前言
本文将最简单的共享内存开始,讲述共享内存/TCP/DPDK/RDMA/CXL/NVLink/UB 等通信方式的基本原理,探讨如何让程序更高效地连起来。
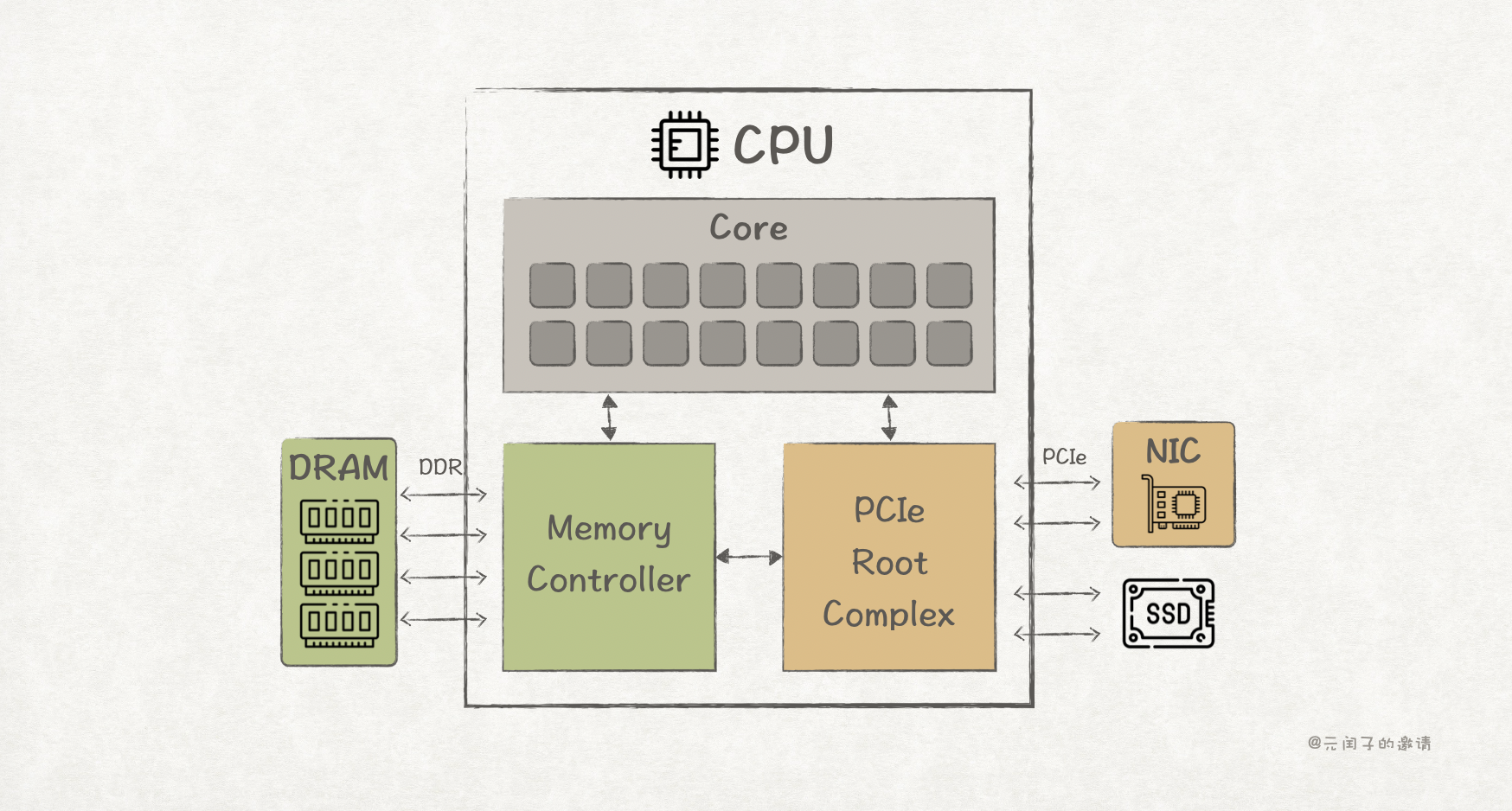
上图为计算机的简易组成,核(Core)是 CPU 的大脑,执行程序的业务逻辑;
内存 DRAM 通过 DDR 接口连接到 CPU 内的内存控制器(Memory Controller)中,存放程序运行所需的数据;
而网卡 NIC、SSD 等高速外围设备则通过 PCIe 接口接入 CPU,由 PCIe Root Complex 进行协议解析、路由等。
在《探索OS的内存管理原理》里我们提到,每个程序都有独立的内存地址空间,以防止其他程序的篡改。所以,程序 A 保存在内存里的业务数据,程序 B 是无法访问的。
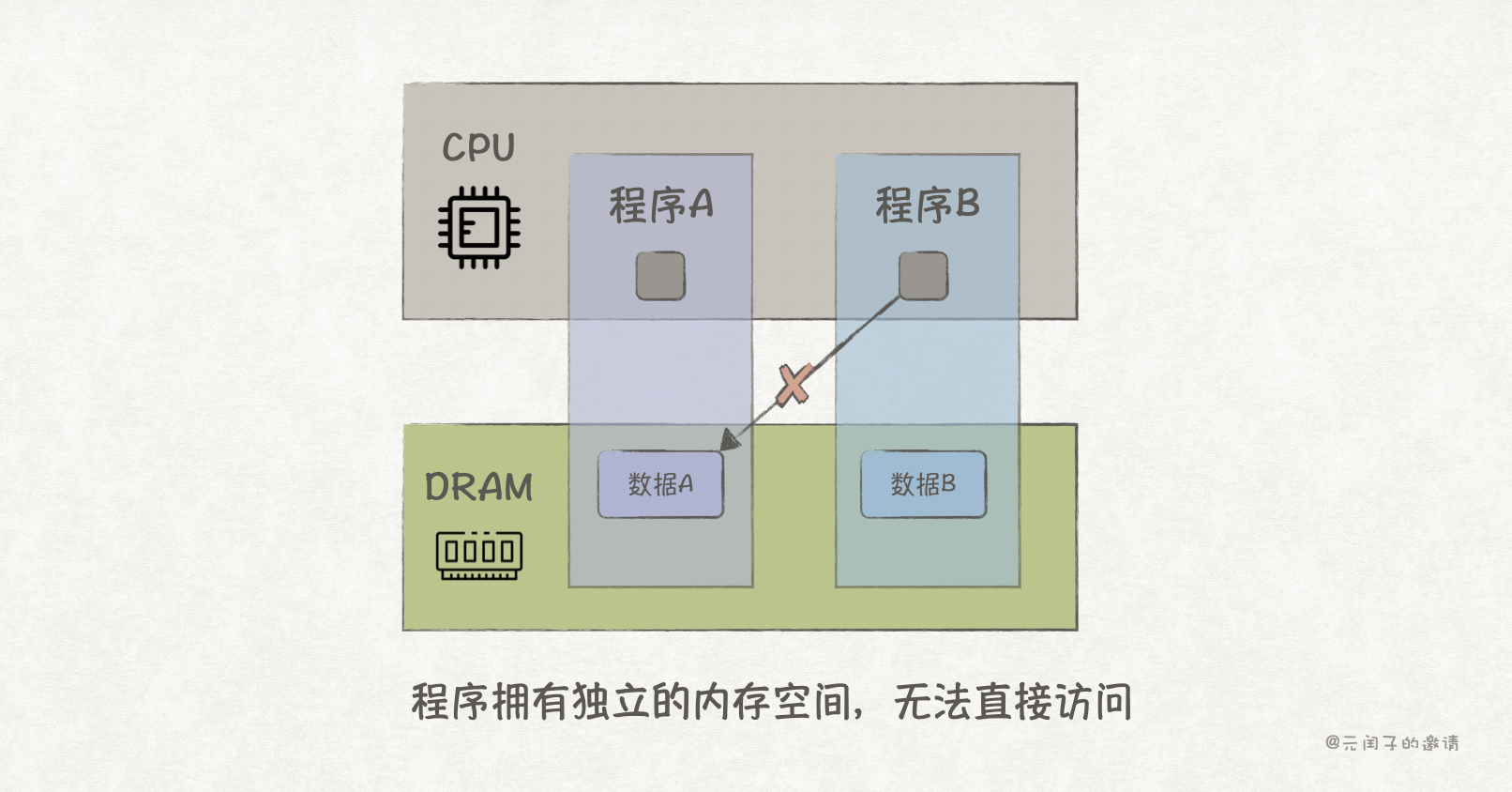
然而,复杂的业务往往需要多个程序协同合作,比如,数据需要先后经过程序 A 和程序 B 的处理。
这时,要怎么把程序连起来,让程序 B 可以访问程序 A 的数据呢?
