GC一小时速通教程
JVM GC 之 "垃圾" 是什么?从用户注册业务说起
在讲解 JVM 中的 GC(垃圾回收)之前,我们首先要搞清楚一个核心问题:什么是 "垃圾"? 为了更直观地理解,我们先从一个常见的业务场景 ------ 用户注册业务入手,逐步剖析业务执行过程中 JVM 内存的变化,进而引出 "垃圾" 的定义。
一、用户注册业务流程梳理
用户注册是我们日常开发中非常基础的业务,完整的业务流程大致如下:
- 用户操作层:用户在前端页面输入注册信息,包括用户名、真实姓名、昵称、密码等,然后点击 "注册" 按钮。
- 请求传输层:前端将用户输入的注册信息封装成请求,发送到后端的 Controller 层。
- 业务逻辑层(Service 层) :Controller 层接收请求后,调用对应的 Service 层方法处理业务逻辑。在 Service 层中,会对用户信息进行校验、组装等操作(这一步是我们关注的重点,涉及对象创建和内存分配)。
- 数据访问层(DAO 层) :Service 层处理完业务逻辑后,调用 DAO 层方法,将用户信息最终持久化到数据库中。
- 结果返回层:数据库存储成功后,通过 DAO 层、Service 层、Controller 层逐层返回结果给前端,告知用户注册成功。后续用户就可以使用数据库中存储的用户名和密码进行登录。
二、Service 层核心操作:对象创建与内存分配
为了简化讲解,我们假设前端传递到 Service 层的是零散的用户信息(而非完整的 User 对象),因此在 Service 层需要手动组装这些信息,创建一个 User 对象。这一步操作直接关联到 JVM 的内存分配,也是理解 "垃圾" 的关键。
\1. 代码示例:Service 层创建 User 对象
首先定义一个简单的 User 实体类,用于封装用户信息:
arduino
// User实体类
public class User {
// 成员变量:对应用户注册信息
private String username; // 用户名
private String realName; // 真实姓名
private String nickname; // 昵称
private String password; // 密码
// 无参构造器
public User() {}
// 有参构造器(用于组装用户信息)
public User(String username, String realName, String nickname, String password) {
this.username = username;
this.realName = realName;
this.nickname = nickname;
this.password = password;
}
// Getter和Setter方法(省略,用于访问和修改成员变量)
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
// 其他成员变量的Getter/Setter方法省略...
}然后在 Service 层中,通过new关键字创建 User 对象,组装用户信息:
typescript
// 用户注册Service层实现类
@Service
public class UserRegisterService {
// 注入DAO层对象(用于后续操作数据库)
@Autowired
private UserDao userDao;
// 用户注册核心方法
public boolean register(String username, String realName, String nickname, String password) {
// 1. 业务校验(省略,如校验用户名是否已存在、密码格式是否合法等)
// 2. 组装用户信息:创建User对象(关键操作:new User())
User user = new User(username, realName, nickname, password);
// 3. 调用DAO层方法,将User对象存入数据库
boolean saveResult = userDao.save(user);
// 4. 返回注册结果
return saveResult;
}
}三、JVM 内存视角:对象存放在哪里?
当执行User user = new User(...)这行代码时,JVM 会在不同的内存区域分配空间,这涉及到 JVM 内存模型中的栈内存 和堆内存。
- 栈内存(Stack):存放引用变量
- 变量user的存储 :代码中的user是一个引用变量(并非真正的 User 对象),它会被存储在栈内存中。
- 引用的本质:栈内存中的user变量存放的是一个 "内存地址",这个地址指向堆内存中真正的 User 对象。
- 堆内存(Heap):存放对象实例
- User 对象的存储 :通过new User(...)创建的 User 对象(实例),会被存储在堆内存中。
- 堆内存的归属:堆内存是 "线程共享" 的,所有线程创建的对象实例都统一存放在堆内存中。
- 对象的内容:堆内存中的 User 对象会存储其成员变量(username、realName等)的值,以及对象的元数据信息(如对象类型、类的引用等)。
四、从业务结束到 "垃圾" 产生:引用的生命周期
当用户注册业务执行完成后(即register()方法执行结束),JVM 内存会发生什么变化?这是判断 "垃圾" 的关键。
- 方法执行结束:栈帧出栈,引用消失
当register()方法执行完成(即 DAO 层将 User 对象存入数据库后),该方法对应的栈帧会从线程栈中 "出栈"。此时,栈帧中的引用变量user会被销毁 ------ 也就是说,栈内存中不再有指向堆内存中 User 对象(地址 0x0012FF3A)的引用。
- 堆内存中的对象:失去引用后成为 "垃圾"
堆内存中的 User 对象(地址 0x0012FF3A)原本是通过user引用被访问的。当user引用被销毁后,这个 User 对象就再也无法被程序中的任何部分访问到了(因为没有任何引用指向它)。
此时,这个无法被程序访问的对象,就是 JVM GC 中所说的 "垃圾"。
核心结论:"垃圾" 的定义
在 JVM 中,"垃圾" 指的是堆内存中那些失去所有引用(或没有任何引用指向它)的对象实例------ 这些对象无法再被程序使用,继续占用堆内存会造成内存浪费,因此需要通过 GC 将它们回收,释放内存空间。
五、扩展思考:哪些情况会导致对象成为 "垃圾"?
