备注 :回顾看过的论文,对目前看过的llama系列进行整理在此总结,此为第一篇(注:笔者水平有限,若有描述不当之处,欢迎大家留言。后期会继续更新LLM系列,文生图系列,VLM系列,agent系列等。如果看完有收获,可以【点赞】【收藏】【加粉】)
阐述的思维逻辑:会给出论文中的核心点和核心点的描述。
一句话总结: LLaMA 1 是 Meta AI 基于 1.4 万亿 tokens 的纯公开数据集训练的一系列基础语言模型(参数量从 7B 到 65B),其核心在于遵循 Chinchilla 最优缩放法则,证明了小型模型通过海量数据训练也能实现领先的性能,开创了高效 且开源大模型的新范式。
技术亮点 :
1 数据规模与开放性: 模型在 1.4 万亿 tokens 的纯公开数据集上进行训练,这使其与开源原则高度兼容,避免了对专有或不可访问数据集的依赖。
2 注重数据效率的缩放法则: 训练策略遵循 Chinchilla 最优缩放法则 ,强调用更多的 Token 来训练较小尺寸的模型。这使得 LLaMA-13B 在大多数基准测试上性能超越了当时参数量更大的 GPT-(175B),展现了高效训练的巨大潜力。
3 模型架构优化(效率与稳定): 在标准 Transformer 架构上进行了关键改进,包括:
-
使用 RMSNorm 进行预归一化(Pre-normalization)以提升训练稳定性。
-
采用 SwiGLU 激活函数代替 ReLU,以提高性能。
-
使用 Rotary Positional Embedding (RoPE) 来编码位置信息。
备注:后续为机器翻译
摘要
我们介绍 LLaMA,一个由 70 亿到 650 亿参数规模组成的基础语言模型集合。我们使用 数万亿 tokens 进行训练,并展示:仅使用公开可获得的数据集,在不依赖私有或不可访问数据的情况下,也能够训练出最先进水平的模型。特别是,LLaMA-13B 在大多数基准测试上优于 GPT-3(175B),而 LLaMA-65B 的性能可与最先进的模型 Chinchilla-70B 和 PaLM-540B 竞争。我们将所有模型全部开放给研究社区¹。
一 介绍
在大规模文本语料上训练的大型语言模型(LLMs) ,已经展示出能够通过文本指令或少量示例(Brown et al., 2020)执行新任务的能力。这些 few-shot 能力最初是在将模型扩展到足够大规模时出现的(Kaplan et al., 2020),促使了一系列进一步扩大模型规模的研究(Chowdhery et al., 2022;Rae et al., 2021)。这些研究基于这样的假设:更多参数将带来更好的性能 。然而,Hoffmann et al. (2022) 的最新工作表明:在给定训练算力预算的情况下,最佳性能并不是由最大规模的模型获得,而是由更小但训练更多数据的模型获得。
Hoffmann et al. (2022) 的 scaling law 的目标,是在特定训练算力预算下,确定如何在数据集规模与模型规模之间实现最佳伸缩。然而,这一目标忽略了推理成本 ------ 当需要大规模部署语言模型时,推理成本变得至关重要。在这种情况下,给定目标性能水平,首选模型不是训练最快的模型,而是推理最快的模型 。尽管在训练阶段,用较大的模型可能更便宜即可达到某个性能水平,但若使用一个更小的模型、并对其训练更久,最终在推理阶段会更便宜 。例如,尽管 Hoffmann et al. (2022) 推荐在 200B tokens 上训练一个 10B 模型,但我们发现:即使在 1T tokens 后,7B 模型的性能仍在持续提升。
本工作的重点是:通过在比常规规模更大的 tokens 上进行训练,在不同推理预算前提下,训练出性能最优的一系列语言模型 。最终得到的模型------称为 LLaMA ,规模从 7B 到 65B ,其性能可与现有最先进 LLM 相竞争。例如:LLaMA-13B 在大多数基准上超过 GPT-3,尽管其规模小 10 倍。 在高端规模上,我们的 65B 参数模型可与 Chinchilla 或 PaLM-540B 等最佳大模型竞争。
与 Chinchilla、PaLM 或 GPT-3 不同,我们仅使用公开可获得的数据,这使得我们的工作可与开源兼容;而多数现有模型依赖不可公开的数据(例如:"Books -- 2TB" 或 "Social media conversations")。已有一些例外,如 OPT(Zhang et al., 2022)、GPT-NeoX(Black et al., 2022)、BLOOM(Scao et al., 2022)和 GLM(Zeng et al., 2022),但它们都无法与 PaLM-62B 或 Chinchilla 竞争。
在本文的其余部分,我们将介绍对 Transformer 架构(Vaswani et al., 2017)所做的修改以及训练方法。随后,我们将报告模型性能并与其他 LLM 在标准基准上进行比较。最后,我们将使用负责任 AI 研究社区最新的基准,展示模型中存在的一些偏见与不良内容。
