提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- [1. 图像特征harris](#1. 图像特征harris)
-
- [1.1 角点检测基本原理](#1.1 角点检测基本原理)
- [1.2 原理](#1.2 原理)
- [1.3 使用](#1.3 使用)
- [2. 图像特征-sift](#2. 图像特征-sift)
-
- [2.1 原理](#2.1 原理)
- [2.2 使用](#2.2 使用)
- [3 特征匹配](#3 特征匹配)
-
- [3.1 Brute-Force蛮力匹配](#3.1 Brute-Force蛮力匹配)
- [3.2 1对1的匹配](#3.2 1对1的匹配)
- [3.3 k对最佳匹配](#3.3 k对最佳匹配)
- [4. 样例实战-图像全景拼接](#4. 样例实战-图像全景拼接)
-
- [4.1 流程解读](#4.1 流程解读)
- [5. 答题卡识别判卷](#5. 答题卡识别判卷)
- 总结
前言
1. 图像特征harris
1.1 角点检测基本原理
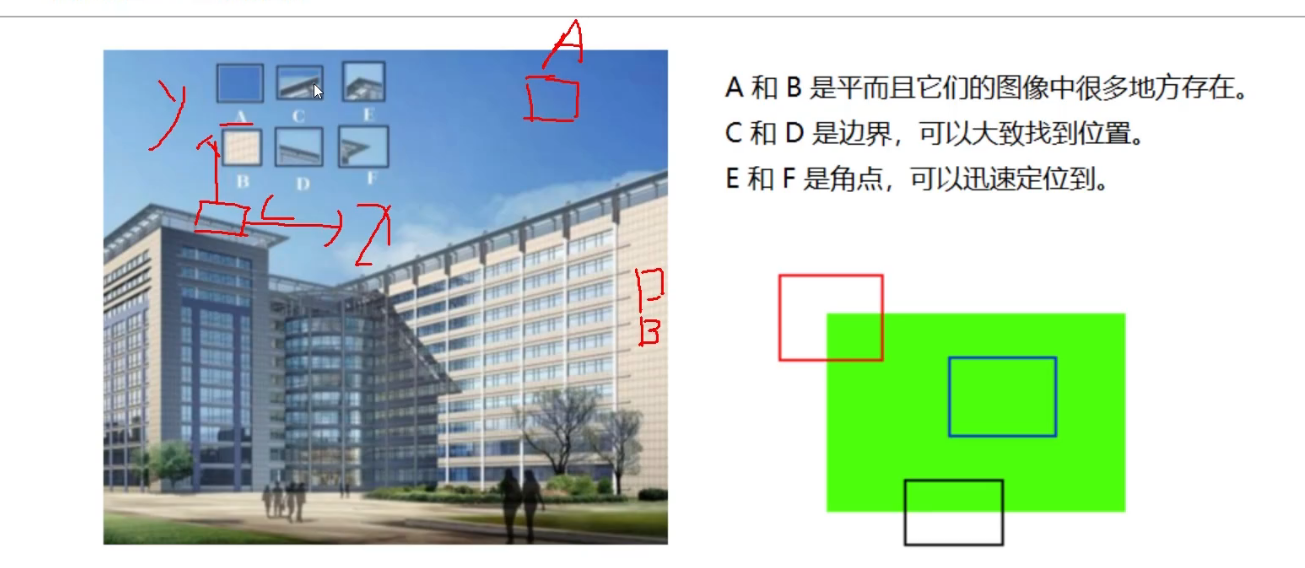
边界:沿着一个方向变化明显,另一个竖直方向变化不明显
角点:水平竖直方向都变化明显
角点特征更加明显
1.2 原理
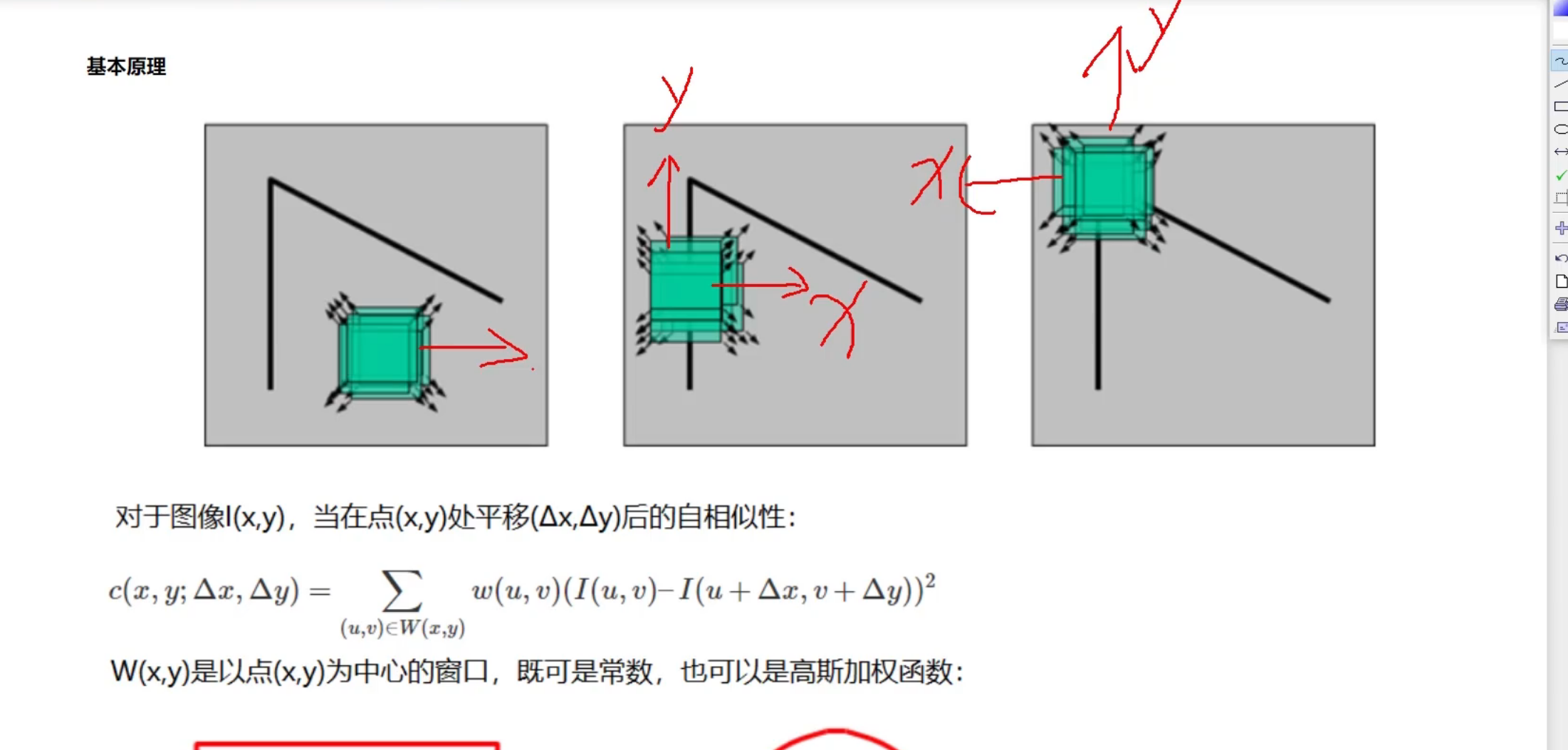
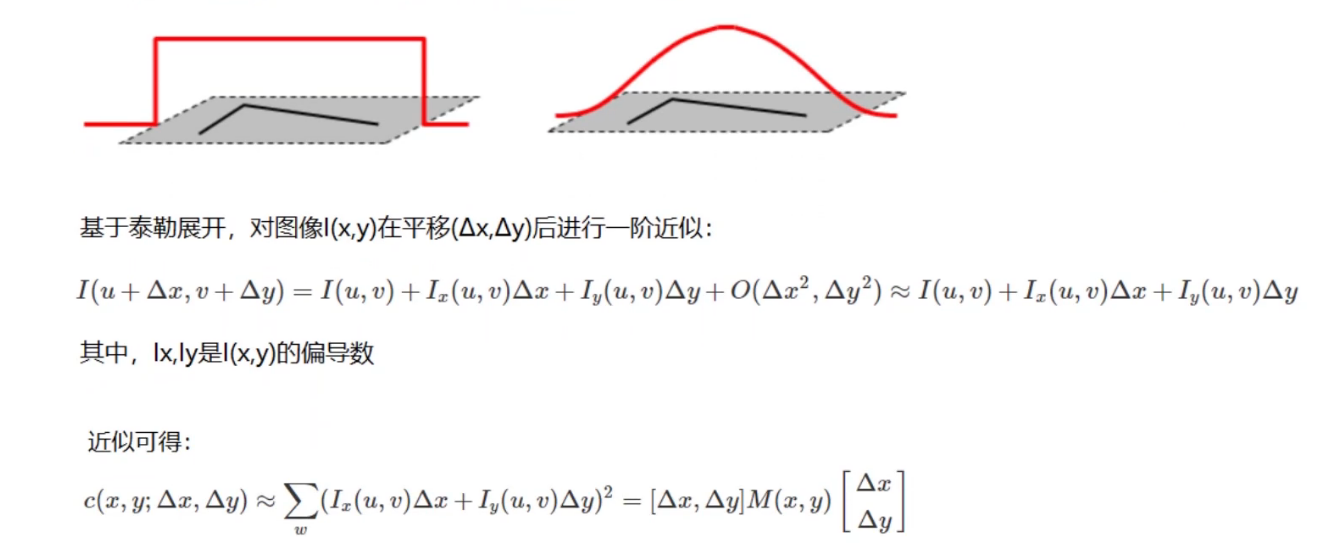

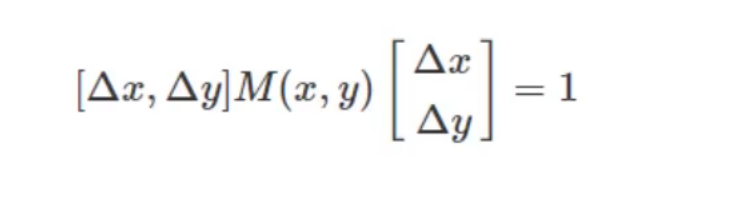
最后就是看水平和竖直的变化率了
1.3 使用
java
cv2.cornerHarris()
img: 数据类型为 float32 的入图像
blockSize: 角点检测中指定区域的大小
ksize: Sobel求导中使用的窗口大小,一般为3
k: 取值参数为 [0,04,0.06],一般就用0.04
java
import cv2
import numpy as np
img = cv2.imread('../chessboard.jpg')
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print ('dst.shape:',dst.shape)
因为dst算出来的也是每个点的变换率,所以是512大小的
java
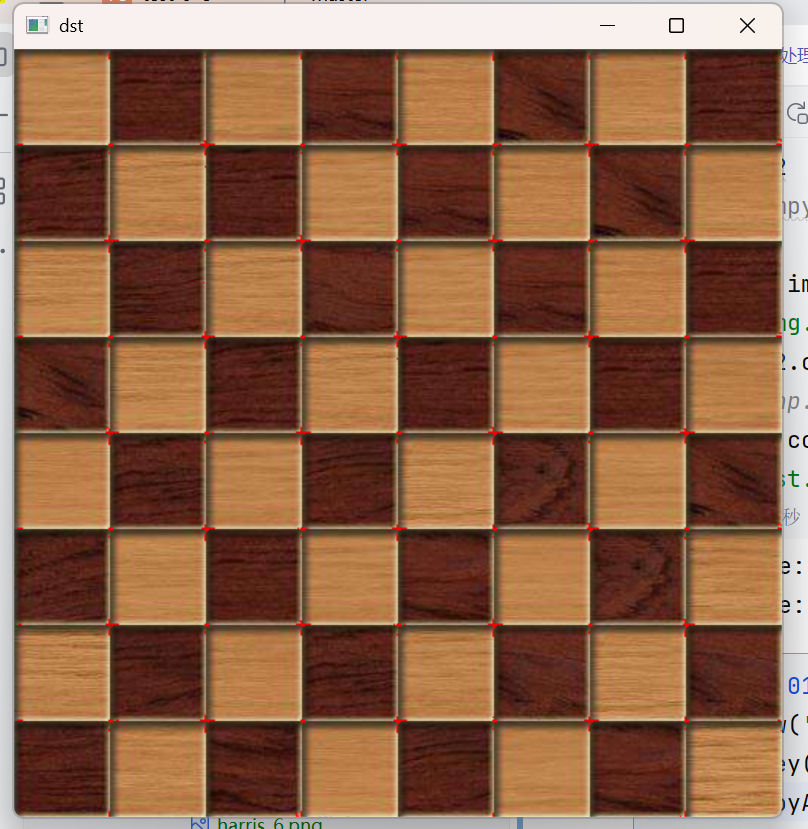
