引言
作为一个 Java/Go 后端开发者 ,你肯定非常熟悉传统的关系型数据库 (MySQL、PostgreSQL)和键值对数据库 (Redis)。它们的核心逻辑通常是精确匹配 (WHERE id = 1 或 key = "session_123")。
但在这个 AI 爆发的时代,我们处理的数据类型变了:文本、图像、音频、视频。这些非结构化数据无法通过简单的"精确匹配"来查询。详细来说,如何让数据库理解"含义"? 比如用户搜"怎么退货?",数据库得能把文档里写着"售后流程"的那一行找出来。传统的 SQL LIKE 或全文检索(Elasticsearch)在这里往往力不从心,因为它们匹配的是字面 ,而不是意思
这时候,向量(Vector)和 向量数据库(Vector Database)就登场了。简单来说,它们是为了解决 "语义搜索"和"模糊匹配"而生的
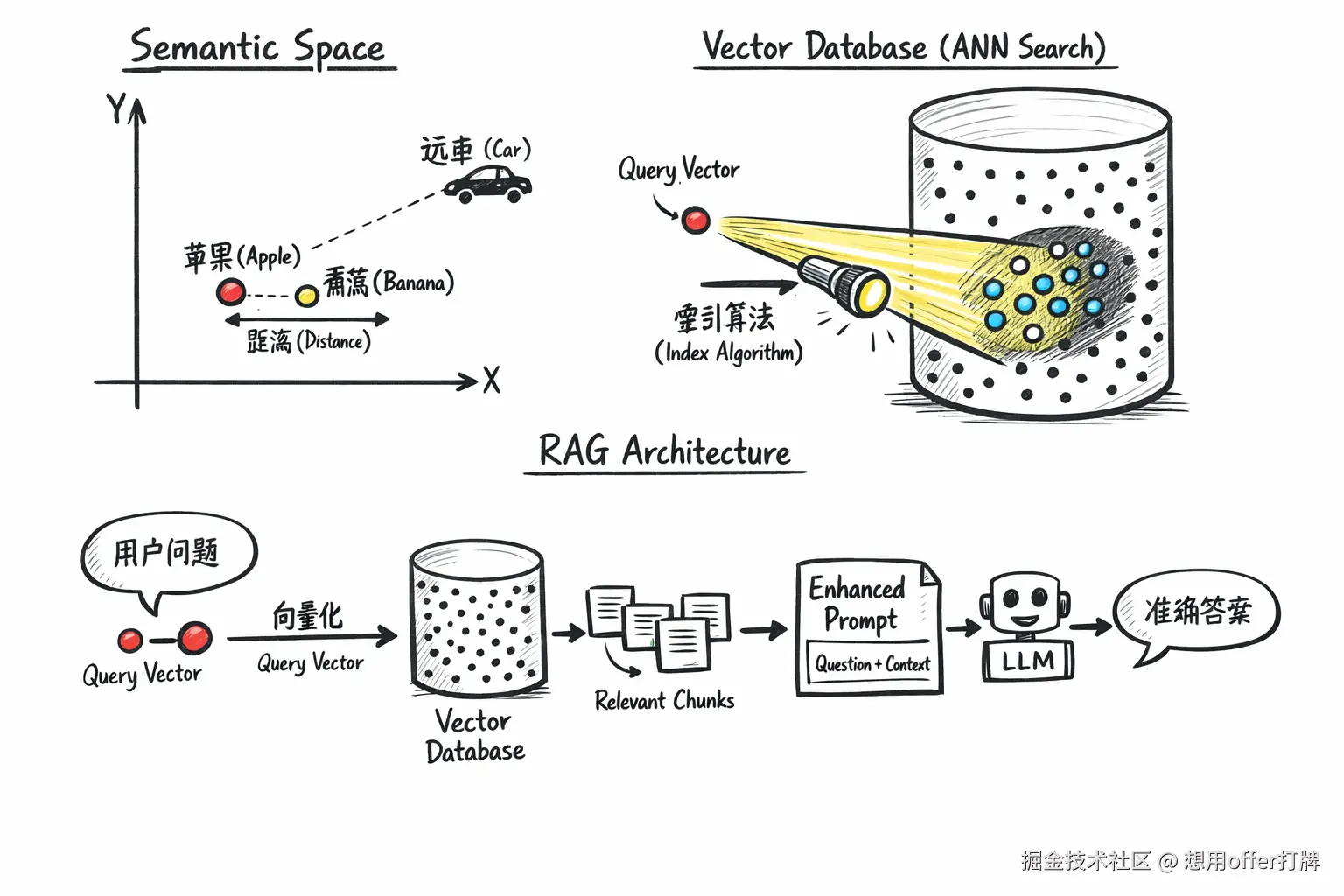
什么是向量 -- 数据的坐标
在数学上,向量是有大小和方向的量。但在 AI 工程中,向量(Embedding) 是非结构化数据(文本、图片、音频)在多维空间中的数值映射
因此,定义是:数据(如一句话、一张图)经过深度学习模型(Embedding Model)计算后,转化成的一串浮点数数组
例如:
-
输入: "苹果"
-
输出 (假设 3 维):
[0.8, 0.1, 0.1] -
输入: "梨子"
-
输出:
[0.7, 0.2, 0.1] -
输入: "卡车"
-
输出:
[-0.9, 0.5, 0.3]
核心逻辑:空间距离代表语义相似度
简单来说呢,就是在这个多维空间里,含义相近的词,坐标距离就近
- 如果两个数据在语义上很像(比如"猫"和"小猫"),它们转换成的向量在数学空间里的距离就会非常近。
- 如果语义无关(比如"猫"和"汽车"),距离就会很远
后端视角
对于后端来说,所谓的"语义搜索",本质上就是计算两个数组(向量)之间的数学距离 。常用的算法是 余弦相似度 (Cosine Similarity) :
similarity=cos(θ)=∥A∥∥B∥A⋅B
结果越接近 1,表示越相似。
向量数据库 (Vector DB) -- "坐标"的引擎
