一、stack和queue的认识和使用
1、sstl中tack和queue的不同
前面我们在学习初阶数据结构的时候,我们已经对这两个数据结构有了很深刻的认识了。
栈的话,其是一种先进后出的结构,其有一个栈底和栈顶,那么其可以是数组的结构来实现的,也可以是链表的结构来实现的。
queue的话其是先进先出的数据结构,其有个队尾和队头,其也可以是数组或者链表的结构来实现。
下面我们看看在库中是如何实现的:


可以看到库中的实现和我们在初阶数据结构的时候的实现是不一样的,其使用的是容器适配器,我们库中的stack和queue就有点像中间商这样,使用别的容器的功能来实现自己的功能。前面学习的vector和list其都是自己去实现和管理自己的数据,而现在的stack和queue都是借用别的容器的功能。
2、容器适配器
这个是一个新的概念,适配器其实是一种容器的设计方式,这个方式就是有一套基础的容器,在对这个容器进行封装设计,然后实现出一个新的容器。
就比如说我们家里使用的插座,其固定的电压是220v的,但是我们每个电器要使用到的电压其实是不一样的,那么我们就会使用一个电源适配器,将当前的电压转换到我们当前需要的电压。
就如我们上面说到的,我们可以按照自己的需求去设计我们的stack和queue。
比如我们现在去实现一个stack,那么我们要是希望其物理结构是连续的,那么我们可以使用vector来适配:
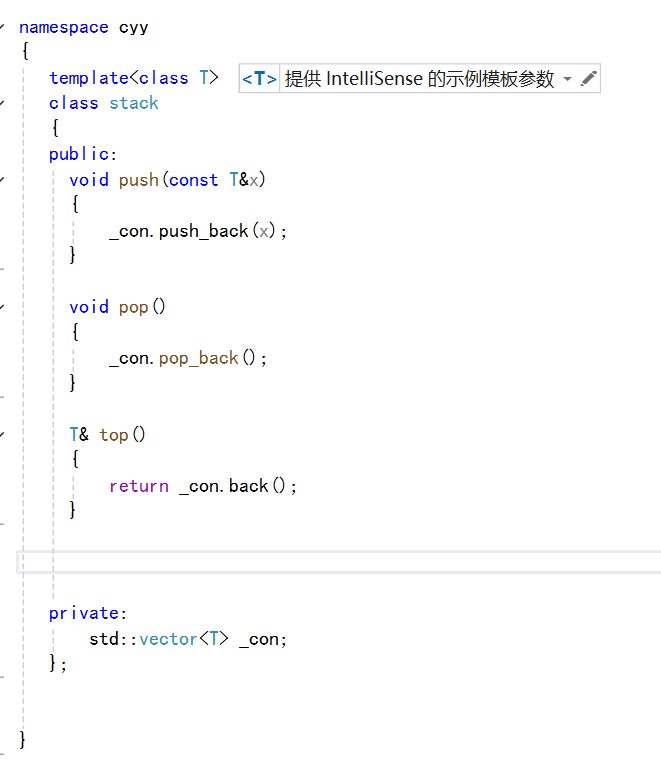
上面这个stack就是我们通过vector的适配实现的stack。
所以和C++和C语言的不同就是,我们很多数据结构和其成员变量之间是解耦的,就是我们更多的是通过几个通用的容器,然后根据实际的需求来设计。
