Apache Spark 集群部署与使用指南
本文档介绍如何使用 Docker 部署 Apache Spark 集群,并通过 PySpark 进行分布式数据处理。
目录
环境准备
确保您的系统已安装以下软件:
- Docker
- Docker Compose
集群部署
1. Docker Compose 配置
创建 docker-compose.yml 文件,配置 Spark 集群:
yaml
services:
spark-master:
image: apache/spark:3.5.0
container_name: spark-master
ports:
- "8080:8080" # Spark Master Web UI
- "7077:7077" # Spark Master 端口
command: /opt/spark/bin/spark-class org.apache.spark.deploy.master.Master
environment:
- SPARK_MASTER_HOST=0.0.0.0
- SPARK_MASTER_PORT=7077
- SPARK_MASTER_WEBUI_PORT=8080
volumes:
- ./data:/opt/spark-data
networks:
- spark-network
spark-worker-1:
image: apache/spark:3.5.0
container_name: spark-worker-1
ports:
- "8081:8081" # Worker 1 Web UI
command: /opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
environment:
- SPARK_WORKER_CORES=2
- SPARK_WORKER_MEMORY=2g
- SPARK_WORKER_WEBUI_PORT=8081
depends_on:
- spark-master
volumes:
- ./data:/opt/spark-data
networks:
- spark-network
spark-worker-2:
image: apache/spark:3.5.0
container_name: spark-worker-2
ports:
- "8082:8081" # Worker 2 Web UI
command: /opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
environment:
- SPARK_WORKER_CORES=2
- SPARK_WORKER_MEMORY=2g
- SPARK_WORKER_WEBUI_PORT=8081
depends_on:
- spark-master
volumes:
- ./data:/opt/spark-data
networks:
- spark-network
networks:
spark-network:
driver: bridge
volumes:
spark-data:2. 启动集群
bash
# 启动 Spark 集群
docker-compose up -d
# 检查容器状态
docker-compose ps
连接集群
1. 进入 Master 容器
bash
docker exec -it spark-master bash2. 启动 PySpark Shell
在容器内执行以下命令连接到集群:
bash
/opt/spark/bin/pyspark --master spark://spark-master:7077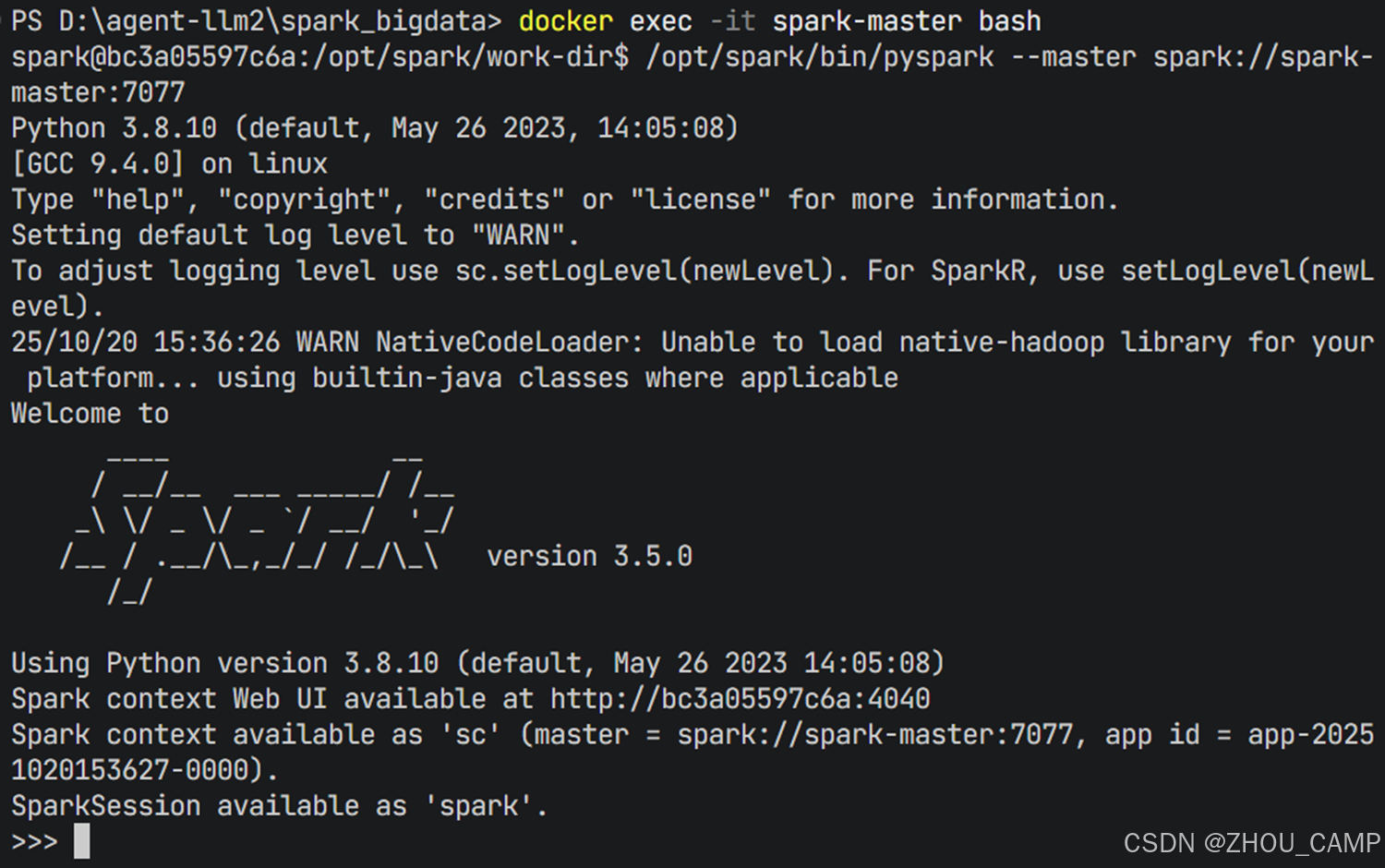
数据处理示例
1. 验证集群连接
