目录
[1. 什么是索引](#1. 什么是索引)
[2. 索引使用的数据结构](#2. 索引使用的数据结构)
[2.1 B 树](#2.1 B 树)
[2.2 B+ 树](#2.2 B+ 树)
[3. Mysql中的页](#3. Mysql中的页)
[3.1 什么是页](#3.1 什么是页)
[3.2 页的结构](#3.2 页的结构)
[3.3 计算三层的B+树能够存储多少条记录](#3.3 计算三层的B+树能够存储多少条记录)
[3.4 优化表的大小](#3.4 优化表的大小)
[4. 索引的分类](#4. 索引的分类)
[4.1 主键索引](#4.1 主键索引)
[4.2 普通索引](#4.2 普通索引)
[4.3 唯一索引](#4.3 唯一索引)
[4.4 聚集索引](#4.4 聚集索引)
[4.5 非聚集索引](#4.5 非聚集索引)
[4.6 索引覆盖](#4.6 索引覆盖)
[4.7 一个表可以有多个索引](#4.7 一个表可以有多个索引)
[5. 使用索引](#5. 使用索引)
[5.1 自动创建索引](#5.1 自动创建索引)
[5.2 手动创建索引](#5.2 手动创建索引)
[5.2.1 创建主键索引](#5.2.1 创建主键索引)
[5.2.2 创建唯一索引](#5.2.2 创建唯一索引)
[5.2.3 创建普通索引](#5.2.3 创建普通索引)
[5.3 创建复合索引](#5.3 创建复合索引)
[5.4 查看索引](#5.4 查看索引)
[5.5 删除索引](#5.5 删除索引)
[5.5.1 删除主键索引](#5.5.1 删除主键索引)
[5.5.2 删除其他索引](#5.5.2 删除其他索引)
[5.6 创建索引注意事项](#5.6 创建索引注意事项)
[5.7 索引失效问题](#5.7 索引失效问题)
1. 什么是索引
索引是数据库中的数据结构,可以帮助我们快速的更新和查找数据。
索引需要消耗额外的内存空间,但是这些空间很小。
2. 索引使用的数据结构
2.1 B 树
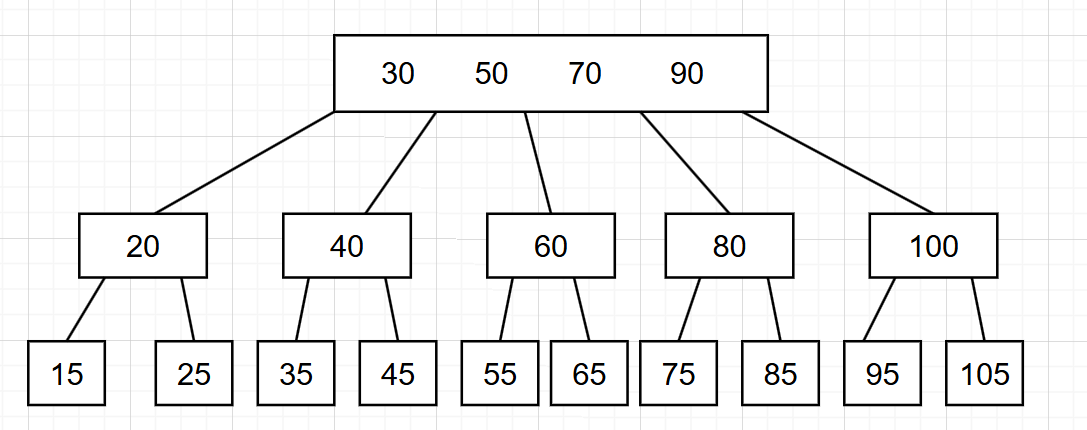
B树是一个n叉搜索树,每个节点有n个子树,每个节点包含n-1个数据。有效的降低了树的高度。
因为mysql在查找的话,需要向硬盘申请数据,如果使用二叉搜索树的话,树的高度过高,每次都要申请数据,开销很大。
下面就是B树的结构:
2.2 B+ 树
mysql在B树的基础上进行了改进,得到一种新的数据结构B+树。
B+树的特点:
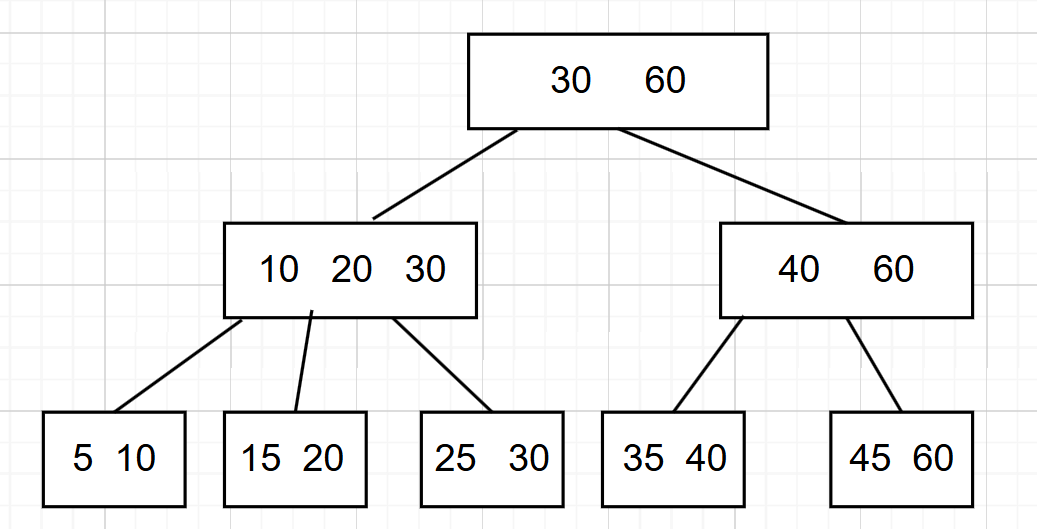
- B+树的每一个节点都有N个节点,每个节点都有N个子节点,也就是每个节点的最后一个值是以这个节点为头结点的树的最大值。
- B+树的父节点的值会作为子节点中最大的值出现。
- 叶子节点会使用双向链表的形式串起来。
- 叶子节点可以包含所有的数据的索引列,我们就可以在叶子节点找到对应的数据,因此非叶子节点只用存储索引列,叶子节点存储数据行。
下面就是一个B+树:
B+树相对于其他数据结构作为索引的优势:
- N叉搜索树,高度比较低,读写硬盘次数比较少。
- 所有的数据都存储在叶子节点中,最后的查询操作也是在叶子节点上进行的,所有在访问硬盘的次数是固定的。