我们前面在学习初阶数据结构的时候,我们会发现我们的数据结构我们要从一个螺丝一个螺丝这样开始,到了C++中,我们就只需要从组装开始即可。
所以我们上面的代码可以增加一个容器模板参数,然后根据需求选择即可:
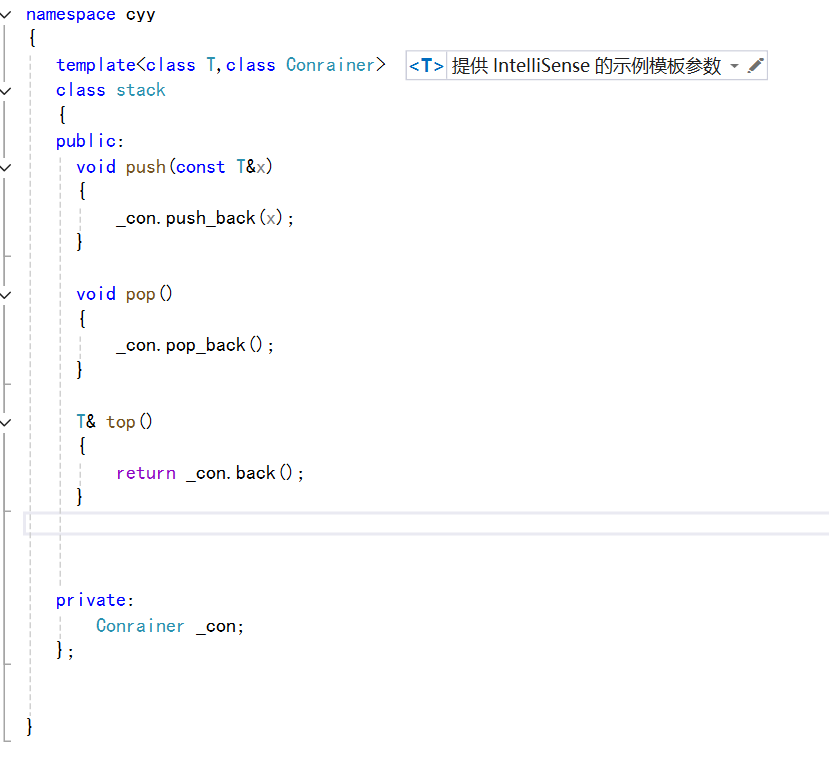
下面是我们实际使用上的写法:

那么同理我们的queue也可以通过容器适配器进行实现:
就是对于queue这个容器,其是先进先出,那么其主要的两个功能就是尾插和头删。但是vector其并没有提供头删的接口,虽然我们可以使用erase来指定位置删除,但是我们进行删除的话,那么就要将后面的数据挪动,其时间复杂度为O(n),效率就不是很高,相反我们的list的话其是一个一个结点的,我们头删只需要删除第一个结点即可,时间复杂度为O(1)。
还有就是我们发现我们的库中的话是默认使用的一个deque的东西,这个接口对数据结构熟悉的就知道,这个是一个双端队列。那么当我们定义一个queue和stack的时候,那么我们可以指定容器的时候,就会使用这个容器来实现。
后续我们会对这个双端队列进行一个详细的讲解的,下面我们通过几个题目来看看stack和queue在我们算法题的应用。
3、stack和queue的相关练习
(1)栈的弹出、压入序列
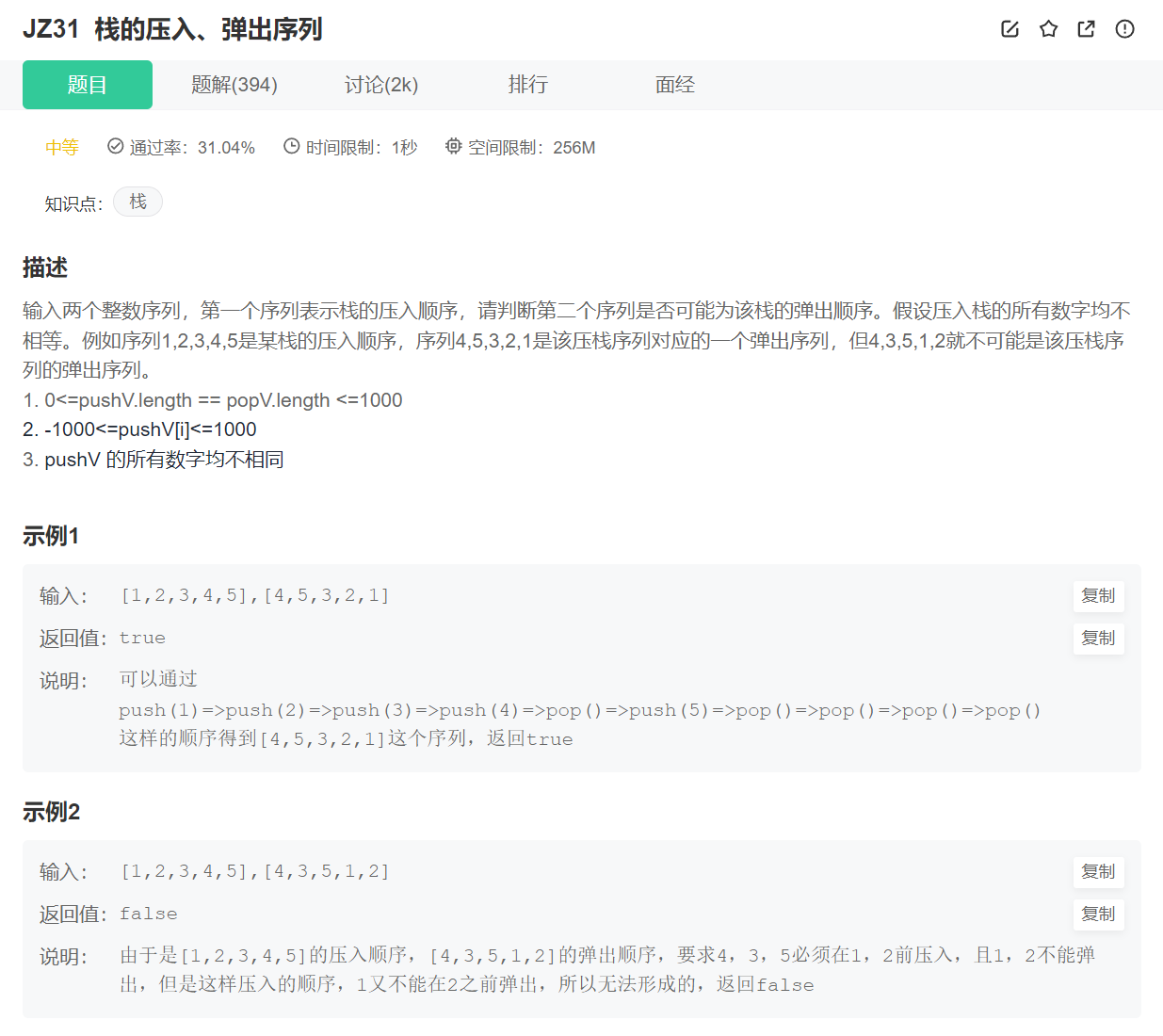
我们首先读题目,知道这是栈的入栈和出栈的相关问题,那么我们首先要知道的是栈的入栈和出栈的规则,先进后出。