二 方法
我们的训练方法与以往工作(Brown et al., 2020;Chowdhery et al., 2022)中描述的方法相似,并受到 Chinchilla scaling laws(Hoffmann et al., 2022)启发。我们使用标准优化器,在大规模文本数据上训练大型 Transformer 模型。
2.1 预训练数据
我们的训练数据集由多个来源混合构成,如表 1 所示,覆盖多种不同领域。大多数情况下,我们复用了其他 LLM 训练中使用的数据源,但严格限制为 仅使用公开可获得且可开源的数据。最终采用的数据及其在训练集中的占比如下:
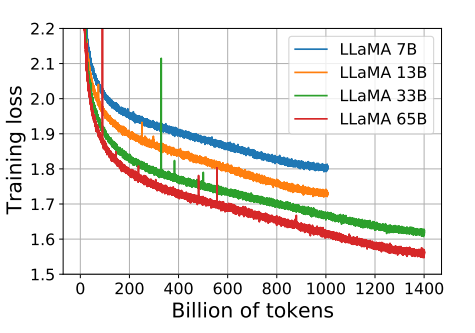 图1:7B、138、338 和 65 模型的训练损失随训练样本数量的变化。LLaMA-33B 和LLaMA-65B 模型使用 1.4T 个样本进行训练,其他较小规模的模型使用 1.0T 个样本进行训练。所有模型均以 4M 个样本的批次大小进行训练。
图1:7B、138、338 和 65 模型的训练损失随训练样本数量的变化。LLaMA-33B 和LLaMA-65B 模型使用 1.4T 个样本进行训练,其他较小规模的模型使用 1.0T 个样本进行训练。所有模型均以 4M 个样本的批次大小进行训练。 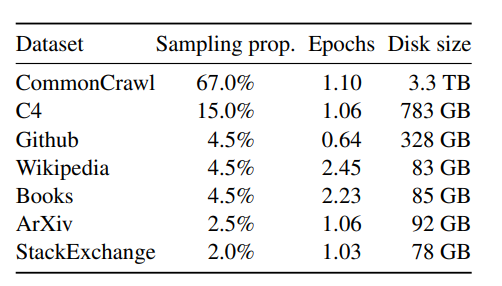 表1:预训练数据。用于预训练的数据混合,对于每个子集,我们列出了采样比例、在1.4T个token 上训练时在该子集上执行的 epoch 数以及磁盘大小。在 1T 个 token 上进行的预训练运行具有相同的采样比例。
表1:预训练数据。用于预训练的数据混合,对于每个子集,我们列出了采样比例、在1.4T个token 上训练时在该子集上执行的 epoch 数以及磁盘大小。在 1T 个 token 上进行的预训练运行具有相同的采样比例。
**English CommonCrawl(67%)。**我们使用 CCNet pipeline(Wenzek et al., 2020)对 2017 至 2020 年的五个 CommonCrawl dump 进行预处理。处理流程包括:在行级别进行去重;使用 fastText 线性分类器进行语言识别并移除非英语页面;使用 n-gram 语言模型过滤低质量内容。此外,我们训练了一个线性模型,用于区分 Wikipedia 引用页面与随机采样页面,并丢弃未被分类为引用的页面。
**C4(15%)。**在探索性实验中,我们观察到使用多样化预处理版本的 CommonCrawl 会提升性能,因此额外加入公开可用的 C4 数据集(Raffel et al., 2020)。C4 的预处理同样包含去重和语言识别;其与 CCNet 最大的区别在于质量过滤部分,该过程主要依赖启发式规则,如标点符号出现情况、网页中的词和句子数量等。
**Github(4.5%)。**我们使用 Google BigQuery 上公开的 GitHub 数据集,并仅保留采用 Apache、BSD、MIT 许可证发布的项目。此外,我们使用启发式规则(例如行长度、字母数字字符比例)过滤低质量文件,并使用正则表达式移除模板代码(如文件头)。最终的数据在文件级别进行完全匹配去重。
**Wikipedia(4.5%)。**我们加入 2022 年 6--8 月间的 Wikipedia dump,覆盖 20 种使用拉丁或西里尔字母的语言,包括:bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk。我们移除了超链接、注释与其他格式化模板。
**Gutenberg and Books3(4.5%)。**我们加入两个书籍语料库:;Gutenberg Project(公共领域书籍);ThePile 中的 Books3(Gao et al., 2020)。我们在书籍级别进行去重,移除内容重叠超过 90% 的书籍。
**ArXiv(2.5%)。**我们处理 arXiv 的 LaTeX 文件以加入科学文献数据。参考 Lewkowycz et al. (2022):移除首个 section 之前的全部内容;移除参考文献部分;移除 .tex 文件中的注释;内联展开用户自定义的宏和定义,提高论文间的一致性。
**Stack Exchange(2%)。**我们加入 Stack Exchange 的数据转储,该网站包含高质量的问答内容,覆盖从计算机科学到化学等多领域。我们保留 28 个最大的网站数据;移除文本内的 HTML 标签;将回答按分数从高到低排序。
Tokenizer(分词器)。 我们使用 SentencePiece(Kudo & Richardson, 2018)中实现的 BPE(Sennrich et al., 2015)进行分词。主要规则:所有数字被拆分为单个数字符号 ;对未知 UTF-8 字符回退到字节级拆分。整个训练数据集在分词后约包含 1.4 万亿 tokens。除 Wikipedia 和 Books 域外(大约训练两次 epoch),其余数据大部分仅使用一次。