img[dst>0.01*dst.max()]=[0,0,255]
cv2.imshow('dst',img)
cv2.waitKey(0)
cv2.destroyAllWindows()0,0,255是红色
把dst>0.01*dst.max()的点变为红色---》可能为角点

2. 图像特征-sift
SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)是一种经典的图像局部特征提取算法,核心优势是能在图像尺度缩放、旋转、光照变化甚至部分遮挡的情况下,稳定提取出具有唯一性的局部特征点,为图像匹配、目标识别、图像拼接等计算机视觉任务提供关键支持。
2.1 原理
在一定的范围内,无论物体是大还是小,人眼都可以分辨出来,然而计算机要有相同的能力却很难,所以要让机器能够对物体在不同尺度下有一个统一的认知,就需要考虑图像在不同的尺度下都存在的特点。
尺度空间的获取通常使用高斯模糊来实现:使用高斯滤波就可以变得越来越模糊
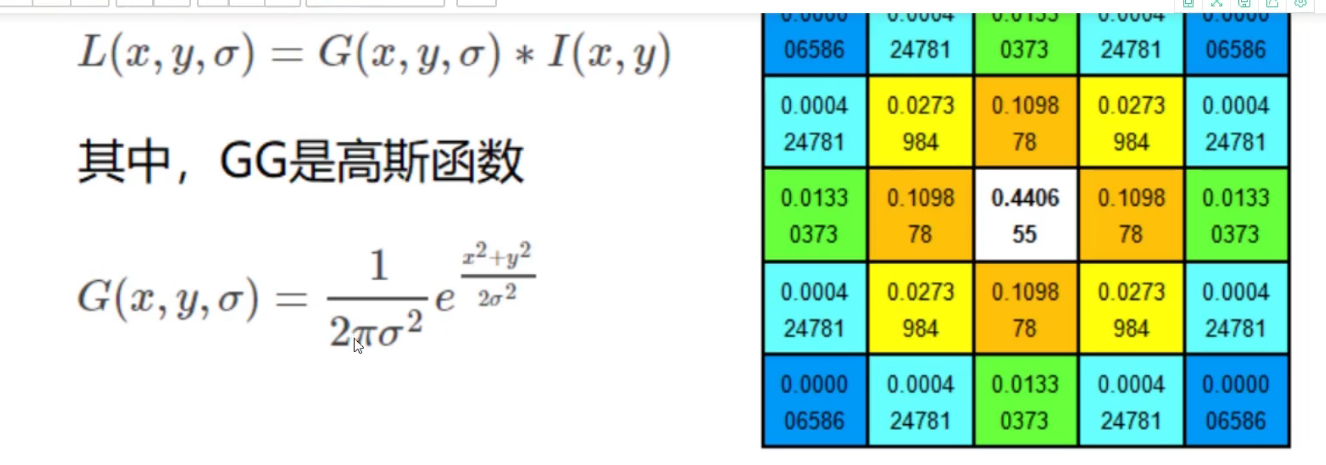

不同σ的高斯函数决定了对图像的平滑程度,越大的σ值对应的图像越模糊。
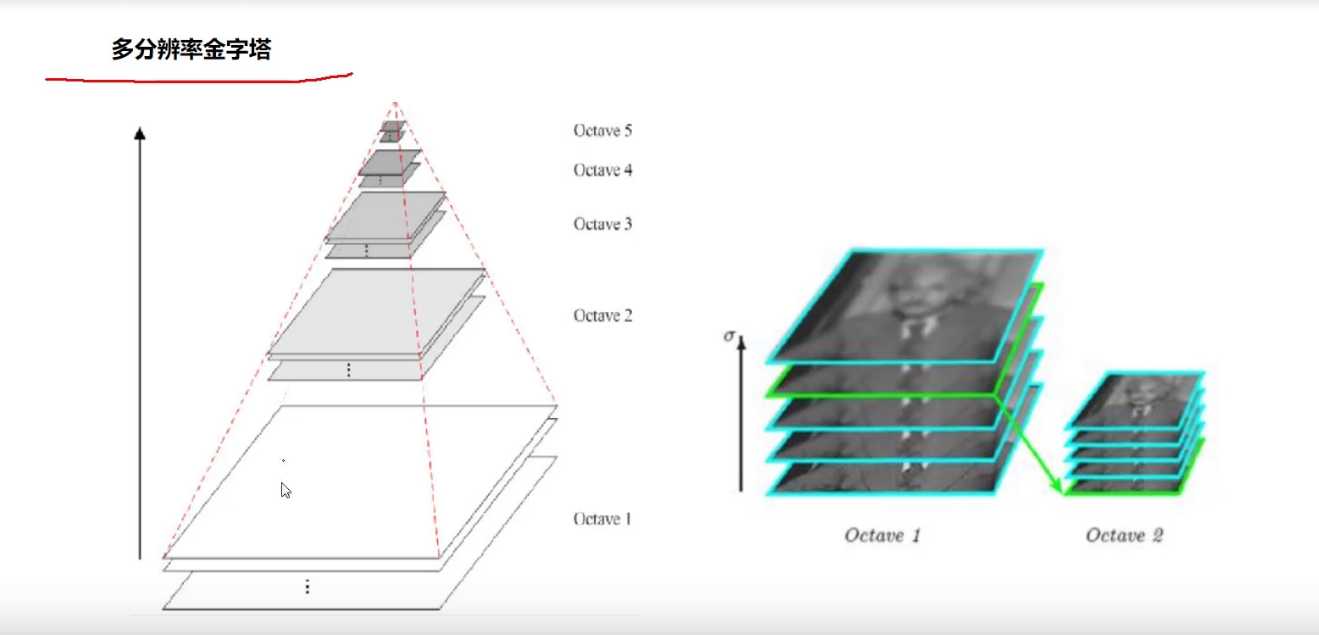
对每一层都进行高斯滤波
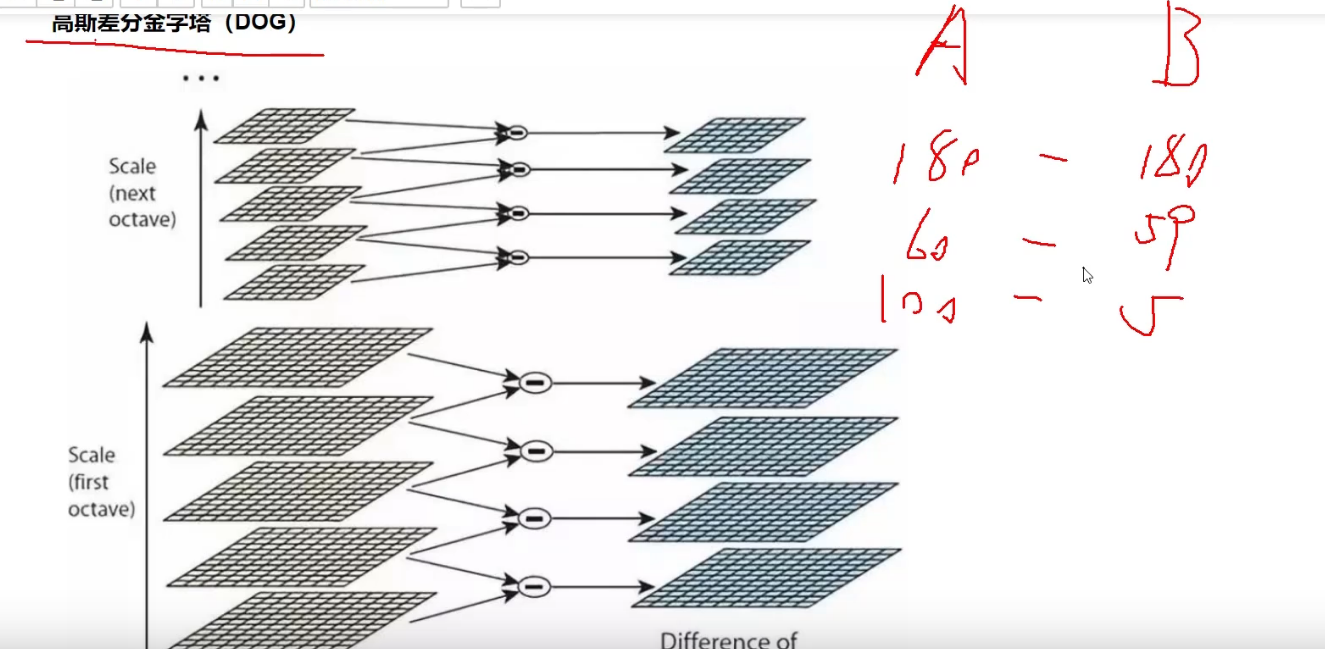
每相邻进行高斯滤波的进行差分
差值比较大的说明特征比较明显
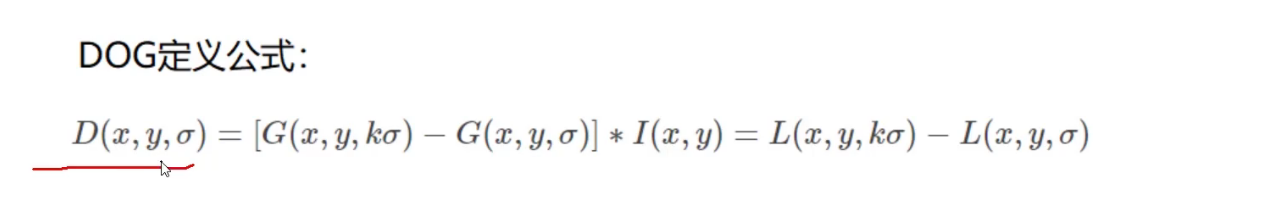
第三个参数是高斯滤波的参数
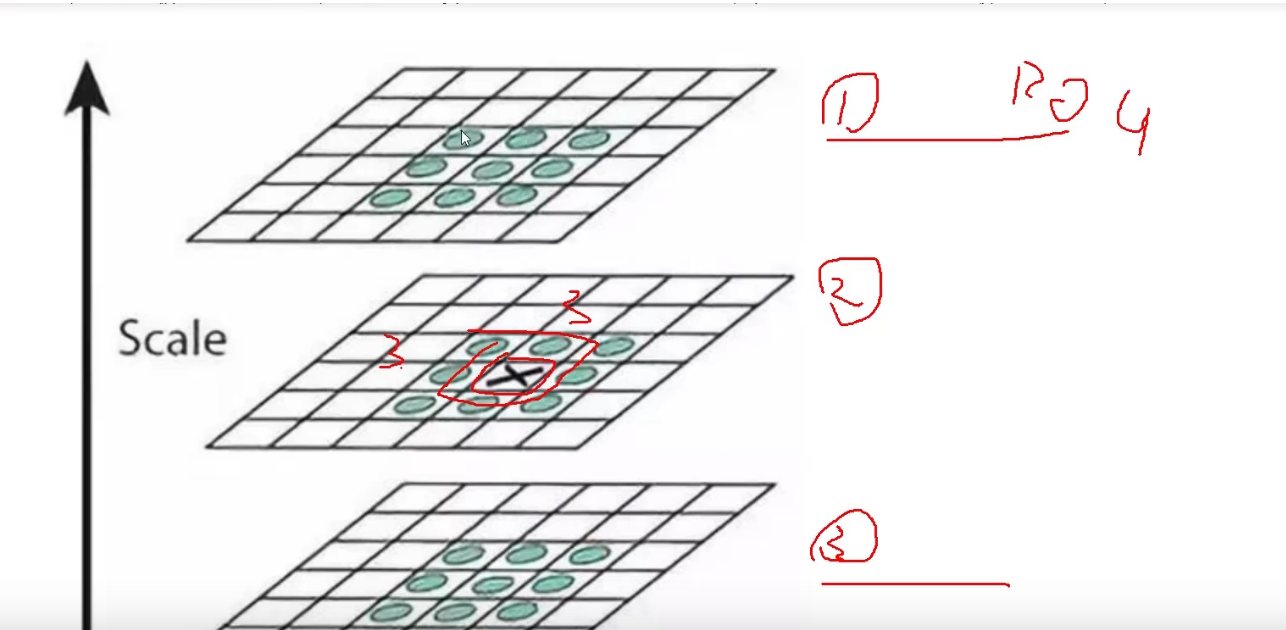
DoG空间极值检测
为了寻找尺度空间的极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。如下图所示,中间的检测点要和其所在图像的3×3邻域8个像素点,以及其相邻的上下两层的3×3领域18个像素点,共26个像素点进行比较。
不仅要和周围3*3进行比较,还要和上下层进行比较
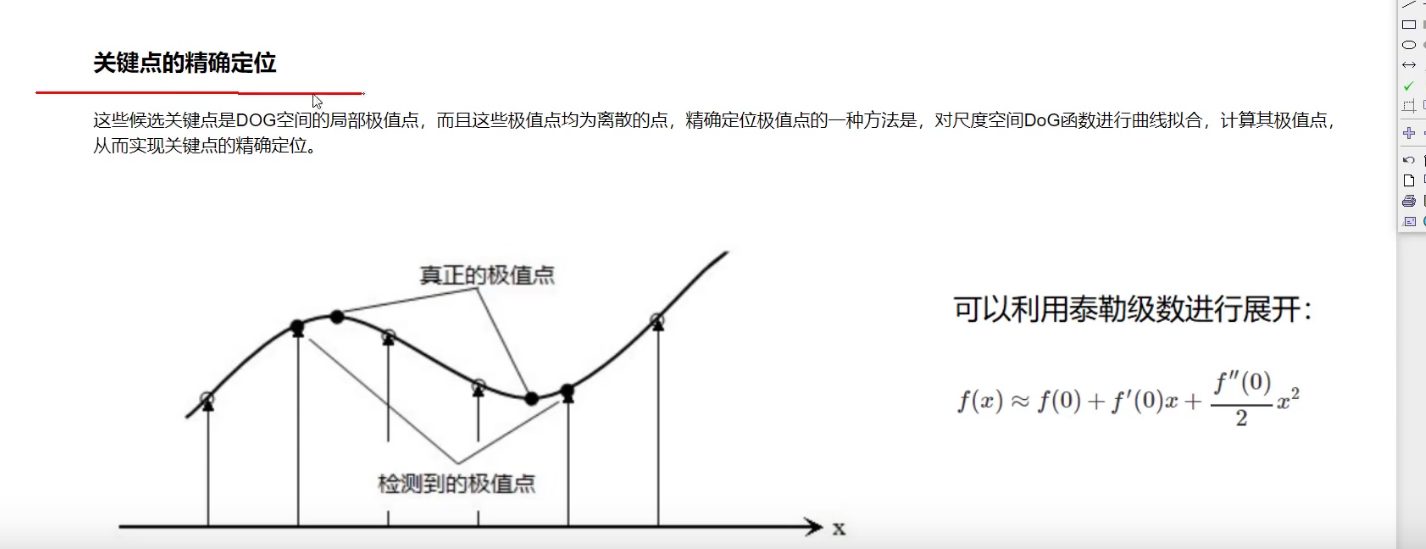
这些候选关键点是DOG空间的局部极值点,而且这些极值点均为离散的点,精确定位极值点的一种方法是,对尺度空间DoG函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
估计出来的极值点可能不是真正极值点,所以要根据这些估计点,算出真实点的极值点