共享内存
这是一个进程间通信的问题,回忆操作系统原理,我们能想到的最简单的方式就是共享内存。
POSIX 提供了 shm_open 和 mmap 系统调用,它们配合可实现进程间的通信,简易代码如下:
c
// 程序A的代码
int procA(void) {
// 1. 双方约定好的共享内存key
const char *key = "/proc_shm";
const size_t sz = sizeof(int);
// 2. 创建并打开共享内存对象
int fd = shm_open(key, O_CREAT | O_RDWR, 0666);
// 3. 设置大小
ftruncate(fd, sz);
// 4. 映射
int *p = mmap(NULL, sz, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// 5. 写入数据
*p = 12345;
...
return 0;
}
// 程序B的代码
int procB(void) {
// 1. 双方约定好的共享内存key
const char *key = "/proc_shm";
const size_t sz = sizeof(int);
// 2. 创建并打开共享内存对象
int fd = shm_open(name, O_RDWR, 0666);
// 3. 映射
int *p = mmap(NULL, sz, PROT_READ, MAP_SHARED, fd, 0);
// 4. 读取数据,输出12345
printf("%d", *p);
...
return 0;
}只要程序 A 和程序 B 约定好一个 key,就能使用 shm_open 等到一个 fd,再通过 mmap 将它映射到内存里,就能实现数据共享。
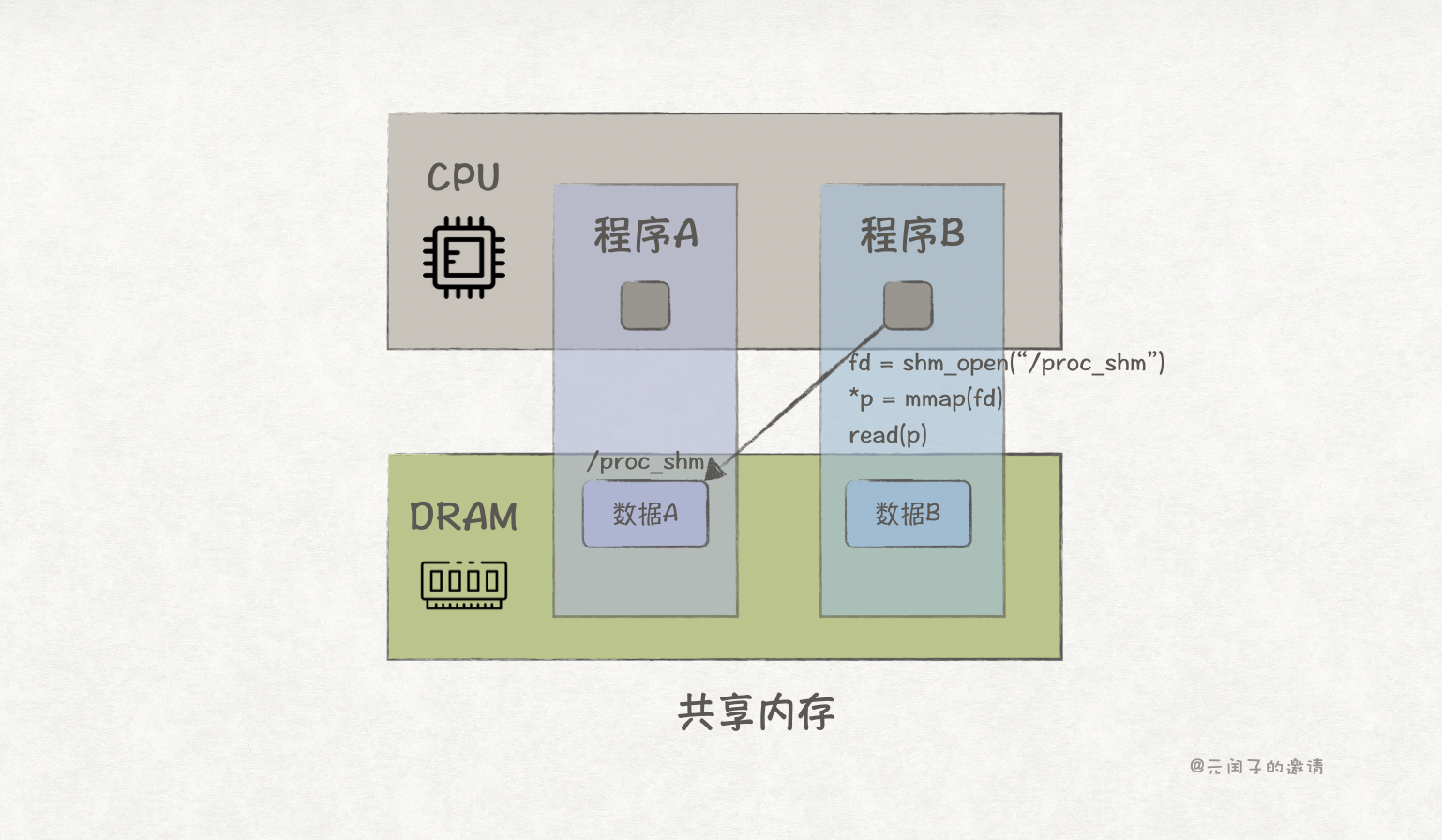
共享内存的方式下,以 AMD Zen5 为例,数据访问的带宽理论可达 614GB/s,时延能够做到 <100ns,这对于常见的程序已经足够快。
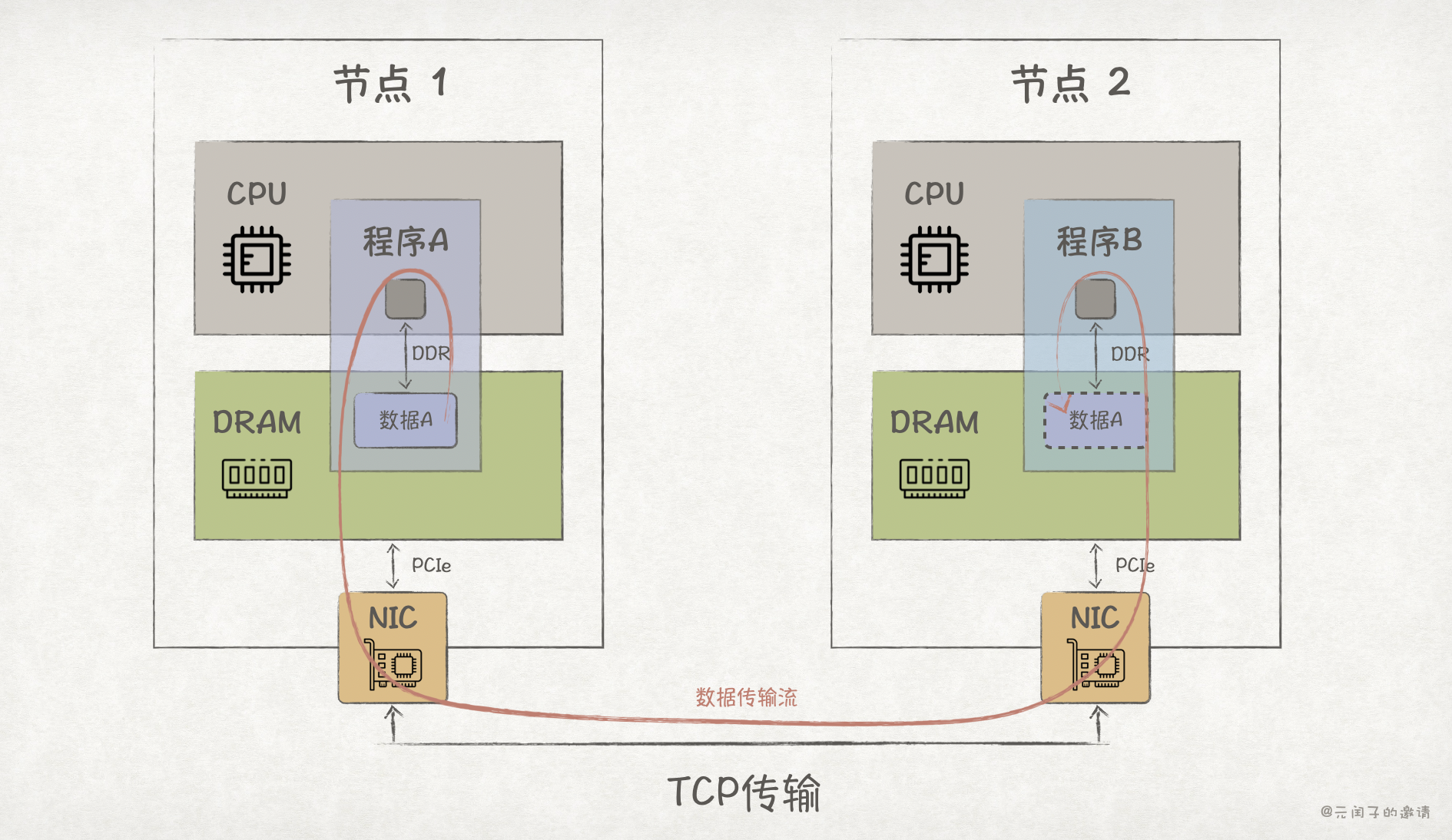
然而,使用共享内存的前提是程序们必须处在同一个物理内存下。如果程序 A 和程序 B 分布在不同的节点,那么共享内存就无法用了,需要网络通信。
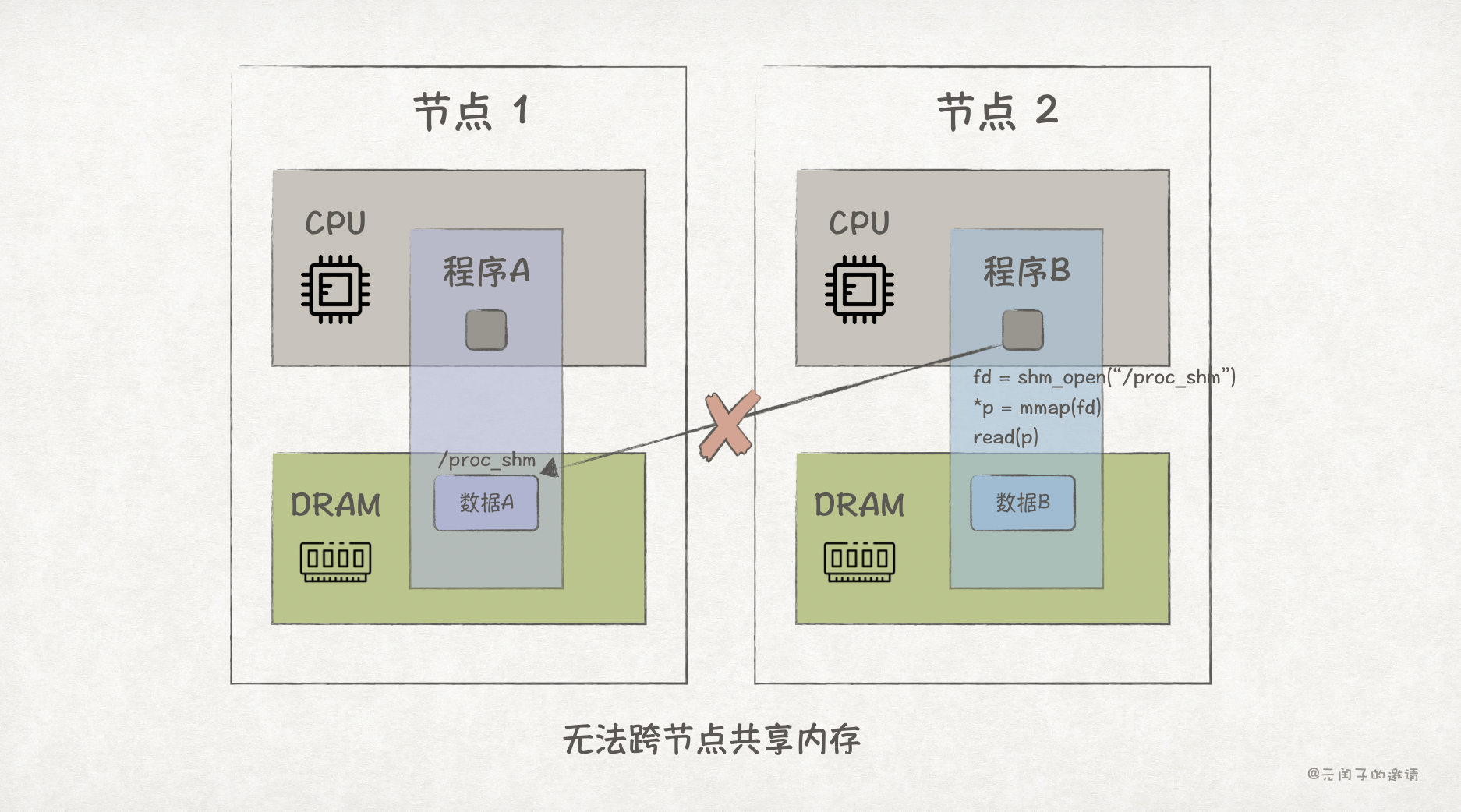
TCP 通信
最常见的网络通信协议是 TCP,它是可靠的传输协议,能够实现跨节点的程序通信。
TCP 只是协议,要实现网络通信,还需要依赖网卡 NIC 硬件的能力。它的基本原理是,程序 A 将内存中的数据按照 TCP 协议格式打包好,通过 NIC 经过以太网传输到程序 B 所在的节点上。
POSIX 同样提供了 TCP 通信的系统调用,主要为 socket、recv、send 等,简易代码如下:
C
// 程序B代码,数据接收方
int procB(void) {
