Spring Boot 数据源自动管理是 Spring Boot 约定优于配置核心思想的典型体现,无需手动编写数据源,框架通过自动配置机制,自动识别数据库依赖、加载连接配置、创建最优的数据源实例,并装配事务管理器、JdbcTemplate 等配套组件,实现数据源的开箱即用,同时兼顾扩展性,支持按需替换数据源、定制连接池参数等。
下面从数据源自动管理、配置 Druid 数据源两方面进行具体介绍。
数据源自动管理
首先需要引入 jdbc 依赖和 springboot 应用场景
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
创建application.yaml

测试数据源
java
@RunWith(SpringRunner.class)
@SpringBootTest
public class DataSourcesTest {
@Autowired
DataSource dataSource;
@Test
public void contextLoads() throws SQLException {
System.out.println(dataSource.getClass());
Connection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
}
}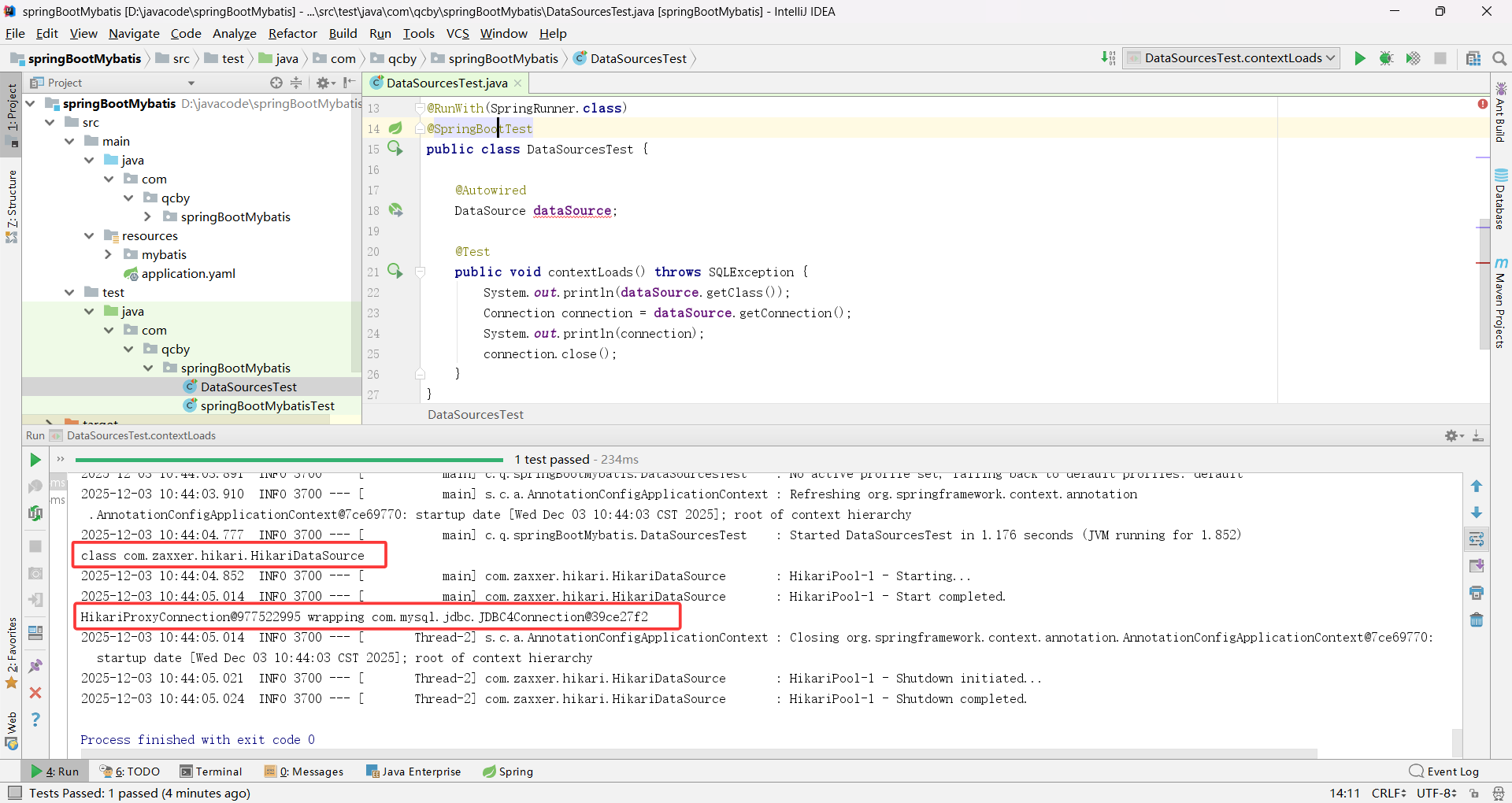
参考 org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration,SpringBoot 