大模型发展这两年,应用型 AI 的焦点一直在 "提示工程"(prompt engineering),但随着更强大的大语言模型(LLM)走向多轮、长时间的自主行动,一个更关键的概念开始走到台前:上下文工程(context engineering)。
与其把精力放在如何雕琢每一句提示,不如把问题聚焦到:怎样构造和维持 "最可能让模型产生期望行为" 的上下文?
本文是参考 Claude 官网博客的总结,文章原文:www.anthropic.com/engineering...
1. 什么是上下文工程
上下文,是在一次 LLM 推断过程中被纳入采样的全部 token 集合,上下文工程的核心任务,是在模型固有约束下,优化这些 token 的效用,以更稳定地获得预期结果。
要驾驭 LLM,往往需要 "在上下文中思考":把模型任意时刻能读取到的一切状态视为整体,并评估这些状态可能产生的行为。
2. 上下文工程 vs 提示工程
- 提示工程:编写和组织模型指令以获得最佳输出,通常聚焦系统提示如何写得清晰、有效。
- 上下文工程:在推断时动态策划和维护 "最优信息集" ,不仅包含提示,还包含工具、外部数据、消息历史、模型上下文协议(MCP)、环境状态等。
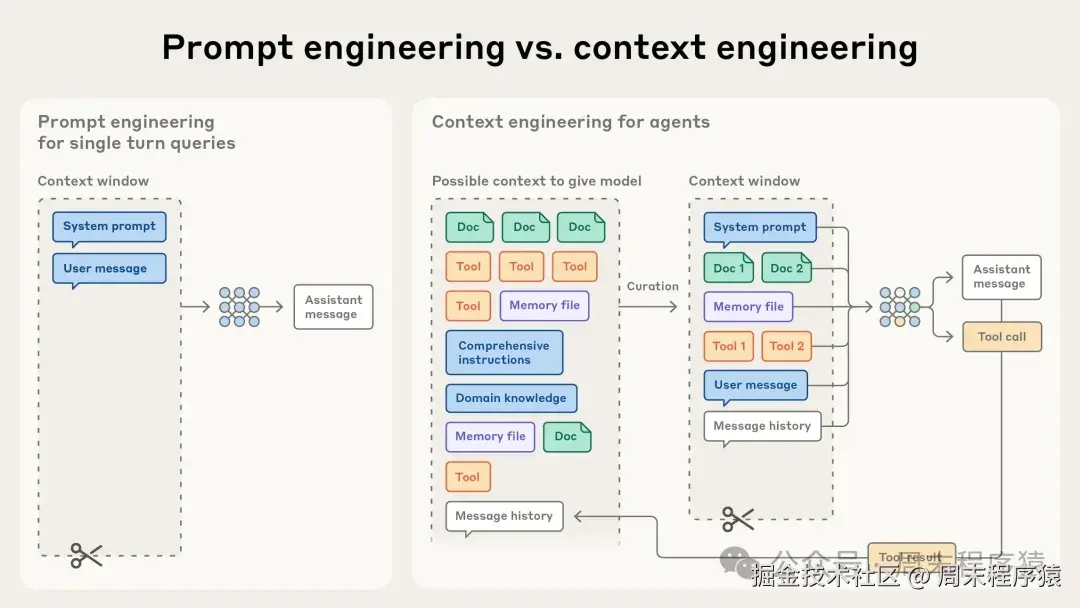
随着我们构建的代理(agent)变得更有能力、能在更长时间维持自治并反复调用工具,我们的工作不再是一次性写好一个提示,而是在每一轮决定 "往模型里放什么,不应该放什么"。
代理循环运行会不断产生新数据,这些信息必须被周期性筛选、提炼。
"上下文工程" 的艺术就在于:在有限的上下文窗口中,选取最有价值的子集。
3. 为什么 "上下文工程" 对强代理至关重要?
