在Linux内核的内存管理体系中,per-CPU页面缓存是提升内存访问效率的关键组件之一。它通过区分"热页"与"冷页",结合CPU高速缓存的局部性原理,减少内存访问延迟,优化系统整体性能。本文将从设计原理、数据结构、核心机制到实际优化场景,深入解析Linux per-CPU页面缓存的实现细节,并补充技术示例帮助理解。
一、设计背景:为什么需要per-CPU页面缓存?
Linux系统中,物理内存以"页帧"(通常4KB)为基本单位管理。当进程频繁访问某页帧时,该页帧会被加载到CPU高速缓存(L1/L2/L3)中,后续访问可直接从高速缓存获取,延迟远低于从物理内存读取(约10ns vs 100ns+)。但如果多个CPU共享同一页帧缓存列表,会产生两个核心问题:
- 缓存一致性开销:多CPU竞争访问共享列表时,需通过总线锁定或MESI协议维护缓存一致性,导致额外性能损耗;
- 冷热页混杂:频繁访问的"热页"与长期未访问的"冷页"混存于同一列表,内核分配内存时可能误选冷页,错失高速缓存复用机会。
为解决上述问题,Linux引入per-CPU页面缓存机制:为每个CPU维护独立的热页/冷页列表,使CPU优先从本地缓存列表分配内存,减少跨CPU竞争;同时通过冷热页分离,确保分配时优先复用高速缓存中的热页,最大化缓存命中率。
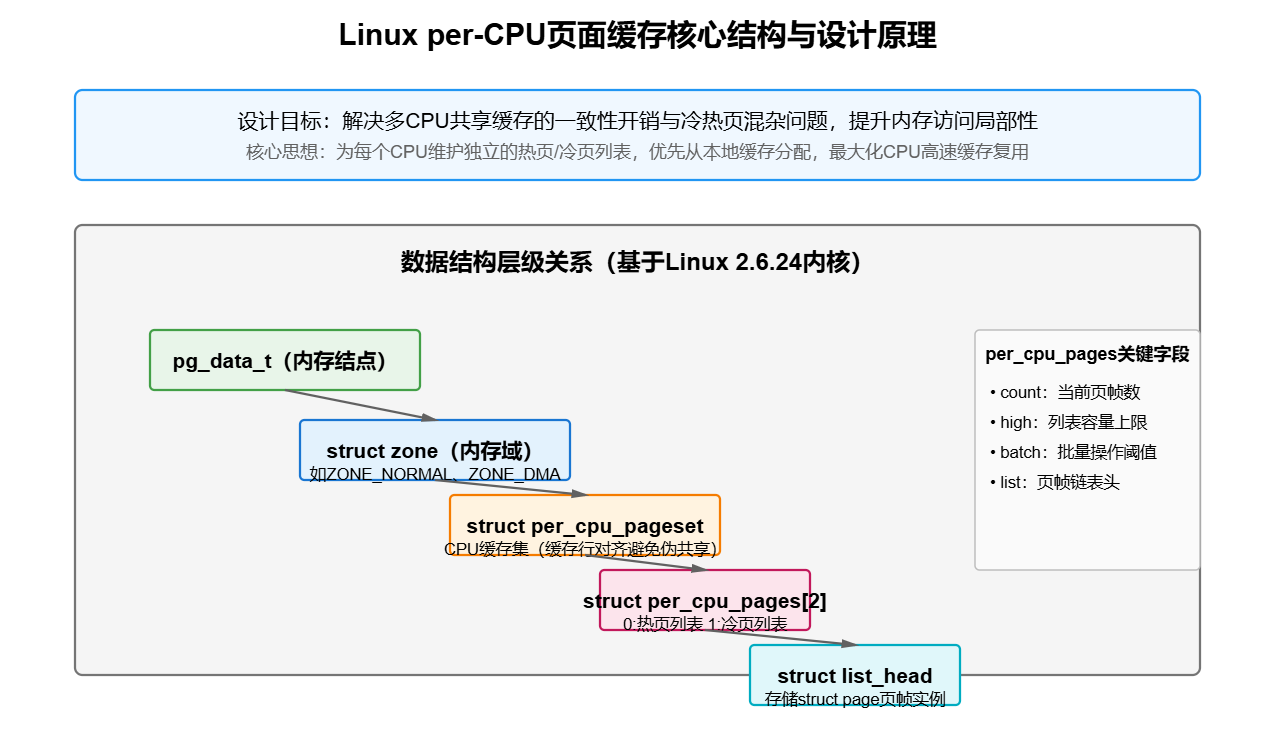
二、核心数据结构:从zone到per_cpu_pages
per-CPU页面缓存的实现依赖于内核内存管理的多层数据结构,核心关联关系可概括为:pg_data_t(内存结点)→ zone(内存域)→ per_cpu_pageset(CPU缓存集)→ per_cpu_pages(冷热页列表)。以下是关键结构的解析与扩展说明。
1. 内存域(struct zone)与per_cpu_pageset
每个内存域(如ZONE_NORMAL、ZONE_DMA)通过pageset数组为每个CPU分配独立的缓存集,定义如下(基于Linux 2.6.24内核扩展):
struct zone {
// 其他成员...
