前言
python脚本适合部署在服务器端,开发和维护都很方便,特别是在人工智能方面的模块非常丰富,许多客户的需求都可以落地。但也有需要制作成window客户端的场景,此时是不适合在用户的电脑上运行python脚本的,这时就需要打包成exe应用进行部署。
以下我将会提供3种打包的OCR应用:不带参数的控制台exe、不带参数的图像界面exe、带参数的控制台exe。涉及的代码分享在资源中,因为exe程序太大,上传不上去,需要的留言。
另外,阅读本文时,一定要先看我分享的上一篇文章,有些关联知识我这里不再重复。python 部署可离线使用的中文识别OCR(window)![]() https://blog.csdn.net/liangyuna8787/article/details/153336448
https://blog.csdn.net/liangyuna8787/article/details/153336448
效果图
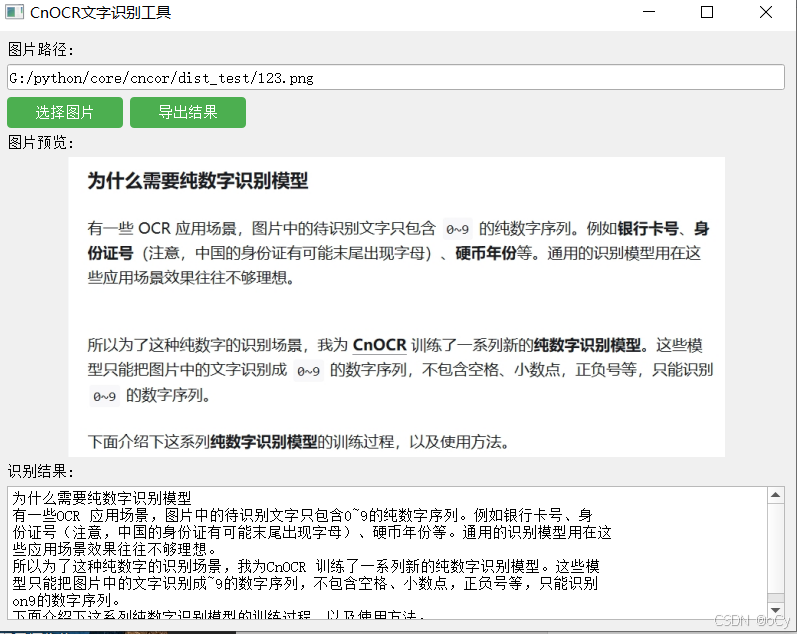
只有一个不带参数的图像界面exe可以看到界面,如下图
打包场景介绍
一、不带参数的控制台exe
先用一个简单的图片识别程序来走通打包流程。
python中的打包专属工具是pyinstaller,在上篇文章中搭建的虚拟环境(cnocr_env)中安装

因为部署好cnocr的python环境之后,训练好的模型ch_PP-OCRv5_det_infer.onnx是在线自动下载(下载到C:\Users\xxxx\AppData\Roaming目录下),而客户的电脑没有部署Python环境,或者是在内网,所以我们需要把模型文件目录一起打包。
本次打包,把模型文件涉及的cnocr和cnstd目录放在与待打包python文件同级目录的models目录下,结构如下:
├── ocr_test.py
└── models/
├── cnocr/
└── cnstd/
ocr_test.py是简单的测试例子,加入了指定models目录下的训练模式作为文字识别模型(python部署环境默认是C:\Users\xxxx\AppData\Roaming,所以必须明确指定到models目录),代码如下:
# ocr_test.py
import os
import sys
from cnocr import CnOcr
def setup_environment():
"""设置运行环境"""
# 获取当前脚本所在目录的绝对路径
if getattr(sys, 'frozen', False):
# 如果是打包后的exe,使用exe所在目录
script_dir = os.path.dirname(sys.executable)
else:
# 开发环境,使用脚本所在目录
script_dir = os.path.dirname(os.path.abspath(__file__))
# 设置模型根目录(绝对路径)
models_dir = os.path.join(script_dir, "models")
cnocr_dir = os.path.join(models_dir, "cnocr")
cnstd_dir = os.path.join(models_dir, "cnstd")
# 设置环境变量
os.environ["CNOCR_HOME"] = cnocr_dir
os.environ["CNSTD_HOME"] = cnstd_dir
return script_dir, models_dir, cnocr_dir, cnstd_dir
# 设置环境
script_dir, models_dir, cnocr_dir, cnstd_dir = setup_environment()
# 检查模型目录是否存在
if not os.path.exists(models_dir):
print(f"错误: 模型目录不存在: {models_dir}")
print("请确保models目录与程序在同一目录下")
input("按任意键退出...")