除了上述 "方法执行结束,引用出栈" 的情况,还有其他场景会导致对象成为 "垃圾",例如:
引用变量被显式赋值为 null:如user = null;,此时user不再指向堆内存中的 User 对象,该对象成为垃圾。
引用变量被重新赋值 :如User user = new User(...); user = new User(...);,第一个 User 对象的引用被覆盖,成为垃圾。集合中的对象被移除:如List list = new ArrayList<>(); list.add(new User(...)); list.remove(0);,被移除的 User 对象若没有其他引用,成为垃圾。
JVM GC 之如何识别垃圾:从活跃线程到 GC Roots
上一部分我们理解了 "垃圾" 是堆内存中失去所有引用的对象实例。但堆内存是所有线程共享的区域,里面可能存在成千上万的对象,如何准确区分 "存活对象" 和 "垃圾对象" 呢?这就需要从线程的运行机制和 GC Roots 说起。
一、线程与堆内存的关系:共享与隔离
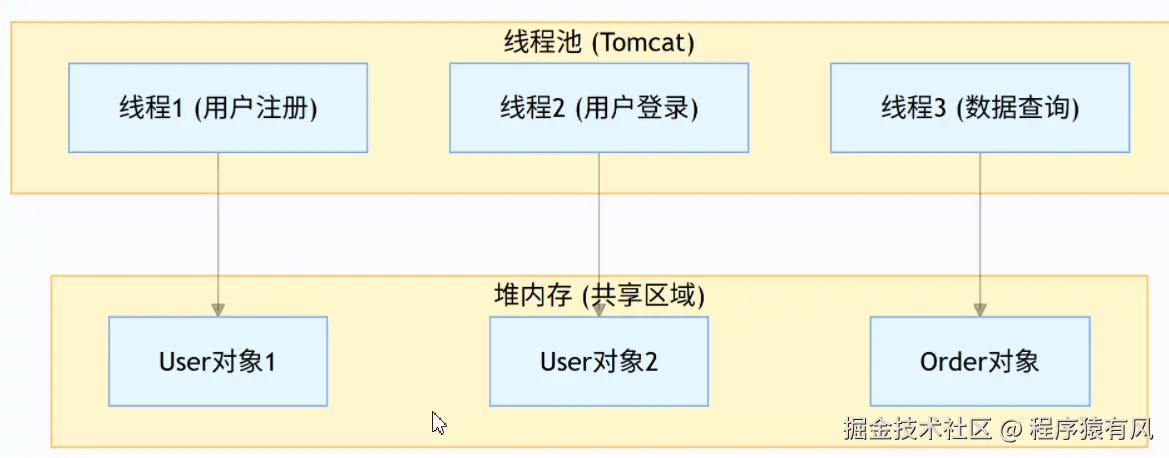
当我们的项目部署到 Tomcat 等服务器运行时,会涉及到多个线程与堆内存的交互:
-
服务器线程池的作用:
- Tomcat 启动后会维护一个线程池,当用户请求(如注册、登录、操作等)到来时,会从线程池中分配一个线程处理该请求
- 每个请求对应一个独立的线程,这些正在处理任务的线程称为 "活跃线程"
-
线程与堆内存的交互:
- 所有线程共享堆内存,不同线程创建的对象都存放在堆中
- 每个线程有自己独立的栈内存(线程私有),用于存储当前执行方法的局部变量(包括对象引用)
二、栈帧与对象引用:活跃线程中的关键线索
每个活跃线程的栈内存中,会为正在执行的方法创建对应的 "栈帧":
-
栈帧的作用:
- 存储方法的局部变量(包括基本类型变量和对象引用)
- 记录方法的执行状态(如返回地址、操作数栈等)
-
以用户注册业务为例:
- 当
register()方法执行时,线程会创建对应的栈帧 - 栈帧中存储
user引用变量,指向堆内存中的 User 对象 - 方法执行过程中,这个引用始终有效(活跃状态)
java// 栈帧中存储的引用关系 public boolean register(...) { // 栈帧中创建user引用,指向堆内存的User对象 User user = new User(...); // 引用有效(活跃状态) // ...业务逻辑... return saveResult; } // 方法执行结束,栈帧出栈,user引用消失 - 当
-
多线程场景下的栈帧状态
- 系统运行时存在多个活跃线程
- 每个线程有多个嵌套执行的方法,形成栈帧链
- 这些栈帧中存储的对象引用,是判断对象是否存活的关键线索