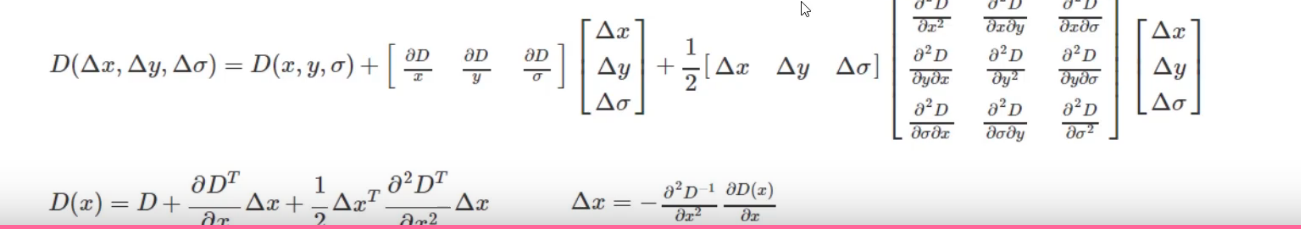
消除边界响应
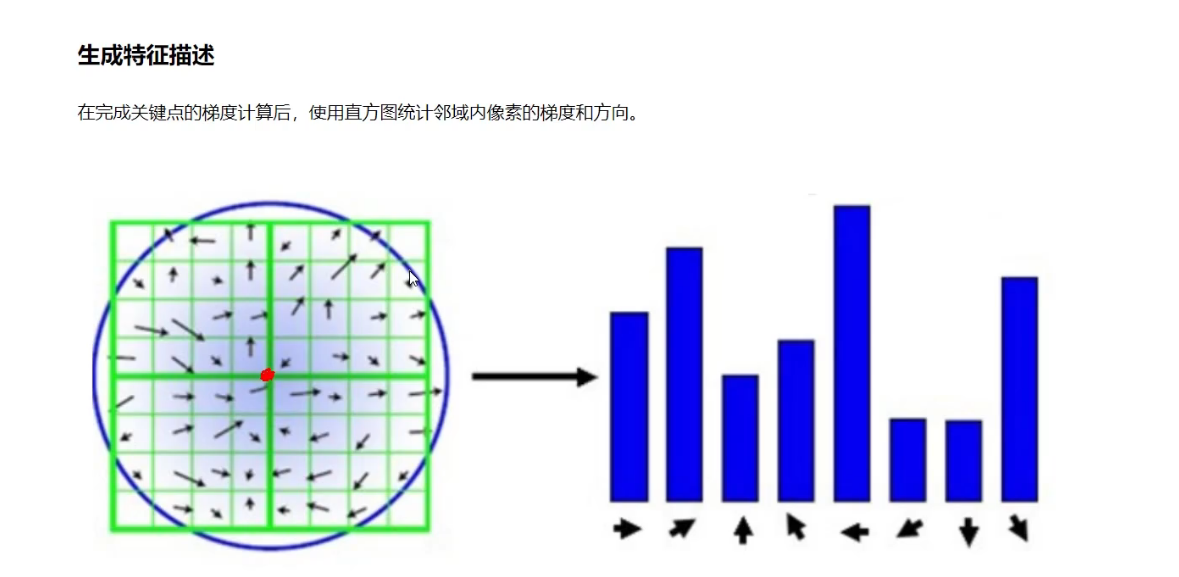
每个特征点可以得到三个信息(x,y,σ,θ),即位置、尺度和方向。具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给复制后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。
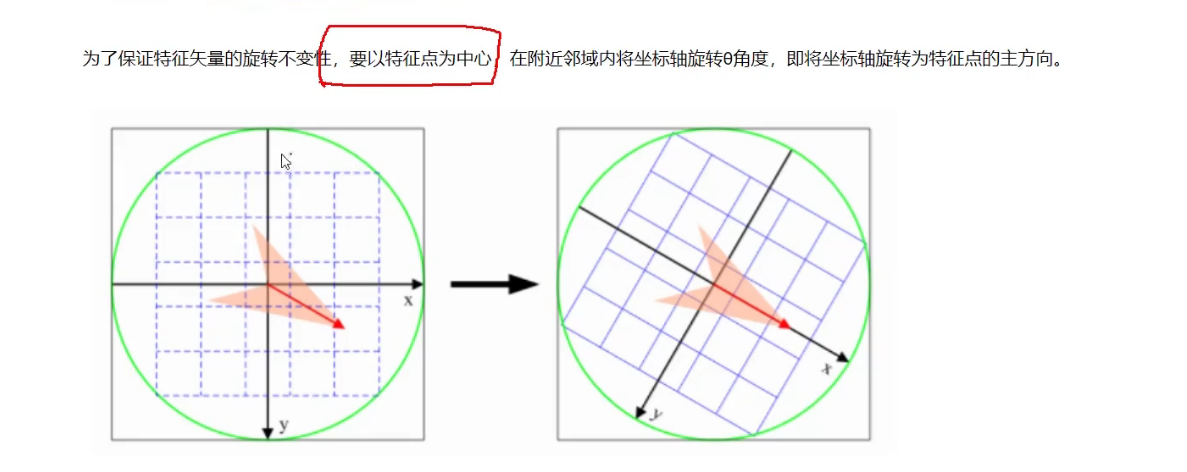
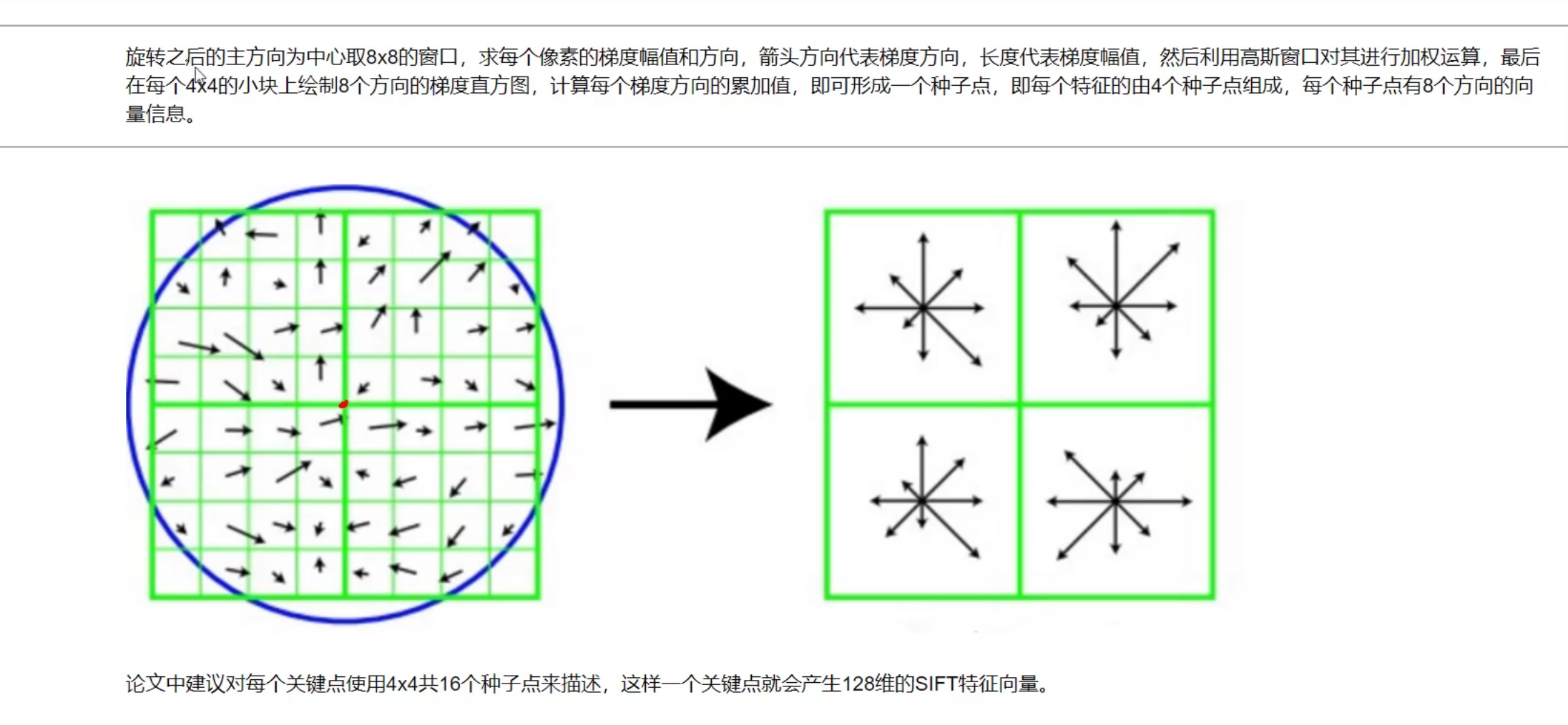
2.2 使用
java
pip list可以查看自己安装的包
java
pip uninstall xxx直接删除
java
import cv2
import numpy as np
img = cv2.imread('../test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
java
sift = cv2.SIFT_create()
kp = sift.detect(gray, None)kp就是关键点
java
img = cv2.drawKeypoints(gray, kp, img)
cv2.imshow('drawKeypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
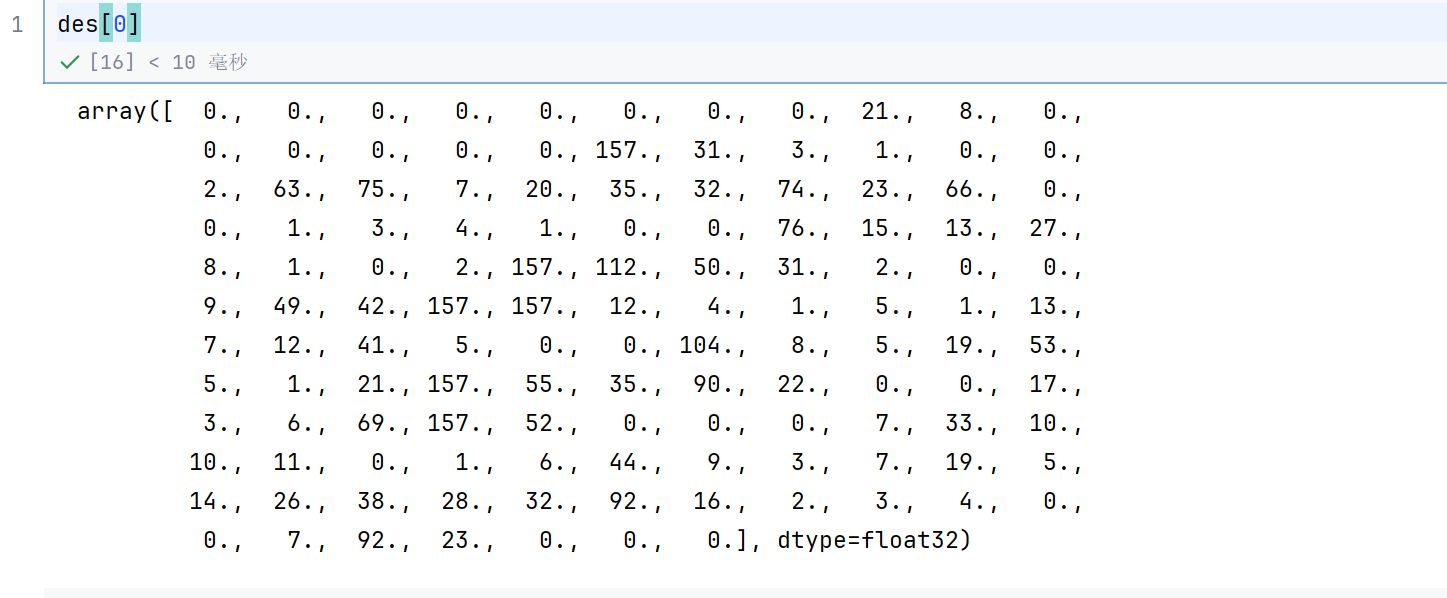
计算特征
java
kp, des = sift.compute(gray, kp)kp还是关键点
des是每个关键点的特征

128个特征
3 特征匹配
3.1 Brute-Force蛮力匹配
java
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline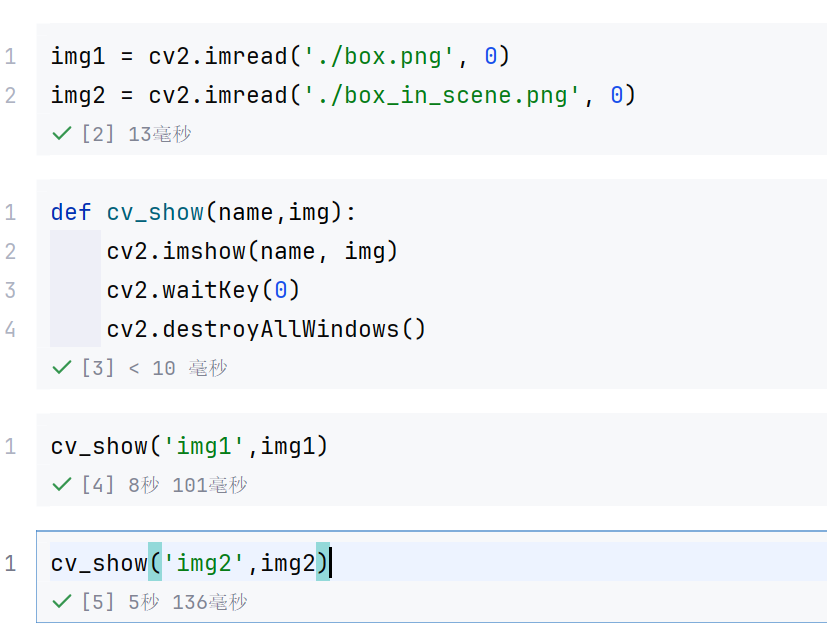


java
sift = cv2.SIFT_create()
java
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
java
# crossCheck表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
#NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True)