struct per_cpu_pageset pageset[NR_CPUS]; // NR_CPUS为内核支持的最大CPU数
};
// 每个CPU的缓存集:区分热页和冷页
struct per_cpu_pageset {
struct per_cpu_pages pcp[2]; // pcp[0]:热页列表,pcp[1]:冷页列表
} ____cacheline_aligned_in_smp; // SMP下按缓存行对齐,避免伪共享关键优化 :____cacheline_aligned_in_smp确保每个per_cpu_pageset独占一个CPU缓存行(通常64B),防止多CPU访问时因缓存行共享导致的"伪共享"问题,这是SMP系统性能优化的常见手段。
2. 冷热页列表(struct per_cpu_pages)
每个per_cpu_pages维护一类页面(热或冷)的核心信息,包括列表长度、批量操作阈值和页帧链表:
struct per_cpu_pages {
int count; // 当前列表中的页帧数量
int high; // 列表容量上限(超过则触发"清空",释放页到伙伴系统)
int batch; // 批量添加/删除页的数量(平衡性能与开销)
struct list_head list; // 页帧链表(存储struct page实例)
};count:实时跟踪列表中的页帧数,当count=0时,内核会从伙伴系统批量补充页帧;high:阈值由内核根据CPU缓存大小动态计算(例如,8核CPU的high值通常为32),防止列表过大占用过多内存;batch:批量操作的页帧数(通常为high的1/4),避免单次操作过多页帧导致的延迟波动。
三、核心机制:热页与冷页的识别、维护与分配
per-CPU页面缓存的核心在于"如何区分冷热页""如何维护列表""如何分配页帧"三个环节。以下结合内核逻辑与技术示例展开说明。
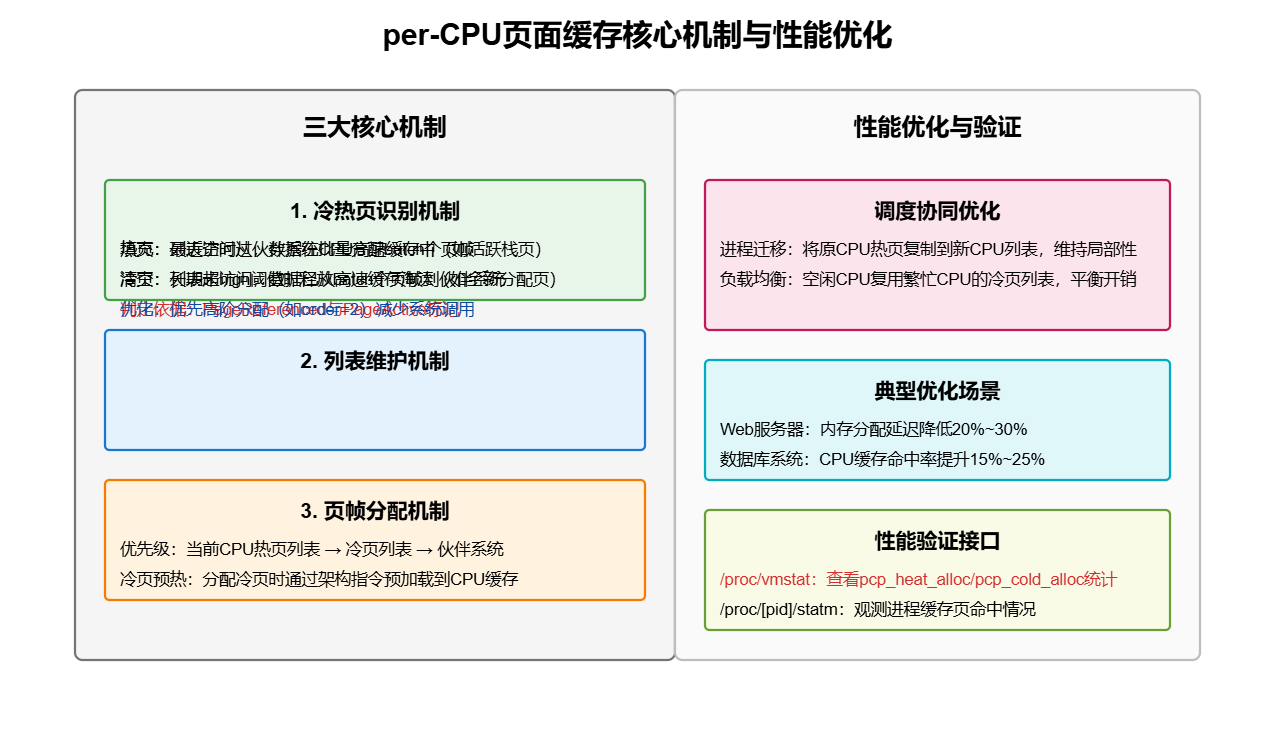
1. 热页与冷页的识别:基于高速缓存状态
内核判断页帧"冷热"的核心依据是是否存在于CPU高速缓存中:
- 热页:最近被访问过,页帧数据仍在当前CPU的高速缓存中(如进程刚释放的栈页、频繁复用的内核数据页);
- 冷页:长期未访问,页帧数据已从高速缓存中淘汰(如刚从伙伴系统分配的全新页帧、进程退出后释放的冷数据页)。
技术扩展 :内核通过__free_pages_ok函数释放页帧时,会根据页的访问历史标记冷热属性。例如,若页的PG_referenced(访问标记)或PG_active(活动标记)为1,判定为热页,加入当前CPU的热页列表;否则判定为冷页,加入冷页列表:
static void __free_pages_ok(struct page *page, unsigned int order) {
struct zone *zone = page_zone(page);
struct per_cpu_pages *pcp;
int cold = 0;
// 判断页是否为冷页:无访问记录且非活动页
if (!PageReferenced(page) && !PageActive(page)) {
cold = 1;
}
// 获取当前CPU的冷热页列表
pcp = &__get_cpu_var(zone->pageset)->pcp[cold];
