一、Docker 网络模型
Docker网络的核心是docker0网桥,当我们安装好docker之后,宿主机上会自动创建一个docker0的网桥来充当交换机的角色,所有容器连接到这个网桥上,使得容器之间的通信就像在同一个局域网中一样,docker网桥如下图;docker容器每个veth都包含两个虚拟网络接口,其中veth负责连接到dicker0网桥,而另外一个接口被配置到容器的网络栈中,命名为eth0,veth像一根虚拟的网线,连接了容器与宿主机的网络命名空间,允许容器发出的数据包直接到达宿主机的网桥,当容器1与容器2间通时,通过docker0实现容器间的通信。
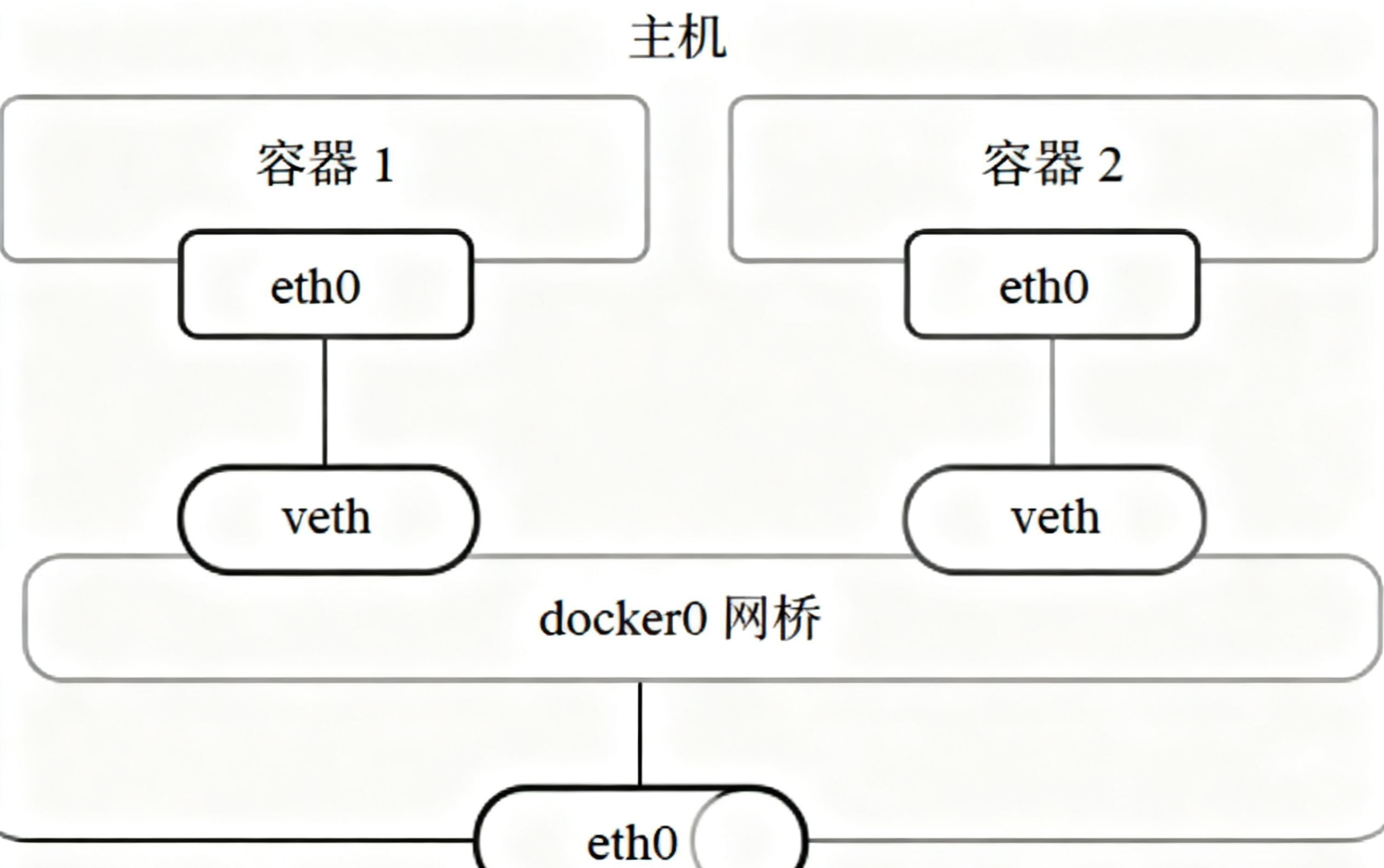
1. 核心组件与通信原理
| 组件 | 作用 |
|---|---|
| docker0 网桥 | 宿主机自动创建的虚拟网桥(类似物理交换机),所有容器默认连接至此网桥 |
| veth 设备 | 虚拟网线,成对存在:一端连 docker0 网桥,另一端作为容器内的 eth0 网卡 |
| 网络命名空间 | 隔离容器网络栈,使容器拥有独立的 IP、路由、端口等网络资源 |
容器间通信流程(同一宿主机)
- 容器1发出数据包,通过自身eth0(veth一端)传递到docker0网桥;
- docker0网桥根据目标IP(容器2的IP)转发数据包到容器2的veth端;
- 容器2通过eth0接收数据包,完成通信
2. 容器与外部网络交互
Docker依赖iptables规则实现内外网转发,核心分为两种场景:
(1)容器访问外部网络(出网)
-
核心iptables规则(POSTROUTING):
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-
规则解析:
-
-s 172.17.0.0/16:匹配来自 Docker 容器网段(默认 172.17.0.0/16)的数据包; -
! -o docker0:排除容器间通信(不通过 docker0 网桥的流量); -
MASQUERADE:动态 SNAT(源地址转换),将容器 IP 替换为宿主机 IP,实现出网。
(2)外部网络访问容器(入网)
容器 IP 仅在宿主机内可见,外网需通过 端口映射 访问,核心是 -p 参数与 iptables 转发规则:
-
启动容器时配置端口映射:
docker run -d --name web -p 8080:80 nginx
2.自动生成的 iptables 规则(以容器 IP 172.17.0.2 为例):
