
空间感知3D查找表 : LUT-Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables(2021 CVPR)
- 专题介绍
- 一、研究背景
- [二、Learnable Spatial-aware 3DLUT方法](#二、Learnable Spatial-aware 3DLUT方法)
-
- [2.1 Spatial-aware 3D LUTs](#2.1 Spatial-aware 3D LUTs)
- [2.2 Self-adaptive two-head weight predictor](#2.2 Self-adaptive two-head weight predictor)
- [2.3 Spatial-aware trilinear interpolation and loss Function](#2.3 Spatial-aware trilinear interpolation and loss Function)
- 三、实验结果
- 四、总结
本文将围绕《SA-3DLUT:LUT-Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables》展开完整解析。该论文提出一种基于可学习空间感知 3D 查找表(3D LUTs) 的实时图像增强模型,通过轻量级双头权重预测器(输出 1D 权重向量用于图像级场景适配、3D 权重图用于像素级类别融合),结合空间感知 3D LUTs 的端到端融合,在保证增强效果的同时提升效率;模型在 MIT-Adobe FiveK 和 HDR + 公开数据集上,主观与客观性能均优于现有 SOTA 方法,在 NVIDIA V100 GPU 上处理 4K 分辨率图像仅需约4ms,且通过消融实验验证了双头权重预测器、多损失函数(MSE Loss、颜色差异损失、感知损失等)的有效性。参考资料如下:
1. 论文地址
专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理 的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流,对该专题感兴趣的读者可以订阅本专栏第一时间看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
【8】Tiny-LUT
【9】3D-LUT
【10】4D-LUT
【11】AdaInt-LUT
【12】Sep-LUT
【13】CLUT
【14】ICELUT
【15】AutoLUT
一、研究背景
该篇文章优化的是原始的3D-LUT,原始的3DLUT方法通过图像特征输出一个LUT加权的系数,使用融合的LUT对原始图像进行增强,弊端在于仅依赖像素值,忽略局部空间信息,易产生局部对比度低、颜色失真、伪影等问题,如下图所示。

上图中3DLUT的背景颜色饱和度欠缺。

上图中3DLUT的红框区域的局部效果不佳。