crossCheck=True的含义是这样的,i的最近是j,但是j的最近也就只能是i了,不能为z
3.2 1对1的匹配
java
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)返回的matches 是匹配出来的结果
排序的目的是给出匹配后的结果,比如第一个就是最相近的,第二个是第二相近的
java
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
java
cv_show('img3',img3)
matches:10, # 要绘制的匹配对(这里只显示前10对)
None, # 输出图像(None表示自动创建)
flags=2 # 绘制标志(2表示只绘制匹配线,不显示单个特征点)
3.3 k对最佳匹配
java
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)这个就表示一个点对应两个相近的点了
java
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])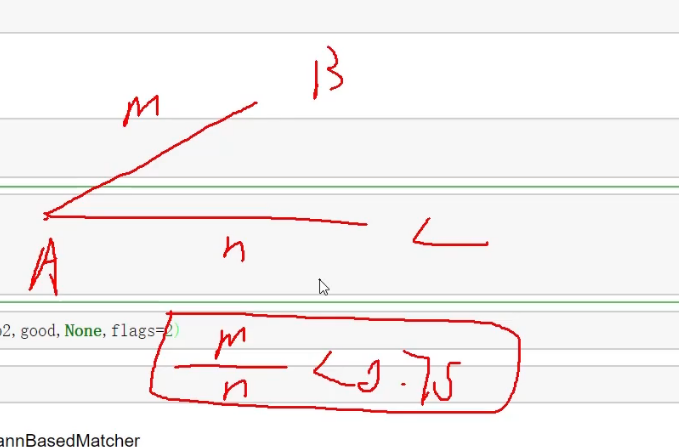
这个就是过滤出距离比小于0.75的了
java
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
cv_show('img3',img3)
发现有些点配对错了----》过滤掉
如果需要更快速完成操作,可以尝试使用cv2.FlannBasedMatcher
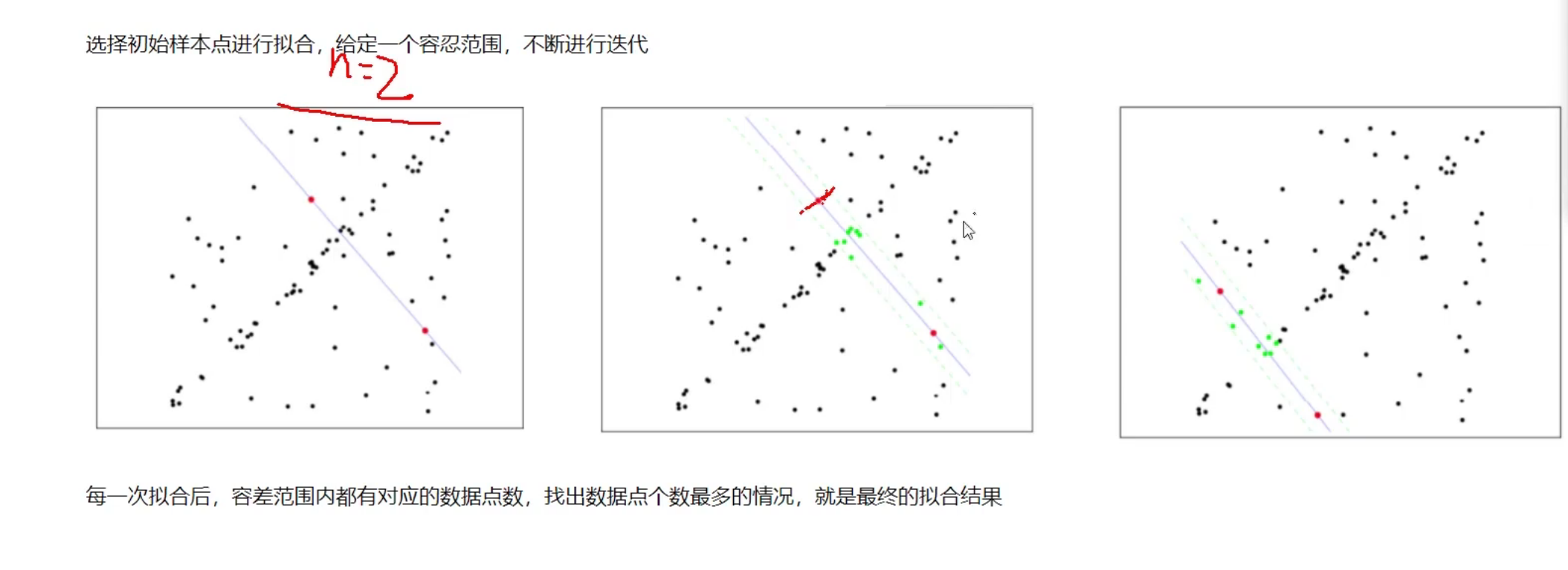
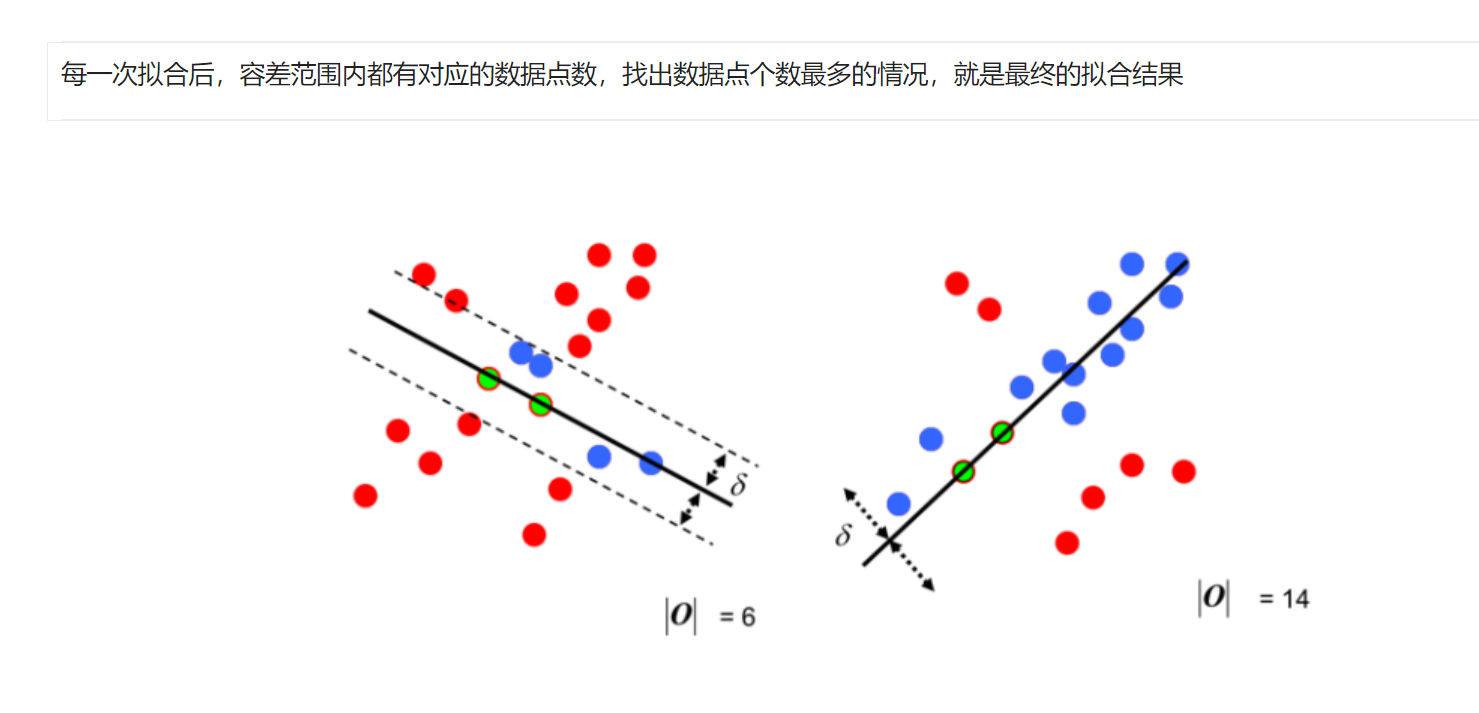
4. 样例实战-图像全景拼接
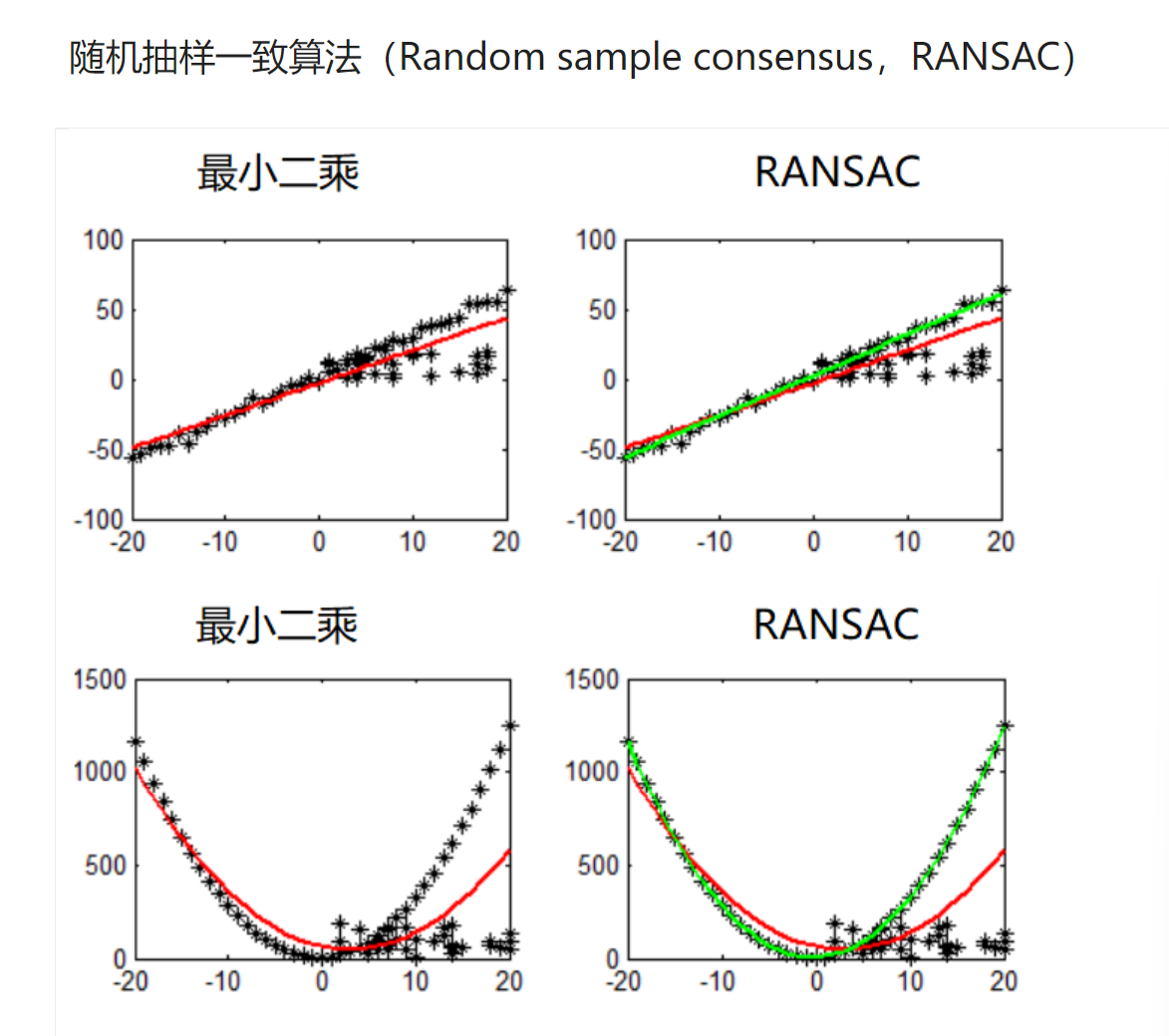
不是简单的切割

H矩阵可以把图像进行弯曲的效果,就是变换矩阵
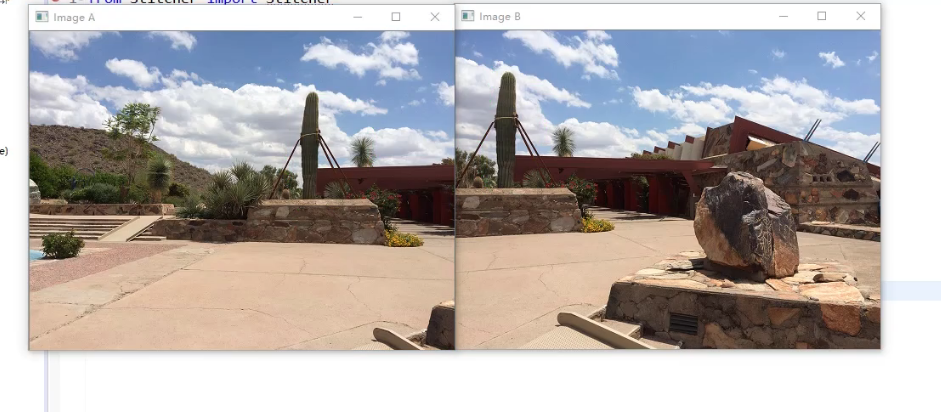
这两个拼接,,比如柱子也应该拼接为一个才行
就是先找很多特征点配对,然后就可以拼接了

4.1 流程解读
java
import numpy as np
import cv2
class Stitcher:
#拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0,showMatches=False):