// 1. 创建套接字:IPv4、面向连接(SOCK_STREAM)、TCP
int listen_fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// 2. 绑定本地IP:端口
bind(listen_fd, &serv_addr, sizeof(serv_addr));
// 3. 开始监听
listen(listen_fd)
// 4. 阻塞等待客户端发起连接
int conn_fd = accept(listen_fd, &cli_addr, &cli_len);
// 5. 建立连接后,接受输入写入本地内存缓冲区buf
char buf[BUF_SIZE];
while ((n = recv(conn_fd, buf, BUF_SIZE, 0)) > 0) {...}
...
}
// 程序A代码,数据发送方
int procA(void) {
// 1. 创建套接字:IPv4、面向连接(SOCK_STREAM)、TCP
int sockfd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// 2. 向服务端发起TCP连接
connect(sockfd, &serv_addr, sizeof(serv_addr));
// 3. 将内存缓冲区buf的数据发送到服务端
send(sockfd, buf, len, 0);
...
}上述代码实际运行时,会涉及到 CPU 与操作系统用户态内存、内核态内存、网卡缓冲区的协同配合,流程如下图所示:
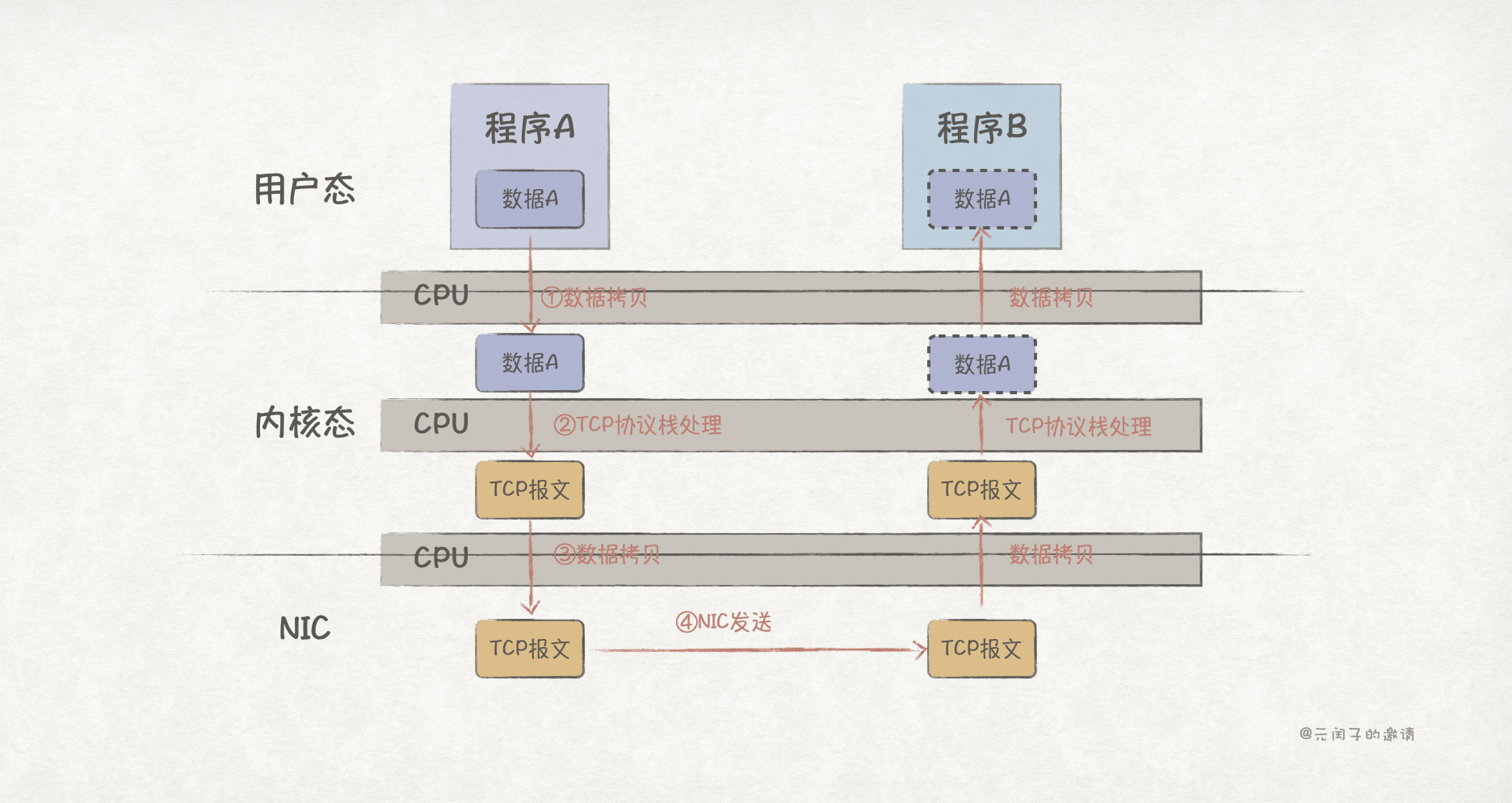
可以看到,在发送方,数据一共经过了 2 次拷贝和 1 次协议栈处理,而且 CPU 都有参与。这意味着,数据在经过 NIC 发出去之前,CPU 全程都处于忙碌状态。
然而,让 CPU 来处理简单的数据传输任务,是一个十分低效的决定。
为此,计算机引入了 DMA(Direct Memory Access)来分担 CPU 数据传输的任务。现代计算机体系结构中,DMA 控制器通常在网卡设备上。
在 TCP 报文从内核态拷贝到 NIC 缓冲区阶段,CPU 只需将 TCP 报文的内存地址映射为 DMA 地址,这样 NIC 就能通过 DMA 将 TCP 报文拷贝到 NIC 缓冲区,拷贝过程无需 CPU 参与。
NIC 发送数据后,再通过硬件中断唤醒 CPU 继续处理程序 A 接下来的逻辑。接收方也是类似的流程。
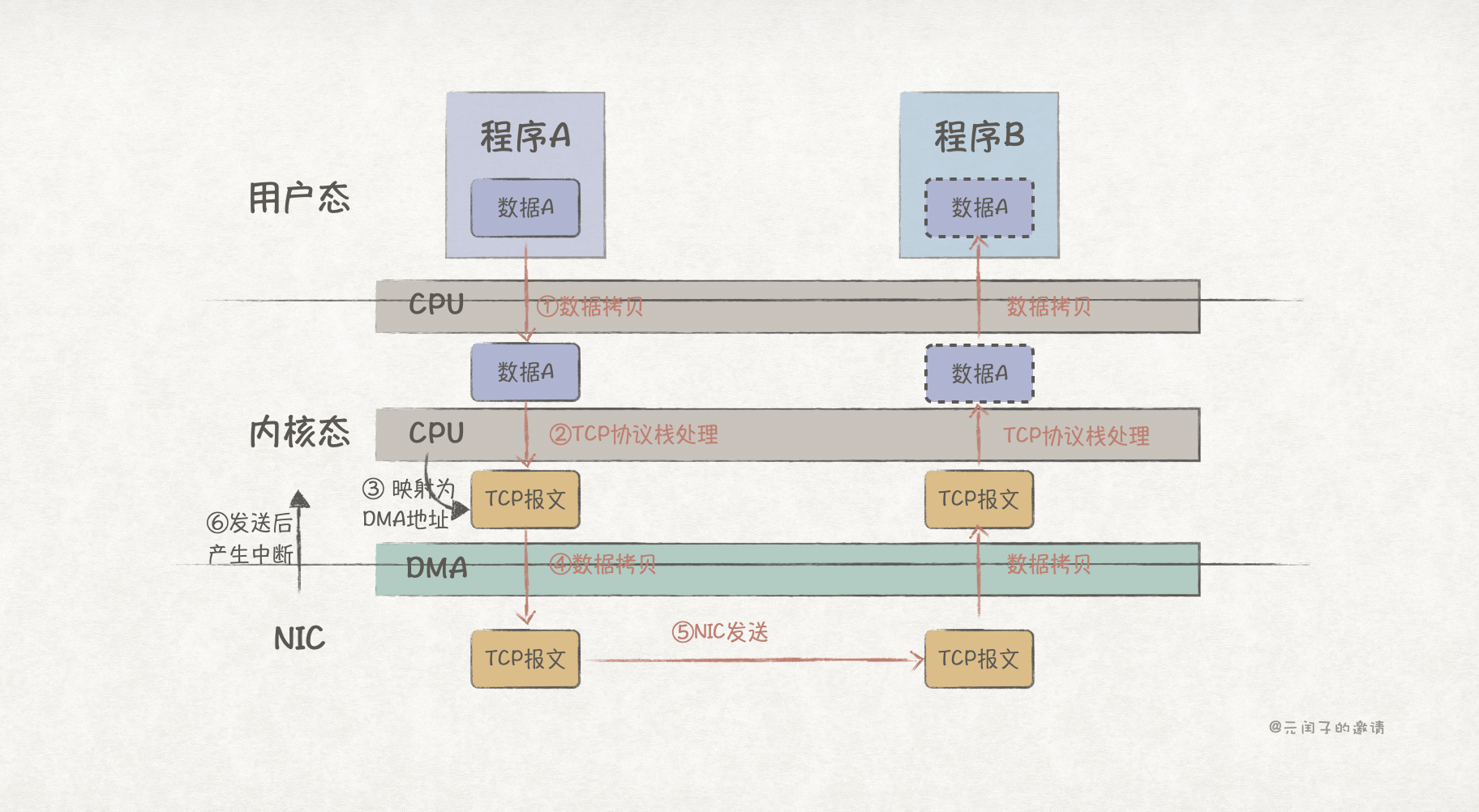
然而,每次发送数据都要经历一次从用户态到内核态的数据拷贝,这其中涉及到了 1 次 CPU 上下文切换;而每次发送后产生中断,都需要 CPU 进行上下文切换,并处理中断程序。
这些流程无疑都增加了 CPU 的负担,对于网络密集型程序,CPU 可能会一直忙于数据拷贝、上下文切换、中断处理!
