这两天,估计大家都刷到了 DeepSeek-OCR 的资讯。
最初看到时,我以为是专门做 OCR 的识别模型,顶多是参数小点、性能好点之类的,就没有太多关注。
直到中午看到卡兹克关于它的解读,我才发现:我被名字骗了。
这哪里是一个 OCR 工具,它完全可以说是一种压缩上下文的新范式。
依旧亮眼的 OCR
虽然,DeepSeek-OCR 的 OCR 特性不是这次火热的重点,但依然非常亮眼。
处理金融研报图片时,DeepSeek-OCR 能在识别结果中完整保留图表的结构化信息。
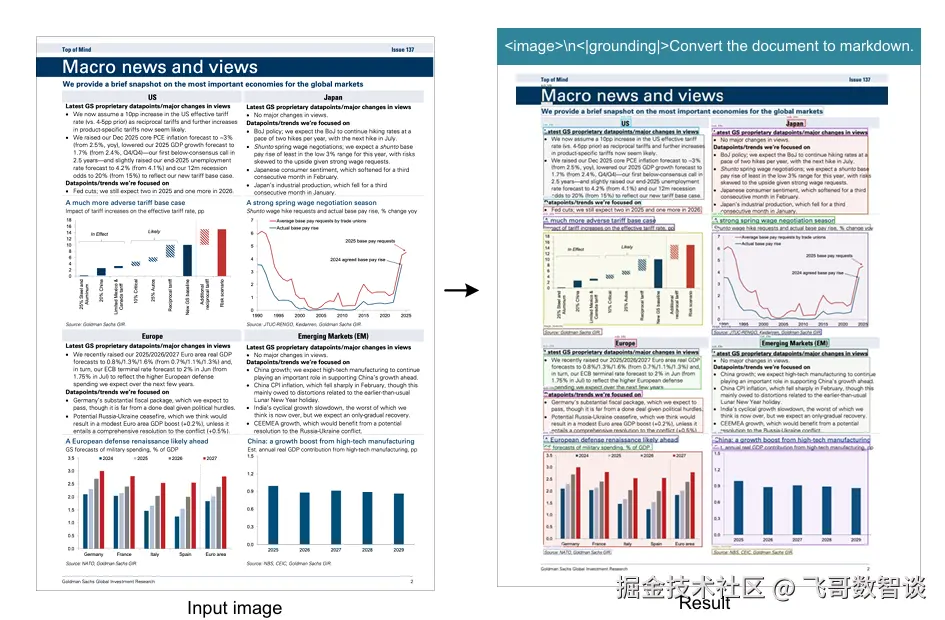
而下面的截图则体现了 DeepSeek-OCR 在科研工作中的一大优势,可以非常准确地从图片中识别出公式、表达式等专有信息。

下面,我们看下真正让它出圈的"压缩"思路。
惊艳的压缩思路
近两年最火的 AI 模型几乎都是大语言模型,大家的思路也都是以自然语言处理(NLP)的思路为主。
其中有一个名词"上下文"大家应该都不陌生了,可以理解为 AI 的"记忆"大小。
在当下,即使上下文上限一直在提升,但实际使用中终究会碰到超出的情况。因此大家提出了很多的压缩思路,尽可能减少信息丢失的情况下,减少上下文的占用。
比如:文字提炼摘要、token级去重,再或者直接丢弃掉最早的记忆。
而 DeepSeek-OCR 则提出了另一种思路:
稍远一点的信息,直接转化为图片进行存储。
乍一听,有点反直觉。
但仔细一想,这和以前提到的"视觉记忆法"、"图像联想记忆法",甚至前几年很火的"记忆宫殿",都挺像的。
或者换种说法可能更好理解,我们不喜欢听微信语音,更喜欢看微信文字消息,就是因为语音智能顺序的一点点听,然后记忆,而文字消息,我们可以一眼扫完,快速记忆。------ 以上说法灵感来自于卡兹克留言区
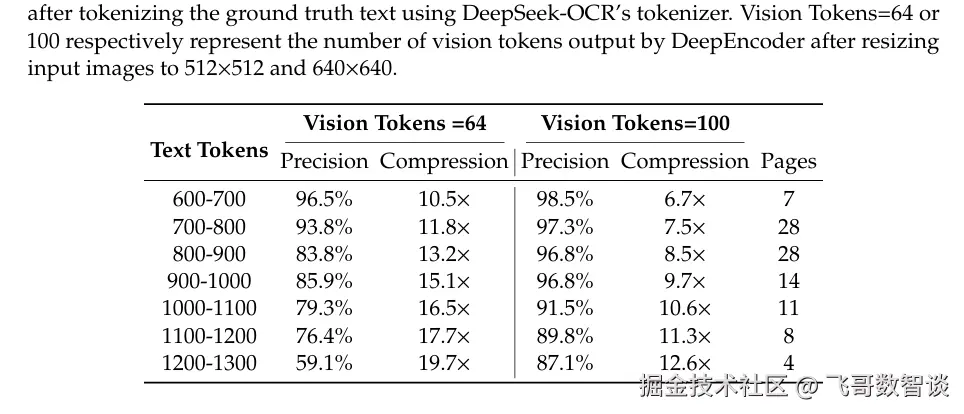
在这种思路下,DeepSeek-OCR 给出以下测试结果:
保持识别精度 96.5% 的情况下,压缩比可以达到 10 倍。
更惊艳的相似性
以上思路确实挺惊艳的了,但更令我惊艳的是论文最终的一点讨论。
DeepSeek-OCR 认为:
"对于较旧的上下文(遥远的记忆),我们可以沿用上述思路,并逐步增大压缩比,从而减少令牌消耗。"
这简直就是人类记忆机制的模拟,我们不会一字不落记住上学时的一堂课,但我们会记住当时课堂的重要画面和知识。
此前,尽管 AI 十分好用,但其基于概率模型的本质总让我担心未来发展会受限。
然而今天,我感觉概率模型和人类记忆好像有些相通了,这让我对 AI 的发展更有信心了。
结语
Gemini 的 OCR 能力和上下文效果也很不错,社区里有大神怀疑可能也采用了类似的思路。
但 DeepSeek 的做法明显更实在,直接就开源了。
就冲这一点,不支持 DeepSeek 都不行啊!