sys.exit(1)
# 初始化OCR实例,使用绝对路径指定模型文件
try:
ocr = CnOcr(
det_model_name='ch_PP-OCRv5_det',
rec_model_name='densenet_lite_136-gru',
det_model_fp=os.path.join(cnstd_dir, "1.2/ppocr/ch_PP-OCRv5_det/ch_PP-OCRv5_det_infer.onnx"),
rec_model_fp=os.path.join(cnocr_dir, "2.3/densenet_lite_136-gru/cnocr-v2.3-densenet_lite_136-gru-epoch=004-ft-model.onnx")
)
print("OCR初始化成功!")
except Exception as e:
print(f"OCR初始化失败: {e}")
print("请检查模型文件是否完整")
input("按任意键退出...")
sys.exit(1)
def process_image(image_path):
"""处理图片并返回识别结果"""
if not os.path.exists(image_path):
return f"错误: 图片文件不存在: {image_path}"
try:
results = ocr.ocr(image_path)
texts = [res['text'] for res in results]
return texts
except Exception as e:
return f"识别过程中出错: {e}"
def save_results(results, output_path):
"""保存识别结果到文件"""
try:
with open(output_path, 'w', encoding='utf-8') as f:
if isinstance(results, list):
for text in results:
f.write(text + '\n')
else:
f.write(results)
return f"结果已保存到: {output_path}"
except Exception as e:
return f"保存结果时出错: {e}"
if __name__ == '__main__':
# 使用示例
image_file = '123.png'
if os.path.exists(image_file):
print(f"正在处理图片: {image_file}")
results = process_image(image_file)
if isinstance(results, list):
print("识别结果:")
for i, text in enumerate(results, 1):
print(f"{i}: {text}")
else:
print(results)
# 保存结果
output_path = os.path.join(script_dir, 'ocr_result.txt')
save_status = save_results(results, output_path)
print(save_status)
else:
print(f"图片文件不存在: {image_file}")
print("请将待识别的图片放在程序同目录下,并命名为'123.png'")
input("按任意键退出...")如果不需要调用模型的话,使用命令pyinstaller ---onefile ocr_test.py就可以完成打包了,以下提供详细配置(.spec配置)方式进行打包,配置代码如下:
# ocr_test.spec
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
# 获取虚拟环境路径
venv_path = r"D:\python\cnocr_env" #这是虚拟环境的实际目录
site_packages = os.path.join(venv_path, "Lib", "site-packages")
def get_package_data(package_name):
"""获取包的数据文件"""
package_dir = os.path.join(site_packages, package_name)
if not os.path.exists(package_dir):
return []
data_files = []
for root, dirs, files in os.walk(package_dir):