TCP 网络通信的带宽与网卡规格相关,比如常见的 100Gb 网卡,双边通信带宽 25GB/s。但在通信时延上,不算网络传播时延,数据从用户态到 NIC 发出的过程,就需要 >100µs。
这百微妙级的时延,会使得网卡带宽的无法被充分利用起来,需要进一步的优化。
DPDK 加速 TCP 通信
DPDK(Data Plane Development Kit)是由 Intel 推出的一个网络加速库,与传统 TCP 通信路径对比如下:
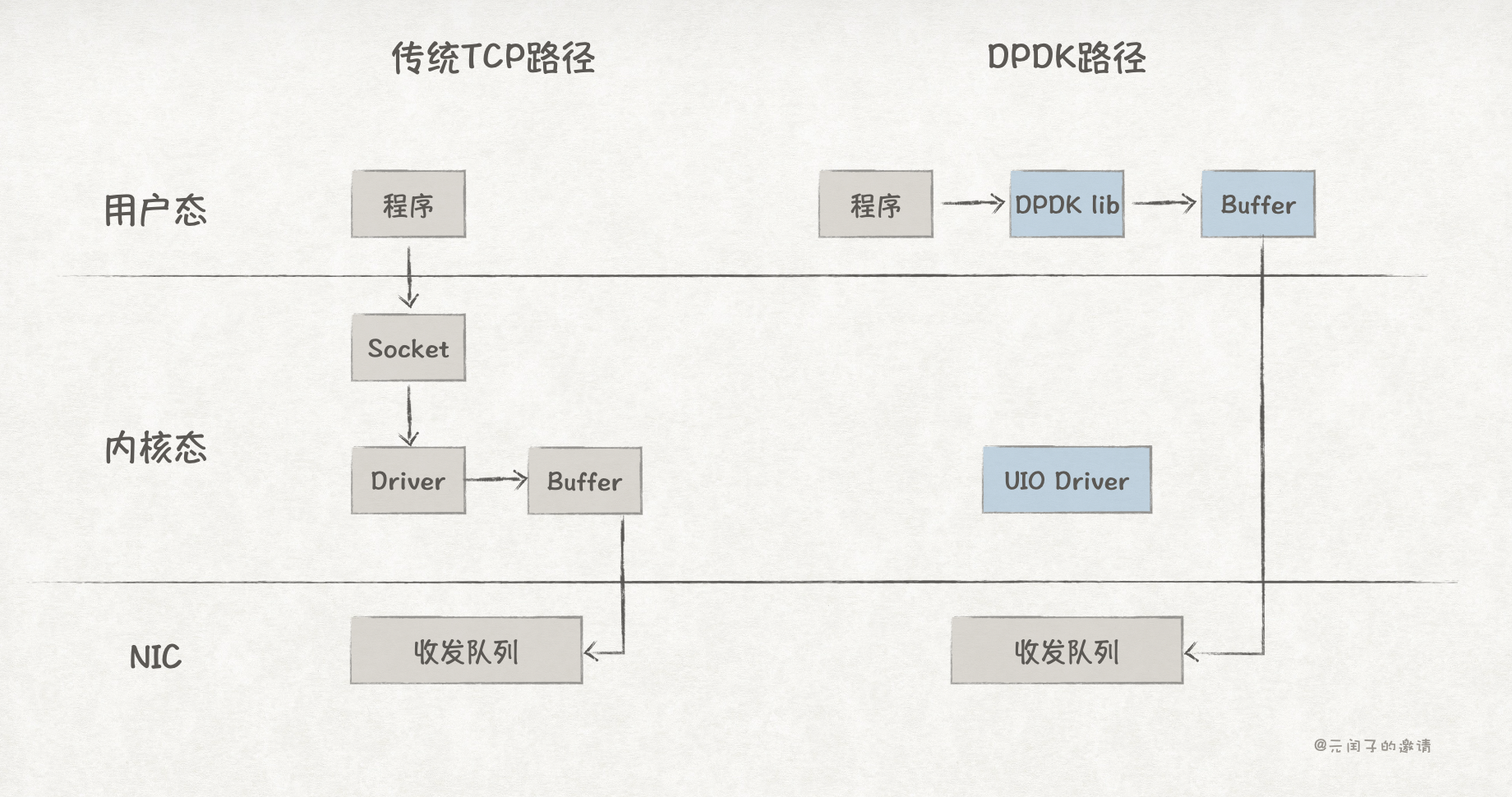
DPDK 提供了 UIO 网卡驱动,应用程序通过 DPDK lib 可直接将数据从用户态传输到 NIC,完全绕过了内核,数据零拷贝;
另外,它基于 PMD(Poll Mode Driver)的轮训模式,消除了数据收发路径上的中断。
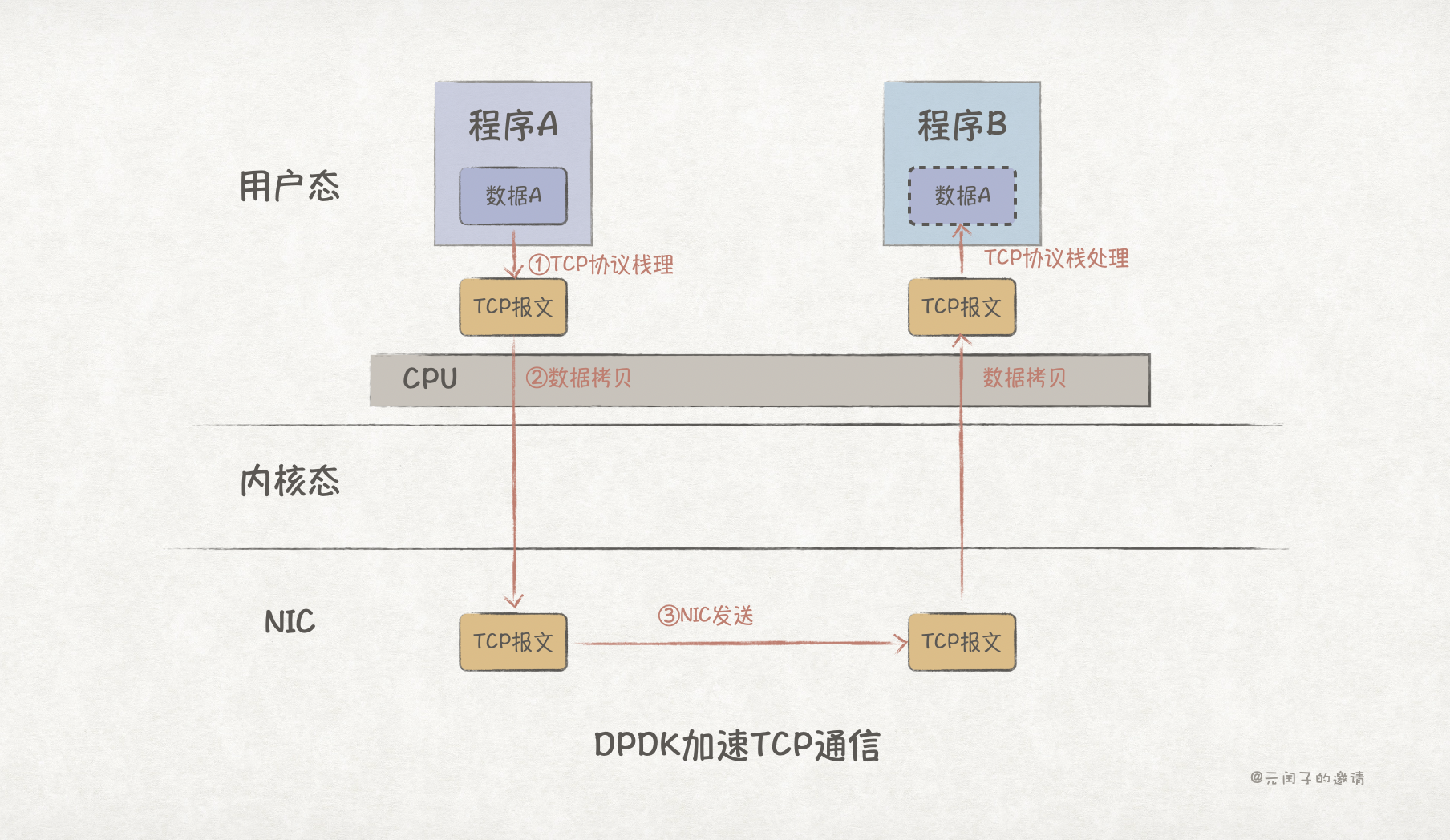
可以看到,DPDK 的路径更加短了,时延也从传统 TCP 通信方式的 100µs 降低至 10µs 左右。
不过 DPDK 并不提供 TCP 协议栈处理能力,程序需要自己实现,或者引入第三方库。
DPDK 虽然通过绕过内核的方式缩短了数据收发路径,降低了 TCP 通信时延,但它仍需要 CPU 对 TCP 协议栈进行处理。而且轮训的数据驱动方式也会一直占用 CPU。
那么,有没有办法能够让整个数据收发链路都绕过 CPU,让 CPU 能够专注业务逻辑处理呢?