# 1. PREROUTING 链:将宿主机 8080 端口的流量转发到容器 IP:端口
-A PREROUTING -p tcp -m tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80
# 2. POSTROUTING 链:确保容器回包能正确返回外网
-A POSTROUTING -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j SNAT --to-source 宿主机IP二、Docker网络模式
安装Docker时会自动创建3个网络,可以使用docker network ls命令列出这些网络。
[root@docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
2379cach4e83 bridge bridge local
52e2de623b35 host host local
4651f24b3341 none null local我们在使用docker run创建容器时,可以用--net选项指定容器的网络模式,Docker有以下4种网络模式:
- Host模式,使用--net=host指定。
- Container模式,使用--net=container:NAME_or_ID指定。
- None模式,使用--net=none指定。
- Bridge模式,使用--net=bridge指定,默认设置。
1.Host 模式核心原理:完全共享宿主机网络栈
Docker 默认会为每个容器创建独立的 Network Namespace (包含独立网卡、IP、路由、iptables 规则),如PID Namespace隔离进程,Mount Namespace隔离文件系统,Network Namespace隔离网络等,但 Host 模式会「跳过」这个隔离,让容器直接使用宿主机的 Root Network Namespace,具体表现为:
- 无独立网卡 / IP :容器内没有
eth0虚拟网卡,而是直接使用宿主机的物理网卡(如ens33); - 端口直接占用 :容器启动的服务会直接使用宿主机的端口(如容器内启动 Nginx 80 端口,外部可通过「宿主机 IP:80」直接访问,无需
-p映射); - 共享网络配置:容器内的路由表、DNS 配置、iptables 规则与宿主机完全一致(修改容器内的路由会直接影响宿主机)。
1.1、Host 模式的安全风险(为什么不推荐?)
