal 按 zxid 顺序并发广播给所有 Follower
-
Follower 收到 Proposal 后:
- 先写本地磁盘日志(sync)
- 返回一个 ACK(携带本机最大 zxid)
-
Leader 统计 ACK:
- 含自己在内,"ACK 数 > 集群半数"(≥ quorum)即认为"可以提交"
- 向所有 Follower 发 COMMIT 消息(带上刚提交的 zxid)
-
Follower 收到 COMMIT 后:
- 把该事务应用到内存 DataTree(此时才正式改内存)
- 之后读请求才能看到新数据
-
最初那台 Follower 把响应返回客户端 → 调用返回成功
二、崩溃恢复阶段(Leader 挂了重新选主)
- 剩余节点进入 Looking 状态,基于 zxid + myid 投票
- 选出的新 Leader 必须拥有已提交事务的最大 zxid(由 ZAB 的 epoch 逻辑保证)
- 新 Leader 会先补齐 其它 Follower 缺失的提案:
- 把本地日志中所有 COMMIT 过的事务重新发送给 Follower
- Follower 把这些事务重放到本地 DataTree
- 直到集群中**"过半节点"**的日志完全一致,才开始接受新的写请求
→ 因此客户端永远不会读到"旧主已提交、新主却丢失"的数据
三、读一致性怎么保证
- ZooKeeper 默认是最终一致性读 :
客户端可能连到某台还没及时同步的 Follower,读到的数据略旧。 - 如果业务必须读到"最新已提交"数据,可以用 sync() + read 组合:
- 先对目标路径发一个 sync() 请求------它会强制让当前连接的 Server 从 Leader 拉一下最新 zxid;
- 再执行读操作,就能保证读到至少不早于 sync 时刻的已提交数据。
四、纠正 / 补充你原句的 3 个细节
| 你原句 | 需要修正/补充 |
|---|---|
| "每个 ZKServer 都有一份完整的数据" | 日志+内存 DataTree 是完整的,但 Observer 可以不参与投票,只异步拉取。 |
| "由 Leader 广播 Server,半数 ACK 后提交" | 准确说法是:Leader 广播 Proposal → 过半 ACK → Leader 发 COMMIT → 各 Server 改内存。单纯"广播数据"不够,必须走 ZAB 的两阶段(Proposal+Commit)。 |
| "Leader 和 Server 之间数据同步" | 日常写操作靠 ZAB 实时广播;崩溃后靠** Leader 选举 + 差异日志回捕(TRUNC + SNAP + DIFF)** 来对齐,而不是简单的全量同步。 |
五、一句话总结
ZooKeeper 通过 ZAB 原子广播协议 把"写请求"变成顺序一致的事务日志:
- 正常阶段:两阶段提交(Proposal + Commit)+ quorum 确认
- 崩溃阶段:选含最新已提交 zxid 的节点为新主,再补齐/回滚其它节点
- 读阶段:默认最终一致,可手动 sync() 拿到线性一致快照
因此,它才能保证 "客户端一旦收到成功响应,数据就永久存在,且后续任何节点崩溃、 Leader 切换都不会丢失这条已提交数据" ------ 这正是 ZooKeeper 所说的"单拷贝一致性"(single-system image)。
3-zookeeper监视器原理
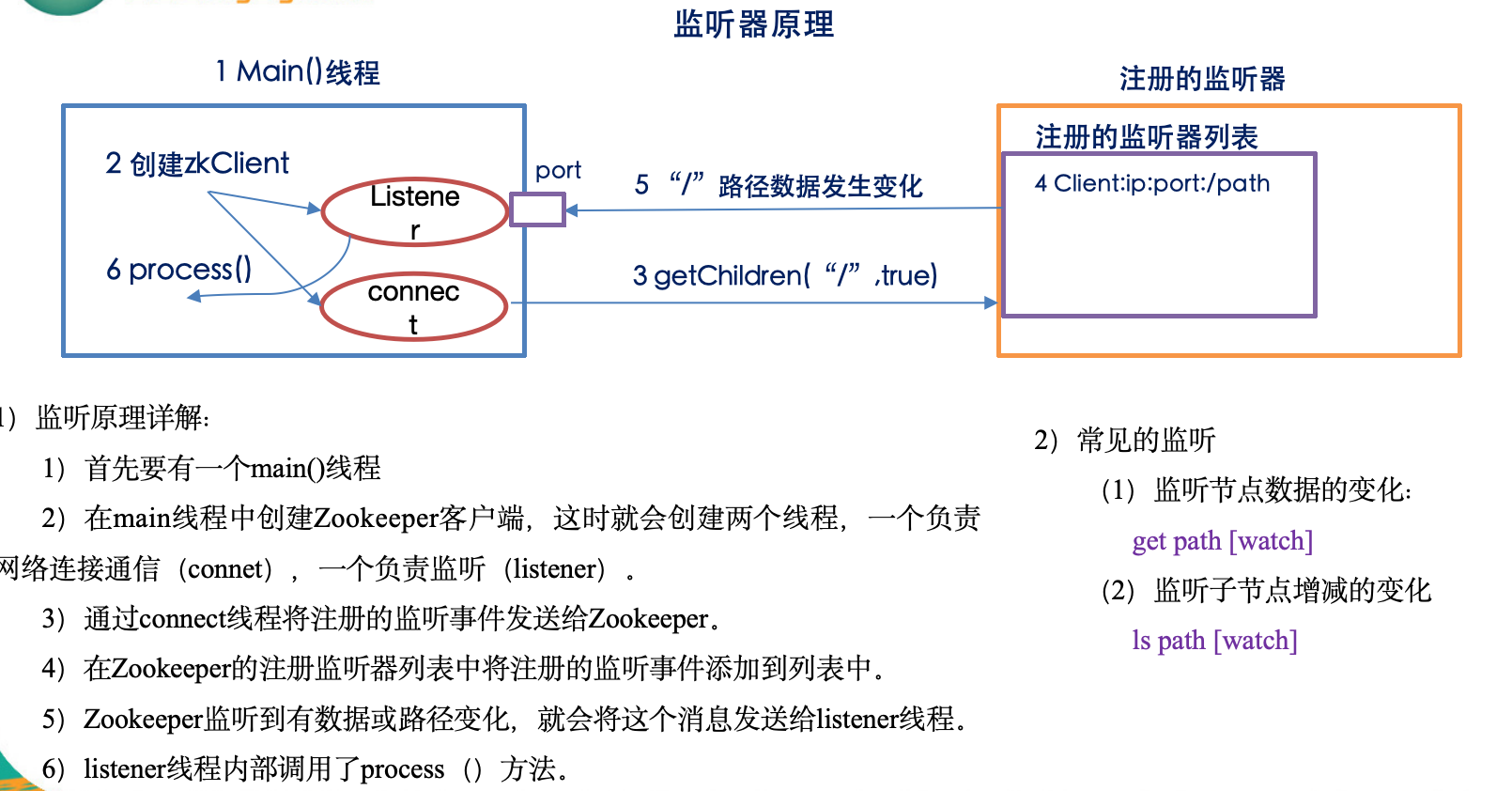
下面把 ZooKeeper 的"监视器"(Watcher)机制从** API 、底层实现、网络协议、事件流、典型坑**五个维度彻底拆开讲一遍。看完你就能明白:
- 为什么 Watch 只能被触发一次;
- 服务端到底存了什么;
- 客户端收到事件后数据却可能"看不见"是怎么回事;
- 怎么利用"异步回调 + 版本号"做出业务层可靠的监听框架。
一、API 视角:三种调用点、两类事件
-
可以挂 Watch 的读接口
- getData(path, watch?) → 监听"数据变更"
- exists(path, watch?) → 监听"节点创建、删除、数据变更"
- getChildren(path, watch?) → 监听"子节点列表增减"
-
事件类型(org.apache.zookeeper.Watcher.Event)
- NodeCreated、NodeDeleted、NodeDataChanged、NodeChildrenChanged
- 连接层事件:Disconnected/SyncConnected/Expired/AuthFailed
-
一次性语义
同一个 Watch 对象被触发后自动失效 ;想持续监听必须重新注册。
二、服务端视角:WatchManager + 轻量级指针
-
服务端不存"业务回调",只存"谁对哪条路径哪类事件感兴趣"。
- DataTree 里每个 ZNode 有三个 WatchManager:
-- dataWatches → getData/exists 挂的
-- childWatches → getChildren 挂的
-- existsWatches → exists 挂的(复用 dataWatches,单独队列方便触发)
- DataTree 里每个 ZNode 有三个 WatchManager:
-
注册过程(以 getData 为例)
- 读请求走到 FinalRequestProcessor,把(ServerCnxn, path, type) 三元组塞进对应的 WatchManager。
- ServerCnxn 就是 NIO 的一个连接句柄,内存占用极小(几十字节级)。
-
触发过程(setData 为例)
-
- 先改内存 DataTree、写事务日志、版本号 dataVersion++
-
- 把 dataWatches 里该 path 的列表拿出来,整体移到一个临时集合,原队列清空 → 保证一次性
-