如果只有几千条数据,你把向量存在内存里,写个 for 循环算距离也行。但如果有 1 亿条数据,每次查询都要算 1 亿次余弦相似度,CPU 直接爆炸。
这就需要 向量数据库
与关系型数据库的区别
它和 MySQL 的本质区别
- MySQL (B+ Tree): 寻找精确匹配 。利用树结构快速定位到
ID=100的叶子节点。 - Vector DB (ANN): 寻找近似最近邻
| 特性 | 传统数据库 (MySQL/PostgreSQL) | 向量数据库 (Milvus/Weaviate/Pinecone) |
|---|---|---|
| 查询逻辑 | 精确匹配 (Exact Match) | 近似最近邻搜索 (ANN - Approximate Nearest Neighbor) |
| 查询语句 | SELECT * FROM table WHERE type='fruit' |
Search(vector=[0.1, 0.2...], top_k=5) |
| 核心算法 | B+ Tree, Hash Index | HNSW (图索引), IVF (倒排索引), Quantization (量化) |
| 结果 | 确定的行数据 | 最相似的数据列表 + 相似度得分 |
躲在背后的皇帝?HNSW 索引
虽然这个小标题有点哗众取宠,但是我恰好是想借其来表达HNSW 索引的重要性。
向量库不会真的去算 1 亿次距离。它通常使用 HNSW 这种图索引算法。
你可以把它想象成"跳表"+"社交网络":
- 分层导航: 顶层只有少数几个"枢纽节点",底层包含所有数据。
- 快速收敛: 查询时,先在顶层找到大概区域,然后像跳伞一样落入下一层,逐步缩小范围,最终找到离目标最近的一簇数据
向量数据库工作一般流程?
来讲讲一般向量数据库是怎么工作的:
-
Embedding(嵌入): 你的后端服务调用 AI 模型(如 OpenAI),把用户的 Query 变成向量。
-
Indexing(索引): 向量数据库使用算法(如 HNSW)构建索引,把向量在空间中按区域划分。
-
Search(搜索): 数据库快速定位到目标向量附近的区域,找出最近的邻居,而不是全表扫描。
向量数据库有哪些推荐?