for file in files:
if file.endswith('.pyc') or '__pycache__' in root:
continue
src_path = os.path.join(root, file)
rel_path = os.path.relpath(root, site_packages)
dest_path = os.path.join(rel_path) if rel_path != '.' else ''
data_files.append((src_path, dest_path))
return data_files
# 收集所有必要的数据文件--必须包含
datas = []
for package in ['rapidocr', 'omegaconf', 'yaml', 'cnocr', 'cnstd']:
datas.extend(get_package_data(package))
a = Analysis(
['ocr_test.py'],
pathex=[],
binaries=[],
datas=datas,
hiddenimports=[
'cnocr',
'PyQt5',
'cnstd',
'rapidocr',
'omegaconf',
'yaml',
'rapidocr.cal_rec_boxes',
'rapidocr.ch_ppocr_rec',
'rapidocr.inference_engine',
'cnstd.ppocr',
'cnstd.ppocr.rapid_detector',
'PIL',
'PIL.Image',
'numpy',
'torch',
'torchvision',
'cnocr.utils',
'cnocr.recognizer',
],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False,
)
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
exe = EXE(
pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='ocr_test',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=True, # 控制台打印print输出的信息
disable_windowed_traceback=False,
argv_emulation=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None,
)此时待打包目录的文件结构如下:
├── ocr_test.py、ocr_test.spec
└── models/
├── cnocr/
└── cnstd/
进入此目录,执行以下命令,即可完成打包,打包耗时较长(3~5分钟),需要耐心等待
pyinstaller ocr_test.spec打包完成之后,会生成两个目录:build和dist。ocr_test.exe文件在dist目录下,把models目录拷贝到dist目录下,一起打包到新的window客户端安装。
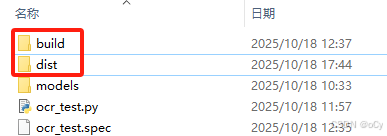

因为代码中检测的是"123.png",可以进入到exe程序目录下运行,运行结果如下图所示:
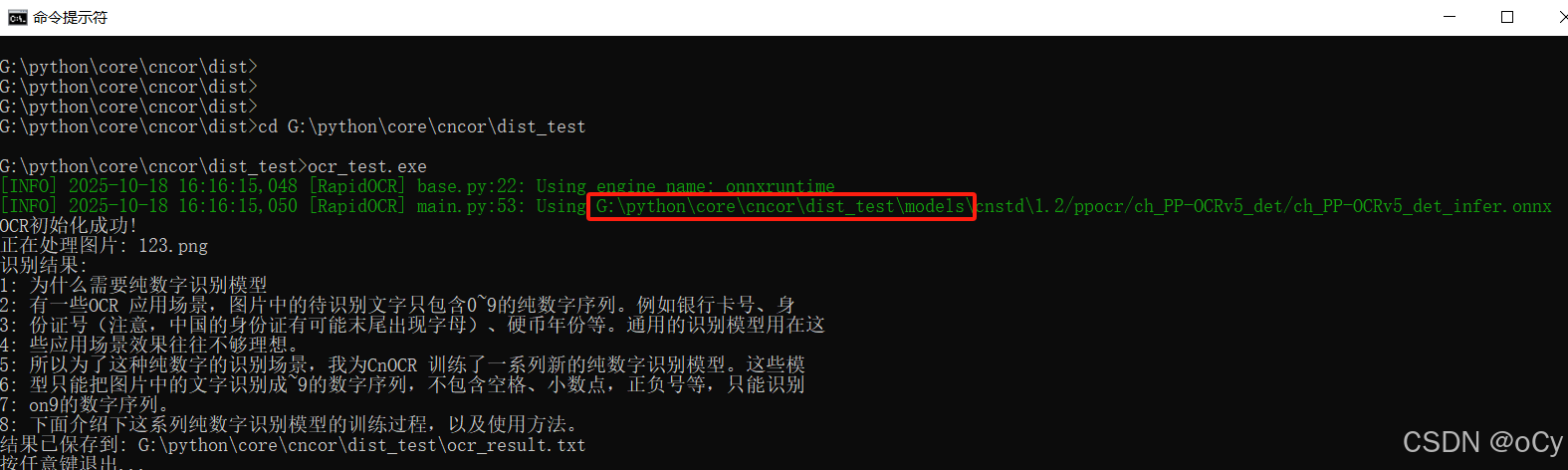
图中标红部分为"G:\python\core\cncor\dist_test\models",说明已经是在读取exe同级目录下的models目录了,至此可以部署在其他window系统中了。
二、不带参数的图像界面exe
python中也有简易的图形界面库pyqt5,与手搓方式的C++ QT很相似,下载方式如下:
pip install PyQt5本应用打包与以上的一样,结构图如下:
├── ocr_tool.py、ocr_tool.spec
└── models/
├── cnocr/
└── cnstd/
如效果图中显示,本界面应用,提供在界面选择图片,可预览图片,然后自动进行中文识别,把结果显示出来,并且提供结果导出功能,方便用于其他用途,ocr_tool.py代码如下:
import sys
import os
import traceback
from PyQt5.QtWidgets import QApplication, QMessageBox
def setup_environment():
"""设置运行环境"""
# 获取当前脚本所在目录的绝对路径
if getattr(sys, 'frozen', False):