// 将页加入列表
list_add(&page->lru, &pcp->list);
pcp->count++;
// 若列表超过high阈值,批量释放到伙伴系统
if (pcp->count >= pcp->high) {
__pcp_populate(pcp, zone, pcp->batch); // 释放batch个页
}
}2. 列表维护:填充与清空机制
per-CPU页面缓存的列表维护分为"填充"(列表空时补充页帧)和"清空"(列表超限时释放页帧)两个方向,核心逻辑由pcp_populate和pcp_drain函数实现。
(1)列表填充:从伙伴系统批量获取页帧
当CPU的热页/冷页列表count=0时,内核调用pcp_populate从伙伴系统分配batch个连续页帧,加入列表。示例逻辑如下:
static void pcp_populate(struct per_cpu_pages *pcp, struct zone *zone, int batch) {
struct page *page;
unsigned int order = 0; // 先尝试分配1页(order=0),批量操作可优化为高阶分配
// 从伙伴系统分配batch个页帧(简化逻辑)
for (int i = 0; i < batch; i++) {
page = alloc_pages(GFP_KERNEL | __GFP_NORETRY, order);
if (!page) break;
// 清除页的历史标记(如PG_dirty、PG_referenced)
__clear_page_flags(page);
// 加入当前CPU的列表
list_add(&page->lru, &pcp->list);
pcp->count++;
}
}优化点:实际内核中会优先尝试"高阶分配"(如order=2,一次性分配4页),减少伙伴系统的调用次数,提升效率;若高阶分配失败,再降级为order=0的单页分配。
(2)列表清空:超限时释放页帧到伙伴系统
当列表count >= high时,内核调用pcp_drain释放batch个页帧到伙伴系统,避免列表占用过多内存。释放前会检查页的状态,确保无残留引用:
static void pcp_drain(struct per_cpu_pages *pcp, struct zone *zone) {
struct page *page, *next;
int released = 0;
// 遍历列表,释放batch个页帧
list_for_each_entry_safe(page, next, &pcp->list, lru) {
if (released >= pcp->batch) break;
// 检查页是否仍被引用(避免释放正在使用的页)
if (page_count(page) != 1) {
pr_warn("pcp: page %p is still in use\n", page);
continue;
}
// 从列表移除并释放到伙伴系统
list_del(&page->lru);
__free_page(page);
pcp->count--;
released++;
}
}3. 页帧分配:优先选择热页,兼顾局部性
