本文系统梳理了机器学习三大范式:监督学习(有标签数据,含回归与分类算法)、无监督学习(无标签数据,含聚类与降维方法)和强化学习(基于奖惩机制)。重点介绍了12种核心算法原理与适用场景,如线性回归、SVM、K-Means等,并给出算法选择指南:预测数值用回归算法,分类问题选逻辑回归/随机森林,无监督分组用K-Means,特征降维用PCA。文末推荐使用Python的Scikit-learn库快速实现这些算法,通过fit-predict标准流程即可完成模型训练与预测。全文以"教科书教学"等生活化类比解析复杂算法,兼顾技术深度与应用指导性。
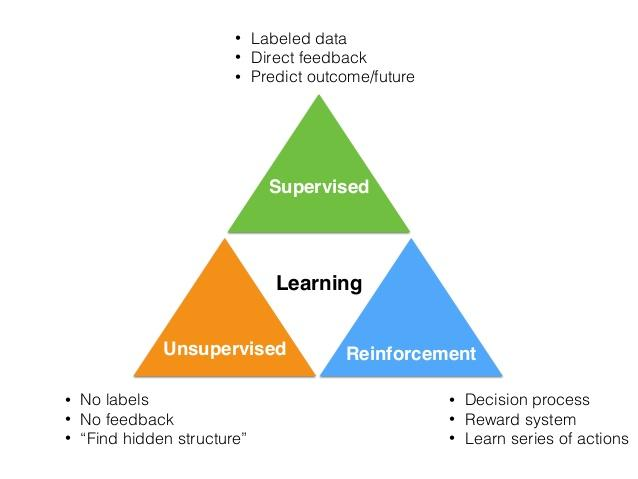
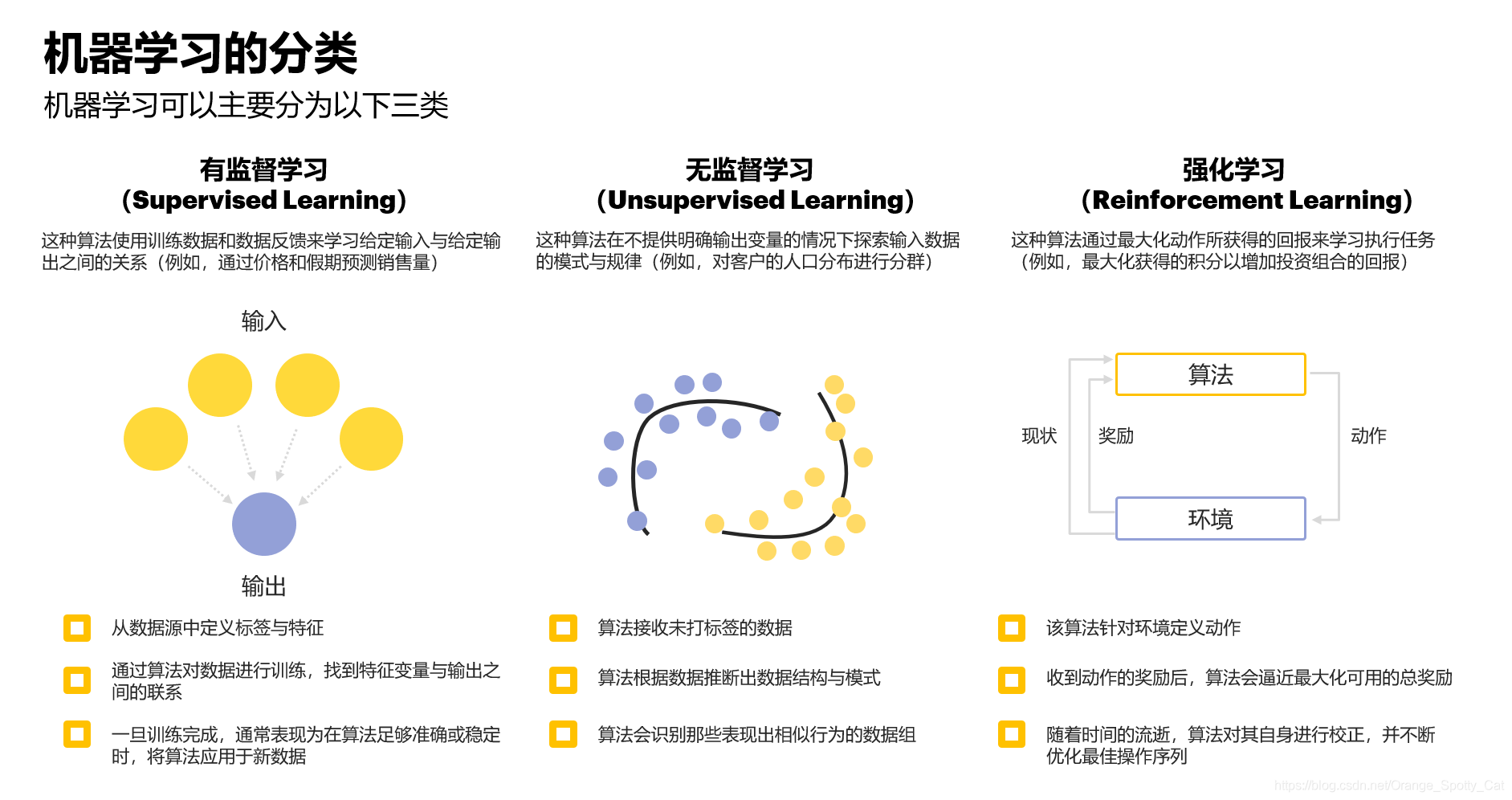
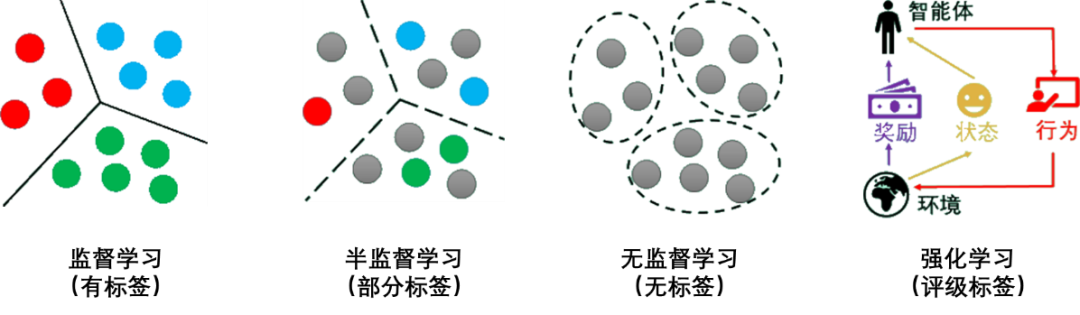

一、 监督学习 (Supervised Learning)
核心逻辑: 老师拿着教科书教学生。给数据(输入 XX),也给答案(标签 YY),让机器学会由 XX 推导 YY。
这是目前应用最广的类型。根据 YY 是数字还是类别,又分为两类:
1. 回归 (Regression) ------ 预测"多少"
输出是一个连续的数字。
- 线性回归 (Linear Regression):
- 原理: 在数据点中画一条直线(y=wx+by=wx+b),让所有点到线的距离之和最小。
- 场景: 预测房价、预测下个季度的销量。
- 多项式回归 (Polynomial Regression):
- 原理: 直线拟合不了,就用曲线(二次方、三次方)去拟合。
2. 分类 (Classification) ------ 预测"是A还是B"
输出是一个离散的类别。
- 逻辑回归 (Logistic Regression):
- 原理: 虽然叫"回归",其实是分类。它在输出端加了一个 Sigmoid 函数,把数值压缩到 0~1 之间(概率)。大于0.5是A,小于0.5是B。
- 场景: 垃圾邮件检测(是/否)、用户是否会点击广告。
- K-近邻 (K-Nearest Neighbors, k-NN):
- 原理: "近朱者赤"。看新来的数据点周围最近的 KK 个邻居大部分是谁,它就是谁。
- 特点: 没有训练过程,直接拿数据比对。
- 支持向量机 (Support Vector Machine, SVM):
- 原理: 在两类数据中间画一条"马路"(超平面)。马路越宽越好(最大化间隔)。
- 数学美感: 几何意义非常清晰,对小样本数据效果极好。
- 朴素贝叶斯 (Naive Bayes):
- 原理: 基于概率论(贝叶斯公式)。假设各个特征之间互不相关。
- 场景: 文本分类(比如判断新闻是体育版还是娱乐版),速度极快。
- 决策树 (Decision Tree):
- 原理: 像人类的流程图。