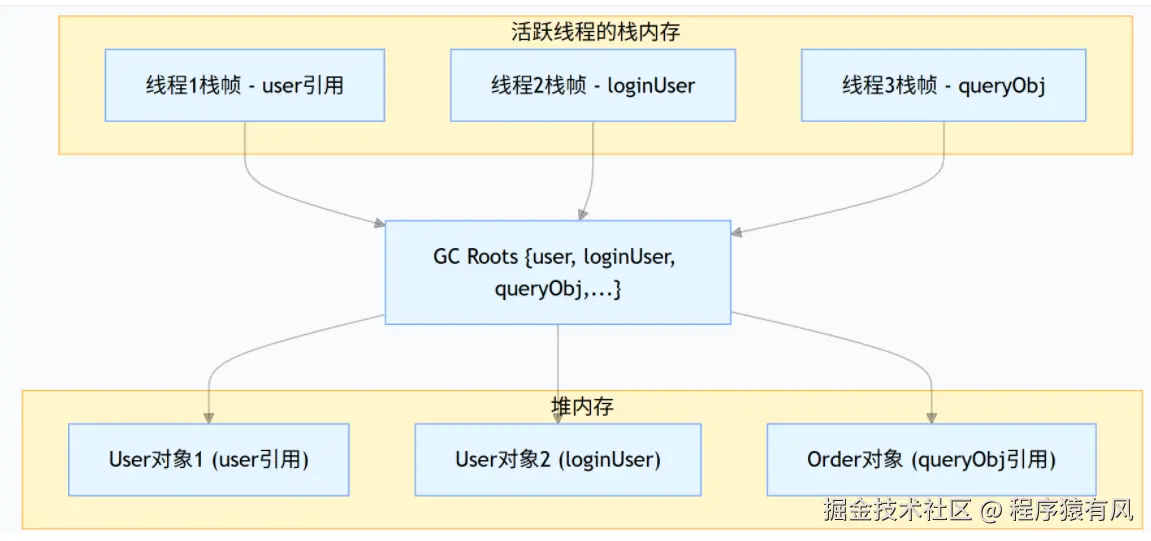
三、GC Roots:垃圾回收的 "起点集合"
JVM 如何确定哪些对象是存活的?核心就是通过 GC Roots(垃圾回收根集):
-
GC Roots 的定义:
- 是一组 "活跃的引用" 的集合
- 主要包括:活跃线程栈帧中的局部变量、静态变量、常量引用、JNI 引用等
- 在我们的业务场景中,主要关注活跃线程栈帧中的局部变量引用
-
GC Roots 的收集过程:
- JVM 扫描所有活跃线程的栈内存
- 收集所有栈帧中正在使用的对象引用
- 这些引用共同构成 GC Roots集合
四、标记 - 清除:垃圾回收的基本流程
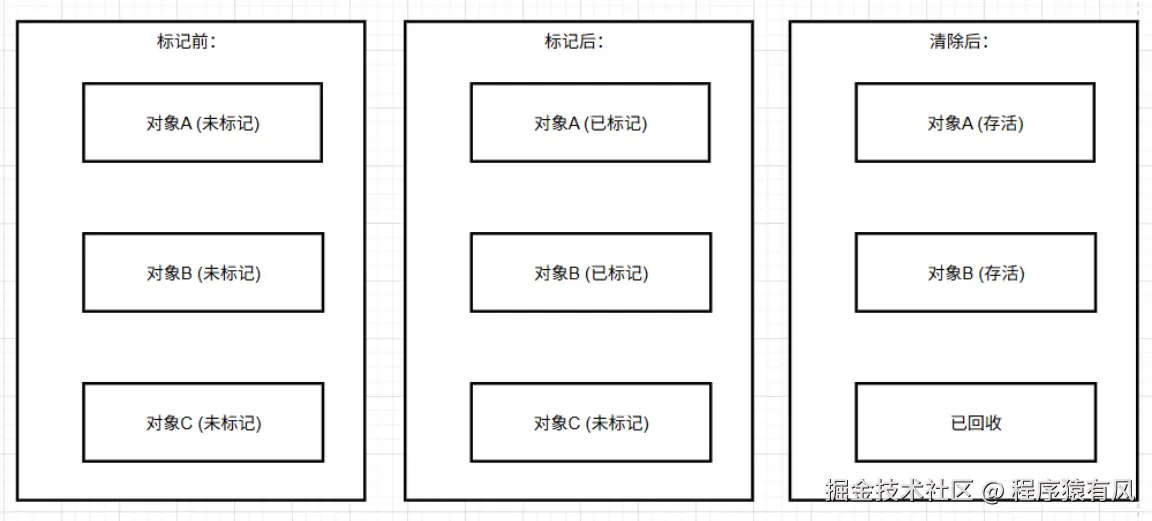
有了 GC Roots 后,JVM 就能通过 "标记 - 清除" 过程识别并回收垃圾:
-
标记阶段:
- 从 GC Roots 集合中的引用出发,遍历所有可达的对象(可达性分析算法)
- 被遍历到的对象会被标记为 "存活对象"(在堆内存中设置标记位)
- 未被标记的对象就是 "垃圾对象"
-
清除阶段:
- 回收所有未被标记的垃圾对象
- 释放其占用的堆内存空间
-
标记的周期性:
- 每次 GC 执行时,都会重新进行标记(上一次的标记会被清零)
- 保证标记结果反映当前对象的存活状态
五、GC Roots 的通用性
虽然不同垃圾回收器(如 SerialGC、ParallelGC、G1、ZGC 等)的实现细节不同:
- 传统回收器在堆内存中标记对象
- 新一代回收器(如 ZGC)采用染色指针技术,不在堆内存中标记
但GC Roots 作为垃圾回收的起点这一核心机制,贯穿了所有垃圾回收器的设计。它是 JVM 判断对象存活状态的根本依据,也是理解垃圾回收原理的关键概念。
下一部分我们将深入讲解不同的垃圾器,回收算法及其实现原理。
垃圾回收算法:基于分代的处理策略(CMS为例)
一、堆内存中垃圾的分类与分代处理
在垃圾清理的时候,每次都要扫描整个堆内存,是非常耗时的,所以,每一代都会对堆内存进行分代处理。
在堆内存中,垃圾主要分为两类:
-
短期存活的垃圾
- 例如用户注册流程,当注册完成后,线程中的相关信息就不再需要,这些对象很快就会变成垃圾。
-
长期存活的垃圾
- 比如用户登录后,将用户对象信息存放在 Session 中,这些对象在很长一段时间内都不会被回收。
即:
- 年轻代:存放那些很快就会被回收的对象,例如在用户注册等操作完成后就没用的对象。
- 老年代:存放长期存活的对象,比如存储在 Session 中的用户对象信息。

二、年轻代的特点与标记复制算法
(一)年轻代的特点
年轻代的显著特点是每次回收时需要处理的对象数量非常多。
(二)标记复制算法
-
垃圾回收的主要操作
