 comfyui官方blog 10月17发了一篇blog,原文地址:https://blog.comfy.org/p/introducing-imagenworld
comfyui官方blog 10月17发了一篇blog,原文地址:https://blog.comfy.org/p/introducing-imagenworld
这里整体翻译下:
文章摘要:
ImagenWorld (https://tiger-ai-lab.github.io/ImagenWorld/)正是为实现这一目标而创建的大规模基准测试数据集:让模型的失败案例可被观察、可被解释。
文章正文:
我们都见过令人惊叹的生成图像,但那些从未出现在展示图库中的失败案例呢?要是我们能清晰看到模型在哪些地方出错了,会怎么样?
ImagenWorld 正是为实现这一目标而创建的大规模基准测试数据集:让模型的失败案例可被观察、可被解释。它包含六项主要任务,用于测试图像生成与编辑的不同方面,涵盖从文本生成图像(TIG-text-to-image generation)到多参考图编辑(MRIE-multiple-reference image editing)------ 在 MRIE 任务中,模型需将多张参考图的信息整合为一张连贯的图像。
通过聚焦真实世界任务,ImagenWorld 会评估模型如何处理复杂、多步骤且开放式的指令 ------ 这类指令与真实用户的需求高度相似。
所有任务均覆盖六个不同的视觉领域,能全面、真实地反映模型在各类视觉内容上的表现。
ImagenWorld 的运作方式
ImagenWorld 不提供模糊的单一分数,而是采用可解释的评估方式。
每张图像均由三名标注人员依据四项可理解的评估标准进行打分:
- 指令相关性:生成结果是否符合指令要求?
- 美学质量:图像视觉是否连贯、是否具有吸引力?