RDMA 通信
RDMA(Remote Direct Memory Access),远程直接内存访问,是一种能够绕过 CPU 和操作系统内核的通信技术。
不同于 DPDK 在 TCP 通信上做优化加速,RDMA 在协议栈、NIC 硬件上都做了优化升级。
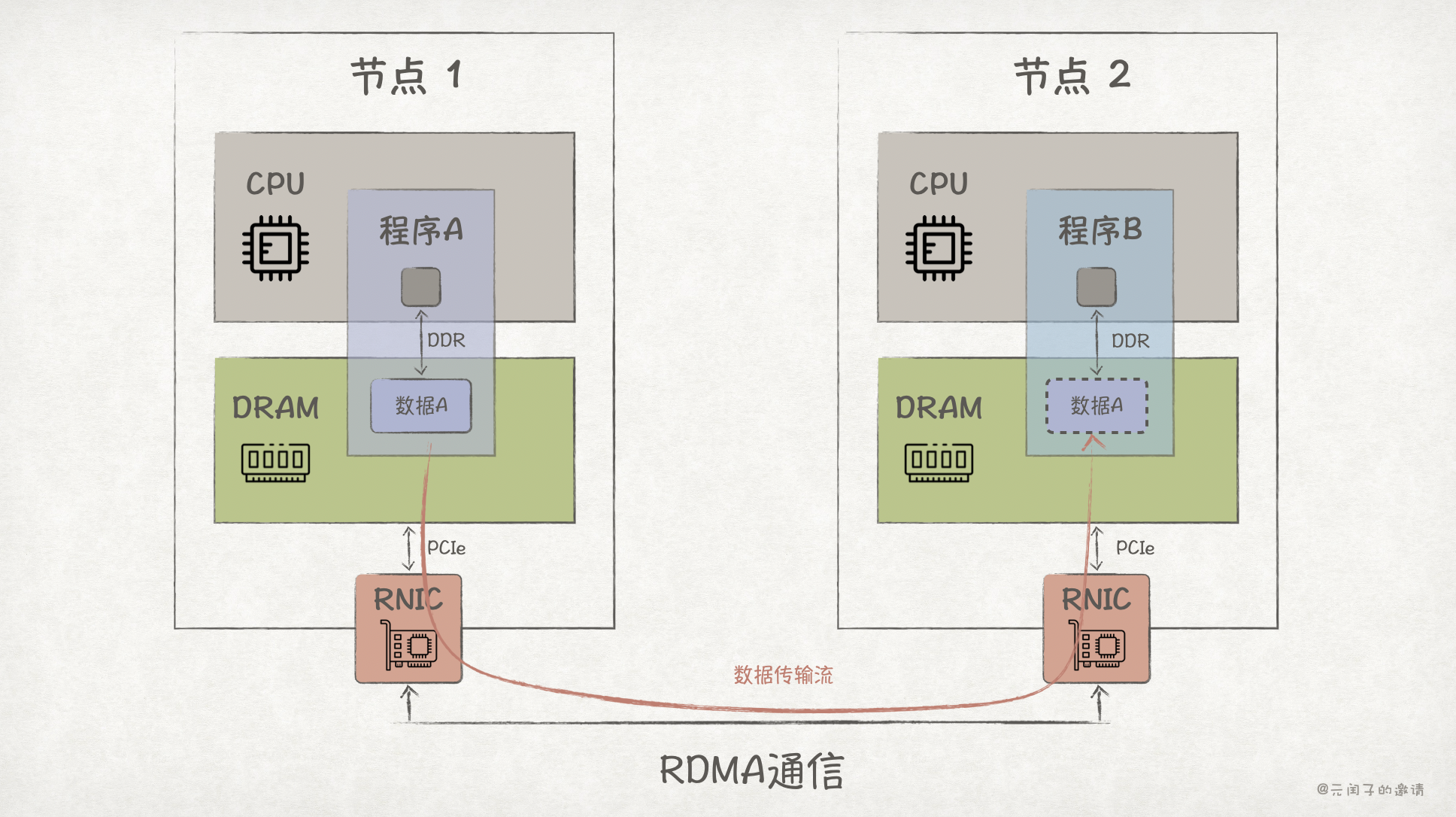
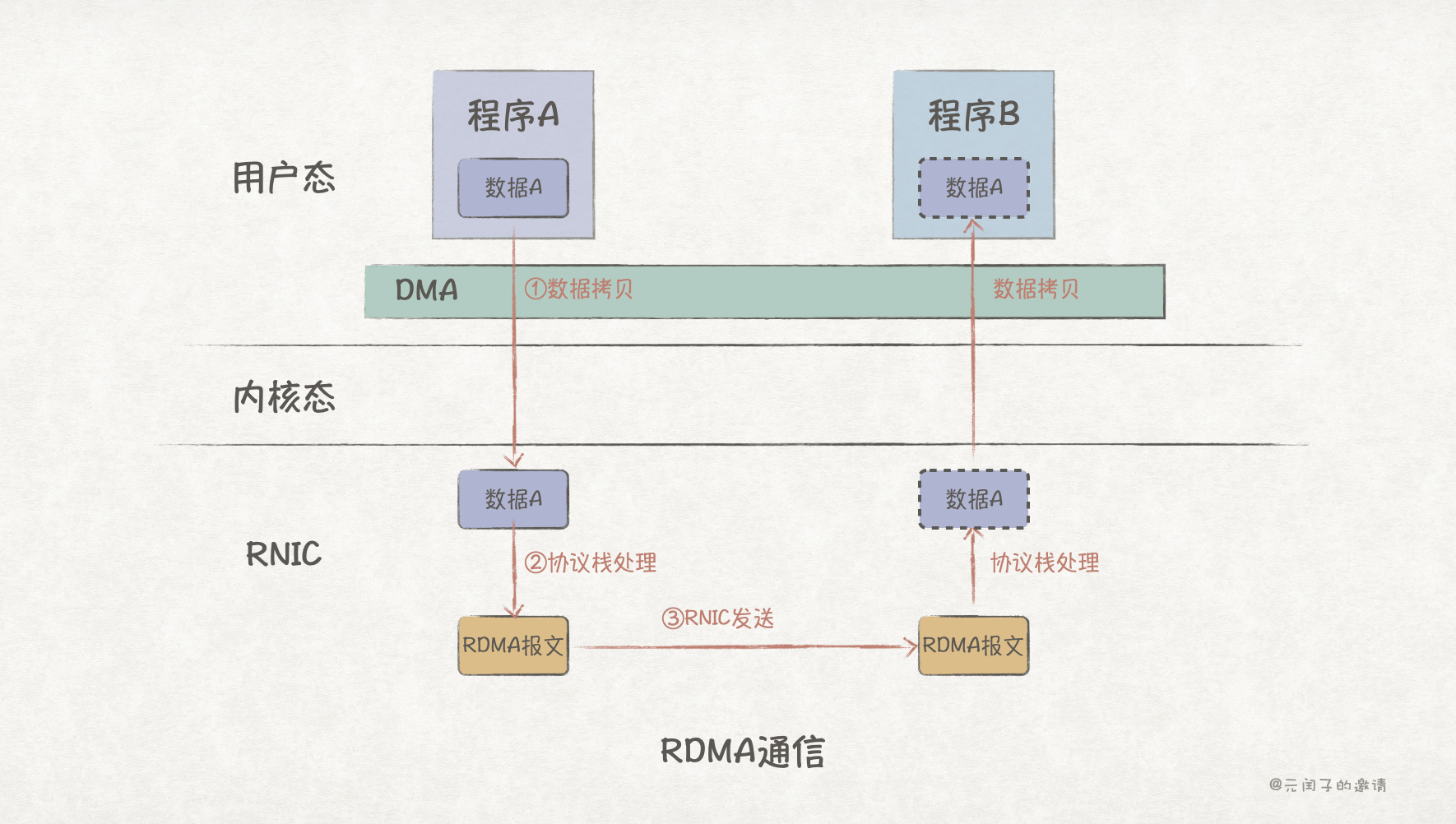
如上图所示,使用 RDMA 需要引入专门的网卡 RNIC,它支持在网卡内直接进行协议栈处理,并能够使用 DMA 将数据从内存传输到网卡上,从而绕过了 CPU。
RDMA 有如下三种实现方式:
| InfiniBand (IB) | RoCE v2 | iWARP | |
|---|---|---|---|
| 底层协议 | 专用 IB 物理/链路层 | 以太网+UDP/IP | 以太网+TCP/IP |
| 时延 | 0.5µs ~ 2µs | 1µs ~ 3µs | 10µs ~ 15µs |
| 硬件依赖 | 专用 IB 交换机、光纤、HCAs、网卡 | 复用现有以太网基础设施、专用网卡 | 完全基于标准以太网+TCP、专用网卡 |
InfiniBand 虽然性能最好,但起建成本也最高。RoCE v2 性能较好且成本适中,约为 InfiniBand 的 30~50%,是目前应用最广泛的实现。
因为 RDMA 时延更低,所以在规格相同的网卡下,比如 100Gb 的 NIC 和 RNIC,RDMA 比传统 TCP 有更高的带宽利用率。
现在 RDMA 已经被广泛应用在 AI、HPC 等依赖高性能通信的场景。
不过 RDMA 的数据收发链路上仍然存在 1 次数据拷贝和协议栈处理,在编程复杂度、带宽和时延上,对比共享内存的方式,仍有较大的差距。
在前文分析中,我们注意到,NIC/RNIC 是通过 PCIe 接口接入 CPU,而 DMA 从内存中拷贝数据,也是通过 PCIe 传输。
那么,能不能在节点间也通过 PCIe 协议通信,这样也许就能做到用 Load/Store 内存语义访问远端节点内存数据,免数据拷贝,也不用复杂的协议栈处理了?
