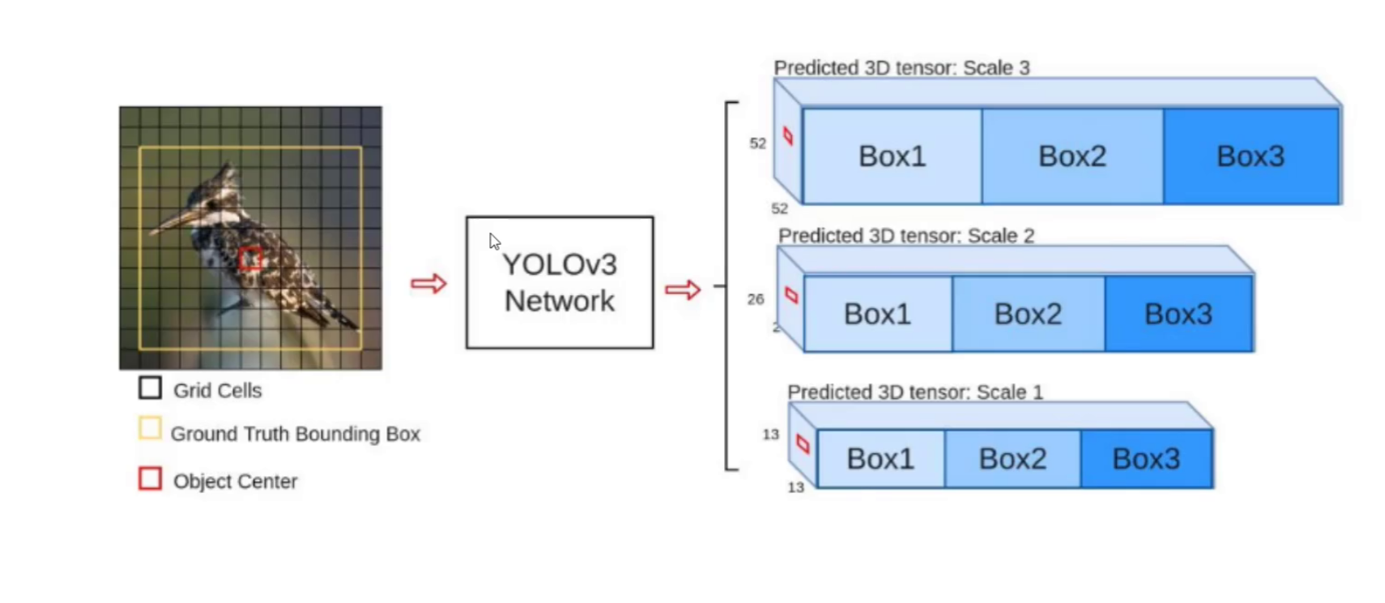
一、先验框改进:更丰富候选框,助力小目标检测
在目标检测中,先验框的设计对检测效果至关重要。YOLOv3 相比 YOLOv2 有了显著提升,采用 K-means 聚类得到 9 种尺度的先验框,在 COCO 数据集上,这 9 个先验框尺寸分别为 (10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116×90)、(156×198)、(373×326)。这些先验框具有一定通用性,能更好适配不同大小物体。
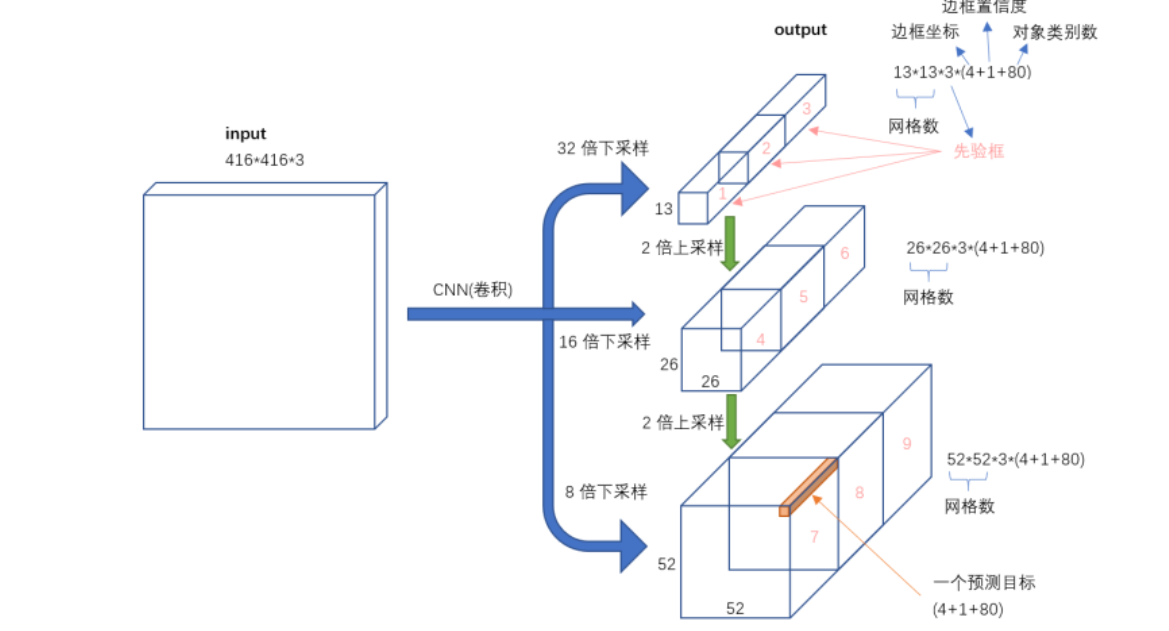
分配上,最小的 13×13 特征图(最大感受野)应用较大的先验框,适合检测大对象;中等的 26×26 特征图(中等感受野)应用中等先验框,检测中等大小对象;较大的 52×52 特征图(较小感受野)应用较小先验框,检测小对象。丰富且适配的先验框,让 YOLOv3 在检测不同大小物体时,有了更贴合的候选框,尤其提升了小目标检测的准确性。
二、网络结构优化:残差连接与全卷积设计,提升特征提取效率
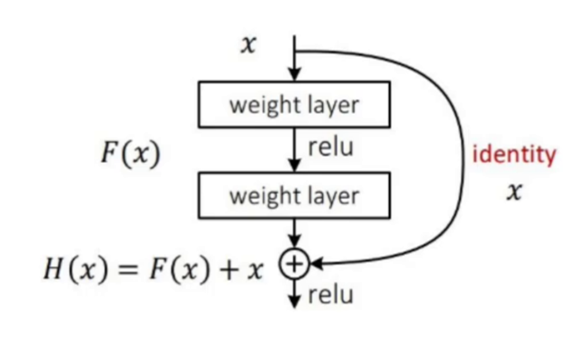
YOLOv3 的网络结构进行了精心设计。它采用类似 ResNet 的残差连接思想,通过堆叠更多层来提取特征,残差连接有效缓解深层网络训练时的梯度消失问题,让网络能更好学习图像特征。
