代码链接:https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/05_mla/README.md
多头潜在注意力(MLA)
这份扩展材料展示了在常规多头注意力(MHA)之上使用多头潜在注意力(MLA)时的内存节省效果。
简介
在 .../04_gqa 中,我们讨论了分组查询注意力(GQA)作为提升 MHA 计算效率的一种替代方案。多项消融研究(例如 原始 GQA 论文 与 Llama 2 论文)显示,其在大语言模型的建模性能上与标准 MHA 相当。
现在,多头潜在注意力(MLA),被应用于 DeepSeek V2、V3 和 R1,提供了另一种与 KV 缓存非常契合的内存节省策略。与 GQA 通过共享键/值头不同,MLA 在将键和值张量存入 KV 缓存之前,先将它们压缩到更低维的空间。
在推理阶段,这些压缩后的张量会在使用前投影回原始大小,如下图所示。这会增加一次矩阵乘法,但可降低内存占用。
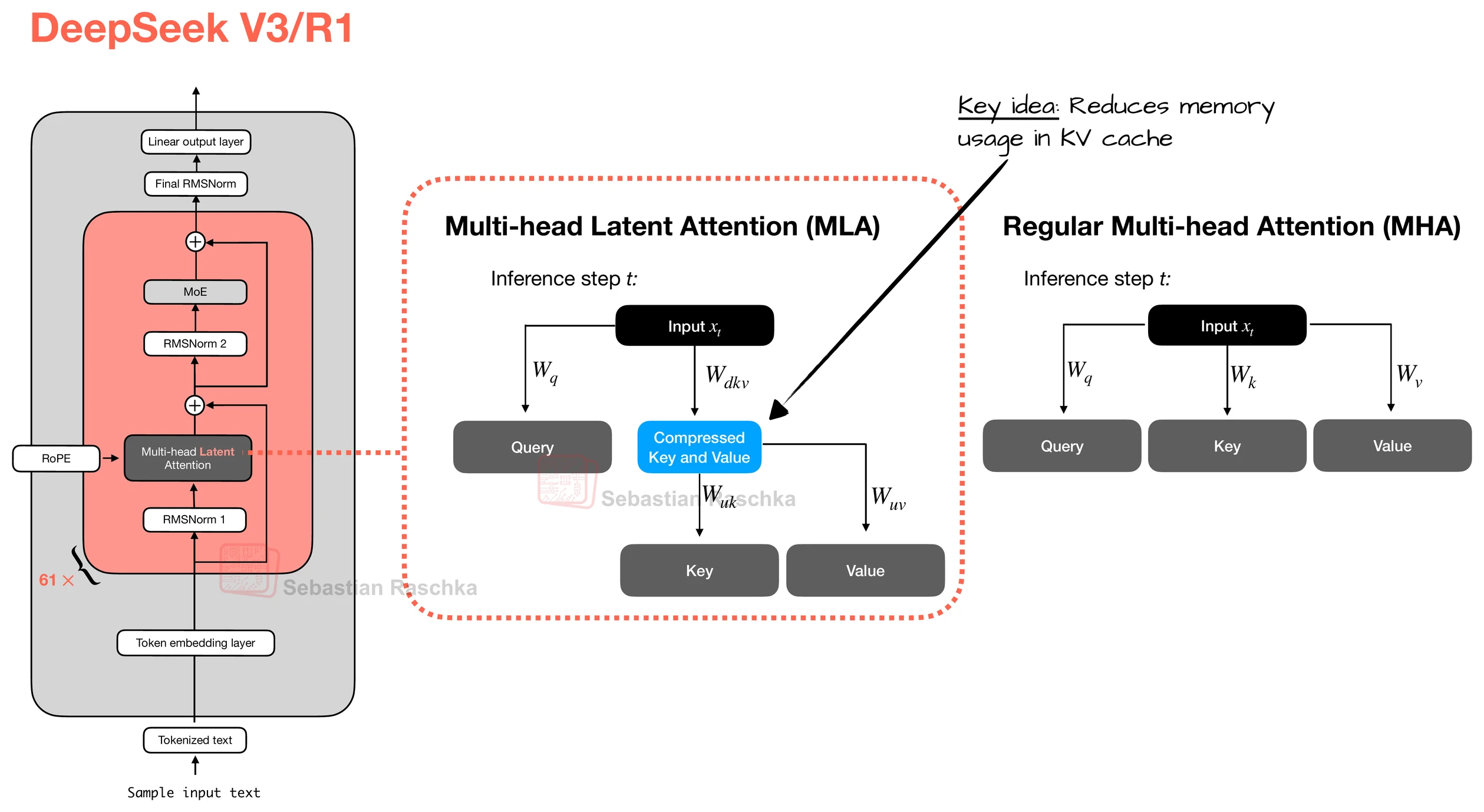
(顺带一提,查询也会被压缩,但仅在训练期间,推理时不会。)
另外,正如前文所述,MLA 并非 DeepSeek V3 的新内容,其前身 DeepSeek V2 也使用并引入了它。此外,V2 论文包含一些有趣的消融研究,或许能解释为什么 DeepSeek 团队选择 MLA 而非 GQA(见下图)。
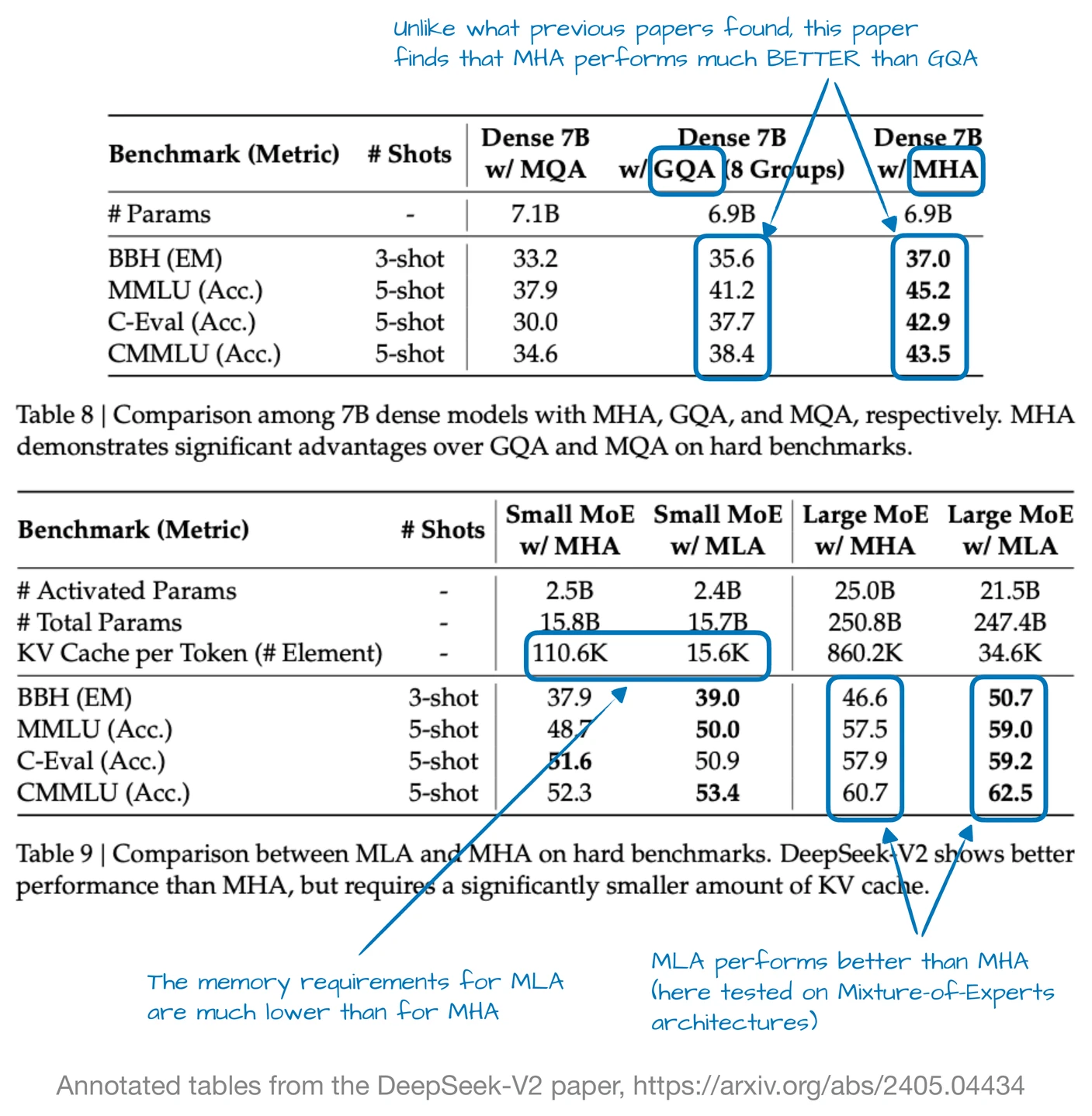
如上图所示,GQA 的表现似乎劣于 MHA,而 MLA 的建模性能优于 MHA,这很可能是 DeepSeek 团队选择 MLA 而非 GQA 的原因。(如果还能看到 MLA 与 GQA 在"每个 token 的 KV 缓存"节省上的比较就更有趣了!)
