0. 具身智能与自动驾驶----相似的VLA
具身智能拥有支持感知和运动的物理身体,可以进行主动式感知,也可以执行物理任务。更重要的是,具身智能强调"感知-行动回路"(perception-action loop)的重要性,即感受世界-对世界进行建模-进而采取行动-进行验证并调整模型的过程。
自动驾驶与具身智能高度重合,两者共享类似的架构:大脑、小脑和身体三个核心部件。在自动驾驶系统中,身体部分替换为底盘控制系统,而大脑部分几乎完全一致,都致力于解决物理世界(驾驶环境)常识认知的问题,构建"感知-推理-预测-行动"的模型,即我们所说的VLA(Vision-Language-Action)。
1. VLA的起源与定义
VLA最早由谷歌在RT-2机器人项目中提出,而RT-1则首次将transformer引入机器人领域。VLA可以理解为直接理解复杂指令从而直接操控机械臂,相当于自动驾驶领域中的一段式或全局式端到端控制系统。
从技术角度看,VLA实际是VLM(Vision-Language Model)的延伸,其中A代表Action,可以是高维度的简单动作描述(如"超越前车再回到原车道"),也可以是低维度的具体Waypoint动作描述。传统的VLM主要用于VQA(Visual Question Answering)任务,而VLA则进一步实现了从视觉理解到物理动作的端到端映射。
2. 自动驾驶与机器人的控制差异
