你好呀,我是歪歪。
前几天我想要巩固一下共识算法这个知识点。
(先声明,这篇文章不深入讨论共识算法本身)
于是我在 B 站大学上搜索了"共识算法"这个词:
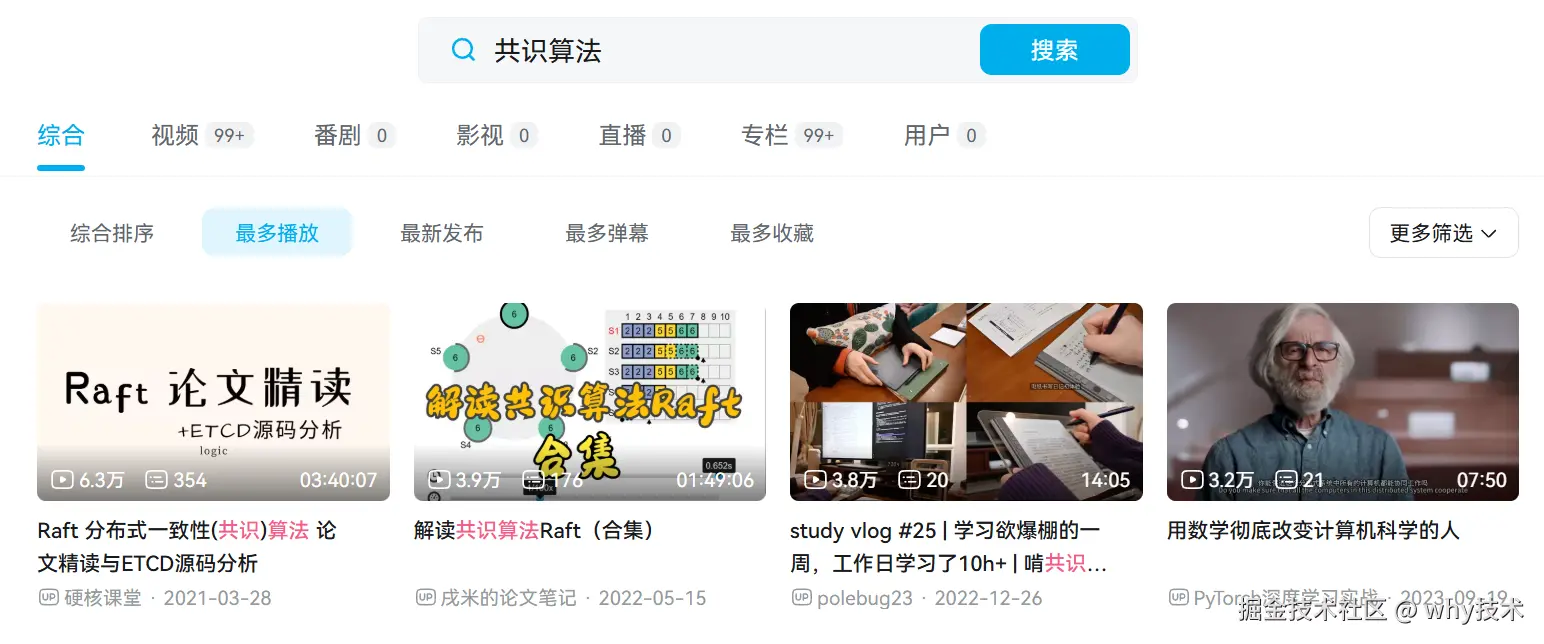
我还特意按照播放量排序了一下,准备先找个播放量高点的视频随随便巴拉几下。
排名第一的视频,播放量只有 6.3w。
说实话,在搜索之前,我潜意识里觉得这种这个话题,头部视频最次最次也得有个 10w+ 的播放吧?
而实际情况是前四的视频播放量,满打满算加起来,18w。
这个数字让我瞬间把共识算法抛在脑后,冒出了另一个念头:要不看看"微服务"这个关键词的播放量?
你猜一下,这个用"微服务"这个关键词,在 B 站搜索,然后按照播放量排序,播放量第一有多少,前四加起来又有多少?
...
...
不要太保守,往大了猜。
...
...
