文章目录
一、理解"⼀切皆文件"
⾸先,在windows中是⽂件的东西,它们在linux中也是⽂件;其次⼀些在windows中不是⽂件的东西,⽐如进程、磁盘、显⽰器、键盘这样硬件设备也被抽象成了⽂件,你可以使⽤访问⽂件的⽅法访问它们获得信息;甚⾄管道,也是⽂件;将来我们要学习⽹络编程中的socket(套接字)这样的东西,使⽤的接⼝跟⽂件接⼝也是⼀致的。
这样做最明显的好处是,开发者仅需要使⽤⼀套 API 和开发⼯具,即可调取 Linux 系统中绝⼤部分的资源。举个简单的例⼦,Linux 中⼏乎所有读(读⽂件,读系统状态,读PIPE)的操作都可以⽤read 函数来进⾏;⼏乎所有更改(更改⽂件,更改系统参数,写 PIPE)的操作都可以⽤ write 函数来进⾏。
1、操作系统对于硬件的管理也要遵循先描述再组织,所以操作系统内部也有描述硬件的结构体,它们用链表组织起来。2、有的硬件只有读操作,如键盘,有的硬件只有写操作,如显示器,有的硬件既有读也有写,如磁盘、网卡。
3、对于不同的计算机硬件,访问的方式一定是不同的,因为硬件之间差异很大。
4、操作系统为了统一进行文件(硬件)管理,所以每个文件的file_struct内部会存在一组指向特定文件操作函数的指针,包括文件的读写操作(结构体中不能定义函数对象,所以定义函数指针),
5、这里介绍的文件的读写操作和操作系统的系统调用read、write不一样,因为read、write本质是拷贝函数,比如write是把内存中用户空间的数据拷贝的文件内核缓冲区。而这里文件的写操作本质是把文件缓冲区的数据刷新到底层硬件中,读操作同理。
6、所以一切皆文件,是站在进程的视角,在file_struct结构体之上,看待文件的视角。
7、Linux打开文件并创建file struct时,file struct中有三个核心:
文件属性 (间接找到文件属性)
文件内核缓冲区 (间接找到文件内容)
底层设备文件的操作表(操作方法集)
8、上层一切皆文件,下层有许多各种各样的文件,这里很像我们在C++学的多态,其实操作系统中的"一切皆文件"理论就是用C语言实现的多态,struct file就是基类,特定文件的操作函数就是子类,struct file中的函数指针指向特定文件的操作函数,就像虚函数表中的虚指针指向的父类或子类的方法。
9、每个进程的一套file struct叫做进程的VFS(虚拟文件系统)。
10、计算机中的一切问题都可以通过添加一层软件层来解决,这句话我们又可以结合这层VFS来加深一下理解:以前进程访问文件时都是直接访问文件(包括硬件),对文件进行读取写入操作时每个文件的接口都不一样,不方便。后来我们在进程PCB和硬件之间添加一层软件层(VFS),并定义函数指针,这样进程看待文件时就以统一的视角看待所以文件了,文件底层的方法对进程来说就被屏蔽了,以函数指针的方式屏蔽。
11、我们前面介绍的虚拟地址空间是进程与内存之间的软件层。
下面是内核对上面理论的实现,值得关注的是 struct file 中的 f_op 指针指向了⼀个 file_operations 结构体,这个结构体中的成员除了struct module* owner 其余都是函数指针。file_operation 就是把系统调⽤和驱动程序关联起来的关键数据结构,这个结构的每⼀个成员都对应着⼀个系统调⽤。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从而完成了Linux设备驱动程序的⼯作。
cpp
struct file {
...
struct inode* f_inode; /* cached value */
const struct file_operations* f_op;
...
atomic_long_t f_count; // 表⽰打开⽂件的引⽤计数,如果有多个⽂件指针指向
//它,就会增加f_count的值。
unsigned int f_flags; // 表⽰打开⽂件的权限
fmode_t f_mode; // 设置对⽂件的访问模式,例如:只读,只写等。所有
//的标志在头⽂件<fcntl.h> 中定义
loff_t f_pos; // 表⽰当前读写⽂件的位置
...