- 对每个 ServerCnxn 发一个 WatchEvent 包(只含 path、type、zxid,不含新数据)
-
- 网络层把事件塞进客户端输出缓冲区,立即返回,不等待客户端 ACK
-
-
触发与提交顺序
- 事务必须先成功提交(ZAB 已落盘 + 过半 ACK)才会去触发 Watch;
- 因此客户端收到事件时,一定可以读到 ≥ 该 zxid 的数据(如果重新连到最新节点)。
三、客户端视角:ZKWatchManager + 异步线程回调
-
结构
- ZKWatchManager 维护三张 HashMap<String, Set>:
-- dataWatches / existWatches / childWatches - 每次读操作传 true 时,客户端把用户传入的 Watcher 对象同步放进对应 Map;
- 网络层收到 WatchEvent 后,IO 线程只负责把事件塞进事件队列 ,真正回调由 EventThread 单线程顺序派发。
- ZKWatchManager 维护三张 HashMap<String, Set>:
-
一次性实现
- 收到事件后,客户端先把对应 Map 里的 Watcher 删掉,再回调 → 与服务器保持语义一致。
-
重连逻辑
- SyncConnected 时,旧 Watch 会被服务端批量重新注册(见四);
- 但 Sasl/AuthFailed/Expired 不会恢复,必须用户重新建连接再挂。
四、网络协议:Watch 在 TCP 包里长什么样
-
请求挂 Watch
- 请求头里有一个 watch 布尔标志位(existsRequest、getDataRequest...);
- 服务端收到 true 才会注册,否则直接返回数据。
-
事件推送
- 响应报文类型为 WATCH_EVENT (-1) ,格式:
type(4) + state(4) + path(string) - 不带新数据、不带版本号,减轻网络峰值。
- 响应报文类型为 WATCH_EVENT (-1) ,格式:
-
重连批量同步
- 客户端 Session 重新建立后,会发 SetWatches 请求 :
把本地三张 Map 里所有 path 一次性打包发给新服务器; - 服务端收到后,瞬间重新注册对应 Watch,保证业务层无感切换。
- 客户端 Session 重新建立后,会发 SetWatches 请求 :
五、典型坑 & 实战技巧
-
"看到了事件却读不到新数据"
原因:客户端重连到旧 Follower,其数据还没同步。
解决:读之前先 sync(path),强制让该 Server 追一下 zxid。
-
"事件丢失"
场景:节点反复快速创建/删除,Watch 还没来得及重新注册。
解决:
- 收到 NodeDeleted 后 循环尝试 exists(..., true) 直到成功;
- 或者使用 递归监听框架(Curator 的 NodeCache/TreeCache)。
-
"海量 Watch 打爆内存"
- 一个 ZNode 上挂 10 万个 Watch,触发时要遍历 10 万连接,单线程炸掉。
- 生产建议:
-- 让业务监听固定父节点 而不是每个子节点;
-- 用 ephemeral sequential + 子节点变化事件 做分布式锁排队,避免百万 Watch。
-
高并发抢主场景
- 抢主失败后需要反复监听父节点,如果直接用 exists 重置 Watch,会把压力集中到一台 Follower;
- 优化:所有客户端监听 /leader/ephemeral_ 前缀 ,收到子节点变化事件后再读取列表,即可分散读压力。
六、一张图总结流程
客户端读请求 → 标记 watch=true
→ 服务端把 (连接,path) 塞进 WatchManager
→ 写请求成功提交 → 服务端抽 Watch 列表 → 发 Event 包
→ 客户端 IO 线程收到 → 删掉本地 Watcher → EventThread 回调用户代码
→ 用户重新注册(若需要)
七、一句话背下来
ZooKeeper 的 Watch 是一次性、轻量级、异步推送 的"触发器 ":
服务端只记"谁对哪感兴趣",事件里只告诉你"哪变了 ",
不包数据、不保证一直监听 ,
业务层必须主动重新注册 + 版本号/同步 才能做出可靠通知框架。
4-zookeeper的leader和follower选举机制是不是和数据写入的proposal机制是一样的,都是基于zxid的ACK
ZooKeeper 的 Leader 选举和事务提交(proposal)机制确实都依赖 zxid ,但流程和目的完全不同,不能简单等同为"基于 zxid 的 ACK"一句话。
-
选举阶段
- 触发:集群启动或原 Leader 失联后,所有节点进入 Looking 状态。
- 比较规则:先 epoch(高 32 位),再 zxid(低 32 位),最后 myid;值"大"者胜出。
- 目的:只选出"数据最新"的节点当 Leader,并不需要等待半数 ACK,只要某个节点能证明自己(epoch, zxid, myid)最优且获得超过半数投票即可当选。
-
事务提交阶段(原子广播)
- 流程:Leader 为每个写请求生成新 zxid → 发出 proposal → Follower 落盘并回 ACK → Leader 收集到 半数以上 ACK 后广播 commit。
- 目的:保证"已经提交"的事务在集群中不丢失,强调投票 ACK和** quorum**。
因此,两者仅共同点是:
- 都用 zxid 作为"全局时序"依据;
- 都需要"超过半数"这一概念(选举是"票数"过半,提交是"ACK"过半)。
但核心差异在于:
- 选举只看节点本地保存的最大 zxid,不需要远程 ACK;
- 提交必须等待 Follower 实时返回 ACK,依赖网络投票。
一句话总结:
"选举用 zxid 做静态比较选最优节点,事务用 zxid 做动态投票达成 quorum,两者不能混为一谈。"
5-ZooKeeper事务提交过程中,如果Leader宕机了怎么办?