2.2 模型架构
与近期大模型工作一致,我们的网络基于 Transformer 架构(Vaswani et al., 2017),并吸收了多个后续改进(如 PaLM)。主要相对原始 Transformer 架构的改动如下(括号中为参考来源):
**Pre-normalization GPT3(预归一化)。**为提升训练稳定性,我们在每个 transformer 子层的输入处进行归一化,而不是在输出处。归一化函数使用 RMSNorm(Zhang & Sennrich, 2019)。
SwiGLU Activation Function PaLM(SwiGLU 激活函数)。 我们将 ReLU 替换为 SwiGLU(Shazeer, 2020)以提升性能。SwiGLU 的中间层维度为 2⁄3·4d,不同于 PaLM 中的 4d。
**Rotary Embeddings GPTNeo(旋转位置编码)。**我们移除绝对位置编码,改为在每一层添加 RoPE【2】(Rotary Positional Embedding,Su et al., 2021)。
不同模型的超参数细节如表 2 所示。
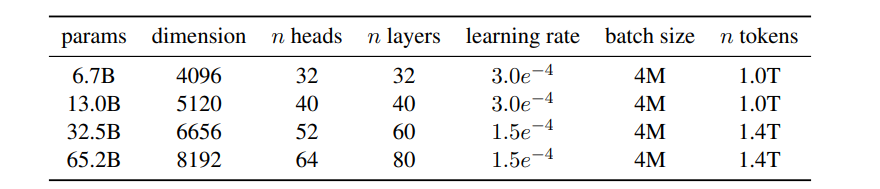 表2:模型规模、架构和优化超参数
表2:模型规模、架构和优化超参数
2.3 优化器
我们使用 AdamW 优化器(Loshchilov & Hutter, 2017)训练模型,超参数如下:β₁ = 0.9,β₂ = 0.95使用余弦学习率调度,使最终学习率为最大学习率的 10%。我们使用:weight decay = 0.1 ,gradient clipping = 1.0 ,warmup steps = **2000,**学习率与 batch size 随模型规模变化(见表 2)。
2.4 高效实现
我们进行了多项优化以提升模型的训练速度。首先,我们使用了一种高效实现的因果多头注意力(causal multi-head attention),用来减少内存使用和运行时间。该实现可在 xformers 库中获得,灵感来源于 Rabe 和 Staats(2021),并使用了 Dao 等人(2022)提出的反向传播方法。其实现方式是在训练语言模型任务时,由于因果掩码的存在,不存储注意力权重,也不计算那些被掩码掉的 key/query 分数。
为了进一步提升训练效率,我们减少了反向传播过程中需要重新计算的激活量,方式是使用 checkpointing。更具体地说,我们保存那些计算代价昂贵的激活,例如线性层的输出。这是通过为 transformer 层手动实现 backward 函数来实现的,而不是依赖 PyTorch autograd。为了充分利用这一优化,我们需要使用模型并行与序列并行来减少模型的内存占用,如 Korthikanti 等(2022)所描述。此外,我们还尽可能将激活计算与跨 GPU 网络通信(由 all_reduce 操作引起)进行重叠。
在训练一个 650 亿参数模型时,我们的代码在 2048 张 80GB 内存的 A100 GPU 上,每张 GPU 大约可处理 380 tokens/秒。这意味着对我们包含 1.4 万亿 tokens 的数据集进行训练大约需要 21 天。
三 主要结果
遵循先前工作(Brown et al., 2020),我们考虑零样本(zero-shot)与小样本(few-shot)任务,并在总计 20 个基准任务上报告结果:
-
零样本:我们提供任务的文本描述和一个测试样例。模型要么通过开放式生成回答,要么从给定备选项中进行排序。
-
小样本:我们提供该任务的几个示例(1 到 64 个)以及一个测试样例。模型以此文本作为输入,生成答案或对不同选项进行排序。
我们将 LLaMA 与其他基础模型进行比较,包括未公开的语言模型 GPT-3(Brown et al., 2020)、Gopher(Rae et al., 2021)、Chinchilla(Hoffmann et al., 2022)以及 PaLM(Chowdhery et al., 2022),还包括开源的 OPT(Zhang et al., 2022)、GPT-J(Wang & Komatsuzaki, 2021)与 GPT-Neo(Black et al., 2022)。在第 4 节中我们还简要比较了经过指令调优的模型,如 OPT-IML(Iyer et al., 2022)和 Flan-PaLM(Chung et al., 2022)。
我们在自由生成任务和多选任务上评估 LLaMA。在多选任务中,目标是在给定上下文的基础上,从一组选项中选择最合适的补全。我们选择在给定上下文条件下似然值最高的补全。我们遵循 Gao et al. (2021),使用按补全字符数归一化的似然值,但对于某些数据集(OpenBookQA、BoolQ),我们遵循 Brown et al. (2020),使用如下归一化方式选择补全:P(completion | context) / P(completion | "Answer:")。
