unsetunset1 背景unsetunset
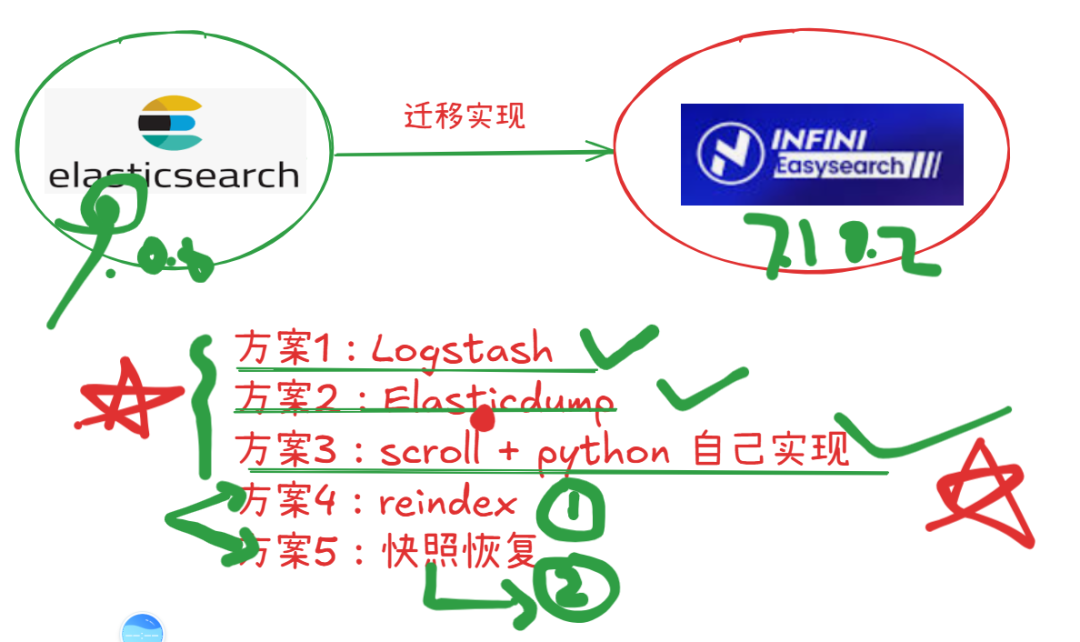
在将云端 Elasticsearch 数据迁移到本地 Easysearch(INFINI Easysearch)的过程中,我们评估了 5 种常见的迁移方案,最终确定了 3 种可行方案。
本文将分享实战经验和踩坑记录。
unsetunset2 迁移方案对比unsetunset
✅ 可行方案
方案1:Logstash
视频:
优点:
-
官方推荐方案,稳定可靠
-
支持数据过滤和转换
-
适合大规模数据迁移
适用场景: 需要数据清洗或转换的迁移任务
方案2:Elasticdump

视频:
优点:
-
轻量级工具,使用简单
-
支持索引映射和数据分离导出
-
适合中小规模数据迁移
适用场景: 快速迁移单个或多个索引
方案3:Python 自定义脚本
视频:
优点:
-
灵活性最高,可自定义逻辑
-
结合 scroll API 实现高效批量读取
-
可添加数据校验和错误处理
适用场景: 有特殊需求或需要精细控制的迁移任务
❌ 不可行方案

方案4:Reindex
失败原因: SSL 证书路径构建异常
从截图可以看到错误信息:
go
PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException:
unable to find valid certification path to requested target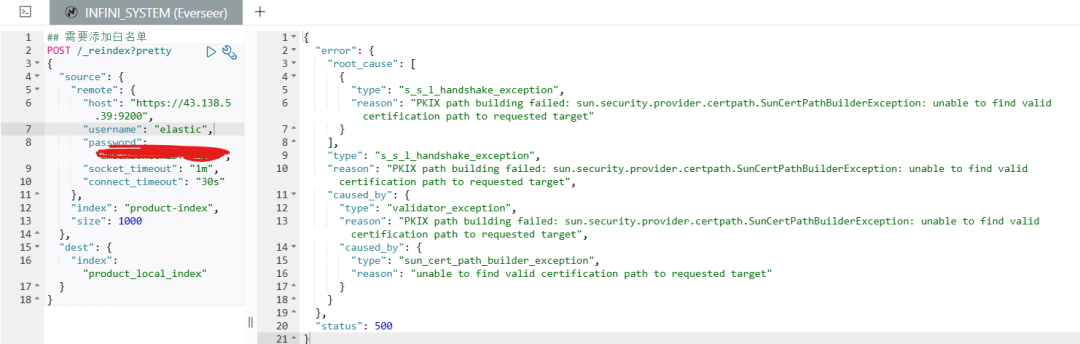
