轻量、多语言、高精度,国产 OCR 模型正在重新定义文档理解的边界。
过去一个月,OCR(光学字符识别)领域迎来了一场前所未有的"发布潮"。10 月以来,DeepSeek、百度、上海 AI Lab 相继发布并开源新一代 OCR 模型,掀起全球多模态文档理解的技术热潮。
尤其引人注目的是,10 月 21 日,HuggingFace 全球模型趋势热榜前三名全部被 OCR 模型包揽 ,展现出这一传统技术在大模型时代焕发的新生命力。其中,百度飞桨团队于 10 月 16 日开源的 PaddleOCR-VL 模型 持续登顶 Trending 榜首至今,以及随后发布DeepSeek发布的DeepSeek-OCR ,成为当前最受全球开发者关注的模型。
一、技术突围:OCR 为何再次成为焦点?
OCR 并不是一个新概念。但从去年开始,随着多模态大模型(VLMs)的快速发展,OCR 作为"视觉与文本的桥梁",其技术价值被重新定义。尤其在以下三大趋势推动下,OCR 正在成为 AI 基础设施中的关键组件:
1. RAG 的"输入守门人"
企业知识库中大量信息以扫描文档、合同、报告等非结构化形式存在。OCR 的识别质量直接决定了检索增强生成(RAG)系统的输入质量,进而影响回答的准确性与可靠性。