ZooKeeper 的事务提交过程一旦Leader 宕机 ,会立即触发**"崩溃恢复"**流程,核心目标只有一句话:
"已提交的事务不能丢,未提交的事务不能生效。"
下面按时间线拆开给你看:
- 故障检测
- Follower 与 Leader 的 socket 断连或心跳超时(默认 tickTime×syncLimit)。
- 该 Follower 把状态设为 LOOKING,广播
LEADER_ELECTION包,整个集群重新进入选举。
- 重新选 Leader
- 选举算法(Fast Leader Election)会选出zxid 最大的节点当新 Leader。
- 这一步保证了:新 Leader 一定拥有最近一次已提交事务(因为已提交 ≥ 半数节点,而 zxid 最大者必在其中)。
- 数据同步阶段(关键!)
新 Leader 先不对外服务,而是和所有 Follower 做一次**"协商式"同步**,把集群状态拉到一致:
- 如果 Follower 的 zxid 正好等于 新 Leader 的 lastZxid → 无需同步,直接加入集群。
- 如果 Follower 的 zxid 落后 → Leader 把缺少的提案(proposal + commit)按顺序重新发一次(称为 DIFF 同步)。
- 如果 Follower 的 zxid 超前 (出现过未提交的事务)→ Leader 向它发送 TRUNC 指令,强制回滚到 lastZxid,丢弃那些"半吊子"事务。
- 极端情况下差距太大,会触发 SNAP 全量快照同步。
只有当超过半数节点完成同步后,新 Leader 才将状态切回 LEADING,集群重新接受写请求。
- 客户端视角
- 客户端对原 Leader 的未返回 写请求,会收到 ConnectionLoss/SessionExpired,需要重试。
- 已收到成功响应(即已达成 quorum commit)的写请求,保证继续存在 ;未达成 quorum 的写请求,自动失效。
一句话总结:
"Leader 宕机 → 重新选举 zxid 最大者 → 新 Leader 把集群数据拉回一致 → 已提交的事务必保留,未提交的事务必丢弃。"
6-选举新Leader后,Followers如何同步数据?
选举结束、新 Leader 诞生后,集群必须先"对齐账本"才能重新提供服务 。ZooKeeper 把这一步严格拆成三条路:DIFF、TRUNC、SNAP,统称 "数据同步阶段"(Synchronization Phase)。流程如下:
- 新 Leader 先不对外服务,把每个 Follower 的
lastZxid跟自己的lastZxid做比对,决定走哪条同步路径:
| Follower 状态 | 同步方式 | 动作说明 |
|---|---|---|
| 刚好相等 | 无需同步 | 直接加入集群,可以立即参与投票。 |
| 落后 | DIFF | Leader 把它本地事务日志 里缺失的提案(proposal+commit)按顺序逐条重放给 Follower;Follower 收到后写盘并应用到内存数据库。 |
| 超前 | TRUNC | 该 Follower 在旧 Leader 宕机前收到过尚未提交的提案 (zxid 比新 Leader 大)。新 Leader 会发送 TRUNC(zxid) 指令,强制把尾部未提交事务截断,回退到与新 Leader 一致的位置。 |
| 差距太大 | SNAP | 如果缺失的日志条目超过阈值(默认 1000 条)或者 Follower 根本没有日志文件,Leader 会生成一个最新快照(snapshot)+ 之后的少量 DIFF,一并发送;Follower 先清空本地数据目录,再加载快照,最后重放 DIFF。 |
- 同步完成标准
- 只有超过半数节点 (含 Leader 自己)完成上述同步后,新 Leader 才会把状态切换成 LEADING,集群重新开放读写。
- 没赶上的节点继续同步,直到满足条件才正式上岗。
- 关键实现细节
- 所有同步包(DIFF、TRUNC、SNAP)都走同一条LearnerHandler 线程 (Leader 侧)与Learner 线程(Follower 侧),保证顺序。
- 每条 DIFF 提案仍然走两阶段 形式:先
PROPOSAL,再COMMIT,让 Follower 的日志与 Leader 完全一致(包括 zxid、checksum、事务体)。 - 整个同步阶段不阻塞客户端重连 ,但客户端请求会被暂存或返回 ConnectionLoss,直到同步结束。
一句话记住:
"对齐账本三把刀:差多少补多少(DIFF),多出来砍掉(TRUNC),差距太大重抄整本(SNAP);过半对完账,集群才开张。"
7-ZK在代码层面怎么保证每个操作都是原子的
在源码层面,ZooKeeper 把**"一个 API 调用 → 一条事务 → 一条日志 → 半数落盘 → 内存应用"整条链做成不可打断的临界区**,从而保证每个 ZNode 操作的原子性。核心代码路径如下(以 ZooKeeper 3.8 为例):
- 客户端:请求打包成一次 "session 包"
ClientCnxn.SendThread.primeConnection()把 create/delete/setData 等调用统一封装成Request对象,一个请求对应一个唯一 xid;TCP 层保证要么整包发、要么整包丢,不会出现半包。
- 服务端网络层:原子入队
NIOServerCnxn.readPayload()/NettyServerCnxn.receiveMessage()收到完整包后,直接submitRequest()把请求塞进PrepRequestProcessor的阻塞队列submittedRequests(LinkedBlockingQueue),队列的入队是原子操作,此时请求要么在队列里,要么不在,不会半残。
- 预处理阶段:生成"事务提案"
PrepRequestProcessor.run()单线程循环消费队列,对每条请求做
-- 路径校验、ACL 校验、版本号校验;
-- 调用pRequest.getTxnFactory().create(create/delete/setData)生成TxnHeader + Record(事务体);
-- 把zxid分配给事务(ZookeeperServer.getNextZxid()原子自增);
这一步单线程串行化,保证同一时刻只处理一个请求,天然互斥。
- 提案阶段:原子广播
Leader.propose()把Proposal(含事务头、事务体、checksum)放进outstandingProposals并发往所有 Follower;- 这里用
synchronized (outstandingProposals)保证:
-- 提案编号(zxid)连续;
-- 提案内容不会被并发修改;
只要 Leader 本地落盘(SyncRequestProcessor)+ 收集到 quorum ACK ,该提案就被标记为 committed,整个 quorum 写日志动作是原子点。
- 日志落盘:事务日志 + 快照