根本原因: 云端 Elasticsearch 和本地 Easysearch 之间存在 SSL/TLS 证书验证问题,跨网络的 reindex 操作无法建立安全连接。
方案5:快照恢复
失败原因: 快照格式不兼容
错误信息:
go
{
"error": {
"type": "parsing_exception",
"reason": "Failed to parse object: unknown field [uuid] found"
},
"status": 500
}
根本原因: Elasticsearch 和 Easysearch 的快照元数据格式存在差异,uuid 字段无法被 Easysearch 正确解析,导致快照无法恢复。
unsetunset3 推荐方案选择unsetunset
| 数据量级 | 推荐方案 | 理由 |
|---|---|---|
| < 10GB | Elasticdump | 简单快速 |
| 10GB - 100GB | Logstash | 稳定高效 |
| > 100GB | Logstash + Python | 分批迁移,可监控 |
| 特殊需求 | Python 自定义 | 灵活可控 |
| [ ] |
unsetunset4 实战建议unsetunset
4.1 迁移前准备
在开始迁移之前,务必做好充分的准备工作。
首先要确认目标 Easysearch 的版本与源 Elasticsearch 的兼容性,特别是索引映射、查询语法和聚合功能是否支持。
其次需要评估源端的数据量、索引数量和文档总数,根据网络带宽和机器性能预估迁移时间,避免在业务高峰期进行大规模迁移。
最后要制定完善的回滚方案,包括保留源数据、记录迁移起始时间点,以及准备快速切换回源端的应急预案,确保迁移失败时能够快速恢复业务。