2. 产业自动化的"效率引擎"
金融、政务、物流等行业依赖高精度、低成本的文档自动化处理。OCR 作为"信息提取层",成为流程数字化中不可或缺的一环。
3. 文明数字化的"转换器"
人类历史与知识大多以纸质或图像形式存在。OCR 技术是实现这些信息数字化、进而成为大模型训练语料的关键前提。
二、双雄并起:DeepSeek-OCR 的理论创新与 PaddleOCR-VL 的实用领先
在本轮 OCR 竞赛中,DeepSeek-OCR 与 PaddleOCR-VL 分别代表了两种不同的技术路径与价值主张。
DeepSeek-OCR:以 OCR 解决大模型"上下文压缩"问题
DeepSeek 在 10 月 20 日开源其 OCR 模型,创新性地提出 "上下文光学压缩" 理念,尝试通过视觉模态解决大语言模型处理长文本时的计算资源爆炸问题。这一思路具有显著的理论前瞻性,为大模型的长文本处理提供了新的可能方向。
PaddleOCR-VL:以 SOTA 性能树立 OCR 实用新标杆
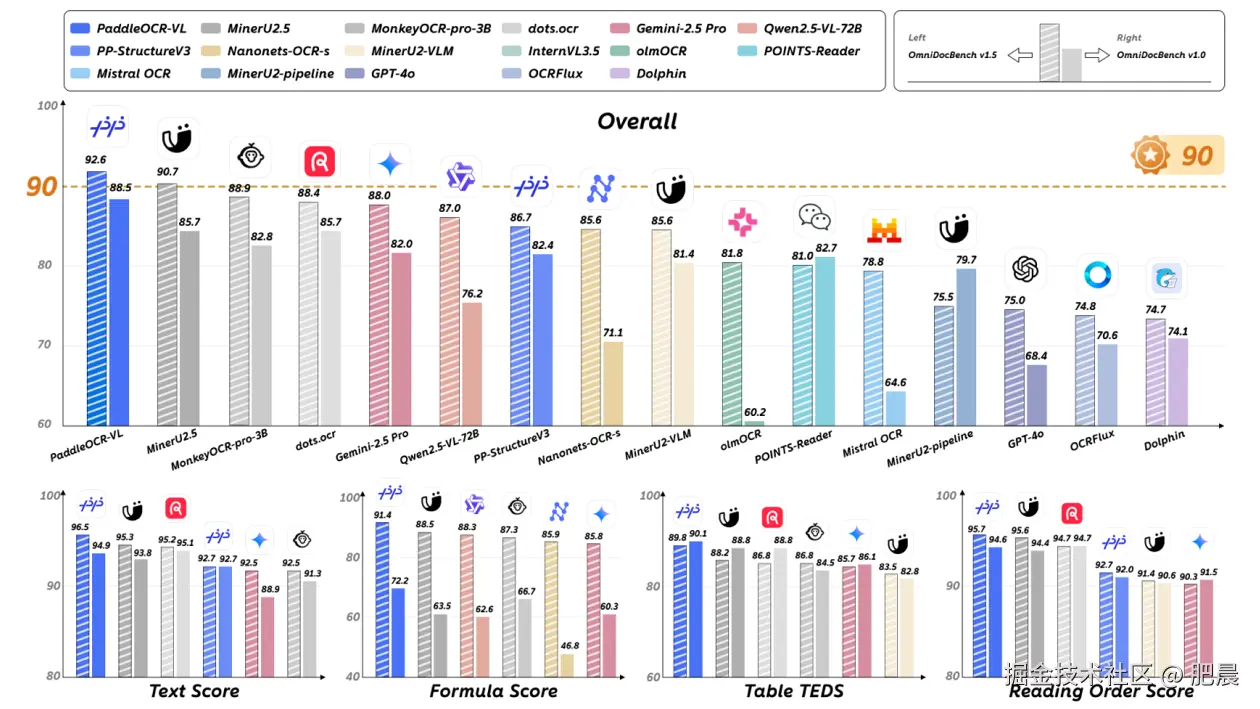