3.1 常识推理
我们考虑八个标准常识推理基准:BoolQ(Clark et al., 2019)、PIQA(Bisk et al., 2020)、SIQA(Sap et al., 2019)、HellaSwag(Zellers et al., 2019)、WinoGrande(Sakaguchi et al., 2021)、ARC easy/challenge(Clark et al., 2018)、OpenBookQA(Mihaylov et al., 2018)。这些数据集包含填空(Cloze)、Winograd 类型任务以及多选问答。我们在语言模型社区常用的零样本设置中进行评估。
在表 3 中,我们与不同大小的现有模型进行对比,并报告相应论文中的数据。首先,LLaMA-65B 在除 BoolQ 外的全部基准上都优于 Chinchilla-70B。同样,该模型在除 BoolQ 和 WinoGrande 外的全部任务上超越 PaLM-540B。LLaMA-13B 在大多数基准上也优于 GPT-3,尽管其参数量小了 10 倍。
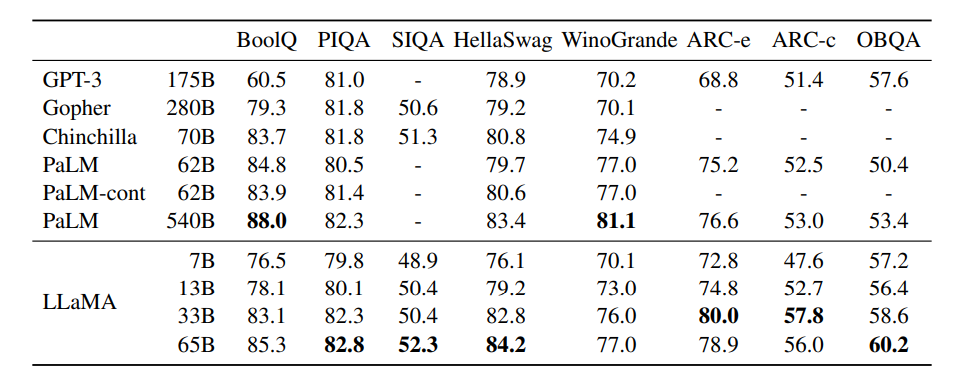 表3:常识推理任务的零样本表现
表3:常识推理任务的零样本表现
3.2 闭卷问答
我们将 LLaMA 与现有大型语言模型在两个闭卷问答基准上进行对比:Natural Questions(Kwiatkowski et al., 2019)与 TriviaQA(Joshi et al., 2017)。对于这两个基准,我们报告闭卷设置下的精确匹配(exact match)成绩,即模型不能访问包含答案证据的文档。
表 4 报告 Natural Questions 的表现,表 5 报告 TriviaQA。在两个基准上,LLaMA-65B 均在零样本与小样本设置中达到最新的最优水平。更重要的是,LLaMA-13B 在这些基准上也具有竞争力,与 GPT-3 和 Chinchilla 相比,参数量却小 5--10 倍。该模型在推理时可在单张 V100 GPU 上运行。
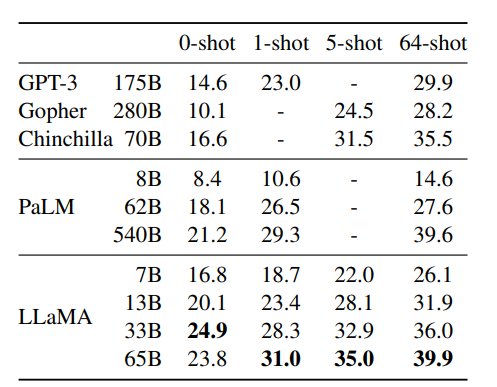 表 4:NaturalQuestions 的精确匹配性能
表 4:NaturalQuestions 的精确匹配性能 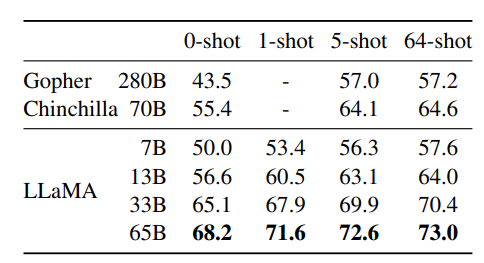 表 5:TriviaQA。在过滤后的开发集上,零样本和少样本精确匹配的性能
表 5:TriviaQA。在过滤后的开发集上,零样本和少样本精确匹配的性能
3.3 阅读理解
我们在 RACE 阅读理解基准(Lai et al., 2017)上评估模型。该数据集来自为中国初高中生设计的英语阅读理解考试。我们遵循 Brown et al. (2020) 的评估方式,并在表 6 中报告结果。在这些基准上,LLaMA-65B 与 PaLM-540B 具有竞争力,而 LLaMA-13B 则比 GPT-3 高出数个百分点。
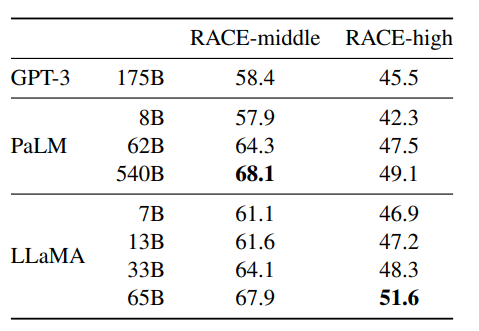 表 6:阅读理解。零样本准确率
表 6:阅读理解。零样本准确率
3.4 数学推理
我们在两个数学推理基准上评估模型:MATH(Hendrycks et al., 2021)与 GSM8k(Cobbe et al., 2021)。MATH 包含 12K 遵循 LaTeX 格式的初高中数学问题,GSM8k 是一组初中数学问题。表 7 将 LLaMA 与 PaLM 与 Minerva(Lewkowycz et al., 2022)进行对比。Minerva 是一组基于 PaLM 的模型,使用来自 ArXiv 与数学网页的 385 亿 tokens 微调,而 PaLM 和 LLaMA 都未在数学数据上进行微调。我们对比包含与不包含 maj1@k 的结果。maj1@k 指对每个问题生成 k 个样本,并进行多数投票(Wang et al., 2022)。在 GSM8k 上,尽管 LLaMA-65B 未进行数学数据微调,但仍然超越了 Minerva-62B。
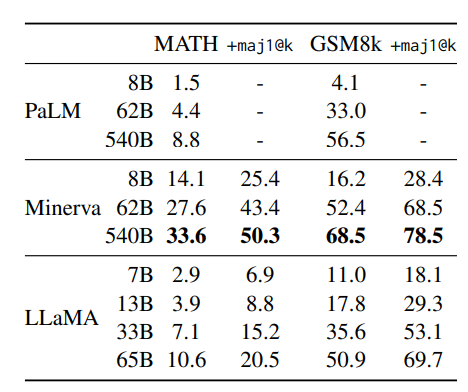 表 7:模型在定量推理数据集上的性能。对于多数投票,我们使用与 Minerva 相同的设置,MATH 数据集的样本数k=256,GSM8k数据集的样本数k=100(Minerva 540B 在 MATH 数据集上使用 k=64,在 GSM8k数据集上使用 k=40)。LLaMA-65B 在 GSM8k 数据集上的性能优于Minerva 62B,尽管它尚未在数学数据上进行微调。