1. 纯向量数据库 (专门产品)
- Milvus: 强烈推荐关注。 它是云原生架构,核心部分是用 Go 写的(对 Go 开发者很亲切),性能极强,国内社区活跃。它有完善的 Java 和 Go SDK。
- Weaviate: 也是用 Go 写的开源向量数据库,支持 GraphQL,不仅存向量,还能存对象。
2. 传统数据库的扩展 (插件)
- Elasticsearch (kNN): 如果你的架构里已经有 ES,可以直接用它的向量搜索功能。
- PostgreSQL (pgvector): 非常火的插件。如果你的数据量不是特别巨大(比如千万级以下),直接用 PG 存向量是最省架构成本的
向量数据库这么火的原因🧐 -- RAG与LLM
作为后端,你可能听说过 RAG (Retrieval-Augmented Generation,检索增强生成) 。这是向量数据库最核心的应用场景。
大模型 (LLM) 的痛点:
- 它不知道你公司的私有数据(比如内部文档、代码库):例如它不知道你公司上周发布的《V3.0 接口文档》,也不知道今天的新闻(不调用任何tool的情况下)
- 它的知识有截止日期,导致了幻觉:一本正经地胡说八道(这个大家应该深有体会🤓)
向量数据库的解法:
- 把你公司的文档切片,变成向量,存入向量数据库(这是"长期记忆")。
- 当用户提问时,先把问题变成向量。
- 去向量数据库里搜出最相关的几段文档。
- 把"用户问题 + 搜到的文档"一起扔给 LLM。
- LLM 基于这些文档回答问题。
这让 LLM 看起来像是读过你公司的维基百科一样
RAG的标准架构流程?
阶段一:数据入库
这是一个离线或异步任务。
- 加载 (Load): 读取 PDF/Word/Markdown 文档。
- 切片 (Chunking): 这是最关键的一步。 你不能把整本书存成一个向量。你需要把文本按语义(或固定字符数,如 500 字)切成小块。
- 嵌入 (Embedding): 调用 OpenAI API 或本地模型,把每个 Chunk 变成向量
[]float32。 - 存储 (Upsert): 将
(Vector, Chunk_Text, Metadata)存入向量数据库(如 Milvus)
阶段二:在线检索与生成
这是用户发起请求时的同步流程。
- 问题嵌入: 用户问:"V3 接口怎么鉴权?" -> 调用模型转成向量
Query_Vector。 - 向量检索: 拿
Query_Vector去向量库搜 Top 3 最相似的 Chunks。 - Prompt 组装:
Plaintext
你是一个技术支持助手。请根据以下已知信息回答用户问题。
已知信息:
1. ... (检索到的 Chunk 1)
2. ... (检索到的 Chunk 2)
用户问题:V3 接口怎么鉴权?4.LLM 生成: 将组装好的 Prompt 发给 GPT,得到最终答案
潜在踩坑点😵
在 Demo 阶段,上面的流程跑得很顺。但在生产环境,你会遇到以下问题,这也是后端工程师的价值所在:
1. 切片策略 (Chunking Strategy)
- 问题: 如果切片太小,上下文丢失;如果切片太大,噪音太多且不仅占 Token。
- 解法: 使用
RecursiveCharacterTextSplitter,并设置 Overlap (重叠) 。比如每块 500 字,块与块之间重叠 50 字,保证句子没被切断。
2. 混合检索 (Hybrid Search)
- 问题: 用户搜具体的"错误码 10045"。向量搜索可能找出一堆"错误"、"异常"相关的文档,但偏偏漏了包含"10045"这个数字的文档(因为向量关注的是语义,对精确数字有时不敏感)。
- 解法: 向量检索 (语义) + 关键词检索 (BM25) 同时进行,然后使用 RRF (Reciprocal Rank Fusion) 算法对结果进行加权重新排序。
3. 元数据过滤 (Metadata Filtering)
- 问题: 你存了全公司的文档。但"财务部"的文档不能被"研发部"的人搜到。
- 解法: 在存向量时,写入 Metadata:
{"dept": "finance"}。在查询向量库时,带上filter: "dept == 'finance'"。先过滤,再做向量近似搜索。
总结❤️
从向量 到向量数据库 ,再到RAG,本质上是我们逃出了结构化思维,对数据处理方式的一次升维:
- 向量 是数据的语义压缩。
- 向量数据库 是语义数据的高性能索引。
- RAG 是连接静态数据 与动态智能的桥梁。
对于 Java/Go 开发者来说,现在的机会在于:不要只盯着 LLM 的 API 调用,而是去建设高质量的数据管道 (Data Pipeline) 。因为在 RAG 架构中,检索的质量(数据切得好不好、搜得准不准)直接决定了最终回答的质量。
如果你觉得我写的好,就点赞收藏关注,这是我更新的最大动力!!!