你提到的「安全风险」可细化为 3 个核心问题,这些问题在生产环境中可能导致严重故障:
1. 端口冲突风险:容器直接占用宿主机端口
- 问题:若宿主机已运行其他服务(如宿主机本身有 Nginx 占用 80 端口),Host 模式容器会启动失败(端口被占用);
- 隐患:若容器服务异常占用关键端口(如 22 SSH 端口、6443 K8s API 端口),会直接导致宿主机核心服务不可用。
2. 网络配置篡改风险:容器可修改宿主机网络
- 问题:容器内执行
ip route add/iptables -A等命令,会直接修改宿主机的路由表 /iptables 规则; - 隐患:恶意容器或误操作可能删除宿主机默认路由,导致整个宿主机断网;或添加错误 iptables 规则,阻断核心服务流量。
3. 进程身份混淆风险:容器进程与宿主机进程难区分
- 问题:宿主机
ps -ef查看进程时,容器内的 nginx 进程显示为「nginx: master process」,无法直观区分是宿主机进程还是容器进程; - 隐患:排查端口占用、进程异常时,容易误杀宿主机进程(如误将宿主机 Nginx 当作容器进程杀死)。
1.2、Host 模式的「少数合理场景」
虽然不推荐,但在以下特殊场景中,Host 模式可能是最优选择(权衡便利性与风险):
- 对网络性能要求极高的场景:如高频网络通信的服务(如分布式缓存、实时数据传输),Host 模式跳过虚拟网络转发(veth、bridge),减少网络延迟(性能比 Bridge 模式高 10%-20%)。
- 需要访问宿主机网络栈的工具类容器:如网络监控容器(需抓取宿主机所有网卡流量)、DNS 服务容器(需修改宿主机 DNS 配置),Host 模式可直接获取宿主机网络数据。
2.Container 模式核心原理:共享指定容器的网络栈
Container 模式的核心是「新容器不创建独立 Network Namespace,而是 "寄生" 到已存在的目标容器的 Network Namespace 中」,具体特性如下:
- 网络资源完全共享 :新容器与目标容器共享 IP、端口、网卡、路由表、DNS 配置(两者在网络层面完全 "融为一体",外部看是同一个 IP);
- 其他资源完全隔离:文件系统、进程列表、PID Namespace、Mount Namespace 等仍与目标容器隔离(比如新容器里看不到目标容器的进程);
- 通信极高效 :两个容器可通过 lo 回环网卡 直接通信(如
ping 127.0.0.1或访问localhost:端口),无需经过网桥转发,延迟极低。
2.1、Container 模式的适用场景
这种模式不常用,但在以下特定场景中能解决关键问题:
-
"工具容器" 辅助主容器 :主容器(如 Nginx/Java 服务)未安装调试工具(如
curl/ping/tcpdump),可启动一个工具容器共享其网络,直接调试主容器的服务(无需进入主容器或暴露额外端口); -
多服务共享端口(特殊需求):某些老旧服务依赖固定端口(如必须用 80 端口),但又不能部署在同一个容器中(需隔离文件系统 / 进程),可通过 Container 模式让多服务共享同一个 IP 和端口(需确保服务监听不同路径,如 Nginx 代理不同 URI 到不同容器)。
-
降低网络延迟:对通信延迟敏感的场景(如主容器是数据库,新容器是缓存服务),通过 lo 网卡直接通信,延迟比跨容器网桥转发低 1-2 个数量级。
2.2、注意事项与风险