默认使用的是 hikari 连接池,默认支持 org.apache.tomcat.jdbc.pool.DataSource、HikariDataSource、dbcp2.BasicDataSource 数据源连接池类型,使用 spring.datasource.type 进行指定自定义的数据源类型。
自定义数据源类型源码:

配置 Druid 数据源
配置 Druid 数据源,本质是在 Spring Boot 项目中将默认的 HikariCP 数据库连接池替换为阿里巴巴开源的 Druid 连接池,并通过配置文件和少量代码完成 Druid 的参数定制,让 Druid 接管数据库连接的生命周期,同时利用其独有的监控、统计、防 SQL 注入等企业级功能,提升数据层的可控性、安全性和性能。
首先需要引入druid 连接池和日志依赖
XML
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>在 application.yaml 中加入 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
验证: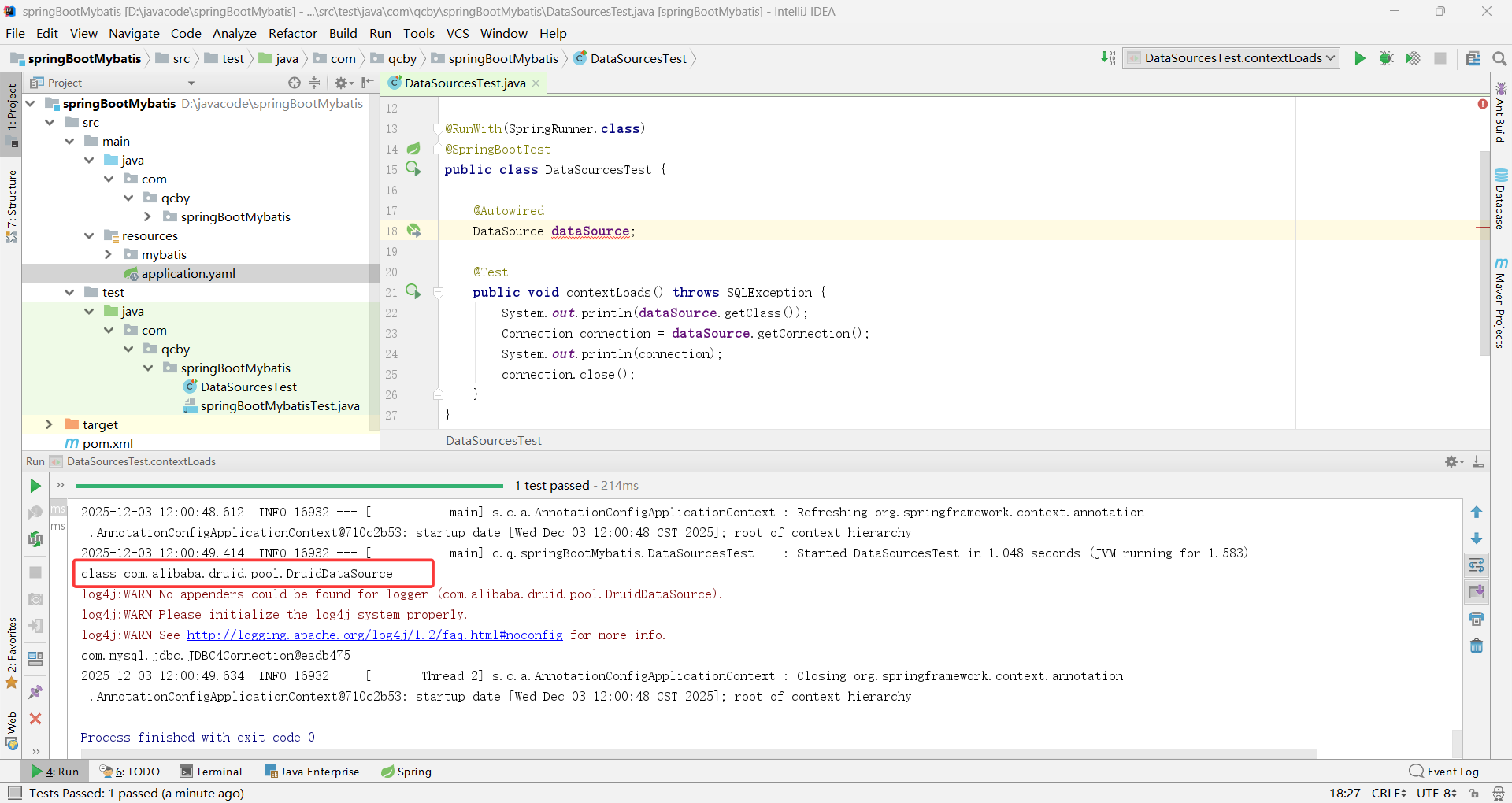
在application.yaml 中加入其他属性配置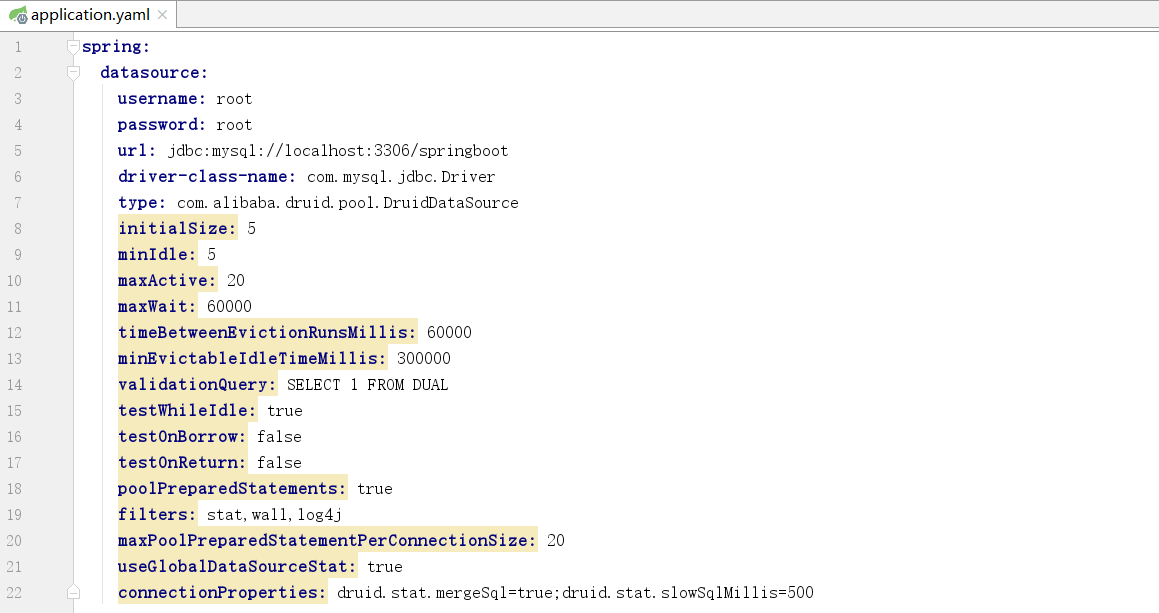
DataSourceProperties 类源码: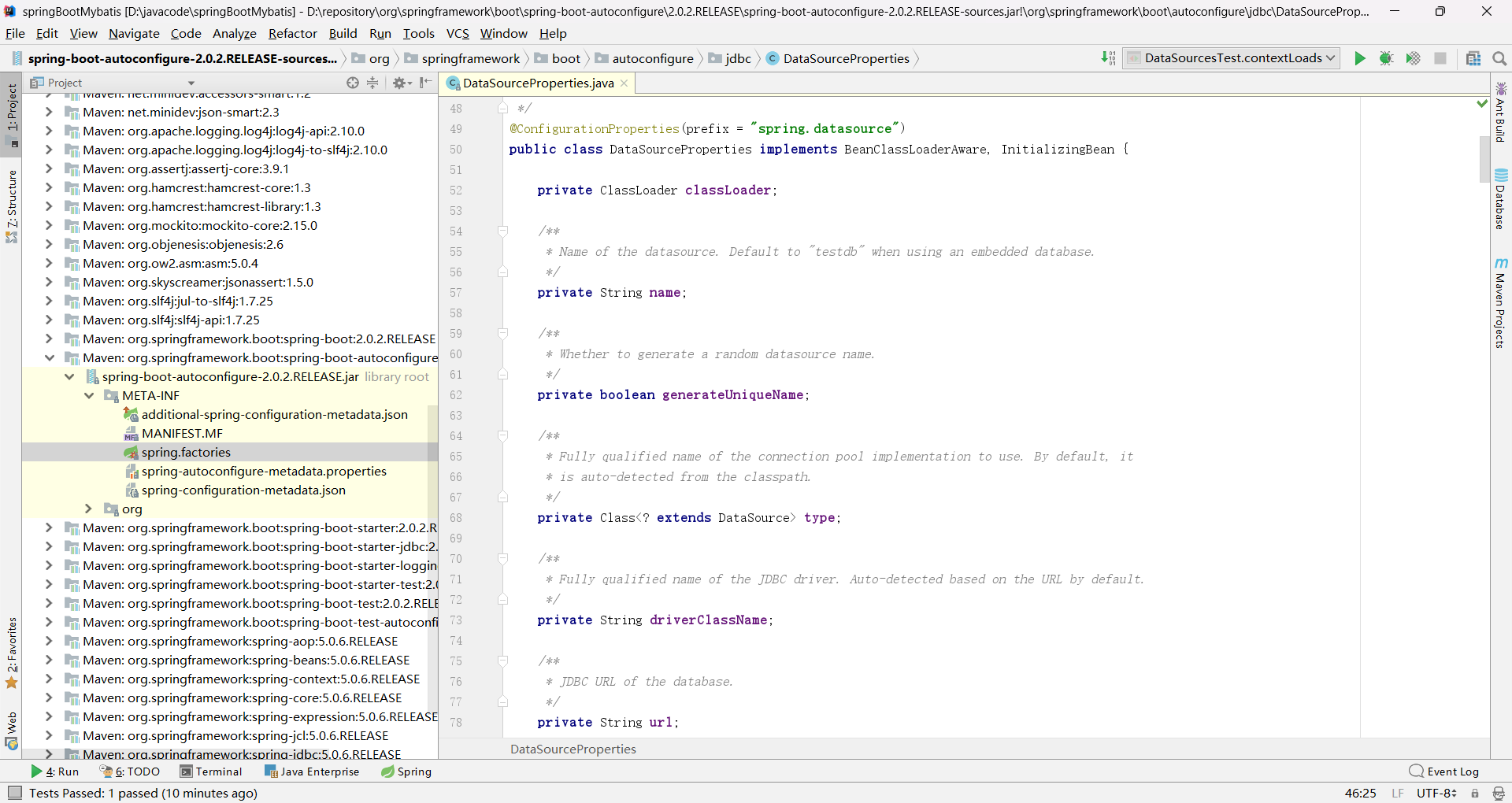