相比之下,PaddleOCR-VL 则更加聚焦于 OCR 本身的核心任务------高精度、多场景、轻量化的文档解析 。在权威评测基准 OmniBenchDoc V1.5 中,PaddleOCR-VL 展现出全面领先的实用性能:
-
综合性能第一 :以 92.56 的综合得分超越 DeepSeek-OCR-Gundam-M(3B)约 6 分,刷新全球纪录;
-
表格理解领先 :在表格结构理解(TEDS)与语义理解(TEDS-S)上分别领先 15.5 分 与 9.9 分;
-
阅读顺序更准 :阅读顺序编辑误差降低约 54%,更符合人类逻辑;
-
极致轻量化 :仅 0.9B 参数量,却在文本、公式、表格、结构理解四大核心任务上实现全线 SOTA。
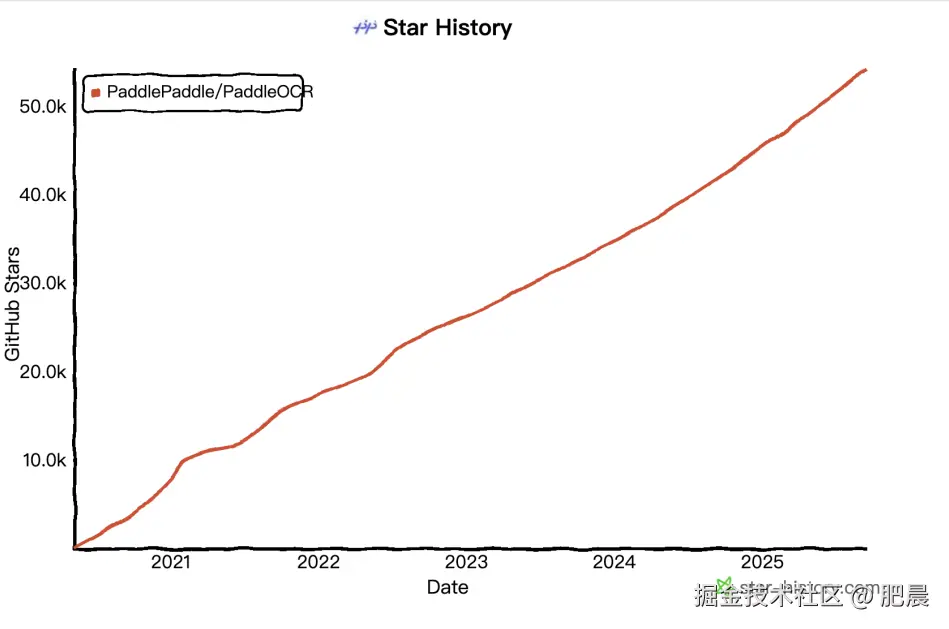
值得一提的是,PaddleOCR-VL 在 GitHub 上是唯一一个 Star 数超过 6 0k 的中国 OCR 项目,开源五年来累计下载突破 900 万次,被超过 5.9k 项目使用,其工业稳定性与社区成熟度已得到充分验证。
三、场景实测:PaddleOCR-VL 的"全能表现"
