近年来,大模型技术逐渐走进我们的生活。无论是在科技新闻里,还是在日常聊天中,总能听到它的名字。它不仅能写文章、画图、翻译语言,还能帮医生诊断疾病,甚至完成一些我们以前觉得只有人类才能做的事情。
"大模型"到底是什么?为什么它这么厉害?它是怎么做到的?这篇文章就用大白话,带您了解大模型的基本概念、工作原理。
大模型的定义
大模型,顾名思义,指的是那些在训练过程中需要海量数据、超强计算能力和大量参数的人工智能模型。这些模型具有惊人的规模、庞大的参数数量以及复杂的算法结构,使其能够处理各种复杂的任务和数据。这些"巨型"模型能从海量的信息中提取出深层次的规律,进而进行高度复杂的任务,如自然语言理解、图像生成、自动推理、机器翻译等。
通俗解释:大模型,顾名思义,就是那些"体型庞大"的人工智能模型。它们需要海量的数据、超强的计算能力和数以亿计的参数来完成训练。
这些模型不仅能处理复杂的任务,还能从海量信息中提取深层次的规律,解决像自然语言理解、图像生成、自动推理等高难度问题。
目前,最具代表性的例子是OpenAI的GPT系列(包括GPT-3、GPT-4等),这些模型拥有上千亿个参数,能够写文章、回答问题、翻译语言,甚至模仿特定风格的文字。再比如春节火爆全球的DeepSeek、阿里的Qwen等等。
一句话总结:大模型就像一个"全能型选手",它能学得更多、看得更广、做得更好。
文章篇幅有限,不便展示AI大模型全部资源。更多AI大模型学习视频及资源,都在智泊AI。
LLM 工作原理解释
条件概率解释
他提到,在介绍 LLM 之前,需要先了解一下条件概率(conditional probability),应该是与高中、大学学的概率学相关。有一个很形象的例子:
有 14 个人,他们中的一部分人(7 个)喜欢网球、一部分人(8个)喜欢足球、少部分人(3 个)同时喜欢网球和足球、也有极少一部分人(2 个)都不喜欢网球和足球。用图表示如下:
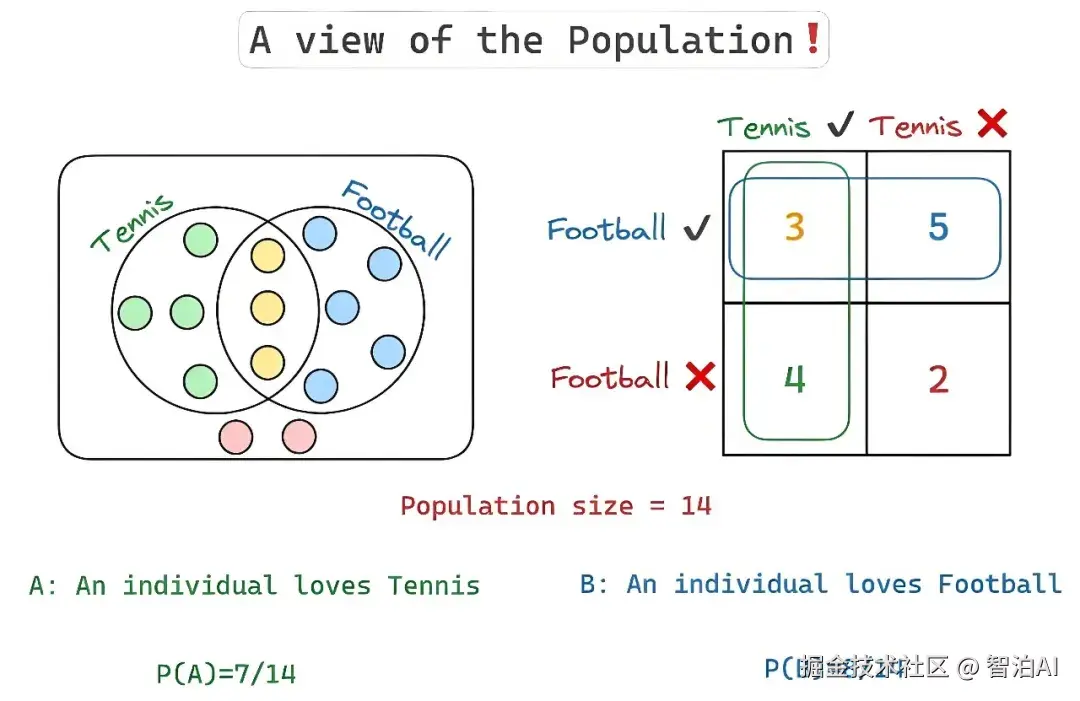
所以如果要表示喜欢网球的人数概率,表示方法为 P(A),结果是 7/14;喜欢足球的人数概率,表示方法为 P(B),结果为 8/14;同时喜欢网球和足球的人数概率,表示方法为 P(A∩B),结果是 3/14;同时表示既不喜欢网球又不喜欢足球的人数概率,结果为 2/14。
那什么条件概率呢?