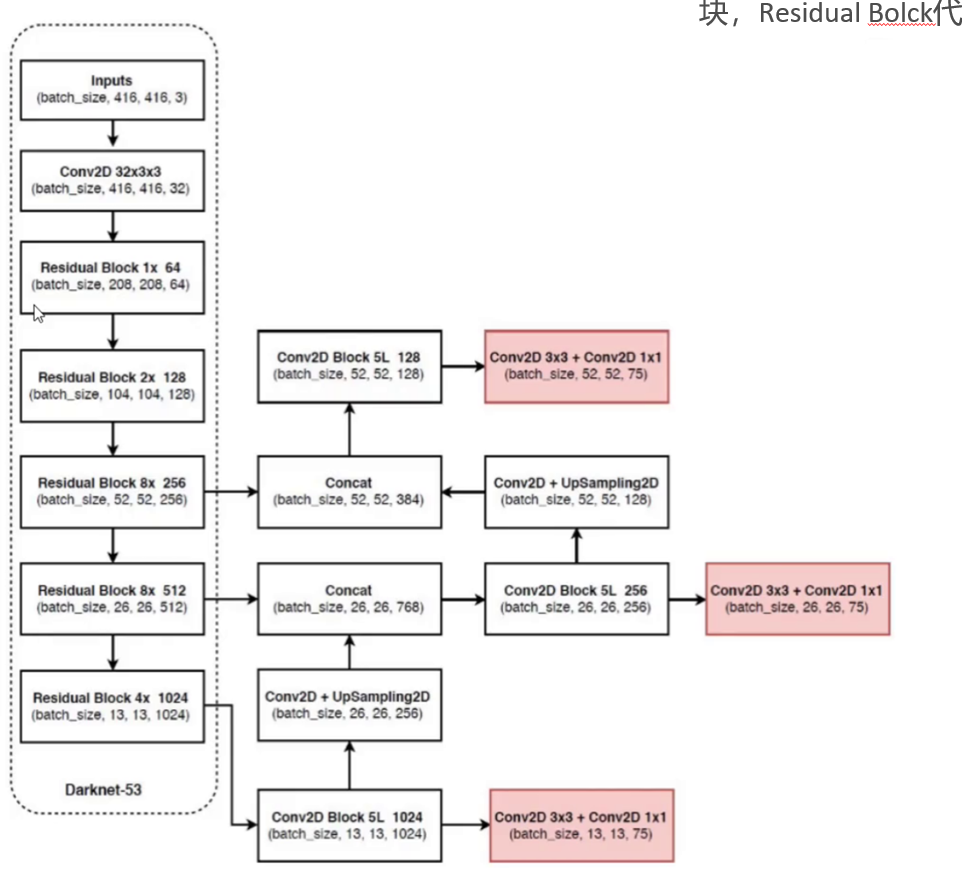
同时,YOLOv3 摒弃池化和全连接层,全部采用卷积层,下采样通过设置 stride 为 2 来实现。这种全卷积的设计,使网络在提取特征时更加灵活高效,能更好地保留图像的空间信息,为后续的目标检测提供更优质的特征支持。
三、分类器革新:从 Softmax 到 Logistic,适配多标签场景
传统目标检测模型常用 Softmax 分类层,Softmax 函数会将神经网络输出转换为概率分布,且所有类别概率之和为 1,强制每个样本只属一个类别。但在复杂场景中,一个物体可能同时属于多个类别,比如一个人可能同时是 "人" 和 "行人",此时 Softmax 不再适用。
YOLOv3 用多个独立的 Logistic 分类器替代 Softmax 分类层。Logistic 分类器中,每个类别预测独立进行,会为每个类别计算概率值表示样本属于该类别的可能性,通常用 Sigmoid 函数作为激活函数,将输出映射到 (0, 1) 区间。
比如识别 "猫""狗""鸟" 的任务,图像 A 中猫概率 0.8、狗 0.3、鸟 0.1,阈值 0.5 时仅标记为猫;图像 B 中狗 0.7、鸟 0.6,会同时标记为狗和鸟。这种改进让 YOLOv3 能处理多标签目标检测任务,在复杂场景表现更灵活准确。
四、总结
YOLOv3 通过先验框、网络结构、分类器的多维度改进,在目标检测的速度和精度上都有出色表现,成为经典算法,为后续 YOLO 系列及其他目标检测算法发展提供了重要参考思路。