这道题,我们的思路可以这样,创建一个栈push_stack。然后我们先让pushV数组的数据入push_queue的数据入栈,入了一个后,将栈顶的元素和popV的数据进行对比,要是一样那么就直接出栈,然后继续比较popV的下一个数据,要是不一样那么就继续将pushV的数据入栈,直到pushV的遍历完整,或者此时的栈已经为空。
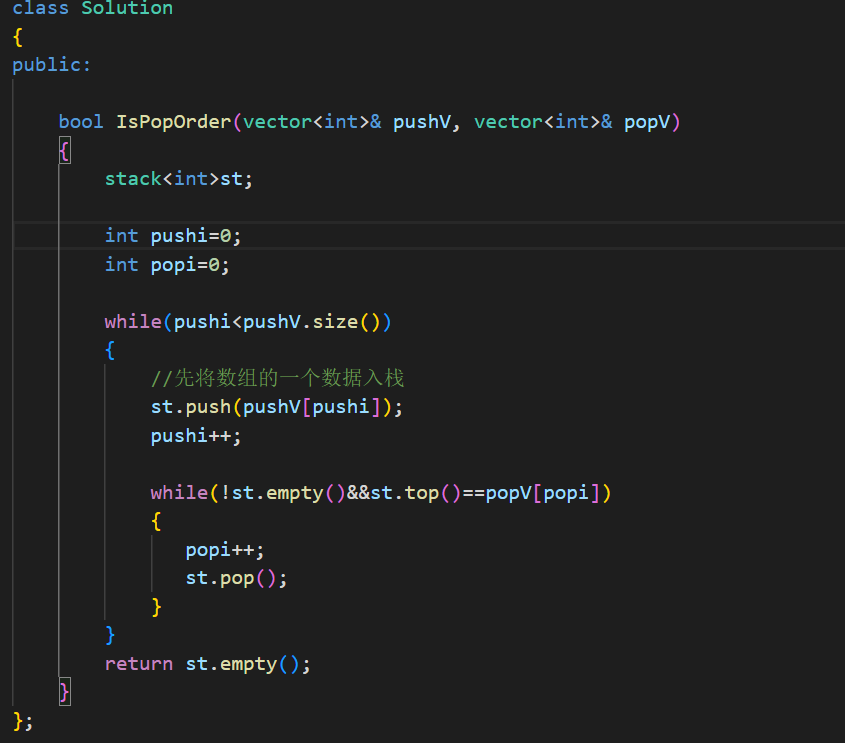
上面就是我们解题的全部代码了,要注意的是我们对于popV数组的往后遍历是在其栈顶元素一样的时候才会继续往后。
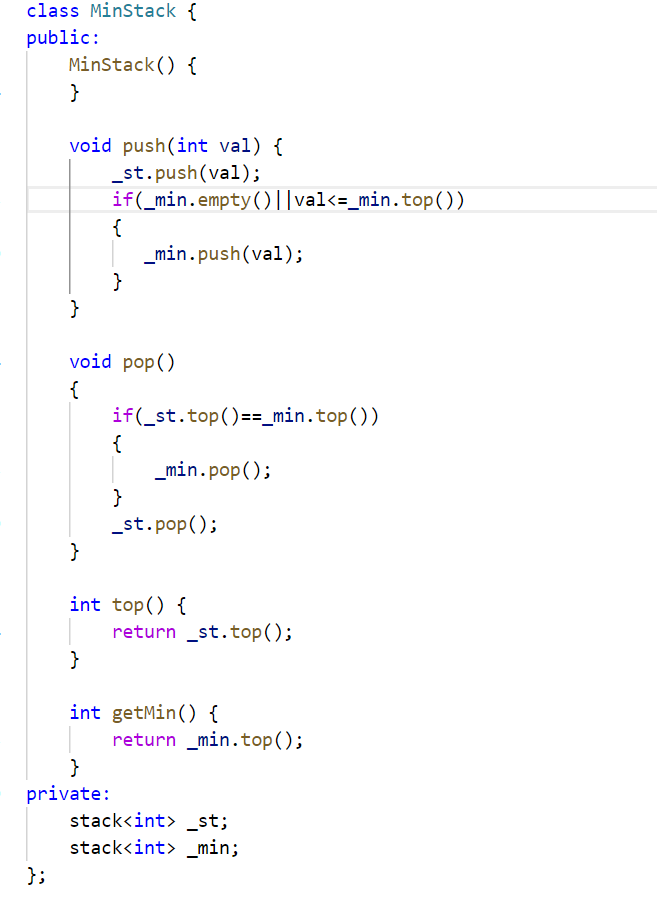
(2)最小栈

我们看题目描述,前几个接口是很容易实现的,就是最后一个,获取栈中的最小元素,我们很快可以想到的是,我们使用一个数组记录入栈的数据,然后对其进行升序的排序,那么一直取的就是最小的元素了,但是有个问题就是,当数据多起来之后,我们进行数据的删除的时候,我们对应的这个数组的元素也要进行删除吧,那么我们就又需要寻找这个数组中这个数据的位置,效率就非常的低了。所以我们可以想想其它的方式。
我们可以创建两个栈,一个栈就用来实现简单的那些接口,然后另外一个栈就专门用来服务我们的取最小栈元素的功能。
我们一开始入栈的时候,就将存储最小元素的栈的栈顶和入栈的元素进行比较,要是比这个栈的栈顶元素还小,那么在存储最小元素的这个栈也入一个。
然后就是对于相等的情况,这个情况我们的数据也要入栈,这是因为其删除的话,栈中的最小元素还是这个。
通过这两道题的练习,我们应该可以感受到,在C++中容器的便利,要是我们使用C语言的方式进行解题,那么我们还要先自己实现一个stack,然后才可以开始解题。
二、stack和queue的模拟实现
上面我们已经了解了库中的stack和queue是如何实现的,那么我们下面来模拟实现一下。
1、deque
