1. 一段话总结
RoboTron-Drive 是由中山大学深圳校区与美团联合提出的一体化大型多模态自动驾驶模型 ,通过课程式预训练与微调 (从单图像到多视图视频、从图像描述到驾驶推理逐步提升难度),整合 6 个公开自动驾驶数据集(如 CODA-LM、MAPLM 等)并进行问答对增强与标准化 ,同时设计视角感知提示词 以处理多视角输入,最终在 6 个基准数据集的 13 项任务中均实现SOTA 性能 ,且在 BDD-X、DRAMA、DriveBench 三个未见过的数据集上展现出更强的零样本泛化能力,能同时处理图像 / 多视图视频等多种输入格式,完成感知、预测、规划等全流程自动驾驶任务。
2. 思维导图(mindmap)
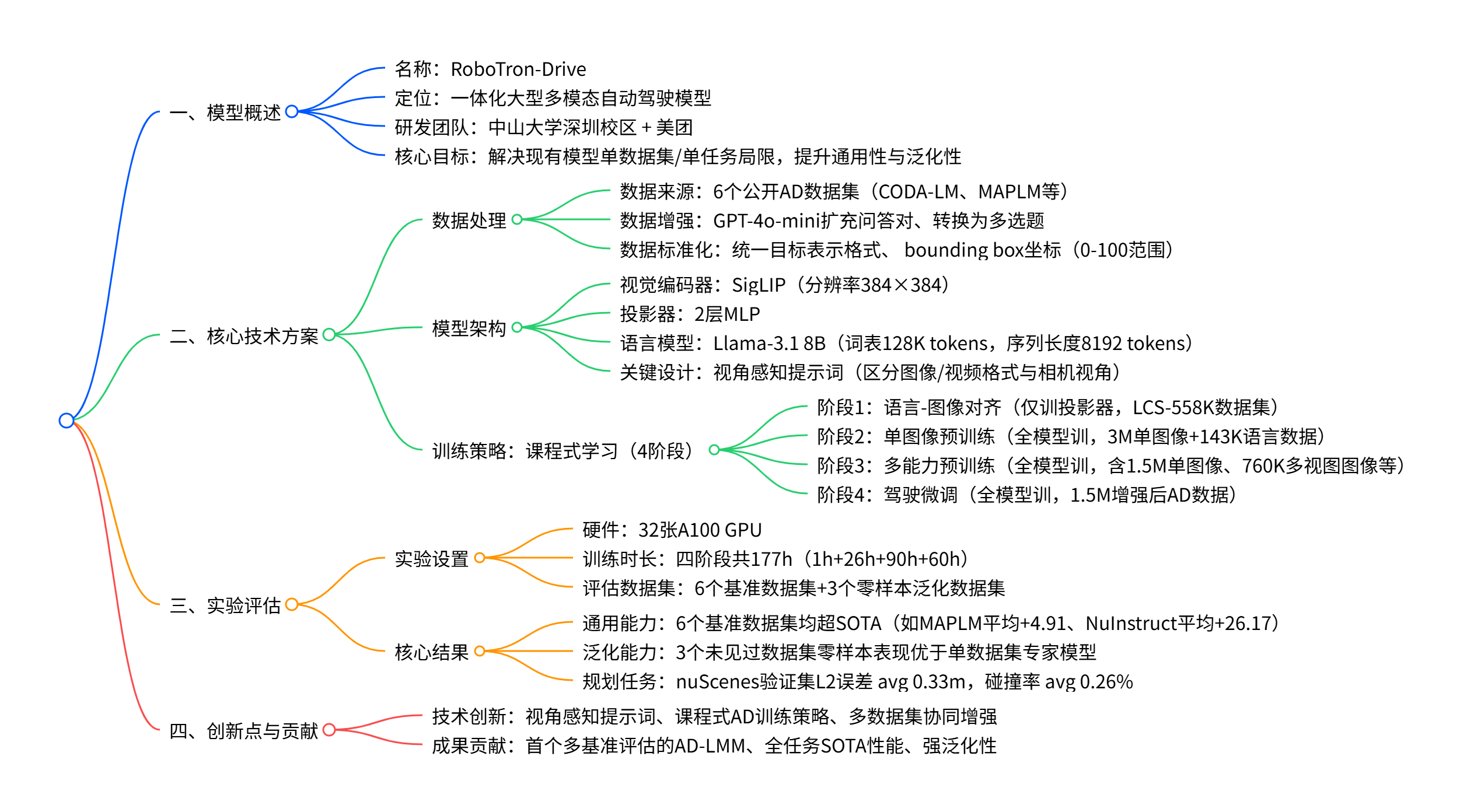
- 技术创新:视角感知提示词、课程式AD训练策略、多数据集协同增强
- 成果贡献:首个多基准评估的AD-LMM、全任务SOTA性能、强泛化性
3. 详细总结
一、研究背景与问题
现有自动驾驶领域的大型多模态模型(LMM)存在两大局限:
- 任务与数据单一:多数模型聚焦于单数据集(如 CODA-LM 仅处理单视图图像、NuInstruct 仅针对多视图视频)和特定任务(如 MAPLM 侧重道路感知、LingoQA 侧重规划),无法应对真实场景的复杂需求;
- 泛化能力弱:单数据集训练的 "专家模型" 在未见过的数据集上表现差,难以适配不同传感器配置(相机 / LiDAR)与场景。
二、模型核心设计
1. 模型架构
| 组件 | 具体配置 |
|---|---|
| 视觉编码器 | SigLIP,预训练于 WebLI,分辨率 384×384,负责将视觉输入编码为特征 |
| 投影器 | 2 层 MLP,将视觉特征投影到语言模型的词嵌入空间 |
| 语言模型 | Llama-3.1 8B,词表大小 128K tokens,处理序列长度 8192 tokens,生成任务输出 |
| 关键优化 | 视角感知提示词,格式为 "1: <image>/<video> ... n: <image>/<video>,标注相机 / LiDAR 视角",解决多视图区分问题 |
2. 数据处理方案
(1)数据来源
整合 3 类核心数据,覆盖多格式与多任务:
- 常规多模态数据:LCS-558K、COCO118K、CC3M 等图像 - 文本对,以及 OneVision 的视觉指令微调数据(单图像 / 多图像 / 视频);
- 感知数据:COCO、Object365(单图像目标检测)、nuScenes(多视图图像 / 视频,含相机视角标注);
- 自动驾驶数据:6 个公开数据集,具体信息如下表:
| 数据集 | 输入类型 | 核心任务领域 | 样本量(增强后) |
|---|---|---|---|
| CODA-LM | 单视图图像(S.I.) | 极端场景感知 | 184,480 |
| MAPLM | 多视图图像(M.I.) | 道路感知 | 94,970 |
| DriveLM | 多视图图像(M.I.) | 感知 + 推理 | 376,181 |
| LingoQA | 单视图视频(S.V.) | 规划 + 行为推理 | 413,829 |
| OmniDrive | 多视图视频(M.V.) | 3D 感知 + 规划 | 374,329 |
| NuInstruct | 多视图视频(M.V.) | 预测 + 决策 | 71,842 |
(2)数据增强与标准化
- 问答对增强:用 GPT-4o-mini 扩充固定模板(如 CODA-LM 从 3 种模板扩展为多样式),部分开放式问题转为多选题,提升数据多样性;
- 问答对标准化:统一目标表示格式(如将 DriveLM 的 "<c6, CAM BACK, 1088.3, 497.5>" 与 NuInstruct 的 "<car>c6, 139, 343, 1511, 900" 统一为 "<car>CAM_BACK, x1, y1, x2, y2"),并将 bounding box 坐标标准化到 0-100 范围(基于图像尺寸)。