模型上下文越长,性能不一定越好,大量基准研究揭示了 "上下文腐化" (context rot):当上下文 token 增加,模型从中准确检索信息的能力会下降,这不是某个模型的特例,而是普遍现象,只是不同模型的退化曲线更缓或更陡。
- 有限注意力长度:像人类的工作记忆一样,
LLM的注意力资源是有限的,每纳入一个token,都会消耗注意力预算的一部分,从而降低对其他信息的分配能力。 - 架构约束:
Transformer允许任意token关注到任意其他token,导致n²指数级别增长,当上下文变长,模型捕捉这些关系的能力被摊薄,此外,训练数据中短序列更常见,模型对 "极长序列的全局依赖" 往往经验不足。 - 位置编码插值:诸如位置编码插值的技术能让模型 "适配" 更长序列,但会带来一定的位置信息理解退化,因此,长上下文下的模型表现更像 "渐进变差",而非悬崖式崩溃:依旧强,但在信息检索、长程推理方面精度略降。
这些问题需要用更好的处理方法:把上下文视为稀缺资源,并以工程化方式加以管理,是构建强大代理的基础。
4. 什么是有效上下文?
目标是用尽可能少的高信号 token 最大化产出概率,落实到实践层面,各类上下文组件都要贯彻 "信息密度高、指导性强、冗余小" 的原则,主要这几方面:
系统提示(system prompt)
- 语言要清晰、直接,给出 "恰到好处" 的指令高度,避免两端的常见失败模式:
-
- 过度硬编码的复杂逻辑(脆弱、维护成本高)
- 过于笼统、假定共享语境的 "空话",缺乏可操作信号
- 可以把提示组织成分区(如背景信息、核心指令、工具使用准则、输出格式描述),并用清晰的标签或标题分隔,格式细节的重要性在降低,但结构清晰仍能有助于模型。
- 追求 "最小完整信息集" :不必刻意短,但要确保必要信息齐备、无冗余,建议从一个 "最小可用" 提示起步,用最强模型测试,围绕失败模式迭代加入明确的指令和示例。
工具(tools)
- 工具是代理与环境互动、拉取新上下文的通道,工具必须令信息返回 "token 高效",并鼓励代理采取高效策略。
- 设计工具时遵循" 单一职责、鲁棒、用途清晰",输入参数要描述明确、无歧义,并契合模型的自然优势。
- 警惕工具集过于庞杂或功能重叠,导致选择困难,如果人类工程师都拿不准该用哪个工具,代理也难以做对。 保持工具集的 "最小可行集" 不仅提升可靠性,还方便在长时交互中做维护与上下文修剪。
示例(few-shot)
- 少样本示例仍是强烈推荐的最佳实践,但不要把所有边界条件都挤进提示,试图罗列每一条规则。
- 更好的做法是精心挑选 "多样而典型" 的示例,直观描摹期望行为,对 LLM 来说,示例往往胜过冗长说明。
总体原则:在系统提示、工具、示例、消息历史等各组件上保持 "信息紧凑而有用"。
4.1 低效的样例
样例1:低效的系统提示
markdown
你是一个非常聪明的全能 AI,尽可能全面地回答所有问题。 无论问题是什么,都要先给出10步解决方案和详细解释。 如果问题涉及价格,则必须先搜索"pricing"关键字;如果是技术问题则必须按下列条件分支:
- 如果包含"error",先假设用户使用的是Linux,再给出Linux专属排错步骤;
- 如果包含"timeout",请把所有相关文档全文粘贴进来,以免遗漏;
- 如果问题很复杂,请写一篇至少1000字的长文来解释背景、历史和可能的未来演进。
请务必列出所有可能的边界情况(不少于20条),并逐条覆盖。 尽量引用你记得的一切信息,避免遗漏。
# 输出
不限制格式,尽量详细,越长越好。 样例2:低效的工具提示
diff
- search: 任意搜索(字符串或正则或自然语言),返回所有匹配文档的全文内容与元数据(可能很大)。
- semantic_search: 与search类似,但"更智能",返回更长的上下文片段。
- list_docs: 列出所有文档并返回每个文档的首5页内容,防止错过重要信息。
- fetch_document: 输入doc_id,返回完整文档(不做截断)。
- open_url: 打开任意URL并把网页完整HTML塞回上下文。
(说明模糊,职责重叠,返回内容过大且无长度限制)样例3:低效的少样本
diff
示例1(定价问题):
- 输入:我们的专业版多少钱?
- 输出:逐条列出30条可能的价格方案、所有历史版本定价、每个地区的税率、以及可能的促销活动;同时粘贴相关文档全文以备参考。
示例2(技术问题):
- 输入:API 请求出现 timeout 怎么办?