FileTxnLog.append()先把整事务序列化到BufferedOutputStream,最后做一次write(ByteBuffer)+FileChannel.force(false)(fdatasync),要么全部刷盘成功,要么失败回滚,保证崩溃恢复时不会读到"半条事务"。- 日志格式带
txnChecksum,启动时若校验失败直接丢弃整条事务,避免部分写入。
- 内存数据应用:单线程串行
FinalRequestProcessor.processRequest()在单线程 (leader 的RequestProcessor链末尾)里把已提交事务按 zxid 顺序应用到DataTree:
--DataTree.processTxn()用synchronized (nodes)锁住整个内存树,同一时刻只有一个事务在修改内存结构 ;
-- 修改完成后才释放锁,因此客户端永远看不到"半成品"ZNode。
- 返回路径:一次性响应
- 内存应用成功后,
FinalRequestProcessor把rc(返回码)+stat+ 新数据一次性封装进ReplyHeader,通过同一 TCP 连接返回;如果中途崩溃,客户端只会收到连接断开,不会收到部分字段。
关键源码片段(3.8.0):
java
// 1. 单线程分配 zxid、生成事务
class PrepRequestProcessor implements RequestProcessor {
public void run() {
while (true) {
Request request = submittedRequests.take(); // 阻塞,原子拿请求
... 校验、封装
TxnHeader hdr = new TxnHeader(request.sessionId, request.cxid, getNextZxid(), ...);
Record txn = pRequest.getTxnFactory().create(request);
request.hdr = hdr;
request.txn = txn;
nextProcessor.processRequest(request); // 交给提案阶段
}
}
}
// 2. 原子广播 + quorum 落盘
class Leader {
synchronized void propose(Request request) {
Proposal p = new Proposal(request.zxid, request.hdr, request.txn);
outstandingProposals.put(request.zxid, p);
sendPacket(request); // 并发发给所有 Follower
}
// 收到 ACK 计数
synchronized void processAck(long zxid, SocketAddress follower) {
p.addAck(follower);
if (p.hasQuorum()) { // 原子点:quorum 达成
commit(zxid); // 标记 committed
}
}
}
// 3. 单线程应用到内存
class FinalRequestProcessor implements RequestProcessor {
public void processRequest(Request request) {
synchronized (dataTree.nodes) { // 全局锁,串行修改
dataTree.processTxn(request.hdr, request.txn);
}
// 一次性构造响应
ReplyHeader rh = new ReplyHeader(request.cxid, request.zxid, err);
cnxn.sendResponse(hrh, rsp, "response");
}
}一句话总结:
"网络整包 + 单线程预处理 + quorum 日志落盘 + 单线程内存锁 + 整包响应" 五级串行化,把每个 ZNode 操作变成不可分割的物理事务,从而在代码层面彻底保证原子性。
8-ZooKeeper 如何保证事务日志的持久化?
ZooKeeper 把"事务日志先落盘再返回 "当成一条铁律,实现了一套双缓冲 + 组提交 + 周期性刷盘 + 崩溃恢复 的组合拳,确保已经承诺的事务在断电、宕机后依旧可恢复。核心代码在 FileTxnLog 和 SyncRequestProcessor,拆开看:
- 双缓冲(TxnlLog 环形队列)
LinkedBlockingQueue<Request>把写请求做成无锁队列 ,Leader 的SyncRequestProcessor线程循环取出一批(默认 1000 个或 1 ms)请求,封装成TxnWithChecksum列表,称为一次 group(组提交)。- 这一批事务先写到内存缓冲区
BufferedOutputStream(默认 64 kB),不立即刷盘,减少 syscall。
- 日志格式与校验
- 每条事务 =
Len(4 B) + TxnHeader + TxnBody + Checksum(8 B),写入前计算 CRC32。 - 文件头部有
magic+version+dbid,尾部永远留空一个zero-filled块,半写断电时可通过长度字段快速判断是否完整。
- 强制刷盘(fsync / fdatasync)
- 当缓冲区满、或时间到、或已达成 quorum 的 commit 请求需要返回客户端前,调用
FileChannel.force(false)(JDK 底层就是fdatasync),把整组事务一次性刷到磁盘。 - 只有刷盘成功后,Leader 才会向 Follower/Observer 发送
COMMIT包,并给客户端返回成功;刷盘失败抛 IOException,当前 Leader 直接自杀,触发重新选举,防止"谎报"成功。
- 顺序写 & 预分配
- 日志文件命名
log.<zxid>,顺序追加写,避免随机 seek。 - 启动时预分配 64 MB 空文件(
FileTxnLog.fill()),减少 ext4/xfs 的块分配延迟。 - 写满后 roll 到新文件,旧文件永不修改,崩溃恢复时只需顺序扫描。
- 崩溃恢复校验
- 重启后
FileTxnLog.fastForwardFrom()从最新的log.<zxid>文件开始顺序解析 ,用长度字段 + checksum 检测最后一条完整事务 ,遇到半条直接 truncate,保证日志视图永远自洽。 - 然后加载最新快照 + 合法日志,重放到内存
DataTree,已刷盘的事务一条不丢,未刷盘的半条被截掉。
- 双路持久化(日志 + 快照)
- 除了事务日志,ZooKeeper 还会定时(默认每 100 000 次事务或 10 min)生成一个 snapshot. 内存镜像;
- 恢复时 "快照 + 增量日志" 两级机制,既保证持久化,又加快启动速度。
关键源码(3.8.0):
java
class SyncRequestProcessor implements RequestProcessor {
LinkedBlockingQueue<Request> queuedRequests = new LinkedBlockingQueue<>();
...