3. 训练策略:课程式学习(4 阶段)
| 训练阶段 | 目标 | 训练数据 | 训练配置 | 时长 |
|---|---|---|---|---|
| 阶段 1:语言 - 图像对齐 | 对齐视觉特征与语言嵌入空间 | LCS-558K | 仅训投影器,冻结视觉编码器与 LLM,学习率 1e-3,batch 512 | 1h |
| 阶段 2:单图像预训练 | 提升单图像理解能力 | 3M 单图像数据(BLIP558K、COCO118K 等)+143K 语言数据 | 全模型训练,视觉编码器学习率 2e-6,其他 1e-5,batch 256 | 26h |
| 阶段 3:多能力预训练 | 适配多格式数据与基础感知推理 | 1.5M 单图像 + 760K 多视图图像 + 501K 单视频 + 145K 多视图视频 | 同阶段 2 配置 | 90h |
| 阶段 4:驾驶微调 | 适配自动驾驶全任务 | 1.5M 增强后的 6 个 AD 数据集 | 同阶段 2 配置 | 60h |
三、实验结果
1. 通用能力评估(6 个基准数据集)
RoboTron-Drive 在所有数据集的关键指标上均超专家模型(单数据集训练)与零样本模型(如 GPT-4o、LLaVA-OV),部分核心结果如下:
| 数据集 | 关键指标 | 专家模型平均 | GPT-4o | RoboTron-Drive | 提升幅度(vs 专家模型) |
|---|---|---|---|---|---|
| CODA-LM | 平均得分 | 63.62 | 48.79 | 64.18 | +0.56 |
| MAPLM | 平均得分 | 71.76 | 23.12 | 76.67 | +4.91 |
| NuInstruct | 平均得分(*) | 20.13 | 1.95 | 46.30 | +26.17 |
| LingoQA | Lingo-Judge 得分 | 60.80 | 18.40 | 69.20 | +8.40 |
| 注:*NuInstruct 平均得分计算方式为 max ((Accuracy+MAP+BLEU-MAE)/4, 0) |
2. 泛化能力评估(3 个未见过数据集)
在零样本设置下,模型表现优于单数据集专家模型:
| 数据集 | 评估指标 | 专家模型平均 | RoboTron-Drive | 提升幅度 |
|---|---|---|---|---|
| BDD-X | GPT-Score | 26.48 | 43.10 | +16.62 |
| DRAMA | GPT-Score | 10.52 | 53.32 | +42.80 |
| DriveBench | 平均得分 | 3.39 | 61.06 | +57.67 |
3. 规划任务专项评估(nuScenes 验证集)
| 模型 | L2 误差(avg,单位:m) | 碰撞率(avg,%) |
|---|---|---|
| UniAD | 0.46 | 0.37 |
| VAD-Base | 0.37 | 0.33 |
| RoboTron-Drive | 0.33 | 0.26 |
四、核心贡献
- 提出首个一体化自动驾驶多模态模型RoboTron-Drive,可处理多输入格式、完成全流程 AD 任务;
- 构建首个多基准评估体系,覆盖 6 个数据集、4 种输入类型、13 项任务,为 AD-LMM 评估提供标准;
- 设计课程式 AD 训练策略与视角感知提示词,结合多数据集协同增强,大幅提升模型通用性与泛化性。
4. 关键问题
问题 1:RoboTron-Drive 通过哪些具体设计突破了现有自动驾驶多模态模型 "单任务 / 单数据集局限"?