但是如果使用一些常规的CNN复杂架构对图像增强,会导致计算开销高,难以实时处理高分辨率(如 4K)图像。
基于此,作者希望能够进一步提升3DLUT性能,设计兼顾视觉感知效果(全局场景 + 局部空间信息)与计算效率(实时处理高分辨率图像)的图像增强模型。
二、Learnable Spatial-aware 3DLUT方法
模型由Spatial-aware 3D LUTs(空间感知 3D LUTs)、Self-adaptive two-head weight predictor(双头权重预测器)、Spatial-aware trilinear interpolation(空间感知三线性插值)三部分构成,流程如图所示:
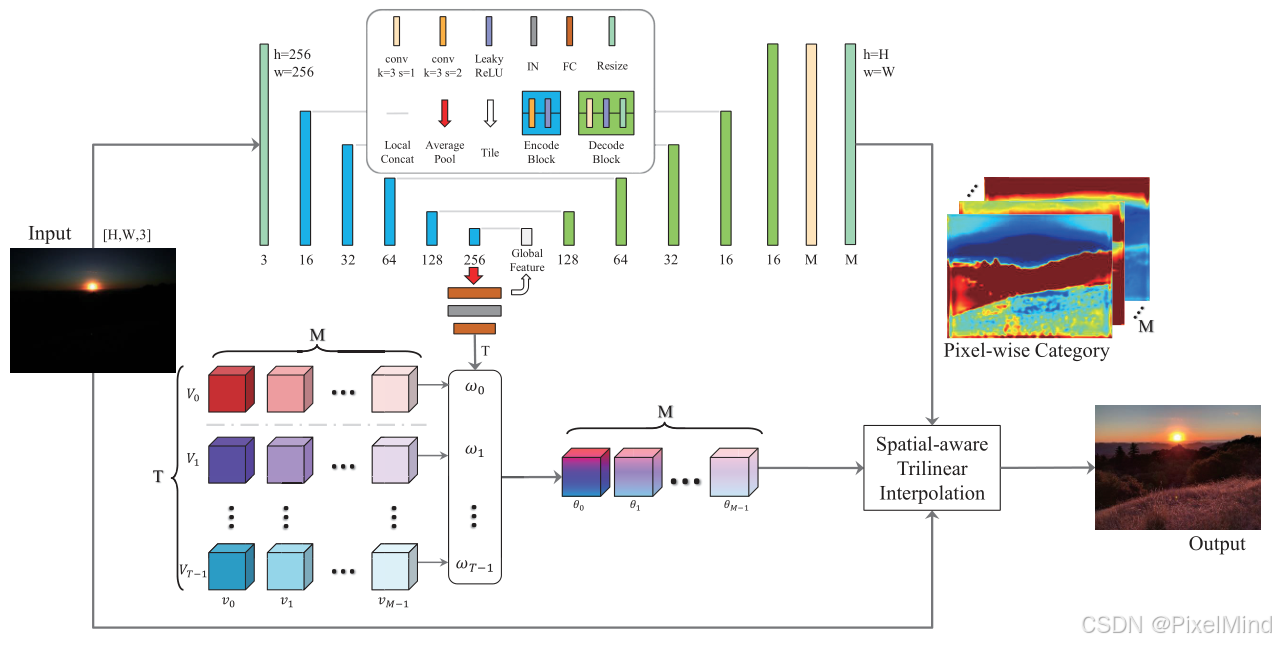
包含以下三步:
- 双头权重预测器对下采样图像处理,输出两类权重,对应着最上面的UNet输出的Pixel-wise Category M空间权重以及白色框中 w 0 w_0 w0到 w T − 1 w_{T-1} wT−1的T个图像LUT权重。
- T个图像LUT权重对 M ∗ T M*T M∗T的LUT矩阵进行加权,得到加权后的 M M M个场景向量预测权重的LUT,此与3DLUT的过程是近似的。
- 对个M个不同的场景LUT使用Pixel-wise Category M空间权重进行空间感知的3D插值将源图像转换为目标色调。
2.1 Spatial-aware 3D LUTs
传统的3DLUT插值公式如下所示: O ( i , j , k ) c = μ c ( I ( i , j , k ) r , I ( i , j , k ) g , I ( i , j , k ) b ) O_{(i,j,k)}^{c} = \mu ^{c}(I_{(i,j,k)}^{r}, I_{(i,j,k)}^{g}, I_{(i,j,k)}^{b}) O(i,j,k)c=μc(I(i,j,k)r,I(i,j,k)g,I(i,j,k)b)其中, O c O^c Oc为3D LUT在颜色通道 c , c ∈ r , g , b c,c∈{r,g,b} c,c∈r,g,b的输出, μ c ( i , j , k ) μ^c(i,j,k) μc(i,j,k)为像素映射函数, I ( i , j , k ) ( r / g / b ) I^{(r/g/b)}_{(i,j,k)} I(i,j,k)(r/g/b)为输入RGB值, i , j , k ∈ I 0 ( N − 1 ) i,j,k∈I₀^{(N-1)} i,j,k∈I0(N−1)(N为每个颜色通道的bin数量)。为了引入空间感知能力,作者使用了如下的结构:
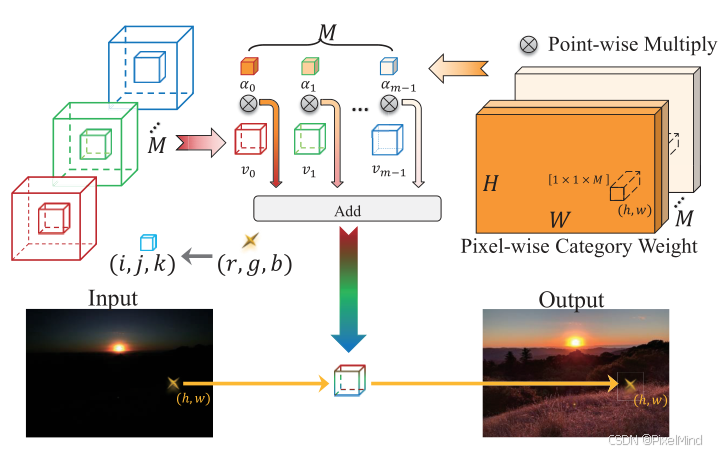
