持续学习
sql 总结
自学了一天sql也刷了一些sql题,写一下我的思路,这里记录一下笔记,如有不对勿喷,因为我是个彩b。
基础:
数据类型:
sql
(1)bit:0/1
(2)int:整数
(3)decimal(n, m) :高精度
(4)char(n) :定长的字符串
(5)varchar(n):不定长的字符串
(6)text:文本,大量的字符
(10)date: 仅日期
(11)datetime:日期和时间
(12)time:时间 函数:
sql
f;
f() over(order by score desc) as Myname;
排名函数
(1) row_number() 行号
(2) rank() 真实的排名,相同值同号。
(3) dense_rank() 真实的排名,按照值依次递增。
(4) ntile(n) 将数据分成n组,然后分别编号。
聚合函数: 集中运算
select avg(col); //返回指定列的平均值
select count(col); // 返回指定列中非null的值
select min(col); // 返回指定列中的最小值
select max(col); // 返回指定列中的最大值
select sum(col); // 返回指定列中所有数的和
数学相关的函数:
select abs(-1); // 取绝对值
select ceit(1.4);
select floor();
select mod();
select rand(); // 随机数
select round(); // 四舍五入
select truncate(x, y); // 保留x的y位小数
字符函数
select concat(col1, col2, ..., coln) from employee; // 拼接成一个字符串
select concat_ws('分隔符', col1, col2, col3, ..., coln) // 用分隔符隔开合并成一个字符串
select trim(col); //去除所有字符串的头尾空格
select ltrim(col); // 去除开头空格
select rtrim(col); //去掉结尾空格
日期函数
select current_date(); // 获取当前日期
select curtime(); // 获取当前的时间
select timestampdiff(hours/year/day, date1, date2) 返回date1和date2的时间戳之差
分组:
分组后只能查询分组的列和聚合的列
from -> where -> groupby -> select -> having
select location from employee; 优先级
sql
优先级:
FROM 子句
ON 子句(用于 JOIN 条件)
JOIN 子句
WHERE 子句
GROUP BY 子句
HAVING 子句
SELECT 子句
DISTINCT 子句
ORDER BY 子句力扣练习题
按照题单的顺序:
(1) 组合两个表:入机题,直接left-join
传送门
sql
# Write your MySQL query statement below
select firstName, lastName, city, state from Person a
left join Address b on a.personId = b.personId; (2) 第二高的薪水: ifnull 函数,判断一下,然后直接通过orderby + limit拿到第二个
sql
# Write your MySQL query statement below
select ifnull(
(select distinct salary
from Employee
order by salary desc
limit 1, 1),
null
) as SecondHighestSalary;(3) 第n高的薪水,limit不能直接跟变量
sql
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare res, x int;
set x = N - 1;
if N > 0 then
set res = (select distinct salary from Employee
order by salary desc
limit 1 offset x);
else
set res = null;
end if;
RETURN res;
END(4) 部门最高的薪水 用max聚合函数和group by组合,但是要先通过id找到对应的部门名字。
sql
select
t2.dname as "Department",
t3.name as 'Employee',
t3.salary as "Salary"
from
(select
dname,
did,
max(salary) as 'salary'
from
(select
a.name as 'name',
a.salary as 'salary',
b.name as 'dname',
a.departmentId as 'did'
from
Employee a inner join Department b on
a.departmentId = b.id
) as t1
group by(t1.dname)
) as t2 inner join Employee t3 on
t3.salary = t2.salary and t2.did = t3.departmentId;(5) 分数排名:
通过窗口函数dense_rank() 可以拿到排名
sql
select s.score as score,
DENSE_RANK() over (order by score desc) as 'rank'
from Scores s
order by score desc;(6) 这道题 看了大佬的题解惊为天人,还是我自己格局小了,sql也能这么妙,看懂了思路,跟算法一样,也帮我打开思路了,自己写sql也能够这样去构造
题意:
给定一个表格,问按照当前顺序中连续出现三次的数字有哪些,去重输出出来。
很简单的做法就是直接三个表联立然后判断,大力出奇迹,但是扩展到k个,是不是就要写k个表了。
有没有O(N)的做法,也不需要联表查询。当然!
先看表格,要看num连续:
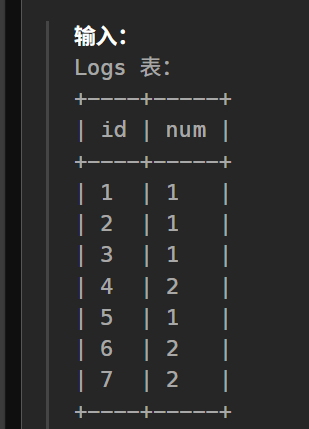
- 我们先构造一列rnk,按当前顺序依次递增(row_number()窗口函数),1, 2, 3, ..., n,因为id不一定是递增1的
- 我们再通过num和rnk构造出来res列 resi = numi - rnki
- 我们再用num为第一关键字(升序)、rnk(升序)为第二关键字去排序。
- 现在就形如:
- num rnk id
1 1 1
1 2 2
1 4 4
2 3 3 - 然后我们通过这个再去弄一个递增的rnk2列,然后我们会发现一个性质:
- rnk - rnk1 相等的 且 num一样的一定是连续一起的
- 证明:
- i, i + 1两个位置的rnk分别是r1, r2如果 i - r1 = i + 1 - r2,一定证明r2 = r1 + 1,证毕。
- 所以我们按照num和rnk-rnk1分组统计 rnk - rnk1的值,最后去重。
sql
# Write your MySQL query statement below
select
distinct num as ConsecutiveNums from
(select
t2.num,
t2.b,
count(*) as gcnt from
(select
t1.num,
(
cast(t1.a as signed) -
cast(row_number() over() as signed)
) as b
from (select
num,
row_number() over(order by id asc) as a
from Logs
order by num asc, a asc) as t1) as t2
group by t2.num, t2.b
having count(*) > 2) as t3;