我们在多种典型场景下对 PaddleOCR-VL 进行了实测,涵盖:
- 手写体中英文识别
刚刚手写了一份非常潦草的英文文档,看一下PaddleOCR-VL 的展现怎么样。
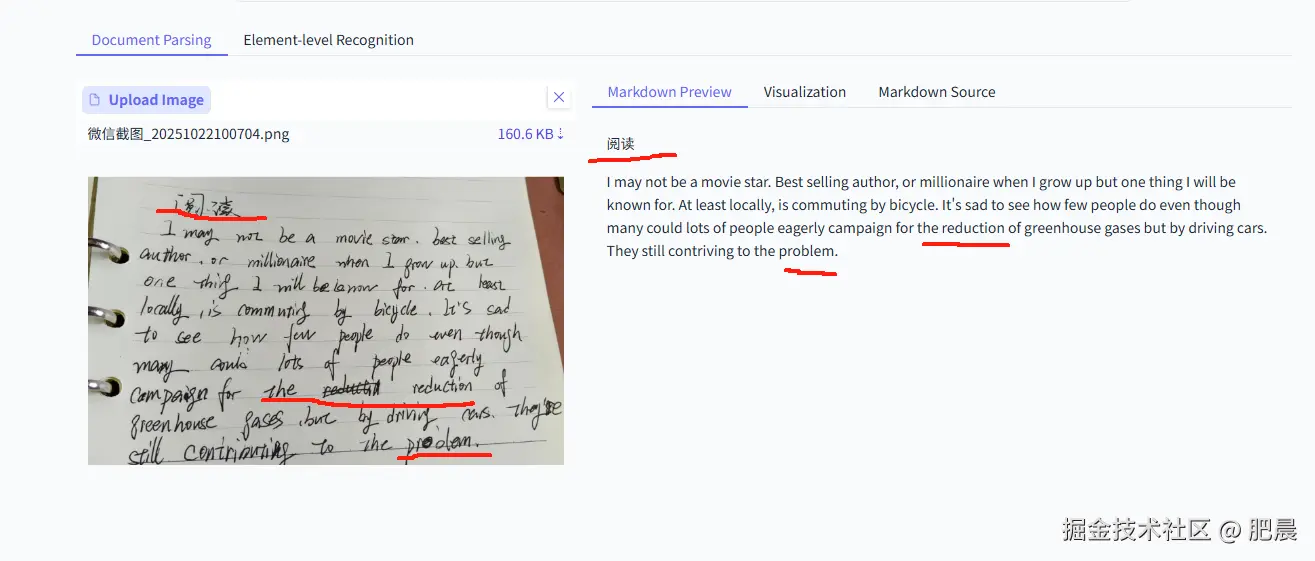
PaddleOCR-VL的展现力非常强,中英文全部读取出来了,并且我写错划掉的也去掉了,下面的单词"problem"写的非常抽象也能读取出来。
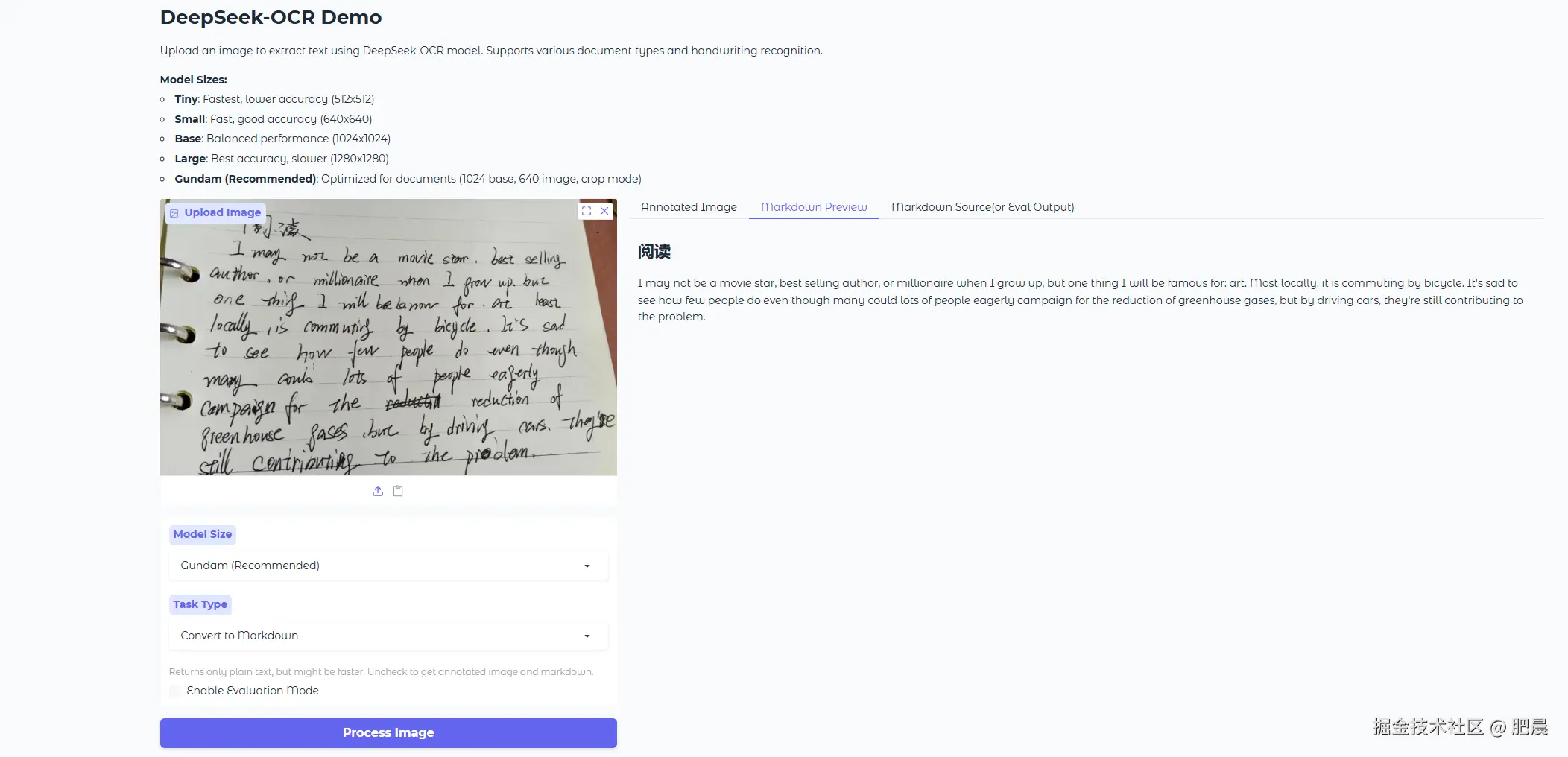
其他平台的展现力也很不错。
- 数学公式
手写了几个极限题,看一下是否能够读取出来。
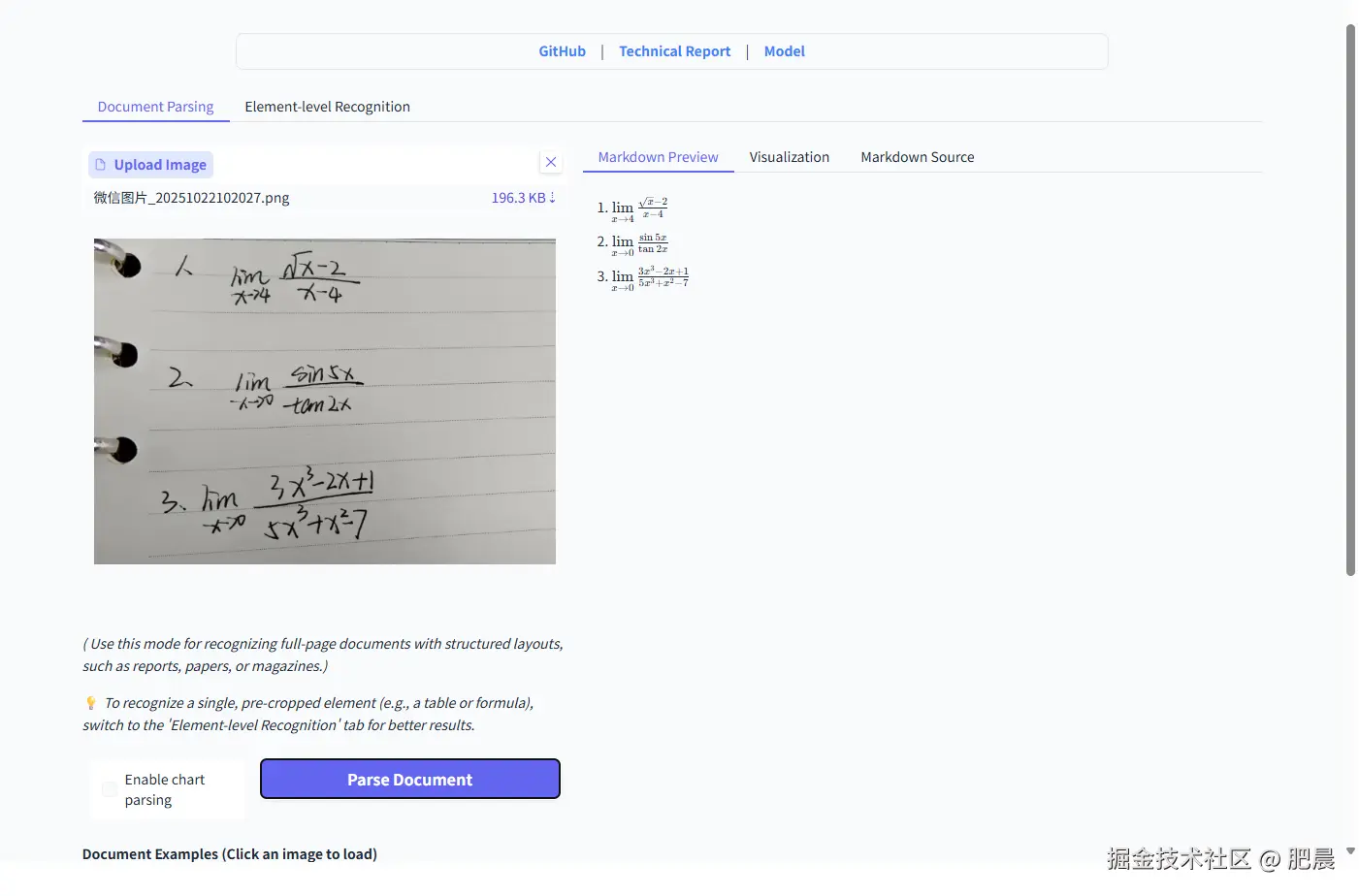
PaddleOCR-VL的展现力非常强,可以直接展示独立数学公式,以后数学老师出卷子也能解放双手了,不用敲LaTeX数学表达式转换了。
其他平台的展现力也很不错,但是并不能直接展示题目,展示的是典型的LaTeX数学表达式格式,并非独立数学公式。
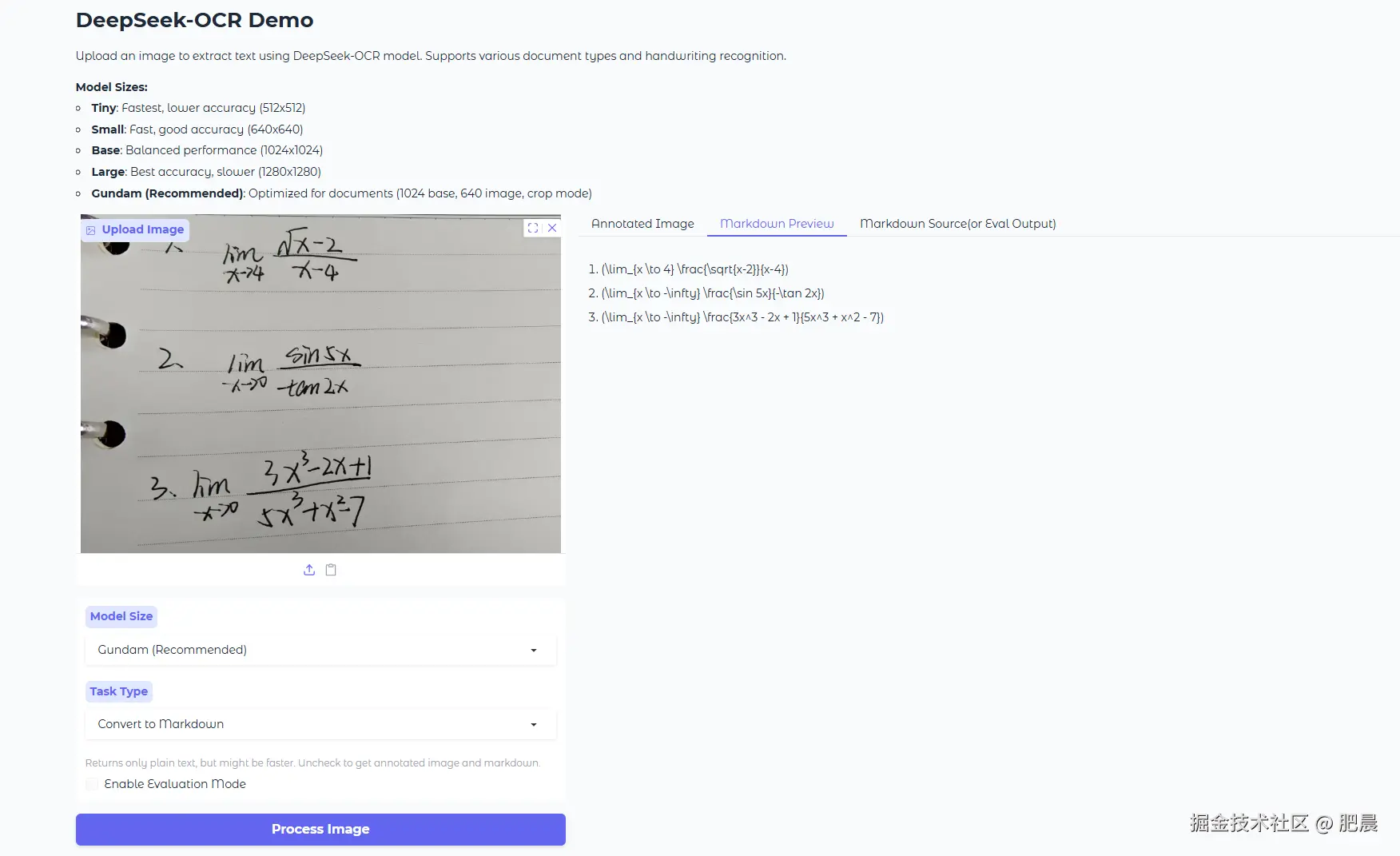
看来这些基础的展现力都很不错。上难度!