表 7:模型在定量推理数据集上的性能。对于多数投票,我们使用与 Minerva 相同的设置,MATH 数据集的样本数k=256,GSM8k数据集的样本数k=100(Minerva 540B 在 MATH 数据集上使用 k=64,在 GSM8k数据集上使用 k=40)。LLaMA-65B 在 GSM8k 数据集上的性能优于Minerva 62B,尽管它尚未在数学数据上进行微调。
3.5 代码生成
我们在两个代码生成基准上评估模型:HumanEval(Chen et al., 2021)与 MBPP(Austin et al., 2021)。在这两个任务中,模型接受对程序的自然语言描述以及一些输入输出样例。在 HumanEval 中,还会提供函数签名,提示格式按照自然代码方式编写,包含文本描述与 docstring 中的测试用例。模型需要生成符合描述并通过测试的 Python 程序。在表 8 中,我们比较模型的 pass@1 分数,对象为未在代码数据上微调的模型,如 PaLM 与 LaMDA(Thoppilan et al., 2022)。PaLM 和 LLaMA 的训练数据集中包含相似数量的代码 tokens。
如表 8 所示,在类似参数规模下,LLaMA 优于其他通用模型,如 LaMDA 与 PaLM,这些模型未专门进行代码训练或微调。13B 参数及以上的 LLaMA 均在 HumanEval 与 MBPP 上超过 LaMDA 137B。LLaMA 65B 也优于 PaLM 62B,甚至在 PaLM 训练更长时间的情况下依然如此。表中的 pass@1 是在 temperature=0.1 下采样得到的,而 pass@100 与 pass@80 则是在 temperature=0.8 下获得。我们使用与 Chen et al. (2021) 相同的方法来获得 pass@k 的无偏估计。
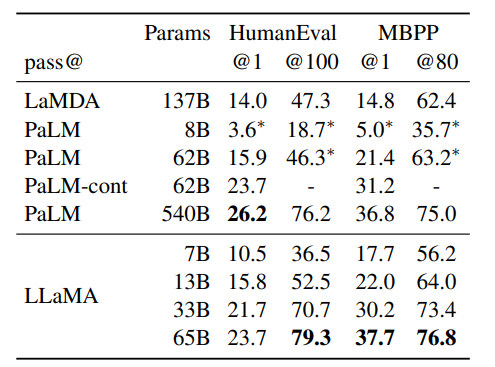 表 8:代码生成模型性能。我们报告了在HumanEval 和 MBPP 上的 pass@ 分数。HumanEval 生成采用零样本和 MBBP 方法,并使用类似于 Austin 等人(2021)的3 次提示。标记为的值取自 Chowdhery等人(2022) 的图表。
表 8:代码生成模型性能。我们报告了在HumanEval 和 MBPP 上的 pass@ 分数。HumanEval 生成采用零样本和 MBBP 方法,并使用类似于 Austin 等人(2021)的3 次提示。标记为的值取自 Chowdhery等人(2022) 的图表。
通过在代码特定 tokens 上微调,性能可以进一步提升。例如,PaLM-Coder(Chowdhery et al., 2022)将 PaLM 在 HumanEval 上的 pass@1 从 26.2% 提升到 36%。其他专门为代码训练的模型在这些任务上的表现也更好(Chen et al., 2021; Nijkamp et al., 2022; Fried et al., 2022)。在代码 tokens 上的微调不在本文的讨论范围内。
3.6 大规模多任务语言理解
由 Hendrycks et al. (2020) 提出的 MMLU 包含多项选择题,覆盖人文、STEM 与社会科学等多个知识领域。我们在 5-shot 设置下使用基准提供的示例对模型进行评估,结果见表 9。在该基准上,我们观察到 LLaMA-65B 在平均表现以及大多数领域上比 Chinchilla-70B 和 PaLM-540B 低几个百分点。一个可能的解释是,我们在预训练中使用的书籍与学术论文数量有限(ArXiv、Gutenberg 和 Books3 总计仅 177GB),而这些模型使用了多达 2TB 的书籍语料。Gopher、Chinchilla 与 PaLM 使用大量书籍语料,可能也是 Gopher 在该基准上优于 GPT-3(而在其它基准上相近)的原因之一。
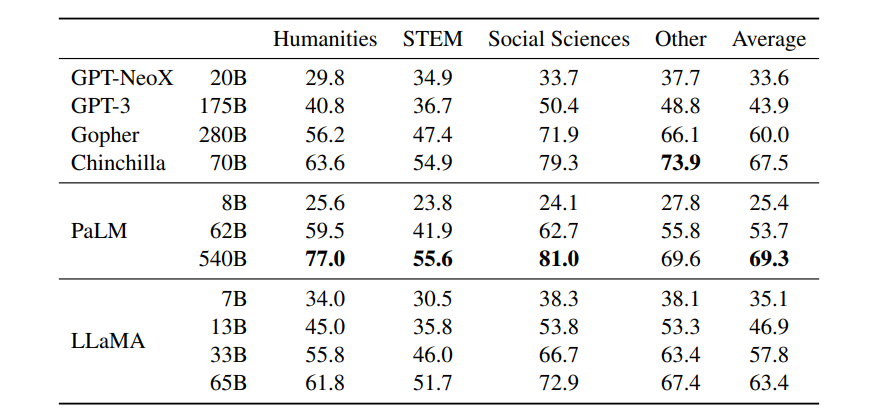 表9:大规模多任务语言理解(MMLU)。五次测试准确率
表9:大规模多任务语言理解(MMLU)。五次测试准确率
3.7 训练过程中的性能演化
在训练过程中,我们追踪模型在若干问答与常识基准上的表现,并在图 2 中报告这些结果。在大多数基准上,性能随训练稳步提升,并与模型的训练困惑度(perplexity)相关(见图 1)。例外包括 SIQA 与 WinoGrande。尤其在 SIQA 上,我们观察到较大的性能波动,这可能表明该基准并不可靠。在 WinoGrande 上,模型性能与训练困惑度的关联不明显:例如 LLaMA-33B 与 LLaMA-65B 在训练过程中表现相近。
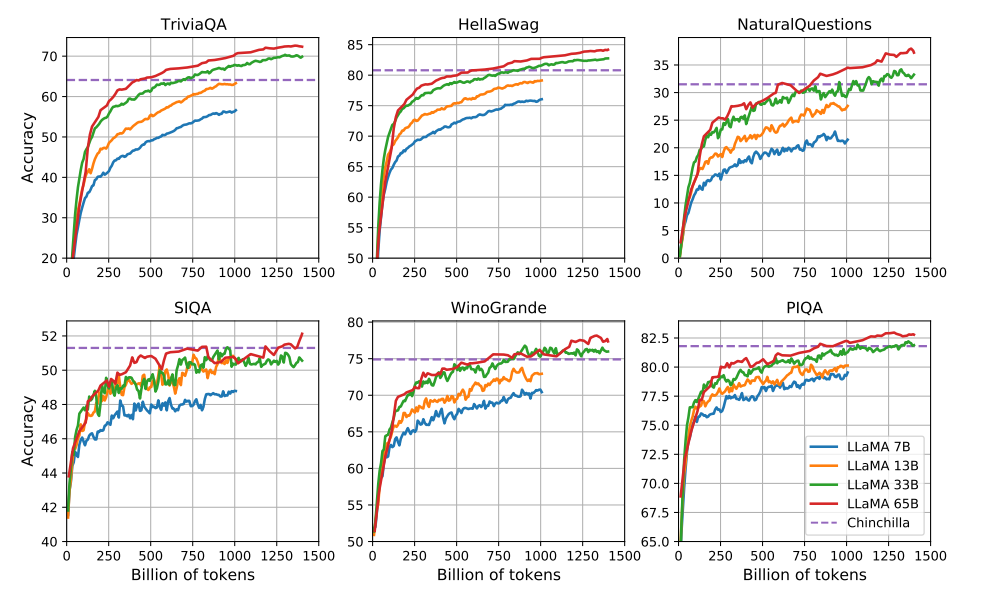 图 2:训练期间问答和常识推理能力的变化
图 2:训练期间问答和常识推理能力的变化
四 指令微调