- 内容连贯性:图像中的所有元素是否逻辑一致?
- 瑕疵:图像是否存在失真、故障或无法识别的文字?
除了数值分数外,标注人员还会标记出导致错误的特定物体和区域:他们会使用标记集(SoM- Set-of-Mark)分割图以及视觉 - 语言模型辅助的物体提取技术。
最终形成的数据集能让你直观看到模型的失分原因。
基准测试数据集详情
ImagenWorld 整合了六项主要任务,涵盖图像生成与编辑两大方向,能全面呈现模型在真实场景下的表现。
- TIG:文本生成图像(Text-to-Image Generation)
- SRIG/MRIG:单参考图生成 / 多参考图生成(Single and Multi-Reference Image Generation)
- TIE:文本引导图像编辑(Text-Guided Image Editing)
- SRIE/MRIE:单参考图编辑 / 多参考图编辑(Single and Multi-Reference Image Editing)
每项任务均对应六个视觉领域:艺术作品、照片级真实图像、计算机图形、截图、信息图表和文本图形。
这种组合能涵盖各种复杂程度和风格的图像。
ImagenWorld 中的每个样本均包含:
- 原始条件图像和指令
- 不同系统(包括开源和闭源)的模型生成结果
- 描述问题所在的人工标注(例如物体缺失、文字失真、颜色错误等)
- 可选的分割掩码,用于标注出错误在生成结果中的位置
凭借超过 20000 个带标注的样本,ImagenWorld 能揭示出模型行为和视觉表现的一致规律。
它不仅能帮助明确图像的外观质量,还能找出图像失败的位置和原因。
探索任务与可视化效果:https://huggingface.co/spaces/TIGER-Lab/ImagenWorld-Visualizer