public void run() {
List<Request> toFlush = new ArrayList<>(1000);
while (true) {
Request si = queuedRequests.poll(1, TimeUnit.MILLISECONDS);
if (si != null) toFlush.add(si);
if (toFlush.size() > 1000 || (si == null && !toFlush.isEmpty())) {
// 1. 组提交:一次性刷一批
txnLog.append(toFlush); // 写内存缓冲
txnLog.commit(); // 2. 强制 fdatasync
for (Request r : toFlush) {
r.logLatency();
nextProcessor.processRequest(r); // 3. 刷完盘才能继续
}
toFlush.clear();
}
}
}
}
class FileTxnLog {
public synchronized void commit() throws IOException {
if (logStream != null) {
logStream.flush();
fc.force(false); // JDK 底层 fdatasync
}
}
}一句话总结:
"组提交刷盘前先缓冲,强制 fdatasync 成功才回 ACK;文件顺序追加 + 校验和 + 断电截断,重启靠快照 + 日志重放------已刷的事务一条不丢,没刷的半条不要,这就是 ZooKeeper 的持久化铁律。"
9-ZAB 协议包含两个阶段: Leader election 阶段和 Atomic Brodcast 阶段
ZAB(ZooKeeper Atomic Broadcast)协议是 ZooKeeper 实现分布式一致性的核心机制,它确实可以分为两个主要阶段:Leader election(领导者选举)阶段 和 Atomic broadcast(原子广播)阶段 。这两个阶段分别对应系统的崩溃恢复模式 和消息广播模式。下面是对这两个阶段的详细介绍:
一、Leader Election(领导者选举)阶段
当 ZooKeeper 集群启动或当前 Leader 崩溃时,系统进入崩溃恢复模式,首先进行的就是 Leader 选举。该阶段的目标是选出一个拥有最新数据的节点作为新的 Leader。
1. 选举触发条件:
- 集群刚启动时;
- Leader 节点宕机;
- Leader 与超过半数节点失联(如网络分区)。
2. 选举过程:
- 所有节点进入 LOOKING 状态;
- 每个节点先投票给自己,投票信息包含:
- ZXID:事务ID,越大表示数据越新;
- myid:服务器唯一编号;
- 节点之间互相交换投票信息,比较 ZXID 和 myid,优先选择 ZXID 大的节点;
- 获得 超过半数投票 的节点成为新的 Leader。
3. 选举完成后:
- 进入 发现(Discovery) 和 同步(Synchronization) 子阶段;
- 新 Leader 收集 Follower 的最新事务信息,并同步数据;
- 所有节点达成一致后,进入 Atomic broadcast 阶段。
二、Atomic Broadcast(原子广播)阶段
这是 ZAB 协议的正常工作阶段,也称为消息广播模式。在此阶段,ZooKeeper 集群对外提供读写服务,所有写操作都由 Leader 协调并广播给 Follower。
1. 写请求处理流程(两阶段提交):
- Leader 将客户端的写请求封装成一个 Proposal (提案),并分配一个全局唯一的 ZXID;
- Leader 向所有 Follower 发送 PROPOSAL 消息;
- Follower 收到后写入本地日志并返回 ACK;
- Leader 收到 过半数 ACK 后,发送 COMMIT 消息;
- Follower 收到 COMMIT 后正式提交事务。
2. 特点:
- 保证事务的全局顺序性 和原子性;
- 只要集群中 超过半数节点 正常,系统就能继续提供服务;
- 所有节点最终数据一致,满足最终一致性。
总结对比:
| 阶段 | 触发条件 | 目标 | 关键机制 |
|---|---|---|---|
| Leader Election | Leader 宕机、集群启动 | 选出数据最新的 Leader | 投票机制、ZXID 比较 |
| Atomic Broadcast | Leader 正常 | 保证事务顺序和一致性 | 两阶段提交、半数确认 |
这两个阶段交替运行,确保 ZooKeeper 在 Leader 故障时能够快速恢复,并在正常运行时保持数据一致和高可用。
10-ZooKeeper 的持久化机制
ZooKeeper 的持久化机制是保障其 数据一致性与可恢复性 的核心组件之一。它通过将内存中的数据状态持久化到磁盘,使得 ZooKeeper 在重启或崩溃后能够恢复数据,继续提供服务。
ZooKeeper 的持久化机制主要依赖以下两个关键文件:
✅ 1. 事务日志(Transaction Log)
- 文件名 :
log.<ZXID> - 作用 :记录所有写操作 (如
create、setData、delete)的事务日志。 - 特点 :
- 每个事务都有一个唯一的 ZXID(ZooKeeper Transaction ID);
- 日志是追加写入的,顺序性强;
- 默认不立即刷盘(可配置为周期性或同步刷盘);
- 是恢复数据的主要依据。
✅ 注意:事务日志是二进制格式,不能直接阅读。
✅ 2. 快照(Snapshot)
- 文件名 :
snapshot.<ZXID> - 作用:保存某一时刻内存中整个数据树(Data Tree)的完整状态。
- 特点 :
- 是内存数据的一个全量备份;
- 定期生成(如每 100,000 次事务后);
- 用于加速恢复过程,避免重放所有历史日志。
✅ 3. 恢复流程(启动时)
当 ZooKeeper 启动时,它会执行以下步骤恢复数据:
- 加载最新的快照 (
snapshot.<latestZXID>); - 重放该快照之后的事务日志 (
log.<ZXID>); - 恢复到崩溃前的最新状态;
- 开始对外提供服务。
✅ 4. 配置参数(部分)
| 参数 | 说明 |
|---|---|
dataDir |
快照存储路径 |
dataLogDir |
事务日志存储路径(建议与快照分离,提升性能) |
snapCount |
每多少个事务后触发一次快照(默认 100,000) |
fsync.warningthresholdms |
日志刷盘延迟警告阈值 |
✅ 5. 优化建议
- 分离日志与快照目录:将事务日志放在高速磁盘(如 SSD)上,提升写入性能;
- 定期清理旧文件 :ZooKeeper 不会自动清理旧日志和快照,需使用
autopurge.snapRetainCount和autopurge.purgeInterval配置自动清理; - 监控磁盘空间:日志文件增长较快,需防止磁盘打满。
✅ 总结一句话:
ZooKeeper 通过 事务日志(log)+ 快照(snapshot) 实现持久化,确保系统在崩溃后可恢复到最后一致状态,是其实现高可用和一致性的基石。
11-KRaft的强一致性和ZAB的最终一致性最核心的区别是什么
KRaft 的强一致性和 ZAB 的最终一致性最核心的区别在于它们对数据一致性的保证程度。
-
KRaft 的强一致性:确保在任何时刻,所有节点看到的数据都是一致的。这意味着一旦数据被写入,任何后续的读取操作都将返回最新的写入值。KRaft 通过使用 Raft 协议来实现这种强一致性,该协议确保了日志条目在大多数节点上复制后才被视为已提交,从而保证了数据的一致性和可靠性。
-
ZAB 的最终一致性:则允许在短时间内数据存在不一致的情况,但最终数据会达到一致状态。在 ZooKeeper 中,当 Leader 切换时,新 Leader 可能会拥有不同的数据子集,这可能导致在切换期间数据的不一致。然而,随着时间的推移,通过数据同步和复制,数据最终会达到一致状态。
总结来说,KRaft 的强一致性 提供了更高水平的数据一致性保证,而 ZAB 的最终一致性则在某些情况下可能会经历短暂的数据不一致,但最终会达到一致。这两种一致性模型在设计哲学和适用场景上有所不同,选择哪种取决于具体的应用需求和对数据一致性的要求。
12-KRaft 是怎么做到强一致性的?