} __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
struct file_operations {
struct module* owner;
//指向拥有该模块的指针;
loff_t(*llseek) (struct file*, loff_t, int);
//llseek ⽅法⽤作改变⽂件中的当前读/写位置, 并且新位置作为(正的)返回值.
ssize_t(*read) (struct file*, char __user*, size_t, loff_t*);
//⽤来从设备中获取数据. 在这个位置的⼀个空指针导致 read 系统调⽤以 -
EINVAL("Invalid argument") //失败.⼀个⾮负返回值代表了成功读取的字节数(返回值是⼀个
"signed size" //类型, 常常是⽬标平台本地的整数类型).
ssize_t(*write) (struct file*, const char __user*, size_t, loff_t*);
//发送数据给设备. 如果 NULL, -EINVAL 返回给调⽤ write 系统调⽤的程序. 如果⾮负, 返
//回值代表成功写的字节数.
ssize_t(*aio_read) (struct kiocb*, const struct iovec*, unsigned long,
loff_t);
//初始化⼀个异步读 -- 可能在函数返回前不结束的读操作.
ssize_t(*aio_write) (struct kiocb*, const struct iovec*, unsigned long,
loff_t);
//初始化设备上的⼀个异步写.
int (*readdir) (struct file*, void*, filldir_t);
//对于设备⽂件这个成员应当为 NULL; 它⽤来读取⽬录, 并且仅对**⽂件系统**有⽤.
unsigned int (*poll) (struct file*, struct poll_table_struct*);
int (*ioctl) (struct inode*, struct file*, unsigned int, unsigned long);
long (*unlocked_ioctl) (struct file*, unsigned int, unsigned long);
long (*compat_ioctl) (struct file*, unsigned int, unsigned long);
int (*mmap) (struct file*, struct vm_area_struct*);
//mmap ⽤来请求将设备内存映射到进程的地址空间. 如果这个⽅法是 NULL, mmap 系统调⽤返
回 - ENODEV.
int (*open) (struct inode*, struct file*);
//打开⼀个⽂件