- 叶子节点作为链表,适合范围查询。
- 非叶子节点只需要存储索引列,内存比较小,适合在内存中缓存,减少读取硬盘的次数。
3. Mysql中的页
3.1 什么是页
Mysql中的页指的是B+树上的每个节点,一个节点对应一页,一页的大小默认是16KB,MySQL在与硬盘进行读写操作时都是以页为单位的,并且每次MySQL读取时都至少读取一页,在硬盘中每个页内部的存储空间都是连续的,我们就可以读取一页,每页包含多条数据,下次用的数据在内存中就直接使用,不再的话就再读取,有效的减少了读取硬盘的次数。
这里利用到了局部性原理的思想:
时间局部性: 程序读取了某个数据,程序下一次大概率会读取到这个数据附近的某些数据。
空间局部性:程序读取到某个数据,未来某个时间大概率还会用到这个数据。
3.2 页的结构
数据库中的表是以.ibd文件存储在硬盘上的,每个文件都是二进制的数据,以页为单位进行组织的。
在我们使用索引查询表时候,如果这个表有主键,就以主键列创建索引,如果没有主键,就会生成一个隐藏列来创建索引。
每张页都有页头和页尾,包含索引列和数据行的页称为数据页,只包含索引列的称为索引页。
下面是数据页的大概结构:
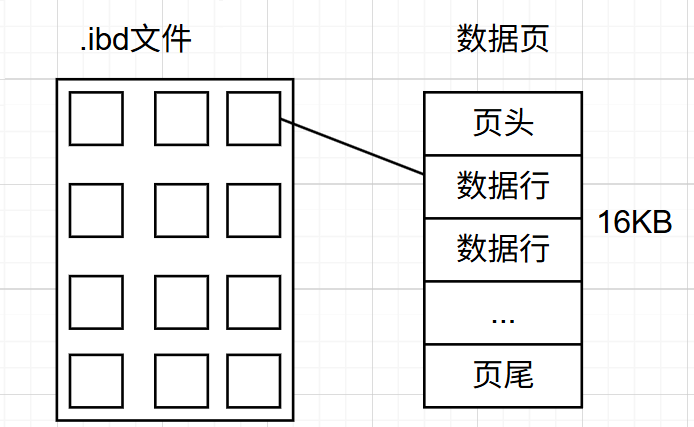
页头大小为38字节,页尾大小为8字节,其余空间全是存储数据行的。
3.3 计算三层的B+树能够存储多少条记录
索引页的每条数据都是由索引列和页的编号组成。
假设索引列的大小为8字节,页的编号为6字节,那么一个索引数据就是14字节。
假设忽略页头和页尾,存储的都是索引行,可以存储 16 * 1024 / 14 大概等于 1170条索引行。
第一层一个节点,第二层1070个节点,第三层1070 * 1070个节点。
叶子节点保存数据行,假设叶子节点的每个数据行的大小为1KB,那么一页可以存储16条数据行。
一共能存储 1070 * 1070 * 16 = 21902400 条数据。
3.4 优化表的大小
我们如何将表的大小进行优化:
可以使用冷热分离将数据分成两个表,一个是热点数据表,一个是冷数据表。将经常使用的数据分到一个表里面,很少使用的数据分到另一个表里面。
我们还可以分库分表:通过表中的字段进行哈希运算,进行划分表。
4. 索引的分类
4.1 主键索引
表中的主键就是一个索引,如果表中没有唯一且不重复的列的话,就会由MySQL创建一个索引列。
4.2 普通索引
通过sql语句创建索引,可能包含多个列。
4.3 唯一索引
被unique修饰的列,就是唯一索引,该列元素不能重复。
4.4 聚集索引
InnoDB是MySQL中的数据存储模块,负责数据存储在硬盘上的。
当表中没有主键时候,InnoDB就会找到最先出现的被unique和not null修饰的列作为聚集索引。
如果上面都没有,InnoDB就会自己生成大小为6字节的行号ROW_ID列,此列递增,该列作为索引列。
4.5 非聚集索引
聚集索引以外的索引称为非聚集索引或者二级索引。
二级索引里面对应的行都包括该行的主键列,找到主键列后,再根据主键列找到对应的数据行。
4.6 索引覆盖
当select语句使用了普通索引,并且查询的列刚好是普通索引的部分列或者全部列,可以直接返回查询结果,不用进行回文操作,这就是索引覆盖。