if 年龄 > 30->if 收入 > 2万->批准贷款。 - 特点: 可解释性最强,你能画出它是怎么想的。
- 原理: 像人类的流程图。
3. 集成学习 (Ensemble Learning) ------ "三个臭皮匠,顶个诸葛亮"
把很多个弱模型组合起来。
- 随机森林 (Random Forest): 种很多棵决策树,最后投票决定结果。
- 梯度提升树 (GBDT / XGBoost / LightGBM): 一棵树学完了,下一棵树专门去学上一棵树犯的错(残差)。这是目前处理表格数据(Excel类数据)的最强王者。
二、 无监督学习 (Unsupervised Learning)
核心逻辑: 只有练习题(输入 XX),没有答案(标签 YY)。机器自己找规律。
1. 聚类 (Clustering) ------ "物以类聚"
- K-Means (K均值聚类):
- 原理: 先随机选 KK 个中心点,把数据分给最近的中心,然后算出新的中心,反复迭代,直到稳定。
- 场景: 客户分群(这波人是价格敏感型,那波是土豪型)。
- DBSCAN:
- 原理: 基于密度的聚类。能发现任意形状的簇,还能识别噪点(离群值)。
2. 降维 (Dimensionality Reduction) ------ "把书读薄"
把高维数据(几百个特征)压缩成低维(2D或3D),同时保留主要信息。
- PCA (主成分分析):
- 原理: 找到数据分布最分散的方向(方差最大),投影过去。数学上就是求协方差矩阵的特征值。
- 场景: 数据可视化、压缩数据以便后续处理。
三、 强化学习 (Reinforcement Learning)
核心逻辑: 驯兽师训练狗。机器(Agent)在环境(Environment)中乱试,做对了给奖励(Reward),做错了给惩罚。
- 基础算法: Q-Learning, SARSA。
- 场景: 下围棋(AlphaGo)、王者荣耀AI、机器人走路。
四、 总结:如何选择?(Cheat Sheet)
| 你的数据情况 | 任务类型 | 推荐算法 (起手式) |
|---|---|---|
| 有标签,预测数值 | 回归 | 线性回归, XGBoost |
| 有标签,预测类别 | 分类 | 逻辑回归, 随机森林, SVM |
| 无标签,想分组 | 聚类 | K-Means |
| 特征太多,想简化 | 降维 | PCA |
| 像玩游戏一样做决策 | 强化 | Q-Learning |
学习建议
用 Python 上手,Scikit-learn (sklearn) 把上面 90% 的算法都封装好了,用法几乎一模一样:
Python
首先安装:pip install scikit-learn
测试:
python
import sklearn
print(sklearn.__version__)使用:
# 经典三板斧
model.fit(X_train, y_train) # 学习
model.predict(X_test) # 考试