int (*flush) (struct file*, fl_owner_t id);
//flush 操作在进程关闭它的设备⽂件描述符的拷⻉时调⽤;
int (*release) (struct inode*, struct file*);
//在⽂件结构被释放时引⽤这个操作. 如同 open, release 可以为 NULL.
int (*fsync) (struct file*, struct dentry*, int datasync);
//⽤⼾调⽤来刷新任何挂着的数据.
int (*aio_fsync) (struct kiocb*, int datasync);
int (*fasync) (int, struct file*, int);
int (*lock) (struct file*, int, struct file_lock*);
//lock ⽅法⽤来实现⽂件加锁; 加锁对常规⽂件是必不可少的特性, 但是设备驱动⼏乎从不实现
它.
ssize_t(*sendpage) (struct file*, struct page*, int, size_t, loff_t*,
int);
unsigned long (*get_unmapped_area)(struct file*, unsigned long, unsigned
long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file*, int, struct file_lock*);
ssize_t(*splice_write)(struct pipe_inode_info*, struct file*, loff_t*,
size_t, unsigned int);
ssize_t(*splice_read)(struct file*, loff_t*, struct pipe_inode_info*,
size_t, unsigned int);
int (*setlease)(struct file*, long, struct file_lock**);
};介绍完相关代码,⼀张图总结:
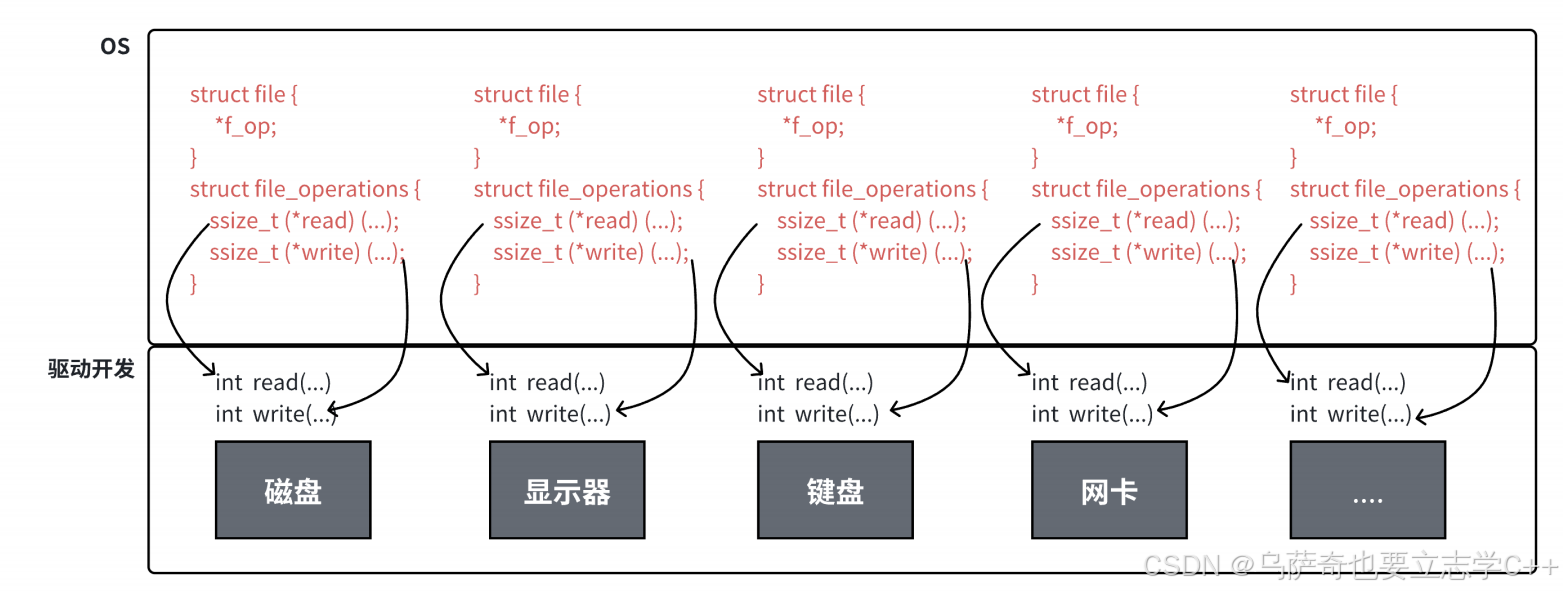
上图中的外设,每个设备都可以有⾃⼰的read、write,但⼀定是对应着不同的操作⽅法!!但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只⽤file便可调取 Linux 系统中绝⼤部分的资源!!这便是"linux下⼀切皆⽂件"的核⼼理解。
二、缓冲区
今天我们要深度理解一下我们从C语言阶段就一直提到的缓冲区概念。
什么是缓冲区
我们先大致理解一下缓冲区,后面再结合实例详细介绍。
1、缓冲区的本质,就是一段内存空间。
