大家好,我是苏三,又跟大家见面了。
前言
最近有球友问了我一个问题:SpringBoot项目到底该用Mybatis还是Spring Data JPA?
这个问题,我几乎在每个项目启动时都会被团队问到。
有些小伙伴在工作中,一看到数据库操作就头疼,选框架时犹豫不决,生怕选错了影响项目后期维护。
其实,这俩框架各有千秋,关键看你的项目需求和团队习惯。
今天这篇文章就跟大家一起聊聊,希望对你会有所帮助。
最近准备面试的小伙伴,可以看一下这个宝藏网站(Java突击队):www.susan.net.cn,里面:面试八股文、场景设计题、面试真题、7个项目实战、工作内推什么都有。
一、Mybatis和Spring Data JPA
在深入比较之前,我们先简单了解一下这两个框架。
Mybatis是一个半自动的ORM(对象关系映射)框架,它需要你手动编写SQL语句,但提供了灵活的映射机制,让你能把数据库结果集直接映射到Java对象上。
Spring Data JPA则是基于JPA(Java Persistence API)规范的实现,通常使用Hibernate作为底层,它是一个全自动的ORM框架,让你用面向对象的方式操作数据库,几乎不用写SQL。
简单说,Mybatis更像一个"SQL映射工具",而JPA更像一个"对象数据库"。
举个例子,如果你习惯直接控制SQL,Mybatis可能更适合;如果你喜欢用Java对象来操作数据,JPA会更顺手。
为了让大家更直观地理解,我画了一个简单的对比图:
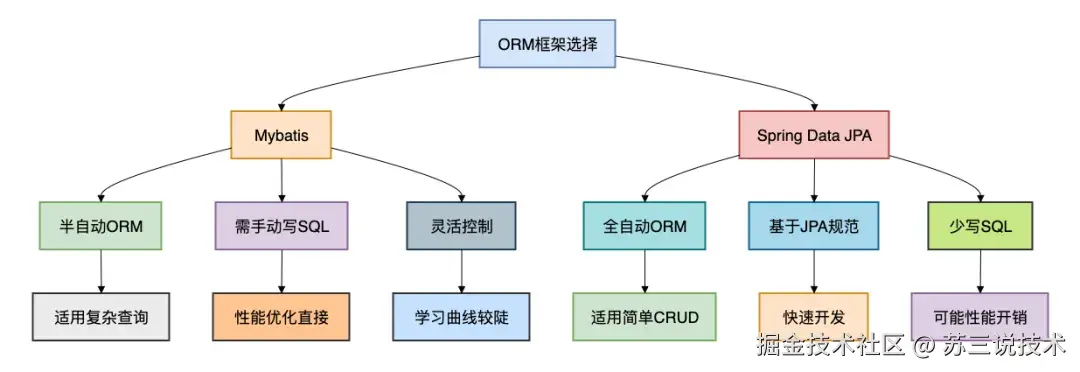
这张图概括了它们的基本特点。
接下来,我们一步步深入。
二、为什么会有这个选择?
有些小伙伴在工作中,一上来就问:"哪个框架更好?"
其实,没有绝对的好与坏,只有合不合适。
我们通常会从项目规模、团队技能、性能要求和长期维护等方面来评估。
- 项目规模:小项目或快速原型,JPA的自动化能节省大量时间;大项目或复杂业务逻辑,Mybatis的灵活性可能更关键。
- 团队技能:如果团队SQL能力强,Mybatis上手快;如果团队更熟悉面向对象编程,JPA更容易接受。
- 性能要求:高并发或复杂查询场景,Mybatis的SQL优化更直接;普通业务,JPA的缓存和延迟加载可能足够。
- 长期维护:Mybatis的SQL在XML中,容易追踪;JPA的代码更简洁,但调试可能复杂些。
下面,我用示例代码来演示两者的基本用法,让你感受一下区别。
三、Mybatis vs. Spring Data JPA
假设我们有一个简单的用户表user,字段包括id、name和email。
我们要实现一个查询:根据用户ID获取用户信息。
Mybatis 示例
首先,在SpringBoot项目中集成Mybatis。你需要添加依赖(这里以Maven为例):
xml
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>然后,定义一个User实体类:
arduino
public class User {
private Long id;
private String name;
private String email;
// 省略getter和setter
}接下来,编写Mybatis的Mapper接口。这个接口定义了数据库操作,但SQL写在XML文件中。
kotlin
@Mapper
public interface UserMapper {
User findById(Long id);
}在src/main/resources/mapper/UserMapper.xml中写SQL:
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper">
<select id="findById" parameterType="Long" resultType="com.example.entity.User">
SELECT * FROM user WHERE id = #{id}
</select>
</mapper>最后,在Service层调用:
kotlin
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public User getUserById(Long id) {
return userMapper.findById(id);
}
}代码逻辑解释 :这里,Mybatis通过XML文件将SQL语句映射到Java方法。#{id}是参数占位符,Mybatis会自动处理参数注入和结果映射。
优点是SQL可见,易于优化;缺点是多了XML配置,如果项目大,XML文件可能变得臃肿。
Spring Data JPA 示例
同样,先添加JPA依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>定义User实体类,但这次用JPA注解映射数据库表:
less
@Entity
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// 省略getter和setter
}然后,创建Repository接口,继承JpaRepository,这样就不用写实现类了:
csharp
public interface UserRepository extends JpaRepository<User, Long> {
// 无需写方法,JPA提供了基本CRUD