# 如果是打包后的exe,使用exe所在目录
script_dir = os.path.dirname(sys.executable)
else:
# 开发环境,使用脚本所在目录
script_dir = os.path.dirname(os.path.abspath(__file__))
# 设置模型根目录(绝对路径)
models_dir = os.path.join(script_dir, "models")
cnocr_dir = os.path.join(models_dir, "cnocr")
cnstd_dir = os.path.join(models_dir, "cnstd")
# 设置环境变量
os.environ["CNOCR_HOME"] = cnocr_dir
os.environ["CNSTD_HOME"] = cnstd_dir
return script_dir, models_dir, cnocr_dir, cnstd_dir
# 设置环境
script_dir, models_dir, cnocr_dir, cnstd_dir = setup_environment()
# 检查模型目录是否存在
if not os.path.exists(models_dir):
print(f"错误: 模型目录不存在: {models_dir}")
print("请确保models目录与程序在同一目录下")
input("按任意键退出...")
sys.exit(1)
# 继续原有的导入
from PyQt5.QtWidgets import (
QApplication, QMainWindow, QPushButton,
QTextEdit, QVBoxLayout, QWidget, QFileDialog,
QHBoxLayout, QLabel, QLineEdit
)
from PyQt5.QtGui import QPixmap
from PyQt5.QtCore import Qt
from cnocr import CnOcr
def init_ocr():
"""初始化OCR引擎,处理打包环境的路径问题"""
try:
ocr = CnOcr(
det_model_name='ch_PP-OCRv5_det',
rec_model_name='densenet_lite_136-gru',
det_model_fp=os.path.join(cnstd_dir, "1.2/ppocr/ch_PP-OCRv5_det/ch_PP-OCRv5_det_infer.onnx"),
rec_model_fp=os.path.join(cnocr_dir, "2.3/densenet_lite_136-gru/cnocr-v2.3-densenet_lite_136-gru-epoch=004-ft-model.onnx")
)
print("OCR初始化成功!")
except Exception as e:
print(f"OCR初始化失败: {e}")
print("请检查模型文件是否完整")
input("按任意键退出...")
sys.exit(1)
return ocr
class OCRApp(QMainWindow):
def __init__(self):
super().__init__()
# 修正:确保方法名一致
self.initUI()
self.ocr = init_ocr()
def initUI(self):
self.setWindowTitle('CnOCR文字识别工具')
self.setGeometry(100, 100, 800, 600)
# 主组件
self.path_edit = QLineEdit()
self.path_edit.setPlaceholderText("图片路径将显示在这里...")
self.path_edit.setReadOnly(True)
self.image_label = QLabel()
self.image_label.setAlignment(Qt.AlignCenter)
self.image_label.setStyleSheet("background-color: #f0f0f0;")
self.image_label.setText("图片预览区域")
self.image_label.setFixedHeight(300)
self.result_text = QTextEdit()
self.result_text.setPlaceholderText("识别结果将显示在这里...")