2、我们可以把人类比成进程,把缓冲区类比成菜鸟驿站,把数据类比成快递。如果实际上没有菜鸟驿站,我们就需要自己跋山涉水把快递送出去,有了菜鸟驿站,我们就可以把快递交给菜鸟驿站,让它帮我们送快递,这样可以极大的节约发快递的人的时间,但是快递始终还是需要有人送,只是这个人不是你。所以结合这个示例,缓冲区最大的意义,是提高使用缓冲区的进程的效率,因为单位时间内使用缓冲区是进程可以做更多的事情,但这不一定提高了整机的效率,因为始终要有人去完成送快递的任务。
3、规定允许数据在缓冲区中积压,所以可以一次批量化刷新,刷新多次数据,这样可以变相的减少IO的次数,提升效率。
(2、3中包含缓冲区的作用)
缓冲区刷新的三种策略、两种情况
策略:
1、无缓冲,立即刷新。
2、有缓冲,行刷新(显示器文件常用)。
3、有缓冲,写满缓冲区再刷新(普通文件常用)。
情况:
1、进程退出,自动刷新缓冲区。
2、进程强制刷新,如fflush(stdout)。
语言级别缓冲区
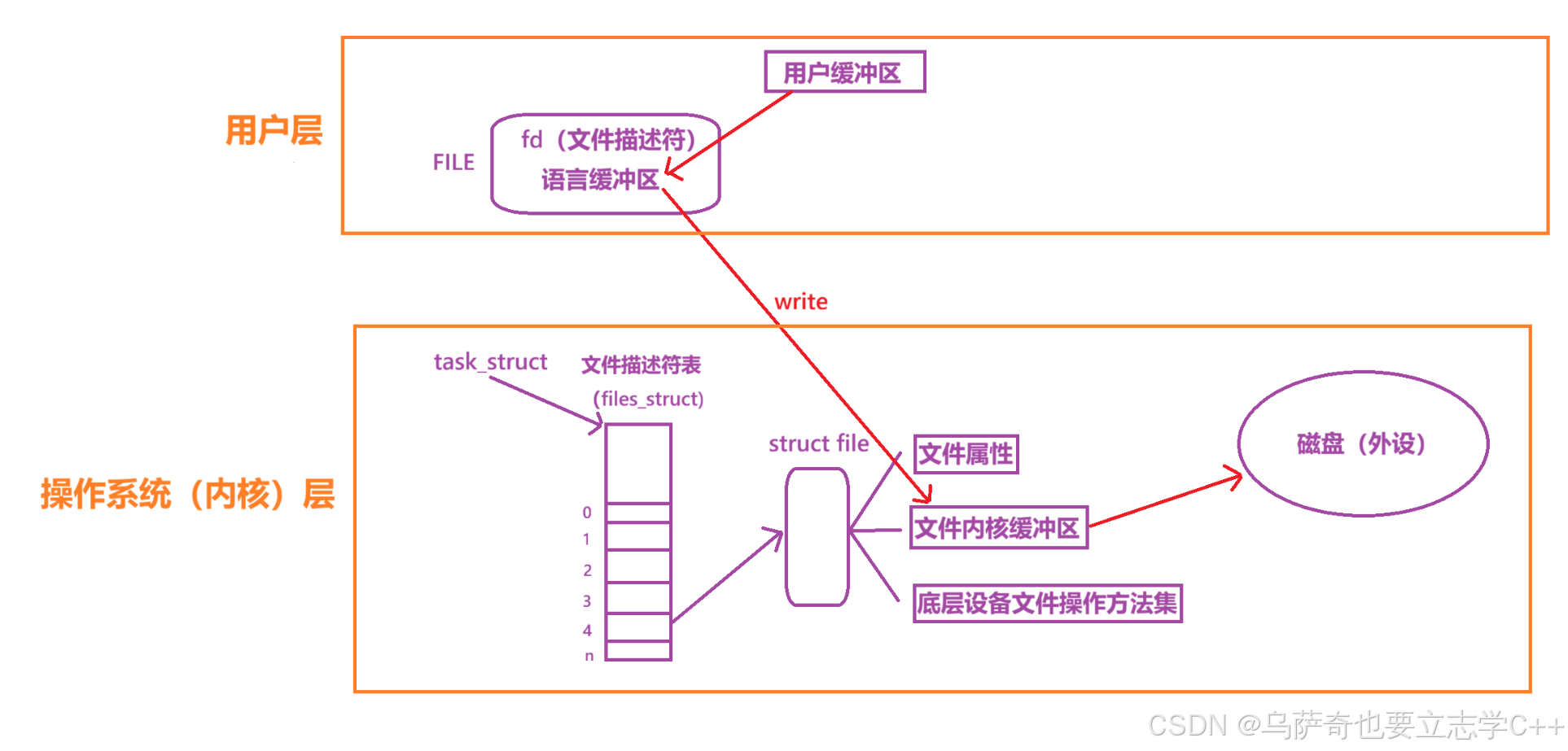
FILE结构体内部会为我们维护语言级别的缓冲区空间,有两个char* 类型的字段:inbuffer outbuffer来维护自己的语言缓冲区。
使用C语言进行文件写入全流程
当我们需要对某个文件如4号文件描述符所指向的文件进行写入时,首先需要打开4号文件,拿到它的FILE结构体,然后调用fputs进行写入,会先把用户缓冲区的数据拷贝到FILE结构体维护的语言级别缓冲区中,然后fputs底层封装的write会适时将语言级缓冲区的数据拷贝到对应文件的内核文件缓冲区中,最后操作系统再把数据从内核文件缓冲区中的数据刷新到外设里就完成了此次写操作。
用户缓冲区就是==int fputs(const char *s, FILE *stream);==接口中第一个参数const char *s,第二个参数FILE文件流里有文件描述符和语言级缓冲区。
对之前现象的解释
我们之前做过一个实验,当我们调用printf打印数据,然后让进程休眠一段时间,当printf的字符串末尾带'\n'时运行程序后我们能立即看到打印在显示器上的字符串,如果printf的字符串末尾不带'\n'时程序后第一时间我们什么都看不到,只有当程序终止后我们才看到打印在显示器上的字符串,接下来小编打算结合上面介绍的用户缓冲区详细聊一聊这一现象的原因。
首先说明:用户缓冲区和语言级别缓冲区属于用户层面,文件内核缓冲区属于操作系统层面。
cpp
printf("hello wusaqi\n");这句代码的意思是printf会把用户缓冲区中的数据"hello wusaqi"拷贝到语言缓冲区中,因为字符串末尾有'\n'所以语言缓冲区中的数据还会立即拷贝到到操作系统层面的内核文件缓冲区中,我们认为只要用户把数据交给了操作系统,用户就完成了写入操作,所以我们就可以立马看到显示器上打印的结果。
cpp
printf("hello wusaqi");如果字符串末尾没有'\n'时,printf照样会把用户缓冲区中的数据"hello wusaqi"拷贝到语言缓冲区中,但是没有'\n'数据就会在语言缓冲区中暂存着不会立即拷贝到内核文件缓冲区中,只有当程序结束、进程退出操作系统主动刷新缓冲区时我们才能看到打印的结果。
总结(为什么要有语言缓冲区?)
