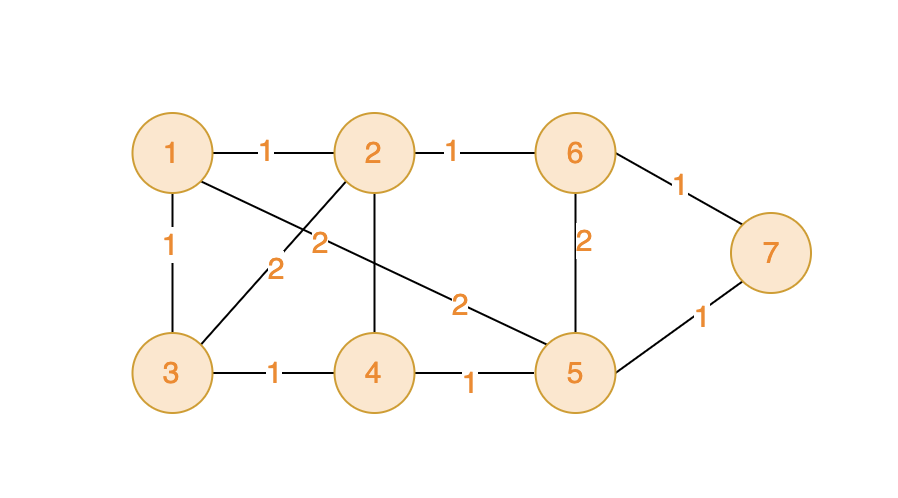
import java.util.*;
class Edge {
int l, r, val; // 起点、终点、权重
Edge(int l, int r, int val) { this.l = l; this.r = r; this.val = val; }
}
public class Main {
private static int n = 10001;
private static int[] father = new int[n];
// 初始化并查集
public static void init() { for (int i = 0; i < n; i++) father[i] = i; }
// 路径压缩查找
public static int find(int u) {
return u == father[u] ? u : (father[u] = find(father[u]));
}
// 合并集合
public static void join(int u, int v) {
u = find(u); v = find(v);
if (u == v) return;
father[u] = v; // 简单合并
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int V = scanner.nextInt(), E = scanner.nextInt();
// 存储所有边
List<Edge> edges = new ArrayList<>();
for (int i = 0; i < E; i++) {
int u = scanner.nextInt(), v = scanner.nextInt(), k = scanner.nextInt();
edges.add(new Edge(u, v, k));
}
// 按权重排序(核心!)
edges.sort(Comparator.comparing(edge -> edge.val));
init(); // 初始化并查集
int result = 0;
// Kruskal算法:从小到大加边
for (Edge edge : edges) {
if (find(edge.l) != find(edge.r)) { // 不同集合才加
result += edge.val; // 累加权重
join(edge.l, edge.r); // 合并集合
}
}
System.out.print(result);
}
}
117.软件构建
题目描述
某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依赖于文件 B,则必须在处理文件 A 之前处理文件 B (0 <= A, B <= N - 1)。请编写一个算法,用于确定文件处理的顺序。
输入描述
第一行输入两个正整数 N, M。表示 N 个文件之间拥有 M 条依赖关系。
后续 M 行,每行两个正整数 S 和 T,表示 T 文件依赖于 S 文件。
输出描述
输出共一行,如果能处理成功,则输出文件顺序,用空格隔开。
如果不能成功处理(相互依赖),则输出 -1。
输入示例
复制代码
5 4
0 1
0 2
1 3
2 4
输出示例
复制代码
0 1 2 3 4
提示信息
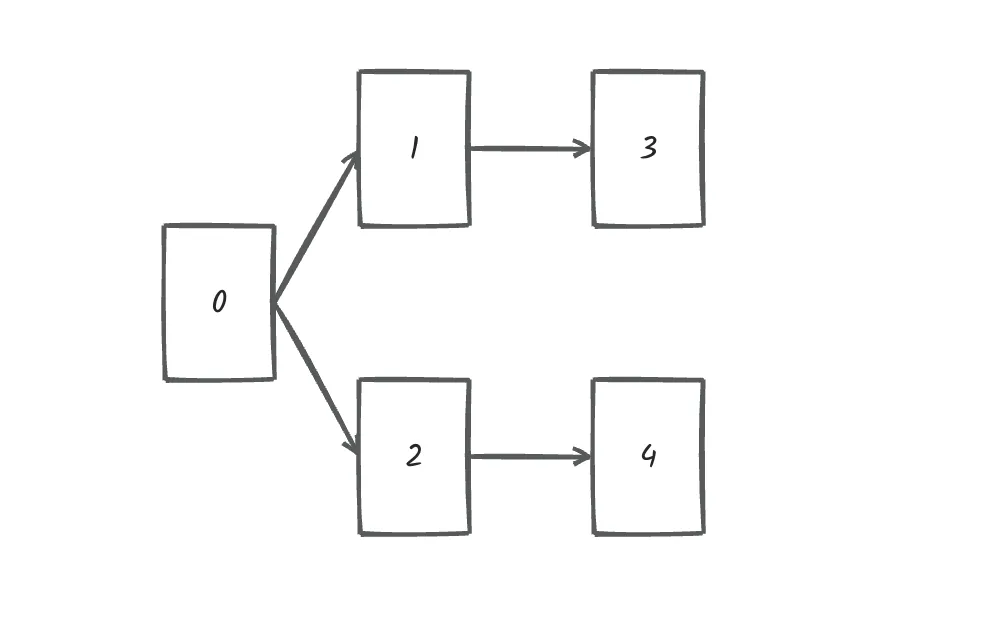
文件依赖关系如下:
所以,文件处理的顺序除了示例中的顺序,还存在
0 2 4 1 3
0 2 1 3 4
等等合法的顺序。
数据范围:
0 <= N <= 10 ^ 5
1 <= M <= 10 ^ 9
每行末尾无空格。
原理
Kahn算法(拓扑排序)
核心 :入度为0 → 处理 → 减少依赖 → 重复
text
复制代码
1. 初始:找所有入度=0的文件入队
2. 循环:
a. 取出队首文件cur,加入结果
b. cur处理完 → 减少其所有依赖文件的入度
c. 新入度=0的文件入队
3. 结果长度==N → 成功;否则 → 存在环
代码
java复制代码
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int N = scanner.nextInt(); // 文件数
int M = scanner.nextInt(); // 依赖关系数
// 入度数组:inDegree[i] = 文件i的依赖数
int[] inDegree = new int[N];
// 邻接表:list[i] = 文件i依赖的文件列表
List<List<Integer>> list = new ArrayList<>();
for (int i = 0; i < N; i++) {
list.add(new ArrayList<>());
}
// 构建图 + 计算入度
for (int i = 0; i < M; i++) {
int s = scanner.nextInt(); // s → t(t依赖s)
int t = scanner.nextInt();
list.get(s).add(t); // s依赖t
inDegree[t]++; // t入度+1
}
// 标记数组:防止重复入队
boolean[] flag = new boolean[N];
// 队列:存储入度为0的节点(无依赖,可先处理)
Queue<Integer> queue = new ArrayDeque<>();
for (int i = 0; i < N; i++) {
if (inDegree[i] == 0) {
queue.add(i);
flag[i] = true;
}
}
// 结果拓扑排序
List<Integer> result = new ArrayList<>();
// Kahn算法:拓扑排序
while (!queue.isEmpty()) {
int cur = queue.poll(); // 取出当前文件
result.add(cur); // 加入结果
// 处理cur的所有依赖文件,入度-1
for (int next : list.get(cur)) {
inDegree[next]--;
}
// 重新扫描找新入度为0的节点
for (int i = 0; i < N; i++) {
if (!flag[i] && inDegree[i] == 0) {
queue.add(i);
flag[i] = true;
}
}
}
// 判断是否所有文件都处理完
if (result.size() == N) {
// 输出拓扑顺序
for (int i = 0; i < N; i++) {
if (i == 0) System.out.print(result.get(i));
else System.out.print(" " + result.get(i));
}
} else {
System.out.print(-1); // 存在环,无法排序
}
}
}