KRaft 把"强一致性"拆成两件事:
- 所有副本上的日志必须完全相同;
- 一旦一条日志被提交(committed) ,就必须永远可读,且不会被覆盖或丢失。
Raft 协议用下面 4 个机制一次性把这两件事都钉死,因此 KRaft 直接继承了这些机制,也就实现了强一致性。
- 单点定序(Leader 唯一性)
- 任意 Term 内最多只有一个 Leader,由选举时的"获得半数以上选票"保证。
- 所有写请求只能走 Leader,Leader 给每条日志分配全局单调递增的索引+Term ,相当于给所有写操作生成全局唯一且递增的序列号 。
→ 日志的顺序在生成那一刻就被唯一确定,副本之间不会出现"并发乱序"。
- 日志复制多数派原则(Quorum)
- Leader 把日志条目通过 AppendEntries RPC 并发复制给所有 Follower;
- 只有半数以上 副本(包括 Leader 自己)都成功写盘并返回 ACK 后,Leader 才把该条目标记为 committed。
- committed 的条目立即应用到状态机,并对外可见。
→ 任何一条已提交日志必然存在于至少半数节点的磁盘上,后续任何 Leader 换主都必须能看到它,因此不会被回滚。
- 选举限制(Election Safety)
- 节点投票前会先比较日志的"up-to-date"程度:
-- 最后一条日志的 Term 更大,或
-- Term 相同但索引更大。 - 只有日志至少不比本节点旧 的候选者才能拿到选票。
→ 新 Leader 一定包含所有已提交日志,因此不会"分叉"出一条缺少旧提交记录的新分支。
- 日志一致性检查(Log Matching)
- AppendEntries 带前一条日志的索引+Term;
- Follower 发现本地对应位置不一致就拒绝,并强制删除冲突部分,再按 Leader 的顺序重新补齐。
→ 一旦 Follower 接受某条目,那么从日志开头到该条目为止的前缀完全与 Leader 一致,最终所有副本变成逐字节相同的日志。
一句话总结
KRaft 通过"唯一 Leader 定序 + 半数以上写盘才提交 + 新 Leader 必须更全 + 冲突日志强制回滚对齐"这四板斧,确保:
- 所有副本最终拥有完全相同的日志;
- 任何一旦返回给客户端的写入都永远不会丢失或回滚。
这就是它宣称"强一致性"的全部底气。
13-ZAB 的最终一致性的理解
ZAB 的最终一致性,是不是因为Leader向Follower提交Proposal后,收到半数以上的ACK之后就告知Server提交COMMIT,不能保证此时每个Server的数据都是最新的,但是随着后续Server和Leader进行DIFF 同步从而逐渐达到数据一致,我这样的理解对不对
你的理解里"半数 ACK 就返回客户端 "这一点是对的,但把 ZAB 的"最终一致性"归因于"后面再慢慢 DIFF 同步 "就不确切 了。
ZAB 在正常写路径 上其实已经把"所有副本日志"拉成完全一致 (严格单调、无空洞、无分叉),它之所以被说成"最终一致性"并不是靠事后的 DIFF 慢慢补齐 ,而是因为主备切换瞬间 允许出现两条不同的小尾巴 ,这两条尾巴对客户端的可见度规则不同,于是外部观察者可能在极短时间内读到不同版本的数据 。一旦新主选出,系统会立即把尾巴统一,而不是"慢慢"才一致。
下面把过程拆开说清:
-
正常写路径(广播阶段)
- Leader 生成 Proposal(zxid 单调递增)。
- 并发发给所有 Follower。
- 收到半数以上 ACK 后,Leader 本地写 COMMIT 并立即通知所有 Follower 写 COMMIT。
- 各 Follower 收到 COMMIT 后立即把该 Proposal 应用到内存 DataTree。
→ 这一步里,日志和内存状态在所有节点上都是强一致的,没有"先返回客户端再慢慢同步"的说法。
-
主备切换瞬间(崩溃恢复阶段)
- 旧 Leader 可能在"已提交给自己、但 COMMIT 消息还在网络路上 "时挂掉,导致
-- 部分 Follower 已经 COMMIT;
-- 部分 Follower 还没收到那条 COMMIT;
-- 旧 Leader 自己可能多一条"只在它本地提交"的 Proposal。 - 新 Leader 选举时,投票规则 + zxid 比较 保证:
-- 新 Leader 一定拥有最大 zxid ;
-- 所有已提交的 Proposal 都包含在新 Leader 的日志里(因为已提交 = 半数以上落盘,选民里至少有一个副本保存了它)。 - 新 Leader 会先和其余节点做一次快速同步 (TRUNC + DIFF + SNAP),把所有人日志截断/补齐到完全一致,然后才开放写服务。
→ 这一步也不是"慢慢" ,而是在几秒内 完成;完成前集群不可写 ,客户端只能读。读到的数据可能因连接不同节点而版本不同 ,这就是"最终一致性"的真正来源------切换窗口内允许读到旧快照,一旦同步结束,数据立即回到强一致。
- 旧 Leader 可能在"已提交给自己、但 COMMIT 消息还在网络路上 "时挂掉,导致
-
对外可见度规则
ZooKeeper 的读操作默认是本地内存读 ,不要求同步最新 Proposal;
因此即使日志已经一致,刚连到新节点的客户端 可能还没收到那次更新,看上去就像"数据还没同步过来"。
如果业务需要强一致读,可以用 sync() + read 组合,这时 ZK 会保证读到最新已提交的数据。
结论
-
ZAB 的"最终一致性"不是因为"后台慢慢 DIFF",而是因为
- 主备切换瞬间允许不同 follower 的小尾巴;
- 切换窗口内读操作不要求同步;
- 一旦新主完成 TRUNC/DIFF/SNAP,日志和状态树立即完全一致。
-
换句话说,日志层面 ZAB 是强一致的 (无分叉、无丢失已提交数据),客户端可见层面由于"本地读"和"切换窗口"才表现出"最终一致"。
14-ZAB也是强一致性吗?