1、我们以前所说的缓冲区全都是语言级别缓冲区,和内核没有半毛钱关系。
2、语言缓冲区在FILE结构体内部。
3、为什么要有语言级别缓冲区?第一点:我们首先要明白调用系统调用是有成本的,比较浪费时间,所以我们在讲解STL容器的扩容机制时经常提到的1.5倍或者2倍扩容就是为了优化这一问题,因为new/malloc扩容空间时底层都会调用系统调用,如果我们来一个数据就扩容一次就会频繁扩容,频繁扩容就会频繁调用系统调用,势必就会造成效率下降,所以1.5倍或者2倍扩容机制就是为了减少系统调用次数,提高效率。
刷新语言缓冲区也是同理,把语言缓冲区的数据刷新到文件的内核缓冲区时必然会调用系统调用,如果有语言缓冲区的存在我们可以暂存一些数据然后一次刷新,减少了系统调用次数。
第二点:我们以写操作为例,有了语言缓冲区,C语言的输出库函数printf,fputs等等,调用它们时它们的的任务就只用把数据从用户缓冲区拷贝到语言缓冲区,并适时调用系统调用write,而不用亲自将数据从用户缓冲区拷贝到硬件设备,这样就可以提高C语言IO接口的效率。
4、以printf为首的格式化输入函数本质是将数据格式化后存到语言缓冲区中了。5、有了上面的认识,我们可以认识到printf本质会做三件事情:将数据格式化,把格式化后的数据拷贝到语言缓冲区中,检查缓冲区是否需要刷新,若需要就调用write系统调用。
一个例子对所学知识融会贯通
代码:
cpp
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
int main()
{
// C语言库函数
const char *s1 = "hello printf\n";
printf(s1);
const char *s2 = "hello fprintf\n";
fprintf(stdout, s2);
const char *s3 = "hello fwrite\n";
fwrite(s3, strlen(s3), 1, stdout);
// 系统调用
const char *s4 = "hello write[syscall]\n";
write(1, s4, strlen(s4));
// 创建子进程
fork();
return 0;
}运行结果:
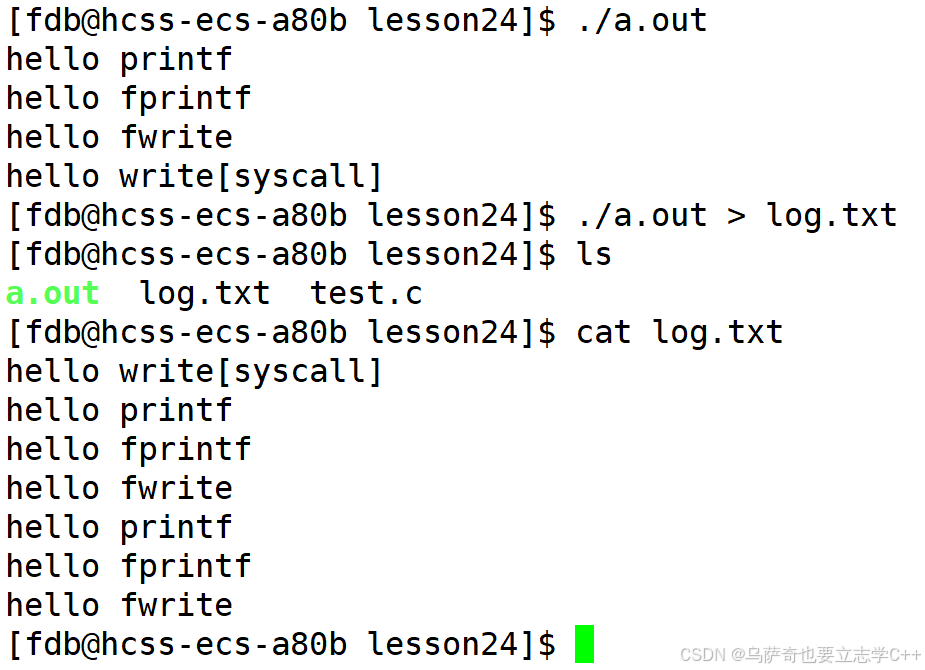
我们可以看到这段代码逻辑就是调用了三次C语言是文件输出库函数,一次系统调用write,当把运行结果打印到显示器文件上时还一切正常,但是当把运行结果打印重定向到普通文件log.txt后结果就变成了打印一次系统调用和六次库函数。下面来分析分析:
1、缓冲区刷新策略的隐式调整。我们先看第一种情况,当输出到显示器文件时是语言缓冲区的刷新策略是行刷新,所以当输出库函数把数据字符串数据拷贝到语言缓冲区后,因为字符串末尾有\n,所以触发行刷新立即将拷贝来的字符串拷贝到文件内核缓冲区中,所以库函数打印的三句字符串我们能马上看到,最后的write打印结果我们也能看到。我们再看第二种情况,当输出重定向到普通文件后对应文件的语言缓冲区就变成了全刷新,这时遇到\n就刷新的策略就不起效了,所以库函数的三句字符串都会暂存在语言缓冲区中,等进程退出主动刷新缓冲区时我们才能看到。而系统调用write是直接把数据从用户缓冲区拷贝到内核缓冲区中,所以我们会先看到系统调用的输出结果。
2、写时拷贝。承接上一点有关第二种情况的解析,我们看到系统调用的输出结果后代码fork了一个子进程,所以父子进程共享log.txt文件和配套的缓冲区,当父子进程退出时都会对它们各自的log.txt用户缓冲区做刷新,我们知道用户缓冲区的刷新本质就是将用户缓冲区的数据拷贝到内核缓冲区中,所以本质就是对用户缓冲区做修改,做修改就会发生写实拷贝,所以我们就会看到库函数的字符串打印了两份,一共六行字符串。