spring.datasource 中默认没有这些属性,所以 application.yaml 中会标黄,且不起作用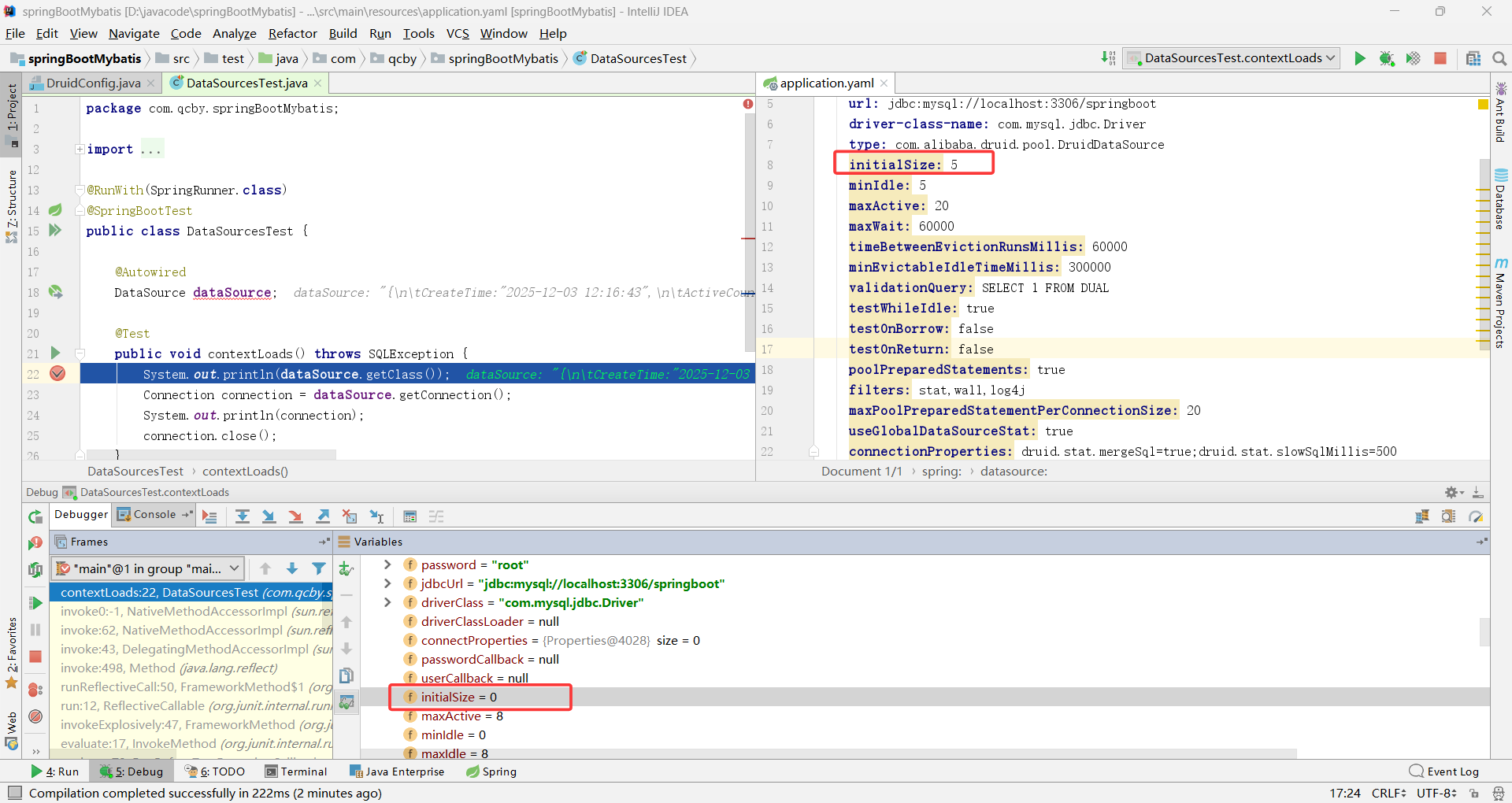
我们需要创建数据源注册类
java
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource dataSource(){
return new DruidDataSource();
}
}DruidDataSource 类包含了那些其他配置属性,如图: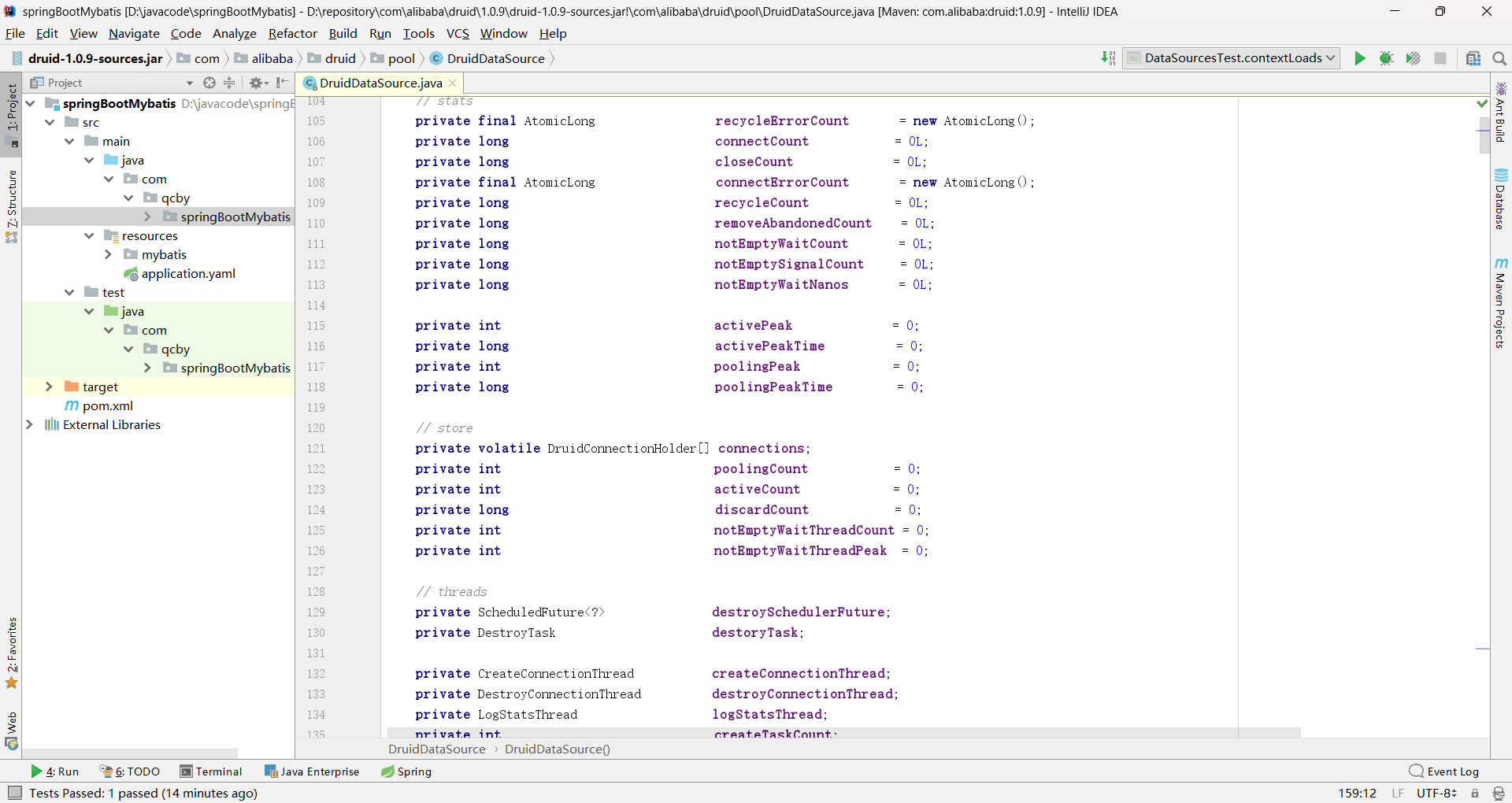
验证,发现这样属性配置就起作用了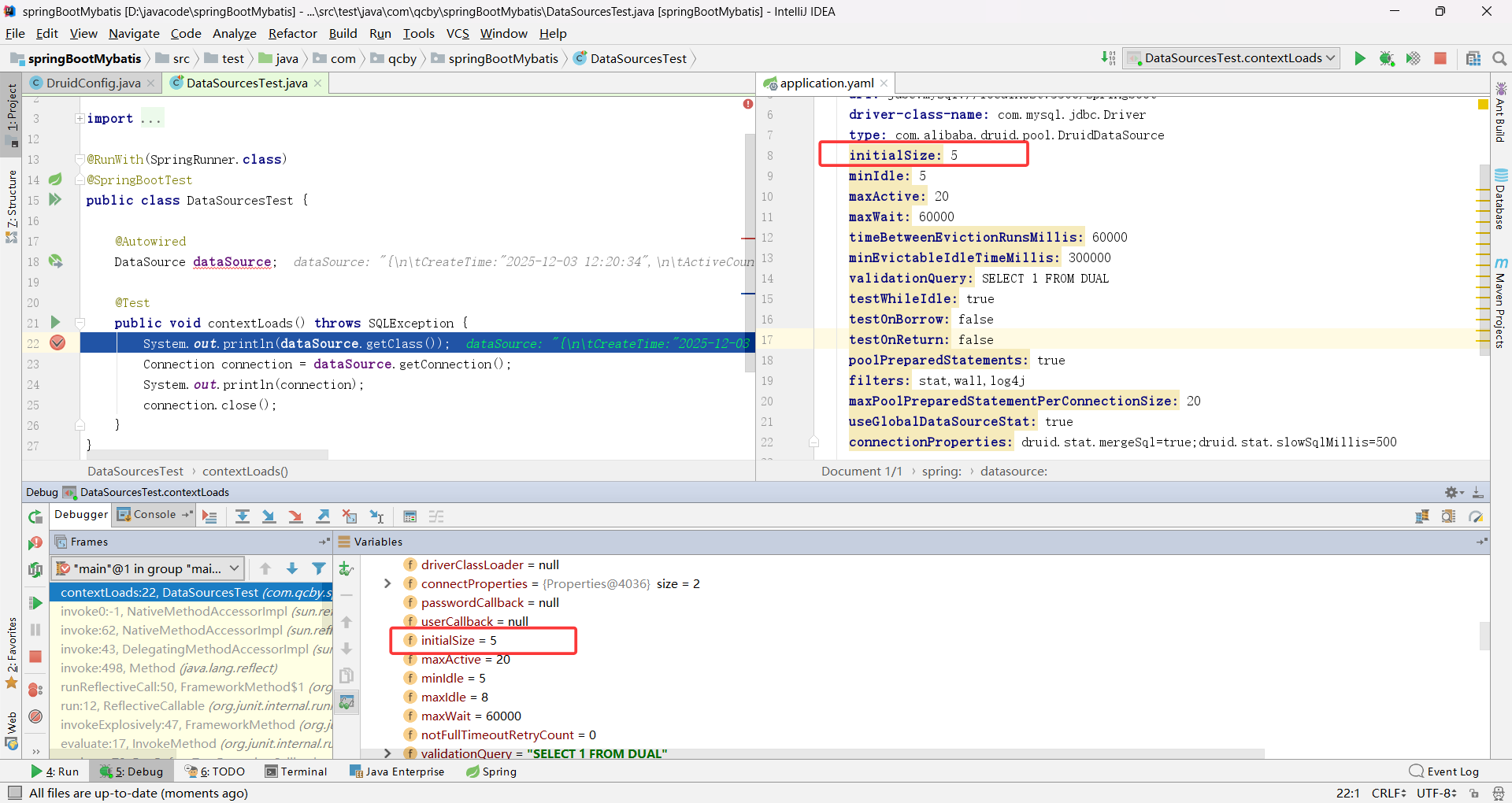
配置druid运行期监控