- 输出:先贴出所有网络相关文档全文,再给出一个长达2000字的网络排错手册,覆盖DNS、TLS、路由、BGP等所有可能性,最后再总结。 4.2 高效的样例
样例1:高效的系统提示
markdown
## 角色
你是"企业知识库问答与行动项生成"代理,目标是在有限上下文内准确回答,并附上文档引用;必要时提出精炼的后续行动。
## 目标
- 高信号:以尽可能少的token交付准确答案与清晰引用。
- 稳健:不确定时按需检索;避免加载全文。
- 可执行:当信息不足,提出具体的下一步。
## 指令
1) 先用工具检索,再回答;避免凭空臆测。
2) 优先返回摘要与引用,不要粘贴大段原文。
3) 若检索结果不足或冲突,说明不确定点并提出下一步(如缩小查询、定位章节)。
4) 遵守输出格式,控制总长度(答案≤200字,引用≤3条)。
## 工具指南
- 先 search_docs(query) 获取候选与片段摘要;
- 用 get_doc(doc_id, section_hint, max_chars=1000) 读取必要部分;
- 用 write_note(key, summary) 记录关键结论与未决项,供后续轮次引用。
## 输出格式
以Markdown返回:
- 答案(简洁结论)
- 引用(最多3条,格式:文档名 · 章节/段落 · 摘要)
- 下一步(当信息不足时)样例2:高效的工具
php
- search_docs(query: string) -> [{doc_id, title, score, snippet}]
说明:语义检索,返回最多5条候选,含简短片段snippet;不返回全文。
- get_doc(doc_id: string, section_hint?: string, max_chars?: number=1000) -> {title, section, excerpt}
说明:按提示抓取指定章节或邻近段落,长度受max_chars限制,返回精炼摘录excerpt。
- write_note(key: string, summary: string) -> {ok: boolean}
说明:将关键结论与未决项持久化,便于后续调用;不回填长文本到上下文。
(职责单一,参数明确;返回内容受限以节省token)样例3:高效的少样本
scss
示例1:定价问答(有答案)
- 输入:专业版的月费是多少?
- 工具:search_docs("专业版 定价"); get_doc(top.doc_id, "价格/订阅", 800)
- 输出:
答案:专业版月费为¥199(按月订阅)。
引用:专业版定价 · 订阅与计费 · "专业版:¥199/月"
下一步:如需年度方案,请检索"年度定价"。
示例2:技术故障(需要更多信息)
- 输入:API 请求出现 timeout,如何排查?
- 工具:search_docs("API timeout 排查"); get_doc(top.doc_id, "网络与重试", 800)
- 输出:
答案:建议先检查网络连接与重试策略(超时阈值、重试间隔)。
引用:服务可用性指南 · 超时与重试 · "建议超时≥3s,指数退避重试"
下一步:请检索"区域网络状态"或提供具体报错信息。
示例3:无答案场景(信息不足)
- 输入:有没有针对巴西市场的专属折扣?
- 工具:search_docs("巴西 市场 折扣")
- 输出:
答案:当前未检索到巴西市场专属折扣的正式说明。
引用:营销政策总览 · 地区优惠 · "未包含巴西的专属折扣条目"
下一步:请查询"区域促销公告"或联系市场团队获取最新政策。 5. 运行时上下文检索与 "代理式搜索"
我们将 "代理" 简化定义为:LLM 在循环中自主使用工具,随着模型提升,代理自治能力增强,能更好地独立探索与纠错。
- 传统做法:在推断前用嵌入检索,把相关资料预先塞入上下文。
- 新的方案:"即时"(just-in-time)上下文策略,代理维护轻量引用(如文件路径、存储查询、网页链接),在需要时用工具动态加载数据,而非一口气把所有数据预处理入上下文。
这一策略像人类的认知:我们不背整库的内容,而是借助文件系统、收件箱、书签等外部索引按需调用。
它还有额外好处:引用的元数据(命名、层级、时间戳、大小)本身就是指导信号,帮助代理更合理地评估用途与相关性。
通过探索,代理逐步揭示重要上下文,并只维护必要的 "工作记忆",其余用 "笔记" 持久化,这能避免在冗余信息里迷失。
当然以上的方案不一定适合你当前的工程,基于实际场景也可以权衡混合策略:
- 即时探索通常比预先检索慢,而且需要更精心的工程指导(工具可用性、导航启发式),否则代理可能滥用工具、走弯路、错过关键信息。