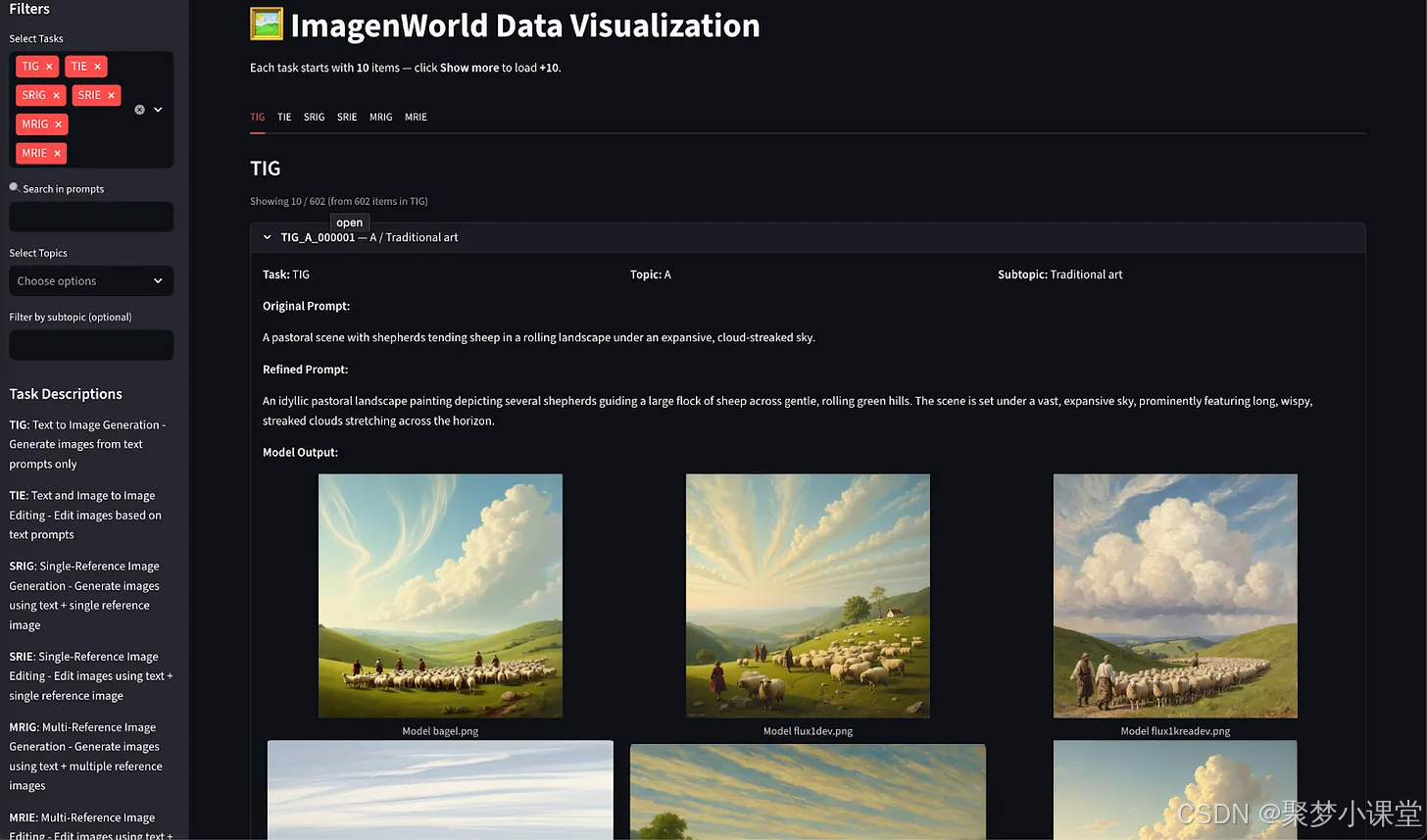
数据集地址:https://huggingface.co/datasets/TIGER-Lab/ImagenWorld
基于统一协议评估 14 个模型
我们评估了 14 个最先进的模型,涵盖扩散型、自回归型和混合架构型,包括开源和闭源系统。
为确保对比公平、可复现,所有模型均在 ImagenWorld 的六项任务中采用相同的统一流程进行测试。
| 架构类型 | 模型列表 |
|---|---|
| 扩散型 | InstructPix2Pix、SDXL、IC-Edit、Flux.1-Krea-dev、Flux.1-Kontext-dev、Qwen-Image |
| 自回归型(AR) | Infinity、BAGEL |
| 自回归 + 扩散混合型 | Janus Pro、UNO、Step1X-Edit、OmniGen2 |
| 未知类型 | GPT-Image-1、Gemini 2.0 Flash |
这些模型共同涵盖了现代生成式架构的全貌:从扩散模型到新兴的自回归 - 扩散混合模型 ------ 后者能在单一多模态框架内实现生成与编辑的一体化。
我们的发现
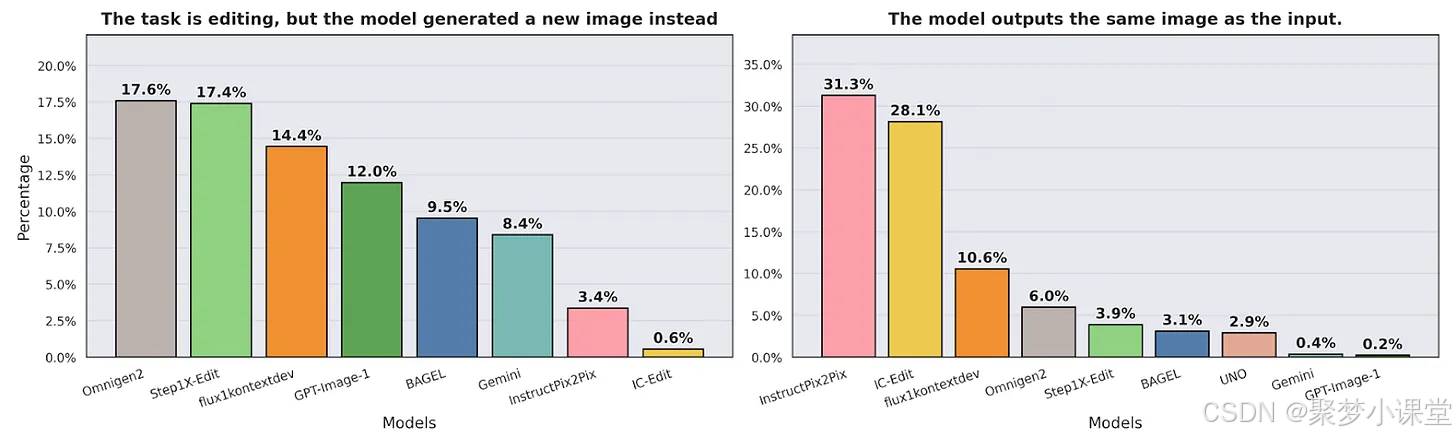
1. 编辑任务仍是最大难点
即使是顶尖模型,在接到编辑指令时,也常常会重新生成一张全新图像,或完全不修改输入图像。这表明当前模型对局部修改仍缺乏精细控制能力。
左图:让模型编辑一张图像,但是生成了一张全新(无关)图像的概率
右图:让模型编辑一张图像,但是生成的图像跟输入图像一致没做任何修改的概率
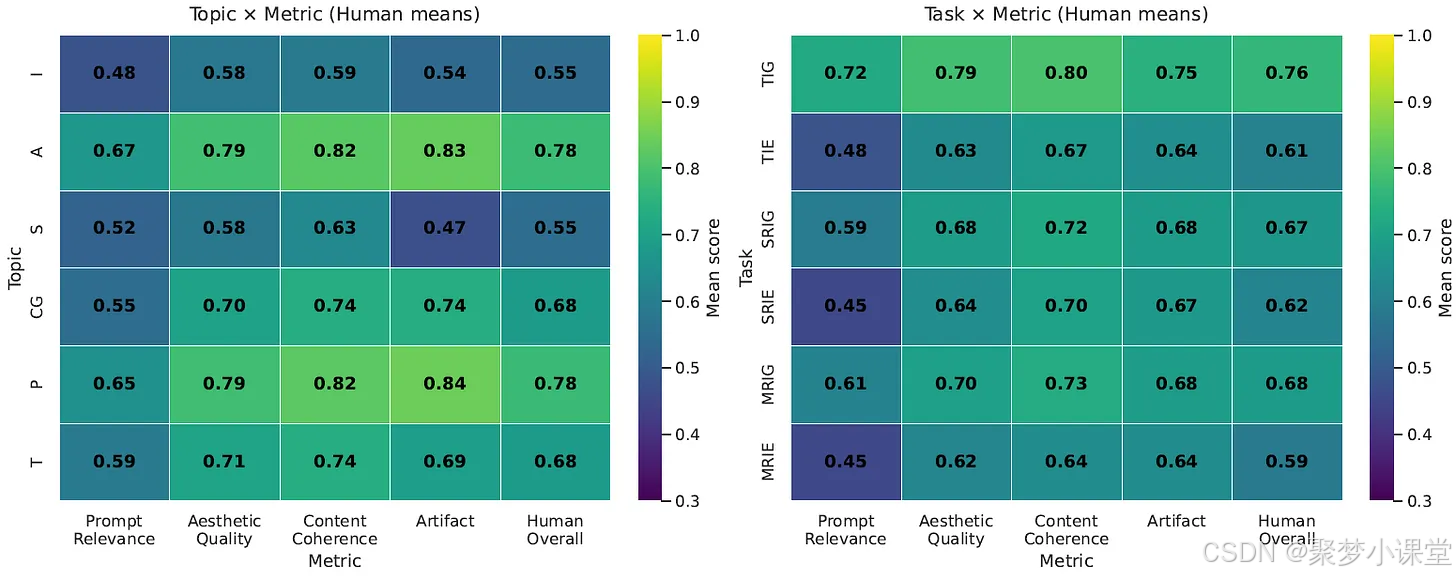
2. 文本密集领域对多数模型构成挑战
艺术作品和照片级真实场景的人工评分最高(总体评分约 0.78)。