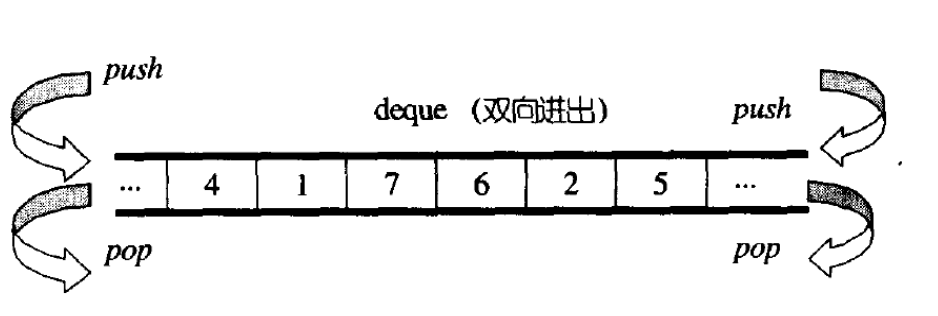
我们看库其默认是使用了这个容器,这个容器其叫做双端队列,其虽然叫队列,但是其并不是队列,因为其支持下标的随机访问,还有头插尾插,头删尾删的功能,其可以说是结合了list和vector的功能,然后对list和vector的一些缺点进行了优化。
下面我们先来看看list和vector的优缺点:
vector:
优点:
1、支持下标随机访问,尾插尾删效率高
2、cpu高速缓存命中率高
缺点:
1、头插和中间位置插入数据的效率低
2、插入数据空间不够要扩容,扩容会消耗一定的性能,然后还会存在扩容太大浪费空间的问题。
list:
优点:
1、任意位置插入元素的时间复杂度为O(1)
2、按需申请空间,不会浪费空间
缺点:
1、不支持下标的随机访问
2、cpu高速缓存低,还存在缓存污染
那么有没有可以兼顾vector和list的优点的容器呢?
所以我们的库中有这个deque,这个就是将二者取中间来实现的。
那么deque其实际上是咋样的一个容器呢?
其有点类似与我们的二维数组这样,但是其又不是完全连续的空间,然后也不是和;list一样的一个一个结点组成的。其是 由一个一个数组组成的,然后其还有一个中控数组来对这些存储数据的数组进行管理。中控数组中存储的是一个一个的指针,其本质上是指针数组。其存储的是每一个存储数据的数据的地址。
其大致样子如下:
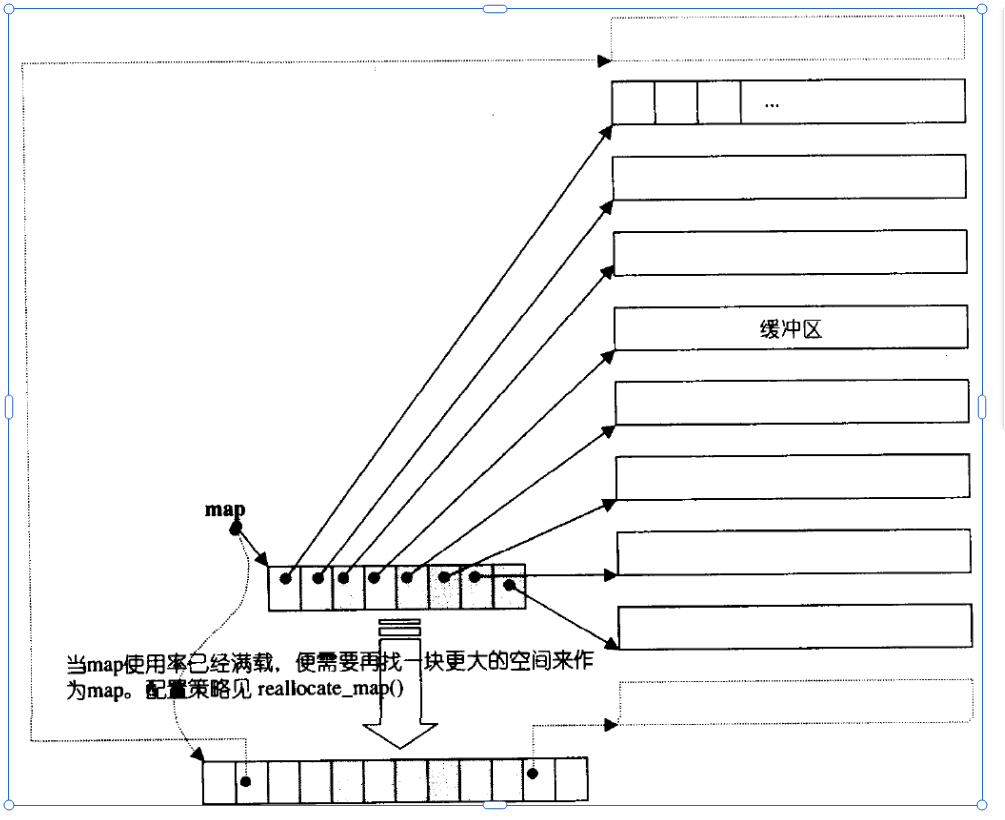
所以我们总的扩容的话,我们就只需要对这个中控数组增加一个数组的指针即可。
2、deque的迭代器
deque是支持迭代器的,但是其空间又不是连续的,那么其是咋样设计迭代器的呢?