具身智能的小脑部分较为复杂,而自动驾驶则相对简单,通常不需要过多描述。自动驾驶可以依靠VLM解码出waypoint坐标,然后用MPC(Model Predictive Control)模型预测控制算法将waypoint坐标分解为横向和纵向控制,交给电机和转向机构负责。
在自由度方面,车辆通常只需6自由度,而具身智能机器人最高可达35自由度,动作精确度及连贯度要求极高。机器人控制需要处理复杂的任务、约束与求解(结合机器人的构型等硬件参数求解出达到运动任务所需要的各关节的控制参数)、关节伺服控制,以及状态估计等问题。
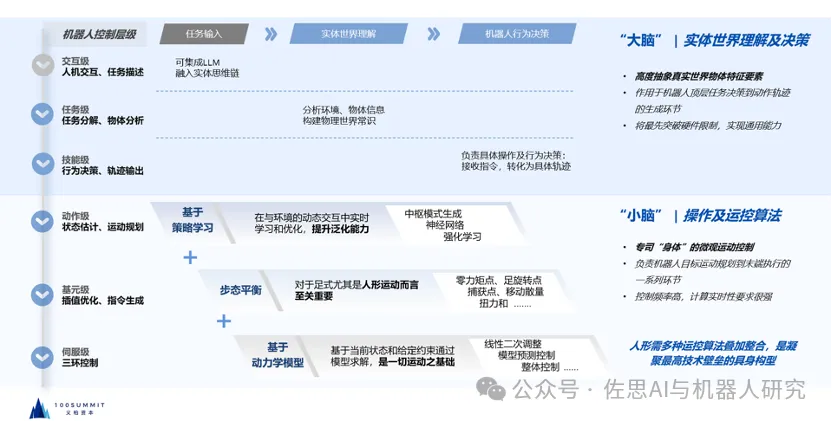
3. 机器人控制的层级
机器人的控制层级可分为6级:
- 交互级
- 任务级(Task Level)
- 技能级(Skill Level)
- 动作级(Motion Level)
- 基元级(Primitive Level)
- 伺服级(Servo Level)
目前,诸多与语言大模型结合的研究主要集中在交互级,而Low-Level指的是技能级。例如人形机器人在伺服级控制的频率需要超过1000Hz。
4. 典型的机器人VLA架构
4.1 谷歌RT-2:机器人VLA的开山之作
RT-2是谷歌开发的VLA模型,它基于多模态大模型PaLI-X(55B参数)、PaLI(3B)和PaLM-E(12B),通过微调使其能够控制机器人。其核心是将机器人动作表示为模型输出中的token,每个维度的动作被量化为256个token,以此建立从视觉理解到物理动作的映射关系。