self.result_text.setReadOnly(True)
# 按钮
self.select_btn = QPushButton("选择图片")
self.select_btn.clicked.connect(self.select_image)
self.export_btn = QPushButton("导出结果")
self.export_btn.clicked.connect(self.export_result)
self.export_btn.setEnabled(False)
# 按钮样式
btn_style = """
QPushButton {
padding: 8px;
min-width: 100px;
background-color: #4CAF50;
color: white;
border-radius: 4px;
}
QPushButton:hover {background-color: #45a049;}
QPushButton:disabled {background-color: #cccccc;}
"""
self.select_btn.setStyleSheet(btn_style)
self.export_btn.setStyleSheet(btn_style)
# 按钮布局
btn_layout = QHBoxLayout()
btn_layout.addWidget(self.select_btn)
btn_layout.addWidget(self.export_btn)
btn_layout.addStretch()
# 主布局
main_layout = QVBoxLayout()
main_layout.addWidget(QLabel("图片路径:"))
main_layout.addWidget(self.path_edit)
main_layout.addLayout(btn_layout)
main_layout.addWidget(QLabel("图片预览:"))
main_layout.addWidget(self.image_label)
main_layout.addWidget(QLabel("识别结果:"))
main_layout.addWidget(self.result_text)
container = QWidget()
container.setLayout(main_layout)
self.setCentralWidget(container)
def select_image(self):
file_path, _ = QFileDialog.getOpenFileName(
self, "选择图片", "", "图片文件 (*.png *.jpg *.jpeg *.bmp)"
)
if file_path:
self.path_edit.setText(file_path)
pixmap = QPixmap(file_path)
self.image_label.setPixmap(
pixmap.scaled(
self.image_label.width(),
self.image_label.height(),
Qt.KeepAspectRatio,
Qt.SmoothTransformation
)
)
results = self.ocr.ocr(file_path)
text_lines = [res['text'] for res in results]
self.result_text.setPlainText('\n'.join(text_lines))
self.export_btn.setEnabled(True)
def export_result(self):
if not self.result_text.toPlainText():
QMessageBox.warning(self, "警告", "没有可导出的识别结果!")
return
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
export_path = os.path.join(desktop_path, "ocr_result.txt")
try:
with open(export_path, 'w', encoding='utf-8') as f:
f.write(self.result_text.toPlainText())
QMessageBox.information(
self,
"导出成功",
f"结果已成功导出到桌面:\n{export_path}"
)
except Exception as e:
QMessageBox.critical(
self,
"导出失败",
f"导出过程中发生错误:\n{str(e)}"
)
if __name__ == '__main__':
try:
app = QApplication(sys.argv)
app.setStyle('Fusion')
ex = OCRApp()
ex.show()
sys.exit(app.exec_())
except Exception as e:
error_msg = traceback.format_exc()
QMessageBox.critical(None, "启动错误", f"程序启动失败:\n\n{error_msg}")
sys.exit(1)以下提供详细配置(.spec配置)方式进行打包,配置代码如下:
# ocr_tool.spec
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
# 获取虚拟环境路径
venv_path = r"D:\python\cnocr_env"
site_packages = os.path.join(venv_path, "Lib", "site-packages")
def get_package_data(package_name):
"""获取包的数据文件"""
package_dir = os.path.join(site_packages, package_name)
if not os.path.exists(package_dir):
return []
data_files = []
for root, dirs, files in os.walk(package_dir):
for file in files:
if file.endswith('.pyc') or '__pycache__' in root:
continue
src_path = os.path.join(root, file)
rel_path = os.path.relpath(root, site_packages)
dest_path = os.path.join(rel_path) if rel_path != '.' else ''