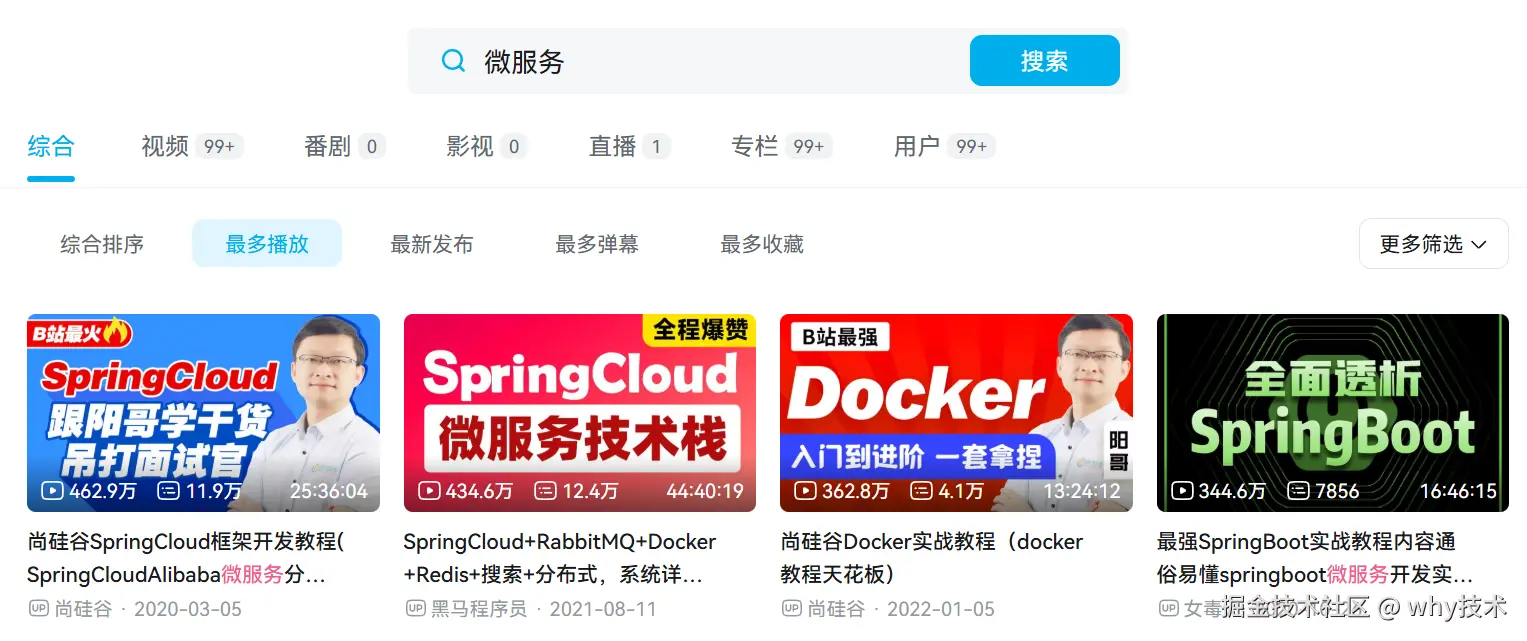 用"微服务"做关键词,播放量第一 462w,前四加起来 1600w,就这我还抹掉了 5w 的"零头"。
用"微服务"做关键词,播放量第一 462w,前四加起来 1600w,就这我还抹掉了 5w 的"零头"。
这个鲜明的对比,确实引发了我的一点思考。
从"共识算法"的 18w 到"微服务"的 1600w,近 90 倍的差距。看到这个数据,你大概能猜到我在想什么。
面对这个现象,我在思考的是:
共识问题可以说是微服务得以存在的理论基石。但是从这个数据上来看,我觉得知识体系在某个环节出现了非常严重的断层。
当然了,我得先叠个甲。
我知道我用上面这个统计方式完全不准确,完全不科学,完全不正确。
但是"知识体系出现了断层"这个结论,歪师傅觉得是正确的,而且也觉得这个是正常的现象。
只是让我觉得诧异的是,我潜意识里面觉得差距不应该是十几万到一千六百万,这种近 90 倍的数量级的差异。
这背后其实有一个值得探讨的且是 IT 行业普遍存在的一个现象:"赶紧上手"和"底层原理"之间的权衡。
数据为什么是这样的
首先,我思考了一下:数据为什么是这样的?
我观察了一下,"微服务"排名前四的都是培训机构上传的系统课程。
培训机构嘛,大家也知道,这一类课程的主要目的就一个:赶紧上手。
底层逻辑是为"尽快找到工作"而服务。
本质上是将一个人在最短时间内打造成能满足企业初级编码岗位要求的合格"牛马"。
在这个标准下,一切不能直接、快速为初级编码岗位服务的知识,都会是"冗余"的。
所以,你看他们的课程:
比如讲到 Eureka 的时候,基本上都是在讲怎么使用,代码应该怎么去写,写完之后怎么跑起来。
我快速浏览了相关内容,完全没有提到"共识算法"和 CAP 相关的点。
当然了,也有可能是我跳着看的,看的不仔细,其实讲了但是我没看到,但是这不重要。
总之,事实就是入门课程完全可以不讲共识算法,甚至不提 CAP 理论。
这类入门课程的受众面就是非常广,播放量高也是非常自然的事情。
写到此处,不得不再次叠个甲了:我也并不是在吐槽这种授课方式,我只是在称述我认为的"数据为什么是这样"的事实。
相反,我站在现在的视角去看,这样的课程安排其实是合理的。
试想一下,对于一名刚刚从单体服务转向分布式系统的初学者来说,还在给你铺垫各个组件的功能,然后讲到注册中心的时候,直接就安排上了 CAP 和共识算法这套非常抽象、难以理解的丝滑小连招,应该是非常劝退的。
直接就是一个"从入门到放弃"的大动作。
这也与"尽快找到工作"这个核心出发点相违背。
在市场上,对于大多数初中级岗位,公司更看重的是你能否在现有的框架下完成业务开发。
如果公司使用的是 SpringCloud 全家桶来搞微服务,那你能够正确、熟练地使用,已经能够胜任百分之七八十的工作了。
至于共识算法什么的,最多也就是在面试的时候出现一下就了不得了。
更进一步
对于培训机构和学习者来说,都需要"更进一步"
对于培训机构来说,虽然这些都是入门课程,但是我觉得理想状态应该是能在讲解相关组件的时候,引出其背后的理论,但是一定要点到为止。
比如:
- 从"为什么要用服务注册中心?",引出服务发现的问题。
- 从"Eureka 和 Nacos 的区别?",引出 CAP 理论。
- 从"分布式事务怎么实现?", 引出数据一致性问题。
- "从集群数据同步",引出共识问题。
点到为止,只需要帮初学者建立一个宏观的、模糊的认知就行了,相当于埋下一颗种子。
而对于学习者,你不能一边自嘲着自己是"CRUD 工程师",一边又没有足够的理论基础和自信的技术决策能力。
你得让前面提到的种子长成一颗技能树。
比如,当面对 CAP 权衡的时候,你能通过你的技能树知道它不是一个选择题,而是一个权衡题。
举个简单的例子。
站在 CAP 的角度,你得知道为什么 Eureka 客户端要缓存服务列表?