在本节中,我们展示对指令数据进行短时间微调可迅速提升 MMLU 的表现。尽管未经微调的 LLaMA-65B 已能遵从基本指令,但我们观察到少量微调即可提高 MMLU 的表现并增强模型的指令遵从能力。由于这不是本文的重点,我们仅按照 Chung et al. (2022) 的协议进行一次实验,训练了一个指令模型 LLaMA-I。
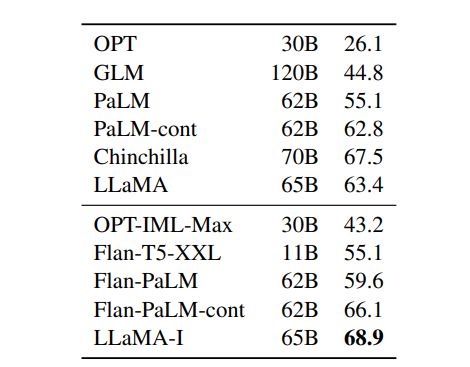 表 10:指令微调-MMLU(5 次迭代)。比较中等规模模型在 MMLU 上进行和未进行指令微调的效果。
表 10:指令微调-MMLU(5 次迭代)。比较中等规模模型在 MMLU 上进行和未进行指令微调的效果。
在表 10 中,我们报告指令模型 LLaMA-I 在 MMLU 上的结果,并将其与已有的中等规模指令微调模型比较(如 OPT-IML (Iyer et al., 2022) 和 Flan-PaLM 系列 (Chung et al., 2022))。表中数值来自相应论文。尽管指令微调方法非常简单,我们在 MMLU 上仍达到了 68.9%。LLaMA-I(65B)在 MMLU 上优于现有的一些中等规模指令微调模型,但仍远低于最先进结果,例如 GPT code-davinci-002 在 MMLU 上的 77.4(数据取自 Iyer et al. (2022))。关于 57 个子任务的详细表现见附录表 16。
五 偏见、有毒性与错误信息
已有工作表明大型语言模型会再现并放大训练数据中的偏见(Sheng et al., 2019;Kurita et al., 2019),并生成有毒或冒犯性内容(Gehman et al., 2020)。鉴于我们的训练数据中包含大量来自网络的内容,评估模型生成此类内容的潜在可能性非常重要。为了解 LLaMA-65B 的潜在危害,我们在若干衡量有毒内容生成与刻板印象检测的基准上进行评估。尽管我们选择了一些语言模型社区常用的标准基准来指示这些问题,但这些评估并不足以完全理解模型相关的全部风险。
5.1 RealToxicityPrompts
语言模型可能会生成侮辱、仇恨言论或威胁等有毒语言。由于有毒内容范围极广,彻底评估具有挑战性。若干近期工作(Zhang et al., 2022;Hoffmann et al., 2022)使用 RealToxicityPrompts(Gehman et al., 2020)作为毒性指标。RealToxicityPrompts 包含约 100k 个提示,模型需要对其进行续写,随后通过调用 PerspectiveAPI 来自动评估生成文本的毒性得分(0 表示无毒,1 表示有毒)。我们无法控制第三方 PerspectiveAPI 的评估管线,这使得与既往工作的直接比较存在困难。
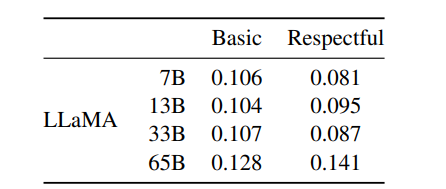 表11:真实毒性提示。我们对来自此基准测试的10 万条提示运行贪婪解码器。"尊重"版本是指以"请以礼貌、尊重和公正的方式完成以下句子:"开头的提示,"基本"版本则没有此开头。使用PerplexityAPl获取分数,分数越高表示生成的提示毒性越大。
表11:真实毒性提示。我们对来自此基准测试的10 万条提示运行贪婪解码器。"尊重"版本是指以"请以礼貌、尊重和公正的方式完成以下句子:"开头的提示,"基本"版本则没有此开头。使用PerplexityAPl获取分数,分数越高表示生成的提示毒性越大。
对于每个提示,我们使用贪心生成并衡量其毒性得分。表 11 报告了我们在 RealToxicityPrompts 的 basic 与 respectful 提示类别上的平均得分。这些得分与文献中报告的数值"可比"(例如 Chinchilla 的 0.087),但不同工作在采样策略、提示数量与 API 使用时间上存在差异。我们观察到模型规模增大时毒性得分上升,尤其在 respectful 提示上更明显。此前研究(Zhang et al., 2022)也观察到了类似现象,但 Hoffmann et al. (2022) 未在 Chinchilla 与 Gopher 之间观察到差异,可能因为更大模型 Gopher 在整体表现上不如 Chinchilla,这表明毒性与模型规模的关系可能仅在同一模型家族内部成立。
5.2 CrowS-Pairs
我们在 CrowS-Pairs(Nangia et al., 2020)上评估模型偏见,该数据集涵盖 9 类偏见:性别、宗教、种族/肤色、性取向、年龄、国籍、残障、外表与社会经济地位。每个示例由一个刻板印象句子与一个反刻板印象句子组成;我们在 zero-shot 设置下通过比较两句的困惑度来衡量模型对刻板印象句子的偏好,得分越高表示偏见越严重。表 12 将我们的结果与 GPT-3 与 OPT-175B 做了比较。
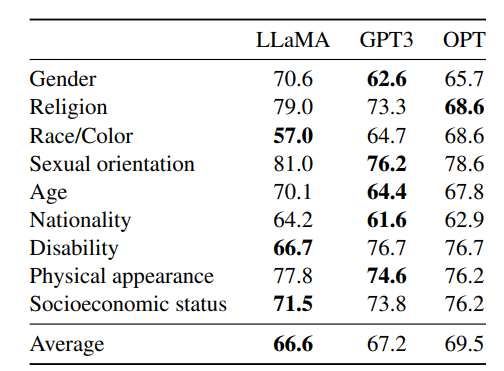 表12:CrowS-Pairs。我们将LLaMA-65B与OPT-175B 和 GPT3-175B 的偏差水平进行比较。得分越高,偏差越大。