- 垃圾回收主要有两个关键操作:标记和回收。标记是指找出存活的对象,回收则是处理那些未被标记的对象。
-
标记复制算法的原理
- 年轻代采用标记复制算法。可以把年轻代想象成有两个 "箱子"。每次创建对象时,都将对象放入其中一个 "箱子"。当进行垃圾回收时,把存活的对象复制到另一个空 "箱子" 中,并排列整齐。这样做的好处是不需要考虑碎片清理的问题。
1.未标记

2.标记存活对象
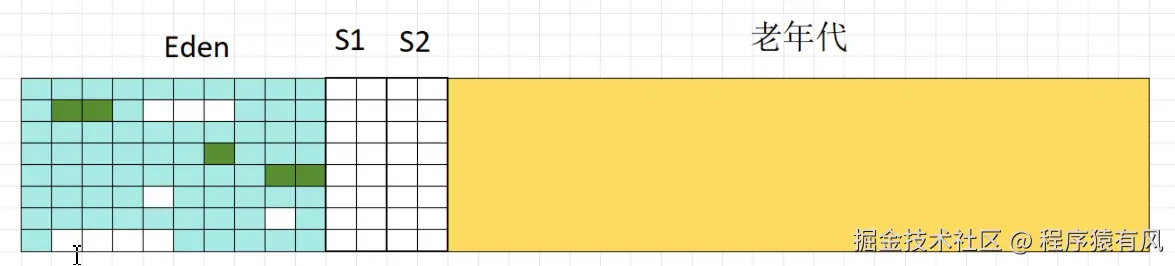 3.先复制对象到S1
3.先复制对象到S1
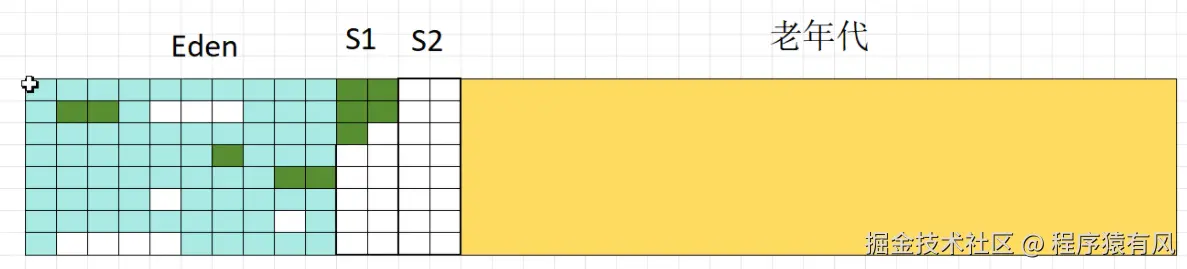
4.清空

5.第二次标记
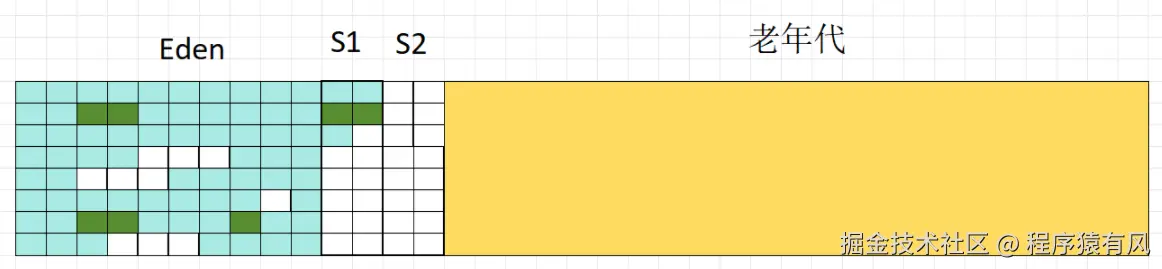
6.第二次复制

7,清空Eden和S1
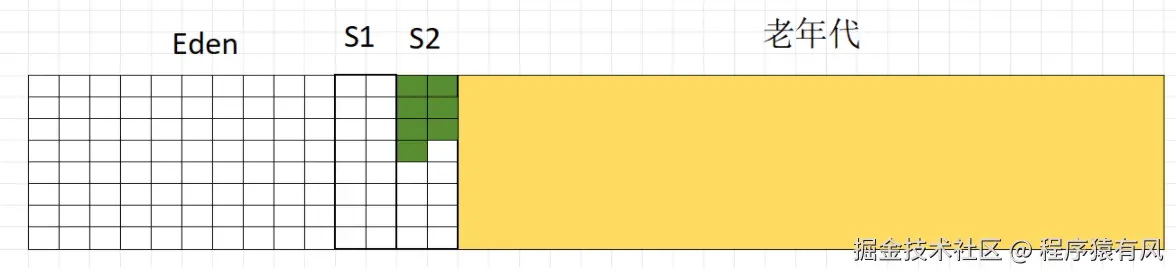
8.下一次复制后清空Eden和S2,周而复始。连续存活到一定次数的对象会被移动到老年代。
三、老年代的特点与标记清理、标记整理算法
(一)老年代的特点
老年代中的对象大部分是长期存活的,每次需要回收的对象相对较少。
(二)标记清理算法
-
标记清理算法的原理
- 标记清理算法适用于老年代。它的操作比较直接,首先标记出那些不再存活的对象,然后直接将这些未被标记的(即无用的)对象清理掉。
-
碎片问题
- 在堆内存中,可以将内存空间想象成 Excel 中的小格子。每个对象会占用若干个小格子。当对象被清理后,会留下一些空格子,这些空格子就是碎片。例如,原来内存中的对象是紧密连续排列的,经过一次清理后,出现了一些零散的空格子。当有新对象需要分配内存时,如果新对象所需的内存空间大于当前零散的空格子,就会出现无法分配的情况,这就需要进行内存整理。
标记(绿色存活)
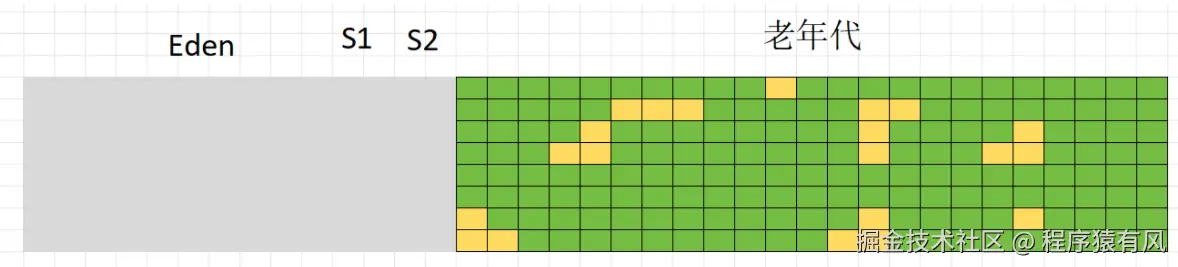
清理,但清理后会留下小面积的空格,无法存入大一点的对象,这些小空格就叫做碎片
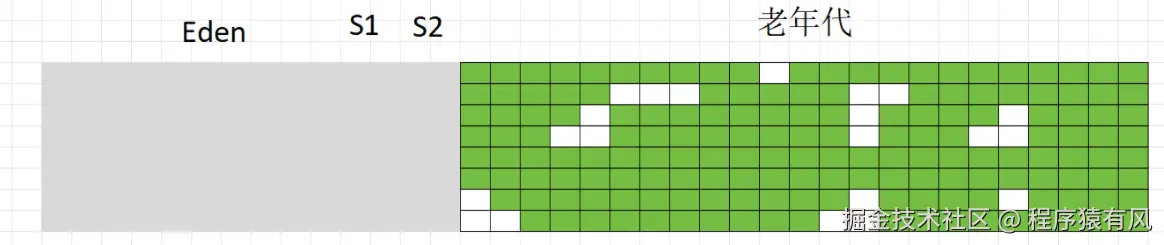
(三)标记整理算法
-
标记整理算法的原理
- 当老年代中碎片过多或者没有足够的连续空间来存放新对象时,就需要使用标记整理算法。该算法首先标记出存活的对象,然后将这些存活对象移动到一起,使它们在内存中排列得更加紧凑,从而腾出连续的空间。
标记
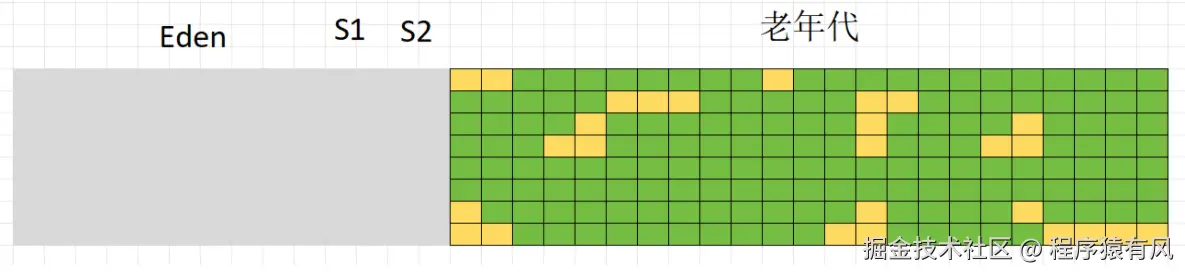
整理,将所有对象向左上角对齐排列,之前的垃圾位置会被直接覆盖
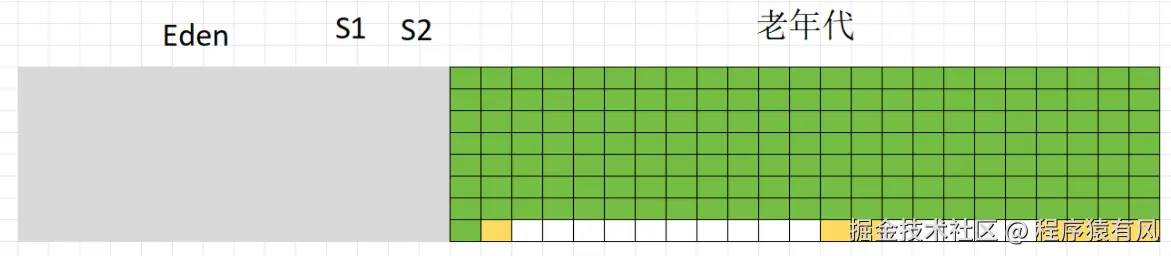
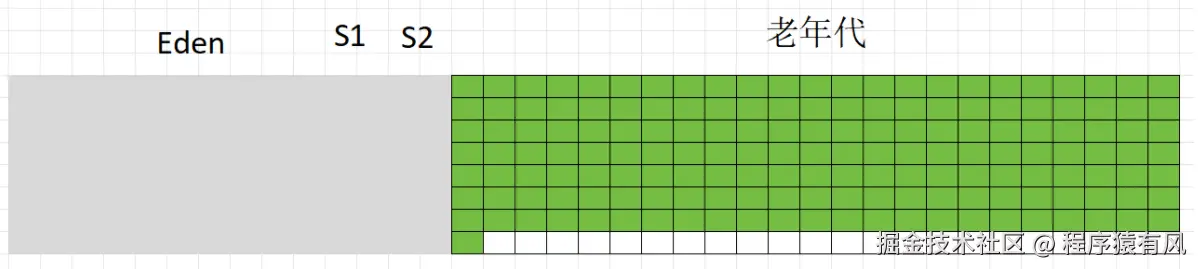
清理剩下的内存空间
JVM 垃圾回收器
什么是 STW(Stop The World)?