- 标签读取
非常高难度的一张图,空调表上面的数字,来看看展现力如何。
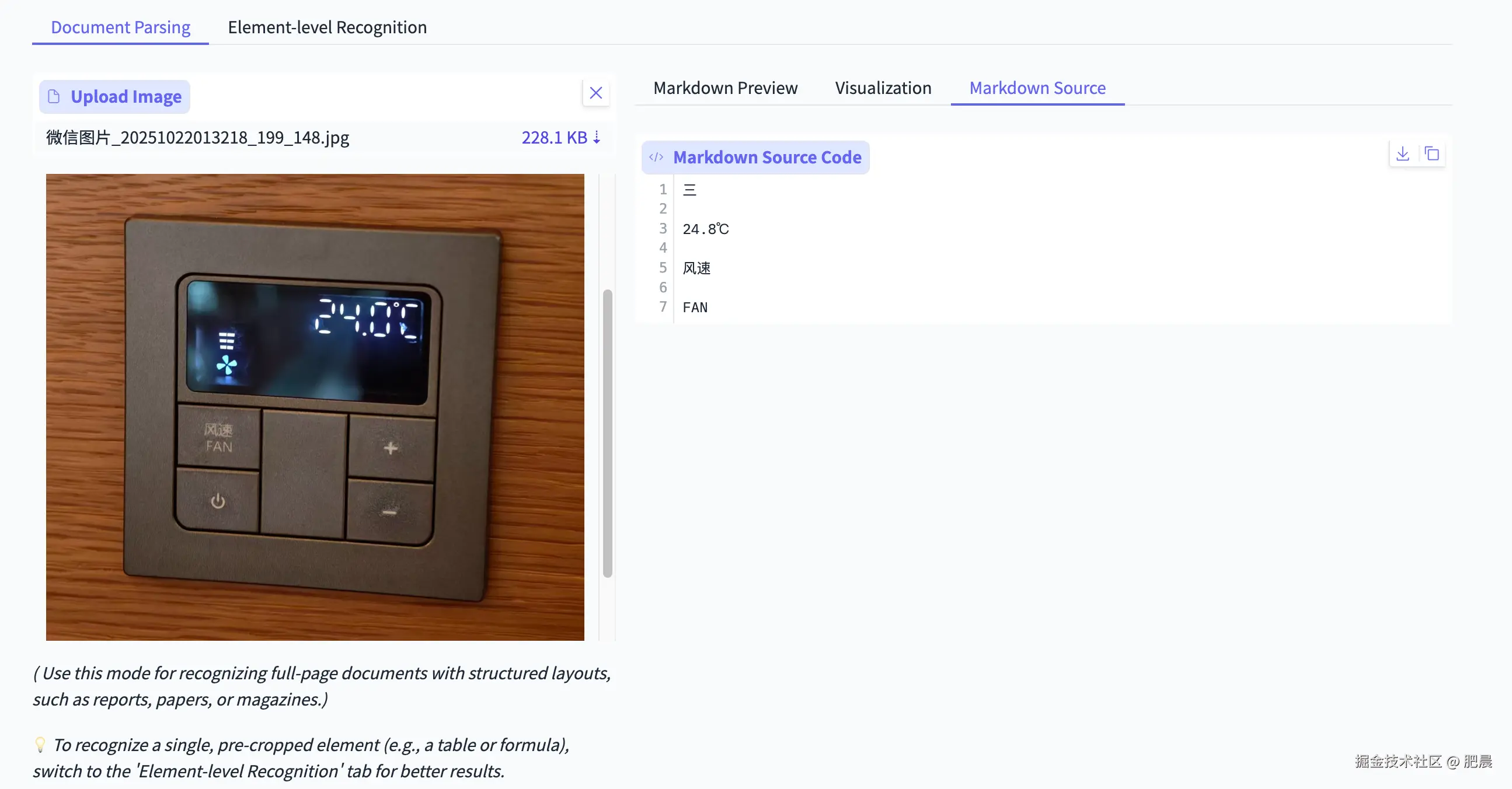
PaddleOCR-VL能识别出显示屏中的大概温度,但小数点后面的数字出错了。三档风速识的icon别成中文"三"。"风速"和"FAN"这个按钮能正确识别出文字,加减号按钮的符号没识别出来。
Deepseek-OCR识别不出任何内容。

- 繁体竖式排版文档
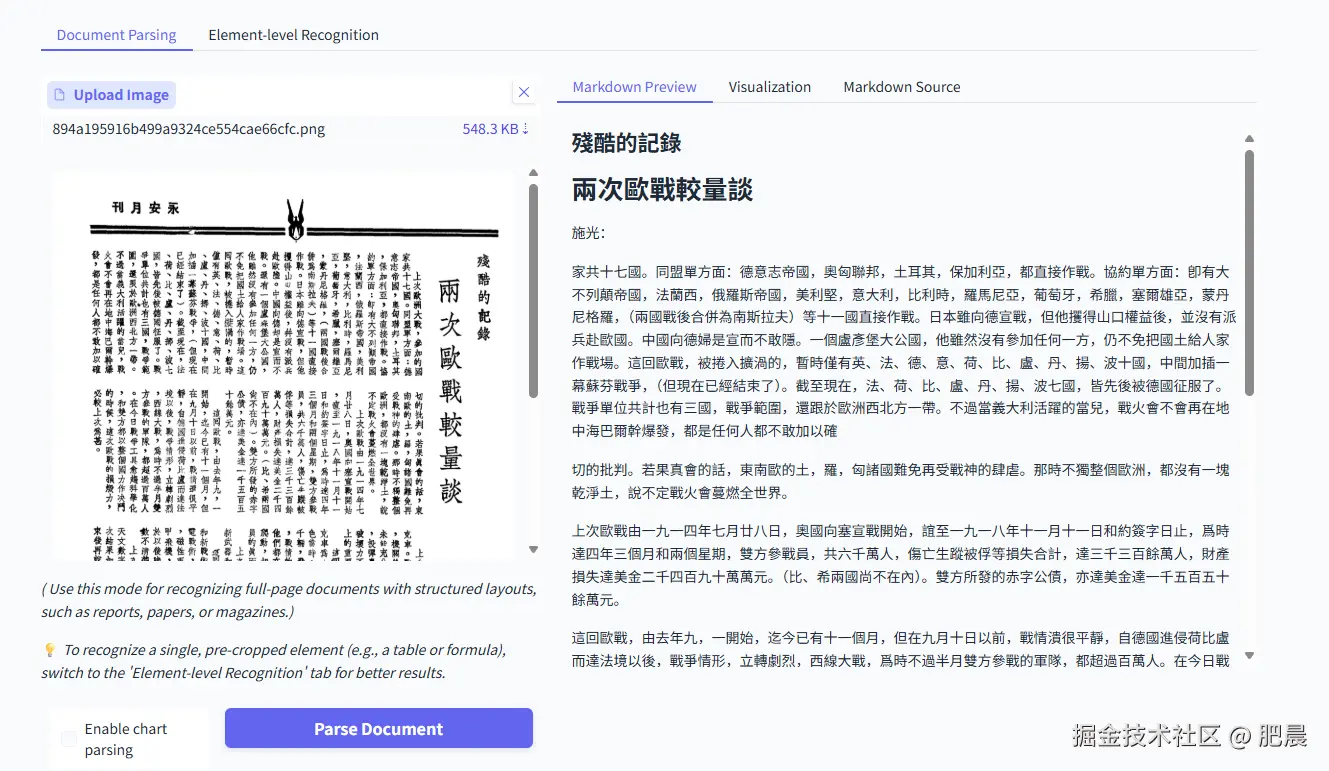
PaddleOCR-VL识别的非常清楚,繁体竖式排版文档分析的非常清楚,并且很完善。
Deepseek-OCR识别乱码了。

