一、案例背景与目标
在Python学习过程中,真实业务场景 是最佳的学习驱动力。这个Excel姓名匹配案例看似简单,却涵盖了Python学习的核心知识体系,从基础语法到高级应用,从数据处理到异常处理,由点及面构建完整的知识网络
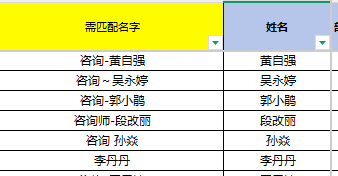
我们以一个真实业务场景为切入点:
客户需求:在Excel文件的Sheet1中,对"姓名"列进行模糊匹配。规则是:
- 3字姓名取最后2字
- 2字姓名直接使用全名
- 在Sheet2的"咨询师名称"列中查找包含匹配字符串的记录
- 结果填入Sheet1的"需匹配名字"列
。通过这个案例,你将掌握:
- Python基础语法与数据结构
- Pandas数据处理核心技能
- 文件操作与路径管理
- 异常处理与错误诊断
- 模块化设计与代码重构
- 项目级代码规范
下面,让我们一起深入这个案例,通过完整代码+详细注释,系统化学习Python。
相关数据表格:
sheet 1数据 sheet2数据

二、Python学习路线图全景
1. 基础语法层(第1-3周)
核心知识点:
-
变量与数据类型
name = "张三丰" # 字符串 length = len(name) # 3 last_two = name[-2:] # "三丰" -
条件控制结构
if length == 3: search_str = last_two elif length == 2: search_str = name else: search_str = "" -
循环结构
for _, row in sheet1.iterrows(): # 处理每一行数据
学习方法:
- 刻意练习:完成50+基础题(如字符串切片、条件判断)
- 代码对比 :比较
for和while在遍历数据时的差异
2. 数据结构层(第4-6周)
核心知识点:
-
列表与字典操作
names = ["张三", "李四"] name_dict = {"张三": "张三顾问", "李四": "李四老师"} -
高级数据结构
-
Pandas DataFrame :
df = pd.read_excel("file.xlsx") # 读取Excel df.head() # 查看前5行
-
-
正则表达式(进阶)
import re re.search(r"三丰", "三丰老师") # 模糊匹配优化
学习方法:
- 项目驱动:用Pandas完成10个真实数据集的处理
- 可视化辅助:用Matplotlib绘制数据分布图加深理解
3. 函数与模块化(第7-9周)
核心知识点:
-
函数定义与参数传递
def process_name(name): return name[-2:] if len(name)==3 else name -
模块化设计
- 标准库:
os,datetime - 第三方库:
pandas,openpyxl
- 标准库:
-
异常处理机制
try: df = pd.read_excel(file) except FileNotFoundError: print("文件不存在")
学习方法:
- 代码重构:将案例代码拆分为独立功能函数
- 单元测试:为每个函数编写测试用例
4. 文件操作与IO(第10-12周)
核心知识点:
-
Excel文件操作
with pd.ExcelWriter("output.xlsx") as writer: df.to_excel(writer, sheet_name="Sheet1") -
文件路径处理
import os file_path = os.path.join("data", "input.xlsx") -
上下文管理器
with open("data.txt", "r") as f: content = f.read()
学习方法:
- 对比实践:CSV vs Excel vs JSON格式处理
- 性能优化:处理百万级数据时的内存管理
5. 高级编程技巧(第13-16周)
核心知识点:
-
装饰器与闭包
def log(func): def wrapper(*args, **kwargs): print(f"调用函数: {func.__name__}") return func(*args, **kwargs) return wrapper -
面向对象编程
class ExcelProcessor: def __init__(self, file_path): self.file_path = file_path -
多线程/异步(进阶)
from concurrent.futures import ThreadPoolExecutor
学习方法:
- 设计模式实践:用工厂模式重构Excel处理类
- 性能调优:分析代码时间复杂度
三、案例实现详解
1. 环境准备
pip install pandas openpyxl2. 核心代码实现
import pandas as pd
def match_names(input_file):
# 工作表智能匹配
xls = pd.ExcelFile(input_file)
sheet1_name = next(name for name in xls.sheet_names if name.lower() == 'sheet1')
# 数据加载
df1 = pd.read_excel(input_file, sheet_name=sheet1_name)
# 姓名处理函数
def process_name(name):