data_files.append((src_path, dest_path))
return data_files
# 收集所有必要的数据文件
datas = []
for package in ['rapidocr', 'omegaconf', 'yaml', 'cnocr', 'cnstd']:
datas.extend(get_package_data(package))
a = Analysis(
['ocr_tool.py'],
pathex=[],
binaries=[],
datas=datas,
hiddenimports=[
'cnocr',
'PyQt5',
'cnstd',
'rapidocr',
'omegaconf',
'yaml',
'rapidocr.cal_rec_boxes',
'rapidocr.ch_ppocr_rec',
'rapidocr.inference_engine',
'cnstd.ppocr',
'cnstd.ppocr.rapid_detector',
'PIL',
'PIL.Image',
'numpy',
'torch',
'torchvision',
'cnocr.utils',
'cnocr.recognizer',
],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False,
)
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
exe = EXE(
pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='ocr_tool',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=False, #这里设置了不显示控制台信息
disable_windowed_traceback=False,
argv_emulation=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None,
)进入打包目录,执行以下命令,即可完成打包,打包耗时较长(3~5分钟),需要耐心等待
pyinstaller ocr_tool.spec打包完成之后,会生成两个目录:build和dist。ocr_tool.exe文件在dist目录下,把models目录拷贝到dist目录下,一起打包到新的window客户端安装,然后手动点击ocr_tool.exe即可运行,但需要注意的是,运行的时间稍微有点长(1~2分钟),主要是加载训练模型,应用界面出来之后,图片识别一半是3~5秒给出结果。
三、带参数的控制台exe
如果是控制台程序,带参数可以更灵活的作为第三方工具使用,而pyinstaller打包带参数的程序时,需要特殊处理,所以这里单拎出来讲解。
本应用打包与以上的一样,结构图如下:
├── ocr_png.py、ocr_png.spec
└── models/
├── cnocr/
└── cnstd/
本工具支持两个参数:图片的路径和识别结果的保存路径。ocr_tool.py代码如下:
import os
import sys
import argparse
from cnocr import CnOcr
def setup_environment():
"""设置运行环境"""
# 获取当前脚本所在目录的绝对路径
if getattr(sys, 'frozen', False):
# 如果是打包后的exe,使用exe所在目录
script_dir = os.path.dirname(sys.executable)
# 设置环境变量,让cnocr能找到数据文件
if hasattr(sys, '_MEIPASS'):
base_path = sys._MEIPASS
# 设置cnocr和cnstd的环境变量
os.environ['CNOCR_HOME'] = os.path.join(script_dir, "models", "cnocr")
os.environ['CNSTD_HOME'] = os.path.join(script_dir, "models", "cnstd")
# 添加包路径到sys.path
for package in ['cnocr', 'cnstd', 'rapidocr']:
package_path = os.path.join(base_path, package)
if os.path.exists(package_path) and package_path not in sys.path:
sys.path.append(package_path)
else:
# 开发环境,使用脚本所在目录
script_dir = os.path.dirname(os.path.abspath(__file__))
return script_dir
def init_ocr():
"""初始化OCR引擎"""
# 设置模型根目录(绝对路径)
script_dir = setup_environment()
models_dir = os.path.join(script_dir, "models")
cnocr_dir = os.path.join(models_dir, "cnocr")
cnstd_dir = os.path.join(models_dir, "cnstd")
# 检查模型目录是否存在
if not os.path.exists(models_dir):
print(f"错误: 模型目录不存在: {models_dir}")
print("请确保models目录与程序在同一目录下")
return None
# 检查必要的模型文件是否存在
required_files = [
os.path.join(cnstd_dir, "1.2/ppocr/ch_PP-OCRv5_det/ch_PP-OCRv5_det_infer.onnx"),
os.path.join(cnocr_dir, "2.3/densenet_lite_136-gru/cnocr-v2.3-densenet_lite_136-gru-epoch=004-ft-model.onnx")
]
for file_path in required_files:
if not os.path.exists(file_path):
print(f"错误: 模型文件不存在: {file_path}")
return None
# 初始化OCR实例
try:
ocr = CnOcr(
det_model_name='ch_PP-OCRv5_det',
rec_model_name='densenet_lite_136-gru',
det_model_fp=required_files[0],
rec_model_fp=required_files[1]
)
print("OCR初始化成功!")