CXL 通信
CXL (Compute Express Link),是一种建立在 PCIe 之上的低时延、高带宽的互联协议,能够实现 CPU 与内存、IO设备、XPU 加速器的互联。
从 2019 年发布至今,已经经历了 CXL 1.0/2.0/3.0 三个大版本。CXL 主要有 3 个子协议组成:
- CXL.io:与 PCIe 的事务层/链路层保持兼容,负责 设备发现、配置、DMA、中断等,为所有 CXL 设备提供统一的 I/O 通道。
- CXL.cache:让 XPU 加速器和外设能够缓存并直接访问主机(CPU)内存,并保持缓存一致性。
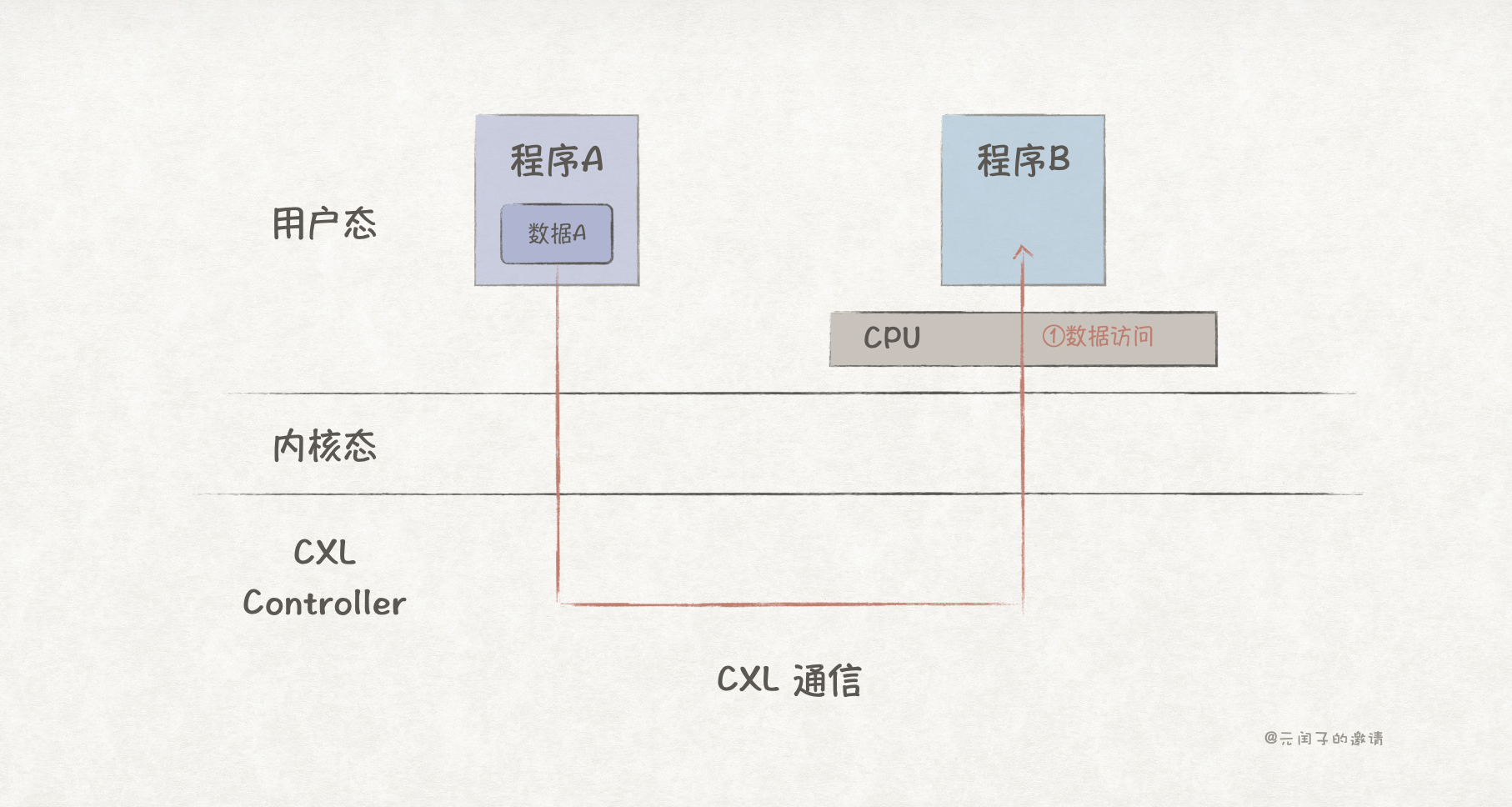
- CXL.mem :使主机 CPU 能够直接对 CXL 端点上挂载的内存设备进行 Load/Store 内存语义访问,等同于把外部内存映射到主机的内存地址空间。
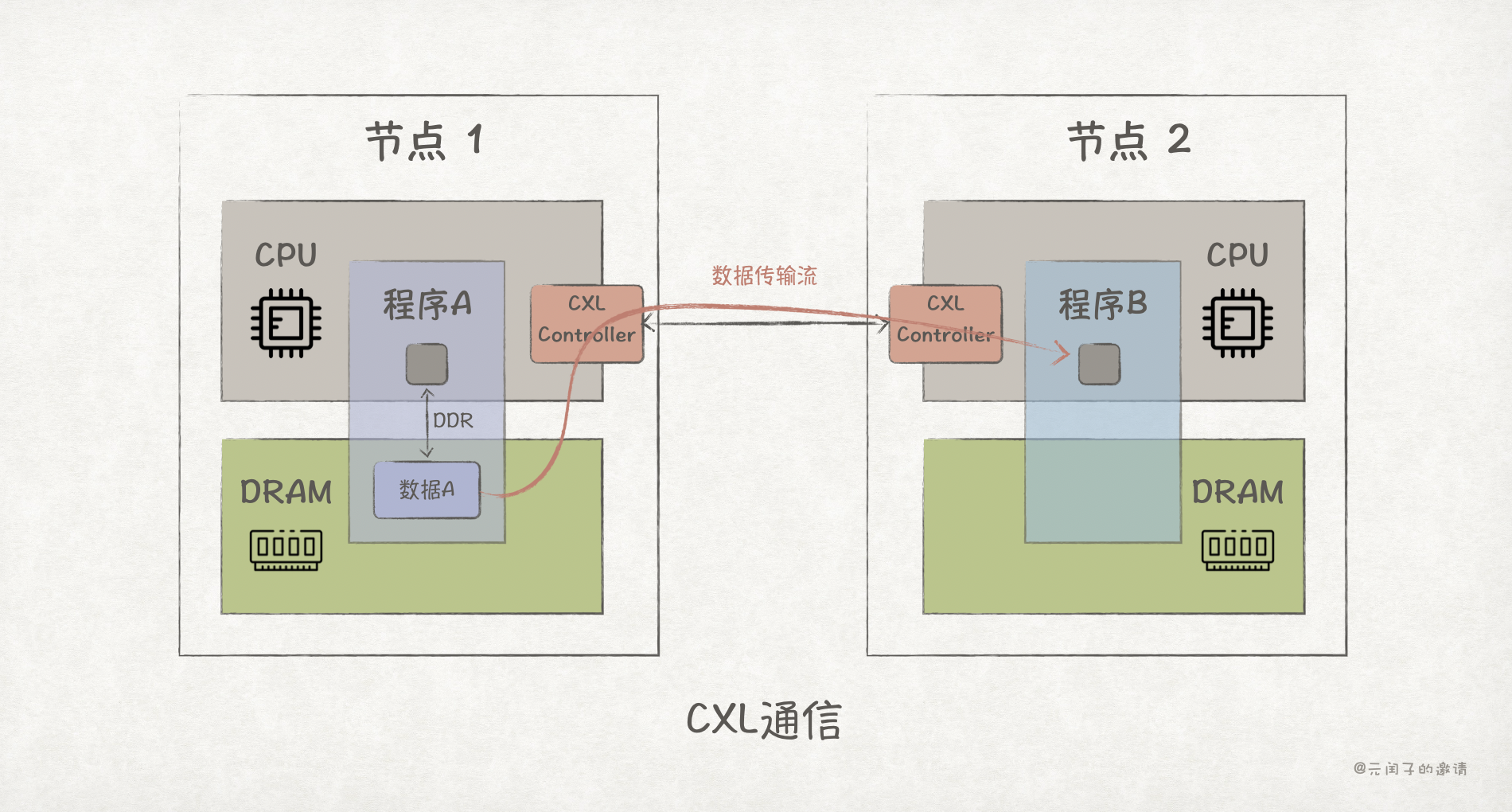
如上图所示,程序 B 可直接远程访问程序 A 的内存数据,且无需经过节点 1 CPU 的处理,直接、高效。
操作系统可以把外部的 CXL 内存设备看做是 DAX Device,这样程序 B 就能通过 mmap 把节点 1 的内存映射到自己的虚拟内存地址空间上,直接通过指针访问,省去了类似 TCP/DPDK/RDMA 繁琐的编程步骤。而且数据收发均在用户态完成。
目前 CXL 2.0 已经陆续有落地应用,在《怎么用CXL加速数据库?· SIGMOD'25》里,我们介绍了阿里云 PolarDB 团队基于 CXL 2.0 实现 PolarCXLMem 全局内存池的案例。
该案例实测数据表明,CXL 2.0 的直连访问时延可以达到 265ns,走 CXL Switch 则可以达到 549ns,是真正的纳秒级通信。CXL 3.0 标准更是将 80ns 点对点访问时延作为目标,这已经和当前的本地 DRAM 访问时延相当了。
CXL 基于 PCIe 实现,这意味着 CXL 的性能受限与 PCIe 的性能,如下为各个版本 PCIe 协议的带宽规格:
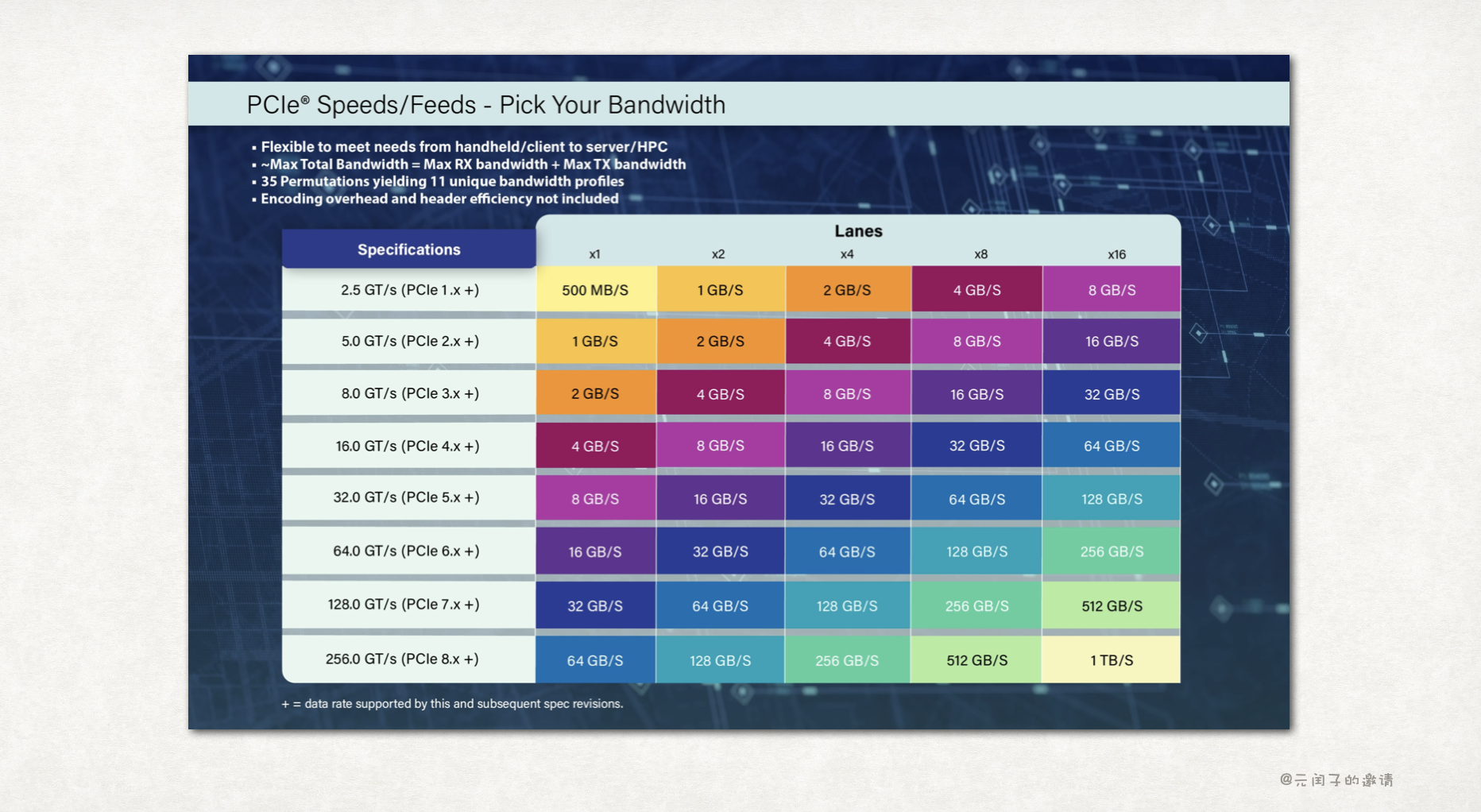