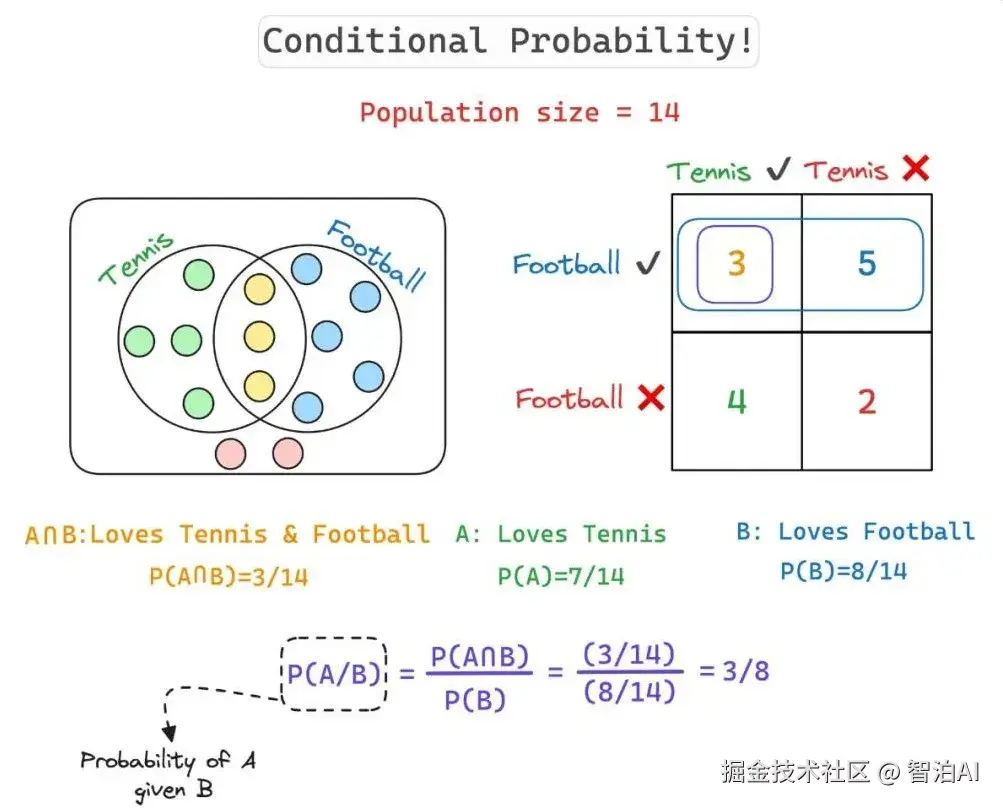
其实就是在另外一件事情发生的前提下,某件事情发生的概率。比如上面的事件 A 和事件 B,如果要表示在事件 B 发生的前提下,事件 A 发生的概率,那么表示方法是P(A∣B)。
所以,如果要计算一个人在喜欢足球的情况下,还喜欢网球的概率,计算方法为 P(A|B)=P(A∩B)/P(B)=(3/14)/(8/14)=3/8。
再拿阴天和下雨天为例来讲条件概率:如果将今天下雨当作事件 A,阴天可能下雨作为事件 B(按照常识,阴天会有下雨的可能),而且事件 B 会影响下雨的预测。所以,阴天的时候就可能会下雨,这个时候就可以说条件概率 P(A|B) 是非常高的。
大模型的特点
庞大的参数量:大模型最为显著的特点就是其参数量之庞大。传统的人工智能模型通常在数百万个参数的规模,而大模型的参数量则往往达到数十亿、数百亿甚至上千亿。例如,GPT-3拥有1750亿个参数,这使得它能够处理复杂的语言生成和理解任务。参数量的增加使得模型可以学习和存储更多的知识,从而提高对任务的理解和执行能力。
通俗解释:知识储备超乎想象。传统的人工智能模型通常只有几百万个参数,而大模型动辄几十亿、上百亿,甚至上千亿个参数。
比如GPT-3有1750亿个参数,这相当于它能记住并运用海量的知识。参数越多,模型越聪明,能够处理的任务也越复杂。
如果你让GPT-3写一篇关于"太空探索"的文章,它可以轻松调用相关领域的知识,生成既专业又流畅的内容,就像一位经验丰富的科普作家一样。
海量的训练数据:为了充分发挥大模型的优势,训练过程中需要使用海量的数据。这些数据可能来自互联网上的文章、书籍、社交媒体、新闻报道等各种来源。通过对这些数据进行深度学习,大模型能够形成更为全面的知识库,并从中发现更为复杂的规律。例如,GPT-3在训练过程中,涉及了数千亿单词的语料数据,这使得它能够理解不同领域的内容,并生成更加精准的回答。
通俗解释:吃得多才能长得壮。大模型的训练需要大量的数据支持,这些数据可能来自互联网上的文章、书籍、社交媒体、新闻报道等。
通过学习这些数据,大模型可以掌握不同领域的知识,并发现其中隐藏的规律。
超强的计算能力:训练如此庞大的模型需要极为强大的计算能力。传统的个人计算机和工作站远远无法满足这一需求,因此大模型的训练通常依赖于分布式计算架构,采用多个GPU或TPU等高性能计算硬件。这些硬件能够在短时间内完成对海量数据的处理,尤其是在使用云计算平台时,训练速度可以大幅度提升。然而,这也意味着大模型的训练成本非常高,且对计算资源的需求极为苛刻。