STW 全称 "Stop The World",即全局停顿。垃圾回收器有专属的 GC 线程,日常业务由工作线程(或用户线程)处理,理想状态下两者各干各的。但垃圾回收时,若工作线程继续往堆内存写入新实例,会干扰回收(比如 GC 刚标记垃圾,工作线程又给垃圾加引用),所以早期 GC 会先停掉所有工作线程,只让 GC 线程单独完成回收,回收完再恢复工作线程,这个过程就是 STW。
早期小型项目中,STW 影响不大;但现在互联网行业发展到顶峰,高并发场景下,STW 时间需越短越好,最好能实现 "回收与业务并行",让工作不受回收影响。
一、先看俩早期 GC:Serial 和 Parallel,实战里的 "卡脖子" 问题
这俩是 JVM 早期的默认 GC,特点鲜明,但在高并发场景下,痛点特别明显。
1. Serial GC(串行垃圾回收器)
-
工作方式:全程就一个线程干垃圾回收的活儿。
-
实战痛点:全程 STW,高并发直接崩
比如电商大促,用户疯狂下单,突然触发 Serial GC 回收。这时候所有处理下单的线程全被暂停(Stop The World,STW),用户点 "提交订单" 没反应,页面卡个几百毫秒甚至几秒要是卡 1 秒,用户可能直接刷新或换平台,订单就丢了。
这种 GC 现在只适合本地跑小 Demo,生产环境基本见不着了。
2. Parallel GC(并行垃圾回收器,JDK 1.8 默认)
- 改进点:多线程一起回收,比 Serial 快。
- 实战痛点:还是 STW,只是短了点,但高并发下仍致命
二,里程碑:并发垃圾回收器CMS
CMS(老年代垃圾回收器,年轻代还是使用早期的GC,因为年轻代使用标记复制算法效率极高,所以停顿几乎感知不到)(Concurrent Mark-Sweep,并发标记 - 清除)是 JVM 中首个以 "低停顿" 为目标的垃圾回收器,核心设计是让 "标记" 和 "清除" 阶段与工作线程并行.
cms执行流程图,源:zhuanlan.zhihu.com/p/34921587
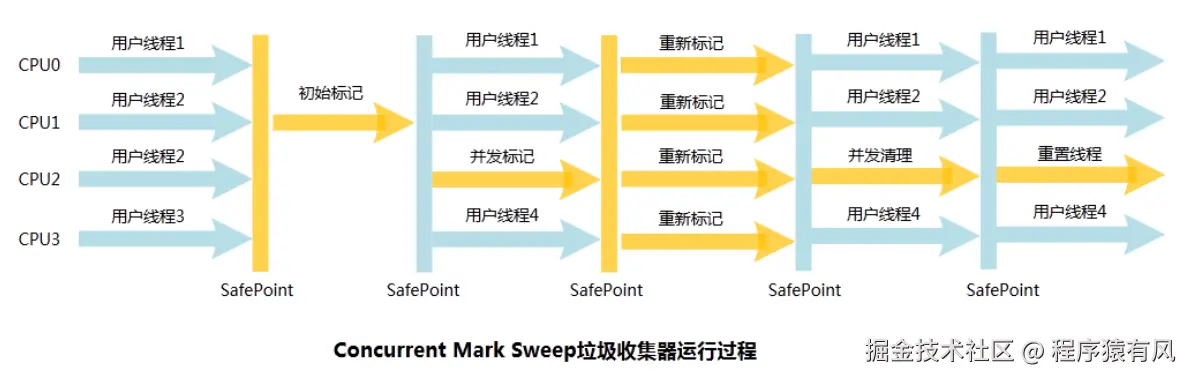
流程:
- 初始标记:短暂 STW,仅标记 GC Roots 直接引用的老年代对象,建立标记起点。
- 并发标记:GC 与工作线程并行,从初始标记的对象出发,遍历并标记老年代所有存活对象。
- 并发预清理:并发处理 "写屏障" 标记的脏卡片,提前修正引用变更,减少下一阶段的 STW 时间。
- 重新标记:短暂 STW,最终修正漏标,确保所有存活对象都被正确标记。(主要处理脏卡片和并发标记中工作线程新增的但是未标记的对象)
- 并发清理:GC 与工作线程并行,清理未标记的垃圾对象,释放内存(会产生碎片)。(清理过程中新产生的对象会放在并发清理之前设定好的"非清理区域")
- 并发重置:并发重置内部状态(如标记位、卡片表),为下一轮回收做准备。
- 新生代联动:回收期间若年轻代满,暂停并发阶段优先执行 Minor GC,完成后再恢复 CMS。(解释一下MinorGC MajorGC FullGC)
并发标记过程中存在一个问题,GC标记和用户线程同时执行,如果被标记的对象引用发生改变怎么办?GC Roots中的A引用了B,B已经被标记为存活,但是线程执行的时候A被重新引用了C怎么办?
解决方案:脏卡片 。线程执行的时候,如果发生引用变更,Jvm会感知(学名叫做写屏障),会给变更后的C对象所在的区域特别标记(学名脏卡片),等到第3和第4阶段时,被脏卡片标记的对象会被重新标记为存活。注意,之前失去引用但依然被标记的B对象不会被清理,依然标记存活,这就是GC的核心原则之一:宁可多标不可漏标的原则。
CMS确实可以大大缩短STW的时间,但是还存在以下问题:
1.全堆扫描,大对象直接丢到老年代,标记清理算法导致内存碎片问题严重,易触发 "致命 Full GC"
2.无法主动控制停顿时间,延迟稳定性差:
3.CPU 资源占用高,吞吐量损耗明显
CMS通常适合中小堆内存,比如8G左右的堆内存。
三.G1垃圾回收器
为了解决上面的问题,推出了新一代的垃圾回收器:G1
优势:
针对于cms全堆扫描以及采用的标记清理算法进行了升级:分成若干region的方式可以很方便的采用标记复制算法(可以参考cms中年轻代的处理方式,非常快,几乎无感),大大优化了碎片问题以及清理速度。
cms中的大对象存入老年代,每次标记都要扫描大对象,最主要的还是cms是一块连续的大内存区,多次回收后大量碎片导致无法存入大对象从而引发频发的Full GC.