- 端口冲突风险:新容器与目标容器不能监听同一个端口(如目标容器已用 80 端口,新容器再启动 80 端口服务会失败);
- 目标容器依赖:若目标容器停止或删除,新容器会失去网络栈(无法联网,需重新启动并指定新的目标容器);
- 安全隔离弱化:新容器与目标容器共享网络,若新容器被入侵,攻击者可通过网络直接访问目标容器的服务(需确保新容器的安全性)。
3.None 模式核心原理:仅保留网络隔离,无任何默认配置
Docker 对 None 模式的处理逻辑非常简单:
- 创建独立 Network Namespace:容器拥有专属的网络隔离环境(与宿主机、其他容器的网络完全隔开);
- 不做任何网络配置 :容器内只有
lo回环网卡(用于容器内进程间通信),没有物理 / 虚拟网卡(如eth0),无 IP、无路由、无 DNS 配置; - 需手动配置网络 :若要让容器联网,必须通过
ip/route等命令手动添加网卡、分配 IP、配置路由(相当于 "从零搭建网络")。
3.1、None 模式的典型使用场景
None 模式因 "完全手动配置" 的特性,仅适用于对网络有 高度定制化需求 的场景,常见场景包括:
-
安全隔离场景:需严格限制容器网络(如仅允许容器内进程通信,不允许联网),例如运行敏感数据处理的容器(无需对外通信,减少攻击面);
- 例:容器内仅运行一个计算脚本,无需联网,用 None 模式可避免网络层面的安全风险。
-
自定义网络协议 / 拓扑:需搭建特殊网络环境(如自定义路由、使用非 TCP/IP 协议、配置 VLAN 等),例如测试网络设备驱动、验证自定义路由算法;
- 例:为容器配置 SR-IOV 直通网卡(绕过操作系统网络栈,直接使用物理网卡),需先通过 None 模式清空默认配置,再手动绑定硬件网卡。
-
网络调试 / 学习场景:用于学习 Linux 网络原理(如手动配置 veth、网桥、路由),None 模式提供了 "干净的网络画布",无默认配置干扰;
- 例:新手学习
ip命令、Network Namespace 隔离原理时,用 None 模式容器实操更易理解。
- 例:新手学习
4、Bridge 模式核心技术细节
Bridge 模式的本质是通过 虚拟网桥(docker0)+ 虚拟网卡对(veth pair)+ iptables 规则 构建的 NAT 网络,各组件协作如下:
| 组件 | 作用 |
|---|---|
| docker0 网桥 | 宿主机启动 Docker 时自动创建的虚拟二层交换机(默认 IP:172.17.0.1/16),所有 Bridge 模式容器都连接至此 |
| veth pair(虚拟网卡对) | 成对存在的虚拟网络接口,形似 "网线":一端(vethxxx)连 docker0 网桥,另一端(eth0)在容器内作为网卡 |
| 容器 Network Namespace | 容器独立的网络空间,包含 eth0 网卡(veth 一端)、IP(从 docker0 网段分配,如 172.17.0.2)、路由表 |
| iptables 规则 | 控制容器与外网、容器间的通信(如 SNAT/DNAT 转发、端口映射、网络隔离),主要作用于 nat 表和 filter 表 |
4.1、Bridge 模式通信全流程解析
1. 容器与容器通信(同一宿主机)
以容器 A(172.17.0.2)访问容器 B(172.17.0.3)为例:
- 容器 A 内进程发送数据包,目标 IP 为 172.17.0.3,通过自身 eth0 网卡(veth 一端)传出;