测试结果显示,PaddleOCR-VL 在绝大多数场景下输出完整、误识别率低,尤其在竖排文本、手写体、复杂表格等传统 OCR 难点任务上表现稳定。相比之下,DeepSeek-OCR 虽在某些任务上具备潜力,但在实际复杂场景中仍存在部分漏识别、结构误判、甚至"幻觉生成"等问题。
四、开源生态的"破圈之力"
近一个月以来,OCR的模型展现出强大的开源影响力:
- 比如PaddleOCR-VL连续 5 天登顶 HuggingFace Trending 全球第一;
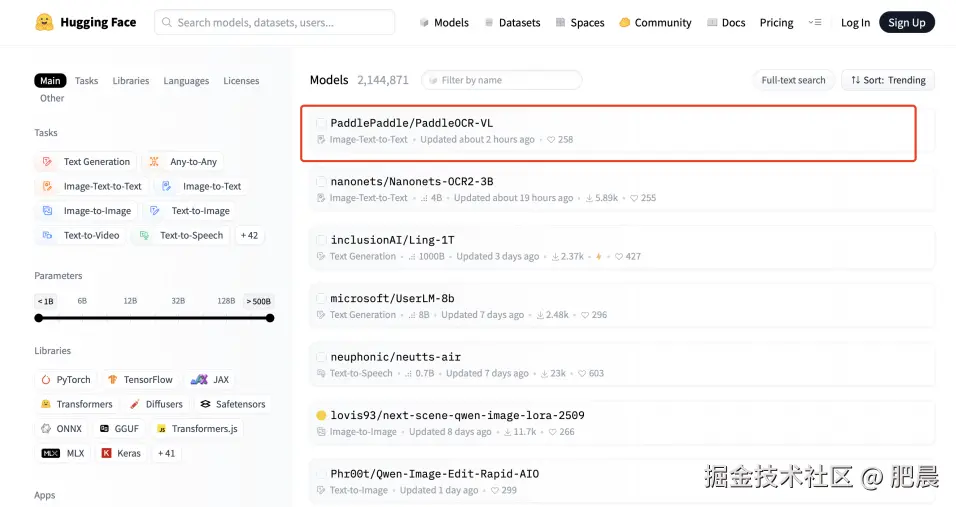
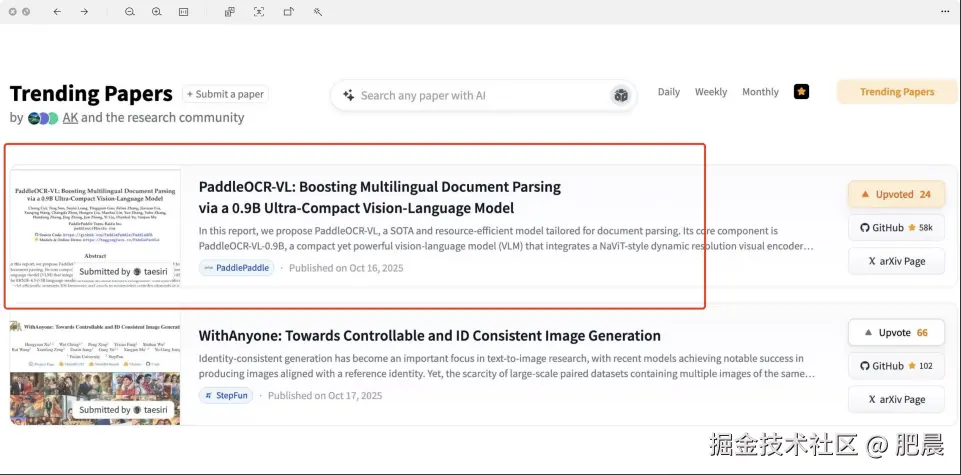