G1中直接创建了大对象区,每个大对象区只存入一个大对象,扫描标记时如果发现已经死亡直接回收即可。
CMS 是全堆连续内存,多线程得 "瓜分整块内存" 来扫描,容易出现 "有的线程扫完没事干、有的线程还在啃大块" 的负载不均,效率受影响;
而 G1 把堆拆成了小 Region 分片,多线程能 "各管一片 Region",不用抢着扫同一块大内存,天然能均匀分担任务,还能针对性优先扫垃圾多的分片,线程利用效率比 CMS 高得多。
cms老年代清理需要全堆扫描,无法控制扫描时间,G1 能通过 -XX:MaxGCPauseMillis 设目标停顿时间,会挑垃圾多的 Region 优先回收,尽量贴合设定时间,这也是 "Garbage-First" 的意思。
G1 执行流程(含 SATB 与 RSet 作用时机)
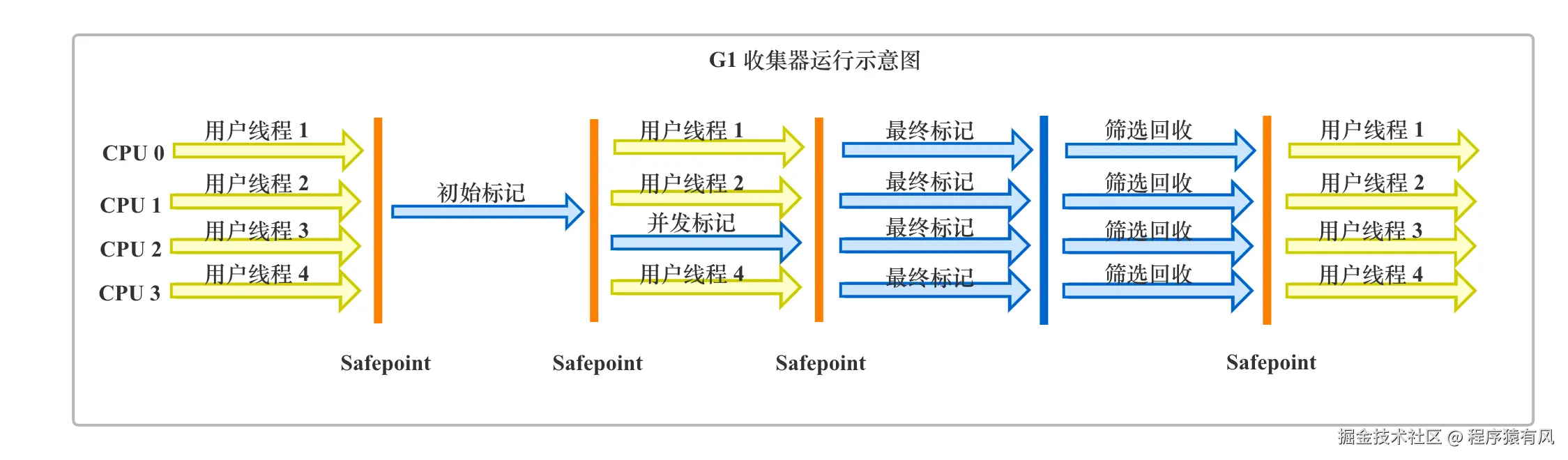
-
初始标记(STW) :暂停用户线程,标记 GC Roots 直接可达的对象。此阶段会初始化部分 RSet 基础信息,为后续并发标记做准备。
-
并发标记
:用户线程恢复运行,GC 线程并行标记所有可达对象。
- 此阶段通过 SATB(初始快照) 配合写屏障,记录并发中引用的变化(如 A 从指向 B 改为指向 C 时,记录 B 到 SATB 旧地址列表;A 新增指向 C 时,直接标灰 C)。
- 同时,RSet 会实时维护外部 Region 对本 Region 对象的引用(如其他 Region 对象引用本 Region 对象时,更新 RSet 记录 Region + Card 信息),支撑后续回收时的存活判断。
-
最终标记(STW) :暂停用户线程,处理并发标记中 SATB 日志记录的旧引用,将旧地址列表中的对象标黑;同时扫描标灰对象及其子引用,批量标黑,确保标记完整。
-
筛选回收(STW)
:暂停用户线程,统计各 Region 存活对象占比,优先选择垃圾率高的 Region 回收。
- 回收时,通过查询目标 Region 的 RSet,快速定位外部引用来源,判断本 Region 对象是否存活;将存活对象复制到新 Region,清理垃圾并压缩内存。
部分核心原理:G1中通过Rset集合,解决不同Region之间的引用关系。比如有三个Region区,R1,R2,R3,分别存放了三个对象,A,B,C。
R1的A对象被B对象和C对象引用。
-
它就像一个 "便签本",上面写着:
"R2 的 Card 0x0A 有人引用我"
"R3 的 Card 0x05 有人引用我"
-
这个便签本不是给你平时看的,是GC 回收时备用的。
-
这表示:
- R2 的 0x0A 卡页里有对象引用了 R1 里的对象;
- R3 的 0x05 卡页里有对象引用了 R1 里的对象。
-
去这些 Card 里找引用对象
- 到 R2 的 0x0A 卡页,找到里面的对象(比如 b1);
- 到 R3 的 0x05 卡页,找到里面的对象(比如 c1)。
-
检查这些引用对象
- 看 b1、c1 本身是不是存活的(可达的);
- 如果它们存活,那它们引用的 R1 内的对象(比如 a)也必须标记为存活。
-
回收未被引用的对象
- 遍历完 RSET 里的所有外部引用源,再加上 R1 内部引用链,就能确定哪些对象还活着;
- 把存活对象复制到新 Region,清空 R1。
并发标签期间,如果发生类似CMS中的脏卡片处理,采用G1专用的SATB处理方式,即:
G1 并发标记:SATB 与写屏障的核心逻辑
G1 和 CMS 一样,并发标记时用户线程(工作线程)不会停,但为了避免漏标,G1 靠 SATB(Snapshot-At-The-Beginning,初始快照) 和写屏障配合,核心原则还是 "宁可多标活,不可漏标",具体分两种关键场景:
一、先简单说:三色标记法基础
为了清晰跟踪对象存活状态,GC 会给对象 "涂色":
- 黑色:已扫描完,对象本身存活,且它引用的子对象也都标记过了;
- 灰色:对象本身存活,但它引用的子对象还没扫描;
- 白色:未被扫描,默认是 "待回收垃圾"(如果最后还是白色,就会被回收)。
二、场景 1:引用 "断旧连新"(A 原本→B,改成 A→C)
- 并发标记前:初始快照(SATB)记录下 "A→B" 这个引用,此时 A、B 还没被 GC 线程扫描;
- 并发标记中:用户线程先动手,把 A 的引用改成 "A→C"(断旧连新);
- 写屏障触发 :因为改了引用,写屏障会把 "B 的旧引用" 记录到 SATB 旧地址列表(相当于给 B 发 "保护令");
- 后续处理 :不管 B 之后有没有其他引用,GC 到了 重新标记阶段(STW 短停顿) ,会把旧地址列表里的 B 直接标为 黑色(多标活)------ 哪怕 B 其实已经没引用了,也先保它一次,避免漏标。
三、场景 2:已标黑对象 "新增引用"(A指向B 已黑,B 新→C)
- 并发标记中 :GC 已经扫描完 A 和 B,两者都标为 黑色(默认它们的子引用都处理完了);
- 用户线程操作:程序继续跑,B 突然新增一个引用 "B→C"(C 之前是白色,没被扫描);
- 写屏障触发 :因为 B 是已标黑的对象,新增引用会触发写屏障,把 C 直接标为 灰色(不让 C 一直是白色,避免被当垃圾);
- 后续处理:到了重新标记阶段,GC 会优先扫描灰色的 C,把 C 及其子引用都标为黑色(补全标记)------ 确保 C 不会因为 "新增引用没被扫描" 而漏标。
总结:SATB + 写屏障的核心作用
- 场景 1 处理 "断旧引用":靠 SATB 旧地址列表保旧对象(B),避免误杀;
- 场景 2 处理 "新增引用":靠写屏障把新对象(C)标灰,避免漏标;