内核缓冲区
我们前面已经把语言缓冲区讲解完毕,用户只要把用户层的数据交给内核文件缓冲区后就完成了任务,那操作系统对于内核缓冲区的刷新策略又是什么呢?
其实内核缓冲区的刷新策略和用户缓冲区差不多,普通文件是全刷新,显示器是行刷新,但内核缓冲区还有一个自己的执行流,它会根据内存的使用情况动态刷新,即使刷新条件不满足。
下面我们再介绍一个系统调用接口,fsync:
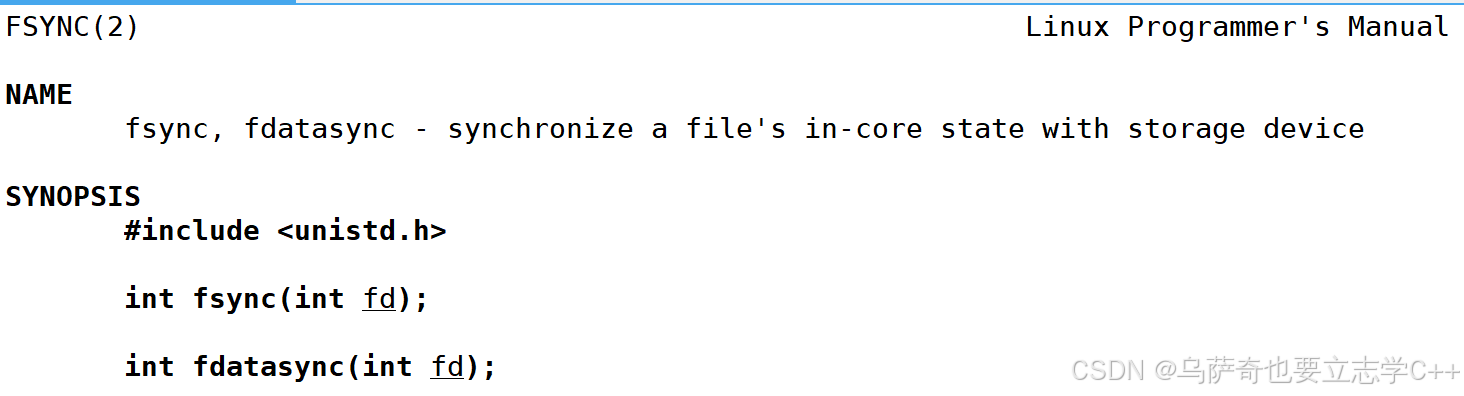
它会强制将文件内核缓冲区的数据刷新到硬件外设中。注意和fflush做区分,fflush是强制将用户缓冲区的数据刷新到内核缓冲区中。
(补充:musql、redis这类数据库所谓的存盘,落盘,持久化本质底层都会调用fsync)
三、标准错误
标准输出、标准错误都是关联显示器文件,那标准错误文件存在的意义是什么呢?它的作用其实是把正确输出和错误输出进行分离。
现象
cpp
int main()
{
printf("hello printf\n");
perror("hello perror");
std::cout << "hello std::cout" <<std::endl;
std::cerr << "hello std::cerr" <<std::endl;
return 0;
}运行结果:

我们看运行结果,当把数据打印到显示器上时一切正常,因为标准输出1和表座错误2对应的文件都是显示器文件。但是但我们把结果输出重定向到文件log.txt后会发生一个奇怪的现象,标准输出正常打印到了log.txt文件中,而标准错误却直接打到了显示器上。
这是因为输出重定向只会对标准输出重定向,假设log.txt的文件描述符是3号,因为'>'底层本质会调用dup(3, 1),这样printf、cout默认往1号文件文件描述符打时就会打到log.txt中,而perror、cerr默认是往二号文件描述符打的,而2号文件描述符没有被重定向、依旧关联显示器,所以perror、cerr会把数据打到显示器上。
操作
下面我们来尝试将标准输出数据和标准错误数据分别打印到两个不同的文件,首先知道我们要知道 ./a.out > log.txt 指令其实是一种简写,把它写全了应该是:
bash
./a.out 1>log.txt 表示把标准输出1重定向到指定文件,所以基于此我们可以写出以下指令: (注意文件描述符和重定向符号之间不能带空格)
bash
./a.out 1>ok.txt 2>error.txt运行结果:
如果我们想把标准输出和标准错误都写入同一个文件可以用下面的指令,表示把2号文件描述符文件重定向到1号文件描述符文件(加了&shell就会把后面的数字当作文件描述符,若不加&就只表示一个单纯的文件名)。
这样写保证输出的顺序性和一致性,这里会用到管道的知识,小编这里就不展开讲了。
cpp
./a.out 1>log.txt 2>&1但是不能用下面这样的指令,可能出现输出交错、竞争混乱。
bash
./a.out 1>log.txt 2>log.txt四、设计一个简易libc库
我们下面通过手搓一个libc库来加深我们对语言级别用户缓冲区刷新方式理解,模拟一下C语言做文件IO的过程,这里我们并不会把全部libc的全部功能都实现,而是着重实现libc库中的缓冲区相关功能。
my_fopen:my_fopen首先底层调用open,然后动态开辟FILE结构体空间,初始化FILE结构体后把FILE结构体返回。