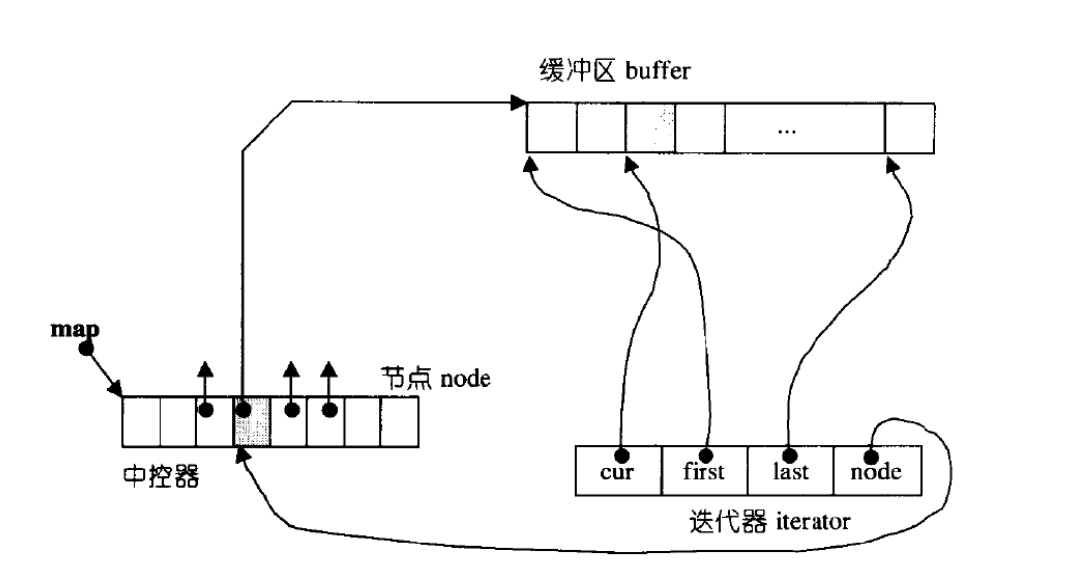
可以看到其迭代器中有四个指针:cur、first、last、node。
下面是这四个指针的用处:
cur就表示当前访问的位置。
first表示现在访问的数组的初始位置。
last指向当前数组的结束位置。
node的话,其是一个二级指针,其指向的是中控数组中的元素,所以其是二级指针。
下面是deque的一个完整示意图:
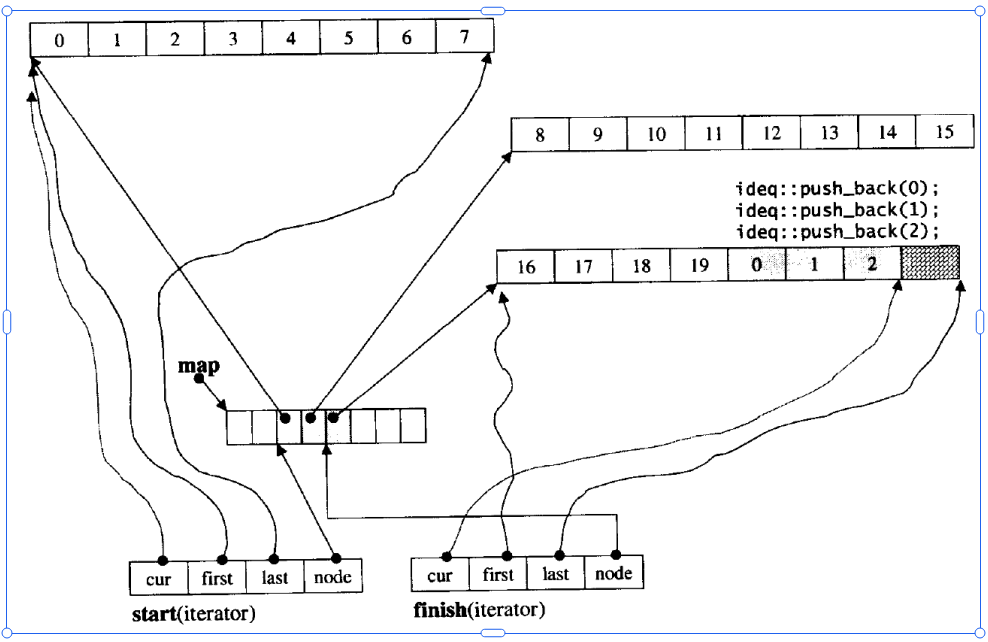
可以看到两个迭代器,其实start就指向的开始的位置,然后finish指向的是末尾的位置。
然后我们看到当前我们第一个数组是满的状态,要是我们此时进行头插,其不是先将数组的元素往后挪动,而是在中控数组中加一个数组的地址,我们看到我们中控数组是从中间位置使用的,这也是其设计的巧妙之处。
3、deque分析
优点:
1、头尾插入和删除的效率高
2、支持下标随机访问数据 ,虽然效率没有vector这么高
3、底层数组是连续的空间,cpu的缓存命中率较list高
缺点:
1、任意位置的插入效率不如list
2、然后其没有vector和list这种特别突出的方面,就中规中矩
3、遍历效率低。
我们的deque是支持下标随机位置访问的,但是为啥其遍历效率不高呢?
