在大模型与人工智能迅猛发展的今天,我们正处在一个"数据爆炸"的时代。据 IDC 统计,2025 年全球数据总量将达到 175 ZB,其中超过 90% 为图片、视频等非结构化数据。这些数据蕴藏着巨大的商业价值,但如何高效存储、检索并挖掘其深层语义信息,成为企业面临的核心挑战。
而这一切的关键,正是------向量化。
无论是图像特征提取,还是大语言模型对自然语言的理解,都依赖于将原始数据转化为高维向量。随着 AI 应用的普及,向量数据的增长速度已远超传统结构化数据。在阿里云平台上,新增的向量数据量已是传统结构化数据的两倍以上。
面对如此庞大的向量洪流,一个专业、高效、可扩展的向量检索引擎变得至关重要。
为什么选择 Milvus?因为它生来就是为向量而设计
市面上虽有不少支持向量能力的数据库,但多数是在原有架构上"叠加"功能。而 Milvus ,从诞生之初就专注于向量数据的存储与检索,是全球最成熟、最流行的开源向量数据库之一。

- GitHub Star 超过3万,已成为向量检索领域的事实标准
- 支持 HNSW 、IVF 等多种先进索引算法,兼顾精度与性能
- 提供丰富的量化与 GPU 加速能力(如 Milvus 2.6 版本已支持 GPU 索引),大幅提升查询效率
- 原生支持标量过滤,满足复杂业务场景下的混合查询需求
- 云原生存储架构,天然支持存算分离,轻松应对海量数据扩展
然而,尽管开源 Milvus 功能强大,企业在自建过程中仍面临诸多痛点:
- 元数据依赖 ETCD ,在高并发下易成瓶颈
- 消息队列依赖 Kafka ,运维复杂度高
- 弹性伸缩能力有限,难以应对动态负载
- 容错机制需自行实现,资源管理成本高昂
这些问题,让许多企业望而却步。
阿里云 Milvus:全托管、高性能、免运维的向量数据库服务
为此,阿里云正式推出全托管 Milvus 服务 ,帮助企业轻松迈入向量数据时代。阿里云 Milvus 不仅继承了开源 Milvus 的所有优势,更在此基础上进行了深度优化和增强,真正实现了"开箱即用"。 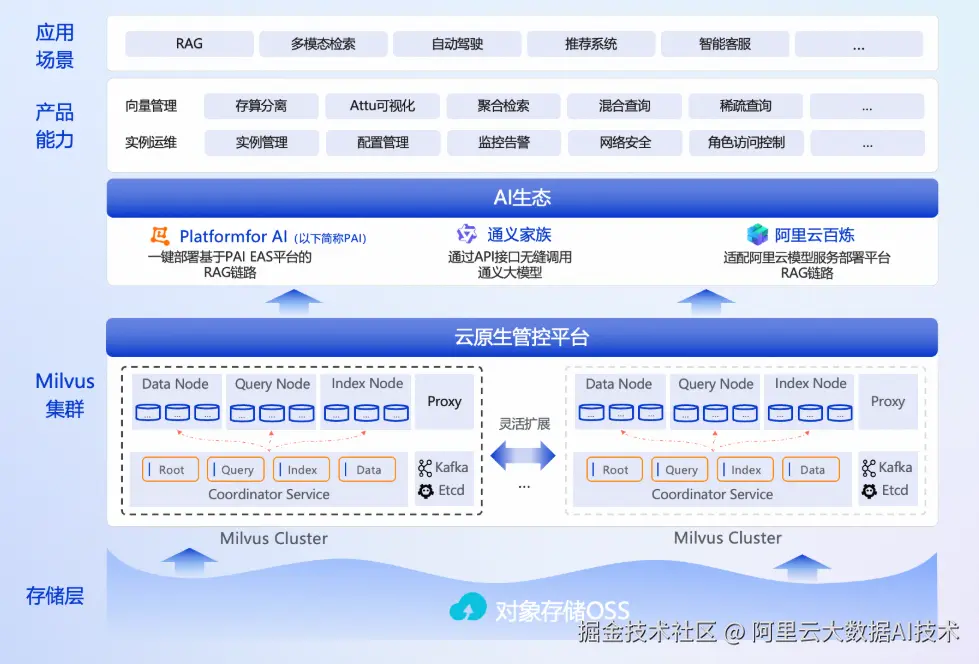
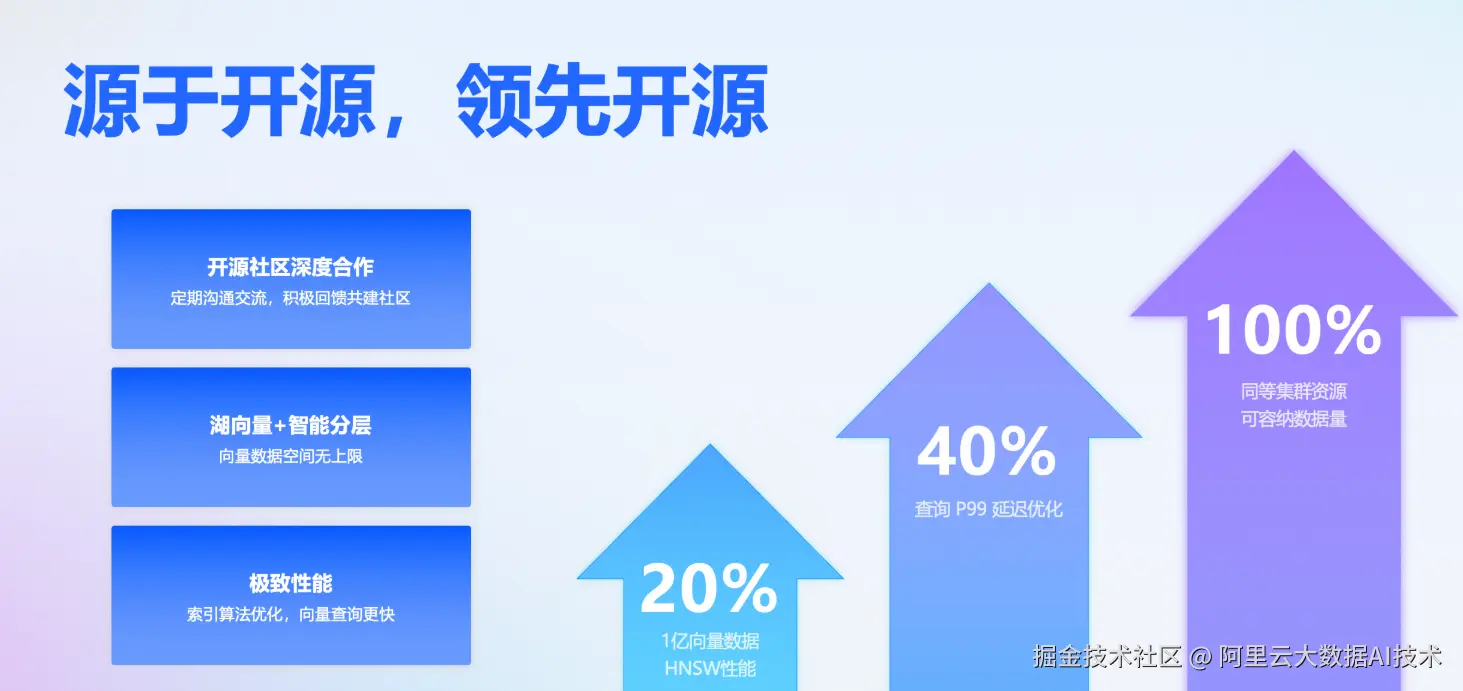
更强内核:百亿级向量,高效稳定