#获取输入图片
(imageB, imageA) = images
#检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
# 将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def cv_show(self,name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(image, None)
# 将结果转换成NumPy数组
kps = np.float32([kp.pt for kp in kps])
# 返回特征点集,及对应的描述特征
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
java
from Stitcher import Stitcher
import cv2
# 读取拼接图片
imageA = cv2.imread("left_01.png")
imageB = cv2.imread("right_01.png")
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# 显示所有图片
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()5. 答题卡识别判卷

这个就是答题卡
java
#导入工具包
import numpy as np
import argparse
import imutils
import cv2
# 正确答案,表示第一题选B,第二题选E
ANSWER_KEY = {0: 1, 1: 4, 2: 0, 3: 3, 4: 1}
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
# 因为类似梯形,所以取最大值
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
def sort_contours(cnts, method="left-to-right"):
# reverse:控制排序是升序还是降序(例如 "从左到右" 是升序,"从右到左" 是降序)。
reverse = False
# i:控制用边界框的 x 坐标(i=0)还是 y 坐标(i=1)作为排序依据(水平排序用 x,垂直排序用 y)。
i = 0
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
# cv2.boundingRect(c)返回轮廓c的最小外接矩形,格式为(x, y, width, height),其中(x, y)是矩形左上角坐标。
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
# zip(cnts, boundingBoxes)将轮廓与其对应的边界框配对
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i], reverse=reverse))
# 排序后的轮廓列表(cnts),对应的排序后边界框列表(boundingBoxes)
return cnts, boundingBoxes
def cv_show(name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 预处理
image = cv2.imread("./images/test_01.png")
contours_img = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯滤波---》去掉噪音点
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
cv_show('blurred',blurred)
# 边缘检测
edged = cv2.Canny(blurred, 75, 200)
cv_show('edged',edged)
# 轮廓检测,会返回两个值,[1]表示只需要轮廓
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[0]
cv2.drawContours(contours_img,cnts,-1,(0,0,255),3)
cv_show('contours_img',contours_img)
docCnt = None
# 确保检测到了
if len(cnts) > 0:
# 根据轮廓大小进行排序
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# 遍历每一个轮廓
for c in cnts:
# 近似,
# 计算轮廓的周长,True表示轮廓是闭合的
peri = cv2.arcLength(c, True)