这是因为我们是一个一个数组组成的,那么我们遍历的时候要判断当前数组是否已经遍历到尾部,然后遍历到尾部后,就要换下一个数组,然后才能继续进行遍历了。所以对于一些要经常遍历数据的就不太合适了。
我们在平常的使用中,更多的是使用vector和list,deque是比较少用的吗,我们学习其是因为库中其默认是使用deque来实现stack和queue的,所以其更多的用法是作为stack和queue的底层数据结构。
那么为啥我们库中的stack和queue使用deque来作为底层的默认容器呢?
这是因为我们使用stack和queue是不需要遍历的,主要是先进先出和先进后出这两个逻辑。
然后deque不需要经常扩容,然后其扩容在数据少的时候和vector浪费的空间差不多,扩容多了,vector浪费多的空间的概率要比deque的概率大。内存的使用效率高。
三、stack和queue的模拟实现
其完整代码如下:
stack.h:
#pragma once
#include<queue>
namespace cyy
{
template<class T, class Conrainer = std::deque<T>>
class stack
{
public:
stack()
{
}
void push(const T& val)
{
_con.push_back(val);
}
void pop()
{
_con.pop_back();
}
T& top()
{
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Conrainer _con;
};
}queue.h:
#include<queue>
namespace cyy
{
template<class T, class Conrainer = std::deque<T>>
class queue
{
public:
queue()
{
}
void push(const T&val)
{
_con.push_back(val);
}
void pop()
{
_con.pop_front();
}
T& back() {
_con.back();
}
T& front() {
return _con.front();
}
size_t size() {
return _con.size();
}
bool emtpy() {
return _con.emtpy();
}
private:
Conrainer _con;
};
}四、优先级队列
这个听名字,我们会以为其和我们的队列一样是那种先进先出的数据结构,其实是实际上来说的话是一个容器适配器,其有点类似我们学习二叉树的时候的堆结构,其第一个元素是所有的元素中的最大值或者最小值。
下面是其库中的原型:

可以看到其底层还是复用的vector容器,然后其还有一个模板参数,其是一个仿函数。
然后其默认传入的那个函数是less,其原型如下:

可以看到其实际上是一个比大小的函数,那么我们的优先级队列中,其默认是优先大的,那么为啥,传小于的函数,就是取的大值,所以取小的就是传入大于号的函数了。
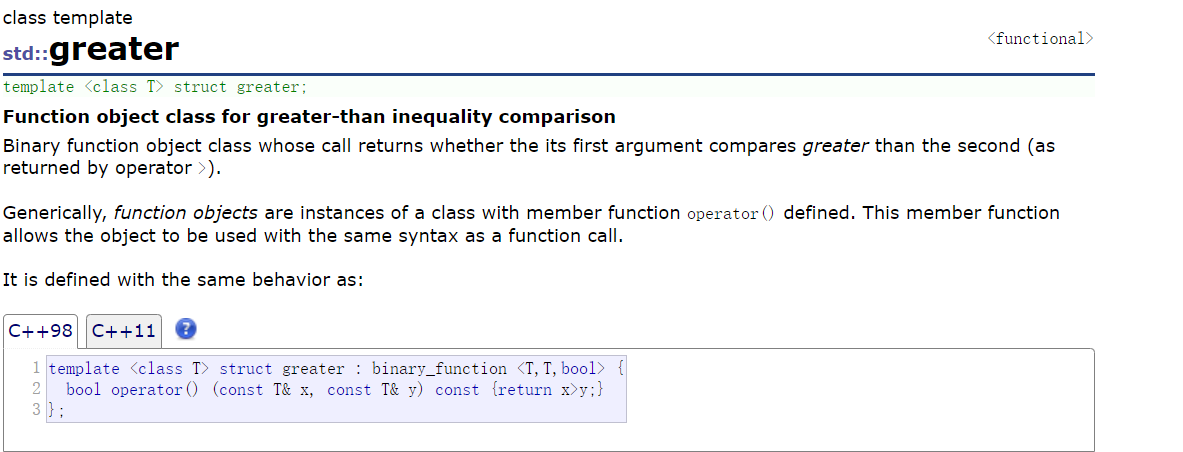
所以对于优先级队列的使用要注意了。传小于号就是大堆排序,传入大于号就是小堆排序。
下面我们来模拟实现一下优先级队列。
五、优先级队列的模拟实现
整体思路:
首先我们是使用的vector容器手适配器,这是因为优先级队列其底层来说是一个堆,然后堆的话其是使用的完全二叉树的结构,那么其是使用的数组来实现的,然后因为我们要始终保持其堆结构成立,那么就经常要进行数据的访问,那么vector的下标随机访问就体现其好处了。
所以我们整体的框架如下:
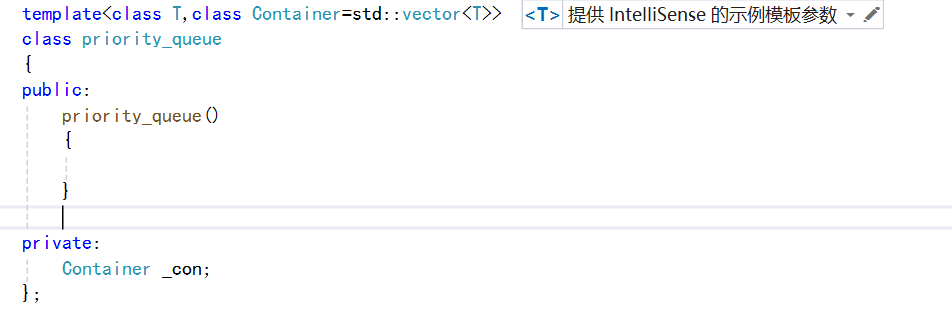
我们在实现堆排序的时候,使用的是向上调整法和向下调整法,然后向上调整法是在我们插入数据的时候使用的。
向上调整法:
我们插入数据的时候,其会破坏我们原来的堆结构,那么我们就需要将这个插入的数据挪动到合适的位置,那么我们该如何进行挪动呢?