my_fwrite:my_ffwrite实现把用户缓冲区数据拷贝到语言缓冲区,并根据当前缓冲区刷新机制适时把缓冲区数据做刷新。我们把刷新缓冲区核心代码逻辑封装成fflush_core,并且只能在当前文件内使用。fflush_core有两套刷新模式,由传给fflush_core的第二个参数决定,一个是NORMAL模式,如行刷新,全刷新是NORMAL模式,my_ffwrite内部的刷新逻辑是调用的fflush_core的NORMAL模式。还有一个是FORCE强制刷新模式,my_ffflush内部是调用的fflush_core的强制刷新模式。
my_fclose:my_fclose首先调用my_ffflush的强制刷新模式刷新缓冲区、把数据从语言缓冲区拷贝到内核缓冲区,然后分调用系统调用fsync把内核缓冲区数据刷新到外设中(fsync可以保证测试代码的打印顺序),接着close关闭文件,最后free掉动态开辟的FILE结构体。
test.c:
cpp
#include "mystdio.h"
#include <string.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
MYFILE* fp = my_fopen("log.txt", "w");
if(fp == NULL)
{
return 1;
}
char data[128];
const char* s = "hello wusaqi";
int count = 20;
while(count--)
{
snprintf(data, sizeof(data), "%s:%d\n", s, count);
my_fwrite(data, strlen(data), fp);
sleep(1);
}
my_fclose(fp);
return 0;
}mystdio.c:
cpp
#include "mystdio.h"
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
MYFILE* my_fopen(const char* filename, const char* mode)
{
// 1、调用系统调用打开文件
int fd = -1;
if (strcmp(mode, "r") == 0)
{
fd = open(filename, O_RDONLY);
}
else if (strcmp(mode, "w") == 0)
{
fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, UMASK);
}
else if (strcmp(mode, "a") == 0)
{
fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, UMASK);
}
else if (strcmp(mode, "a+") == 0)
{
fd = open(filename, O_RDWR | O_CREAT | O_APPEND, UMASK);
}
else {
//todo
}
if (fd < 0)
{
//fopen失败返回NULL
return NULL;
}
// 2、创建MYFILE结构体
MYFILE* fp = (MYFILE*)malloc(sizeof(MYFILE));
if (fp == NULL)
{
return NULL;
}
// 3、初始化MYFILE内数据
fp->fileno = fd;
fp->flag = FLUSH_LINE; //默认行刷新,方便后续测试
fp->outbuffer[0] = 0; //缓冲区置空
fp->curr = 0;
fp->cap = SIZE;
return fp;
}
// 不暴露给外部
static void fflush_core(MYFILE* fp, int force)