通俗解释:硬件是硬实力。训练如此庞大的模型,普通的电脑根本不够用,必须依赖高性能的GPU或TPU等计算硬件。而且,很多时候还需要借助云计算平台来加速训练过程。
这也意味着训练成本非常高,可能需要花费数百万美元。训练一个像GPT-3这样的大模型,其能耗相当于几百个家庭一年的用电量。所以,大模型不仅烧钱,还很耗电!
LLM 预测解释
回到 LLM 上来说,这些模式的任务就是预测下一个出现的单词。这就和前面讲的条件概率类似:如果给定已经出现过的单词,那下一个最可能出现的单词是哪一个?

所以,要预测下一个单词,模型就要根据之前给定的单词(上下文)来为每一个接下来可能出现的单词进行条件概率的计算,条件概率最高的单词就会被作为预测单词所选中。
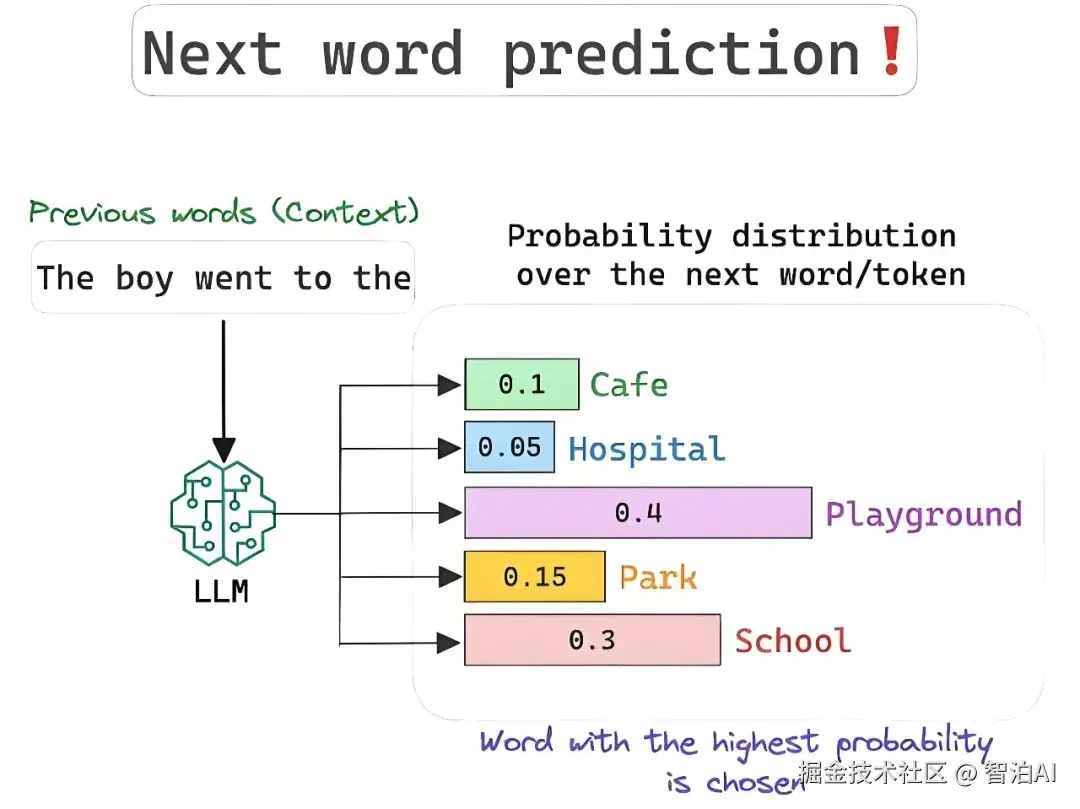
而 LLM 学习的是一个高维度的单词序列概率分布。这个分布的参数就是经过训练的权重。但是这种概率毕竟是一种预测,并不是实际的结果,所以这个过程中就有一个 损失计算(Loss calculation) 的概念。

大模型的技术原理
大模型之所以能够展现出如此强大的能力,离不开其背后复杂而精妙的技术原理。从训练方法到推理优化,再到知识蒸馏,这些技术共同构成了大模型的"基石"。接下来,我们将深入探讨大模型的技术原理,包括以下几个核心方面:
Transformer架构:大模型的核心引擎
大模型的成功离不开Transformer架构的广泛应用。Transformer是一种基于自注意力机制(Self-Attention Mechanism)的深度学习模型,最早由谷歌在2017年的论文《Attention is All You Need》中提出。相比于传统的RNN和CNN,Transformer具有以下优势:
并行计算:RNN需要逐个处理序列数据,而Transformer可以同时处理整个输入序列,极大地提高了训练效率。
长距离依赖建模:通过自注意力机制,Transformer能够捕捉输入序列中任意两个位置之间的关系,从而更好地处理长距离依赖问题。
可扩展性:Transformer架构支持参数规模的灵活扩展,这为构建超大规模的大模型奠定了基础。