信息图表和截图的评分最低(约 0.55),这类图像中常出现文字失真、图表错位的问题。
3. 数据筛选的重要性堪比模型规模
Qwen-Image 模型使用合成的文本密集型样本进行训练,在文本图形任务上的表现甚至优于 GPT-Image-1。
这表明精心的数据集设计,其效果可媲美甚至超越大模型规模带来的优势。
4. 自动评估技术正在追赶人工评估
基于视觉 - 语言模型(VLM)的评分器,其肯德尔相关系数 τ 约为 0.79,已接近人工对模型排序的一致性水平。
但这类评分器仍无法识别细微瑕疵,因此将人工评估与 VLM 评估相结合,仍是目前最可靠的方法。
常见失败模式
1. 无法精准遵循指令
模型常常无法精准遵循用户指令,尤其是在指令涉及多个约束条件或属性时。
指令:编辑图像 1。将左上角的箱子替换为图像 3 中的黄色警示标志。将(图像 2 中央的)粉色船员角色和(图像 2 右下角的)黄色船员角色,放置在图像 1 的中央门口并排站立。确保所有新增元素都以正确的透视、光影和比例融入图像。(Edit image 1. Replace the top-left crate with the yellow warning sign from image 3. Place the pink crewmate (from the center of image 2) and the yellow crewmate (from the bottom right of image 2) standing side-by-side on the central doorway in image 1. Ensure all new elements are integrated with correct perspective, lighting, and scale.)