4.7 一个表可以有多个索引
我们定义一个主键索引id,再定义一个name索引,这时候会有两个B+树,主键B+树叶子节点会存储数据行,name索引的B+树会存储id,我们利用name创建的索引去查数据时候,会先在name的B+树上查到对应id,然后再去另一棵树上去查找对应的数据行。这种查询两次的方式叫做回文。
这种回文的方法也比遍历查询的速度快。
5. 使用索引
5.1 自动创建索引
当我们为表添加主键约束,唯一约束,外键约束,会将对应列创建为索引。
如果上面都没有,mysql的数据存储模块(InnoDB)就会自动创建一个索引列ROW_ID。
5.2 手动创建索引
5.2.1 创建主键索引
sql
#直接添加索引约束
create table student(
id primary key auto_increment,
name varchar(20)
);
#单独创建某列为主键
create table student(
id auto_increment,
name varchar(20),
primary key(id)
);
#将某一列创建为主键索引
create table student(
id int,
name varchar(20)
);
alter table student add primary key(id);5.2.2 创建唯一索引
sql
#直接添加唯一约束
create table student(
id primary key auto_increment,
name varchar(20) unique
);
#单独创建某列为唯一索引
create table student(
id primary key auto_increment,
name varchar(20),
unique(name)
);
#将某一列创建为唯一索引
create table student(
id primary key auto_increment,
name varchar(20)
);
alter table student add unique(name);5.2.3 创建普通索引
sql
#创建表时指定索引列
create table student(
id primary key auto_increment,
name varchar(20) unique,
sno varchar(20),
index(sno)
);
#修改表中的列为普通索引
create table student(
id primary key auto_increment,
name varchar(20),
sno varchar(20)
);
alter table student add index(sno);
#单独创建索引并自己命名
create table student(
id primary key auto_increment,
name varchar(20),
sno varchar(20)
);
create index index_sno on student(sno);5.3 创建复合索引
创建符合索引的过程和创建普通索引的过程基本相同,只是复合索引包含多个列:
sql