以GPT系列为例,它们完全基于Transformer架构,通过堆叠多层编码器(Encoder)或解码器(Decoder),形成了一个能够处理多种任务的通用模型。
通俗解释:Transformer就像是一个"超级大脑",它能同时关注一段话中的所有词语,并快速找到它们之间的关系。
比如当你问"谁是爱因斯坦?"时,它会迅速定位到"爱因斯坦"这个关键词,并从海量知识中提取相关信息。
预训练与微调:大模型的学习方式
大模型的训练通常分为两个阶段:预训练和微调。
预训练(Pre-training):预训练是大模型学习的第一步,也是最关键的一步。在这个阶段,模型会使用海量的无标注数据进行训练,目标是让模型掌握语言的基本规律和知识。例如,GPT系列模型在预训练阶段会学习如何根据上下文预测下一个单词,BERT模型则会学习如何根据上下文补全被遮掩的单词。
通俗解释:预训练就像让一个孩子读遍图书馆里的所有书,虽然他还不知道这些知识具体有什么用,但他已经掌握了大量的背景信息。
微调(Fine-tuning):微调是针对特定任务对模型进行进一步优化的过程。在这个阶段,模型会使用少量标注数据进行训练,以适应具体的任务需求。例如,如果你想让大模型完成情感分析任务,你只需要提供一些带有情感标签的文本数据,模型就能学会如何判断一段文字的情感倾向。
通俗解释:微调就像给孩子布置作业,让他把之前学到的知识应用到实际问题中。比如,教他识别一篇文章是正面评价还是负面评价。
Token化:大模型的语言单位
在自然语言处理中,大模型并不是直接处理原始文本,而是将文本分解成一个个"Token"(标记)。Token可以是一个单词、一个子词(Subword),甚至是一个字符。这种分解方式被称为分词或Tokenization。
通俗解释:Token就像是大模型的"语言积木",它把复杂的语言拆解成简单的单元,方便模型理解和处理。
为什么需要Token?Token化的主要目的是将自然语言转化为计算机能够理解的形式。例如,句子"我喜欢人工智能"可能会被分解为三个Token:"我"、"喜欢"、"人工智能"。
子词分割的优势:在某些情况下,直接使用单词作为Token可能会导致词汇表过于庞大,尤其是对于像中文这样的语言。因此,许多大模型采用子词分割(Subword Segmentation)技术,将单词拆分成更小的单元。例如,"人工智能"可能会被拆分为"人工"和"智能"。