// 如果需要自定义查询,可以这样写:
User findByName(String name); // 根据方法名自动生成SQL
}在Service层使用:
kotlin
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User getUserById(Long id) {
return userRepository.findById(id).orElse(null);
}
}代码逻辑解释 :JPA通过注解(如@Entity)定义实体和表的映射,Repository接口自动生成SQL。findById方法是JPA内置的,你不需要写任何SQL。
优点是代码简洁,开发快;缺点是SQL不可见,复杂查询可能生成低效SQL。
从示例可以看出,Mybatis需要手动写SQL,而JPA几乎不用。
但这只是表面,接下来我们深度剖析性能、灵活性和适用场景。
最近为了帮助大家找工作,专门建了一些工作内推群,各大城市都有,欢迎各位HR和找工作的小伙伴进群交流,群里目前已经收集了不少的工作内推岗位。加苏三的微信:li_su223,备注:掘金+所在城市,即可进群。
四、性能、灵活性和适用场景
1. 性能比较:谁更快?
有些小伙伴在工作中,总觉得写SQL的Mybatis性能更好,因为能直接优化。
事实真的如此吗?
-
Mybatis :由于SQL手动编写,你可以针对数据库特性优化,比如添加索引提示或使用特定函数。在高并发场景下,直接控制SQL可以减少不必要的开销。例如,如果你需要分页查询,Mybatis可以写高效的
LIMIT语句,而JPA可能生成更复杂的SQL。但Mybatis的缺点是,如果SQL写得不好,可能导致性能问题,比如N+1查询问题(一个查询触发多个子查询)。你需要自己在XML中管理关联查询。
-
Spring Data JPA:它使用Hibernate作为默认实现,有缓存机制(一级和二级缓存),能减少数据库访问。对于简单CRUD,JPA的性能可能比Mybatis更好,因为缓存避免了重复查询。
然而,JPA的自动SQL生成可能不高效。例如,关联查询时,如果使用
@OneToMany,可能生成多条SQL语句,造成性能瓶颈。你可以用@Query注解写自定义SQL来优化,但这又回到了类似Mybatis的方式。
总结:Mybatis在复杂查询和性能调优上更直接,但需要开发者有SQL优化能力;JPA在简单操作上高效,但复杂场景可能需要手动干预。
2. 灵活性:谁能应对复杂业务?
灵活性是架构师最关心的点。Mybatis在这方面优势明显,因为它不强制你使用对象模型,你可以直接写任意SQL,包括存储过程或复杂联接。
例如,假设我们需要查询用户及其订单数量。在Mybatis中,可以这样写:
sql
<select id="findUserWithOrderCount" resultType="map">
SELECT u.id, u.name, COUNT(o.id) as order_count
FROM user u
LEFT JOIN order o ON u.id = o.user_id
GROUP BY u.id, u.name
</select>在JPA中,你可能需要定义DTO类,并用@Query写JPQL或原生SQL:
java
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT new com.example.dto.UserOrderCount(u.id, u.name, COUNT(o)) FROM User u LEFT JOIN u.orders o GROUP BY u.id, u.name")
List<UserOrderCount> findUserWithOrderCount();
}这里,JPA的代码更面向对象,但需要额外定义DTO类,灵活性稍差。
有些小伙伴在工作中,遇到动态SQL时,Mybatis的<if>标签非常方便:
ini
<select id="findUsers" parameterType="map" resultType="User">
SELECT * FROM user
WHERE 1=1
<if test="name != null">
AND name = #{name}
</if>
<if test="email != null">
AND email = #{email}
</if>
</select>JPA中,你需要用Specification或QueryDSL来实现动态查询,代码更复杂。
总结:Mybatis在复杂查询和动态SQL上更灵活;JPA在标准CRUD上更高效,但复杂业务需要额外学习。
3. 学习曲线和开发效率
对于新手来说,JPA可能更容易上手,因为Spring Boot自动配置了大量东西。
你只需要定义实体和Repository,就能完成基本操作。
Mybatis则需要学习XML配置和SQL映射,初期可能更耗时。
但从长期看,Mybatis的SQL可见性有助于团队理解数据库操作,而JPA的"黑盒"特性可能导致调试困难。
我见过一些项目,因为JPA的延迟加载问题,在性能调优上花了大量时间。
4. 社区和生态
两者都有强大的社区支持。
Mybatis起源于Apache,在国内使用广泛,文档丰富。
JPA是Java EE标准,Spring Data生态完善,更新频繁。
选择时,可以考虑团队熟悉度和社区资源。
五、实际工作中的应用场景
有些小伙伴在工作中,问我:"三哥,我们项目是电商系统,该用哪个?"