- 数据包经 veth 对传输到 docker0 网桥(veth 另一端连接网桥);
- docker0 网桥作为二层交换机,根据目标 MAC 地址(通过 ARP 协议获取)直接转发数据包到容器 B 的 veth 端;
- 容器 B 通过 eth0 网卡接收数据包,完成通信。
- 关键:无需经过宿主机物理网卡,直接通过 docker0 网桥转发,效率较高。
2. 容器访问外部网络(出网流程)
以容器 A(172.17.0.2)访问百度(220.181.38.148)为例:
-
容器 A 数据包目标 IP 为 220.181.38.148,经 eth0 → veth 传到 docker0 网桥;
-
docker0 网桥发现目标 IP 不在自身网段(172.17.0.0/16),根据容器内默认路由(网关指向 172.17.0.1,即 docker0 IP),将数据包转发到宿主机物理网卡;
-
宿主机 iptables 的
POSTROUTING链触发 SNAT 规则(MASQUERADE):bash
# 查看规则:将容器网段的数据包源 IP 替换为宿主机物理网卡 IP iptables -t nat -vnL POSTROUTING | grep 'MASQUERADE' -
数据包以宿主机 IP 作为源地址发送到外网,外网响应包回到宿主机后,反向通过 iptables 规则转发到容器 A。
3. 外部网络访问容器(入网流程,端口映射)
以外部主机访问宿主机 8080 端口(映射到容器 A 的 80 端口)为例:
-
外部主机发送数据包到宿主机 IP:8080,宿主机物理网卡接收;
-
宿主机 iptables 的
PREROUTING链触发 DNAT 规则(端口映射):bash
# 查看规则:将宿主机 8080 端口流量转发到容器 A 的 172.17.0.2:80 iptables -t nat -vnL PREROUTING | grep '8080' -
数据包经 docker0 网桥转发到容器 A 的 veth 端,容器 A 通过 eth0 接收并处理;
-
容器 A 的响应包经原路径返回,iptables 自动替换源地址为宿主机 IP,确保外部主机能识别响应。
4.2、Bridge 模式的 iptables 规则详解
Docker 会自动在宿主机的 nat 表和 filter 表中创建规则,控制 Bridge 模式的网络流量,核心规则如下:
| 表(Table) | 链(Chain) | 典型规则示例 | 作用 |
|---|---|---|---|
| nat | PREROUTING | -A PREROUTING -p tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80 |
外部访问宿主机端口 → 转发到容器端口 |
| nat | POSTROUTING | -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE |
容器出网流量 → 替换源 IP 为宿主机 IP |
| nat | DOCKER | -A DOCKER ! -i docker0 -p tcp --dport 8080 -j DNAT --to-destination 172.17.0.2:80 |
关联 PREROUTING 链,细化端口映射规则 |
| filter | DOCKER-USER | (默认空,用户可自定义) | 优先控制所有 Docker 流量(如黑名单) |