模型放置的是红色和绿色船员角色,而非粉色和黄色;且黄色警示标志的位置与要求不符。
2. 数值不一致
模型无法完成基础算术或比例推理。例如百分比超过 100%、求和结果与总数不符,或内部数值存在矛盾。

3. 分割与标注问题
模型会标注错误标签、边界框位置错误,或无法将语义分割区域与目标区域对齐。
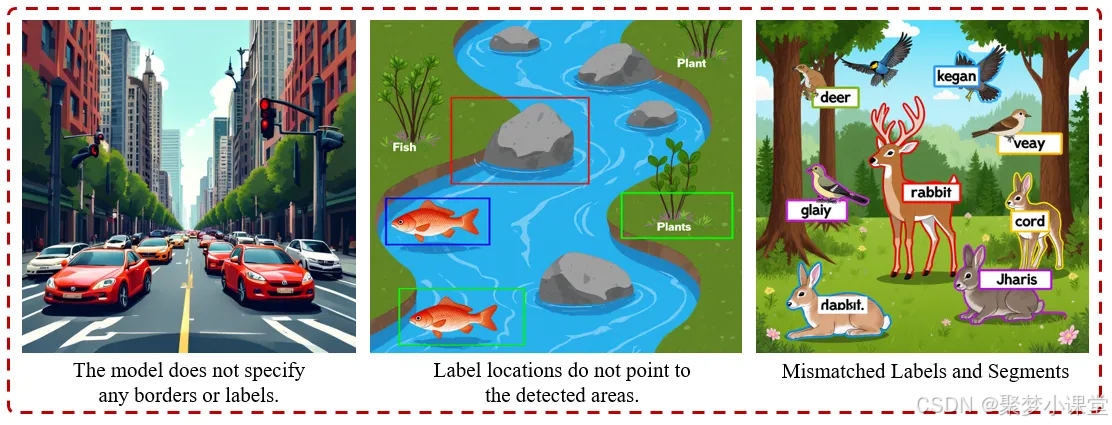
- 左图:该模型未标注任何边界或标签。(The model does not specify any borders or labels.)
- 中图:标签位置未指向检测到的区域。(Label locations do not point to the detected areas.)
- 右图:标签与分割区域不匹配(Mismatched Labels and Segments)
4. 编辑时重新生成图像
当要求模型进行小幅编辑时,模型常常会重新生成一张全新图像,或完全忽略源图像内容。

- 上图:指令:将标志中的三角形转换为有光泽的霓虹蓝色正方形,需带有反光高光和轻微斜角。(Transform the triangle in logo into a glossy neon blue square with a reflective highlight and slight bevel.)生成结果中,模型生成了一个新人物(The model generates a new person)同时,模型改变了源图像的比例(The model changes the source image ratio)
- 中图:指令:在田野右侧添加一台拖拉机。需遵循原画作的纹理风格。(Add a tractor at the right side of the field. Follow the texture of the original painting.)模型生成了一个与源图像背景相似的新背景。(The model generates a new background similar to the one in the source image.)
- 下图:指令:从这张图像中移除钉子。(remove the nail from this image)模型生成了一个颜色不同的新骨骼结构(The model generates a new bone structure with different coloring)
5. 图表错误
在图示类或分析类视觉内容中,模型难以维持图像的内部逻辑和结构。
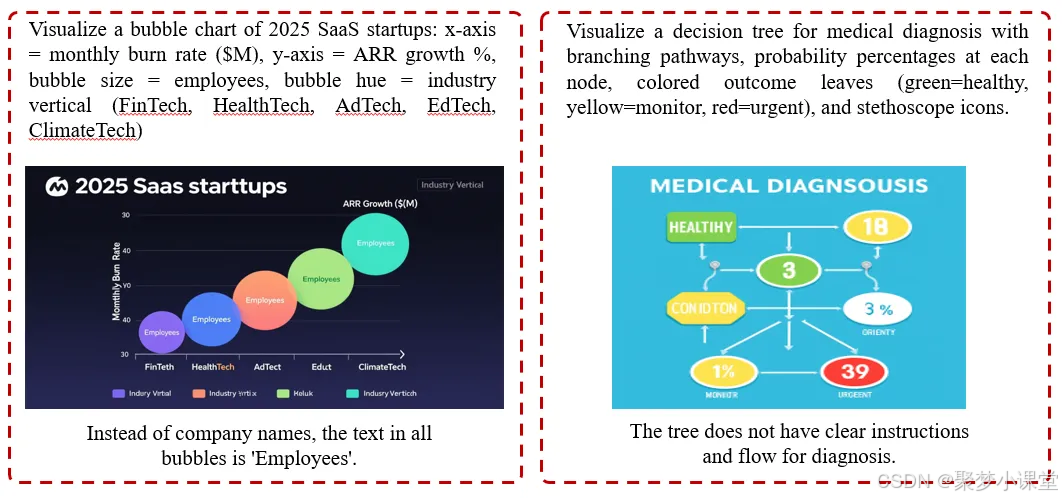
指令 1:绘制 2025 年 SaaS(软件即服务)创业公司的气泡图:X 轴 = 月烧钱率(百万美元),Y 轴 = 年度经常性收入(ARR)增长率(%),气泡大小 = 员工数量,气泡颜色 = 行业领域(金融科技、医疗科技、广告科技、教育科技、气候科技)。(Visualize a bubble chart of 2025 SaaS startups: x-axis = monthly burn rate ($M), y-axis = ARR growth %, bubble size = employees, bubble hue= industry vertical (FinTech, HealthTech, AdTech, EdTech, Climate Tech))
所有气泡中的文字本应是公司名称,而模型生成的却是 "Employees"(员工)。