我们前面学习堆的时候,我们是先将其进行尾插,然后将其和它的父结点进行比较,然后如果是大堆,那么要是插入的数据大于当前子树的父结点,那么其就交换,然后继续让其和上一级的父结点进行比较,直到走到第一个子树。
然后就是我们直到我们父结点找其左右子结点的算法是:
假设我们当前结点在数组中的下标是n。
左孩子结点下标:2n+1。
右孩子结点下标:2n+2。
然后其父结点为:(n-1)/2。
然后当我们不需要交换的时候,那么插入的数据合适的位置就找到了,那么就直接break即可。
代码如下:

push:
上面我们将向上调整法的写完,就可以实现我们的数据插入了:
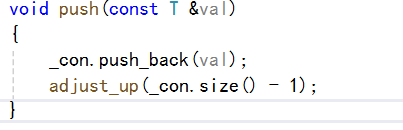
向下调整法:
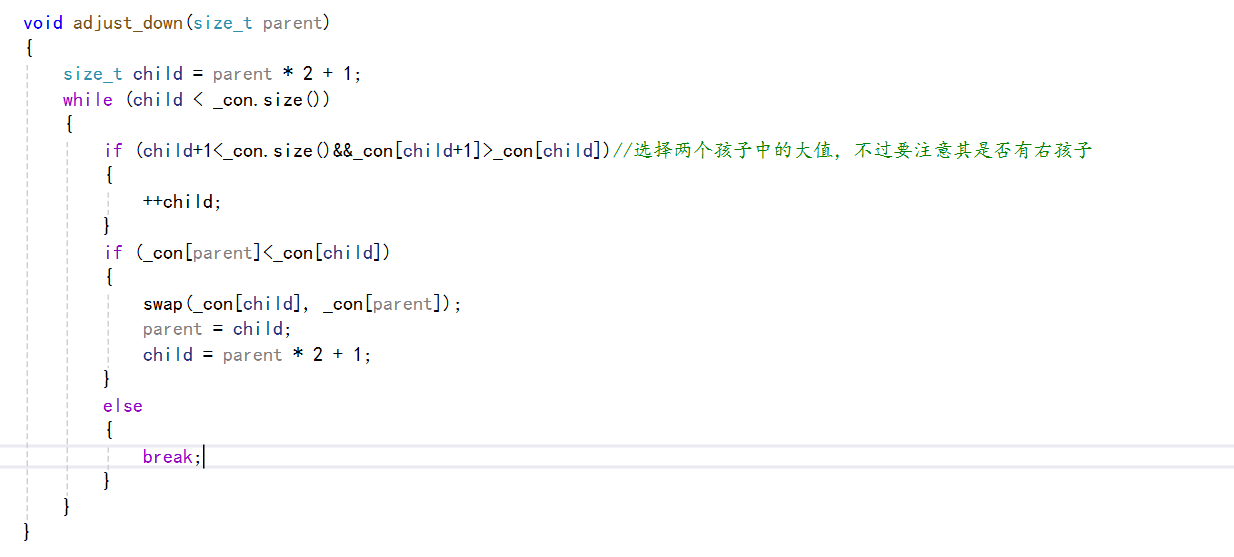
向下调整法是服务于我们的删除操作的,那么我们数据的删除要如何删呢?