CXL 3.0 基于 PCIe 6 实现,可以做到 16GB/s/lane 的带宽,最高支持 x16 lane,所以理论带宽最大值为 256GB/s。这对大部分程序来说,已经够大了。
然而,当前 CXL 并未被广泛应用,一个重要的原因是成本过高,它需要引入 CXL 控制器、CXL Switch 等新的硬件,且无法像 RDMA 一样复用现有以太网基础设施。
对于大多数程序来说,RDMA 的性能已经足够了。而那些需要更高通信性能的应用,比如 LLM 训练和推理,CXL 的带宽又不够用。
那怎么办呢?
既然 PCIe 已经无法满足性能要求,那就不要 PCIe 了。
NVLink 通信
AI 应用程序通常会跑在 GPU 上,GPU 通过 PCIe 接口接入 CPU。当程序需要跨 GPU 通信时,最开始的方案是基于 PCIe 的 DMA 完成数据传输。
然而,随着模型变得越来越大,PCIe 的带宽已难以支撑高效的模型训练和推理,在 LLM 时代更是如此。
既然 PCIe 性能达到了上限,那就重新为 GPU 设计一个更高带宽的通信方式,于是,NVLink 诞生了。
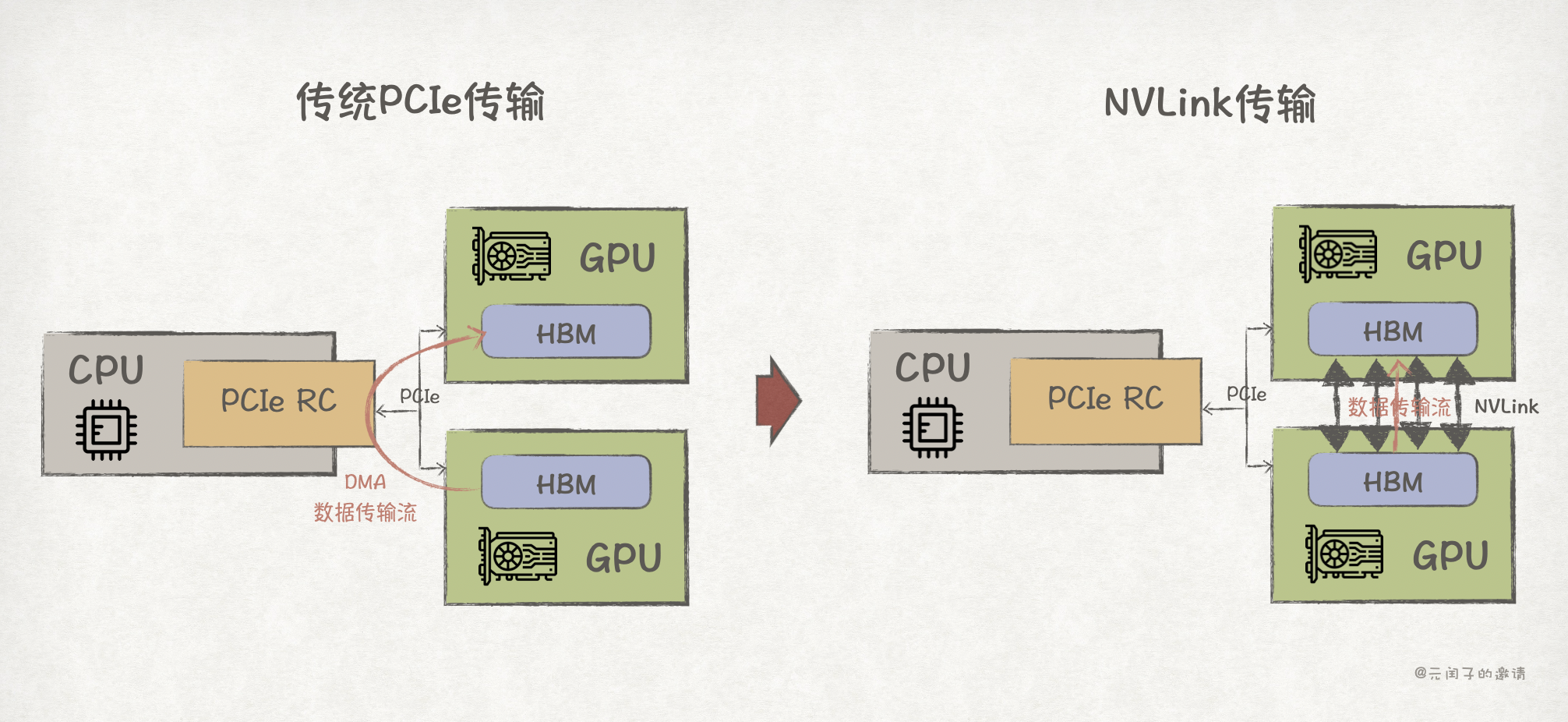
NVLink 是英伟达在 2014 年推出的用于 GPU 高速互连的协议,它能够实现 GPU 之间的显存数据直接访问,完全绕过了 CPU。
NVLink 依赖专门的硬件 ,NVLink 控制器、NVLink Switch 等,最新 NVLink 5.0 的点对点直连带宽可以达到 50GB/s/lane,每个 NVLink 端口 x2 lane,每个 GPU 最多可支持 18 个 NVLink 端口,总带宽可达 1.8TB/s,通信时延 <500ns。
可以看到,NVLink 的带宽比 CXL 要大 7 倍多,但 CXL 的通信时延更低。这体现了两者设计的权衡,NVLink 是专门针对 GPU 强大并行计算能力的高带宽设计;而 CXL/PCIe 则针对 CPU 的低时延设计。
NVLink 通信带宽很大,但仅限于 NVIDIA 生态,主要是面向 NVIDIA 的 GPU-GPU、GPU-CPU 互联;而 CXL 则更通用,CPU、DRAM、SSD、SmartNIC 等多种设备互联。
那么,能不能设计一个带宽跟 NVLink 相当,而且通用性又能跟 CXL/PCIe 相当的协议或通信方式呢?