- 本质都是用 "多标活"(比如场景 1 的 B 可能多标)换 "无漏标",同时不用长时间停用户线程,平衡了停顿和安全性。
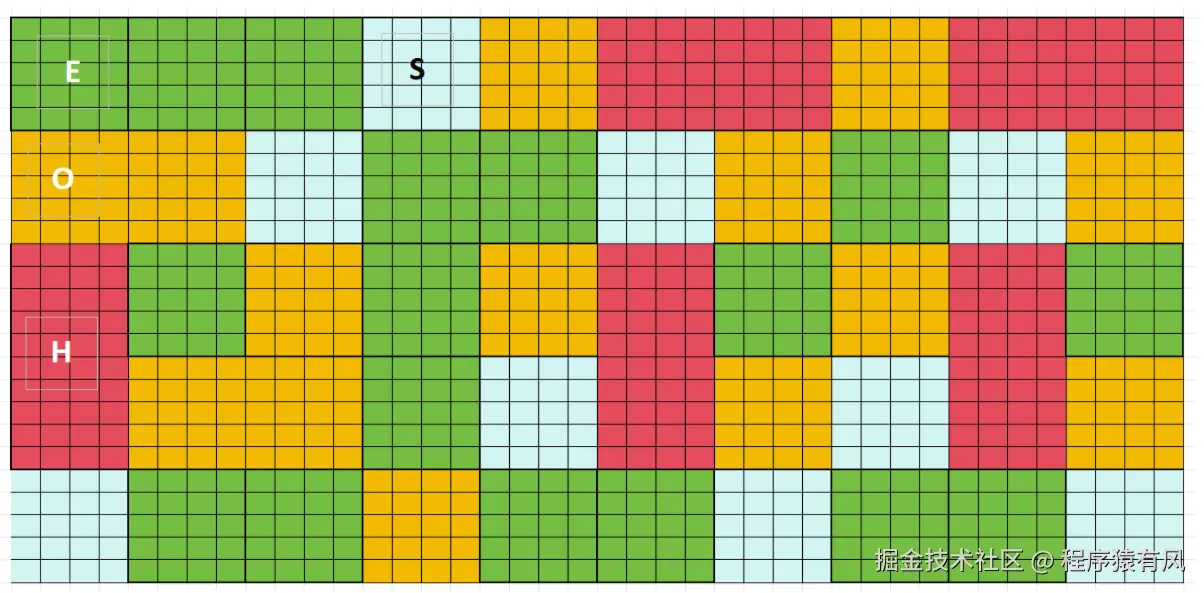
图例:G1直接将内存分成了一个一个的region(区),如下图,分别用不同的字母标出每个区域的用途。除了大对象区,每个region的大小是一样的,只是数量不同。
- Eden 区:由若干个 Region 组成,数量动态变化(比如 50 个 → 100 个)。
- 老年代区:由若干个 Region 组成,数量随对象晋升逐渐增加。
- 大对象会占用连续多个 Region,比如一个 5MB 的对象会占用 3 个连续的 2MB Region(最后一个只用 1MB,剩下 1MB 浪费)
G1 是非常优秀的垃圾收集器,日常工作里,不管是单体中小型项目,还是负载均衡做得好的微服务,只要单机堆内存控制在 16G 左右,它的性能完全够用,压根不用换。但像美团这类企业,在 TB 级海量内存的大型服务器上,就优先用 ZGC 了.
因为 G1 有个坎:堆内存一旦超 64G,问题就全来了。首先,G1 的 Region 是初始化时就固定大小的,堆越大,划分出的 Region 数量越多,管理这些 Region 以及维护 RSet、处理 SATB 日志的开销会暴增。其次,G1 延续了 CMS 的思路,标记对象时要去内存里找对象,改对象头的标记位 ------ 单次寻址开销不大,但堆大了,寻址范围广,来回折腾的时间就扛不住了,吞吐量直接掉下来。
而 ZGC 正好解决了这些问题:
第一,它不用固定 Region,改成动态页面管理。就像按物品大小选箱子,小对象给 2MB 小页面,大对象给 32MB 甚至更大的页面,不用一次性把 1T 内存全分成小格子,管理负担自然轻。
第二,最关键的是染色指针技术。这里可以用 Redis 类比:原来项目读数据要直接查数据库,慢;加个 Redis 缓存常用数据,速度就快了。CPU 里的寄存器和缓存也一样,是内存的'临时 Redis',会存当前常用的指针。ZGC 直接在这些指针的高位加标记(比如用 00、01 表示对象状态),不用去内存里改对象头 ------ 就像给快递单号加前缀表示状态,不用拆快递看单子。尤其在 TB 级内存里,不用频繁往内存寻址、改对象头,速度和效率直接拉满。
所以总结下来:中小堆用 G1 性价比最高,超大堆场景,ZGC 的动态页面 + 染色指针就是降维打击。
什么是染色指针:
先说指针,我们在学习Java的入门课的时候,都会在创建对象的时候学到如下的知识点,比如:
ini
User user = new Uesr();其中前面的user叫做引用变量,后面的new User()叫做对象创建的表达式,可以简单理解为就是一个方法(函数),该方法(函数)会返回在内存中创建User类实例所在的内存地址。也就是说,引用变量user就是指针,它保存了User实例的内存地址。
而在64位的Linux系统中,使用64位中的低46位用来寻址,剩余的高18位是闲置的,ZGC利用了这个规则,从闲置的前18位中取出来4位用来标识该地址的对象实例的具体状态:
sql
// 1. 栈上的user是指针,指向堆中User实例的内存地址(如0x000123456789ABCD)
User user = new User();
// 2. ZGC在指针高位嵌入"颜色标记",假设高4位为0001 表示"已标记存活"
// 此时实际使用的指针为:0001 + 000123456789ABCD → 0x500123456789ABCD
User anotherUser = user; // 引用传递时,指针高位的"颜色"也随之传递G1 标记时要修改堆中User实例的mark word,而 ZGC 只需修改栈上user指针的高位 ------ 由于栈上的指针(尤其是频繁访问的引用)会被 CPU 缓存到寄存器或 L1/L2 缓存中,修改操作可在 CPU 内部完成,无需访问堆内存,速度比对象头修改快数百倍。
染色指针的核心 "颜色" 类型(状态标记)
ZGC 通过指针高位的二进制组合定义对象状态,当前主要包含三类核心标记(不同 JDK 版本可能微调位定义):
ZGC 64 位指针高 4 位元数据含义表
| 指针高 4 位标识 | 对应状态 | 状态含义 |
|---|---|---|
| 0000 | Marked0 | 对象的三色标记状态之一 |
| 0001 | Marked1 | 对象的三色标记状态之一 |
| 0010 | Remapped | 表示对象已进入重分配集,即被移动过 |
| 0011 | Finalizable | 表示对象只能通过 finalize () 方法才能被访问到 |
指针类型:明确 Java 中与染色指针相关的指针形态
Java 开发中虽不直接操作指针,但 ZGC 的染色指针设计需结合 JVM 层面的指针类型理解,核心分为两类:
栈指针(Stack Pointer)
- 即方法栈中局部变量对应的引用(如User user),是 GC Roots 的核心组成部分。
- 特点:频繁被访问,大概率被 CPU 缓存,ZGC 初始标记阶段仅需扫描栈指针,通过高位染色标记根对象,无需遍历堆。
堆内指针(Heap Pointer)
- 堆中对象内部的引用(如User实例中private Address addr对应的指针)。
- 特点:数量庞大,但 ZGC 通过 "读屏障" 实时拦截堆内指针的访问 ------ 若指针高位标记为 "已转移",读屏障会自动将指针重定向到对象的新地址(即 "引用自愈"),无需暂停用户线程。
新的问题来了,写屏障我们在了解cms,G1时已经非常清楚了,这个读屏障又是什么呢?