return ocr
except Exception as e:
print(f"OCR初始化失败: {e}")
print("请检查模型文件是否完整")
return None
def process_image(ocr, image_path, output_path=None):
"""处理图片并保存识别结果"""
if not os.path.exists(image_path):
print(f"错误: 图片文件不存在: {image_path}")
return False
try:
print(f"正在处理图片: {image_path}")
results = ocr.ocr(image_path)
texts = [res['text'] for res in results]
# 打印识别结果
print("识别结果:")
for i, text in enumerate(texts, 1):
print(f"{i}: {text}")
# 确定输出文件路径
if output_path is None:
script_dir = setup_environment()
output_path = os.path.join(script_dir, 'ocr_result.txt')
# 确保输出目录存在
output_dir = os.path.dirname(output_path)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
# 保存结果
with open(output_path, 'w', encoding='utf-8') as f:
for text in texts:
f.write(text + '\n')
print(f"结果已保存到: {output_path}")
return True
except Exception as e:
print(f"处理图片时出错: {e}")
return False
def main():
"""主函数,处理命令行参数"""
parser = argparse.ArgumentParser(description='OCR文字识别工具')
parser.add_argument('image_path', nargs='?', help='要识别的图片路径')
parser.add_argument('output_path', nargs='?', help='结果输出文件路径(可选)')
# 解析命令行参数
args = parser.parse_args()
# 初始化OCR
ocr = init_ocr()
if ocr is None:
input("按任意键退出...")
sys.exit(1)
# 处理图片
if args.image_path:
# 使用命令行参数
success = process_image(ocr, args.image_path, args.output_path)
if not success:
input("按任意键退出...")
sys.exit(1)
else:
# 没有参数,使用默认图片
script_dir = setup_environment()
default_image = os.path.join(script_dir, '123.png')
if os.path.exists(default_image):
success = process_image(ocr, default_image)
if not success:
input("按任意键退出...")
sys.exit(1)
else:
print("使用方法:")
print(" ocr_png.exe <图片路径> [输出文件路径]")
print("")
print("示例:")
print(" ocr_png.exe C:\\images\\test.png C:\\results\\output.txt")
print(" ocr_png.exe test.png (结果将保存为ocr_result.txt)")
print("")
print("如果没有参数,将尝试处理同目录下的123.png文件")
input("按任意键退出...")
if __name__ == '__main__':
main()以下提供详细配置(.spec配置)方式进行打包,配置代码如下:
# ocr_png.spec
# -*- mode: python ; coding: utf-8 -*-
import os
import sys
block_cipher = None
# 获取虚拟环境路径
venv_path = r"D:\python\cnocr_env"
site_packages = os.path.join(venv_path, "Lib", "site-packages")
def get_package_data(package_name):
"""获取包的数据文件"""
package_dir = os.path.join(site_packages, package_name)
if not os.path.exists(package_dir):
return []
data_files = []
for root, dirs, files in os.walk(package_dir):
for file in files:
# 排除不必要的文件
if file.endswith('.pyc') or '__pycache__' in root:
continue
src_path = os.path.join(root, file)