- 在许多场景里,混合策略更优:部分数据预取以提速,其余由代理按需探索,比如把关键说明文档直接放入上下文,同时提供 glob、grep、head、tail 等原语,让代理就地检索文件、分析数据,绕过陈旧索引和复杂语法树的负担。
- 相对静态的领域(法律、金融)往往更适合混合策略,随着模型能力跃升,设计会逐步放手,让智能模型更自由地做 "智能行为",在此过渡期,对团队的建议始终是:用 "最简单且有效" 的方案。
5.1 低效的样例
diff
# 场景
目标:找出过去1小时 API 超时率上升的根因,并给出可执行行动项。
# 预处理(推断前)
- 用嵌入检索关键字 "timeout", "latency", "error"
- 将所有匹配文档(Wiki 页、运行手册、SRE 备忘、过去事故报告)的大段内容粘贴入上下文
- 将最近24小时的日志文件(/logs/api/*.log)全文截断到前3MB后仍塞入
- 将监控平台的几张图表(以Markdown导出)和完整查询DSL放入
# 传入模型的初始上下文(≈20k tokens)
- Wiki: 《API超时全指南》(3,000+字)
- 运行手册:网络栈排查(2,500+字)
- 事故报告:2023‑09‑17 高延迟事件(摘要+长引用)
- 日志:api‑gateway.log(最近24h前半段)
- 日志:auth‑service.log(最近24h前半段)
- 监控:Latency 95th/99th、Error Rate 图表说明与查询DSL全文
- 若干无关的边缘案例(误检)
...(大量冗余、上下文污染)
# 第1轮推断行为
- 模型在冗余信息中"捡针",关注分散,回溯变慢
- 将不相关的旧事故细节混入当前分析
- 给出冗长结论(>1,500字),包含多条假设与过度覆盖
# 输出问题
- 结论不聚焦,包含过期配置与不适用策略
- 后续行动不具体:建议"全面检查网络与依赖",成本高
- Token 浪费,且后续轮次难以保持上下文清晰5.2 高效的样例
bash
# 场景
目标不变:定位过去1小时超时率上升的根因,输出精炼行动项与引用。
# 初始上下文(≈300 tokens)
- 任务说明:排查过去1小时的 API timeout spike
- 轻量引用(不加载内容):
- 日志根路径:/logs/api/
- 监控面板URL(id=latency_p95, error_rate)
- Wiki 索引:SRE/Runbooks/Timeout.md, Incidents/
- 工具可用:list_files, grep, head/tail, read_partial, query_metrics, open_wiki, write_note
# 第1轮(探索起点:用元数据缩小范围)
- list_files("/logs/api/", last_modified>=now-90m)
- 返回(文件名·大小·修改时间):
- api-gateway.log(420MB, 09:15)
- auth-service.log(180MB, 09:12)
- payments-service.log(95MB, 09:17)
- 决策信号:
- 修改时间接近事件窗口,大小提示数据量与复杂度
- 优先检查 gateway(流量汇聚点)
- grep("/logs/api/api-gateway.log", "timeout", window=last_60m)
- 返回匹配统计与最近片段的偏移量
- tail("/logs/api/api-gateway.log", n=200, from=offset)
- 观测模式:timeout集中在某条上游路由
- query_metrics(panel="error_rate", range=last_60m, filter="service=gateway route=/v1/orders")
- 结果:09:05‑09:20 错误率升高,与日志吻合
- write_note("hypothesis", "超时集中在 /v1/orders 路由,时间对齐监控峰值;可能与下游 auth-service 连接池耗尽相关")
# 第2轮(渐进披露:加载必要片段)
- grep("/logs/api/auth-service.log", "connection pool|timeout", window=last_60m)
- head("/logs/api/auth-service.log", n=100, from=matched_offset-500)