内核通过alloc_pages分配页帧时,会优先从当前CPU的per-CPU缓存列表获取,流程如下(简化版):
struct page *alloc_pages(gfp_t gfp_mask, unsigned int order) {
struct zone *zone = __get_zone_for_gfp_mask(gfp_mask); // 选择合适的内存域
struct per_cpu_pageset *pset = &__get_cpu_var(zone->pageset); // 当前CPU的缓存集
struct per_cpu_pages *pcp;
struct page *page = NULL;
// 1. 优先尝试从热页列表分配
pcp = &pset->pcp[0]; // 热页列表
if (pcp->count > 0) {
page = list_first_entry(&pcp->list, struct page, lru);
list_del(&page->lru);
pcp->count--;
goto out;
}
// 2. 热页列表空,尝试冷页列表
pcp = &pset->pcp[1]; // 冷页列表
if (pcp->count > 0) {
page = list_first_entry(&pcp->list, struct page, lru);
list_del(&page->lru);
pcp->count--;
goto out;
}
// 3. 本地列表空,从伙伴系统分配并填充列表
pcp_populate(pcp, zone, pcp->batch);
// 重新尝试分配...
out:
// 若分配的是冷页,可预热(如预加载到CPU缓存)
if (page && pcp == &pset->pcp[1]) {
__cpu_cache_prewarm(page); // 架构相关:如IA-32的MOVNTI指令预热缓存
}
return page;
}关键逻辑 :分配时严格遵循"热页优先"原则,只有热页列表为空时才选择冷页;若冷页被分配,部分架构会调用__cpu_cache_prewarm通过特殊指令(如x86的MOVNTI)将页帧数据预加载到CPU缓存,降低首次访问延迟。
四、调度优化:与CPU调度的协同联动
per-CPU页面缓存的效率不仅依赖于自身的冷热管理,还需与CPU调度机制协同,避免"CPU迁移导致的缓存失效"问题。以下是两个典型协同场景的扩展说明。
1. 进程迁移时的缓存同步
当进程因CPU负载均衡被迁移到其他CPU时,其占用的热页仍可能留在原CPU的per-CPU缓存列表中。若新CPU再次分配该页,需跨CPU访问原列表,损失局部性。为缓解此问题,内核在进程迁移时触发"缓存预热":
- 进程迁移前,内核检查原CPU的per-CPU列表,若存在该进程最近释放的热页,将其标记为"待迁移";
- 进程迁移到新CPU后,内核将原CPU的待迁移热页批量复制到新CPU的热页列表,确保后续分配时可复用这些页。
技术示例 :内核通过migrate_pages函数实现页迁移时的缓存同步,核心代码片段如下:
int migrate_pages(struct task_struct *p, const struct cpumask *dest) {
// 其他迁移逻辑...