GC 线程和用户线程可能 "抢着" 访问对象 ------ 若用户线程先访问未标记的对象,而 GC 线程还没扫描到它,就可能被误判为垃圾回收。读屏障通过实时标记 "未标记" 的指针,确保所有被用户线程访问的对象都会被标记为存活,避免漏标。
scss
// 读屏障伪代码(嵌入在引用读取操作中)
Address readBarrier(Address pointer) {
// 1. 检查指针高位的颜色标记
if (pointer.color == 未标记) {
// 2. 将指针颜色改为"已标记(0000)",标记该对象为存活
pointer.color = 已标记;
// 3. 将该对象加入GC线程的"待扫描队列",后续遍历其引用链
addToMarkQueue(pointer);
}
// 4. 返回原始指针,用户线程正常访问对象
return pointer;
}场景二:并发转移阶段 ------ 实现 "引用自愈"
当 ZGC 处于 "并发转移" 阶段(GC 线程正在将存活对象复制到新内存地址),用户线程可能访问 "已转移" 的对象(假设指针高位为0010)------ 此时旧地址已无效,新地址存储在 "转发表(Forwarding Table)" 中。读屏障会触发 "引用自愈" 逻辑:
scss
// 读屏障伪代码(并发转移阶段)
Address readBarrier(Address oldPointer) {
// 1. 检查指针高位的颜色标记
if (oldPointer.color == 已转移(0010)) {
// 2. 从转发表中查询旧地址对应的新地址
Address newPointer = forwardingTable.get(oldPointer);
// 3. 关键:将用户线程的旧指针"更新为新指针"(引用自愈)
updateUserPointer(oldPointer, newPointer);
// 4. 返回新地址,用户线程访问新对象
return newPointer;
}
// 若未转移,直接返回旧指针
return oldPointer;
}好的,接下来看一下ZGC具体的执行流程:
ZGC执行流程图,源:zhuanlan.zhihu.com/p/585254683
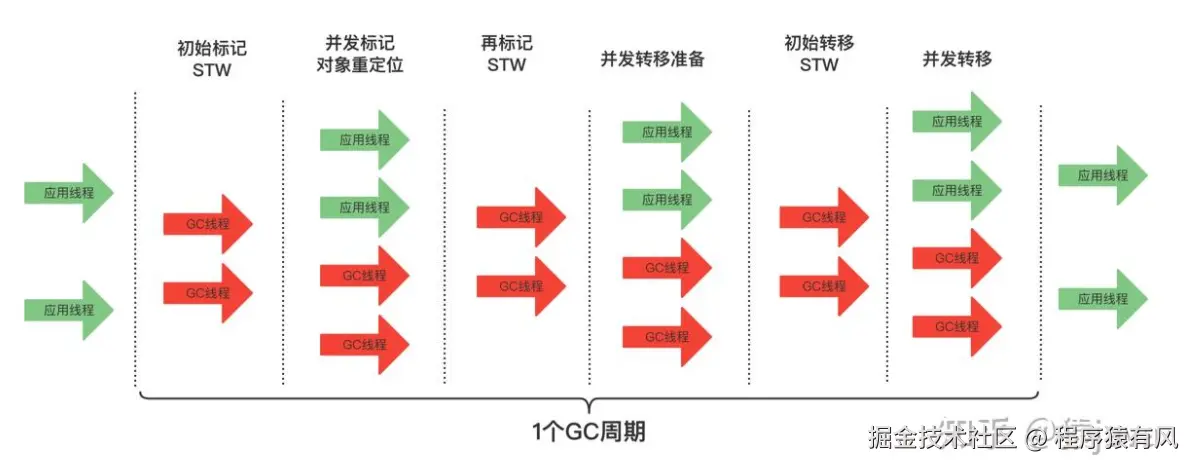
ZGC 执行流程以 "极致低延迟" 为核心,仅 2 个极短 STW 阶段(均 <1ms),其余步骤全与用户线程并发执行,核心流程可简述为 7 步:
- 初始标记(STW) :快速标记 GC Roots 直接可达的对象,仅处理 "根→对象" 的第一层引用,耗时与堆大小无关;
- 并发标记:GC 线程与用户线程并行,通过染色指针遍历引用链,标记所有存活对象(仅修改指针颜色,不碰对象头);
- 再标记:并发处理标记遗漏(如用户线程新增的引用),极少场景需微秒级 STW;
- 并发转移准备:筛选垃圾率高的页面,创建转发表(记录对象转移后新地址),锁定待回收页面;
- 初始转移(STW) :快速转移 GC Roots 直接指向的对象,更新根引用指针,耗时极短;
- 并发转移:GC 线程与用户线程并行转移剩余存活对象,用户线程访问已转移对象时,读屏障自动重定向到新地址(引用自愈);
- 并发重映射:并发更新所有旧指针为新地址,删除转发表,释放旧页面供后续分配。
全程靠染色指针管理对象状态、读屏障处理并发冲突,实现 "超大堆下低延迟回收"。