我来分享几个真实案例。
- 案例1:快速创业项目 :一个MVP(最小可行产品)需要快速上线。我们选了JPA,因为代码量少,开发速度快。团队在两周内就完成了用户和订单模块,后期用
@Query优化了复杂查询。 - 案例2:金融系统:需求涉及复杂报表和大量SQL优化。我们用了Mybatis,因为可以直接写高效的SQL,并与DBA协作优化索引。XML文件成了文档,方便后续维护。
- 案例3:微服务架构:在多个服务中,有的服务用JPA(简单CRUD),有的用Mybatis(复杂查询)。架构师需要统一规范,避免混用带来的维护成本。
画一个决策流程图,帮你快速选择:
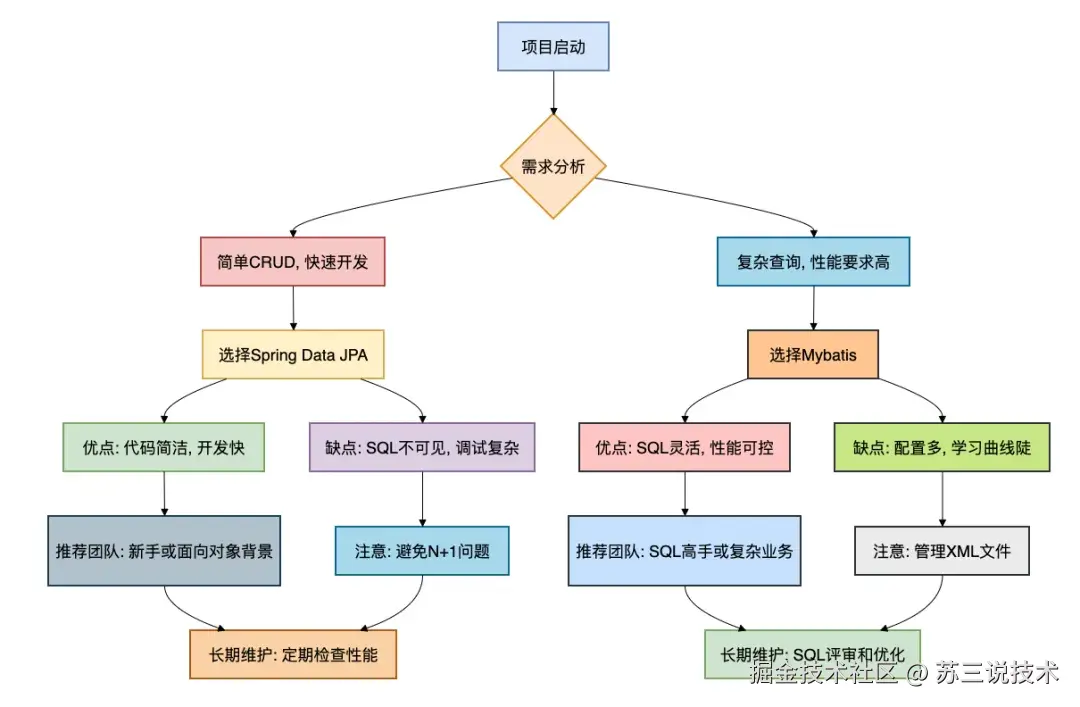
总结
- 如果你的项目以简单CRUD为主,团队熟悉面向对象编程,追求开发效率,那么Spring Data JPA是更好的选择。它能让你快速原型开发,减少代码量。
- 如果你的项目涉及复杂查询、高性能要求,或者团队有较强的SQL能力,那么Mybatis更合适。它提供了直接控制SQL的灵活性,便于优化和维护。
在实际工作中,我经常看到团队混用两者------例如,用JPA处理简单操作,用Mybatis处理报表查询。
但这需要良好的架构设计,避免混乱。
最后,记住:框架是工具,关键是理解和需求。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。