| filter | DOCKER | -A DOCKER -d 172.17.0.2/32 ! -i docker0 -o docker0 -p tcp --dport 80 -j ACCEPT |
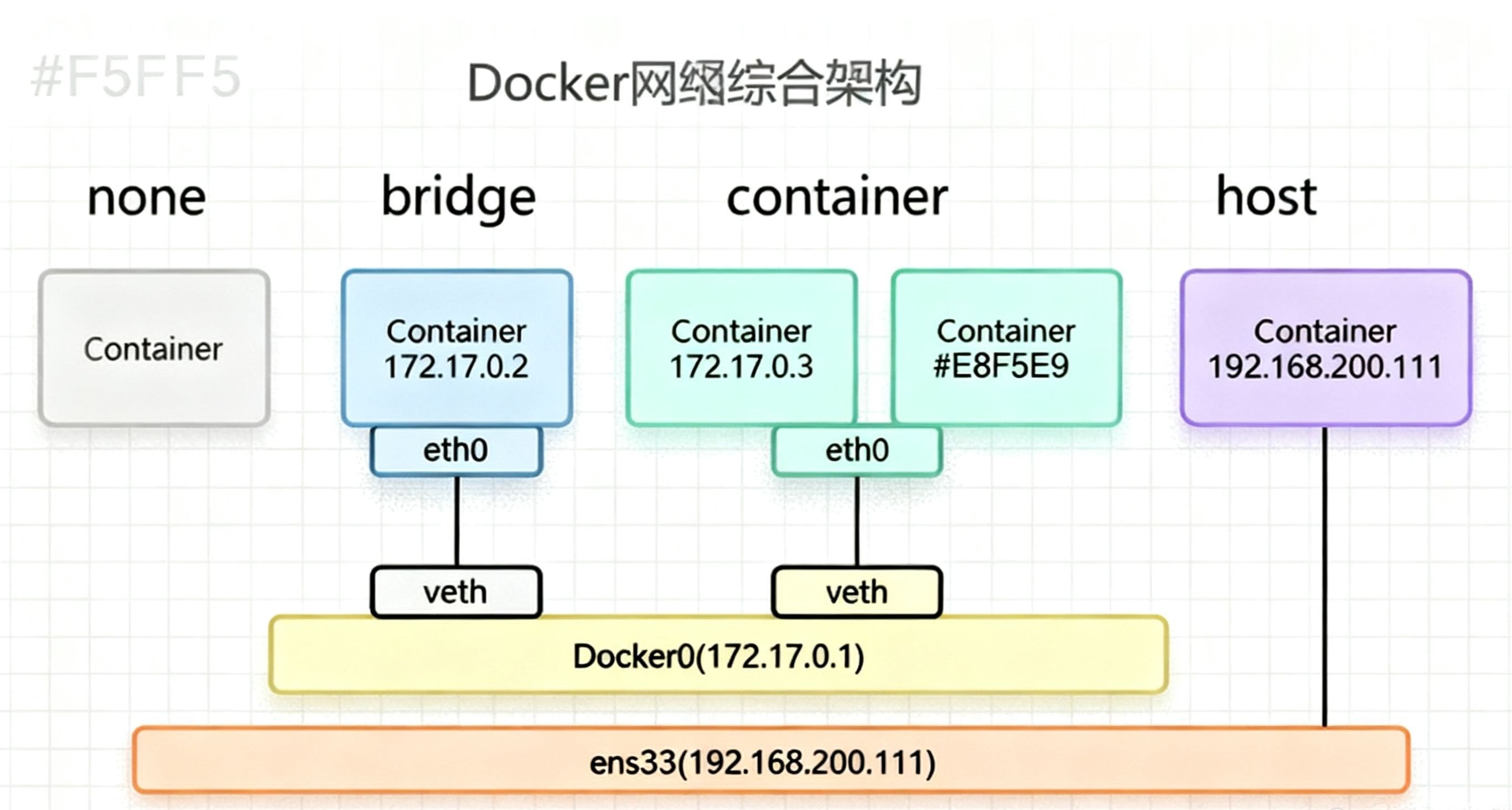
Docker网络综合图形
五、k8s网络模型
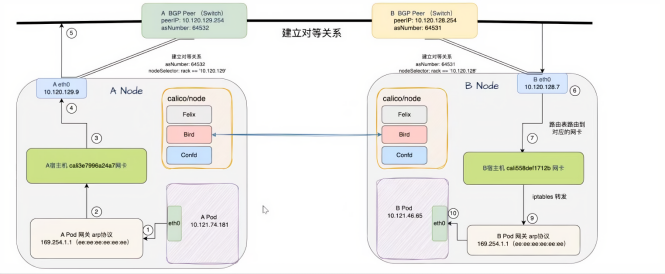
5.1、BGP Pod通信过程
5.1.2、在 Calico 网络流量传输流程里,calico/node 中的三个组件各自承担关键作用:
Felix:作为 Calico 的核心代理,负责在宿主机上配置网络接口(如创建 cali 开头的虚拟网卡)、管理路由规则(确保 Pod 流量能正确转发到目标节点或 Pod),还会维护网络策略(控制 Pod 间的访问权限),是实现网络连通和安全策略的基础执行者。
Bird:作为 BGP(边界网关协议)客户端,负责与其他节点的 Bird 组件或外部 BGP 设备建立对等连接,交换路由信息,让集群中各节点能知晓不同 Pod 网段对应的目标节点,从而为跨节点的 Pod 流量提供准确的路由指引,保障数据包能跨节点传递。
Confd:主要负责监听 Calico 资源的配置变化(比如 IP 池、网络策略等配置的更新),并将这些配置转化为 Felix 和 Bird 可识别的格式,确保两者能基于最新配置工作,维持网络配置的一致性与动态更新能力。
正是这三个组件协同工作,才使得 Calico 能实现高效、灵活且可控的容器网络通信。
5.1.3、跨节点通讯过程:
宿主机calico网卡与Pod的是成对的网卡(veth网卡);在网卡上使用proxy arp协议
calico会开启响应,A Pod将数据包交给calico网卡。
A Pod 的 eth0(IP 为 10.121.74.181)先通过 ARP 找到网关,接着经 A 宿主机的 cali3e7996a24a7 网卡,依据路由表确定 B Pod 所在网段,然后从 A 节点的 eth0发送出去;数据包到达 B Node 的 eth0(IP 为 10.120.128.7)后,通过路由表找到目标 IP(10.121.46.65)对应的 B 宿主机 cali558def1712b 网卡,交给calico网卡后自然的到 B Pod 的 eth0(IP 为 10.121.46.65)。
5.2、IPIP Pod通信流程
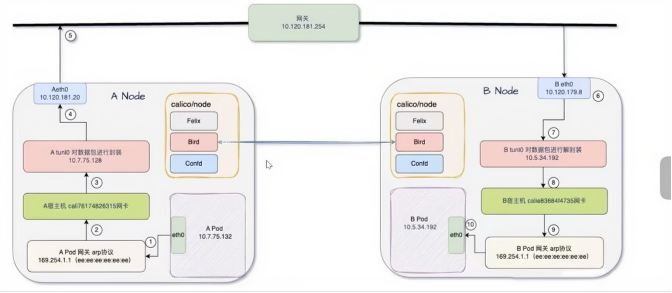
5.2.1、跨节点通讯过程:
前面这个是一样的A Pod 的 eth0(IP 为 10.7.75.132)先将流量发往自身网关,随后流量经 A 宿主机的 cali76174826315 网卡;进入 A 宿主机的 tunl0(IP 为 10.7.75.128)进行 IP-in-IP 封装;(新增的封装报文(外层报文)的目标 IP 确实是 B Node 的地址)封装后的数据包从 A 节点的 eth0(IP 为 10.120.181.20)发出,通过网关 10.120.181.254(路由器;如果是交换机,那就不加IP头了用标准BGP协议来通信) 转发到下一跳 B Node 的 eth0(IP 为 10.120.179.8);在 B Node 上对数据包进行解封装,之后经 B 宿主机的 tunl0(IP 为 10.5.34.192),再通过 B 宿主机的 calie83684f4735 网卡,最终将流量转发到 B Pod 的 eth0(IP 为 10.5.34.192)。