是的,ZAB 也是强一致性协议。它通过以下机制保证了与 KRaft(Raft)相同的两条核心承诺:
- 所有副本最终拥有完全相同的日志;
- 任何一旦返回给客户端的写入都永远不会丢失或回滚。
具体实现上,ZAB 与 KRaft 类似,也采用了以下关键机制:
- 唯一 Leader 定序:所有写请求都由 Leader 转换为事务 Proposal,并分配全局唯一的 ZXID,严格保序。
- 半数以上写盘才提交:Leader 必须收到超过半数的 Follower 确认(ACK)后,才会提交事务并广播 COMMIT。
- 新 Leader 必须更全:选举过程中,新 Leader 会确保自己拥有 quorum 中最完整的日志。
- 冲突日志强制回滚对齐:新 Leader 会强制所有 Follower 回滚并补齐日志,确保所有副本一致。
因此,ZAB 协议在 ZooKeeper 中实现了线性化写 和顺序一致性读,满足强一致性的要求。
15-ZAB协议对比KRaft的最终一致性
ZAB 并不是"照抄" KRaft(Raft)那四步,但核心套路确实非常相似:
- 全局单 Leader 把写请求转成事务 Proposal,并按 ZXID 严格保序;
- Leader 收到半数以上 Follower 的 ACK 才在本地 commit,随后广播 COMMIT;
- 新 Leader 选举阶段会把自己日志补齐到 quorum 里最全,再强制所有 Follower 回滚-对齐;
- 通过以上手段保证"已提交事务"不会丢,且各副本最终完全一致。
因此,ZAB 在"半数写盘→提交""新 Leader 必须更全""冲突日志回滚"这几点上与 KRaft 几乎同构,只是术语、包格式和选举细节不同,所以也能给出同样的强一致性承诺 。
16-ZAB协议是强一致性,那怎么说zookeeper自己是最终一致性的分布式协调工具
先给结论:
- ZAB 协议本身是"强一致"的,它保证已经 commit 的那条写记录在所有节点上不会丢、顺序唯一。
- 但 ZooKeeper 对外提供的整体语义 是"顺序一致性(sequential consistency)",业界往往把它归为"最终一致性"家族,是因为客户端默认可能读到过期数据 ------不是协议做不到强一致,而是 ZooKeeper 故意把"读"做成不经过 quorum 确认的优化,从而牺牲一点实时性换取性能。
- 因此二者并不矛盾:底层 ZAB 是强一致日志,上层 ZooKeeper 服务出于性能考虑只承诺"顺序一致",所以文档里会说它是"eventually-consistent 的协调服务"。
下面把细节拆开说清。
一、ZAB 的强一致到底指什么
- 只有一条 Leader 给 proposal 分配单调递增的 zxid,commit 前必须收到 ≥⌈N/2⌉ 个 ACK。
- 新 Leader 选举时,先把自己的日志补齐到"quorum 中最全",再强制所有 follower truncate + 对齐。
- 由此保证:一旦一条写被服务端返回"OK",它就永不丢失,且在所有节点上顺序一样------这就是协议层面的强一致。
二、ZooKeeper 对外 API 的一致性等级
ZooKeeper 给客户端做了两层承诺:
-
写操作(create/setData/delete...)
全部走 Leader → ZAB → commit,线性化写(linearizable writes)。
-
读操作(getData/getChildren...)
默认直接由任意节点本地内存返回,不经过 quorum 。
带来的后果:
- 同一个客户端如果迁移连接,可能"时光倒流"读到比刚才还旧的数据;
- 不同客户端并发读,可能一个读到新值一个读到旧值。
因此"读"不是线性化的,只满足两条较弱保证:
- 顺序一致性:同一个客户端的读写操作,看到的顺序与提交顺序一致;
- 最终一致性:如果停止写,过一段时间后所有客户端都会看到最新值。
三、为什么 ZooKeeper 不把所有读也做成强一致?
- 协调服务场景里读占 90% 以上,若每次读都走 quorum,性能直接跌到 Paxos/Raft 的水平,吞吐量会差一个量级。
- 业务上往往只需要"单调读""因果读"就够了,ZooKeeper 提供了 sync() 调用:
客户端在读之前显式 sync(),服务器会把该读请求挂在一条"伪写"后面走一次 ZAB,就能保证读到最新已提交数据。
换句话说,强一致读能力 ZooKeeper 有,只是默认不用。
四、总结一句话
ZAB 协议 = 强一致日志;
ZooKeeper 服务 = 顺序一致(默认读可能滞后),所以文档说它是"eventually-consistent 的协调工具"。
两者谈论的层级不同,并不冲突。
17-那我是不是可以这样理解:最终一致性或者强一致性,是针对会不会读取到旧数据,不是针对是否是最新的数据(因为半数提交之后,不同节点的最新数据不一定一致)
不是的。
"强一致 / 最终一致"并不是在讨论"能不能读到旧数据"这么简单,而是在描述整个系统对"已经返回给客户端成功"的那条数据所给出的保证:
-
强一致(线性化)
一旦某次写被服务端确认成功,之后任何客户端、任何节点、任何读操作 都能立刻看到这条写(或者看到比它更新的值),不可能再退回到更旧的状态。
换句话说,系统对外表现得像"所有操作按某个全局时钟顺序瞬间生效"。
-
最终一致
写完得到确认后,某些客户端在某些节点上仍可能在一段时间内读到旧值 ;只要后续不再有新的写,最终所有节点都会收敛到新值。
这里"旧值"可以是"成功返回之前的值",也可以是"成功返回之后、但尚未同步到该节点的值"。
回到你提到的"半数提交后不同节点最新数据不一定一致"------
- 在强一致系统 里,这条"最新数据"只要已经被确认(commit),之后的任何读都必须能读到它(或更新的),不允许再退回去;
- 在最终一致系统 里,即使这条数据已确认,某个节点/某个客户端当下仍可能读不到它,这就是"读到旧数据"的来源。
所以关键区别不是"有没有旧数据",而是**"已经确认成功的写,能否立刻被所有后续读看到"**。
强一致 = 立刻可见;最终一致 = 可能延迟可见。
18-Kafka数据的读取,一定是从Leader进行读取的吗?
先给一句话结论:
Kafka 读消息默认只从 Leader 分区读 ;Follower 副本不会对外提供读服务,除非你把 ReplicaSelector 换成自定义实现且客户端版本 ≥ 2.4,并显式把 client.rack 配置好,才能做"就近读"(follower fetching)------但那条读链路仍然要先把对应 Follower 提升成 同步副本 (ISR),且读取范围不能超过它已复制的 HW,因此本质上还是"从 ISR 成员读",而非任意旧副本都能读。
下面分几点展开。
- 服务端角度
- 每个 topic-partition 同一时间只有一台 broker 是它的 Leader,该 broker 负责所有 Produce 和所有 Consume 的请求路由。
- 其余副本叫 Follower,只做被动拉取(replica.fetcher),把数据抄到本地磁盘,不对外提供读服务。
- 这样设计是为了:
-- 保证 Offset 单调、连续,简化消费逻辑;
-- 避免"读扩散"带来的额外一致性检查和缓存同步;
-- 让高水位 (HW) 更新路径单一,易于实现"已提交消息才能被消费"的语义。
- 特例:Follower Fetching(2.4+)
Kafka 从 2.4 开始支持"就近读"优化,目的是让跨机房/云可用区的消费者减少网络费用或延迟。
- 客户端必须设置
client.rack=xxx,且服务端给 broker 也配置了broker.rack。 - 如果某个 Follower 与消费者在同一个 rack,且该 Follower 已经在 ISR 里,Controller 会把这部分读请求重定向到该 Follower。
- 读的时候仍然要遵守 HW 限制------Follower 未复制到的消息不会返回,因此不会破坏一致性。
- 该特性默认关闭,需要显式把
replica.selector.class设成org.apache.kafka.common.replica.RackAwareReplicaSelector并打开allow.follower.fetching=true。
- 旧版本 / 无 rack 配置时
只要没开 follower fetching,或者客户端版本 < 2.4,所有 FetchRequest 都会打到 Leader;Follower 只承担"备份+高可用"角色。
- 消费端能否"自己连任意 broker 去读文件"?