# 对轮廓进行多边形近似,参数0.02 * peri表示近似精度(周长的 2%)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 准备做透视变换
# 当近似后的多边形有 4 个顶点时,认为找到了四边形(通常是矩形文档),将其保存到docCnt并跳出循环。
if len(approx) == 4:
docCnt = approx
break
# 执行透视变换,,因为手机照出来的不是真正的长方形,所以要投射变换
warped = four_point_transform(gray, docCnt.reshape(4, 2))
cv_show('warped',warped)
# Otsu's 阈值处理,THRESH_OTSU自动计算阈值来划分,但是第二个参数要为0
thresh = cv2.threshold(warped, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
cv_show('thresh',thresh)
thresh_Contours = thresh.copy()
# 找到每一个圆圈轮廓
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[0]
cv2.drawContours(thresh_Contours,cnts,-1,(0,0,255),3)
cv_show('thresh_Contours',thresh_Contours)
questionCnts = []
# 遍历,只要圆形
for c in cnts:
# 计算比例和大小,计算外接矩形boundingRect---》圆的外接矩形,h和w差不多一样大
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# 根据实际情况指定标准
if w >= 20 and h >= 20 and ar >= 0.9 and ar <= 1.1:
questionCnts.append(c)
# 按照从上到下进行排序
questionCnts = sort_contours(questionCnts,
method="top-to-bottom")[0]
correct = 0
# 每排有5个选项,生成步长为 5 的索引序列(0,5,10...),用于按排取轮廓
# q:当前是第几排(从 0 开始计数)
# i:当前排的起始索引(如第 1 排从 i=0 开始,第 2 排从 i=5 开始)
for (q, i) in enumerate(np.arange(0, len(questionCnts), 5)):