通过M个不同的3DLUT搭配Pixel-wise Category Weight(H,W,M)大小的权重对其进行加权完成一个合并后的LUT对图像进行处理,公式如下: O ( i , j , k ) h , w , c = ϕ h , w , c ( I ( i , j , k ) r , I ( i , j , k ) g , I ( i , j , k ) b , α h , w ) = ∑ m = 0 M − 1 α m h , w ν c ( I ( i , j , k ) r , I ( i , j , k ) g , I ( i , j , k ) b , m ) = ∑ m = 0 M − 1 α m h , w O ( i , j , k ) m , c \begin{aligned} O_{(i, j, k)}^{h, w, c} &= \phi^{h, w, c}\left(I_{(i, j, k)}^{r}, I_{(i, j, k)}^{g}, I_{(i, j, k)}^{b}, \alpha^{h, w}\right) \\ &= \sum_{m=0}^{M-1} \alpha_{m}^{h, w} \nu^{c}\left(I_{(i, j, k)}^{r}, I_{(i, j, k)}^{g}, I_{(i, j, k)}^{b}, m\right) \\ &= \sum_{m=0}^{M-1} \alpha_{m}^{h, w} O_{(i, j, k)}^{m, c} \end{aligned} O(i,j,k)h,w,c=ϕh,w,c(I(i,j,k)r,I(i,j,k)g,I(i,j,k)b,αh,w)=m=0∑M−1αmh,wνc(I(i,j,k)r,I(i,j,k)g,I(i,j,k)b,m)=m=0∑M−1αmh,wO(i,j,k)m,c其中, O ( i , j , k ) ( h , w , c ) O^{(h,w,c)}{(i,j,k)} O(i,j,k)(h,w,c)为最终空间感知增强结果, ϕ ( h , w , c ) \phi^{(h,w,c)} ϕ(h,w,c)为整体映射函数, α ( h , w ) α^{(h,w)} α(h,w)为像素级权重图(H、W为图像高宽,M为基础3D LUT数量), ν c ν^c νc为第m个基础LUT映射函数, O ( i , j , k ) ( m , c ) O^{(m,c)}{(i,j,k)} O(i,j,k)(m,c)为第m个基础LUT映射结果。
显然,通过上述公式可以引入空间感知增强的效果。
2.2 Self-adaptive two-head weight predictor
整体基于 UNet 风格骨干网络,输入为下采样低分辨率图像(支持任意尺寸图像实时处理,扩大感受野),如下:
两个输出分别是:
- 1D 权重向量 :含 T 个概率(实验中 T=3),用于图像级场景适配,融合 T 组空间感知 3D LUT,公式如下所示: Y = ∑ t = 0 T − 1 ω t ⋅ V t ( X , A ) Y = \sum_{t=0}^{T-1} \omega_{t} \cdot V_{t}(X, A) Y=t=0∑T−1ωt⋅Vt(X,A)其中,Y为最终增强图像, ω t ω_t ωt为1D权重向量中第t个场景概率(实验中T=3), V t ( X , A ) V_t(X,A) Vt(X,A)为第t组空间感知3D LUT对输入图像 X X X的映射结果, A A A为像素级类别信息。