{
if (fp->curr <= 0)
{
//缓冲区没有数据,直接return
return;
}
if (force == FORCE)
{
write(fp->fileno, fp->outbuffer, fp->curr);
fp->curr = 0;
}
else {
if (fp->flag == FLUSH_LINE && fp->outbuffer[fp->curr - 1] == '\n')
{
//符合行刷新条件,进行行刷新
write(fp->fileno, fp->outbuffer, fp->curr);
fp->curr = 0;
}
else if (fp->flag == FLUSH_FULL && fp->curr == fp->cap)
{
//符合全刷新条件,进行全刷新
write(fp->fileno, fp->outbuffer, fp->curr);
fp->curr = 0;
}
else {
// todo
}
}
}
int my_fwrite(const char* s, int size, MYFILE* fp)
{
if (fp == NULL || fp->fileno < 0)
{
return;
}
// 1、将数据从用户缓冲区拷贝到语言缓冲区
memcpy(fp->outbuffer + fp->curr, s, size);
// 2、适时调用write,刷新缓冲区
fp->curr += size;
fflush_core(fp, NORMAL);
// 返回写了多少个单位元素
return size;
}
void my_fflush(MYFILE* fp)
{
if (fp == NULL || fp->fileno < 0)
{
return;
}
fflush_core(fp, FORCE);
}
void my_fclose(MYFILE* fp)
{
if (fp == NULL || fp->fileno < 0)
{
return;
}
my_fflush(fp);
fsync(fp->fileno);
close(fp->fileno);
free(fp);
}mystdio.h:
cpp
#ifndef __MYSTDIO_H__
#define __MYSTDIO_H__
#define FLUSH_NONE 1 //无缓冲,立即刷新
#define FLUSH_LINE 2 //行刷新
#define FLUSH_FULL 4 //全刷新
#define SIZE 4096
#define UMASK 0666
//刷新策略
#define FORCE 1
#define NORMAL 0
typedef struct _MY_IO_FILE
{
int fileno; //文件描述符
int flag; //文件刷新方式
char outbuffer[SIZE]; //缓冲区
int curr; //缓冲区有效数据个数,也是最后一个元素下一个位置的下标
int cap; //缓冲区容量
}MYFILE;
MYFILE* my_fopen(const char *filename, const char *mode);
void my_fclose(MYFILE* fp);
int my_fwrite(const char *s, int size, MYFILE* fp);
void my_fflush(MYFILE* fp);
#endif以上就是小编分享的全部内容了,如果觉得不错还请留下免费的赞和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~