# 排序
# questionCnts[i:i + 5]:截取当前排的 5 个选项轮廓
# sort_contours(...):调用之前的排序函数,默认按 "从左到右" 排序
# [0]:取排序后的轮廓列表(因为sort_contours返回两个值:轮廓列表和边界框列表)
cnts = sort_contours(questionCnts[i:i + 5])[0]
bubbled = None
# 遍历每一个结果
# j:当前选项在这一排中的索引(0-4,对应 5 个选项)
for (j, c) in enumerate(cnts):
# 使用mask来判断结果
mask = np.zeros(thresh.shape, dtype="uint8")
cv2.drawContours(mask, [c], -1, 255, -1) #-1表示填充
cv_show('mask',mask)
# 通过计算非零点数量来算是否选择这个答案
# mask与thresh进行and操作,, # 只保留掩码区域内的阈值图像内容
mask = cv2.bitwise_and(thresh, thresh, mask=mask)
# # 统计掩码区域内非零像素的数量(即被涂黑的像素数)
total = cv2.countNonZero(mask)
# 通过阈值判断。。。找出最大黑色像素点---》被涂的位置,j表示涂的哪个选项,j=1表示选的B
if bubbled is None or total > bubbled[0]:
bubbled = (total, j)
# 对比正确答案
color = (0, 0, 255)
k = ANSWER_KEY[q]
# 判断正确,bubbled[1]就是j
if k == bubbled[1]:
color = (0, 255, 0)
correct += 1
# 绘图
cv2.drawContours(warped, [cnts[k]], -1, color, 3)
score = (correct / 5.0) * 100
print("[INFO] score: {:.2f}%".format(score))
cv2.putText(warped, "{:.2f}%".format(score), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
cv2.imshow("Original", image)
cv2.imshow("Exam", warped)
cv2.waitKey(0)