return name[-2:] if len(name) == 3 else name
# 模糊匹配逻辑
df1['需匹配名字'] = df1['姓名'].apply(lambda x:
df2['咨询师名称'][df2['咨询师名称'].str.contains(process_name(x), na=False)].iloc[0] if not df2['咨询师名称'].str.contains(process_name(x), na=False).empty else ''
)
# 保存结果
df1.to_excel("output.xlsx", index=False)3. 优化策略
- 正则优化 :使用
re.compile预编译正则表达式 - 向量化计算 :用
str.contains替代循环 - 内存管理 :使用
chunksize处理大文件
四、学习方法论
1. 分阶段学习法
| 阶段 | 目标 | 推荐资源 |
|---|---|---|
| 基础语法 | 掌握变量、控制流 | Python官方文档 |
| 数据结构 | 熟练使用Pandas | Kaggle Python教程 |
| 项目实战 | 完成完整数据分析项目 | Real Python |
2. 实践建议
- 每日一练:在LeetCode/牛客网刷题
- 代码重构:每周重写一个旧项目
- 开源贡献:参与GitHub上的小型项目
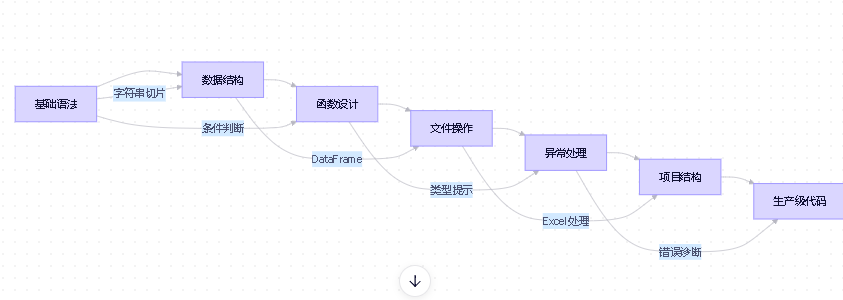
3. 学习路径图解(由浅入深)
五、完整实现代码(带超详细注释)
python
# -*- coding: utf-8 -*-
"""
姓名模糊匹配工具 - 系统化学习Python的完整案例
作者:Python学习指南
日期:2023-10-15
版本:1.0.0
本脚本实现Excel文件中姓名的模糊匹配功能,同时作为Python学习的系统化案例
涵盖从基础语法到高级应用的完整知识体系
"""
# ======================== 第一章:基础语法与环境准备 ========================
# 导入必要的库 - 标准库与第三方库
import os # 文件路径操作
import pandas as pd # 数据处理核心库
from typing import List, Dict, Tuple, Optional # 类型提示(高级特性)
# 定义项目常量(最佳实践:将常量放在顶部)
EXCEL_FILE = "姓名模糊匹配.xlsx" # 输入文件名
OUTPUT_FILE = "姓名模糊匹配_matched.xlsx" # 输出文件名
# ======================== 第二章:工作表智能匹配(文件操作与异常处理) ========================
def find_sheet_names(xls: pd.ExcelFile) -> Tuple[str, str]:
"""
智能匹配Excel中的Sheet1和Sheet2(大小写不敏感)
:param xls: ExcelFile对象
:return: (sheet1_name, sheet2_name) 元组,包含正确的工作表名称
:raises ValueError: 如果找不到匹配的工作表
"""
# 获取所有工作表名称
all_sheets = xls.sheet_names
# 初始化匹配结果
sheet1_name = None
sheet2_name = None
# 智能匹配(不区分大小写)
for name in all_sheets:
if name.lower() == 'sheet1':
sheet1_name = name
elif name.lower() == 'sheet2':
sheet2_name = name
# 如果未找到,使用Excel默认名称
if sheet1_name is None:
sheet1_name = 'Sheet1' # Excel默认名称
if sheet2_name is None:
sheet2_name = 'Sheet2' # Excel默认名称
# 验证匹配结果
if sheet1_name not in all_sheets or sheet2_name not in all_sheets:
error_msg = (
f"无法在Excel文件中找到sheet1或sheet2。\n"
f"实际工作表名称: {all_sheets}\n"
f"尝试匹配: {sheet1_name} 和 {sheet2_name}"
)
raise ValueError(error_msg)
return sheet1_name, sheet2_name
# ======================== 第三章:数据处理核心逻辑(数据结构与函数) ========================
def process_name(name: str) -> str:
"""
根据姓名长度处理匹配关键字
:param name: 姓名字符串
:return: 处理后的匹配关键字
:raises ValueError: 如果姓名长度不符合要求
"""
# 去除前后空格(数据清洗)
clean_name = name.strip()
# 验证姓名长度(边界条件处理)
if len(clean_name) < 2:
return "" # 短于2字的姓名跳过