# 计算相对路径
rel_path = os.path.relpath(root, site_packages)
dest_path = os.path.join(rel_path) if rel_path != '.' else ''
data_files.append((src_path, dest_path))
return data_files
# 收集所有必要的数据文件
datas = []
essential_packages = ['rapidocr', 'omegaconf', 'yaml', 'cnocr', 'cnstd']
for package in essential_packages:
package_files = get_package_data(package)
if package_files:
datas.extend(package_files)
print(f"已添加 {len(package_files)} 个 {package} 文件")
else:
print(f"警告: 未找到 {package} 包的数据文件")
# 手动添加可能缺失的关键文件
def add_critical_files():
"""手动添加关键文件"""
critical_files = []
# 查找 cnocr 目录中的 label_cn.txt
cnocr_path = os.path.join(site_packages, 'cnocr')
if os.path.exists(cnocr_path):
label_file = os.path.join(cnocr_path, 'label_cn.txt')
if os.path.exists(label_file):
critical_files.append((label_file, 'cnocr'))
print("已添加 label_cn.txt")
# 查找 rapidocr 目录中的 default_models.yaml
rapidocr_path = os.path.join(site_packages, 'rapidocr')
if os.path.exists(rapidocr_path):
default_models = os.path.join(rapidocr_path, 'default_models.yaml')
if os.path.exists(default_models):
critical_files.append((default_models, 'rapidocr'))
print("已添加 default_models.yaml")
return critical_files
# 添加关键文件
critical_files = add_critical_files()
datas.extend(critical_files)
hidden_imports = [
'cnocr',
'cnstd',
'rapidocr',
'omegaconf',
'yaml',
'argparse',
'rapidocr.cal_rec_boxes',
'rapidocr.ch_ppocr_rec',
'rapidocr.inference_engine',
'cnstd.ppocr',
'cnstd.ppocr.rapid_detector',
'PIL',
'PIL.Image',
'numpy',
'torch',
'torchvision',
'cnocr.utils',
'cnocr.recognizer',
'onnxruntime',
]
a = Analysis(
['ocr_png.py'],
pathex=[],
binaries=[],
datas=datas,
hiddenimports=hidden_imports,
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False,
)
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)
exe = EXE(
pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='ocr_png',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=True, # 使用控制台以便查看输出
disable_windowed_traceback=False,
argv_emulation=False,
target_arch=None,
codesign_identity=None,
entitlements_file=None,
)进入打包目录,执行以下命令,即可完成打包,打包耗时较长(3~5分钟),需要耐心等待
pyinstaller ocr_png.spec打包完成之后,会生成两个目录:build和dist。ocr_png.exe文件在dist目录下,把models目录拷贝到dist目录下,一起打包到新的window客户端安装,可以进入到exe程序目录下运行,运行结果如下图所示:
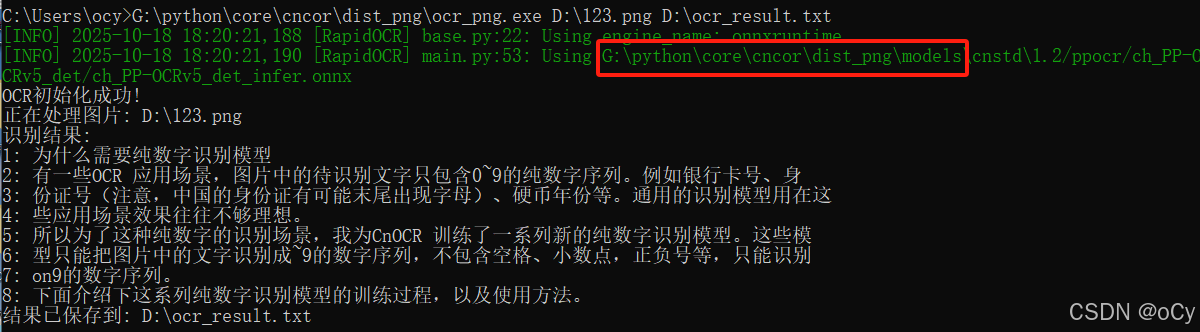
图中标红部分为"G:\python\core\cncor\dist_test\models",说明已经是在读取exe同级目录下的models目录了,至此可以部署在其他window系统中了。
结尾
以上python打包的exe很大,有两百多M,如果不用虚拟环境会更加大,整体来说控制台程序首次启动后15秒内执行完成,而pyqt的界面需要1~2分钟左右,建议可以考虑用C++ QT调用控制台程序的组合方式来部署。