StatViewServlet 是 Druid 数据库连接池提供的一个内置监控 Servlet,核心作用是通过 Web 界面可视化监控 Druid 连接池的运行状态、SQL 执行情况、慢查询统计等核心指标,是 Druid 连接池的核心监控组件之一。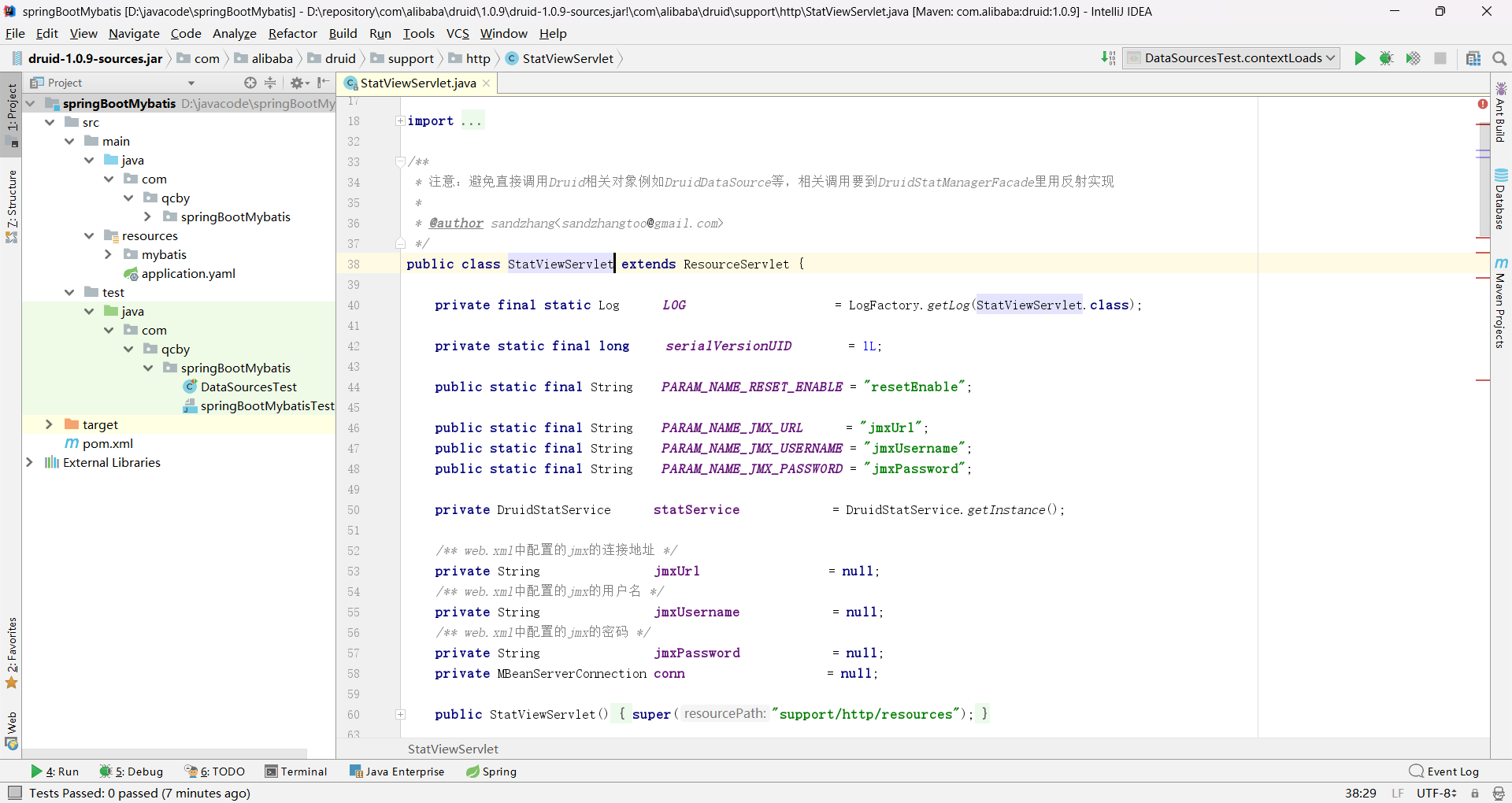
WebStatFilter 是 Druid 数据库连接池提供的一款 Web 监控过滤器,核心作用是采集 Web 应用中HTTP 请求与数据库操作的关联链路数据,为 StatViewServlet(Druid 监控页面)提供Web 层面的监控数据支撑。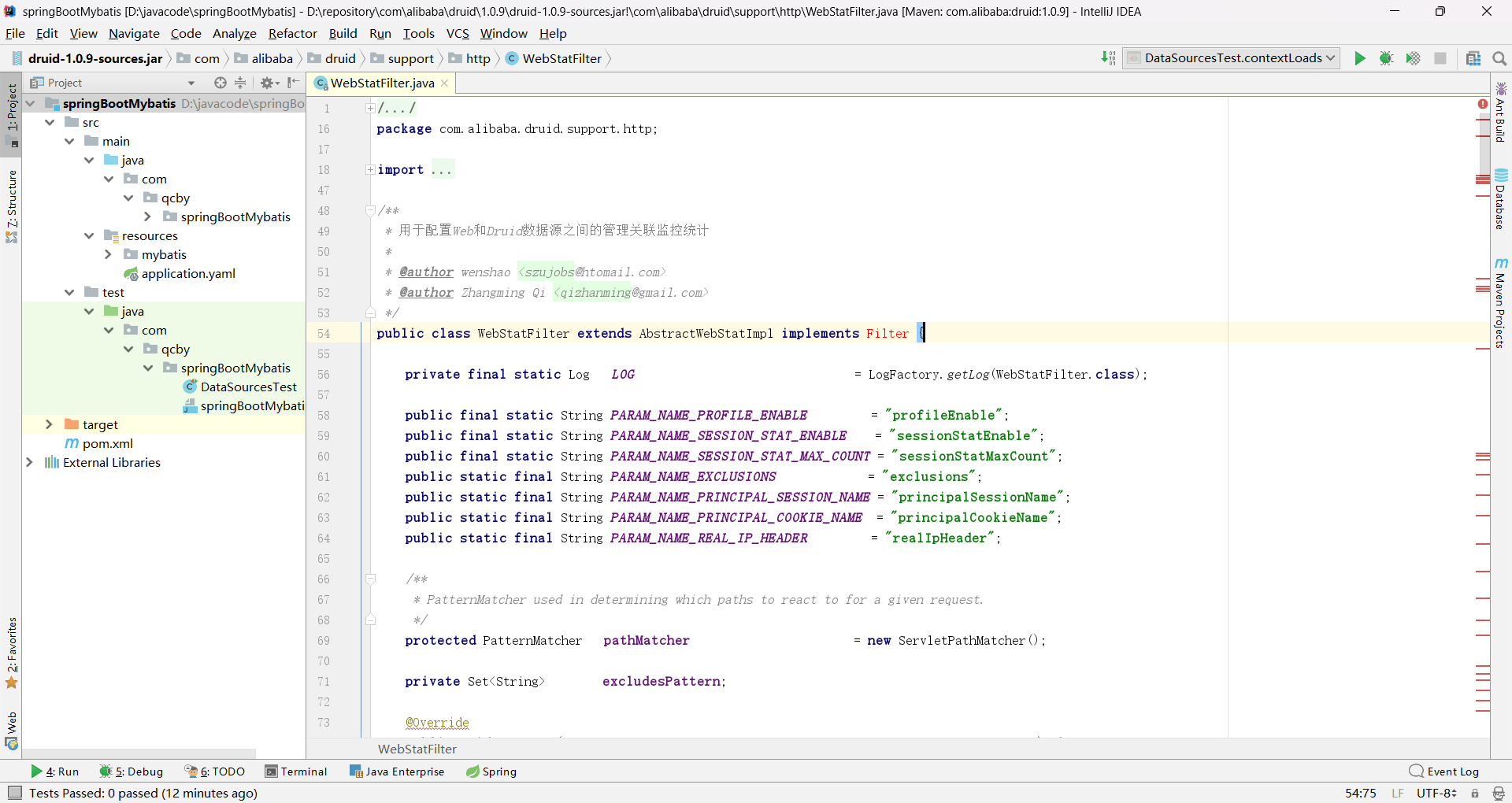
代码内容:
我们需要配置一个管理后台的 Servlet,还需要配置一个监控的 filter,以及配置初始化参数
java
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource dataSource(){
return new DruidDataSource();
}
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(),
"/druid/*");
Map<String,String> initParams = new HashMap<>();
initParams.put("loginUsername","root");
initParams.put("loginPassword","root");
initParams.put("allow","");//默认就是允许所有访问
initParams.put("deny","192.168.15.21");
bean.setInitParameters(initParams);
return bean;
}
//2、配置一个web监控的filter
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean;
bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String,String> initParams = new HashMap<>();
initParams.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}http://localhost:8080/druid 打开监控页面