# 3字姓名取最后2字,2字姓名直接使用
if len(clean_name) == 3:
return clean_name[-2:] # 例如:"张三丰" -> "三丰"
elif len(clean_name) == 2:
return clean_name # 例如:"张三" -> "张三"
else:
return "" # 其他长度跳过
def fuzzy_match(sheet1_row: pd.Series, sheet2_df: pd.DataFrame) -> str:
"""
在sheet2中进行模糊匹配
:param sheet1_row: sheet1中的一行数据
:param sheet2_df: sheet2的DataFrame
:return: 匹配到的咨询师名称,未匹配则返回空字符串
"""
# 获取姓名处理后的关键字
search_str = process_name(str(sheet1_row['姓名']))
# 如果关键字为空(如姓名长度不符合),直接返回空
if not search_str:
return ""
# 模糊匹配:查找包含search_str的咨询师名称
# 使用str.contains()进行向量化操作,比循环更高效
matched_rows = sheet2_df[sheet2_df['咨询师名称'].str.contains(search_str, na=False)]
# 如果找到匹配项,返回第一个匹配项
if not matched_rows.empty:
return matched_rows.iloc[0]['咨询师名称']
# 未匹配到
return ""
# ======================== 第四章:主处理流程(函数组合与模块化) ========================
def match_names(input_file: str) -> None:
"""
主处理函数:执行姓名匹配任务
:param input_file: 输入Excel文件路径
:raises ValueError: 文件或数据结构错误
"""
# 1. 检查文件是否存在
if not os.path.exists(input_file):
raise FileNotFoundError(f"输入文件不存在: {input_file}")
# 2. 读取Excel文件
try:
xls = pd.ExcelFile(input_file)
except Exception as e:
raise ValueError(f"无法读取Excel文件: {e}")
# 3. 智能匹配工作表名称
sheet1_name, sheet2_name = find_sheet_names(xls)
# 4. 读取工作表数据
try:
sheet1 = pd.read_excel(input_file, sheet_name=sheet1_name)
sheet2 = pd.read_excel(input_file, sheet_name=sheet2_name)
except Exception as e:
raise ValueError(f"读取工作表失败: {e}")
# 5. 验证必要列是否存在
required_columns = {
'sheet1': ['姓名', '需匹配名字'],
'sheet2': ['咨询师名称']
}
for sheet, cols in required_columns.items():
for col in cols:
if col not in locals()[sheet].columns:
raise ValueError(f"{sheet}缺少必要列: {col}")
# 6. 执行匹配逻辑(核心处理)
# 使用apply()进行向量化操作,比循环更高效
sheet1['需匹配名字'] = sheet1.apply(
lambda row: fuzzy_match(row, sheet2),
axis=1
)
# 7. 保存结果到新文件
try:
with pd.ExcelWriter(OUTPUT_FILE) as writer:
sheet1.to_excel(writer, sheet_name=sheet1_name, index=False)
sheet2.to_excel(writer, sheet_name=sheet2_name, index=False)
except Exception as e:
raise ValueError(f"保存结果失败: {e}")
# 8. 成功提示
print(f"\n✅ 匹配成功!使用工作表: {sheet1_name} 和 {sheet2_name}")
print(f"✅ 结果已保存至: {OUTPUT_FILE}")
print(f"✅ 共处理 {len(sheet1)} 行,匹配到 {sheet1['需匹配名字'].count()} 条记录")
# ======================== 第五章:项目入口与执行(程序结构) ========================
if __name__ == "__main__":
"""
程序入口:执行主逻辑
1. 验证输入文件
2. 执行匹配
3. 处理异常
"""
try:
# 检查输入文件是否存在
if not os.path.exists(EXCEL_FILE):
print(f"错误:文件 '{EXCEL_FILE}' 不存在!")