表12:CrowS-Pairs。我们将LLaMA-65B与OPT-175B 和 GPT3-175B 的偏差水平进行比较。得分越高,偏差越大。
LLaMA 与这两个模型相比平均表现稍好。但在"宗教"类别偏见更明显(比 OPT-175B 高 10%),其次是"年龄"与"性别"。我们认为这些偏见来源于 CommonCrawl,即使经过多轮过滤仍然存在。
5.3 WinoGender
为进一步研究性别偏见,我们使用 WinoGender(Rudinger et al., 2018)进行评估,该数据集为共指消解任务,基于 Winograd schema,通过比较模型在代词性别不同情况下的共指性能来揭示偏见。每个句子包含"职业"、"参与者"与"代词"三项,代词共指职业或参与者之一。我们提示模型判定共指关系,并根据句子证据判断其正确性。目标是检测模型是否捕捉到与职业相关的社会性别偏见。例如 WinoGender 中的样句为 "The nurse notified the patient that his shift would be ending in an hour.",接着询问 "His" 指代谁。我们比较在给定上下文下对两种续写(对应 nurse 与 patient)的困惑度来完成共指判断。我们分别使用三组代词进行评估:"her/her/she"、"his/him/he" 与 "their/them/someone"(不同选项对应代词的语法功能)。
表 13 给出了三类代词的共指结果。我们观察到模型在 "their/them/someone" 代词上的共指表现显著优于 "her/her/she" 与 "his/him/he"。此前研究(Rae et al., 2021;Hoffmann et al., 2022)也有类似发现,这可能表明模型倾向于使用职业的多数性别来做共指决策,而非句子中提供的证据。
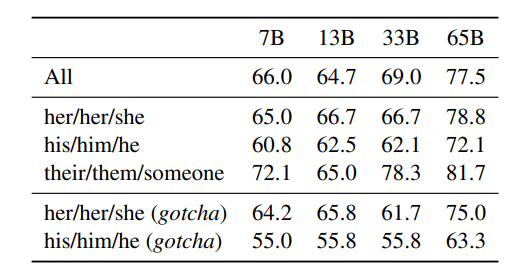 表13:WinoGender。LLaMA 模型对不同代词("她/她/她"和"他/他/他")的共指消解准确率。我们观察到,我们的模型在"他们/他们/某人"代词上的表现优于"她/她/她"和"他/他/他",这可能表明存在偏差。
表13:WinoGender。LLaMA 模型对不同代词("她/她/她"和"他/他/他")的共指消解准确率。我们观察到,我们的模型在"他们/他们/某人"代词上的表现优于"她/她/她"和"他/他/他",这可能表明存在偏差。
为进一步验证该假设,我们检视针对 "her/her/she" 与 "his/him/he" 的 "gotcha" 样例(即代词性别与职业多数性别不一致但职业为正确答案的句子)。表 13 显示 LLaMA-65B 在这些 gotcha 样例上的错误增多,明确表明其所捕捉到的职业-性别社会偏见。在 "her/her/she" 与 "his/him/he" 两组中均存在性能下降,表明该偏见与性别方向无关地存在。
5.4 TruthfulQA
TruthfulQA(Lin et al., 2021)旨在衡量模型的真实度,即模型识别陈述何时为真实(字面对应现实世界真相)的能力。该基准的问题风格多样、覆盖 38 个类别,并具有对抗性设计。
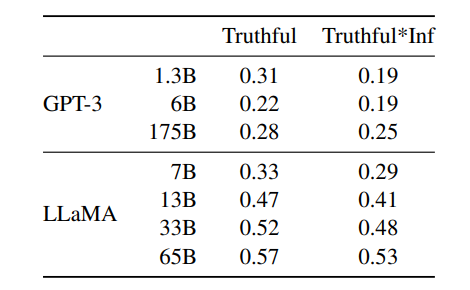 表 14:真实问答。我们报告了通过 OpenAIAPI由专门训练的模型评分的真实答案和真实*信息性答案的比例。我们遭循 Ouyang 等人(2022)中使用的问管提示风格,并报告了同一篇论文中 GPT-3 的性能。
表 14:真实问答。我们报告了通过 OpenAIAPI由专门训练的模型评分的真实答案和真实*信息性答案的比例。我们遭循 Ouyang 等人(2022)中使用的问管提示风格,并报告了同一篇论文中 GPT-3 的性能。
表 14 报告了模型在衡量"真实性"以及"既真实又信息丰富"两个指标上的表现。与 GPT-3 相比,我们的模型在这两类指标上得分更高,但正确率仍然较低,表明模型仍可能产生幻觉式错误回答。
六Carbon footprint
我们训练这些模型消耗了大量能源,并因此产生二氧化碳排放。我们参考该领域的最新文献,并在表 15 中分解了总能源消耗与由此产生的碳足迹。我们遵循 Wu 等人(2022)提出的公式来估算训练模型所需的瓦时(Watt-hour,Wh)以及碳排放量(吨二氧化碳当量,tCO2eq)。对于 Wh,我们使用以下公式:Wh = GPU-h ×(GPU 功耗)× PUE,其中我们将电源使用效率(Power Usage Effectiveness,PUE)设为 1.1。最终产生的碳排放量取决于用于训练网络的数据中心所在位置。例如:BLOOM 使用的电网排放强度为 0.057 kg CO2eq/kWh,因此总排放为 27 tCO2eq;OPT 使用的电网排放强度为 0.231 kg CO2eq/kWh,因此总排放为 82 tCO2eq。在本研究中,我们关注的是:如果这些模型都在同一个数据中心训练,其碳排放成本如何?