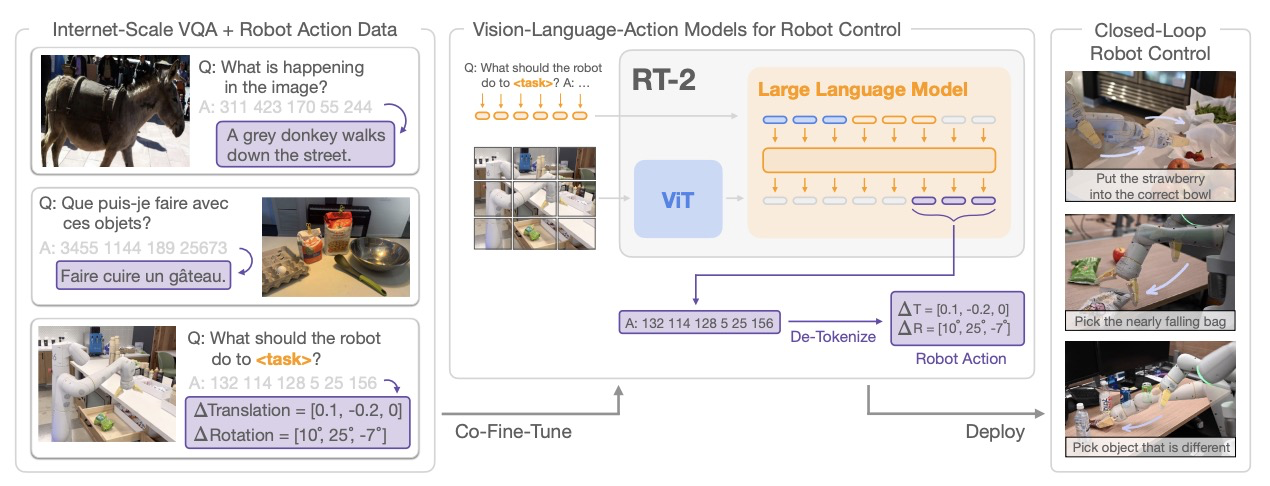
RT-2将VLA分为Plan和Action两个层级,类似于自动驾驶中的高维度驾驶策略与低维度指令的waypoint。但RT-2的决策频率仅为1-5Hz,难以实现高频率的实时操控。
4.2 OpenVLA:首个真正开源的VLA框架
OpenVLA由丰田、谷歌、斯坦福、UC巴克利合作开发,于2024年3月公布。它使用Meta的Llama 2 7B作为基础模型,比RT-2使用的PaLI-X小很多。其架构包括两个并行的视觉编码器(共6亿参数),通过MLP投影将视觉编码与语言对齐,最终进入LLM处理并输出控制token。
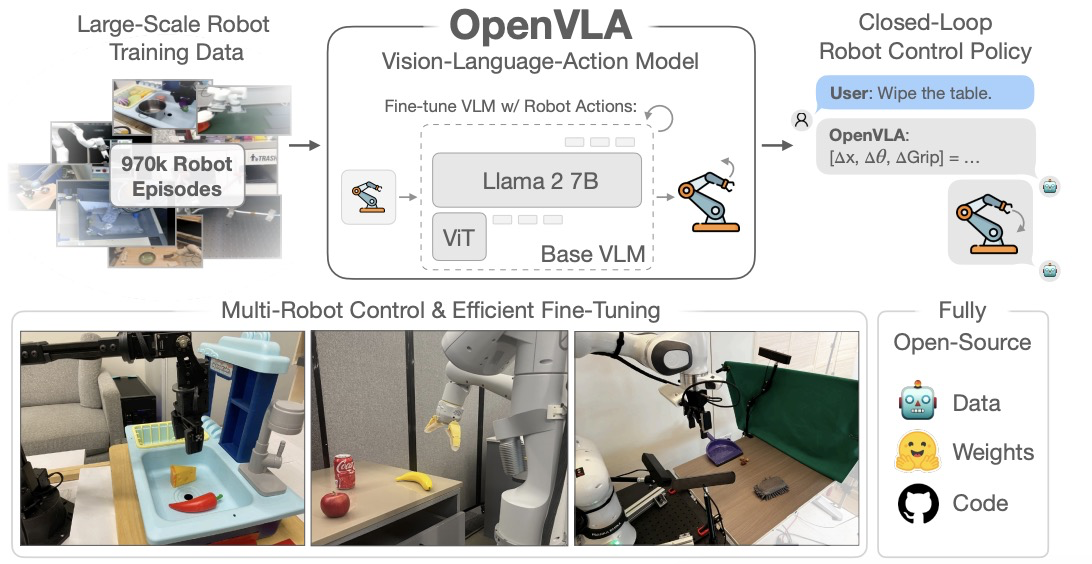
OpenVLA的最大特色是真正的开源,包括权重、数据和代码,而之前的VLA系统都是封闭的。它还提供了用于训练VLA模型的模块化PyTorch代码库,支持从单GPU微调到多节点GPU集群训练。
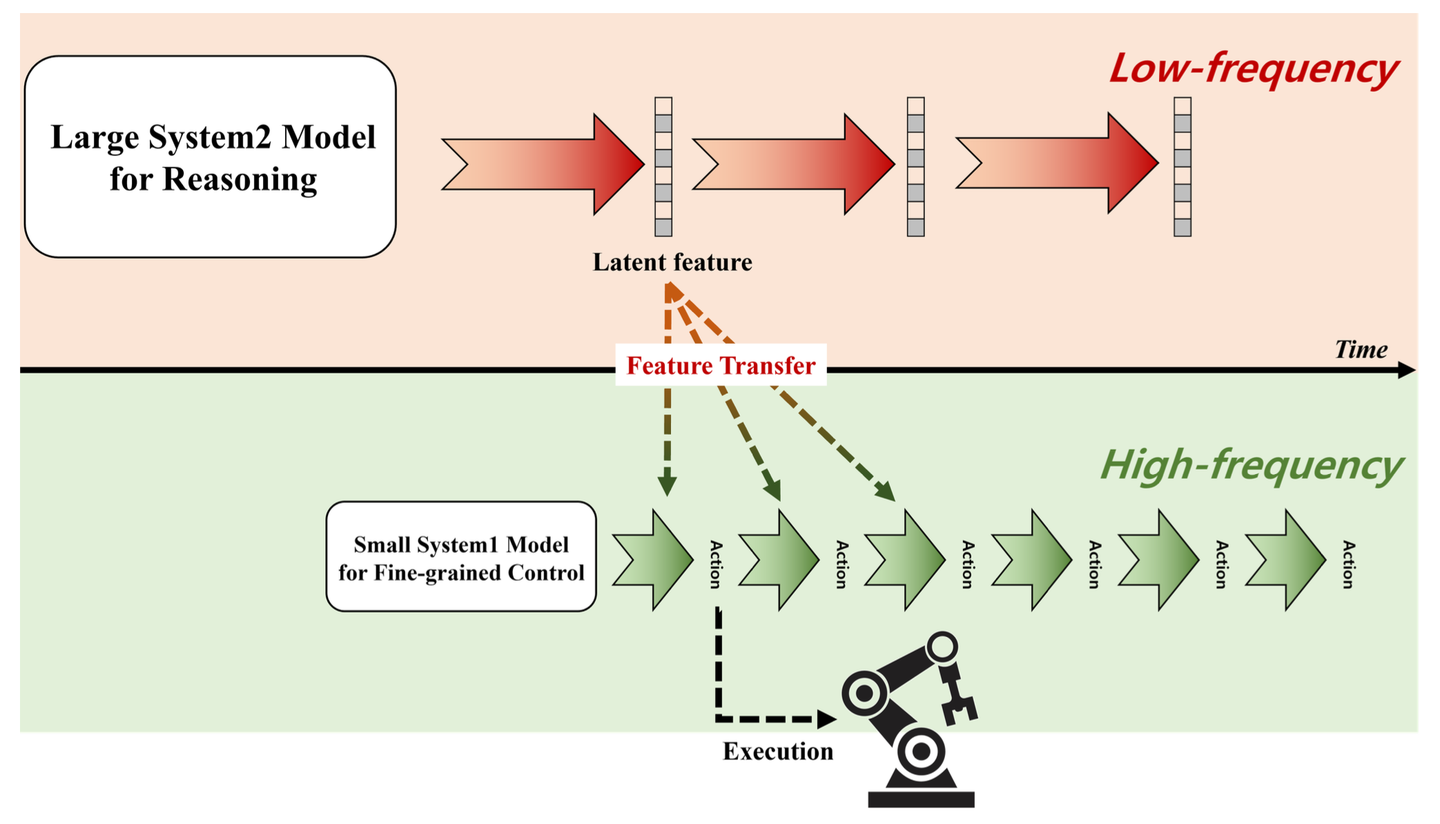
4.3 快慢双系统:机器人VLA的发展趋势
随着技术发展,机器人领域出现了快慢双系统架构,这与自动驾驶领域的发展趋势相似。韩国ETRI和Figure.AI的Helix都采用了双系统设计,结合了VLM的强大理解能力和轻量级模型的快速响应能力。
高通的DiMA框架也采用分层设计:上层(理解层)基于多模态大模型进行任务规划,输出文本动作序列;下层(操作层)负责将技能标识和环境信息转换为精确的末端姿态或关节角度。