UB 通信
华为给出了他们的答案,在今年 9 月份开放了灵衢 UB 2.0 协议。UB(Unified Bus)是一个面向超节点的互联协议:
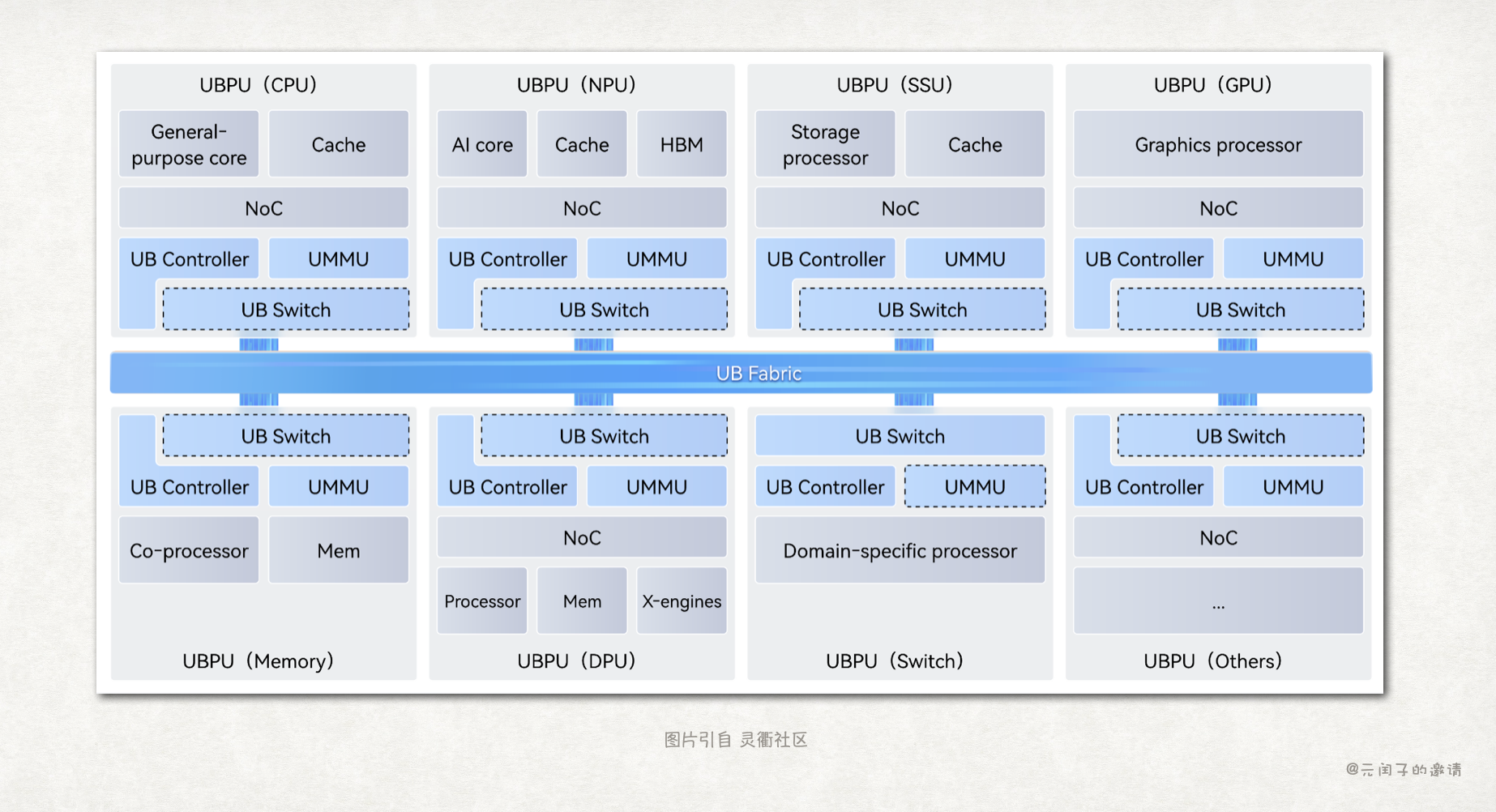
与 NVLink 的思路类似,UB 不再基于 PCIe 做优化,而是对通信协议进行了重新设计。
与以 CPU 为中心的 CXL/PCIe 协议不同,UB 采用了对等架构。在 UB 的世界里,CPU/NPU/SSU/GPU/Memory/DPU 等设备都是平等的,任何设备都可以通过 Load/Store 内存语义直接访问其他设备的数据。
这种对等架构的一大好处是,各种异构的计算资源、存储资源都可以池化,根据应用的需求动态组合,提高资源利用率,同时也能减少不必要的数据搬运。
UB 的应用在今年初也已亮相,面向 LLM 推理场景的 CloudMatrix384 超节点,它基于 UB 协议完成 384 个 Ascend 910 NPU 和 192 个 Kunpeng CPU 的高速互联。
据灵衢社区的宣传资料显示,UB 的带宽可达 TB/s 级,点对点时延可达 200ns。
目前来看,PCIe 经过多年的发展,已具备非常好的生态。而 UB 想要替换 PCIe 成为新的总线,如何发展生态,可能是它所面临的最大难题。
最后
本文从最简单的共享内存开始,回顾了程序通信的各种技术方案:
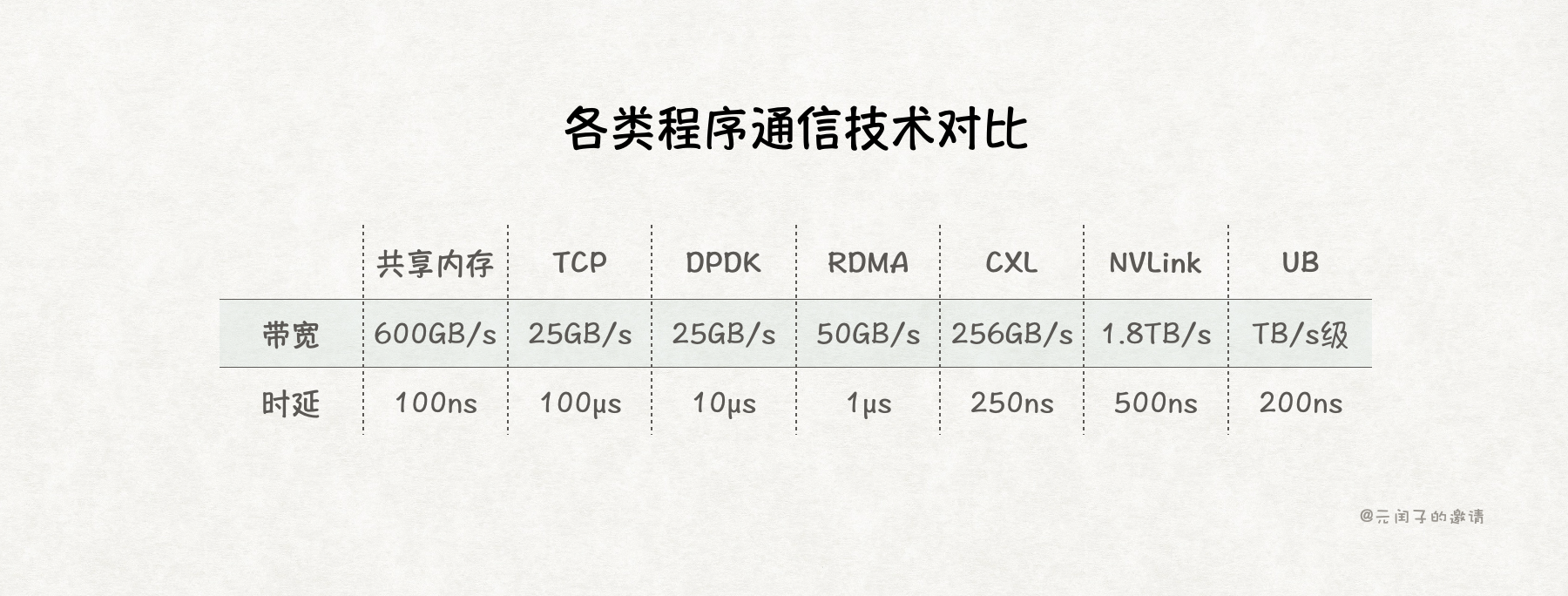
整体来看,程序间的通信性能可以优化得很高,但与之伴随的代价是,需要引入新的硬件,需要更高的成本。
其实,并不是所有的程序都需要很高的通信性能,比如,一个普通社交聊天软件并不需要 TB/s 级的通信带宽,传统的 TCP 通信已经够用了。
所以,要选择最合适的,而不是最高性能的通信方式将程序连起来。
文章配图
可以在 用Keynote画出手绘风格的配图 中找到文章的绘图方法。
参考
1 优化篇 | 网络时延优化知多少?!, 一森咖记
2 想要了解DPDK,这篇文章就够了, linux高性能网络
3 5th Gen AMD EPYC Processor Architecture, AMD
4 The Performance of CXL Memory, 0x10.sh
5 Nvlink的国产替代:华为Unified Bus背后的思考, 半导体行业观察
6 Serving Large Language Models on Huawei CloudMatrix384, Huawei
7 灵衢社区, Huawei
(完)