- 结果:09:05 开始出现 "pool exhausted" 警告
- open_wiki("SRE/Runbooks/Timeout.md#connection-pool")
- 只取节选(max_chars=600):推荐将 pool.size 从 200 提升至 400,并启用指数退避
- query_metrics(panel="latency_p95", range=last_60m, filter="service=auth")
- 结果:p95 在 09:05 附近突升,与连接池告警时间一致
- 更新工作记忆(上下文仅保留三条核心摘录)
- 摘录1:gateway 路由 /v1/orders timeout 片段(~200行尾部)
- 摘录2:auth‑service pool exhausted 告警片段(~80行)
- 摘录3:Wiki Runbook 连接池节选(~400字)
- 其他细节写入持久笔记(write_note),不留在上下文
# 第3轮(收敛与行动)
- 结论(≤200字):超时由 auth‑service 连接池耗尽引发,集中影响 /v1/orders;与监控峰值时间吻合
- 引用(≤3条):日志片段偏移、监控查询ID、Wiki小节锚点
- 行动项:
- 临时:提升 auth 连接池至 400 并启用指数退避;观察 15 分钟
- 根因复盘:评估本周订单高峰的流量建模与容量规划
- 跟进:记录变更与影响范围到 Incidents/2025‑10‑18.md
# 上下文管理
- 工作记忆:仅保留当前决策所需的3个摘录
- 持久化:详细日志偏移、图表链接、附加线索写入笔记(不占用上下文)
- Token 用量:每轮≈1‑2k tokens,随检索渐进增加但保持可控6. 长时任务的上下文工程
当任务跨越数十分钟到数小时,超过上下文窗口容量时,代理需要专门技术维持连贯性、目标导向与状态记忆,使用更大窗口的模型并不能解决问题:再大的窗口也会遭遇上下文污染与相关性衰减。
我们实践出三类应对手段:压缩、结构化笔记、多代理架构。
压缩(Compaction)
- 当对话接近窗口上限,先高保真总结,再以该总结重建新上下文,保留关键决策、未解决问题、实现细节,丢弃重复的工具输出或不再有用的信息。
- 工程要点是 "取舍的艺术":过度压缩会丢掉后来才显得关键的细节,建议用复杂的代理轨迹调教压缩提示,先最大化召回率(尽可能捕获所有相关信息),再迭代提升精准度(去掉冗余)。
- 低风险的轻量压缩举措是 "清理历史工具调用结果":一旦工具结果在很早的历史中出现,通常无需再次原样保留。
结构化笔记(Agentic Memory)
- 让代理定期把重要信息写入上下文外的持久笔记(如 NOTES.md、待办清单),并在需要时拉回上下文。
- 这是一种低开销的持久记忆机制,适合复杂项目的进度跟踪、依赖管理、关键策略保留,跨越几十次工具调用仍保持连贯。
- 实践表明,即便在非编码领域,结构化记忆也能显著提升代理能力:它能维护地图、目标计数、策略效果,跨越多次上下文重建仍能连续推进长期计划。
多代理架构(Sub-agent)
- 将大任务拆分为专长明确的子代理,每个子代理独立探索、保持干净的上下文,主代理负责高层规划与结果统筹。
- 子代理可用大量
token深挖细节,但只返回凝练的摘要(如1,000--2,000 tokens),这样就实现了清晰的关注点分离:细节搜索的上下文隔离在子代理中,主代理只处理综合与决策。 - 在复杂研究与分析任务中,这一模式往往比单代理更稳健。
如何选择策略(按任务特征)
- 压缩:适合需要大量来回互动、对话连续性的任务。
- 结构化笔记:适合里程碑明确、迭代推进的开发类任务。
- 多代理:适合并行探索收益显著的复杂研究与分析。
7. 总结上下文功能原则
- 明确目标与评估标准:期望的行为具体是什么?怎么度量成功?
- 从最小上下文开始:用最强模型测底线表现,围绕失败模式增补信息。
- 精炼系统提示:把"刚刚好"的指令高度写清楚,结构分区,去掉硬编码的脆弱逻辑。
- 筛选工具:保留最小可行集,明确参数与用途,避免重叠与选择歧义。
- 精挑示例:多样而典型,优先展示期望的推理与输出形态。
- 设计检索策略:根据任务选择预检索、即时检索或混合;提供轻量引用与基础命令。
- 管理上下文污染:上线压缩与历史清理,优先清理冗余工具输出。
- 建立记忆机制:持久笔记/文件式内存,记录目标、进度、关键决策与依赖。
- 考虑多代理:对复杂任务引入子代理,要求返回高质量摘要。
- 持续迭代:基于真实代理轨迹调参提示与策略,以召回和精准度为双目标。
如果以上内容你觉得太多,最有效的一条建议就是:上下文尽量足够小,一次只做少量的任务。