- 3D 权重图:尺寸为 H×W×M,含像素级类别信息,用于像素级类别融合,提升局部对比度与饱和度,对应前面讲到的模块。
2.3 Spatial-aware trilinear interpolation and loss Function
通过定制 CUDA 代码实现高效计算,降低高分辨率图像处理耗时,可解决传统插值忽略空间信息的问题,提升增强结果平滑度,相当于对前面模块的工程实现。
损失函数包含几个部分:
- MSE Loss:保证生成图像与 GT 的内容一致性,此在3DLUT一样。
- Smooth Loss:确保 3D LUT 的平滑性,减少伪影,此在3DLUT一样。
- Monotonicity Loss:单调性损失,防止出现反转,此在3DLUT一样。
- Color Difference Loss:使增强图像颜色匹配 GT,公式如下: L c = Δ L 2 + ( Δ C S C ) 2 + ( Δ H S H ) 2 + ϵ L_{c} = \sqrt{\Delta L^{2} + \left(\frac{\Delta C}{S_{C}}\right)^{2} + \left(\frac{\Delta H}{S_{H}}\right)^{2} + \epsilon} Lc=ΔL2+(SCΔC)2+(SHΔH)2+ϵ 其中, Δ L ΔL ΔL为亮度差异, Δ C ΔC ΔC为彩度差异, Δ H ΔH ΔH为色相差异, S C S_C SC、 S H S_H SH为校正因子, ϵ \epsilon ϵ为极小值(避免根号内为负)。
- Perception Loss:提升图像的感知质量(如细节清晰度),公式如下: L p = ∑ l 1 H l W l ∑ h = 1 , w = 1 H l , W l ∥ y ^ h w l − y h w l ∥ 2 2 L_{p} = \sum_{l} \frac{1}{H^{l} W^{l}} \sum_{h=1, w=1}^{H^{l}, W^{l}} \left\| \hat{y}{h w}^{l} - y{h w}^{l} \right\| {2}^{2} Lp=l∑HlWl1h=1,w=1∑Hl,Wl y^hwl−yhwl 22其中, l l l为计算LPIPS损失的网络层, H l 、 W l H^l、W^l Hl、Wl为第 l l l层特征图高宽, y ^ ( h w ) ( l ) ŷ^{(l)}{(hw)} y^(hw)(l)为增强图像第 l l l层特征, y ( h w ) ( l ) y^{(l)}_{(hw)} y(hw)(l)为Ground Truth第 l l l层特征。