5.3、VXLAN Pod通信流程
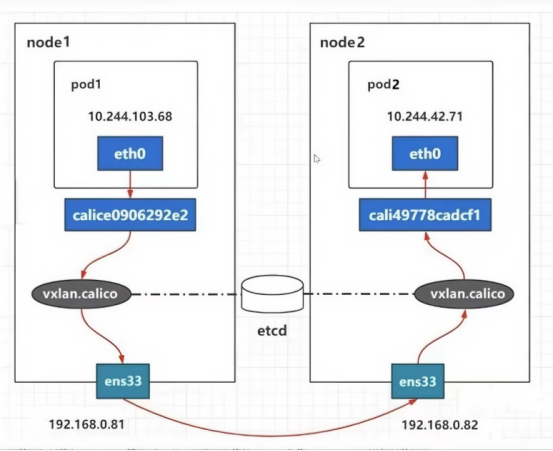
5.3.1、跨节点通讯过程:
Pod1(IP:10.244.103.68)的流量先经自身 eth0 网卡,传递到 Node1 上的 calice0906292e2 虚拟网卡;随后进入 Node1 的 vxlan.calico 设备,在此处,原始数据包被封装到 UDP(端口 4789)报文里,外层头部的源 IP/MAC 设为 Node1 物理网卡 ens33 的 IP(192.168.0.81)与 MAC;封装后的报文通过物理网络传输至 Node2 的 ens33 网卡(IP:192.168.0.82),接着进入 Node2 的 vxlan.calico 设备进行解封装,取出原始数据包;最后,数据包经 Node2 上的 cali49778cadcf1 虚拟网卡,转发到 Pod2 的 eth0 网卡(IP:10.244.42.71),完成通信。
Calico的VXLAN模式不需要BGP生成路由表,而使用VXLAN隧道自身来维护的路由表实现
5.3.2、VXLAN with BGP 模式下,当网络设备为交换机时,通信过程可这样解析:
假设 Node1 和 Node2 处于同一物理子网(如都在 192.168.1.0/24),Pod1(IP:10.244.1.10,在 Node1)要访问 Pod2(IP:10.244.1.20,在 Node2),中间设备是交换机:
Pod1 发送数据包,经自身 eth0 → Node1 上的 cali 虚拟网卡 → Node1 的路由表(由 BGP 同步而来,记录 "10.244.1.20/32 对应 Node2 的物理 IP 192.168.1.2")。
Node1 将数据包通过 ** 物理网卡(如 ens33)** 发往交换机;交换机基于 "目的 IP(Node2 物理 IP 192.168.1.2)" 和 MAC 表,转发到 Node2。
Node2 接收数据包后,经自身路由表(BGP 同步),将数据包转发到 Pod2 的 cali 虚拟网卡 → Pod2 的 eth0,完成通信。
(此过程无 VXLAN 封装,依赖 BGP 传递 "Pod IP → 节点物理 IP" 的路由规则,交换机仅做二层转发。)
如果同一网段,就使用BGP
如果不同网段,就用VXLAN机制
6、Calico 路由反射器(Route Reflector)
6.1、路由反射器的核心作用:解决全互联模式的痛点
Calico 默认的 Node-to-Node Mesh(节点全互联) 模式,虽能实现路由信息同步,但存在明显局限性:
- 连接数爆炸 :若集群有
N个节点,每个节点需与其他N-1个节点建立 BGP 连接,总连接数为N×(N-1)/2(如 100 个节点需 4950 个连接); - 资源开销大:大量 BGP 连接会占用节点 CPU、内存及网络带宽,且路由同步效率随节点数增加而下降。
路由反射器(RR)的核心是 "集中转发路由信息":
- 选择少数节点作为 RR,其他节点(客户端节点)仅与 RR 建立 BGP 连接;
- 路由同步流程简化为 "客户端→RR→其他客户端",总连接数降至
N(仅客户端到 RR 的连接),彻底解决连接数爆炸问题,适用于 100 节点以上的大规模集群。
点赞+关注+收藏,下期再见。博主忙着学习shell脚本,更新有点慢,有兴趣可以一起交流shell脚本的。