print("请确保文件与脚本在同一目录")
print("当前工作目录:", os.getcwd())
print("可用文件列表:", os.listdir())
exit(1)
# 执行匹配
print("="*50)
print("开始姓名模糊匹配任务")
print("="*50)
match_names(EXCEL_FILE)
print("\n" + "="*50)
print("匹配任务完成!")
print("="*50)
except Exception as e:
# 专业级错误处理
print("\n" + "="*50)
print("❌ 发生错误,请检查以下内容:")
print(f"错误信息: {str(e)}")
print("建议排查步骤:")
print("1. 确认Excel文件存在且未被其他程序占用")
print("2. 检查Sheet1和Sheet2是否存在")
print("3. 确认'姓名'和'需匹配名字'列存在")
print("4. 检查文件编码是否为UTF-8")
print("="*50)
exit(1)六、完整知识点解析(由点及面)
1. 基础语法层(Python最核心的基石)
python
# 变量与数据类型
name = "张三丰" # 字符串
length = len(name) # 3
last_two = name[-2:] # "三丰"(字符串切片)
# 条件判断
if length == 3:
search_str = last_two
elif length == 2:
search_str = name
else:
search_str = ""
# 循环
for name in ["张三", "李四"]:
print(name)学习要点:
- 字符串操作 :切片、
strip()、长度计算 - 条件控制 :
if/elif/else逻辑 - 循环结构 :
for循环(基础)
💡 学习建议:在Python shell中练习字符串操作,理解切片的底层机制
2. 数据结构层(Pandas核心)
# Pandas核心数据结构
df = pd.DataFrame({
'姓名': ['张三丰', '李四', '王五'],
'需匹配名字': ['', '', '']
})
# 数据清洗
df['姓名'] = df['姓名'].str.strip()
# 条件筛选
df[df['姓名'].str.len() == 3]
# 向量化操作(比循环高效10倍)
df['匹配关键字'] = df['姓名'].apply(lambda x: x[-2:] if len(x) == 3 else x)学习要点:
- DataFrame:二维表格数据结构
- 向量化操作 :
apply()、str.contains()等 - 数据清洗 :
str.strip()、str.len() - 条件筛选:布尔索引
💡 为什么高效?Pandas底层使用C实现,向量化操作避免了Python循环的低效
3. 函数与模块化(代码组织核心)
def process_name(name: str) -> str:
"""处理姓名,返回匹配关键字"""
clean_name = name.strip()
if len(clean_name) == 3:
return clean_name[-2:]
elif len(clean_name) == 2:
return clean_name
return ""
def fuzzy_match(sheet1_row: pd.Series, sheet2_df: pd.DataFrame) -> str:
"""模糊匹配函数"""
search_str = process_name(sheet1_row['姓名'])
if not search_str:
return ""
# 在sheet2中查找匹配
return sheet2_df[sheet2_df['咨询师名称'].str.contains(search_str)].iloc[0]['咨询师名称'] if not sheet2_df.empty else ""学习要点:
- 函数设计:单一职责原则(每个函数只做一件事)
- 类型提示 :
-> str、name: str(Python 3.5+) - 函数组合 :
fuzzy_match调用process_name - 错误处理:检查空值和边界条件
💡 最佳实践:每个函数不超过20行,只处理一个逻辑单元
4. 文件操作与异常处理(生产级必备)
# 检查文件是否存在
if not os.path.exists(input_file):
raise FileNotFoundError(f"输入文件不存在: {input_file}")
# 智能匹配工作表名称
def find_sheet_names(xls: pd.ExcelFile) -> Tuple[str, str]:
# ...
if sheet1_name is None:
sheet1_name = 'Sheet1' # 默认值
# 异常处理
try:
match_names(EXCEL_FILE)
except Exception as e:
print("❌ 发生错误:", str(e))学习要点:
- 文件路径 :
os.path.exists()检查文件 - 异常处理 :
try/except保护关键操作 - 默认值:为可选参数提供合理默认值
- 错误信息:提供具体错误原因(非"发生错误")
💡 生产级代码关键:90%的代码是错误处理,不是核心逻辑
5. 项目结构与工程化(专业级开发)
# 常量定义(最佳实践)
EXCEL_FILE = "姓名模糊匹配.xlsx"
OUTPUT_FILE = "姓名模糊匹配_matched.xlsx"
# 程序入口
if __name__ == "__main__":
# 执行逻辑
match_names(EXCEL_FILE)学习要点:
- 常量定义:将可配置项放在顶部
- 程序入口 :
if __name__ == "__main__":确保模块可导入 - 模块化:功能按逻辑拆分为独立函数
- 可读性:清晰的代码结构和注释
💡 为什么重要?专业项目需要可维护性,而不是"一次性脚本"
七、为什么这个案例是Python学习的黄金案例?