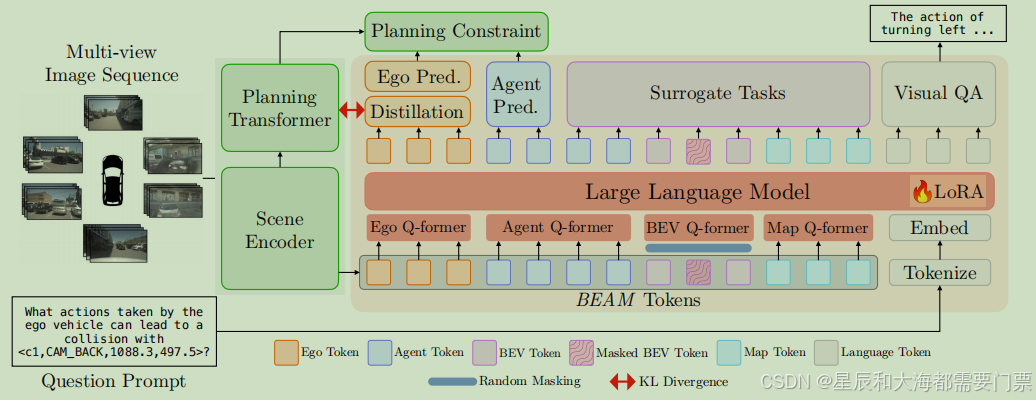
4.4 Figure.AI的Helix:最接近量产的机器人VLA系统
Helix是Figure.AI于2025年2月发布的VLA模型,被认为是机器人领域最接近量产的VLA系统。其优势包括:
- 高速响应:达到200Hz的操作速度,远超RT-2的1-5Hz
- 简化架构:通过单一大模型,直接从自然语言获得最终Action
- 高效训练:无需专门微调不同的高级行为
- 强大泛化能力:直接输出高维动作空间的连续控制
- 低数据需求:仅使用约500小时高质量监督数据,远低于一般VLA所需的1万小时起步
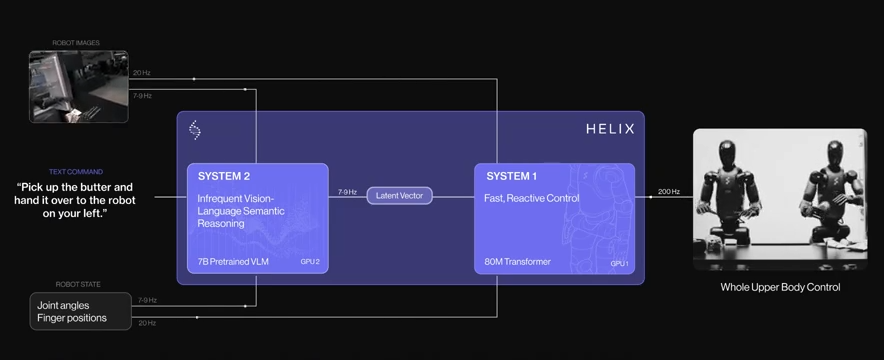
Helix采用了双系统架构:系统2是70亿参数的VLM,运行频率达到7-9Hz;系统1是参数量仅8000万的轻量级模型,能够以200Hz的频率生成精确的连续机器人动作,包括手腕姿势、手指控制和身体方向等35个自由度的控制信号。
5. VLA在自动驾驶中的应用
5.1 特斯拉的端到端自动驾驶尝试
特斯拉是VLA在自动驾驶领域的早期探索者,其FSD(全自动驾驶)系统采用了类似VLA的思路,尝试从视觉输入直接生成控制指令。特斯拉AI总监Andrej Karpathy曾提出"视觉即语言"的概念,将驾驶场景理解视为一种类似语言处理的任务。
特斯拉的端到端方法虽然理念上接近VLA,但仍需克服实时性、安全性和可解释性等挑战。