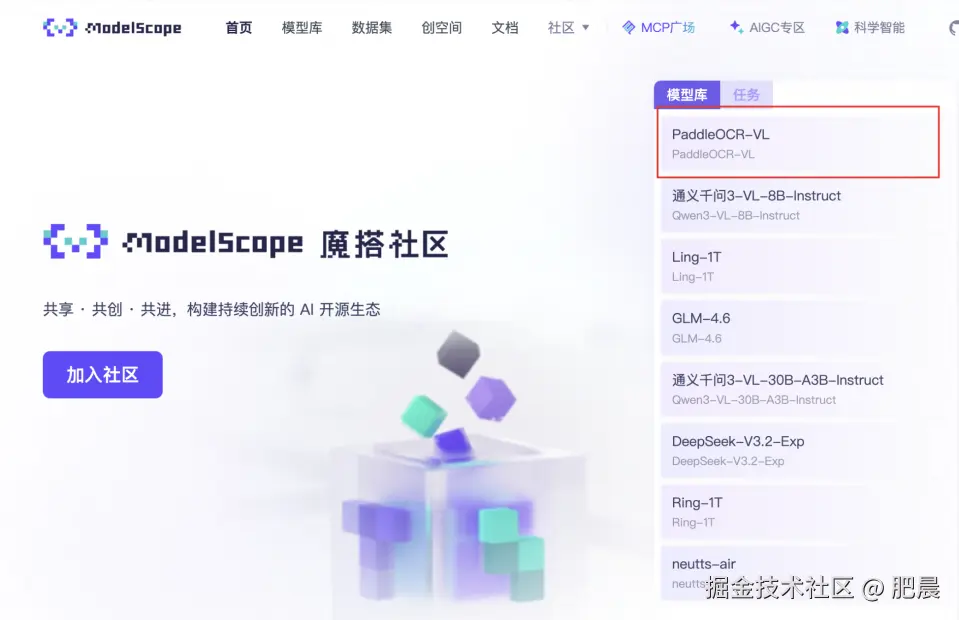
- 同步登顶 ModelScope Trending 全球第一;
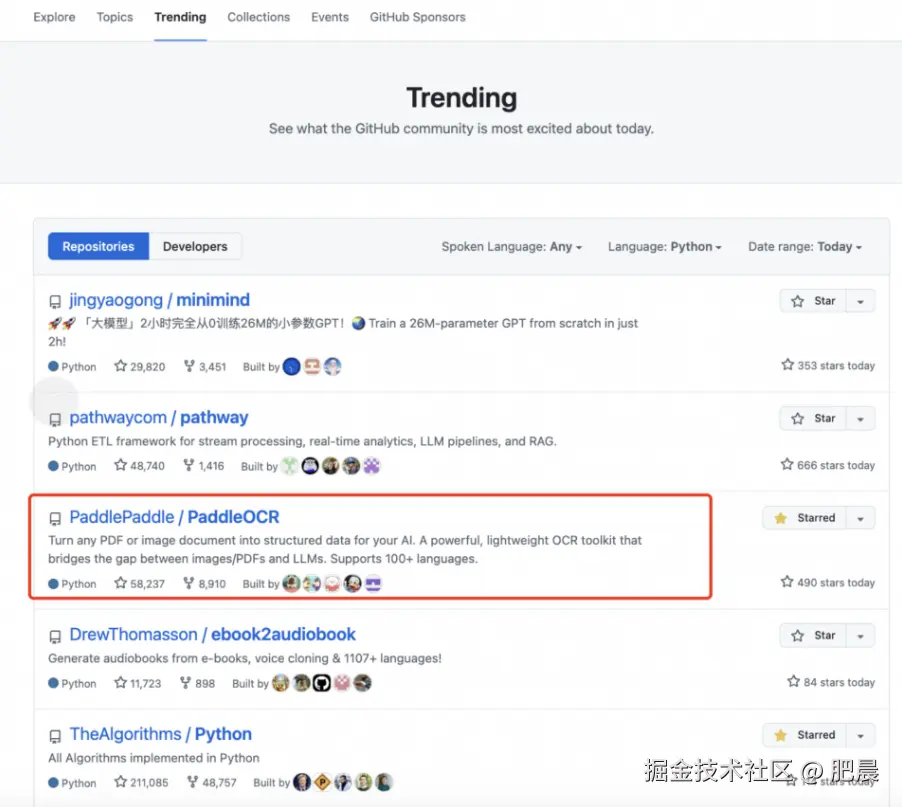
- 跻身 GitHub Python 总榜第 3、全球总榜第 9;
- 提供在线 Demo 与完整开源代码,支持快速部署与二次开发。
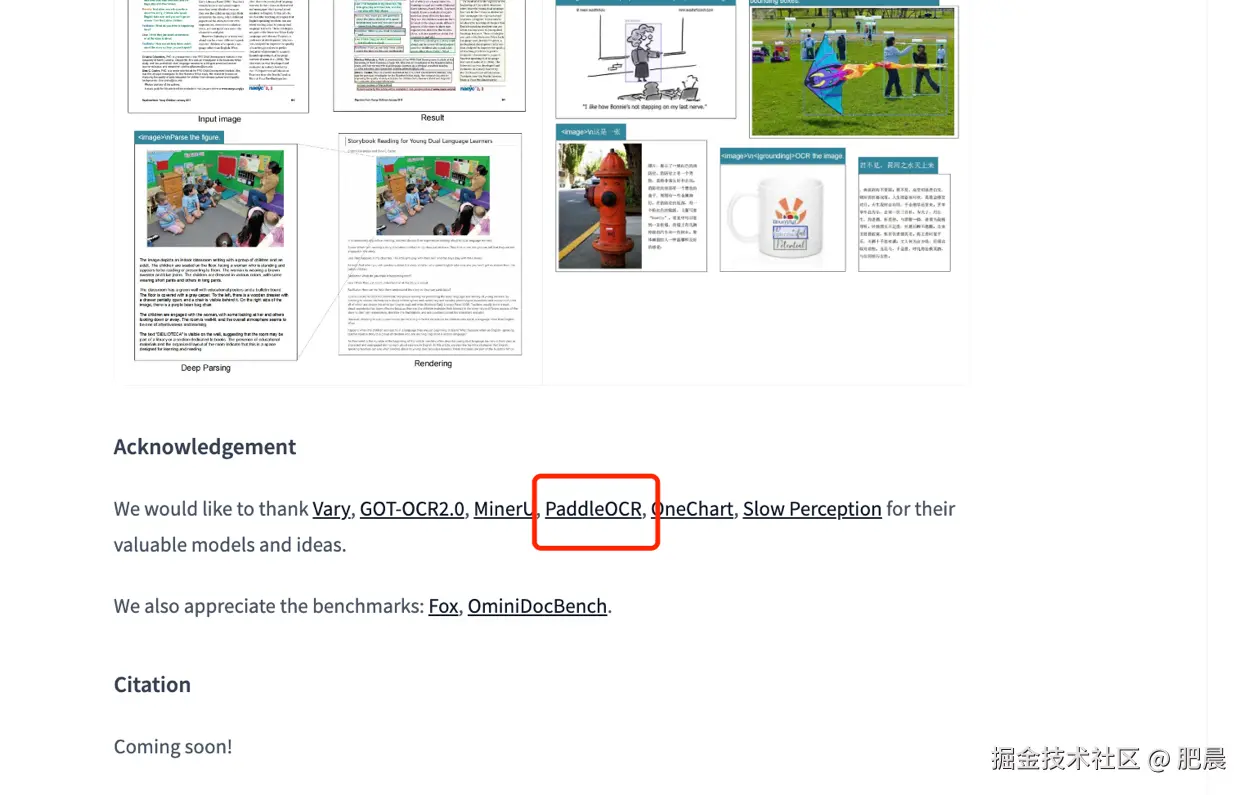
值得注意的是,DeepSeek 在其论文致谢中特别感谢 PaddleOCR,并透露使用 PaddleOCR 进行数据标注------这从侧面印证了 PaddleOCR 在 OCR 领域的基础设施地位。

原文链接:huggingface.co/deepseek-ai...
五、OCR 进入"实用驱动"新时代
如果说 DeepSeek-OCR 代表了 OCR 在"大模型上下文压缩"方向上的前沿探索,那么 PaddleOCR-VL 则代表了当前 OCR 技术在实用性能与产业落地方面的最高水准。
随着多模态大模型不断演进,OCR 作为"视觉与语言交叉点"的关键技术,其战略价值将持续提升。以PaddleOCR-VL和 DeepSeek-OCR为代表的中国模型, 不仅刷新了 OCR 模型的技术天花板,更为金融、教育、出版、文化保护等行业的数字化转换提供了坚实的技术基础,为中国在下一代人工智能基础设施竞争中占据了重要先机。