不能。Kafka 协议里只有 Fetch API,而 Fetch API 由 Leader(或上面说的 ISR Follower)统一处理;消费者无法跳过协议直接读某台 broker 的日志文件。
一句话总结
默认情况下,Kafka 的数据读取一定走 Leader;只有在 2.4+ 并显式开启机架感知 follower fetching 时,才可能从 ISR 中的 Follower 读,但绝不会让非 ISR 副本对外提供读服务。
19-zookeeper的数据读取可以从任意一个ZkServer中读取,还是从Leader中读取?
可以从任意一个 ZooKeeper 服务器(只要它已正常连接且处于可用状态)读数据 ,不必、也默认不会 去找 Leader。
但读到的值可能"滞后",因为 Follower/Observer 把请求直接本地内存返回,不经过 quorum 确认------这正是 ZooKeeper 只提供"顺序一致性"而非"线性一致性"的原因。
- 服务端角色
- Leader :负责所有写请求(create/setData/delete/setACL)的提案与提交。
- Follower :参与写投票,同时直接对外提供读服务。
- Observer (可选):不参与投票,只同步数据并对外提供读服务,用于水平扩展读性能。
- 读写路径
- 写:客户端发请求 → 若连的不是 Leader,当前服务器会返回 "I'm not the leader" 重定向信息;客户端再重新连到 Leader 完成写。
- 读 :getData、getChildren、exists ... 任何节点直接在本地内存快照里返回 ,不转发、不投票、不等 Leader。
结果:
-- 性能高(本地内存读);
-- 可能读到"尚未同步最新 commit"的旧值;
-- 同一个客户端如果一直连着同一台 Follower,ZooKeeper 会保证"单调读"------不会读到比上一次还旧的值(顺序一致性)。
- 想强制读到最新值?
客户端在读操作前显式调用sync():
java
zk.sync(path, null, null);
byte[] data = zk.getData(path, false, null);sync() 会让当前服务器先向 Leader 发一次"追赶"请求,把日志拉到最新高水位,再执行后续读,从而拿到线性化读效果------代价是多一次 RTT。
一句话总结
ZooKeeper 的读取默认就近在任意 Follower/Observer 本地完成 ,不需要经过 Leader;只有写才必须走 Leader。若业务需要"强一致读",显式 sync() 即可。
20-Kafka和zookeeper的一致性理解
我的理解是否正确:
判断Kafka和zookeeper的服务是不是最终一致性或者强一致性,是针对会不会读取到最新的数据来进行判断的:
强一致性协议:保证已经 commit 的那条写记录在所有节点上不会丢、顺序唯一
- Kafka不管是KRaft协议还是ZAB都是强一致性的数协议(此时谈论的强一致性是【保证已经 commit 的那条写记录在所有节点上不会丢、顺序唯一】)
- Zookeeper使用的是ZAB的强一致性的协议(此时谈论的强一致性是【保证已经 commit 的那条写记录在所有节点上不会丢、顺序唯一】)
但是会不会读取到最新的数据
- Kafka因为使用Leader对外提供查询服务,所有的数据写入Leader后同步到Follower(有一个HW的最好水位)来控制数据是否课件,所有提供的数据一定是HW可见范围的最新(但不是一定是LEO的最新数据)
- Zookeeper因为每个ZkServer提供查询服务,但是因为Leader同步数据到Follower时只要半数以上通过就Commit了,所以每个Server不一定是最新数据,所以Zookeeper是最终一致性服务你的思路已经很接近,但把"协议强一致性"和"服务对外一致性语义"混在了一起,容易得出"Kafka 是强一致、ZooKeeper 是最终一致"这种不够精确的结论。下面按两条线重新梳理:
一、协议层面(KRaft / ZAB)
- 两者都是强一致日志复制协议
‑ 写请求 → Leader 生成记录 → 收到 quorum ACK → 提交(commit)。
‑ 一旦 commit,该记录在所有节点上永不丢失、顺序唯一 ,这叫"线性化写"或"强一致日志"。
所以你说"KRaft、ZAB 是强一致性协议"在这一点上完全正确。
二、服务对外语义(用户能观察到的"读")
这里才真正决定用户把系统叫"强一致"还是"顺序一致 / 最终一致"。
-
Kafka(0.11+,含 KRaft)
‑ 读只能 从 Leader(或已开启 follower-fetching 的 ISR 成员)拉取,且返回上限被 HW 截断;
‑ 任何成功写入且已 commit 的消息,随后发起的读都一定看得见 (单调读 + 读己之写),并且全局顺序固定;
‑ 因此 Kafka 对外提供的是顺序一致性 (sequential consistency),很多场景里也被当成"强一致"来使用------但它并不是严格意义上的线性一致性,因为读路径没有 quorum 确认,只是"Leader 本地 HW"决定可见性。
所以:
"Kafka 读到的一定是 HW 范围内最新" ✅
"Kafka 是强一致服务" ❌(更准确的词是顺序一致)
-
ZooKeeper
‑ 读可落在任意节点,默认本地内存立即返回,不经过 Leader;
‑ 因此一个客户端可能读到"commit 之后但尚未同步到该节点"的旧值;
‑ 只保证"同一个会话的读写顺序一致",不保证实时读到最新 commit ;
‑ 如果想强一致读,需要显式
sync()。所以官方文档说 ZooKeeper 是"顺序一致性"或"最终一致性"服务,而不是"强一致性"服务。
三、结论一句话
- 协议:KRaft、ZAB 都是强一致日志(commit 后不丢、顺序唯一)。
- Kafka 服务:顺序一致(默认读必为 HW 内最新,但不是线性化)。
- ZooKeeper 服务:顺序一致 / 最终一致(默认读可能滞后,可 sync() 升级成线性化读)。
因此,把"会不会立即读到最新数据"作为判断对外一致性语义的依据是可以的,但不要把"协议强一致"直接等价成"整个系统是强一致服务"。