- 支持百亿级向量存储与检索,适用于超大规模应用场景
- 大规模向量检索性能相比开源版本提升 20% 以上,P99 延迟降低 40%
- 同等资源配置下,向量存储容量提升一倍
- 综合性能较同类产品领先 1 倍以上 ,性价比提升 3 到 4 倍
- 存算分离架构,显著降低存储成本。
更优平台:全托管 Serverless,弹性无忧
- 免运维设计:元数据管理、消息队列、集群调度全部由阿里云托管,用户零维护负担
- 智能弹性伸缩:自动适配业务流量变化,无需手动配置规则
- 高可用与容错保障:云资源故障自动恢复,确保服务持续稳定运行
更好生态:无缝集成 AI 与大数据体系
阿里云 Milvus 深度融入阿里云 AI 生态,全面支持:
- 百炼 、通义千问 、人工智能平台 PAI 等主流大模型工具链
- 多模态检索、RAG(检索增强生成)、语义搜索、图像/视频相似性分析等典型 AI 场景
- 与阿里云 EMR Spark、DataWorks 等大数据组件无缝对接,构建端到端的数据处理 Pipeline
两大核心场景,助力企业快速落地AI应用
- 多模态搜推场景:超大规模向量检索
- 数据增长快、访问频率高、延迟敏感
- Milvus 通过混合存储+标量过滤+高性能索引,实现低成本、低延迟的精准召回
- 大模型 RAG 场景:智能检索增强生成
- 对语义理解精度要求高,可与 AI 框架深度集成
- 支持多租户隔离、细粒度权限控制、重排序与聚合查询,打造安全可靠的 AI 知识底座
未来已来:更智能、更开放的向量数据库演进方向
阿里云将持续投入 Milvus 的产品迭代,未来将重点聚焦三大方向:
- 平台智能化:推出 Milvus Agent,支持交互式操作;提供全面的集群服务诊断和弹性伸缩能力;自研全新元数据管理平台
- 内核极致优化:全面升级至社区最新 Milvus 2.6 内核,支持内置 Embedding、ReRank 函数等新特性,同时进一步提升向量存储和检索性能
- 向量数据湖建设:提供完善的数据冷热分层和高效远程检索能力,打造真正的"向量 Lakehouse"
结语
在这个以 AI 驱动的新时代,向量数据已成为企业核心资产。阿里云 Milvus 作为专业的向量数据库,以极致性能、全托管体验、深度 AI 集成,帮助企业轻松驾驭向量洪流,释放非结构化数据的无限潜能。