因为在与注册中心网络分区 P 时,要保证服务的可用性 A,所以牺牲了部分一致性 C。
你也得知道为什么 ZooKeeper 不能像 Eureka 那样允许节点间长时间失联?
因为它要保证一致性 C,在出现分区 P 时,宁愿牺牲可用性 A。
从而要知道,在要求强一致性的金融场景下,底层设计要保证 CP ,而在追求高可用的电商场景下,要保证 AP。
再比如,当学习到 Seata 时,需要追问各种分布式事务模式的实现,什么 2PC、TCC、Saga 这些玩意在根本上是想说什么,是怎么和 ACID、BASE 理论以及最终一致性这些概念关联上的。
我知道这些要求对于初学者来说,确实很高。
但是结合我自己亲自走过的技术路线,我确实是先掌握了基础的使用,然后在长达几年的时间中逐步慢慢去理解上面这些东西的。
而我上面说的这么多,核心想要表达的是:首先你得有一颗种子,然后你得让种子长成一颗树。
有的人运气比较好,得到种子的过程比较轻松,不需要花费大力气,在这个维度确实有差异。
但是在如何让种子长成树的努力上,我觉得大家所需要付出的精力是大差不差的,而且这方面完全是勤能补拙的。
灌溉
让种子成长为树,你得用知识去灌溉。
比如,就具体到前面讨论的这些问题。
写的过程中我就想起我之前看过的一本书,《数据密集型应用系统设计》这本分布式领域的书,必读,是非常好的"肥料"。
然后源码也是上好的肥料,可以从一些相对简单的项目开始读。
比如读一读 Nacos 客户端服务发现的流程,你会发现,理论在具体的代码中是如何体现的。
也可以尝试去阅读一些别人梳理好了的论文导读,比如前面提到的 Raft,相关的论文已经被很多人解读过了,甚至网上已经有了非常清晰的解释原理的可视化动画,帮助你理解其核心思想。
这些都是我过去使用的比较"古老"的学习方式。
现在有了 AI 大模型的加持,学习新技术、寻找优质资料都变得更加方便了。
你可以让 AI 帮你解释复杂概念、推荐学习路径、甚至模拟面试问答,这就大大降低了学习的门槛。
写在最后
最后,我还想表达一个额外的点。
我们回到最开始的数据。
那 1600 万播放量,代表了一条好走、明确且广阔的道路。
那 6.3 万播放量,则代表着一条更孤独、更艰难、更崎岖的通往山峰的路。
每个人都会在大路上走一段时间,但是有人走着走着路就不一样了。
不论你选择哪条路,道路都是清晰的,资源都是充沛的。选择任何一条路,并坚定地走下去,都值得尊敬。
但是,你得自洽。
自洽是指,你不能一边享受着这条"好走、明确且广阔的道路"的快捷与轻松,自嘲着自己是"CRUD 工程师",又下不了决心、没有足够的毅力往难走的路上走,还在心里嘲讽正在这条更难的路上努力往前的人。
其实工作的越久,我越发现,又是真正阻碍一部分技术人成长的,正是这种"既要、又要、还要"的拧巴心态。
而且,我也曾经在这种心态中沉沦过一段时间。
它让你既无法安心享受当下的成就,又缺乏魄力去追寻更高的目标,最终把精力都耗在了自我消耗和无效的评判上。
想清楚自己想去哪儿,然后坦然地、专注地走你自己的路。
对你没选择的路保持尊重,对你选择的路负起全责。
最重要的是,回头再看的时候,不要用"假设"来美化你没走过的那条路。
好了,以上就是我个人的一些主观思考。