指令 2:绘制医疗诊断决策树,需包含分支路径、每个节点标注概率百分比、彩色结果叶节点(绿色 = 健康、黄色 = 需监测、红色 = 紧急),并添加听诊器图标。(Visualize a decision tree for medical diagnosis with branching pathways, probability percentages at each node, colored outcome leaves (green=healthy, yellow=monitor, red=urgent), and stethoscope icons.)
该决策树没有清晰的诊断指引和流程。
6. 文字无法识别
在截图、漫画或信息图表等文本密集场景中,模型表现常常不佳。生成的文字会出现混乱不清、错位或完全无法识别的情况。

这些文字无法识别。(The text is not readable)
重要意义
现代图像模型生成的图像看似效果惊艳,但是很多时候完全偏离指令核心,。
一幅构图完美的图像,可能仍无法完成最简单的指令:"在桌子上放一个杯子"。相反,模型可能会把杯子放在桌子下,或把杯子变成花瓶。
ImagenWorld 通过可被人类理解的评估方式,摆脱了 "看起来不错" 这类主观判断,能清晰展示模型失败的原因和位置。
它的设计兼顾研究与创意探索的需求,为模型对比、极端案例排查,以及训练新系统应对真实用户关注的复杂场景,提供了平台。
规模概况
- 6 项任务(生成 + 编辑)(6 Tasks (generation + editing))
- 6 个视觉领域(艺术作品→截图)(6 Visual Domains (artwork -> screenshots))
- 3.6 万个条件集合(3.6K Condition Sets)
- 2 万条人工标注(20K Human Annotations)
- 14 个模型(含开源和闭源系统)(14 Models, including both open-source and closed-source systems)
这是一个丰富的测试平台,有助于了解模型在不同架构和领域下的表现。
迈向更可靠的图像模型
ImagenWorld 不仅是一个数据集,更是下一代模型评估的框架。
它将视觉质量、人类推理与局部错误定位相结合,为构建更稳健、更可信的生成式系统提供了必要工具。
项目主页:https://tiger-ai-lab.github.io/ImagenWorld/(Project page: https://tiger-ai-lab.github.io/ImagenWorld/)
写在最后的补充(非原文中内容)
1.ImagenWorld 由第三方机构开发,非 ComfyUI 本身
ImagenWorld 是由 TIGER-Lab(老虎人工智能实验室)研发的图像生成与编辑基准测试平台,并非 ComfyUI 开发。核心依据来自原文关键信息:
- 项目主页明确标注为 "https://tiger-ai-lab.github.io/ImagenWorld/",数据集与可视化工具均托管在 TIGER-Lab 的 Hugging Face 账号下(如 https://huggingface.co/datasets/TIGER-Lab/ImagenWorld)。
2. 评估结果采用 "人工评估为主、模型辅助" 的混合模式
ImagenWorld 的评估并非单一方式,而是结合了人工判断与模型评分,以确保准确性和效率:
- 基础评估:人工打分每张图像由 3 名专业标注人员,依据 "指令相关性、美学质量、内容连贯性、瑕疵" 四项标准逐一打分,同时标记错误物体 / 区域(如 "文字失真""颜色错误"),并通过分割图定位错误位置。
- 辅助评估:模型辅助验证引入基于视觉 - 语言模型(VLM)的自动评分器,其评分与人工评分的一致性(Kendall τ)约为 0.79,接近人类判断水平。但该模型无法识别细微瑕疵(如微小文字错位),因此最终仍以 "人工评估 + VLM 辅助" 作为可靠方案。
3. 价值和意义
ImagenWorld 并不是"几个研究员凭个人喜好跑一圈模型、出张排行榜"就完事的"一次性对比",而是一份公开发布、可被整个社区复用、迭代和训练的真实场景基准。它的价值主要体现在以下三点:
-
任务与数据"自带解释"
-
每条样本都附带 3 人独立标注的"错误标签"+ 分割掩码,直接告诉开发者"模型在哪一步、哪个物体、哪种属性"上失败。
-
研究者不用再自己猜"为什么分数低",可视化工具里点开就能看到人类写的失败原因,方便针对性改进模型或训练数据。
-
-
覆盖真实且难啃的"边缘场景"
-
六大任务里包含"多参考图融合""带文字的信息图编辑"等目前开源模型普遍做不好的场景;6 大视觉域里专门把"截图、信息图、文字图"单拎出来,正是当下商用最容易翻车的方向。
-
20 K 条人工标注样本全部开源,社区可以拿来继续训练、做 LoRA、做强化学习奖励模型,相当于白送一份高质量"错题本"。
-
-
提供可复现的"统一管线"
-
所有 14 个模型(开源+闭源)都在同一提示、同一随机种子、同一后处理流程下推理,避免"各家实验室自己跑分"时常出现的隐藏超参差异。
-
代码和评测脚本随数据集一起放出,任何人都可以在自己的模型上重跑一遍,得到可横向对比的分数,天然具备"持续集成"属性。
-
因此,ImagenWorld 的定位更接近"真实场景下的 ImageNet"------早期也有人觉得 ImageNet 只是"斯坦福自己收集的 100 万张猫狗照片",但正是这份公开、可复现、带标签的数据,催生了 AlexNet、ResNet 等后续突破。ImagenWorld 想做的是图像生成/编辑领域的同类基础设施:
-
对研究者 → 提供"错误可解释"的训练信号和评测标准;
-
对开发者 → 快速验证新模型在"商用高危场景"里到底行不行;
-
对社区 → 公开数据 + 公开评估脚本,避免再被"黑箱榜单"忽悠。
只要后续有人用它持续训练、打榜、发论文,它就会像 ImageNet 或 COCO 一样,从"第三方一次测评"变成"行业默认的硬度测试场"。
用一句大白话总结
以前各家模型"王婆卖瓜"时都拿自家题库考试,考题简单、打分宽松,真到用户手里就露馅;ImagenWorld 相当于把考题公开、监考统一、每道错题还给你写评语,让"卖家秀"和"买家秀"尽量同屏。
当然,它解决不了所有问题:
-
模型厂愿不愿意来"裸考"还是看自觉------毕竟真跑一遍可能当场翻车。
-
就算来了,也还有人偷偷在训练集里"刷题"(数据污染)。
-
真实用户提示的复杂度和长尾分布永远比任何题库更丰富。
但至少以后社区有了"同一把尺子":
-
谁不敢跑,就等于默认心虚;
-
跑了分数低,还能按维度看"到底是文字崩了,还是多物体没对齐";
-
研究者也能直接拿这些"错题"去做针对性改进,而不是盲猜。
它就是个"统一考场+错题本",能不能推广开,要看大家愿不愿意放下自家"小灶试卷",来公共考场裸考一次。