#创建表时候创建复合索引
create table student(
id int primary key auto_increment,
name varchar(20),
sno varchar(20),
class_id int,
index(sno,class_id)
);
#修改表中的某些列为复合索引
create table student(
id int primary key auto_increment,
name varchar(20),
sno varchar(20),
class_id int,
);
alter table student add index(sno,class_id);
#单独创建索引并命名
create table student(
id int primary key auto_increment,
name varchar(20),
sno varchar(20),
class_id int,
);
create index index_name on student(sno,class_id);5.4 查看索引
sql
#方法一:
show keys from 表名;
#方法二:
show index from 表名;
#方法三:
desc 表名;5.5 删除索引
5.5.1 删除主键索引
sql
alter table 表名 drop primary key;
#如果有自增约束,先去除约束
alter table 表名 modify id int;
alter table 表名 drop primary key;5.5.2 删除其他索引
sql
#语法
alter table 表名 drop index 索引名;5.6 创建索引注意事项
对于一些很大的表来说,创建索引是很危险的,因为要进行大量的硬盘的IO操作。
我们应该把索引创建在查询频率高的列上。
一般最初设计表的时候,就规划好了索引。
假设一台mysql的服务器正在运行,如何给这台服务器添加索引?
我们可以找到一台未工作的服务器,将添加好索引的数据搭建在这台服务器上,然后将应用程序接到新的服务器上。
5.7 索引失效问题
我们创建索引,如果没有使用,那么依旧是采用遍历表的方式查询数据,那么此时的索引就属于失效,没有使用。
单个列索引:
- 在查询时候,查询条件中没有索引列。
- 在查询过程中,查询条件使用了索引列,但是索引列比较单一,比如性别:男/女,依然要遍历整个表。
- 查询时候,查询条件对查询列进行了表达式计算或者隐式类型转换,比如:id + 10 > 50。
- 查询条件包含or,并且一边是包含索引列,一边不包含索引列,比如:id > 20 or class_id < 10。
- 查询条件字符串查询包含like,并且是"%孙"这种形式的。
- 查询条件是 i= 或者 not 之类的。
- 多个表联合查询,但是表之间的字符集不同。
复合索引:
假设有a b c d e f 六个列,我们设置a b c三个列为复合索引,我们会先根据a索引来查询,相同的话,再根据b索引,还相同,再根据c索引来查。如果我们根据a来查后直接根据c来查就会失效。
我们可以使用explain关键字来查看SQL语句的 是否使用索引,以及使用的那种索引。