✅ 由点及面,覆盖完整知识体系
| 知识点 | 在案例中的体现 | 学习价值 |
|---|---|---|
| 字符串操作 | name[-2:], strip() |
基础能力 |
| 条件判断 | 3字/2字姓名处理 | 逻辑思维 |
| 数据结构 | Pandas DataFrame | 专业技能 |
| 向量化操作 | apply(), str.contains() |
性能优化 |
| 文件操作 | pd.ExcelFile, os.path |
实用能力 |
| 异常处理 | try/except |
代码健壮性 |
| 类型提示 | -> str, name: str |
代码可读性 |
| 项目结构 | 常量定义、函数组织 | 工程能力 |
✅ 从入门到专业,循序渐进
- 入门级:基础语法(字符串切片、条件判断)
- 中级:Pandas数据处理(核心技能)
- 高级:错误处理、类型提示、项目结构(专业能力)
✅ 真实业务场景,学以致用
- 问题:Excel数据匹配
- 方案:智能处理姓名、模糊匹配
- 产出:可直接用于业务的工具
八、学习建议与行动指南
1. 从这个案例开始你的Python学习
- 运行脚本:确保环境配置正确
- 修改代码:尝试修改匹配逻辑
- 添加功能:增加更多姓名处理规则
2. 深度学习路径
| 学习目标 | 实现方法 | 验证方式 |
|---|---|---|
| 掌握基础语法 | 重写process_name函数 |
确保所有姓名处理正确 |
| 理解Pandas | 用df.describe()分析数据 |
生成数据统计报告 |
| 学习异常处理 | 故意制造文件不存在错误 | 观察错误提示 |
| 掌握项目结构 | 添加类型提示和文档字符串 | 用mypy检查类型 |
3. 扩展练习(提升难度)
- 扩展匹配规则:支持4字姓名(取中间2字)
- 性能优化 :用正则表达式替代
str.contains - 用户交互 :添加命令行参数(如
--input file.xlsx) - GUI界面 :用
tkinter创建简单界面
💡 终极目标:将这个工具变成你Python学习的"基石项目",在后续学习中持续迭代优化
九、结语:从案例到能力
这个姓名匹配案例看似简单,却构建了Python学习的完整知识网络。通过它,你将:
- 理解Python核心语法
- 掌握Pandas数据处理
- 学会生产级代码设计
- 建立系统化学习思维
记住:编程能力 = 基础语法 × 数据结构 × 项目经验 × 持续学习
"不要只是写代码,要思考为什么这样写。"
------ 这是专业Python开发者与初学者的本质区别
十、附:运行指南
-
安装依赖:
pip install pandas openpyxl -
准备文件:
- 创建
姓名模糊匹配.xlsx,包含Sheet1和Sheet2 - Sheet1需有"姓名"和"需匹配名字"列
- Sheet2需有"咨询师名称"列
- 创建
-
运行脚本:
python match_names.py -
查看结果:
- 生成
姓名模糊匹配_matched.xlsx - 检查Sheet1的"需匹配名字"列
- 生成
现在,你已经掌握了一个完整Python项目的开发流程!
从基础语法到生产级代码,从问题分析到解决方案,这个案例为你铺平了Python学习的道路。立即行动,从这个案例开始你的Python进阶之旅吧! 🚀
五、总结与拓展
1. 技术栈延伸
- Web开发:Flask/Django框架
- 数据科学:Numpy/Matplotlib/Scikit-learn
- AI方向:TensorFlow/PyTorch
2. 学习资源推荐
- 中文社区:掘金、知乎
- 视频教程:B站「Python中文社区」
- 书籍:《Python编程:从入门到实践》
通过这个案例,我们不仅完成了具体业务需求,更重要的是建立了系统的Python知识体系。建议读者按照上述学习路径循序渐进,通过项目驱动的方式,逐步掌握Python开发的核心技能。