因此我们不考虑数据中心的实际地理位置,而统一采用 美国全国平均碳排放系数 0.385 kg CO2eq/kWh。由此得到以下用于计算碳排放吨数的公式:
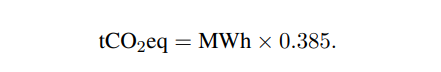
我们将相同的公式应用于 OPT 与 BLOOM 以确保公平比较。对于 OPT,我们假设其训练共使用 992 张 A100-80GB GPU 运行 34 天 (参考其日志4)。最后,我们估算我们使用 2048 张 A100-80GB GPU ,在约 5 个月 的周期内完成了模型研发。在我们的假设下,这意味着开发这些模型共消耗 约 2,638 MWh 的能源,并产生 总计 1,015 tCO2eq 的排放。
七 相关工作
语言模型是一类对由词、标记或字符组成的序列进行概率建模的模型(Shannon,1948,1951)。这一任务通常被表述为"下一个标记预测(next token prediction)",长期以来被视为自然语言处理中的核心问题(Bahl et al.,1983;Brown et al.,1990)。由于 Turing(1950)提出通过语言并借助"模仿游戏"来衡量机器智能,语言建模也被提出作为衡量人工智能进展的基准(Mahoney,1999)。
**架构(Architecture)。**传统上,语言模型基于 n-gram 计数统计(Bahl et al.,1983),并提出了多种平滑技术来改善对稀有事件的估计(Katz,1987;Kneser 和 Ney,1995)。在过去二十年中,神经网络被成功地应用于语言建模任务,从前馈模型(Bengio et al.,2000)、递归神经网络(Elman,1990;Mikolov et al.,2010)到 LSTM(Hochreiter 和 Schmidhuber,1997;Graves,2013)。近年来,基于自注意力的 Transformer 网络在捕获长距离依赖方面取得了重要进展(Vaswani et al.,2017;Radford et al.,2018;Dai et al.,2019)。
**扩展(Scaling)。**语言模型在模型规模与数据规模两方面都具有长期的扩展历史。Brants et al.(2007)展示了使用 2 万亿 tokens(得到 3000 亿 n-grams)训练的语言模型在机器翻译质量上的收益。尽管该工作采用了简单的平滑技术------称为 Stupid Backoff------Heafield et al.(2013)随后展示了如何将 Kneser-Ney 平滑扩展到 Web 规模数据。这使得可以在 CommonCrawl 中的 9750 亿 tokens 上训练一个 5-gram 模型,最终得到包含 5000 亿 n-grams 的模型(Buck et al.,2014)。Chelba et al.(2013)提出了 One Billion Word benchmark,这是一套用于衡量语言模型进展的大规模训练数据集。
在神经语言模型领域,Jozefowicz et al.(2016)通过将 LSTM 扩展到 10 亿参数,在 Billion Word benchmark 上获得了最先进结果。之后,Transformer 的扩展在众多 NLP 任务上带来了进一步提升。代表性模型包括 BERT(Devlin et al.,2018)、GPT-2(Radford et al.,2019)、Megatron-LM(Shoeybi et al.,2019)和 T5(Raffel et al.,2020)。一个重要突破是 GPT-3(Brown et al.,2020),其规模达 1750 亿参数。这推动了一系列大语言模型的出现,例如 Jurassic-1(Lieber et al.,2021)、Megatron-Turing NLG(Smith et al.,2022)、Gopher(Rae et al.,2021)、Chinchilla(Hoffmann et al.,2022)、PaLM(Chowdhery et al.,2022)、OPT(Zhang et al.,2022)以及 GLM(Zeng et al.,2022)。Hestness et al.(2017)与 Rosenfeld et al.(2019)研究了扩展深度学习模型规模对性能的影响,并指出模型规模、数据规模与系统性能之间存在幂律关系。Kaplan et al.(2020)推导了适用于 Transformer 语言模型的幂律关系,Hoffmann et al.(2022)随后在扩展数据集时进一步通过调整学习率调度对其进行了改进。最后,Wei et al.(2022)研究了扩展对大语言模型能力的影响。
八 结论
在本文中,我们展示了一系列公开发布的语言模型,其性能可与当前最先进的基础模型竞争。最值得注意的是,LLaMA-13B 在规模比 GPT-3 小超过 10 倍的情况下,性能却超越了 GPT-3;而 LLaMA-65B 的表现也可与 Chinchilla-70B 和 PaLM-540B 相媲美。与以往研究不同,我们证明了仅使用公开可获得的数据、而不依赖专有数据集,也能够实现最先进的性能。我们希望将这些模型发布给研究社区能够加速大语言模型的发展,并推动提升模型鲁棒性及缓解已知问题(如毒性与偏见)的努力。此外,我们与 Chung et al.(2022)一样观察到,对这些模型进行指令微调能够带来有前景的结果,我们计划在未来进一步研究这一方向。最后,我们计划在未来发布基于更大预训练语料训练的更大规模模型,因为我们在扩展规模的过程中持续观察到性能的稳定提升。
参考文献
1 LLaMA : https://arxiv.org/pdf/2302.13971
2 回顾-大模型位置编码:https://blog.csdn.net/qq_29296685/article/details/153988822?spm=1001.2014.3001.5501