答案:
主要通过三大设计突破局限:
- 多数据集整合与增强:整合 CODA-LM(极端场景)、MAPLM(道路感知)等 6 个覆盖不同任务的 AD 数据集,用 GPT-4o-mini 扩充问答对(如 CODA-LM 模板多样化)并标准化格式(统一目标表示与 bounding box 坐标),实现数据集间协同;
- 课程式训练策略:从 "单图像 - 图像描述" 到 "多视图视频 - 驾驶推理" 逐步提升数据与任务复杂度,阶段 3 专门融入多格式数据(1.5M 单图像、760K 多视图图像等),让模型适配全场景输入;
- 视角感知提示词:通过 "序号 + 输入类型 + 视角标注"(如 "1: <image>(前视图)、2: <video>(后右视图)")的提示词设计,让模型区分多相机 / LiDAR 视角,处理多视图数据的空间关系,支持感知、预测、规划全任务。
问题 2:在实验验证中,RoboTron-Drive 的 "通用能力" 与 "泛化能力" 分别通过哪些数据集和指标验证?核心结果如何体现其优势?
答案:
(1)通用能力验证
- 验证数据集:6 个公开 AD 基准数据集(CODA-LM、MAPLM、DriveLM、LingoQA、OmniDrive、NuInstruct),覆盖 13 项任务;
- 核心指标:各数据集专属指标(如 CODA-LM 用 GPT-4 评分、MAPLM 用分类准确率 + BLEU、NuInstruct 用 MAE+Accuracy+MAP+BLEU);
- 优势体现:所有数据集均超 SOTA,如 MAPLM 平均得分 76.67(vs 专家模型 71.76,+4.91)、NuInstruct 平均得分 46.30(vs 专家模型 20.13,+26.17),且同时处理多输入格式(单图像 / 多视图视频),打破 "单任务专家模型" 局限。
(2)泛化能力验证
- 验证数据集:3 个未见过的数据集(BDD-X、DRAMA、DriveBench),分别对应场景描述、风险定位、多任务可靠性评估;
- 核心指标:GPT-Score(BDD-X/DRAMA)、DriveBench 多任务平均得分;
- 优势体现:零样本设置下大幅优于单数据集专家模型,如 DRAMA 的 GPT-Score 达 53.32(vs 专家模型 10.52,+42.80)、DriveBench 平均得分 61.06(vs 专家模型 3.39,+57.67),证明其在未知场景的适配能力。
问题 3:从模型架构与训练配置来看,RoboTron-Drive 的硬件成本与训练效率如何?其架构选择(如 SigLIP、Llama-3.1 8B)有哪些考量?
答案:
(1)硬件成本与训练效率
- 硬件配置:实验使用 32 张 A100 GPU,总训练时长 177 小时(阶段 1:1h、阶段 2:26h、阶段 3:90h、阶段 4:60h),属于大型多模态模型的常规训练规模;
- 效率优化:阶段 1 仅训练投影器(冻结其他组件)、阶段 3 对视频特征采用 2×2 空间池化压缩维度,减少计算量,平衡训练成本与模型性能。
(2)架构选择考量
- 视觉编码器(SigLIP):预训练于 WebLI 数据集,在图像 - 文本对齐任务上表现优异,分辨率 384×384 兼顾细节捕捉与计算效率,适配自动驾驶场景的视觉感知需求;
- 语言模型(Llama-3.1 8B):8B 参数规模平衡 "性能与部署成本",128K 词表支持复杂驾驶指令理解,8192 tokens 序列长度可处理长视频帧与多轮问答,满足规划任务的逻辑推理需求;
- 投影器(2 层 MLP):结构简单且高效,能快速将视觉特征映射到 Llama-3.1 的词嵌入空间,避免复杂架构带来的训练延迟,保障多阶段训练的流畅性。