本节小结:在进入下一架构组件前,MLA 是一种巧妙的技巧,可以降低 KV 缓存的内存占用,并在建模性能上略优于 MHA。
MLA 内存节省
内存节省主要体现在 KV 存储上。我们可以用如下公式计算 KV 存储大小:
bytes ≈ batch_size × seqlen × n_layers × latent_dim × bytes_per_elem
相比之下,MHA 的 KV 缓存内存按如下方式计算:
bytes ≈ batch_size × seqlen × n_layers × embed_dim × 2 (K,V) × bytes_per_elem
这意味着,在 MLA 中,我们将"embed_dim × 2(K、V)"缩减为"latent_dim",因为我们只存储压缩后的潜在表示,而不是完整的键和值向量(如前图所示)。
你可以使用本目录中的脚本 <memory_estimator_mla.py>,针对不同模型配置计算使用 MLA 相较于 MHA 能节省多少内存:
bash
➜ uv run memory_estimator_mla.py \
--context_length 8192 \
--emb_dim 2048 \
--n_heads 24 \
--n_layers 48 \
--n_kv_groups 4 \
--batch_size 1 \
--dtype bf16 \
--latent_dim 1024
==== Config ====
context_length : 8192
emb_dim : 2048
n_heads : 24
n_layers : 48
n_kv_groups : 4
latent_dim : 1024
batch_size : 1
dtype : bf16 (2 Bytes/elem)
head_dim : 86
GQA n_kv_heads : 6
==== KV-cache totals across all layers ====
MHA total KV cache : 3.25 GB
GQA total KV cache : 0.81 GB
MLA total KV cache : 0.81 GB
Ratio (MHA / GQA) : 4.00x
Savings (GQA vs MHA): 75.00%
Ratio (MHA / MLA) : 4.03x
Savings (MLA vs MHA): 75.19%注意,上述压缩(--emb_dim 2048 -> latent_dim 1024)实现了与 GQA 相近的节省效果。实际使用中,压缩程度是需要仔细研究的超参数,因为将 latent_dim 设得过小会对建模性能产生负面影响(类似于在 GQA 中选择过多的 n_kv_groups)。
下图进一步展示了在不同 latent_dim 取值下,随上下文长度变化时 MLA 相较于 MHA 的节省:
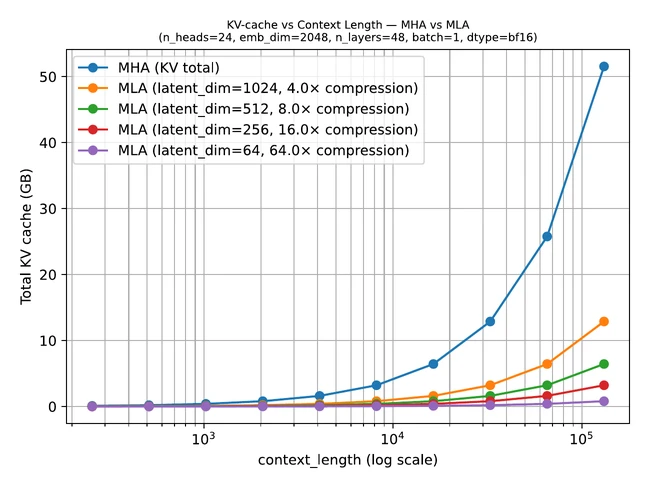
你可以通过执行 uv run plot_memory_estimates_mla.py 复现该图。
MLA 代码示例
本目录中的 <gpt_with_kv_mha.py> 与 <gpt_with_kv_mla.py> 脚本提供了在 GPT 模型实现背景下比较 MHA 与 MLA 内存占用的实操示例。
此处的 MLA 代码受该实现启发:https://huggingface.co/bird-of-paradise/deepseek-mla。
需要注意,MLA 也可以与 GQA 结合使用,但为简化起见,这里没有这样做。(目前我也不了解有知名的 LLM 同时采用两者。)
另请注意,该模型未经过训练,因此会生成无意义的文本。不过,你可以在第 5-7 章中将其作为标准 GPT 模型的替代实现并进行训练。
最后,该实现使用了 另一扩展章节 中解释的 KV 缓存,因此内存节省更为显著。
bash
uv run gpt_with_kv_mha.py \
--max_new_tokens 32768 \
--n_heads 24 \
--n_layers 12 \
--emb_dim 768
...
Time: 453.81 sec
72 tokens/sec
Max memory allocated: 1.54 GB
bash
uv run gpt_with_kv_mla.py \
--max_new_tokens 32768 \
--n_heads 24 \
--n_layers 12 \
--emb_dim 768 \
--latent_dim 192 # 4x compression
...
Time: 487.21 sec
67 tokens/sec
Max memory allocated: 0.68 GB之所以没有像上面的图表那样看到更大的节省,原因有二:
- 为了让模型在合理时间内完成生成,我使用了较小的配置。
- 更重要的是,我们这里观察的是整个模型,而不仅仅是注意力机制;模型中的全连接层占据了大部分内存(这本身值得另行分析)。