我们要是直接删除头结点,那么我们的整个树的结构就乱了,所以我们删除数据的操作是,先将头结点和尾部结点是数据进行交换,然后进行尾删,这是因为我们的vector的尾删的效率高,然后头删的话效率低要挪动数据。
然后我们删除尾部数据后,那么我们当前的堆结构就不成立了,就是当前的头结点的数据不符合,那么我们将其和其左右孩子进行比较,那么我们可以先将左右孩子进行比较取出孩子中大的那个,将其和这个孩子进行比较,要是孩子大的话,那么孩子和其就交换,反之就结束循环,最坏的情况就是走到最底的一层。
pop:
上面我们完成了删除操作的前体,向下调整法。
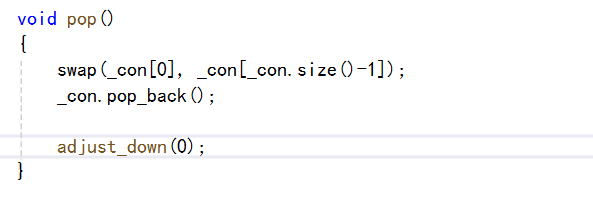
那么我们就可以实现删除的操作了。
代码如下:
top:
这个接口是取堆顶元素的,那么我们直接返回_con的首元素即可:

size:
这个接口我们直接复用vector容器中的size()即可:

empty:
这个接口是用来判断我们当前队列是否为空的,这个我们也可以直接调用_con中的即可:
我们会发现我们优先级队列的功能都实现完了,但是还是没见到模板中的第三个参数,这个是一个仿函数,下面我们对其展开讲解。
六、仿函数
仿函数实际上是一个函数对象,更本质的说,其就是一个类,这个类可以让我们和函数一样去调用。
下面我们看看在优先级队列中仿函数是咋样的:
我们的优先级队列中,其默认是大堆,这是受到其第三个模板参数的影响的。
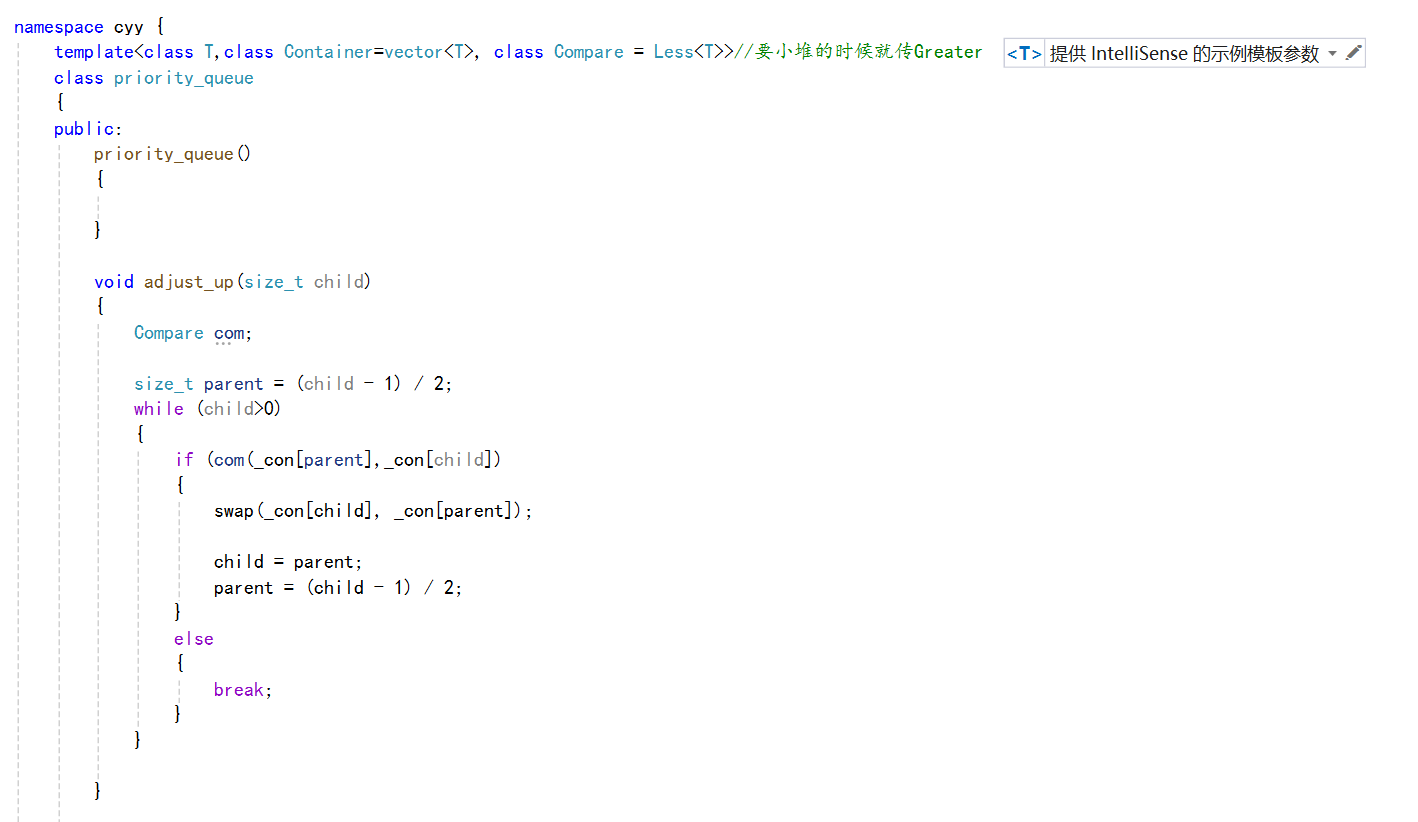
可以看到这样我们就可以使用一个类来实现大堆和小堆的优先级队列了。
七、完整代码
#pragma once
#include<vector>
using namespace std;
// 仿函数/函数对象
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
namespace cyy {
template<class T,class Container=vector<T>, class Compare = Less<T>>//要小堆的时候就传Greater
class priority_queue
{
public:
priority_queue()
{
}
void adjust_up(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child>0)
{
if (com(_con[parent],_con[child])
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T &val)
{
_con.push_back(val);
adjust_up(_con.size() - 1);
}
void adjust_down(size_t parent)
{
Compare com;
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child+1<_con.size()&&_con[child+1]>_con[child])//选择两个孩子中的大值,不过要注意其是否有右孩子
{
++child;
}
if (com(_con[child],_con[parent])
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size()-1]);
_con.pop_back();
adjust_down(0);
}
const T& top() const
{
return _con[0];
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}