python
# 验证 SparkContext 是否正确连接到集群
print("Spark version:", sc.version)
print("Master:", sc.master)
print("应用ID:", sc.applicationId)2. 创建和处理 RDD
python
# 创建一个简单的 RDD 进行计算
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
rdd = sc.parallelize(data)
# 执行分布式计算
result = rdd.map(lambda x: x * 2).filter(lambda x: x > 5).collect()
print("计算结果:", result)预期输出:
计算结果: [6, 8, 10, 12, 14, 16, 18, 20]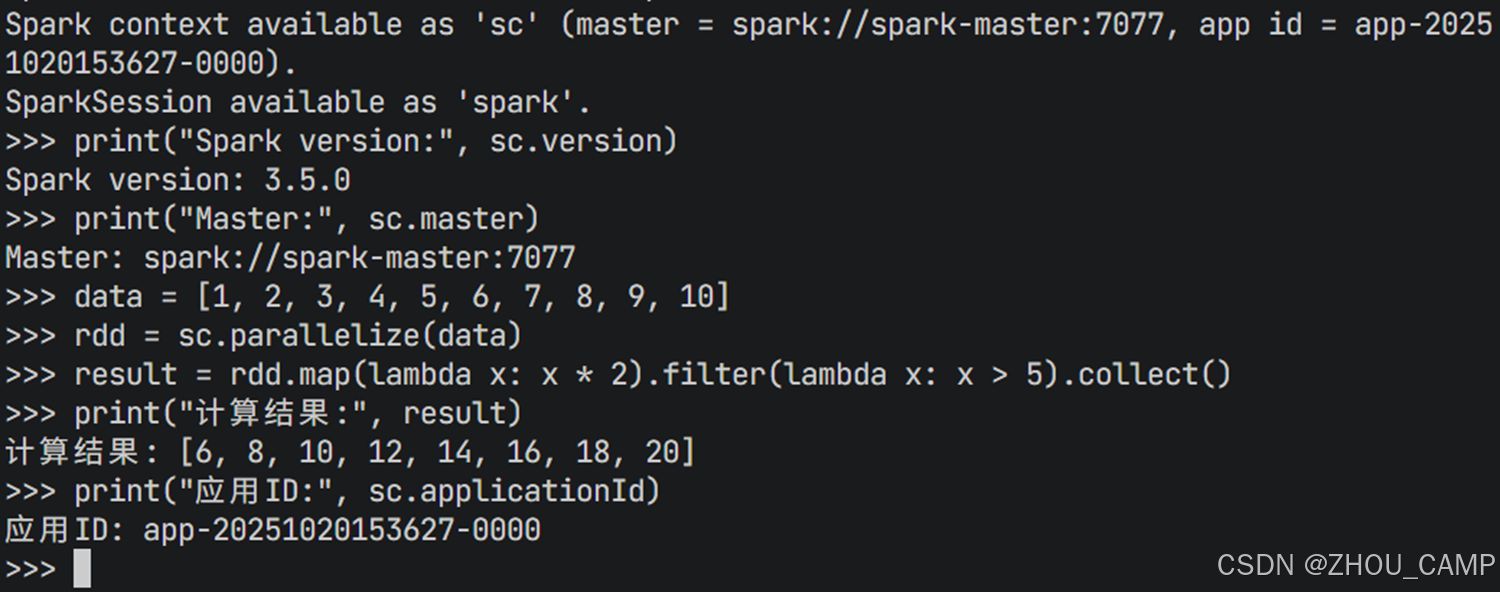
Web UI 访问
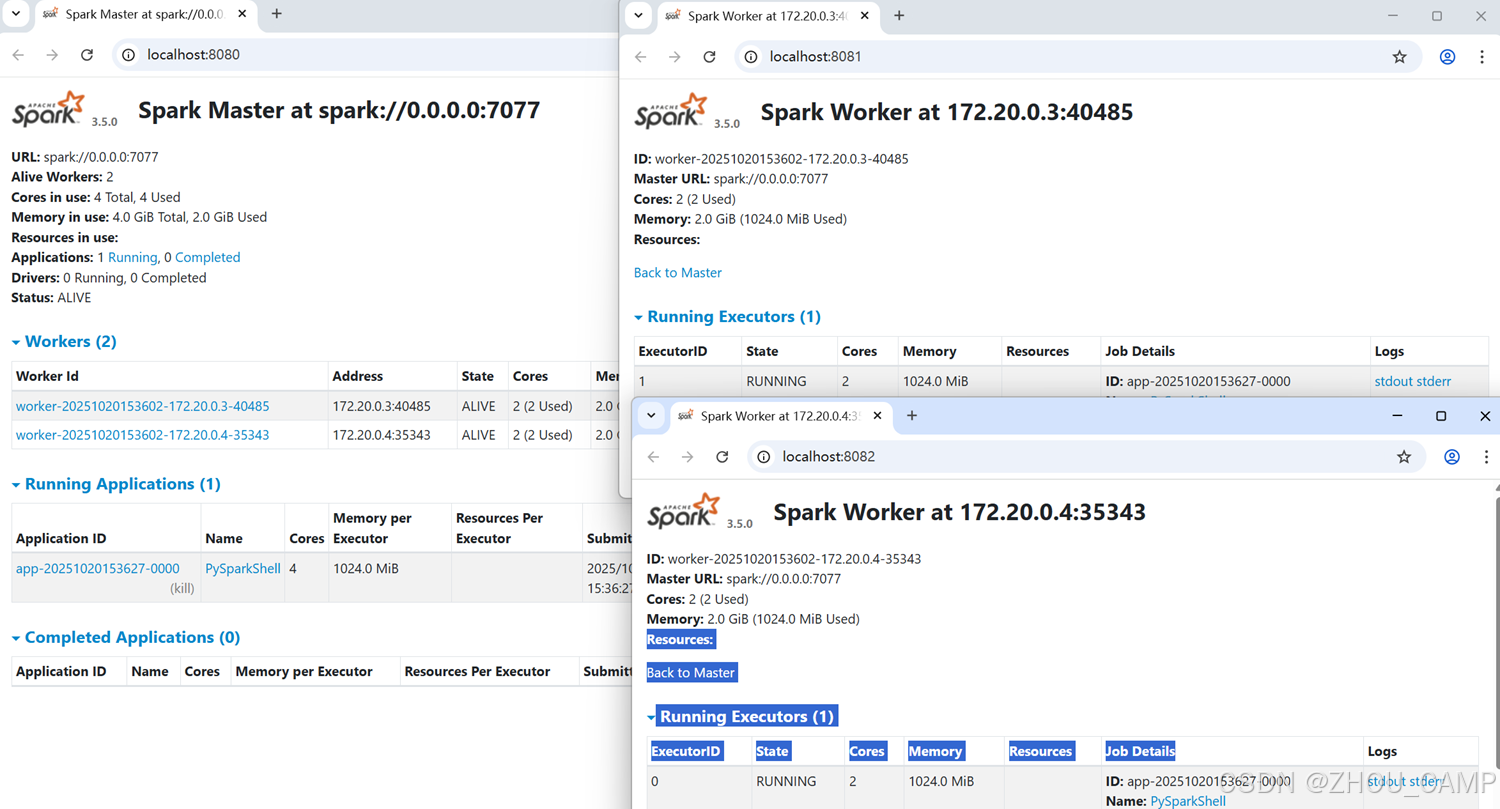
部署完成后,您可以通过以下 URL 访问 Spark Web UI:
- Spark Master UI: http://localhost:8080
- Worker 1 UI: http://localhost:8081
- Worker 2 UI: http://localhost:8082
通过 Web UI 可以监控:
- 集群状态和资源使用情况
- 正在运行的应用程序
- 作业执行历史
- 执行器状态
总结
通过本指南,您已经学会了:
- 使用 Docker Compose 部署 Spark 集群
- 连接到集群并使用 PySpark
- 执行基本的分布式数据处理任务
- 通过 Web UI 监控集群状态
这为进一步的大数据处理和分析奠定了基础。