4.2 迁移中注意
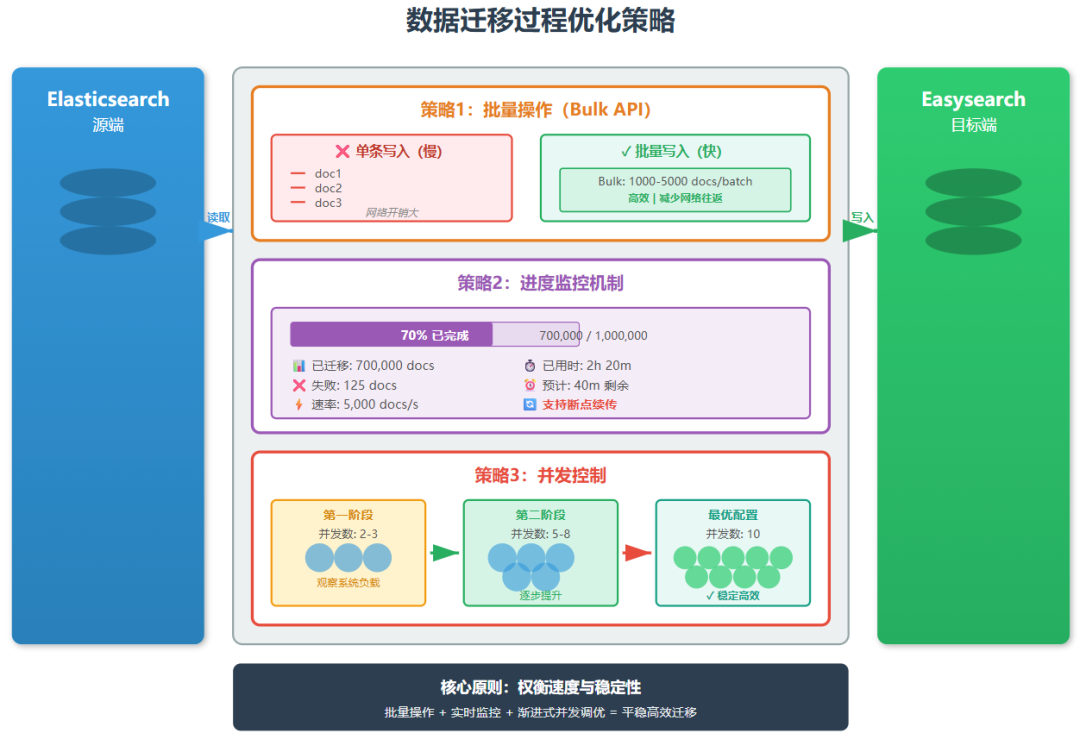
迁移过程中需要权衡速度与稳定性。建议使用批量操作(bulk API)而非单条写入,通常每批 1000-5000 条文档能够获得较好的性能。
同时要实现完善的进度监控机制,实时记录已迁移的文档数、失败记录和错误日志,便于问题排查和断点续传。
另外要合理控制并发度,避免对源端造成过大压力或导致目标端资源耗尽,建议从较小的并发数开始测试,逐步调优到最佳配置,确保迁移过程平稳进行。
4.3 迁移后验证
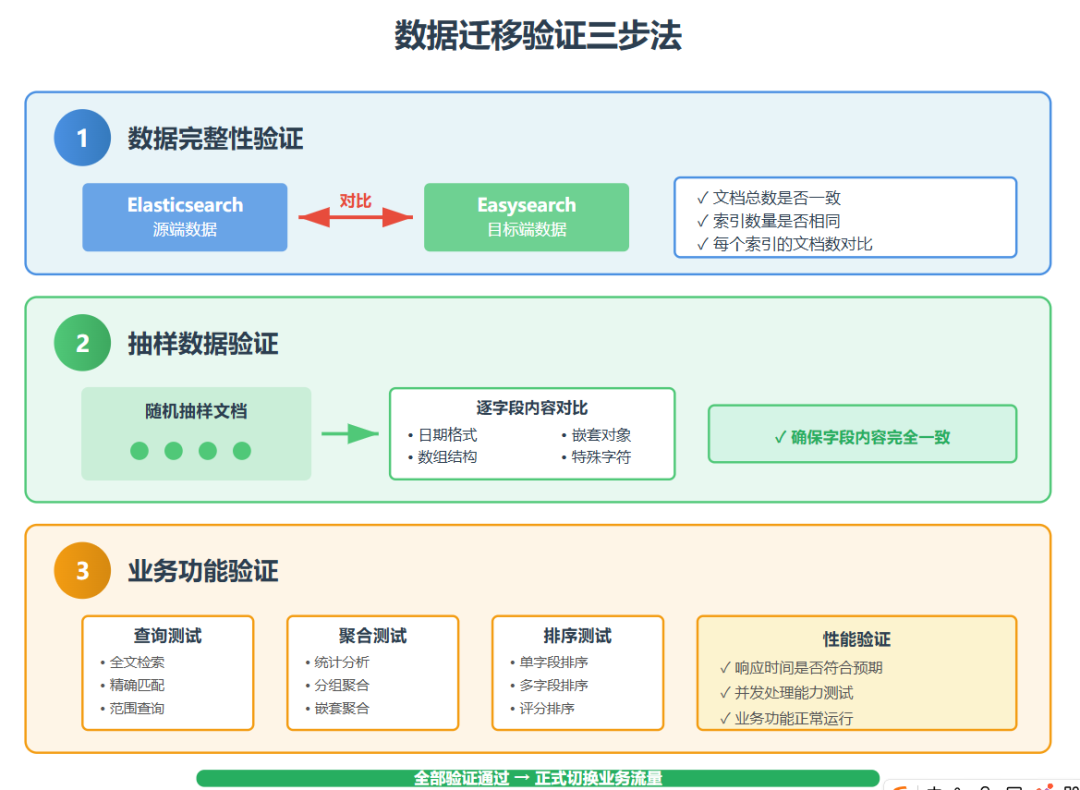
迁移完成后的验证环节至关重要,不能仅凭工具提示成功就认为迁移完成。
首先要对比源端和目标端的文档总数、索引数量以及每个索引的文档数,确保数据完整性。
其次应该进行抽样验证,随机抽取部分文档对比原始数据和迁移后数据的字段内容是否一致,特别关注日期、数组、嵌套对象等复杂字段类型。
最后要在目标端执行常用的查询、聚合、排序等操作,验证业务功能是否正常,响应时间是否符合预期,只有通过全面验证后才能正式切换业务流量。
unsetunset5 总结unsetunset
跨产品的数据迁移需要充分考虑兼容性问题。本次实践证明,基于 API 的数据传输方案 (Logstash、Elasticdump、Python)比基于存储的方案(快照、reindex)更加可靠。建议优先选择成熟工具,在遇到特殊需求时再考虑自定义开发。

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn------ElasticStack进阶助手

抢先一步学习进阶干货!