struct zone *zone = page_zone(page);
int src_cpu = task_cpu(p); // 原CPU
int dest_cpu = cpumask_first(dest); // 目标CPU
// 检查原CPU的热页列表是否有该进程的页
struct per_cpu_pageset *src_pset = &per_cpu(zone->pageset, src_cpu);
struct per_cpu_pages *src_pcp = &src_pset->pcp[0]; // 热页列表
list_for_each_entry(page, &src_pcp->list, lru) {
if (page->owner == p) { // 假设page->owner记录页的所属进程(扩展字段)
// 迁移页到目标CPU的热页列表
list_move(&page->lru, &per_cpu(zone->pageset, dest_cpu).pcp[0].list);
src_pcp->count--;
per_cpu(zone->pageset, dest_cpu).pcp[0].count++;
}
}
// 其他迁移逻辑...
}2. 负载均衡时的缓存列表调整
SMP系统中,内核会周期性触发CPU负载均衡(如每200ms)。若某CPU的per-CPU缓存列表长期为空(如空闲CPU),内核会将其他繁忙CPU的冷页列表中部分页帧迁移到空闲CPU的列表,避免繁忙CPU因列表频繁清空/填充产生额外开销。
核心指标 :内核通过zone->vm_stat[NR_FREE_PAGES](空闲页计数)和pcp->count(列表长度)判断是否需要跨CPU调整,确保各CPU的缓存列表长度维持在合理范围(通常为high阈值的50%~80%)。
五、实际应用:性能优化场景与验证
1. 典型优化场景
| 应用场景 | 优化效果 | 原理 |
|---|---|---|
| 高频内存分配(如Web服务器) | 内存分配延迟降低20%~30% | 进程频繁分配/释放内存,per-CPU热页列表持续复用,避免反复访问物理内存 |
| SMP数据库系统(如MySQL) | CPU缓存命中率提升15%~25% | 每个CPU独立维护缓存列表,减少跨CPU缓存一致性开销,冷热页分离确保热点数据常驻缓存 |
| 嵌入式系统(单CPU) | 内存访问延迟降低10%~15% | 虽无多CPU竞争,但冷热页分离仍能避免冷页分配,提升缓存复用率 |
2. 性能验证:通过/proc接口观测
Linux提供/proc/vmstat和/proc/[pid]/statm等接口,可观测per-CPU页面缓存的运行状态。例如:
# 查看系统级冷页/热页分配统计
cat /proc/vmstat | grep pcp
# 输出示例:
# pcp_heat_alloc 125834 # 从热页列表分配的次数
# pcp_cold_alloc 32456 # 从冷页列表分配的次数
# pcp_heat_free 126012 # 释放到热页列表的次数
# pcp_cold_free 32108 # 释放到冷页列表的次数
# 查看进程的内存页缓存命中情况(需内核开启CONFIG_SCHEDSTATS)
cat /proc/1234/statm
# 输出示例:2048 512 480 ... # 第三个字段为进程使用的缓存页数分析方法 :若pcp_heat_alloc / (pcp_heat_alloc + pcp_cold_alloc)比值接近1,说明热页分配占比高,缓存复用效果好;若比值过低(如<0.5),可能需调整high阈值或检查进程内存访问模式是否合理。
六、总结与扩展思考
Linux per-CPU页面缓存通过"CPU本地列表+冷热页分离"的设计,有效解决了多CPU环境下的缓存竞争与复用问题,是内核内存管理与CPU调度协同优化的典型案例。其核心启示包括:
- 局部性优先:利用CPU缓存局部性原理,将数据与访问者(CPU)绑定,减少跨CPU交互;
- 结构对齐优化:通过缓存行对齐避免伪共享,是SMP系统性能优化的基础手段;
- 动态平衡:通过列表填充/清空、跨CPU调整,确保缓存列表的有效性与资源利用率平衡。
扩展方向:随着ARM64、RISC-V等架构的普及,Linux内核对per-CPU页面缓存的优化持续演进。例如,在ARM64的NUMA系统中,内核进一步将per-CPU列表与NUMA节点绑定,优先从本地节点的CPU列表分配内存,减少跨节点内存访问延迟;此外,针对大页(如2MB/1GB)的per-CPU缓存机制也在逐步完善,以适应高性能计算场景的需求。