最后可以得到总的损失函数 L = L r + 0.0001 ⋅ L s + 10 ⋅ L m + 0.005 ⋅ L c + 0.05 ⋅ L p L = L_{r} + 0.0001 \cdot L_{s} + 10 \cdot L_{m} + 0.005 \cdot L_{c} + 0.05 \cdot L_{p} L=Lr+0.0001⋅Ls+10⋅Lm+0.005⋅Lc+0.05⋅Lp其中, L r 、 L s 、 L m 、 L c 、 L p L_{r}、L_{s} 、L_{m}、L_{c}、L_{p} Lr、Ls、Lm、Lc、Lp分别代表MSE损失,平滑损失,单调性损失,颜色损失以及感知损失。
三、实验结果
首先讲一下消融实验。
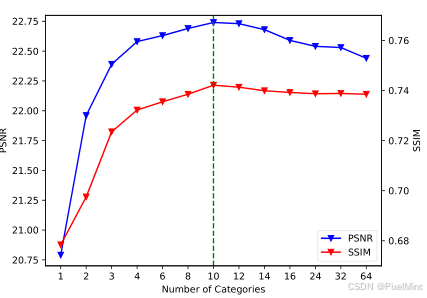
- 类别数目 M M M :M 从 1 增至 10 时,PSNR 与 SSIM 显著提升;M>10 时,性能趋于平稳甚至下降;最终选择10。
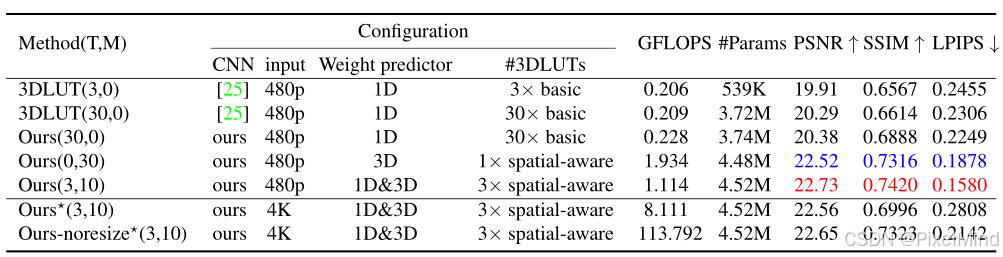
- 双头权重预测器 :单独 1D 或 3D 权重预测器效果有限,1D+3D 组合(Ours (3,10))效果最优,较原始 3DLUT (3,0) 提升 2.82dB PSNR;处理 4K 图像时,仅 0.17dB PSNR 下降,效率高。
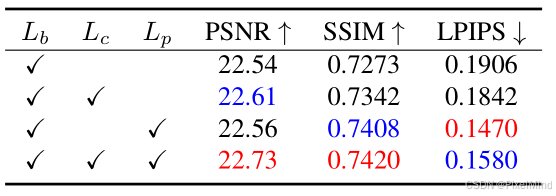
- 损失函数 :仅用基础损失效果不好,需要组合所有损失,验证了颜色与感知损失的必要性。

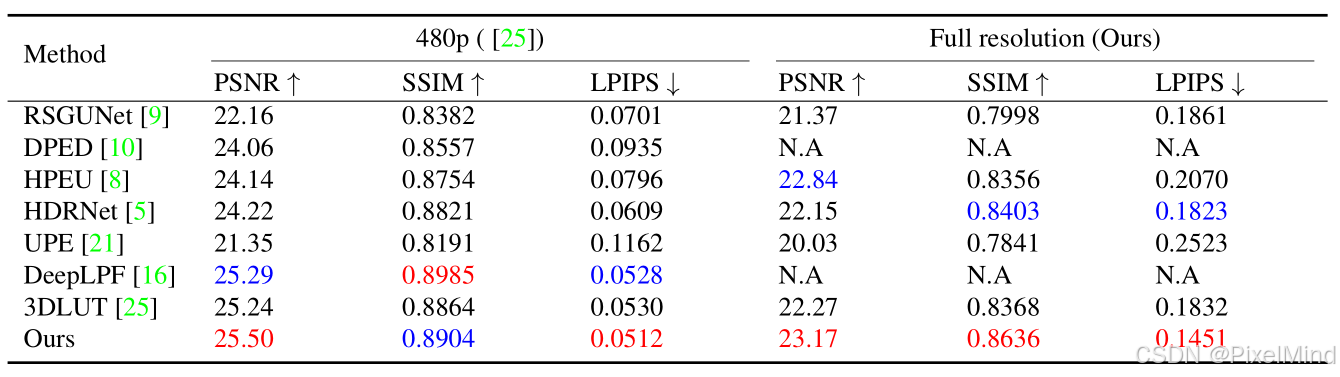
接着是定量实验 。
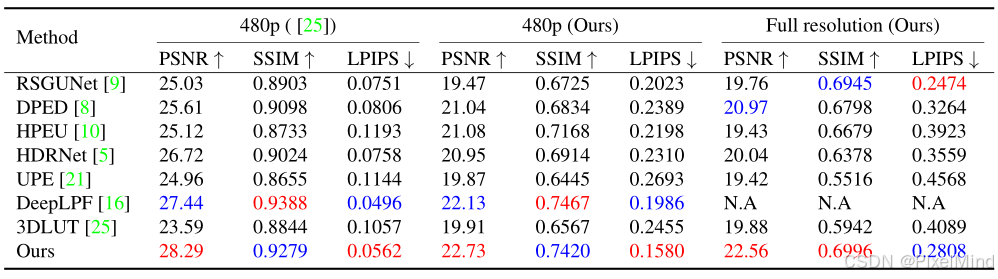
结论:
- MIT-Adobe FiveK 数据集:模型在全分辨率下 PSNR 达 23.17dB、SSIM 达 0.8636、LPIPS 达 0.1451,优于 3DLUT 25、HDRNet 等方法,仅 480p SSIM 略低于 DeepLPF(差距 < 1%),但 DeepLPF 无法处理全分辨率图像;
- HDR + 数据集:480p 下 PSNR 达 22.73dB(较第二优 DeepLPF 高 0.6dB),全分辨率下 PSNR 达 22.56dB(较第二优 3DLUT 高 2.68dB),LPIPS 均为最低。
整体效果更有优势。
然后是定性实验 。


效果有优势,模型增强结果颜色更接近 GT、细节更清晰。
最后作者对比了实际的推理性能:
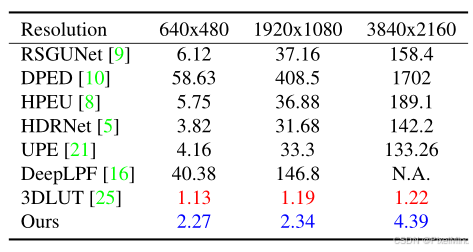
推理实时,相较3DLUT增加的推理成本不大。
四、总结
该论文提出空间感知 3D LUTs 架构,结合双头权重预测器,首次在 3D LUT 方法中融入局部空间信息,解决传统方法局部增强不足的问题,在公开数据集上验证了效果和性能,可惜没有开源,且在一些算力吃紧的场合下相较3DLUT还是增加了不少推理成本。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。